二维连续型随机变量
- 格式:ppt
- 大小:605.00 KB
- 文档页数:37



二维连续型随机变量分布函数及概率的计算1. 引言1.1 背景介绍随着现代科学技术的不断发展,随机变量理论作为概率论和数理统计中的重要分支,已经成为了各个领域研究的重要工具之一。
而在随机变量理论中,二维连续型随机变量的分布函数及概率的计算更是一个重要且复杂的问题。
二维连续型随机变量是指在二维空间中取值的连续的随机变量,其分布函数的计算涉及了多元积分和概率密度函数等高阶数学知识。
对于二维连续型随机变量分布函数及概率的计算,研究者们一直在探索各种不同的方法和技术。
通过推导分布函数和利用概率密度函数,可以计算出不同事件的概率,从而更好地理解与分析随机变量的性质和特点。
常见的二维分布,如正态分布、均匀分布等,在实际问题中的应用也十分广泛。
研究二维连续型随机变量分布函数及概率的计算对于深入理解概率论和数理统计的基本原理,解决实际问题具有重要意义。
本文将深入探讨二维连续型随机变量的定义、分布函数的推导、概率的计算方法、常见二维分布的概率计算、以及其特性分析,旨在为读者提供对这一重要领域的全面认识和理解。
1.2 研究意义二维连续型随机变量分布函数及概率的计算在概率论和统计学中具有重要的研究意义。
通过对二维连续型随机变量的分布函数和概率的计算,可以帮助我们更好地理解随机现象的规律性和不确定性。
这对于深入研究各种实际问题,如金融市场波动、自然灾害发生等具有重要意义。
二维连续型随机变量的分布函数和概率计算是概率统计学中的基础知识,对于建立概率模型、进行风险评估和决策分析等方面都至关重要。
通过研究二维连续型随机变量的特性和常见分布的概率计算方法,还可以为实际问题的解决提供重要的参考。
深入探讨二维连续型随机变量的分布函数及概率的计算,不仅对学科发展具有重要意义,也对社会问题的解决有着积极的推动作用。
通过本文对该方面的研究,我们能够更全面地理解和应用二维连续型随机变量的相关知识,同时也为未来在这一领域的深入探索提供了基础和指导。

二维连续型随机变量公式 随机变量在概率论中起着重要的作用,它是对可能的结果进行数值化表示的工具。
在概率论中,随机变量可以分为离散型和连续型两种。
本文将重点探讨连续型随机变量中的二维连续型随机变量及其相关的公式。
首先,我们来介绍一些基本概念。
二维连续型随机变量是指对平面上的某个区域内的可能结果进行数值化表示的随机变量。
该随机变量可用一个二维函数来描述其概率密度函数 (Probability Density Function, 简称PDF)。
概率密度函数是一个非负的实值函数,满足以下两个条件:1、对于任意的(x, y),概率密度函数f(x, y) ≥ 0;2、二重积分∬f(x, y)dxdy的值为1。
概率密度函数可以用来计算某个点落在某个区域内的概率。
在二维连续型随机变量中,还有一些相关的重要概念,如累积分布函数 (Cumulative Distribution Function, 简称CDF)、边缘概率密度函数 (Marginal Probability Density Function) 和条件概率密度函数 (Conditional Probability Density Function)等。
累积分布函数F(x, y)表示随机变量(X, Y)的取值小于等于(x, y)时的概率,即F(x, y) = P(X ≤ x, Y ≤ y)。
边缘概率密度函数fX(x)和fY(y)分别表示随机变量X和Y的概率密度函数。
条件概率密度函数fY|X(y|x)表示在已知X的取值为x的条件下,随机变量Y的取值为y 的概率密度。
有了以上必要的基本概念和定义,我们可以进一步讨论二维连续型随机变量的相关公式。
首先是概率密度函数的性质。
对于任意的可测集合A,有P((X, Y)∈A) = ∬Af(x, y)dxdy。
根据这个性质,我们可以计算随机变量落在某个集合内的概率。
接下来是边缘概率密度函数和条件概率密度函数之间的关系。




