数据库操作语法
- 格式:docx
- 大小:17.83 KB
- 文档页数:8

数据库简单的增删改查语法总结数据库是指在计算机系统中长期储存的、有组织的、可共享的大量数据的集合。
在数据库中,常用的操作有增加、删除、修改和查询等。
以下是数据库简单的增删改查语法总结:一、增加数据在数据库中,增加数据的操作可以使用INSERT语句。
INSERT语句的基本格式如下:INSERTINTO表名(字段1,字段2,...)VALUES(值1,值2,...);例如,向一个学生表student中增加一条记录,可以使用以下语句:INSERT INTO student (id, name, age)VALUES('1','张三','20');这条语句将向student表中插入一条id为1,name为"张三",age为20的记录。
二、删除数据在数据库中,删除数据的操作可以使用DELETE语句。
DELETE语句的基本格式如下:DELETEFROM表名WHERE条件;例如,从学生表student中删除id为1的记录,可以使用以下语句:DELETE FROM student WHERE id = '1';这条语句将从student表中删除id为1的记录。
三、修改数据在数据库中,修改数据的操作可以使用UPDATE语句。
UPDATE语句的基本格式如下:UPDATE表名SET字段1=新值1,字段2=新值2,...WHERE条件;例如,将学生表student中id为1的记录的name字段修改为"李四",可以使用以下语句:UPDATE student SET name = '李四' WHERE id = '1';这条语句将修改student表中id为1的记录的name字段为"李四"。
四、查询数据在数据库中,查询数据的操作可以使用SELECT语句。
SELECT语句的基本格式如下:SELECT字段1,字段2,...FROM表名WHERE条件;例如,查询学生表student中所有记录的id和name字段,可以使用以下语句:SELECT id, name FROM student;这条语句将查询student表中所有记录的id和name字段。

sqlite数据库的语法SQLite 是一个轻量级的数据库系统,它的语法相对简单。
以下是 SQLite 的一些基本语法:1. 创建数据库和表```sql-- 创建一个名为 '' 的数据库CREATE DATABASE ;-- 使用已存在的数据库ATTACH DATABASE ;-- 创建一个名为 'mytable' 的表CREATE TABLE mytable (id INTEGER PRIMARY KEY,name TEXT,age INTEGER);```2. 插入数据```sqlINSERT INTO mytable (name, age) VALUES ('Alice', 25); INSERT INTO mytable (name, age) VALUES ('Bob', 30); ```3. 查询数据```sql-- 查询所有数据SELECT FROM mytable;-- 查询 age 大于 25 的数据SELECT FROM mytable WHERE age > 25;```4. 更新数据```sqlUPDATE mytable SET age = 31 WHERE name = 'Alice';```5. 删除数据```sqlDELETE FROM mytable WHERE name = 'Bob';```6. 创建索引 (提高查询效率)```sqlCREATE INDEX idx_name ON mytable (name);```7. 创建视图 (基于一个或多个表的虚拟表)```sqlCREATE VIEW myview AS SELECT FROM mytable WHERE age > 25; ```8. 创建触发器 (响应 INSERT、UPDATE 或 DELETE 操作时自动执行的代码)由于篇幅有限,这里只列举了一些基本的 SQLite 语法。

mysql和sqlite语法MySQL和SQLite是两种常见的关系型数据库管理系统(RDBMS),它们都具有自己的语法和特点。
本文将详细介绍MySQL和SQLite的语法与用法,并对它们的异同进行比较。
一、MySQL语法 MySQL是一种开源的关系型数据库管理系统,它的语法相对较为复杂。
MySQL的语法由不同的命令组成,常见的命令包括创建数据库、创建表、插入数据、查询数据、更新数据和删除数据。
以下是MySQL的一些常用语法及用法:1. 创建数据库使用CREATE DATABASE命令可以创建一个新的数据库。
例如,创建名为“mydb”的数据库:``` CREATE DATABASE mydb; ```2. 创建表使用CREATE TABLE命令可以创建一个新的表。
例如,创建名为“users”的表,包含id、name和age 字段: ``` CREATE TABLE users ( id INT PRIMARY KEY, name VARCHAR(50), age INT ); ```3. 插入数据使用INSERT INTO命令可以向表中插入新的数据。
例如,向“users”表中插入一条数据: ``` INSERT INTO users (id, name, age) VALUES (1,'John', 25); ```4. 查询数据使用SELECT命令可以从表中查询数据。
