6 常用统计分布与参数估计
- 格式:ppt
- 大小:1.75 MB
- 文档页数:46

统计学中的参数估计方法统计学中的参数估计方法是研究样本统计量与总体参数之间关系的重要工具。
通过参数估计方法,可以根据样本数据推断总体参数的取值范围,并对统计推断的可靠性进行评估。
本文将介绍几种常用的参数估计方法及其应用。
一、点估计方法点估计方法是指通过样本数据来估计总体参数的具体取值。
最常用的点估计方法是最大似然估计和矩估计。
1. 最大似然估计(Maximum Likelihood Estimation)最大似然估计是指在给定样本的条件下,寻找最大化样本观察值发生的可能性的参数值。
它假设样本是独立同分布的,并假设总体参数的取值满足某种分布。
最大似然估计可以通过求解似然函数的最大值来得到参数的估计值。
2. 矩估计(Method of Moments)矩估计是指利用样本矩与总体矩的对应关系来估计总体参数。
矩估计方法假设总体参数可以通过样本矩的函数来表示,并通过求解总体矩与样本矩的关系式来得到参数的估计值。
二、区间估计方法区间估计是指根据样本数据来估计总体参数的取值范围。
常见的区间估计方法有置信区间估计和预测区间估计。
1. 置信区间估计(Confidence Interval Estimation)置信区间估计是指通过样本数据估计总体参数,并给出一个区间,该区间包含总体参数的真值的概率为预先设定的置信水平。
置信区间估计通常使用标准正态分布、t分布、卡方分布等作为抽样分布进行计算。
2. 预测区间估计(Prediction Interval Estimation)预测区间估计是指根据样本数据估计出的总体参数,并给出一个区间,该区间包含未来单个观测值的概率为预先设定的置信水平。
预测区间估计在预测和判断未来观测值时具有重要的应用价值。
三、贝叶斯估计方法贝叶斯估计方法是一种基于贝叶斯定理的统计推断方法。
贝叶斯估计将先验知识与样本数据相结合,通过计算后验概率分布来估计总体参数的取值。
贝叶斯估计方法的关键是设定先验分布和寻找后验分布。


113第六章 参数估计一、 知识点1. 点估计的基本概念2. 点估计的常用方法(1) 矩估计法① 基本思想:以样本矩作为相应的总体矩的估计,以样本矩的函数作为相应的总体矩的同一函数的估计。
(2) 极大似然估计法设总体X 的分布形式已知,其中),,,(21k θθθθΛ=为未知参数,),,(21n X X X Λ为简单随机样本,相应的),,,(21n x x x Λ为它的一组观测值.极大似然估计法的步骤如下:① 按总体X 的分布律或概率密度写出似然函数∏==ni i n x p x x x L 121);();,,,(θθΛ (离散型)∏==ni i n x f x x x L 121);();,,,(θθΛ (连续型)若有),,,(ˆ21nx x x Λθ使得);,,,(max )ˆ;,,,(2121θθθn n x x x L x x x L ΛΛΘ∈=,则称这个θˆ为参数θ的极大似然估计值。
称统计量),,,(ˆ21nX X X Λθ为参数θ的极大似然估计量。
② 通常似然函数是l θ的可微函数,利用高等数学知识在k θθθ,,,21Λ可能的取值范围内求出参数的极大似然估计k l x x x nl l ,,2,1),,,,(ˆˆ21ΛΛ==θθ 将i x 换成i X 得到相应的极大似然估计量k l X X X nl l ,,2,1),,,,(ˆˆ21ΛΛ==θθ 注:当);,,,(21θn x x x L Λ不可微时,求似然函数的最大值要从定义出发。
3. 估计量的评选标准(1) 无偏性:设),,(ˆˆ21nX X X Λθθ=是参数θ的估计量,如果θθ=)ˆ(E ,则称θˆ为θ的无偏估计量。
(2) 有效性:设1ˆθ,2ˆθ是θ的两个无偏估计,如果)ˆ()ˆ(21θθD D ≤,则称1ˆθ较2ˆθ更有效。
4. 区间估计114 (1) 定义 设总体X 的分布函数族为{}Θ∈θθ),;(x F .对于给定值)10(<<αα,如果有两个统计量),,(ˆˆ111n X X Λθθ=和),,(ˆˆ122n X X Λθθ=,使得{}αθθθ-≥<<1ˆˆ21P 对一切Θ∈θ成立,则称随机区间)ˆ,ˆ(21θθ是θ的双侧α-1置信区间,称α-1为置信度;分别称1ˆθ和2ˆθ为双侧置信下限和双侧置信上限. (2) 单侧置信区间(3) 一个正态总体下未知参数的双侧置信区间(置信度为α-1)二、 习题 1. 选择题(1) 设n X X X ,,,21Λ是来自总体X 的一个样本,则以下统计量①)(211n X X + ②)2(14321n X X X X X n ++++-Λ ③)2332(101121n n X X X X +++-作为总体均值μ的估计量,其中是μ的无偏估计的个数是A.0B.1C.2D.3(2) 设321,,X X X 是来自正态总体)1,(μN 的样本,现有μ的三个无偏估计量321332123211216131ˆ;1254131ˆ;2110351ˆX X X X X X X X X ++=++=++=μμμ其中方差最小的估计量是A.1ˆμB.2ˆμC. 3ˆμD.以上都不是 (3) 设0,1,0,1,1为来自0-1分布总体B(1,p)的样本观察值,则p 的矩估计值为 。