二维连续型随机变量的几何意义二维连续型随机变量是指在一个平面上取值的随机变量,它的几何意义可以通过概率密度函数来描述。
概率密度函数(Probability Density Function,简称PDF)是用来描述随机变量取值的概率分布的函数。
对于二维连续型随机变量,其概率密度函数是一个二维函数。
假设有一个二维连续型随机变量(X, Y),我们可以通过概率密度函数f(x, y)来描述其几何意义。
概率密度函数f(x, y)表示在某个区域上随机变量(X, Y)取值的概率密度,即单位面积上随机变量(X, Y)取值的概率。
在几何上,我们可以将概率密度函数f(x, y)表示为一个曲面。
这个曲面的高度表示概率密度,即在这个点上随机变量(X, Y)取值的概率密度大小。
曲面的轮廓线表示概率密度相等的点,即在这些点上随机变量(X, Y)取值的概率密度相等。
通过观察概率密度函数的图像,我们可以获得二维连续型随机变量的几何意义。
具体包括以下几个方面:1. 概率密度最大值所在的点表示随机变量(X, Y)取值最可能出现的点。
这个点的概率密度最大,意味着在这个点上随机变量(X, Y)取值的概率最高。
2. 概率密度较高的区域表示随机变量(X, Y)取值的一些可能范围。
在这些区域内,随机变量(X, Y)取值的概率较高。
3. 不同概率密度的轮廓线表示随机变量(X, Y)取值的不同概率水平。
一般来说,概率密度越大的轮廓线表示随机变量(X, Y)取值的概率越高。
4. 概率密度函数的图像还可以提供一些关于随机变量(X, Y)取值的其他信息,比如随机变量(X, Y)的均值、方差等。
根据概率密度函数的图像,我们可以对随机变量(X, Y)的取值范围、取值的平均程度等有一定的了解。
总之,二维连续型随机变量的几何意义可以通过观察概率密度函数的图像来获得。
概率密度函数描述了在平面上随机变量(X, Y)取值的概率分布,通过观察概率密度函数的特征,我们可以了解随机变量(X, Y)取值的可能范围、可能程度等几何性质。

二维连续型随机变量分布函数及概率的计算
二维连续型随机变量是指具有两个维度的随机变量,其取值可以是一个平面上的任意一个点。
与一维连续型随机变量类似,二维连续型随机变量也有分布函数和概率密度函数。
对于任意的实数x和y,定义二维随机变量(X,Y)的分布函数为:
F(x,y) = P(X≤x, Y≤y)
P表示概率,F(x,y)表示(X,Y)取值在区域(-∞,x] × (-∞,y]中的概率。
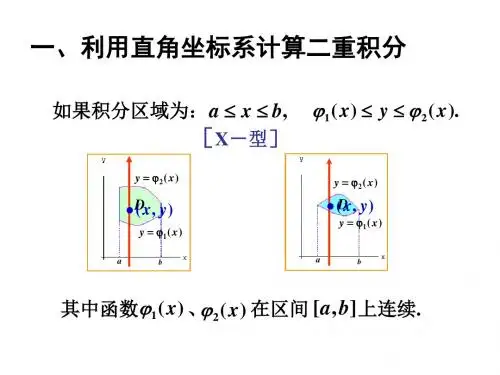
D表示平面上的任意一个区域,∬表示对D进行二重积分。
如果f(x,y)满足以下两个条件,即可称为(X,Y)的概率密度函数:
1. 非负性:f(x,y)≥0,对于任意的实数x和y成立。
2. 归一性:∬R f(x,y)dxdy = 1,其中R表示整个平面。
三、概率的计算
根据概率密度函数可以计算二维随机变量的概率。
对于任意的区域D,有:
如果要计算二维随机变量(X,Y)在区域D内的概率,可以通过计算概率密度函数在该区域上的积分来得到。
具体计算方法是将概率密度函数带入积分式中,并对x和y分别进行积分。
总结:二维连续型随机变量的分布函数是一个二维平面上的函数,可以用来描述随机变量在某个区域内取值的概率。
而概率密度函数则是用来计算二维随机变量在某个区域内的概率的函数。
在计算概率时,可以通过对概率密度函数进行积分来得到。

