Mplus:因素分析模型与全模型
- 格式:pdf
- 大小:7.26 MB
- 文档页数:50

第2章 Mplus简介及主要命令语句2.1 Mplus简介2.3 Mplus语言概述2.2 Mplus安装2.4 Mplus常用命令2.5 Mplus的功能2.6 小结2.1 M plus简介Mplus是一款功能强大的多元统计分析软件,其综合了数个潜变量分析方法于一个统一的一般潜变量分析框架内。
Mplus主要处理如下模型:探索性因素分析(Exploratory factor analysis)、验证性因素分析与结构方程模型(Structural equation modeling)、项目反应理论(Item response theory analysis)、潜类别分析(Latent class analysis)、潜在转换分析(Latent transition analysis)、生存分析(Survival analysis)、增长模型(Growth modeling)、多水平模型(Multilevel analysis)、复杂数据(Complex survey data analysis)和蒙特卡洛模拟(Monte Carlo simulation)等。
Mplus 软件的前身是Bengt O. Muthén教授开发的结构方程建模软件LISCOMP(1988)。
Mplus的第一版发布于1998年底,经过10多年的完善,最近一次升级为2010年发布的第6版,最新版本6.12。
当前的Mplus 6提供了多个操作系统版(Windows, Mac OS X, 和Linux)。
图2-1为Mplus的界面,非常简洁。
图2-2为Mplus的工作界面,所有的建模过程均呈现在工作界面上。
Mplus默认命令符为蓝色字体,其他为黑色字体,注释通过感叹号“!”引导开始,为草绿色字体。
图2-1 Mplus windows版的界面图2-2 Mplus的工作界面(输入窗口)模型定义完成后,首先保存,然后点击图标,程序将会进入dos运行界面(图2-3),并出现运行提示(见图2-4)短暂停留后呈现结果输出界面(图2-5)。
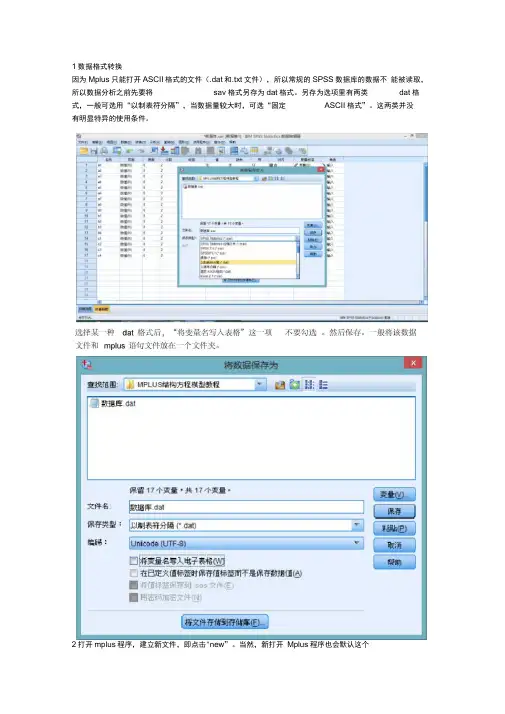
1数据格式转换因为Mplus只能打开ASCII格式的文件(.dat和.txt文件),所以常规的SPSS数据库的数据不能被读取,所以数据分析之前先要将sav格式另存为dat格式。
另存为选项里有两类dat格式,一般可选用“以制表符分隔”,当数据量较大时,可选“固定ASCII格式”。
这两类并没有明显特异的使用条件。
2打开mplus程序,建立新文件,即点击"new”。
当然,新打开Mplus程序也会默认这个TITLE: example3.2然后表明我们引用的数据库来自于哪里,也就是刚刚那个DAT文件。
命令为:DATA: FILE IS C:\Users\dell\Desktop\MPLUS结构方程模型教程数据库.dat;这里面需要注意的是:DATA: FILE IS (或者DATA: FILE=是固定句式,是必要的。
之后“C:\Users\dell\Desktop\MPLUS结构方程模型教程数据库.dat”这是DAT文件的保存路径。
一般情况下,如果mplus语句文件和dat文件在同一个文件夹中,只需要DATA: FILE I黴据库.dat;但实际上很多情况下,两者即使在同一个文件中,也很可能读不出来,所以必要的话,可将该DAT文件的保存路径写全,这样肯定是没错的。
另外,一个命令结束后,必须必须加上“;”即英文格式下的分号(除外TITLE)°3.3写出数据库中所有的变量名称以及本次分析需要的变量名称。
这需要按照spss数据库中变量名称顺序来写。
VARIABLE: NAMES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;USEVARIABLES ARES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;当然这是最基本繁琐的写法,可以直接写为:VARIABLE: NAMES ARE a1-a9 b1-b4 c1-c4;USEVARIABLES ARES ARE a1-a9 b1-b4 c1-c4;不同变量间有空格。


