基因组和转录组高通量测序数据分析流程和分析平台
- 格式:pdf
- 大小:5.93 MB
- 文档页数:21

RNA-seq(转录组学)的分析流程和原理在开始详细讲解RNA测序之前,我们先来了解一下它的基本步骤:1.建库:提取RNA,富集mRNA或消除rRNA,合成cDNA和构建测序文库。
2.测序:然后在高通量平台(通常是Illumina)上进行测序(每个样本测序reads在DNA测序中,读数是对应于单个DNA片段的全部或部分的碱基对(或碱基对概率)的推断序列。
深度为10-30 Million reads。
)3.分析:先比对/拼装测序片段到转录本,通过计数、定量,样本间过滤和标准化,以进行样本组间基因/转录本统计差异分析。
大致了解这个过程之后,我们就先从建库开始了解建库的难点在于提纯出mRNA, 一般在我们抽离出的RNA中rRNA占比很大,其他还会有tRNA、microRNA等。
我们需要从抽离出的RNA中提取出mRNA,并建立cDNA文库。
这里以应用最广泛的Illumina公司的Truseq RNA的建库方法为例来进行介绍。
首先,利用高等生物的mRNA通常有poly(A)尾的(使mRNA更稳定,翻译不容易出错)特点,用带有poly(T)探针的磁珠与总RNA进行杂交,这样磁珠就和带poly(A)尾巴的mRNA结合在一起了。
接下来,就回收磁珠,把这些带poly(A)的mRNA从磁珠上洗脱下来。
再用镁离子溶液(或者超声波)进行处理,把mRNA打成小段。
然后,利用这些被打断的mRNA片段,以随机引物进行逆转录,得到第一链cDNA。
再根据第一链cDNA合成出ds-cDNA。
对cDNA在平末端进行3’端加A碱基(腺苷酸)(adapter接头上带了T碱基头,为了和adapter配对)在双链cDNA的两端加分别上Y型接头再经PCR扩增经筛选的目的基因,就得到可以上机的测序文库了。
这个建库方法对RNA的完整度有较高的要求。
也就是说,只有在mRNA大部分是完整的状态下,才能得到比较好的效果。
因为带Poly(T)的磁珠,它所吸附的是带有Poly(A)的那些序列。

生物信息学中的转录组测序数据分析流程解析转录组测序是一种基于高通量测序技术的生物学研究方法,用于研究特定物种在特定生理或环境条件下所产生的所有转录本(mRNA)。
转录组测序数据分析是将原始的测序数据转化为有意义的生物学信息的过程。
本文将解析转录组测序数据分析的基本流程。
1. 数据质量控制(Quality Control,QC)数据质量控制是在转录组测序数据分析中非常重要的一步,它能够及早发现并剔除测序过程中产生的低质量测序数据,保证后续分析的准确性。
常用的QC工具包括FastQC和Trimmomatic。
FastQC用于检查测序数据的质量分布情况,发现可能存在的测序错误和污染问题。
Trimmomatic则用于去除低质量的测序片段和接头,提高数据的质量。
2. 数据比对数据比对是将测序数据与参考基因组进行比对的过程。
比对的目的是将测序片段精确地定位到基因组上,并获得每个基因组区域的覆盖度和深度等信息。
常用的比对工具包括Bowtie2和TopHat。
Bowtie2是一种基于Burrows-Wheeler Transform的短序列比对工具,适用于低错配率的比对。
TopHat则是一种用于对转录组数据进行比对和注释的工具,可以检测新基因和外显子剪接事件。
3. 定量分析定量分析是研究不同转录本在不同条件下的表达水平差异的过程。
常用的定量工具包括Cufflinks和HTSeq。
Cufflinks是一种用于估计转录本表达水平和发现新的转录本的工具。
它可以根据RNA-Seq数据拼接转录本,并计算不同基因或转录本的表达水平。
HTSeq则是一种用于计算不同基因的读数的工具,读数可以用来估计基因的表达水平。
4. 差异分析差异分析是研究在不同处理条件下,基因或转录本的表达水平是否存在显著差异的过程。
