二叉树中序遍历的非递归算法实现
- 格式:doc
- 大小:47.50 KB
- 文档页数:5

中序遍历二叉树t的非递归算法-回复中序遍历是二叉树遍历的一种方法,它的特点是先访问左子树,然后访问根节点,最后访问右子树。
在非递归算法中,我们需要借助栈来实现中序遍历。
下面我们将逐步分析如何用非递归算法中序遍历二叉树。
首先,我们需要了解栈的基本知识。
栈是一种后进先出(LIFO)的数据结构,它有两个基本操作:入栈(push)和出栈(pop)。
在中序遍历中,我们将节点按照遍历顺序依次入栈,然后出栈并访问节点。
接下来,我们来介绍中序遍历二叉树的非递归算法。
我们可以通过模拟递归来实现中序遍历。
首先,我们定义一个栈用于存储待访问的节点。
初始时,将根节点入栈。
在每一次迭代中,我们需要判断栈是否为空。
若不为空,则将栈顶节点出栈,并访问该节点。
然后,我们将栈顶节点的右子树入栈。
接下来,将栈顶节点的左子树依次入栈,直到左子树为空。
下面,我们以一个简单的例子来说明这个过程。
假设我们有如下二叉树t:1/ \2 3/ \ / \4 5 6 7我们使用中序遍历的非递归算法来遍历这棵树。
首先,将根节点入栈,此时栈中的元素为[1]。
然后,循环执行以下步骤:1. 判断栈是否为空,栈不为空,执行以下步骤;2. 将栈顶节点出栈,访问该节点;3. 将栈顶节点的右子树入栈;4. 将栈顶节点的左子树依次入栈,直到左子树为空。
按照这个步骤,我们首先将1出栈并访问,然后将右子树入栈,栈中的元素为[2, 3]。
然后,我们继续将左子树入栈,栈中的元素变为[4, 2, 3]。
此时,我们将4出栈并访问,然后将栈中的元素变为[2, 3]。
接着,我们将2出栈并访问,将右子树入栈,栈中的元素变为[5, 3]。
继续将左子树入栈,栈中的元素为[5, 6, 3]。
接着,我们将5出栈并访问,将栈中的元素变为[6, 3]。
最后,我们将6出栈并访问,将右子树入栈,栈中的元素变为[7, 3]。
最后,我们将7出栈并访问,此时栈为空,遍历结束。
通过这个例子,我们可以看到中序遍历的非递归算法确实按照中序遍历的顺序访问了二叉树的所有节点。


二叉树的遍历算法1 先序遍历(T、p、S()、top)\*先序遍历的非递归算法,T为根指针,p为指针,指向当前结点。
使用一个栈S()、top为栈顶指针*\1.if(T=NULL)2.Printf( “这是一棵空二叉树”);3.else{△△p=T;top=0;4. While(top≠0)||(p≠NULL){△while(p≠NULL){﹡Visit(p→data); \﹡访问结点﹡\top=top+1;if (top>n) 调用栈满else{S(top)=p→rchild;P=P→lchild;}}﹡if (top≠0){p= S(top);top--;}}△}△△{算法结束}算法2 中序遍历(T、p、S()、top)\*{中序遍历的非递归算法,使用栈S(),top为栈顶指针,T指向根,p为指针,指向当前结点*\top=0,p=TWhile(top≠0)||(P≠NULL){While(P≠NULL){Top=top+1if (top>n) 调用栈满else{S(top)=p, p=p→lchied;}}If (top≠null){p=S(top);top=top-1;Visit(p→data); \﹡访问结点﹡\p=p→rchild;}}{算法结束}算法3 后序遍历(T、p、S()、top)\*后序遍历的非递归算法,T指向根,P为指标指向当前结点,使用堆栈S(),栈顶指针为top,*\1、if (t=NIL)2、then { 输出“这是一棵空树”go 22 \* 结束 *\3、else { p=t;top=0;4、 while (top≠0)||(p≠NIL) {5、 while (p≠NIL){6、 top=top+1;7、 if (top﹥n)8、调用栈满9、 else{S(top)=p;10、 p=p→lchild;}11、 }12、 if (top≠0){13、 p=S(top);top=top-114、 if (p﹤0){15、 p=-p;16、 Visit(p→data); \﹡访问结点﹡\17、 p=NIL;〕18、 else {top=top+1;19、 S(top)=-P;20、 p=p→rchild;}21、 }22、{算法结束}算法4 二叉树后序遍历(t、p、S()、top、h)\*后序遍历的非递归算法,T指向根,使用堆栈S(),top为栈顶指针,P为指针,指向当前结点,h为指针,指向刚被访问结点*\1、if (T=Nil){ 输出“这是一棵空树”go 20}2、else{﹡p=t,top=03、 if (p→lchild=Nil)&&(P→rchild=Nil)4、 then go 125、 else{△△top=top+1;S(top)=p;6、 if (p→lchild=Nil)7、 {p= p→rchild; go 3;}8、 else {△if (p→rchild=Nil)9、 go 1110、 else {top=top+1; S(top)= p→rchild;}11、 P=p→lchil; go 3}△}△△12、 Visit(p→data); \﹡访问结点﹡\13、 h=p14、 if (top=0){15、输出“栈空” go 20;}16、 else {p= S(top);top=top-1;17、 if(p→Lchild=h)OR(p→rchild=h)18、 then go 12;19、 else go 3;}}﹡20、{算法结束}。