一、mplus结构方程模型简介mplus是一种常用的结构方程模型(Structural Equation Modeling, SEM)分析软件,它具有强大的功能和灵活的操作方式,被广泛应用于社会科学、心理学、教育学等领域的数据分析中。
在mplus中,基础命令是进行SEM分析的基础,熟练掌握基础命令对于进行SEM分析是至关重要的。
二、mplus基础命令的语法结构mplus基础命令的语法结构主要包括变量定义、模型设置和分析选项三个部分,在编写基础命令时需要按照特定的格式书写。
1. 变量定义变量定义部分通过使用VARIABLE命令来定义观测变量和潜在变量,语法格式如下:VARIABLE:变量1-变量n;定义观测变量和潜在变量的名称,并使用分号进行分隔。
2. 模型设置模型设置部分通过使用ANALYSIS命令来指定模型的参数设置和分析选项,语法格式如下:ANALYSIS:TYPE = basic;在模型设置部分可以指定各种参数和选项,以满足具体的分析需求。
3. 分析选项分析选项部分通过使用MODEL命令来指定SEM模型的结构和参数估计方法,语法格式如下:MODEL:f1 BY x1-x3;f2 BY x4-x6;在分析选项部分可以定义模型中的路径和参数,以及指定变量之间的关系。
三、mplus基础命令的使用方法在使用mplus进行SEM分析时,需要按照以下步骤进行基础命令的编写和运行。
1. 打开mplus软件并创建新的分析文件。
2. 编写基础命令,包括变量定义、模型设置和分析选项。
3. 保存基础命令文件,并使用.mplus后缀名进行命名。
4. 运行基础命令文件,查看分析结果并进行进一步的模型检验和修正。
四、mplus基础命令的案例分析以下是一个基础的mplus命令案例,用于进行双因子结构方程模型的分析:VARIABLE:y1-y5;f1 f2;ANALYSIS:TYPE = general;MODEL:f1 BY y1 y2 y3;f2 BY y4 y5;在这个案例中,通过使用VARIABLE命令定义了观测变量和潜在变量,使用ANALYSIS命令指定了分析类型,使用MODEL命令定义了双因子结构方程模型,并指定了观测变量和潜在因子之间的关系。



M p l u s结构方程模型步骤(入门)1数据格式转换因为Mplus只能打开ASCII格式的文件(.dat和.txt文件),所以常规的SPSS 数据库的数据不能被读取,所以数据分析之前先要将sav格式另存为dat格式。
另存为选项里有两类dat格式,一般可选用“以制表符分隔”,当数据量较大时,可选“固定ASCII格式”。
这两类并没有明显特异的使用条件。
选择某一种dat格式后,“将变量名写入表格”这一项不要勾选。
然后保存。
一般将该数据文件和mplus语句文件放在一个文件夹。
2 打开mplus程序,建立新文件,即点击“new”。
当然,新打开Mplus程序也会默认这个界面。
3 编辑命令。
这是Mplus分析数据最核心的步骤3.1 首先我们可以给该分析起个名字(该步骤可有可无),例如:TITLE: example3.2 然后表明我们引用的数据库来自于哪里,也就是刚刚那个DAT文件。
命令为:DATA: FILE IS C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库.dat;这里面需要注意的是: DATA: FILE IS (或者DATA: FILE=)是固定句式,是必要的。
之后“C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库.dat”这是DAT文件的保存路径。
一般情况下,如果mplus语句文件和dat文件在同一个文件夹中,只需要DATA: FILE IS数据库.dat; 但实际上很多情况下,两者即使在同一个文件中,也很可能读不出来,所以必要的话,可将该DAT文件的保存路径写全,这样肯定是没错的。
另外,一个命令结束后,必须必须加上“;”即英文格式下的分号(除外TITLE)。
3.3 写出数据库中所有的变量名称以及本次分析需要的变量名称。
这需要按照spss数据库中变量名称顺序来写。
VARIABLE: NAMES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4; USEVARIABLES ARES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4; 当然这是最基本繁琐的写法,可以直接写为:VARIABLE: NAMES ARE a1-a9 b1-b4 c1-c4;USEVARIABLES ARES ARE a1-a9 b1-b4 c1-c4;不同变量间有空格。