常用的差异分析工具包括DESeq2和edgeR。
DESeq2是一种基于负二项分布模型的差异表达分析工具,它可以对转录本进行差异分析,并计算基因的表达水平在不同条件下的折叠变化。

基因组和转录组高通量测序数据分析流程和分析平台基因组和转录组高通量测序数据分析是生物信息学领域中的一个重要研究方向。
随着高通量测序技术的发展,获取大规模基因组和转录组数据已经成为可能。
通过对这些数据的分析,可以深入了解生物体内基因的表达和功能等相关信息。
本文将介绍基因组和转录组高通量测序数据分析的基本流程和常用的分析平台。
数据预处理是分析流程的第一步,主要包括测序数据的质控和去除低质量序列。
常用的质控工具包括FastQC和Trim Galore等,它们可以评估测序数据的质量和检测可能的污染。
在质控的基础上,可以使用Trimmomatic等工具去除低质量序列和适配体序列,保证后续分析的准确性和可靠性。
基因定量是分析流程的第二步,用于评估基因的表达水平。
常用的基因定量工具包括kallisto、Salmon和STAR等。
这些工具可以根据测序数据和已知的转录组序列,计算基因的表达水平。
基因定量的结果一般以表达矩阵的形式输出,该矩阵包含了每个样本中每个基因的表达值。
差异表达基因分析是分析流程的第三步,用于寻找基因表达水平在不同样本中存在显著差异的基因。
常用的差异表达基因分析工具包括DESeq2、edgeR和limma等。
这些工具可以对表达矩阵进行统计学分析,找出在不同样本之间具有显著差异的基因。
差异表达基因分析的结果一般以差异表达基因列表的形式输出。
富集分析是分析流程的第四步,用于寻找差异表达基因中富集的生物学功能或通路。
常用的富集分析工具包括GOseq、KEGG和enrichR等。
这些工具可以根据差异表达基因列表,基于GO注释和KEGG通路等数据库,计算差异表达基因在特定功能或通路上的富集度。
生物学注释是分析流程的最后一步,用于解释基因的功能和相关信息。
常用的生物学注释工具包括DAVID、GSEA和STRING等。
这些工具可以根据差异表达基因列表,提供关于基因功能、互作关系和代谢通路等信息。
除了上述基本流程外,还有一些附加的分析步骤,如差异剪接分析、外显子计数等。

生物信息学分析工具的使用教程导言:在生物学领域中,随着高通量测序技术的快速发展,生物信息学分析工具的应用变得越来越重要。
这些工具能够帮助研究人员进行基因组、转录组、蛋白质组等大规模数据的分析和解释。
本文将为您介绍几种常用的生物信息学工具,并提供详细的使用指南。
一、BLAST(基因序列比对工具)BLAST(Basic Local Alignment Search Tool)是最常用的生物信息学工具之一,用于比对基因或蛋白质序列中的相似性。
以下是使用BLAST的步骤:1. 打开NCBI网站的BLAST页面,并选择适当的BLAST程序(如BLASTn、BLASTp等)。
2. 将查询序列粘贴到"Enter Query Sequence"框中,或者上传一个FASTA格式的文件。
3. 选择适当的数据库,如"nr"(非冗余序列数据库)或"refseq_rna"(已注释的RNA序列数据库)。
4. 设置相似性阈值、期望值和其他参数。
5. 点击"BLAST"按钮开始比对。
6. 结果页面会显示比对结果的列表和详细信息,包括匹配上的序列、相似性得分等。
二、DESeq2(差异表达基因分析工具)DESeq2是一种用于差异表达基因分析的R包。
以下是使用DESeq2的步骤:1. 安装R语言和DESeq2包。
2. 将基因表达矩阵导入R环境中,并进行预处理(如去除低表达基因)。
3. 根据实验设计设置条件和组别。
4. 进行差异分析,计算基因的表达差异和显著性。
5. 可视化差异表达基因的结果,如绘制散点图、MA图、热图等。