例如,查询“users”表中的所有数据: ``` SELECT * FROM users; ```5. 更新数据使用UPDATE命令可以更新表中的数据。
例如,将“users”表中id为1的记录的age字段更新为30: ``` UPDATE users SET age = 30 WHERE id = 1;```6. 删除数据使用DELETE命令可以从表中删除数据。
例如,删除“users”表中id为1的记录: ``` DELETE FROM users WHERE id = 1; ```二、SQLite语法 SQLite是一种轻量级的关系型数据库管理系统,它的语法相对简单。

数据库操作的基本语法⼤全1. 操作数据库:CRUD1. C(Create):创建* 创建数据库:* create database 数据库名称;* 创建数据库,判断不存在,再创建:* create database if not exists 数据库名称;* 创建数据库,并指定字符集* create database 数据库名称 character set 字符集名;* 练习:创建db4数据库,判断是否存在,并制定字符集为gbk* create database if not exists db4 character set gbk;2. R(Retrieve):查询* 查询所有数据库的名称:* show databases;* 查询某个数据库的字符集:查询某个数据库的创建语句* show create database 数据库名称;3. U(Update):修改* 修改数据库的字符集* alter database 数据库名称 character set 字符集名称;4. D(Delete):删除* 删除数据库* drop database 数据库名称;* 判断数据库存在,存在再删除* drop database if exists 数据库名称;5. 使⽤数据库* 查询当前正在使⽤的数据库名称* select database();* 使⽤数据库* use 数据库名称;2. 操作表1. C(Create):创建1. 语法:create table 表名(列名1 数据类型1,列名2 数据类型2,....列名n 数据类型n);* 注意:最后⼀列,不需要加逗号(,)* 数据库类型:1. int:整数类型* age int,2. double:⼩数类型* score double(5,2)3. date:⽇期,只包含年⽉⽇,yyyy-MM-dd4. datetime:⽇期,包含年⽉⽇时分秒 yyyy-MM-dd HH:mm:ss5. timestamp:时间错类型包含年⽉⽇时分秒 yyyy-MM-dd HH:mm:ss* 如果将来不给这个字段赋值,或赋值为null,则默认使⽤当前的系统时间,来⾃动赋值6. varchar:字符串* name varchar(20):姓名最⼤20个字符* zhangsan 8个字符张三 2个字符* 创建表create table student(id int,name varchar(32),age int ,score double(4,1),birthday date,insert_time timestamp);* 复制表:* create table 表名 like 被复制的表名;2. R(Retrieve):查询* 查询某个数据库中所有的表名称* show tables;* 查询表结构* desc 表名;3. U(Update):修改1. 修改表名alter table 表名 rename to 新的表名;2. 修改表的字符集alter table 表名 character set 字符集名称;3. 添加⼀列alter table 表名 add 列名数据类型;4. 修改列名称类型alter table 表名 change 列名新列别新数据类型;alter table 表名 modify 列名新数据类型;5. 删除列alter table 表名 drop 列名;4. D(Delete):删除* drop table 表名;* drop table if exists 表名 ;3.增删改表中数据1. 添加数据:* 语法:* insert into 表名(列名1,列名2,...列名n) values(值1,值2,...值n);* 注意:1. 列名和值要⼀⼀对应。

InfluxDB基本操作语法1.概述本文档将介绍In flu x DB的基本操作语法,包括数据库的创建与删除、数据的写入与查询等内容。
通过学习本文档,您将能够熟悉In f lu xD B的基本使用方法,为后续的数据管理和分析提供基础。
2.数据库操作2.1创建数据库要创建一个新的数据库,可以使用以下语法:C R EA TE DA TA BA SE<da t ab as e_na me>其中,`<d at ab as e_n am e>`是您希望创建的数据库的名称。
2.2删除数据库如果需要删除一个已存在的数据库,可以使用以下语法:D R OP DA TA BA SE<d ata b as e_na me>其中,`<d at ab as e_n am e>`是您希望删除的数据库的名称。
3.数据操作3.1写入数据要将数据写入In fl ux D B中,可以使用以下语法:I N SE RT IN TO<m ea sur e me nt_n am e><f iel d_s et>[ta g_se t]其中,`<m ea su re me n t_na me>`代表测量值(M ea su re me nt)的名称,`<fi el d_se t>`代表字段集合(Fi el dS e t),`[t ag_s et]`代表标签集合(Ta gS et)。