Mplus 6.1 使用示例Mplus结构方程模型步骤(入门)1数据格式转换因为Mplus只能打开ASCII格式的文件(.dat和.txt文件),所以常规的SPSS数据库的数据不能被读取,所以数据分析之前先要将sav格式另存为dat格式。
另存为选项里有两类dat格式,一般可选用“以制表符分隔”,当数据量较大时,可选“固定ASCII格式”。
这两类并没有明显特异的使用条件。
选择某种dat格式后,“将变量名写入表格”这一项不要勾选。
然后保存。
一般将该数据文件和mplus语句文件放在一个文件夹。
2 打开mplus程序,建立新文件,即点击“new”。
当然,新打开Mplus程序也会默认这个界面。
3 编辑命令。
这是Mplus分析数据最核心的步骤3.1 首先我们可以给该分析起个名字(该步骤可有可无),例如:TITLE: example3.2 然后表明我们引用的数据库来自于哪里,也就是刚刚那个DAT文件。
命令为:DATA: FILE IS C:\Users\dell\Desktop\MPLUS 结构方程模型教程\数据库.dat;这里面需要注意的是:DATA: FILE IS (或者DATA: FILE=)是固定句式,是必要的。
之后“C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库.dat”这是DAT文件的保存路径。
一般情况下,如果mplus语句文件和dat文件在同一个文件夹中,只需要DATA:FILE IS数据库.dat; 但实际上很多情况下,两者即使在同一个文件中,也很可能读不出来,所以必要的话,可将该DAT文件的保存路径写全,这样肯定是没错的。
另外,一个命令结束后,必须必须加上“;”即英文格式下的分号(除外TITLE)。
3.3 写出数据库中所有的变量名称以及本次分析需要的变量名称。
这需要按照spss数据库中变量名称顺序来写。
VARIABLE: NAMES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4; USEVARIABLES ARES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;当然这是最基本繁琐写法,可直接写为:VARIABLE: NAMES ARE a1-a9 b1-b4 c1-c4; USEVARIABLES ARES ARE a1-a9 b1-b4 c1-c4;不同变量间有空格。

多元分析处理的是多指标问题。
由于指标太多,使得分析的复杂性增加。
众多的要素常常给模型的构造带来很大困难。
观察指标的增加本来是为了使研究过程趋于完整,但反过来说,为使研究结果清晰明了而一味增加观察指标又让人陷入混乱不清。
由于在实际工作中,指标间经常具备一定的相关性,故人们希望用较少的指标代替原来较多的指标,但依然能反映原有的信息,于是产生了主成分分析、对应分析、典型相关分析和因子分析等方法。
因素分析就是解释外显变量之间相关的结构分析模型,主要用于实现两个目的:解释指标间的相关性和化简数据。
在因素分析模型理论中,假定每个指标(外显变量或称题项、观察值、问卷问题)均有两个部分组成,一为共同因素(common factor),一为唯一因素或独特因素(unique factor)。
唯一因素性质的两个假定n所有的唯一因素彼此之间没有相关n所有的唯一因素与所有的共同因素间也没有相关共同因素的性质n可能有相关(斜交旋转),也可能没有相关(直交旋转)因素分析理论模型Z j = a j1F1 + a j2F2 + a j3F3 + ··· + a jm F m + U j其中的符号意义分别表示如下:① Z j为第j个变量的标准化分数。
②F i为共同因素。
③m为所有变量的共同因素的数目。
④U j为变量Z j的唯一因素。
⑤a ji为因素负荷量,表示第i个共同因素对j个变量的变异量贡献。