三、GSEA(基因集富集分析工具)GSEA(Gene Set Enrichment Analysis)是一种基于基因集的富集分析方法,用于识别与特定性状或实验条件相关的生物学功能。
以下是使用GSEA的步骤:1. 准备基因表达矩阵和相关的分组信息。

转录组学分析流程及常用软件介绍转录组学是研究在特定条件下生物体内转录的所有RNA分子的总体,包括信使RNA(mRNA)、转运RNA(tRNA)、核糖体RNA(rRNA)和小核RNA(snRNA)等。
转录组学研究可以通过分析转录组中的基因表达水平和调控机制,揭示基因功能和调控网络,从而深入了解生物体的生命活动和适应能力。
转录组学分析流程包括实验设计、RNA提取、RNA测序、数据分析和结果解释等环节,并依赖于一系列的软件工具来完成。
下面将介绍转录组学分析的流程以及常用的软件。
1.实验设计:确定研究目的和假设,设计实验方案,包括样本的选择和处理方式等。
2.RNA提取:从样本中提取总RNA,并进行纯化和富集,去除DNA和其他杂质。
3. RNA测序:将提取得到的RNA反转录成cDNA,然后通过高通量测序技术进行测序。
常用的测序技术包括Illumina HiSeq、Ion Torrent Proton等。
4.数据分析:对测序得到的数据进行质控、比对和定量等处理。
这一步通常需要使用一系列的转录组学分析软件。
5.结果解释:根据数据分析的结果,进行差异表达基因的筛选、基因富集分析和信号通路分析,以探索转录组的生物学意义。
常用的转录组学分析软件包括:1. 基因表达微阵列分析:在早期的转录组学研究中,基因表达微阵列是常用的分析方法。
常用的分析软件有Affymetrix Expression Console、Partek Genomics Suite等。
2. RNA测序数据分析:随着高通量测序技术的发展,RNA测序已成为转录组学研究的主要方法。
RNA测序数据的分析可以分为质控、比对和定量等环节。
常用的软件工具有Trimmomatic、FastQC、STAR、HISAT等。
3. 差异表达基因分析:差异表达基因是通过比较不同样本之间的基因表达水平而筛选出来的。
常用的软件包括DESeq2、edgeR、limma等。
4. 基因富集分析:基因富集分析可以帮助我们了解不同基因集之间的功能和通路差异,从而揭示转录组的生物学意义。

转录组测序数据分析流程1.样品准备:根据研究需求,选择适当的样品,如病人和对照组组织、不同发育阶段的样品等。
提取总RNA,并通过凝胶电泳、紫外线分析、比色法等方法鉴定RNA的完整性和浓度。
2. 测序:使用高通量测序技术,如Illumina HiSeq、Ion Torrent等对RNA样品进行测序。
根据实验的需要,可以采用不同的测序策略,如单端测序或双端测序,以及测序长度的选择。
3. 质控:对测序数据进行质量控制,包括去除低质量Reads、修剪接头序列、去除低复杂度序列、过滤低质量的碱基等,以确保后续分析的准确性和可靠性。
4. 数据预处理:根据测序平台的要求,对测序数据进行数据切分、过滤低质量read、去除低质量碱基等。
同时,进行去除rRNA、tRNA等非编码RNA的对应序列,以提高分析效果。
5. 比对:将得到的测序reads与参考基因组进行比对。
常用的比对工具有Bowtie、Tophat、STAR等,通过比对可以找到reads在参考基因组中的位置,为后续的表达量计算提供支持。
6. 表达量计算:根据比对结果,统计每个基因的reads数或覆盖度来计算其表达量。
可以使用RSEM、HTSeq、Cufflinks等工具进行表达量的计算,得到基因表达量矩阵。
7. 差异表达基因分析:根据不同条件下的样品表达量矩阵,使用统计学方法分析基因的差异表达情况。
常用的差异分析工具有DESeq2、edgeR、Limma等,通过计算差异表达基因的显著性水平,筛选出差异表达的基因。