第6章抽样与参数估计第6章抽样与参数估计6.1抽样与抽样分布6.2参数估计的基本方法6.3总体均值的区间估计6.4总体比例的区间估计6.5样本容量的确定学习目标理解抽样方法与抽样分布估计量与估计值的概念点估计与区间估计的区别评价估计量优良性的标准总体均值的区间估计方法总体比例的区间估计方法样本容量的确定方法参数估计在统计方法中的地位统计推断的过程6.1抽样与抽样分布什么是抽样推断概率捕样方法抽样分布抽样方法抽样方法概率抽样(probabilitysampling)也称随机抽样特点按一定的概率以随机原则抽取样本抽取样本时使每个单位都有一定的机会被抽中每个单位被抽中的概率是已知的,或是可以计算出来的当用样本对总体目标量进行估计时,要考虑到每个样本单位被抽中的概率简单随机抽样(simplerandomsampling)从总体N个单位中随机地抽取n个单位作为样本,每个单位入抽样本的概率是相等的最基本的抽样方法,是其它抽样方法的基础特点简单、直观,在抽样框完整时,可直接从中抽取样本用样本统计量对目标量进行估计比较方便局限性当N很大时,不易构造抽样框抽出的单位很分散,给实施调查增加了困难没有利用其它辅助信息以提高估计的效率分层抽样(stratifiedsampling)将抽样单位按某种特征或某种规则划分为不同的层,然后从不同的层中独立、随机地抽取样本优点保证样本的结构与总体的结构比较相近,从而提高估计的精度组织实施调查方便既可以对总体参数进行估计,也可以对各层的目标量进行估计系统抽样(systematicsainplmg)将总体中的所有单位(抽样单位)按一定顺序排列,在规定的范闱内随机地抽取一个单位作为初始单位,然后按爭先规定好的规则确定其它样本单位先从数字1到k之间随机抽取一个数字r作为初始单位,以后依次取r+k,r+2k…等单位优点:操作简便,可提高估计的精度缺点:对估计量方差的估计比较困难整群抽样(clustersampling)将总体中若干个单位合并为组(群),抽样时直接抽取群,然后对中选群中的所有单位全部实施调查特点抽样时只需群的抽样框,可简化工作量调查的地点相对集中,节省调查费用,方便调查的实施缺点是估计的精度较差抽样分布总体中各元素的观察值所形成的分布分布通常是未知的可以假定它服从某种分布总体分布(populationdistribution)一个样本中各观察值的分布也称经验分布当样本容屋n逐渐增大时,样本分布逐渐接近总体的分布样本分布(sampledistribution)抽样分布的概念(samplingdistribution)抽样分布是指样本统计屋的分布,即把某种样本统计量看作一个随机变量,这个随机变屋的全部可能值构成的新的总体所形成的分布即为某种统计量的抽样分布.统计量:样本均值,样本比例,样本方差等样本统计量的概率分布是一种理论概率分布随机变量是样本统计量样本均值,样本比例,样本方差等结果来自容量相同的所有可能样本提供了样本统计量长远稳定的信息,是进行推断的理论基础,也是抽样推断科学性的重要依据对抽样分布的理解抽样分布:即不是总体分布,也不是样本分布,是根据所有可能样本计算的统计量的全部可能取值形成的分布样本均值的抽样分布容量相同的所有町能样本的样本均值的概率分布一种理论概率分布进行推断总体均值的理论基础样本均值的抽样分布样本均值的抽样分布(例题分析)【例】设一个总体,含有4个元素(个体),即总体单位数N=4。