3.2查询数据为了从I nf lu xD B中查询数据,可以使用以下语法:S E LE CT<f ie ld_k ey>F RO M<me as ur em ent_na me>[WH ER E<tag_ke y>= '<ta g_va lu e>']其中,`<f ie ld_k ey>`代表字段(Fi eld)的名称,`<me as ur em en t_nam e>`代表测量值(Me a su re me nt)的名称,`[WH ER E<ta g_ke y>='<t ag_v al ue>']`是可选项,用于进行数据筛选。

mimic数据库语法Mimic数据库语法简介一、概述Mimic是一种模拟数据库语法,它的目的是为了提供一个类似真实数据库的环境,以便用户能够在没有真实数据库的情况下进行开发和测试。
本文将介绍Mimic数据库语法的基本用法和常见操作。
二、创建数据库和表1. 创建数据库:CREATE DATABASE <数据库名>;2. 使用数据库:USE <数据库名>;3. 创建表:CREATE TABLE <表名>(<列名1> <数据类型1>,<列名2> <数据类型2>,...);三、插入数据1. 插入单条数据:INSERT INTO <表名> VALUES (<值1>, <值2>, ...);2. 插入多条数据:INSERT INTO <表名> (<列名1>, <列名2>, ...)VALUES(<值1>, <值2>, ...),(<值1>, <值2>, ...),...;四、查询数据1. 查询所有列的数据:SELECT * FROM <表名>;2. 查询指定列的数据:SELECT <列名1>, <列名2>, ... FROM <表名>;3. 查询特定条件的数据:SELECT * FROM <表名> WHERE <条件>;五、更新数据1. 更新单条数据:UPDATE <表名> SET <列名1>=<新值1>, <列名2>=<新值2>, ... WHERE <条件>;2. 更新多条数据:UPDATE <表名> SET <列名1>=<新值1>, <列名2>=<新值2>, ...;六、删除数据1. 删除指定条件的数据:DELETE FROM <表名> WHERE <条件>;2. 删除表中所有数据:DELETE FROM <表名>;七、删除表和数据库1. 删除表:DROP TABLE <表名>;2. 删除数据库:DROP DATABASE <数据库名>;八、其他操作1. 排序:SELECT * FROM <表名> ORDER BY <列名> [ASC|DESC];2. 聚合函数:SELECT COUNT(*) FROM <表名>;SELECT SUM(<列名>) FROM <表名>;SELECT AVG(<列名>) FROM <表名>;SELECT MAX(<列名>) FROM <表名>;SELECT MIN(<列名>) FROM <表名>;3. 连接查询:SELECT * FROM <表名1> INNER JOIN <表名2> ON <条件>;4. 子查询:SELECT * FROM <表名1> WHERE <列名> IN (SELECT <列名> FROM <表名2>);以上是Mimic数据库语法的基本用法和常见操作,希望能对你的开发和测试工作有所帮助。

数据库相关操作命令语法格式在数据库管理中,掌握数据库相关操作命令语法格式是非常重要的。
无论是初学者还是有一定经验的数据库管理员,都需要对这些命令有深入的了解。
接下来,我将带你深入探讨数据库相关操作命令语法格式,并详细解析各种常见的操作命令。
希望通过本文的阅读,你能对数据库操作命令有更清晰的认识和理解。
一、数据库基本操作命令1. 创建数据库创建数据库是数据库管理的第一步,其命令语法格式如下:CREATE DATABASE database_name;这里,你需要将"database_name"替换为你想创建的数据库名称。
这个命令是非常简单明了的,但是在实际操作中需要注意数据库名称的规范性和唯一性。
2. 删除数据库删除数据库是一个谨慎的操作,其命令语法格式如下:DROP DATABASE database_name;同样地,你需要将"database_name"替换为你想删除的数据库名称。
删除数据库前,务必备份重要数据,以免误操作造成不可挽回的后果。
3. 使用数据库使用数据库是进行数据库操作的前提,其命令语法格式如下:USE database_name;在操作数据库前,必须确保使用了正确的数据库,以免对错误的数据库进行操作。
二、数据表操作命令1. 创建数据表创建数据表是数据库设计的基础,其命令语法格式如下:CREATE TABLE table_name (column1 datatype,column2 datatype,column3 datatype,...);在创建数据表时,你需要为每个列指定列名和数据类型,以确保数据表的结构合理完善。
2. 删除数据表删除数据表可能是在数据库设计过程中不断调整的一部分,其命令语法格式如下:DROP TABLE table_name;删除数据表时,需谨慎操作,避免误删重要数据表。
3. 插入数据插入数据是对数据表进行实际数据录入的操作,其命令语法格式如下:INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...);在插入数据时,需要确保插入的数据符合数据表列的数据类型和约束条件。