8. 功能注释:对差异表达基因进行生物学功能注释,包括基因本体论(Gene Ontology, GO)、KEGG通路分析等。
可以通过数据库如DAVID、GSEA、KEGG等进行功能注释,以进一步了解差异表达基因在生物学过程中的功能。
9. 富集分析:对差异表达基因进行富集分析,即确定差异表达基因是否富集在特定的功能类别中。
可以使用Fisher精确检验、超几何检验等方法,从而发现与特定疾病或生物过程相关的富集基因集。

高通量测序技术的数据分析方法教程随着生物技术的发展,高通量测序技术(high-throughput sequencing technology)已成为生物学、医学和生物信息学研究中的重要工具。
高通量测序技术可以快速而准确地测定DNA或RNA序列,透过大量的数据来揭示生物体的基因组、转录组以及其他生物学过程中的变化。
然而,正确且高效地分析测序数据是高通量测序技术应用的关键一步。
本文将介绍高通量测序技术的数据分析方法教程。
首先,分析高通量测序数据前,我们需要了解常见的测序平台和数据格式。
当前常用的高通量测序平台包括Illumina、ABI SOLiD、Ion Torrent等,而测序数据通常以FASTQ、SAM/BAM和VCF等格式存储。
FASTQ格式用于存储原始测序数据,其中包含了每个测序读段的序列信息及其对应的质量分数。
而SAM/BAM格式则是将测序读段比对到参考基因组之后的结果,其中SAM是比对结果的文本格式,而BAM则是对应的二进制格式。
VCF(Variant Call Format)格式则用于存储基因型变异信息。
接下来,我们将介绍高通量测序数据的基本分析流程。
通常,测序数据分析可以分为质控、比对、变异检测和功能注释几个主要步骤。
在质控步骤中,我们需要对测序数据进行质量评估和过滤。
质量评估可以通过查看测序数据的质量分数、GC含量、碱基分布和测序错误率等指标来判断测序数据的质量。
使用质量评估工具如FastQC和NGS QC Toolkit可以帮助我们快速准确地评估测序数据的质量,并进行相应的过滤工作,去除低质量的测序读段。
接下来,我们需要将测序读段比对到参考基因组上。
比对工作可以通过软件如Bowtie、BWA和HISAT等进行。
比对结果通常以SAM格式存储,然后可以进行排序、去重和索引等处理,生成最终的BAM格式文件。
在变异检测步骤中,我们需要从比对后的BAM文件中检测样本中存在的变异信息。
变异检测可以通过多种工具来实现,如GATK、Samtools和VarScan等。
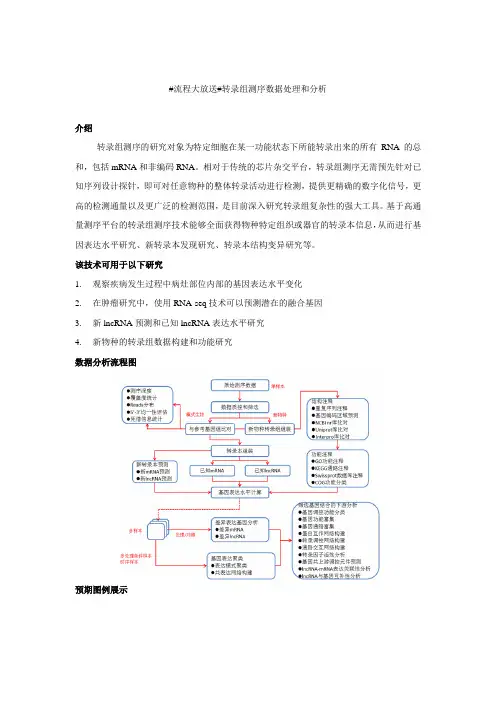
#流程大放送#转录组测序数据处理和分析
介绍
转录组测序的研究对象为特定细胞在某一功能状态下所能转录出来的所有RNA的总和,包括mRNA和非编码RNA。
相对于传统的芯片杂交平台,转录组测序无需预先针对已知序列设计探针,即可对任意物种的整体转录活动进行检测,提供更精确的数字化信号,更高的检测通量以及更广泛的检测范围,是目前深入研究转录组复杂性的强大工具。
基于高通量测序平台的转录组测序技术能够全面获得物种特定组织或器官的转录本信息,从而进行基因表达水平研究、新转录本发现研究、转录本结构变异研究等。
该技术可用于以下研究
1.观察疾病发生过程中病灶部位内部的基因表达水平变化
2.在肿瘤研究中,使用RNA-seq技术可以预测潜在的融合基因
3.新lncRNA预测和已知lncRNA表达水平研究
4.新物种的转录组数据构建和功能研究
数据分析流程图
预期图例展示
示例图1 差异表达基因筛选示例2 基因聚类分析heatmap图
示例3 差异基因互作网络图示例4 lncRNA、基因与上游共有miRNA网络图。

基因测序数据处理与分析方法分析基因测序是指以高通量测序技术为基础,对DNA序列进行大规模分析的过程,用于对基因组、转录组或单个基因进行研究。
基因测序数据的处理和分析是基因测序研究的重要一环。