以三个变量抽取两个共同因素为例,三个变量的线性组合分别为:Z1 = a11F1 + a12F2 + U1Z2 = a21F1 + a22F2 + U2Z3 = a31F1 + a32F2 + U3转换成因素矩阵如下表:变量F1F2共同性h²唯一因素d²X1a11a12a²11+ a²121-h²1X2a21a22a²21+ a²221-h²2X3a31a32a²31+ a²321-h²3特征值a²11+ a²21+ a²31a²12+ a²22+ a²32解释量(a²11+ a²21+ a²31)÷3(a²12+ a²22+ a²32)÷3根据测量理论架构在分析过程中所扮演的角色与检验时机不同,可以把因素分析分为探索性因素分析(EFA)与验证性因素分析(CFA)两类。

Mplus 6.1 使用示例文案大全 Mplus结构方程模型步骤(入门)1数据格式转换因为Mplus 只能打开ASCII 格式的文件(.dat 和.txt 文件),所以常规的SPSS 数据库的数据不能被读取,所以数据分析之前先要将sav 格式另存为dat 格式。
另存为选项里有两类dat 格式,一般可选用“以制表符分隔”,当数据量较大时,可选“固定ASCII 格式”。
这两类并没有明显特异的使用条件。
文案大全选择某种dat 格式后,“将变量名写入表格”这一项不要勾选。
然后保存。
一般将该数据文件和mplus 语句文件放在一个文件夹。
2 打开mplus程序,建立新文件,即点击“new”。
当然,新打开Mplus程序也会默认这个界面。
3 编辑命令。
这是Mplus分析数据最核心的步骤3.1 首先我们可以给该分析起个名字(该步骤可有可无),例如:TITLE: example3.2 然后表明我们引用的数据库来自于哪里,也就是刚刚那个DAT文件。
命令为:DATA: FILE IS C:\Users\dell\Desktop\MPLUS 结构方程模型教程\数据库.dat;这里面需要注意的是:DATA: FILE IS (或者DATA: FILE=)是固定句式,是必要的。
之后“C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库.dat”这是DAT文件的保存路径。
一般情况下,如果mplus语句文件和dat文件在同一个文件夹中,只需要DATA:文案大全FILE IS数据库.dat; 但实际上很多情况下,两者即使在同一个文件中,也很可能读不出来,所以必要的话,可将该DAT文件的保存路径写全,这样肯定是没错的。
另外,一个命令结束后,必须必须加上“;”即英文格式下的分号(除外TITLE)。
3.3 写出数据库中所有的变量名称以及本次分析需要的变量名称。
这需要按照spss数据库中变量名称顺序来写。
VARIABLE: NAMES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4; USEVARIABLES ARES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;当然这是最基本繁琐写法,可直接写为:VARIABLE: NAMES ARE a1-a9 b1-b4 c1-c4; USEVARIABLES ARES ARE a1-a9 b1-b4 c1-c4;不同变量间有空格。

Mplus(Muthén & Muthén,1998-2022)是一种用于进行统计分析和结构方程建模的软件包。
它在社会科学研究、心理学、教育研究以及其他领域中广泛应用,尤其擅长处理复杂的结构方程模型(SEM)。
"MLR" 在Mplus 中代表"Maximum Likelihood Robust",它是一种用于估计参数的统计方法。
MLR 方法结合了最大似然估计(MLE)和鲁棒标准误差估计。
鲁棒标准误差估计考虑了非正态数据分布和异方差性的情况,因此在具有一些数据偏差或异常值的情况下更稳健,可以提供更可靠的参数估计和假设检验结果。
在Mplus 中,您可以通过指定`ESTIMATOR = MLR` 来使用MLR 方法进行结构方程建模。
例如:
```mplus
MODEL:
[Your model specification here];
OUTPUT:
TECH1 TECH8;
```
其中,`ESTIMATOR = MLR` 指定了使用MLR 方法进行参数估计。
然后,通过
`OUTPUT` 命令来请求输出,以查看估计的参数、标准误差、拟合指标等。
MLR 方法特别适用于处理偏离正态分布的数据或具有异方差性的数据,因此在实际应用中,如果您的数据不满足正态性假设,使用MLR 方法可能是一个明智的选择,以获得更准确的结构方程模型估计结果。
但请注意,MLR 方法的计算成本可能较高,因此对于大规模数据集,可能需要更多的计算时间。