Oracle数据库语法总结一、DDL(数据定义语言)1、创建、删除表(1)CREATE TABLE 语句用于在Oracle数据库中创建新表:CREATETABLE表名(列1数据类型(大小/长度)[NOTNULL][CONSTRAINT约束名]列2数据类型(大小/长度)[NOTNULL][CONSTRAINT约束名]……(2)DROP TABLE 语句用于从Oracle数据库中删除表:DROPTABLE表名2、更改表(1)ALTERTABLE语句用于更改现有的表:ALTERTABLE表名ADD(添加新的列),MODIFY(修改现有的列),DROP(删除现有的列)(2)RENAME语句用于更改表名:RENAME表名1TO表名23、创建索引(1)CREATEINDEX语句用于在表中创建索引:CREATEINDEX索引名ON表名(列1,列2,...)(2)DROPINDEX语句用于从表中删除索引:DROPINDEX索引名4、创建约束(1)Primary Key 约束:ALTERTABLE表名ADDCONSTRAINT主键名PRIMARYKEY(列名)(2)Foreign Key约束:ALTERTABLE表名ADDCONSTRAINT外键名FOREIGNKEY(列名)REFERENCES参照表名(参照列);(3)Unique 约束:ALTERTABLE表名ADDCONSTRAINT唯一约束名UNIQUE(列1,列2,...);(4)NOTNULL约束:ALTERTABLE表名ADDCONSTRAINT非空约束名NOTNULL(列1,列2,...);5、删除约束(1)Primary Key 约束:ALTERTABLE表名DROPCONSTRAINT主键名PRIMARYKEY;(2)Foreign Key约束:ALTERTABLE表名DROPCONSTRAINT外键名FOREIGNKEY;(3)Unique 约束:。
数据库操作语法错误(SQLsyntaxerror)之两步⾛ 今天在做web应⽤操作数据库时出现了语法错误,提⽰的是在“xxxxxxx”附近出现了语法错误:CODE:Error: You have an error in your SQL syntax. Check the manual that corresponds to your MySQL server version for the right syntax to use near 's XXXXX。
当遇到这种错误时请记住按照以下两步⾛进⾏错误排除: 1. 简单语法错误。
检查错误提⽰中的“XXXXX”附近是否出现了中英⽂符号错误(特别注意中⽂空格和分号),然后检查是否出现单词拼写错误,或是与数据库中定义属性(数据库名、属性名等)拼写不⼀致,如果有则改正,这种错误时最简单的了,但必须要⾜够细⼼才能发现。
2. 数据库保留字错误。
如果不是上⾯的错误,即你百分百确定不存在中英⽂符号错误和拼写错误,那就可以参考⼀下此条建议:观察查询语句中的对象属性名,是否出现了数据库中的保留字,即把数据库的保留字命名为了数据对象属性名,这种错误不知道这⼀点的确实发现不了。
我当时遇到的就是这种错误,把From命名为了我的数据对象属性名,检查了⼀晚上才发现。
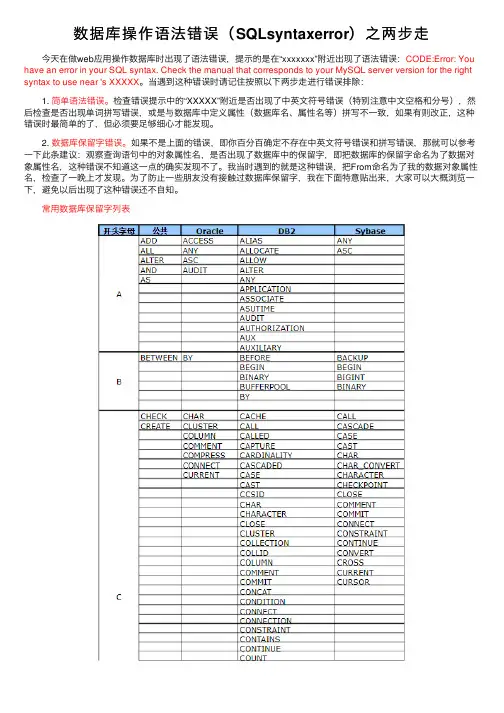
为了防⽌⼀些朋友没有接触过数据库保留字,我在下⾯特意贴出来,⼤家可以⼤概浏览⼀下,避免以后出现了这种错误还不⾃知。
常⽤数据库保留字列表 以上就是博主为⼤家介绍的这⼀板块的主要内容,这都是博主⾃⼰的学习过程,希望能给⼤家带来⼀定的指导作⽤,有⽤的还望⼤家点个⽀持,如果对你没⽤也望包涵,有错误烦请指出。
如有期待可关注博主以第⼀时间获取更新哦,谢谢!版权声明:本⽂为博主原创⽂章,未经博主允许不得转载。

数据库的基本语法及操作结构化查询语⾔包含6个部分:1、数据查询语⾔(DQL:Data Query Language):其语句,也称为“数据检索语句”,⽤以从表中获得数据,确定数据怎样在应⽤程序给出;保留字SELECT是DQL(也是所有SQL)⽤得最多的动词,其他DQL常⽤的保留字有WHERE,ORDER BY,GROUP BY和HAVING。
这些DQL保留字常与其它类型的SQL语句⼀起使⽤。
2、数据操作语⾔(DML:Data Manipulation Language):其语句包括动词INSERT、UPDATE和DELETE。
它们分别⽤于添加、修改和删除。
3、事务控制语⾔(TCL):它的语句能确保被DML语句影响的表的所有⾏及时得以更新。
包括COMMIT(提交)命令、SAVEPOINT(保存点)命令、ROLLBACK(回滚)命令。
4、数据控制语⾔(DCL):它的语句通过GRANT或REVOKE实现权限控制,确定单个⽤户和⽤户组对数据库对象的访问。
某些RDBMS可⽤GRANT或REVOKE控制对表单个列的访问。
5、数据定义语⾔(DDL):其语句包括动词CREATE,ALTER和DROP。
在数据库中创建新表或修改、删除表(CREAT TABLE 或 DROP TABLE);为表加⼊索引等。
6、指针控制语⾔(CCL):它的语句,像DECLARE CURSOR,FETCH INTO和UPDATE WHERE CURRENT⽤于对⼀个或多个表单独⾏的操作。