本文将介绍一些常见的基因测序数据处理和分析方法。
一、原始数据处理基因测序技术产生的原始测序数据包括FASTQ格式的序列文件,需要进行以下处理:1. 质量控制测序数据中包含了由于测序误差产生的错误碱基,这些错误碱基会对后续的分析产生影响。
因此,需要对测序数据进行质量控制。
通常采用的方法是使用软件工具进行去除低质量序列(如Trimmomatic)。
2. 序列比对将原始测序数据比对到一个基因组参考序列上,以确定每个序列片段来源于不同的基因或区域。
常用的软件包括Bowtie2和BWA。
二、基因组重测序与比较基因组学基因组重测序是指对已有的基因组进行测序并进行序列比对,以确定基因组的完整性和准确性。
比较基因组学是指通过对多个物种的基因组进行比较,来研究它们的演化关系。
这些研究都需要对基因组序列进行以下处理和分析:1. 基因组装连续的序列数据中包含了来自同一个基因的多个片段,需要将这些片段进行拼接以形成完整的基因。
常用的软件包括SPAdes和SOAPdenovo。
2. 基因注释基因注释是指对基因组序列进行功能注释,以确定基因的具体功能。
注释方法包括比对到已知基因库、预测开放阅读框、功能域预测等。
3. 基因演化分析基因演化分析是指通过对不同基因、物种的基因组序列进行比较,研究它们的演化关系。
常用的软件包括PhyML和MrBayes。
三、转录组测序与差异表达分析转录组测序是指对细胞中所有mRNA的测序,以研究某些生物过程中变化的基因表达。
差异表达分析是指比较不同条件下的基因表达量,从而确定哪些基因在这些条件下发生了显著的变化。
处理和分析转录组测序数据包括以下步骤:1. 转录组装与基因组装类似,需要对连续的序列数据进行拼接以形成完整的转录本。

rnaseq数据分析流程RNA-seq数据分析流程。
RNA测序(RNA-seq)是一种用于研究转录组的高通量测序技术,它可以帮助科研人员了解基因表达和转录本结构。
在本文中,我们将介绍RNA-seq数据分析的一般流程,包括数据预处理、基因表达分析和功能注释等步骤。
1. 数据预处理。
首先,我们需要对原始的RNA-seq数据进行质量控制(QC)。
这包括使用软件如FastQC来评估测序数据的质量,检测是否存在低质量的碱基或测序错误。
接下来,我们需要对数据进行去除接头(adapter trimming)和过滤低质量读(quality filtering)。
这些步骤可以使用工具如Trimmomatic或Cutadapt来完成。
最后,我们需要对清洗后的数据进行比对到参考基因组(alignment),这可以使用软件如HISAT2或STAR来完成。
2. 基因表达分析。
一旦我们获得了比对到参考基因组的数据,我们就可以开始进行基因表达分析。
首先,我们需要对比对结果进行计数,这可以使用软件如featureCounts或HTSeq来完成。
然后,我们需要对表达数据进行标准化,例如使用DESeq2或edgeR来进行基因表达的差异分析。
最后,我们可以使用一些可视化工具如ggplot2或heatmap 来展示基因表达的模式和差异。
3. 功能注释。
最后,我们可以对不同表达的基因进行功能注释。
这包括对差异表达基因进行富集分析(enrichment analysis),例如富集在特定的通路(pathway)或生物学过程(biological process)中。
这可以使用工具如DAVID或Enrichr来完成。
此外,我们还可以对差异表达基因进行蛋白质-蛋白质相互作用分析(protein-protein interaction analysis),例如使用STRING数据库来预测蛋白质之间的相互作用网络。
总结。
综上所述,RNA-seq数据分析是一个复杂的过程,涉及到数据预处理、基因表达分析和功能注释等多个步骤。