中介中介、、调节模型分析——MPLUS 建模温忠麟吴艳华南师范大学心理应用研究中心广东外语外贸大学应用心理系内容提要MPLUS简介MPLUS常用命令 中介模型分析调节模型分析MPLUS 简介MPLUS 是一款功能强大的多元统计分析软件,它可分析以下模型:探索性因子分析探索性因子分析((EFA )验证性因子分析验证性因子分析((CFA )结构方程模型结构方程模型((Structural equation modeling)项目反应理论分析(Item response theory analysis)潜类别分析(Latent class analysis)潜转换分析(Latent transition analysis)增长模型(Growth modeling)多水平建模分析(Multilevel analysis) 混合模型混合模型((Mixture modeling )M plus的分析框架一个EFA程序模型定义完成后,首先保存,然后点击“RUN”图标,程序将会进入dos 运行界面MPLUS常用命令TITLEDATADEFINEVARIABLEANALYSISMODELOUTPUTSAVEDATAPLOTMONTECARLO(红色的三个为必须命令群)DATA只能读取ASCII 格式文件格式文件((可用SPSS 文件的“另存为另存为””功能功能,,具体操作步骤为,打开SPSS 文件→FILE→SAVE DATA→对话框选择保存文件类型,下拉选项中选择“Tab-delimited(*.dat)”格式)) 只能识别数字数字默认数据文件与分析文档在同一个文件夹同一个文件夹同一个文件夹,如果不在同一个文件夹,需要额外指定路径变量数的上限是500,字符的长度是5000注意事项新命令必须另起一行命令必须以分号(;)结束如果命令一行写不下,可以直接按回车分行 “!”是后面的信息不读入,作为注释验证性因子分析验证性因子分析(Confirmatory factor analysis, CFA)是结构方程模型的重要组成部分,主要处理观测指标与潜变量之间的关系,也被称作测量模型(Measurement Model)。
中介中介、、调节模型分析——MPLUS 建模温忠麟吴艳华南师范大学心理应用研究中心广东外语外贸大学应用心理系内容提要MPLUS简介MPLUS常用命令 中介模型分析调节模型分析MPLUS 简介MPLUS 是一款功能强大的多元统计分析软件,它可分析以下模型:探索性因子分析探索性因子分析((EFA )验证性因子分析验证性因子分析((CFA )结构方程模型结构方程模型((Structural equation modeling)项目反应理论分析(Item response theory analysis)潜类别分析(Latent class analysis)潜转换分析(Latent transition analysis)增长模型(Growth modeling)多水平建模分析(Multilevel analysis) 混合模型混合模型((Mixture modeling )M plus的分析框架一个EFA程序模型定义完成后,首先保存,然后点击“RUN”图标,程序将会进入dos 运行界面MPLUS常用命令TITLEDATADEFINEVARIABLEANALYSISMODELOUTPUTSAVEDATAPLOTMONTECARLO(红色的三个为必须命令群)DATA只能读取ASCII 格式文件格式文件((可用SPSS 文件的“另存为另存为””功能功能,,具体操作步骤为,打开SPSS 文件→FILE→SAVE DATA→对话框选择保存文件类型,下拉选项中选择“Tab-delimited(*.dat)”格式)) 只能识别数字数字默认数据文件与分析文档在同一个文件夹同一个文件夹同一个文件夹,如果不在同一个文件夹,需要额外指定路径变量数的上限是500,字符的长度是5000注意事项新命令必须另起一行命令必须以分号(;)结束如果命令一行写不下,可以直接按回车分行 “!”是后面的信息不读入,作为注释验证性因子分析验证性因子分析(Confirmatory factor analysis, CFA)是结构方程模型的重要组成部分,主要处理观测指标与潜变量之间的关系,也被称作测量模型(Measurement Model)。
mplus数据分析:增长模型潜类别增长模型与增长混合模型再解释混合模型,增长混合模型这些问题咨询的同学还是比较多的,今天再次尝试写写它们的区别,希望对大家进一步理解两种做轨迹的方法有帮助。