1. 数据库引擎:InnoDB:⽀持事务, ⽀持外键⽀持崩溃修复能⼒并发控制修改缺点:读写效率低占⽤空间⼤MyISAM :⽀持静态型动态型,压缩型优势:占⽤空间少,插⼊时候⽐较⾼数据的完整性Memory:默认使⽤hash索引放在内存中,处理速度快临时表缺点:放⼊内存,断电后,就失效了。
安全性差=不能建⽴太⼤的表1.2 创建数据库:语法:CREATE DATABASE [IF NOT EXISTS] <数据库名>[[DEFAULT] CHARACTER SET <字符集名>][[DEFAULT] COLLATE <校对规则名>];<数据库名>:创建数据库的名称。

pgsql数据库SQL语法一、概述PostgreSQL(简称 pgsql)是一种开源的关系型数据库管理系统,使用自定义的SQL语言进行操作,具有高度的可靠性和稳定性。
本文将通过详细介绍pgsql数据库SQL语法,帮助读者更加深入地了解pgsql数据库操作语法。
二、SQL基础1. 创建数据库在pgsql中,可以使用CREATE DATABASE语句来创建一个新的数据库。
语法如下:```sqlCREATE DATABASE dbname;```其中,dbname是数据库的名称。
通过这个语句,我们可以在pgsql 中创建一个新的数据库。
2. 创建表使用CREATE TABLE语句可以在pgsql中创建一张新表。
语法如下:```sqlCREATE TABLE table_name (column1 datatype,column2 datatype,column3 datatype,....);```通过这个语句,我们可以在pgsql中创建一个新的表,并且定义表的字段和各个字段的数据类型。
3. 插入数据使用INSERT INTO语句可以在pgsql中向表中插入新的数据。
语法如下:```sqlINSERT INTO table_name (column1, column2, column3, ....) VALUES (value1, value2, value3, ....);```通过这个语句,我们可以向pgsql中的表中插入新的数据。
4. 查询数据使用SELECT语句可以在pgsql中查询数据。
语法如下:```sqlSELECT column1, column2, ....FROM table_name;```通过这个语句,我们可以在pgsql中查询数据并且获取所需的结果。
5. 更新数据使用UPDATE语句可以在pgsql中更新表中的数据。
语法如下:```sqlUPDATE table_nameSET column1 = value1, column2 = value2, ....WHERE condition;```通过这个语句,我们可以在pgsql中更新表中的数据。
数据库增删改查基本语句1 增数据库增操作可以用于向数据库中添加新记录。
其 syntax(语法) 为:INSERT INTO 表名称 VALUES (值1, 值2,......)其中,`INSERT INTO` 负责指示数据库服务器执行插入操作,`表名称` 负责指定要向哪张表添加记录,`VALUES` 负责指定每列(field)所要添加的信息。
2 删数据库删操作可以用于删除数据库中的记录。
其 syntax(语法) 为:DELETE FROM 表名称 WHERE 条件其中,`DELETE FROM` 负责指示删除操作的执行,`表名称`负责指定从哪个数据库中删除数据,`WHERE` 负责指定要删除哪些记录(record)。
3 改数据库改操作可以用于修改数据库记录中的值。
其 syntax(语法) 为:UPDATE 表名称 SET 字段名称 = 新值 WHERE 条件如果需要同时修改多个字段,则可以把多个字段依次列出,用逗号分隔的形式:UPDATE 表名称 SET 字段1=值1, 字段2=值2,... WHERE 条件其中,`UPDATE ` 表示要进行更新操作,`表名称` 负责指定要更新的表,`SET` 负责指示要更新哪个字段,`新值` 负责指定更新后的值,`WHERE` 负责指定要更新哪些记录。
4 查数据库查操作可以用于从数据库中检索数据。
其 syntax(语法) 为:SELECT 字段1, 字段2, ... FROM 表名称 WHERE 条件其中,`SELECT` 负责指示要从数据库中的某个表中查询相应的字段信息,`字段1, 字段2,...`负责指定要从记录中查询哪些字段,`表名称`负责指定要从哪个表中检索数据,`WHERE` 负责指定检索哪些记录。
通过使用以上四种数据库操作语句,可以操作数据库中的记录,进行增删改查。
数据库的数据增删改查操作数据库是一个重要的数据存储工具,它能够有效地管理和组织数据,并提供强大的查询和处理功能。
在数据库应用中,常见的操作是对数据进行增加、删除、修改和查询。
本文将重点探讨数据库的数据增删改查操作的相关知识。
一、数据增加操作数据增加操作是向数据库中添加新数据的过程。
在数据库中,我们可以使用INSERT语句来实现数据的增加。
INSERT语句的基本语法如下:INSERT INTO 表名 (列1, 列2, 列3, ...)VALUES (值1, 值2, 值3, ...);在这个语法中,我们需要指定要插入数据的表名和要插入的列名以及对应的值。
例如,要向一个名为"students"的表中插入一条新纪录,可以使用下面的语句:INSERT INTO students (id, name, age, gender)VALUES (1001, '张三', 20, '男');以上语句将在"students"表中插入一条id为1001,姓名为"张三",年龄为20,性别为"男"的记录。