高通量测序技术及实用数据分析高通量测序技术(HTS)是一种高度并行的DNA或RNA测序技术,通过同一时间对成千上万个DNA或RNA分子进行测序,可以快速、准确地获取大规模基因组数据。
HTS技术的发展革命性地改变了生物学研究和医学诊断的方式,广泛应用于基因组测序、转录组分析、表观遗传学研究等领域。
HTS的工作流程包括样品准备、测序和数据分析三个主要步骤。
样品准备阶段需要对DNA或RNA进行提取、文库构建和PCR扩增等处理。
测序阶段采用不同的测序平台,如Illumina、Ion Torrent、PacBio等,根据不同平台的不同工作原理,将DNA或RNA片段测序为原始测序数据。
数据分析阶段则涉及序列比对、变异分析、基因表达定量等多个步骤。
数据分析是HTS技术的关键环节,也是利用测序数据进行生物学研究的重要步骤。
首先,序列比对将原始测序数据与参考基因组或转录组序列进行比对,确定每条测序读段的起始位置和匹配度。
对于基因组数据,需要考虑基因组的序列重复性,处理多种多样的变异类型。
接下来,变异分析可以检测样品中存在的单核苷酸多态性(SNP)、插入、缺失等变异信息,并将其与已知数据库进行比对,鉴定可能的功能影响。
对于转录组数据,数据分析过程中常使用的方法包括差异表达分析、富集分析和功能注释等,可以发现不同条件下基因的表达差异及其可能的生物学功能。
实际的HTS数据分析过程还可能涉及到质量控制、数据预处理、归一化、去除批次效应等步骤。
质量控制主要通过分析测序数据中的碱基质量值、GC含量、测序错误率等,确保数据质量达到要求。
数据预处理则包括去除低质量的碱基、接头序列、PCR复制以及低频度的SNP等,以减少潜在的假阳性结果。
数据归一化可以解决不同样品之间的技术差异,确保可靠的差异分析结果。
批次效应的去除是在多批次测序实验中常遇到的问题,可以使用统计学方法对批次效应进行校正,从而减少其对差异分析结果的影响。
随着HTS技术的不断发展,数据分析方法也在不断创新。
高通量测序数据分析的基本流程与软件介绍高通量测序技术的广泛应用已经在基因组学、转录组学、表观基因组学等领域产生了巨大的影响。
高通量测序数据分析是将测序仪输出的原始数据转化为有意义的生物学信息的过程。
本文将介绍高通量测序数据分析的基本流程以及一些常用的软件工具。
1. 数据质控与预处理高通量测序数据的质量对后续分析结果至关重要。
首先,需要对测序数据进行质量控制,检查测序质量值、测序错误率、测序深度等指标,以评估数据的可靠性。
常用的质控软件包括FastQC和NGS QC Toolkit。
在质控后,还需要对原始测序数据进行预处理,包括去除接头序列、过滤低质量序列、去除PCR扩增引物等。
这些步骤可以使用Trimmomatic、Cutadapt等软件来完成。
2. 序列比对与变异检测在得到高质量的测序数据后,下一步是将测序reads比对到参考基因组或转录组上。
常用的比对软件有Bowtie、BWA、STAR等。
比对结果可以用于检测基因组上的变异,如单核苷酸多态性(SNP)、插入缺失(Indel)等。
变异检测软件包括GATK、SAMtools等。
3. 基因表达分析基因表达分析是高通量测序数据分析中的一个重要方面。
它可以帮助我们了解哪些基因在不同条件下的表达水平发生了变化。
常用的基因表达分析流程包括表达定量、差异表达分析和功能富集分析。
表达定量是将测序reads映射到基因组或转录组上,并计算每个基因的表达水平。
常用的表达定量软件有HTSeq、featureCounts等。
差异表达分析可以帮助我们找到在不同条件下表达水平有显著变化的基因。
常用的差异表达分析软件有DESeq2、edgeR等。
功能富集分析可以帮助我们了解差异表达基因的功能特征,如富集通路、功能分类等。
常用的功能富集分析工具有DAVID、GSEA等。
4. 转录因子结合位点分析转录因子结合位点是转录因子与DNA结合的特定区域,对基因的调控起重要作用。
高通量测序数据可以用于预测转录因子结合位点。