统计分布计算随机变量的统计分布和参数估计统计分布计算是一种重要的数学工具,用于描述和分析随机变量的特征。
通过统计分布的计算,我们可以了解随机变量可能的取值范围、出现的概率以及其他相关特征。
同时,参数估计则是在已知一组观测数据的情况下,根据统计模型的假设来推断未知参数的值。
本文将详细介绍统计分布的计算方法和参数估计的原理与应用。
一、统计分布计算1. 离散型随机变量的统计分布离散型随机变量是在一组有限或可列的值中取值的随机变量。
对于离散型随机变量,我们可以通过概率质量函数(Probability Mass Function, PMF)来描述其取值的概率分布。
概率质量函数通过为每个可能的取值分配一个概率值来表示随机变量的分布情况。
以二项分布为例,二项分布是一种描述相互独立的伯努利试验结果的离散型随机变量,在多次独立重复实验中,成功次数的分布满足二项分布。
二项分布的概率质量函数可以表示为:P(X=k) = C(n, k) * p^k * (1-p)^(n-k)其中,n表示实验的次数,k表示成功的次数,C(n, k)表示组合数。
2. 连续型随机变量的统计分布连续型随机变量是可以取任意实数值的随机变量。
对于连续型随机变量,我们使用概率密度函数(Probability Density Function, PDF)来描述其分布情况。
概率密度函数表示在某个取值范围内的概率密度。
以正态分布为例,正态分布是一种常见的连续型随机变量概率分布,其概率密度函数可以表示为:f(x) = (1/(sqrt(2*pi)*sigma)) * exp(-(x-mu)^2 / (2*sigma^2))其中,mu表示均值,sigma表示标准差。
二、参数估计参数估计是在已知一组观测数据的情况下,通过对统计模型的假设来推断未知参数的值。
参数估计有两种常用的方法:点估计和区间估计。
1. 点估计点估计是通过选择一个合适的统计量来估计未知参数的值。


统计学常用分布一、引言在统计学中,分布是描述数据变化规律和概率的重要工具。
不同的数据类型和问题背景需要采用不同的分布来描述。
本篇文章将介绍统计学中常用的几种分布,包括正态分布、二项分布与泊松分布、指数分布与对数正态分布、卡方分布与t分布等。
二、正态分布正态分布是最常见的连续概率分布之一,它在自然现象、工程技术和社会科学等领域都有广泛的应用。
正态分布的曲线呈钟形,数据值集中在均值附近,随着远离均值,概率逐渐减小。
正态分布在统计学中具有重要地位,许多统计方法和模型都以正态分布为基础。
三、二项分布与泊松分布1.二项分布:二项分布是用来描述伯努利试验中的随机事件的概率分布,其中每次试验只有两种可能的结果,并且每次试验都是独立的。
二项分布适用于计数数据,尤其在生物实验和可靠性工程等领域有广泛应用。
2.泊松分布:泊松分布是二项分布在伯努利试验次数趋于无穷时的极限形式,常用于描述单位时间内随机事件的次数。
泊松分布在概率论和统计学中具有重要地位,广泛应用于保险、通信和生物医学等领域。
四、指数分布与对数正态分布1.指数分布:指数分布描述的是随机事件之间的独立间隔时间或者随机变量的概率分布。
指数分布常用于描述寿命测试和等待时间等问题,例如电话呼叫的间隔时间和电子元件的寿命等。
2.对数正态分布:对数正态分布在统计学中用于描述那些其自然对数呈正态分布的随机变量。
许多生物学、经济学和社会科学中的数据都服从对数正态分布,例如人的身高、体重以及股票价格等。
五、卡方分布与t分布1.卡方分布:卡方分布在统计学中主要用于描述离散型概率分布。
卡方分布是通过对两个独立的随机变量进行平方和运算得到的,常用于拟合检验和置信区间的计算。
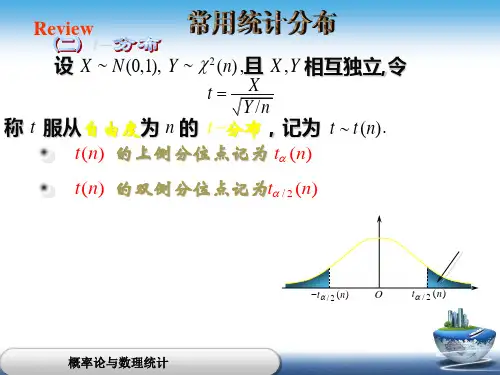
2.t分布:t分布在统计学中广泛应用于样本数据的参数估计和假设检验。
相比于正态分布,t分布在数据量较小或参数偏离正态性时具有更好的稳定性。
t分布在金融、生物医学和可靠性工程等领域有广泛应用。
六、结论在统计学中,不同的数据类型和问题背景需要采用不同的分布来描述。