二、数据删除操作数据删除操作是从数据库中删除指定数据的过程。
在数据库中,我们可以使用DELETE语句来实现数据的删除。
DELETE语句的基本语法如下:DELETE FROM 表名WHERE 条件;在这个语法中,我们需要指定要删除数据的表名和删除的条件。
例如,要从名为"students"的表中删除所有年龄小于18岁的学生记录,可以使用下面的语句:DELETE FROM studentsWHERE age < 18;以上语句将从"students"表中删除所有年龄小于18岁的学生记录。
三、数据修改操作数据修改操作是对数据库中已有数据进行修改或更新的过程。
在数据库中,我们可以使用UPDATE语句来实现数据的修改。
td数据库语法TD数据库是一种分布式数据库,其使用的SQL查询语法与传统的关系型数据库类似,但也有一些特殊的语法和功能。
一、数据定义语言(DDL)1.创建表:在TD数据库中,可以使用CREATE TABLE语句创建表。
例如,创建一个名为“employees”的表,其中包含ID、姓名和年龄字段:```CREATE TABLE employees (id INT PRIMARY KEY,name VARCHAR(50),age INT);```2.删除表:使用DROP TABLE语句从数据库中删除表。
例如,删除名为“employees”的表:```DROP TABLE employees;```3.修改表:可以使用ALTER TABLE语句修改表的结构,如添加、删除或修改列。
例如,向名为“employees”的表添加一个新的“department”列:```ALTER TABLE employeesADD COLUMN department VARCHAR(50);```二、数据操作语言(DML)1.插入数据:使用INSERT INTO语句将一条或多条数据插入到表中。
例如,将一条员工记录插入到“employees”表中:```INSERT INTO employees (id, name, age, department)VALUES (1, 'John Doe', 25, 'HR');```2.更新数据:使用UPDATE语句更新表中的数据。
例如,将名为“John Doe”的员工的年龄更新为30岁:```UPDATE employeesSET age = 30WHERE name = 'John Doe';```3.删除数据:使用DELETE FROM语句删除表中的数据。
例如,删除名为“John Doe”的员工记录:```DELETE FROM employeesWHERE name = 'John Doe';```4.查询数据:使用SELECT语句从表中检索数据。
数据库操作命令与语法规范详解数据库是存储、管理和操作数据的关键组件之一。
不管是个人使用还是企业级应用,了解数据库操作命令和语法规范是非常重要的。
本文将详细解释常见的数据库操作命令,并介绍其语法规范,以帮助读者更好地理解和操作数据库。
1. 数据库创建命令创建数据库是数据库管理系统中的常见操作。
一般来说,下面的SQL命令是创建数据库的示例:```CREATE DATABASE database_name;```在这个命令中,`database_name`是待创建的数据库的名称。
通过这个命令,我们可以在数据库服务器上创建一个新的数据库。
2. 数据库表创建命令在数据库中,数据以表的形式进行组织和存储。
创建表是数据库设计中的重要一步。
以下是一个简单的创建表的示例:```CREATE TABLE table_name (column1 datatype constraint,column2 datatype constraint,...);在这个命令中,`table_name`是待创建表的名称。
`column1`,`column2`等是表中的列名,`datatype`是每一列的数据类型,`constraint`是列的约束条件,如主键、外键等。
3. 数据库表插入命令一旦数据库表创建完成,我们可以使用插入命令向表中添加数据。
下面是一个插入数据的示例:```INSERT INTO table_name (column1, column2, ...)VALUES (value1, value2, ...);```在这个命令中,`table_name`是待插入数据的表的名称。
`column1`,`column2`等是表中的列名。
`value1`,`value2`等是待插入的数据值。
通过这个命令,我们可以将数据插入到特定的表中。
4. 数据库表查询命令查询是数据库操作中常用的命令之一。
通过查询命令,我们可以从数据库中检索出特定的数据。