转录组测序具体详细流程转录组测序是一种高通量测序技术,用于研究特定生物体内的所有转录本。
这种技术可以帮助我们了解基因表达的调控机制,以及在不同生理和病理状态下基因表达的变化。
下面将详细介绍转录组测序的具体流程。
1. RNA提取需要从样本中提取RNA。
这可以通过使用商业化RNA提取试剂盒或自制试剂盒来完成。
提取的RNA应该是高质量的,没有降解或污染。
2. RNA质量评估为了确保RNA的质量,需要对提取的RNA进行质量评估。
这可以通过使用生物分析仪或琼脂糖凝胶电泳来完成。
RNA的完整性和纯度是评估RNA质量的两个重要指标。
3. RNA文库制备RNA文库制备是转录组测序的关键步骤。
在这个步骤中,需要将RNA转录成cDNA,并将其连接到测序适配器上。
这可以通过使用商业化RNA文库制备试剂盒或自制试剂盒来完成。
4. 文库质量评估为了确保文库的质量,需要对文库进行质量评估。
这可以通过使用生物分析仪或PCR扩增来完成。
文库的大小和纯度是评估文库质量的两个重要指标。
5. 测序文库制备完成后,需要进行测序。
转录组测序可以使用Illumina HiSeq、NovaSeq或PacBio等高通量测序平台来完成。
在测序过程中,需要对测序数据进行质量控制和过滤,以确保测序数据的质量。
6. 数据分析需要对测序数据进行数据分析。
这可以通过使用不同的生物信息学工具和软件来完成。
数据分析的目的是识别差异表达基因、功能注释和通路分析等。
转录组测序是一种强大的技术,可以帮助我们了解基因表达的调控机制和在不同生理和病理状态下基因表达的变化。
通过上述步骤的详细介绍,我们可以更好地理解转录组测序的具体流程。
二代基因测序流程和试剂二代基因测序是指采用高通量测序技术进行基因组或转录组的测序,主要包括Illumina的测序平台(如HiSeq和MiSeq)、Ion Torrent的测序平台(如Ion Proton和Ion S5)以及PacBio的测序平台(如Sequel)等。
下面将详细介绍二代基因测序的流程和相关试剂。
首先,对DNA样品进行制备。
这一步骤主要包括DNA提取和纯化,可以使用各种商业化的DNA提取试剂盒,如Qiagen的QIAamp DNA MiniKit。
DNA提取的目的是从样品中提取出纯净的DNA,以便后续的测序。
接下来是文库构建。
文库是指将DNA样品转化为适合测序的文库,其中包含了需要测序的DNA片段。
文库构建的方法有多种,包括PCR扩增法、限制性酶切法、超声波剪切法等。
不同的文库构建方法需要使用不同的试剂,如PCR试剂盒、酶切试剂、DNA修复试剂等。
然后是DNA片段扩增。
在文库构建后,需要对文库中的DNA片段进行扩增,以得到足够数量的DNA模板进行测序。
扩增的方法主要有PCR扩增和桥式PCR扩增。
PCR扩增一般使用PCR试剂盒,如Taq DNA Polymerase、dNTPs、引物等。
桥式PCR扩增则需要使用桥式PCR试剂盒。
测序是整个基因测序流程的核心环节。
常用的测序平台有Illumina的HiSeq和MiSeq、Ion Torrent的Ion Proton和Ion S5以及PacBio的Sequel等。
这些平台都需要使用相应的试剂盒进行测序。
以Illumina为例,测序试剂盒包括引物、测序芯片、碱基、酶等。
具体测序的原理和步骤不同平台略有差异,但都是通过不断添加碱基和检测生成的信号来确定DNA序列。
最后是数据分析。
数据分析是基因测序的最后一步,主要包括序列质量控制、序列比对和变异检测等。
数据分析通常需要使用专门的生物信息学软件或者在线平台,如Bowtie、BWA、GATK等。
这些软件和平台可以根据测序数据进行序列比对、SNP/Indel检测、RNA表达分析等。
高通量测序数据分析总结引言高通量测序(high-throughput sequencing)是一种快速和高效地获取大量DNA或RNA序列信息的技术,被广泛应用于基因组学、转录组学和表观基因组学等领域。