第六章 参数值的估计 第一节 参数估计的一般问题一、估计量与估计值参数估计就是用样本统计量去估计总体参数,如用X 估计μ,用S2估计2σ,用p 估计π等。
总体参数可以笼统地用一个符号θ表示。
参数估计中,用来估计总体参数的统计量的名称,称为估计量,用θ表示,如样本均值、样本比例等就是估计量。
用来估计总体参数时计算出来的估计量的具体数值,叫做估计值。
二、点估计与区间估计——参数估计的两种方法 1、点估计用样本估计量θ的值直接作为总体参数θ的估计量值。
2、区间估计它是在点估计基础上,给出总体参数估计的一个区间,由此可以衡量点估计值可靠性的度量。
这个区间通常是由样本统计量加减抽样误差而得到。
以样本均值的区间估计来说明区间估计原理:根据样本均值的抽样分布可知,重复抽样或无限总体抽样情况下,样本均值,由此可知,样本均值落在总体均值两侧各为一个标准误差范围内的概率为0.6827,两个标准误差范围0.9545,三个标准误差范围0.9973,并可计算出样本均值落在μ的两侧任何一个标准误差范围内的概率(根据已知的μ,σ计算)。
但实际估计时,μ是未知的,因而不再是估计样本均值落在某一范围内的概率,而只能根据已设定的概率计算这个范围的大小。
例如:约有95%的样本均值会落在距μ的两个标准误差范围内,即约有95%的样本均值所构造的两个标准误差的区间会包括μ。
在区间估计中,由样本统计量所构造的总体参数的估计区间,称为置信区间,区间的最小值为置信下限,最大值为置信上限。
例如,抽取了1000个样本,根据每个样本构造一个置信区间,其中有95%的区间包含了真实的总体参数,而5%的没有包括,则称95%为置信水平/置信系数。
构造置信区间时,可以用所希望的值作为置信水平,常用的置信水平是90%,95%,99%,见下表:α称为显著性水平,表示用置信区间估计的不可靠的概率,1-为置信水平。
如何解释置信区间:如用95%的置信水平得到某班学生考试成绩的置信区间为(60,80),即在多次抽样中有95%的样本得到的区间包含了总体真实平均成绩,(60,80)这个区间有95%的可能性属于这些包括真实平均成绩的区间内的一个。

数理统计6:泊松分布,泊松分布与指数分布的联系,离散分布参数估计前两天对两⼤连续型分布:均匀分布和指数分布的点估计进⾏了讨论,导出了我们以后会⽤到的两⼤分布:β分布和Γ分布。
今天,我们将讨论离散分布中的泊松分布。
其实,最简单的离散分布应该是两点分布,但由于在上⼀篇⽂章的最后,提到了Γ分布和泊松分布的联系,因此本⽂从泊松分布出发。
由于本系列为我独⾃完成的,缺少审阅,如果有任何错误,欢迎在评论区中指出,谢谢!⽬录Part 1:泊松分布简介泊松分布是⼀种离散分布,先给出其概率分布列。
若X∼P(λ),则P(X=k)=λkk!e−λ,k=0,1,⋯它的取值是⽆限可列的。
为什么泊松分布会与指数分布、Γ分布有联系呢?这是因为,它们三个都是随机事件发⽣的⼀种描述。
实际上,指数分布的参数λ是⼀种速率的体现,它刻画了随机事件发⽣的速率。
⽽指数分布随机变量的取值,就代表某⼀事件在⼀定的速率下发⽣的时刻距离计时原点的长度。
Y∼E(λ),就代表Y对应的事件事件的发⽣速率是λ,所以平均发⽣时间就在在1/λ处。
这也可以作为E(Y)=1/λ的⼀种解释。
指数分布具有⽆记忆性,这与随机事件的发⽣相似,即已经发⽣历史事件对未来不产⽣影响,⽤数学语⾔说就是P(Y>s+t|Y>s)=P(Y>t)。
这指的是,如果⼀个事件平均会在s时间后发⽣,但是⽬前经过了t时间还没有发⽣,则事件的平均发⽣时间就移动到t+s时间后。
它不会因为你已经等了t时间,就会更快地发⽣。
⽽如果把n个独⽴同分布于E(λ)指数分布随机变量相加,得到的⾃然就是恰好发⽣k个事件的平均时间,这个时间Z∼Γ(n,λ),本质还是⼀种时间的度量。
但Z就不具有⽆记忆性了,这是因为,经过t时间后可能已经发⽣了n−1个事件就差最后⼀个没有发⽣,也可能⼀个事件都没发⽣还需要n个才能凑齐。
泊松分布则刚好相反,指数分布和Γ分布都是限定了发⽣次数,对发⽣时间作度量;泊松分布则是限定了时间1,求随机事件在这⼀段时间内发⽣的次数服从的概率分布。