数据库基本语法(1)数据记录筛选: sql="select * from 数据表 where 字段名=字段值 orderby 字段名 [desc] " sql="select * from 数据表 where 字段名 like '%字段值%' orderby 字段名 [desc]"sql="select top10 * from 数据表 where 字段名 orderby 字段名[desc]"sql="select * from 数据表 where 字段名 in('值1','值2','值3')"sql="select * from 数据表 where 字段名 between 值1 and 值 2"(2)更新数据记录:sql="update 数据表 set 字段名=字段值 where 条件表达式"sql="update 数据表 set 字段1=值1,字段2=值2……字段n=值n where 条件表达式"(3)删除数据记录:sql="delete from 数据表 where 条件表达式"sql="delete from 数据表 "(将数据表所有记录删除)(4)添加数据记录:sql="insert into 数据表(字段1,字段2,字段3…) values(值1,值2,值3…)"sql="insert into ⽬标数据表 select * from 源数据表"(把源数据表的记录添加到⽬标数据表) (5)数据记录统计函数:AVG(字段名)得出⼀个表格栏平均值COUNT(*|字段名)对数据⾏数的统计或对某⼀栏有值的数据⾏数统计MAX(字段名)取得⼀个表格栏最⼤的值MIN(字段名)取得⼀个表格栏最⼩的值SUM(字段名)把数据栏的值相加引⽤以上函数的⽅法:sql="selectsum(字段名)as别名from数据表where条件表达式"setrs=conn.excute(sql)⽤rs("别名")获取统的计值,其它函数运⽤同上。
一、增:有4种方法1.使用insert插入单行数据:语法:insert [into] <表名> [列名] values <列值>例:insert into Strdents (姓名,性别,出生日期) values ('开心朋朋','男','1980/6/15') 注意:into可以省略;列名列值用逗号分开;列值用单引号因上;如果省略表名,将依次插入所有列2.使用insert select语句将现有表中的数据添加到已有的新表中语法:insert into <已有的新表> <列名>select <原表列名> from <原表名>例:insert into tongxunlu ('姓名','地址','电子邮件')select name,address,emailfrom Students注意:into不可省略;查询得到的数据个数、顺序、数据类型等,必须与插入的项保持一致3.使用select into语句将现有表中的数据添加到新建表中语法:select <新建表列名> into <新建表名> from <源表名>例:select name,address,email into tongxunlu from students注意:新表是在执行查询语句的时候创建的,不能够预先存在在新表中插入标识列(关键字‘identity’):语法:select identity (数据类型,标识种子,标识增长量) AS 列名into 新表from 原表名例:select identity(int,1,1) as 标识列,dengluid,password into tongxunlu from Struents 注意:关键字‘identity’4.使用union关键字合并数据进行插入多行语法:insert <表名> <列名> select <列值> tnion select <列值>例:insert Students (姓名,性别,出生日期)select '开心朋朋','男','1980/6/15' union(union表示下一行)select '蓝色小明','男','19**/**/**'注意:插入的列值必须和插入的列名个数、顺序、数据类型一致二、删:有2中方法1.使用delete删除数据某些数据语法:delete from <表名> [where <删除条件>]例:delete from a where name='开心朋朋'(删除表a中列值为开心朋朋的行)注意:删除整行不是删除单个字段,所以在delete后面不能出现字段名2.使用truncate table 删除整个表的数据语法:truncate table <表名>例:truncate table tongxunlu注意:删除表的所有行,但表的结构、列、约束、索引等不会被删除;不能用语有外建约束引用的表,并且不可恢复三、改使用update更新修改数据语法:update <表名> set <列名=更新值> [where <更新条件>]例:update tongxunlu set 年龄=18 where 姓名='蓝色小名'注意:set后面可以紧随多个数据列的更新值;where子句是可选的,用来限制条件,如果不选则整个表的所有行都被更新四、查1.普通查询语法:select <列名> from <表名> [where <查询条件表达试>] [order by <排序的列名>[asc或desc]]1).查询所有数据行和列例:select * from a说明:查询a表中所有行和列2).查询部分行列--条件查询例:select i,j,k from a where f=5说明:查询表a中f=5的所有行,并显示i,j,k3列3).在查询中使用AS更改列名例:select name as 姓名from a where xingbie='男'说明:查询a表中性别为男的所有行,显示name列,并将name列改名为(姓名)显示4).查询空行例:select name from a where email is null说明:查询表a中email为空的所有行,并显示name列;SQL语句中用is null或者is not null来判断是否为空行5).在查询中使用常量例:select name '唐山' as 地址from a说明:查询表a,显示name列,并添加地址列,其列值都为'唐山'6).