随着高通量测序技术的发展,分析测序数据的能力也变得越来越重要。
本文将总结高通量测序数据分析的主要步骤和常用工具。
数据预处理在进行高通量测序数据分析之前,首先需要对原始测序数据进行预处理。
数据预处理的主要步骤包括:1.质量控制:使用质量控制工具(如FastQC)检查测序数据的质量,并去除低质量的读取。
2.去除接头序列:高通量测序数据通常会包含测序接头序列,需要使用工具(如Trimmomatic)去除这些序列。
3.低复杂度序列过滤:根据实验需求,可以使用工具(如Prinseq)过滤掉低复杂度的序列,以减少数据分析的噪音。
4.对reads进行比对:使用工具(如Bowtie、BWA)将reads与参考基因组或转录组进行比对,以获取比对到基因组或转录组的reads。
数据分析完成了数据预处理后,可以进行高通量测序数据的分析。
常见的数据分析任务包括:1.变异分析:通过比对到基因组的reads进行变异分析,识别单核苷酸变异(SNV)和小片段插入/删除(Indel)。
常用的工具有GATK、SAMtools 等。
2.转录本定量:利用比对到转录组的reads进行转录本定量分析,计算基因的表达水平。
常用的工具有Cufflinks、Salmon等。
3.差异表达分析:通过对比不同条件下的转录本表达水平,识别差异表达基因。
常用的工具有DESeq2、edgeR等。
4.GO/KEGG富集分析:通过对差异表达基因进行功能富集分析,探索这些基因的生物学功能和通路调控。
常用的工具有DAVID、Enrichr等。
5.其他分析:高通量测序数据还可以进行基因组装、转录因子结合位点分析、表观基因组学分析等。
结果展示高通量测序数据分析的结果可以通过各种方式展示,常用的包括绘制柱状图、散点图、热图、曲线图等。
高通量基因测序技术的数据分析与解读高通量基因测序技术(High-throughput sequencing,HTS)是一种高效快速的基因测序方法。
它可以同时测序数百万个DNA片段,从而在短时间内获得海量遗传信息。
随着HTS技术的逐步成熟和应用进展,其数据量也愈发庞大,观察到的基因序列变异也更加详细。
因此,对于HTS数据的准确分析与解读,对基因研究、临床诊断和个性化治疗等方面都有重要意义。
本文将从HTS技术的分析流程、数据处理方法及解读实例等方面介绍HTS数据的分析和解读方法。
一、HTS技术的分析流程HTS技术的分析流程主要包括以下几个环节:文库构建、DNA测序、数据处理、变异检测及功能注释等环节。
具体流程如下:1. 文库构建HTS技术采用的是文库测序,首先要进行文库构建。
文库构建可分为以下几个步骤:DNA片段剪辑、适配体链接、PCR扩增、文库纯化、检测文库质量等。
文库构建的质量和纯度会直接影响到后面测序结果的准确性和可靠性。
2. DNA测序HTS技术的核心是高通量的DNA测序。
当样品DNA在仪器上进行PCR扩增后,得到簇生长的序列簇。
这些簇通过荧光信号或其他方法进行读取,利用计算机的处理能力,将这些信号转换为成千上万条DNA片段序列。
测序过程分为两种方法:单端序列和双端序列,前者是只测序一个端点,而后者是同时测序两个端点,更有利于确定序列。
3. 数据处理为了从测序机器得到的原始序列数据中提取有用的信息,离线数据处理必不可少,这一过程一般包括以下几个步骤:(1) 质量控制测序质量控制是数据分析的第一道工序,它可确保数据质量和可靠性,排除无效数据的干扰。
质量控制一般采用FastQC、Trimmomatic等软件进行,通过检查测序质量和分析碱基组成等指标,去除低质量序列、污染序列等。
(2) 序列比对HTS技术所产生的海量序列数据必须与参考基因组进行比对以识别基因组中的变异及其位置。
比对软件一般有BWA、Bowtie2、SAMtools、GATK等。