首先,无论是LCGA还是GMM,它们都是潜增长模型的框框里面的东西:Latent growth modeling approaches,such as latent class growth analysis (LCGA)and growth mixture modeling (GMM),have been increasingly recognized fortheir usefulness for identifyinghomogeneous subpopulations within thelarger heterogeneous population and forthe identification of meaningful groups orclasses of individuals我们一开始做增长模型或者增长曲线模型的时候,初始的目的就是看轨迹,最简单的想法就是看看我的研究人群的某个变量的轨迹随着时间是如何发展的,这是目的1--------不考虑异质性,认为所有的人都有同样的轨迹,协变量对所有人的作用都是一样的。
然后更进一步,人们发现,其实人群中就算是同一个变量(特质)是存在着不同的轨迹的,如果我们单单认为一个轨迹能说明问题,其实是将问题过分地简单化了,是不对的-------这个时候考虑轨迹的潜类别和才是更加好的方法------考虑轨迹的潜类别就涉及到两个方法了一个就是GMM另一个就是LCGA。
增长混合模型GMM下图左边是全体个案的增长轨迹,传统的增长模型试图去描述整个群体的增长情况,认为所有个体的增长情况都可以用一个总的平均增长趋势去描述(左图中的实线)。
但是我们看整个人群中的其中一个亚组人群(右图),其实这个亚组的增长趋势是和人群总体大不相同的,人群的总体趋势是在上升,此亚组则是在下降,这也是从一个侧面说明考虑轨迹的潜类别的重要意义,我就是希望通过这么一套方法识别出整体轨迹发展的异质性,实现分类和干预的精准化:其实下面的左图可以理解为多水平模型(随机截距+随机斜率),中间的实线就是拟合出来的时间的固定效应:The conventional growth model canbe described as a multilevel,randomeffects model (Raudenbush &Bryk, 2002). According to this framework,intercept and slope vary across individualsand this heterogeneity is captured byrandom effects而GMM是在干什么呢?GMM, on the other hand, relaxes thisassumption and allows for differences ingrowth parameters across unobservedsubpopulations.GMM认为轨迹,也就是变量随着时间变化的情况是存在亚组的,而且这些亚组的斜率和截距其实不一样了,这些亚组怎么来呢,是用潜变量表示的,就是潜轨迹类别,叫做latent trajectory classes:This is accomplished using latenttrajectory classes (i.e., categorical latentvariables), which allow for different groupsof individual growth trajectories to varyaround different means (with the same ordifferent forms)就是你这样理解:多水平模型和潜类别分析一结合就有了增长混合模型(这句话我似乎之前在文章中写过,感兴趣的同学再去翻翻之前的文章):就是将多水平模型的随机斜率弄出来潜类别。
1数据格式转换因为Mplus只能打开ASCII格式的文件(.dat和.txt文件),所以常规的SPSS数据库的数据不能被读取,所以数据分析之前先要将sav格式另存为dat格式。
另存为选项里有两类dat格式,一般可选用“以制表符分隔”,当数据量较大时,可选“固定ASCII格式”。
这两类并没有明显特异的使用条件。
选择某一种dat格式后,“将变量名写入表格”这一项不要勾选。
然后保存。