查询返回限制行数(关键字:top percent)例1:select top 6 name from a说明:查询表a,显示列name的前6行,top为关键字例2:select top 60 percent name from a说明:查询表a,显示列name的60%,percent为关键字7).查询排序(关键字:order by , asc , desc)例:select namefrom awhere chengji>=60order by desc说明:查询表中chengji大于等于60的所有行,并按降序显示name列;默认为ASC升序2.模糊查询1).使用like进行模糊查询注意:like运算副只用语字符串,所以仅与char和varchar数据类型联合使用例:select * from a where name like '赵%'说明:查询显示表a中,name字段第一个字为赵的记录2).使用between在某个范围内进行查询例:select * from a where nianling between 18 and 20说明:查询显示表a中nianling在18到20之间的记录3).使用in在列举值内进行查询例:select name from a where address in ('北京','上海','唐山')说明:查询表a中address值为北京或者上海或者唐山的记录,显示name字段3.分组查询1).使用group by进行分组查询例:select studentID as 学员编号, AVG(score) as 平均成绩(注释:这里的score是列名)from score (注释:这里的score是表名)group by studentID说明:在表score中查询,按strdentID字段分组,显示strdentID字段和score字段的平均值;select语句中只允许被分组的列和为每个分组返回的一个值的表达试,例如用一个列名作为参数的聚合函数2).使用having子句进行分组筛选例:select studentID as 学员编号, AVG(score) as 平均成绩(注释:这里的score是列名)from score (注释:这里的score是表名)group by studentIDhaving count(score)>1说明:接上面例子,显示分组后count(score)>1的行,由于where只能在没有分组时使用,分组后只能使用having来限制条件,4.多表联接查询1).内联接①在where子句中指定联接条件例:select ,b.chengjifrom a,bwhere =说明:查询表a和表b中name字段相等的记录,并显示表a中的name字段和表b中的chengji字段②在from子句中使用join…on例:select ,b.chengjifrom a inner join bon (=)说明:同上2).外联接①左外联接查询例:select ,c.courseID,c.scorefrom strdents as sleft outer join score as con s.scode=c.strdentID说明:在strdents表和score表中查询满足on条件的行,条件为score表的strdentID 与strdents表中的sconde相同②右外联接查询例:select ,c.courseID,c.scorefrom strdents as sright outer join score as con s.scode=c.strdentID说明:在strdents表和score表中查询满足on条件的行,条件为strdents表中的sconde 与score表的strdentID相同5. 不显示重复的值1).查询一个字段①使用关键字distinct例:select distinct name from a;说明:查询表a中name字段的记录,并不显示表a中的重复的name字段2).查询多列,其中一个列不重复①使用关键字distinct例:select * from 表名where rowed in (select min(rowid) from 表名group by 列名);说明:查询表a中多个字段的记录,并且不显示子查询中分组的字段。
其中rowid为oracle 中的虚拟column用来指向表中一个row的存放地址,改为其它的不能运行。
其中min方法若改成max时结果会有所不同(说明暂定)3).查询并统计该字段的数量①使用函数count(列名)例:select name,count(name) from 表名group by name;说明:group by 那个字段只能查找哪个字段和该字段的数量。
若要同事搜索其它字段就报错。
原因可能是:搜索的结果是一组组的数据。
在每一组数据中,其它的列有很多,所以不能搜索出唯一的一个值。
4).从两表中查询并统计数据表a字段int tid = 0;//加班代码float days = 0;//工日数表b字段int tid = 0;//加班人员代码int overtimeid = 0;//加班代码int userid=0;//用户ID①使用函数sum(表名.列名)例:select erid,sum(a.days) from a,b where a.id=b.bid group by erid;说明:查询出一个人加班的天数,把人员分组,然后统计它加班的天数。