二维连续型随机变量公式
二维连续型随机变量(或称二维随机向量)是指有两个连续变量
的随机变量。
其概率密度函数(PDF)可以表示为f(x, y),其中x和
y是二维随机变量的取值。
对于二维连续型随机变量,我们可以使用多种方法来表达其概率。
以下是几种常见的表示方法:
1.边缘概率密度函数:边缘概率密度函数是指将二维随机变量的
概率分布转化为一个单独维度的概率分布。
例如,边缘概率密度函数
fX(x)表示X的概率分布,边缘概率密度函数fY(y)表示Y的概率分布。
边缘概率密度函数可以通过对二维概率密度函数在另一个变量的所有
取值上积分得到。
2.条件概率密度函数:条件概率密度函数是指在已知一个变量的
条件下,另一个变量的概率分布。
例如,给定Y=y的条件下,随机变
量X的条件概率密度函数为fX|Y(x|y)。
条件概率密度函数可以通过对二维概率密度函数进行归一化得到。
3.相关系数和协方差:相关系数和协方差用于衡量两个随机变量之间的线性相关性。
相关系数ρ可以通过计算协方差cov(X, Y)以及X和Y的标准差σX和σY来得到。
如果ρ接近于1,表示两个随机变量具有正相关关系;如果ρ接近于-1,表示两个随机变量具有负相关关系;如果ρ接近于0,表示两个随机变量没有线性相关关系。
此外,还有一些其他与二维连续型随机变量相关的概念和方法,如联合分布函数、矩阵、边际分布、条件分布等。
这些方法可以用于描述和分析二维随机变量的统计特征、相关性以及它们与其他变量之间的关系。
二维连续型随机变量相互独立的充要条件
二维连续型随机变量相互独立的充要条件是指,给定两个随机变量X和Y,它们的联合概率密度函数为f(x, y),如果满足以下条件,则称X和Y是相互独立的:
1. 边缘概率密度函数独立:X和Y的边缘概率密度函数分别为f_X(x)和f_Y(y),如果f(x, y)可以表示为f_X(x)乘以f_Y(y)的形式,即 f(x, y) = f_X(x) * f_Y(y),则X 和Y相互独立。
2. 条件概率密度函数独立:对于任意的实数a和b,如果f(x,y)不等于0,那么
条件概率密度函数满足以下条件:f_X|Y(x|y) = f_X(x) 和 f_Y|X(y|x) = f_Y(y)。
其中,f_X|Y(x|y)表示在给定Y=y的条件下,随机变量X的条件概率密度函数。
需要注意的是,这里的相互独立是指X和Y的取值之间没有任何关联,即对
于任意的x和y,知道了X的取值并不能提供任何关于Y的信息,反之亦然。
通过满足上述两个条件,我们可以判断二维连续型随机变量X和Y是否相互
独立。
这种相互独立的情况在概率统计学中是非常重要的,它简化了许多计算和分析的过程,为数理统计学的应用提供了基础。
《二维连续型随机变量的几何意义》1. 引言在概率论与数理统计中,随机变量是一个非常重要的概念。
在二维连续型随机变量中,更是涉及到了平面上两个维度的随机变量。
本文将从几何意义的角度出发,探讨二维连续型随机变量的特点、分布、密度函数以及其在实际问题中的应用。
2. 二维连续型随机变量的定义我们先来了解一下二维连续型随机变量的定义和特点。
在二维平面上,任意一个点(x, y)都可以作为一个二维连续型随机变量的取值。
而其概率密度函数f(x, y)可以描述在(x, y)处取到的概率密度。
这样,我们可以通过对二维平面上的任意区域进行积分,来得到对应区域内取值的概率。
3. 二维连续型随机变量的分布二维连续型随机变量的分布包括边缘分布和联合分布。
边缘分布描述了在某一变量上的分布情况,而联合分布则描述了两个变量同时取值的情况。
其中,边缘分布可以通过联合分布对某个变量进行积分得到。
而联合分布则可以通过概率密度函数f(x, y)来计算任意区域内的概率。
4. 二维连续型随机变量的几何意义从几何意义上来看,二维连续型随机变量可以被理解为在二维平面上的概率密度分布。
通过对概率密度函数的图像进行分析,我们可以发现其中的一些几何特征。
概率密度函数的图像能够直观地表现出不同区域内取值的概率大小,从而帮助我们理解随机变量的分布规律。
5. 二维连续型随机变量的应用在实际问题中,二维连续型随机变量的应用非常广泛。
在经济学中,可以用二维连续型随机变量来描述两个相关变量之间的关系;在物理学中,可以用来描述在二维平面上的物理过程等。
通过对二维连续型随机变量的了解,我们能够更好地处理和分析这些实际问题。
6. 个人观点和理解在我看来,二维连续型随机变量的几何意义不仅仅是一个抽象的数学概念,更是一个能够帮助我们理解和处理实际问题的工具。
通过对其特点、分布和应用的深入研究,我们能够更好地把握随机变量的规律,从而在实际问题中做出更为准确的预测和决策。
在本文中,我们对二维连续型随机变量的几何意义进行了深入探讨,并且从实际问题中归纳了其应用。
二维连续型随机变量的几何意义摘要:一、二维连续型随机变量的基本概念二、二维连续型随机变量的几何意义1.联合分布函数2.边缘分布函数3.条件分布函数三、二维连续型随机变量的应用正文:一、二维连续型随机变量的基本概念二维连续型随机变量是指在二维空间中的随机变量,它的取值范围是连续的。
它由两个相互独立的连续型随机变量组成,通常表示为(X,Y)。
在概率论和统计学中,二维连续型随机变量有着广泛的应用。
二、二维连续型随机变量的几何意义1.联合分布函数联合分布函数(Joint Distribution Function)是描述二维连续型随机变量的一种重要方式。
它表示的是两个随机变量同时小于等于某个值的概率。
比如,F(x, y)表示二维连续型随机变量(X,Y)的分布函数,那么F(x,y) =P(X≤x,Y≤y)。
2.边缘分布函数边缘分布函数(Marginal Distribution Function)是指在一个随机变量上进行的累积分布函数。
对于二维连续型随机变量(X,Y),我们可以得到两个边缘分布函数:Fx(x) = P(X≤x) 和Fy(y) = P(Y≤y)。
3.条件分布函数条件分布函数(Conditional Distribution Function)是在已知一个随机变量的取值的情况下,另一个随机变量的分布函数。
对于二维连续型随机变量(X,Y),我们可以得到条件分布函数:FX|Y(x|y) = P(X≤x|Y≤y)。
三、二维连续型随机变量的应用二维连续型随机变量在实际应用中广泛存在,比如在金融领域的风险管理、天气预报、生物医学等领域。
通过研究二维连续型随机变量的分布规律,我们可以更好地理解和预测现实世界中的现象。
总结,二维连续型随机变量是概率论和统计学中的重要概念,它的几何意义有助于我们理解和分析现实世界中的复杂现象。