一般将该数据文件和mplus语句文件放在一个文件夹。
2 打开mplus程序,建立新文件,即点击“new”。
当然,新打开Mplus程序也会默认这个界面。
3 编辑命令。
这是Mplus分析数据最核心的步骤3.1 首先我们可以给该分析起个名字(该步骤可有可无),例如:TITLE: example3.2 然后表明我们引用的数据库来自于哪里,也就是刚刚那个DAT文件。
命令为:DATA: FILE IS C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库.dat;这里面需要注意的是:DATA: FILE IS (或者DATA: FILE=)是固定句式,是必要的。
之后“C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库.dat”这是DAT文件的保存路径。
一般情况下,如果mplus语句文件和dat文件在同一个文件夹中,只需要DATA: FILE IS数据库.dat; 但实际上很多情况下,两者即使在同一个文件中,也很可能读不出来,所以必要的话,可将该DAT文件的保存路径写全,这样肯定是没错的。
另外,一个命令结束后,必须必须加上“;”即英文格式下的分号(除外TITLE)。
3.3 写出数据库中所有的变量名称以及本次分析需要的变量名称。
这需要按照spss数据库中变量名称顺序来写。
VARIABLE: NAMES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;USEVARIABLES ARES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;当然这是最基本繁琐的写法,可以直接写为:VARIABLE: NAMES ARE a1-a9 b1-b4 c1-c4;USEVARIABLES ARES ARE a1-a9 b1-b4 c1-c4;不同变量间有空格。
1数据格式转换因为Mplus只能打开ASCII格式的文件(.dat和.txt文件),所以常规的SPSS数据库的数据不能被读取,所以数据分析之前先要将sav格式另存为dat格式。
另存为选项里有两类dat格式,一般可选用“以制表符分隔”,当数据量较大时,可选“固定ASCII格式”。
这两类并没有明显特异的使用条件。
选择某一种dat格式后,“将变量名写入表格”这一项不要勾选。
然后保存。
一般将该数据文件和mplus语句文件放在一个文件夹。
2 打开mplus程序,建立新文件,即点击“new”。
当然,新打开Mplus程序也会默认这个界面。
3 编辑命令。
这是Mplus分析数据最核心的步骤3.1 首先我们可以给该分析起个名字(该步骤可有可无),例如:TITLE: example3.2 然后表明我们引用的数据库来自于哪里,也就是刚刚那个DAT文件。
命令为:DATA: FILE IS C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库.dat;这里面需要注意的是:DATA: FILE IS (或者DATA: FILE=)是固定句式,是必要的。
之后“C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库.dat”这是DAT文件的保存路径。
一般情况下,如果mplus语句文件和dat文件在同一个文件夹中,只需要DATA: FILE IS数据库.dat; 但实际上很多情况下,两者即使在同一个文件中,也很可能读不出来,所以必要的话,可将该DAT文件的保存路径写全,这样肯定是没错的。
另外,一个命令结束后,必须必须加上“;”即英文格式下的分号(除外TITLE)。
3.3 写出数据库中所有的变量名称以及本次分析需要的变量名称。
这需要按照spss数据库中变量名称顺序来写。
VARIABLE: NAMES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;USEVARIABLES ARES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;当然这是最基本繁琐的写法,可以直接写为:VARIABLE: NAMES ARE a1-a9 b1-b4 c1-c4;USEVARIABLES ARES ARE a1-a9 b1-b4 c1-c4;不同变量间有空格。