golang 中序遍历递归非递归中序遍历是二叉树遍历的一种方式,以左子树、根节点、右子树的顺序访问节点。
在Golang中,我们可以使用递归和非递归两种方式实现中序遍历。
一、递归实现中序遍历递归实现中序遍历是最简单直观的方式。
我们可以定义一个递归函数,用于按中序遍历访问树的节点。
```gopackage mainimport "fmt"type TreeNode struct {Val intLeft *TreeNodeRight *TreeNode}func inorderTraversal(root *TreeNode) {if root != nil {inorderTraversal(root.Left)fmt.Printf("%d ", root.Val)inorderTraversal(root.Right)}}func main() {// 构造一棵二叉树root := &TreeNode{Val: 1}root.Left = &TreeNode{Val: 2}root.Right = &TreeNode{Val: 3}root.Left.Left = &TreeNode{Val: 4}root.Left.Right = &TreeNode{Val: 5}fmt.Println("中序遍历结果:")inorderTraversal(root)}```以上代码中,我们先构造了一棵二叉树,然后调用`inorderTraversal`函数进行中序遍历。
递归函数首先检查根节点是否为空,如果不为空,则按照左子树、根节点、右子树的顺序递归调用自身。
二、非递归实现中序遍历非递归实现中序遍历使用栈来模拟递归的过程。
具体实现过程如下:```gopackage mainimport "fmt"type TreeNode struct {Val intLeft *TreeNodeRight *TreeNode}func inorderTraversal(root *TreeNode) { stack := []*TreeNode{}cur := rootfor len(stack) > 0 || cur != nil {for cur != nil {stack = append(stack, cur)cur = cur.Left}cur = stack[len(stack)-1]stack = stack[:len(stack)-1]fmt.Printf("%d ", cur.Val)cur = cur.Right}}func main() {// 构造一棵二叉树root := &TreeNode{Val: 1}root.Left = &TreeNode{Val: 2}root.Right = &TreeNode{Val: 3}root.Left.Left = &TreeNode{Val: 4}root.Left.Right = &TreeNode{Val: 5}fmt.Println("中序遍历结果:")inorderTraversal(root)}```以上代码中,我们定义了一个栈和一个指针`cur`,其中栈用于存储遍历过程中的节点。

第5章树和二叉树一、填空题1、指向结点前驱和后继的指针称为线索。
二、判断题1、二叉树是树的特殊形式。
()2、完全二叉树中,若一个结点没有左孩子,则它必是叶子。
()3、对于有N个结点的二叉树,其高度为。
()4、满二叉树一定是完全二叉树,反之未必。
()5、完全二叉树可采用顺序存储结构实现存储,非完全二叉树则不能。
()6、若一个结点是某二叉树子树的中序遍历序列中的第一个结点,则它必是该子树的后序遍历序列中的第一个结点。
()7、不使用递归也可实现二叉树的先序、中序和后序遍历。
()8、先序遍历二叉树的序列中,任何结点的子树的所有结点不一定跟在该结点之后。
()9、赫夫曼树是带权路径长度最短的树,路径上权值较大的结点离根较近。
()110、在赫夫曼编码中,出现频率相同的字符编码长度也一定相同。
()三、单项选择题1、把一棵树转换为二叉树后,这棵二叉树的形态是(A)。
A.唯一的B.有多种C.有多种,但根结点都没有左孩子D.有多种,但根结点都没有右孩子解释:因为二叉树有左孩子、右孩子之分,故一棵树转换为二叉树后,这棵二叉树的形态是唯一的。
2、由3个结点可以构造出多少种不同的二叉树?(D)A.2 B.3 C.4 D.5解释:五种情况如下:3、一棵完全二叉树上有1001个结点,其中叶子结点的个数是(D)。
A.250 B. 500 C.254 D.501解释:设度为0结点(叶子结点)个数为A,度为1的结点个数为B,度为2的结点个数为C,有A=C+1,A+B+C=1001,可得2C+B=1000,由完全二叉树的性质可得B=0或1,又因为C为整数,所以B=0,C=500,A=501,即有501个叶子结点。
4、一个具有1025个结点的二叉树的高h为(C)。
A.11 B.10 C.11至1025之间 D.10至1024之间解释:若每层仅有一个结点,则树高h为1025;且其最小树高为⎣log21025⎦ + 1=11,即h在11至1025之间。

中序遍历的非递归算法中序遍历是二叉树遍历的一种方法,它按照左子树、根节点、右子树的顺序访问二叉树的节点。
相比于递归算法,非递归算法使用循环和栈来模拟递归过程,实现中序遍历。
1. 算法介绍中序遍历的非递归算法基于栈数据结构。
具体步骤如下:1.创建一个空栈。
2.初始化当前节点为根节点。
3.当当前节点不为空或者栈不为空时,执行以下操作:–如果当前节点不为空,则将当前节点压入栈,并将当前节点指向其左子节点。
–如果当前节点为空,则从栈中弹出一个节点,并将其输出。
然后将当前节点指向被弹出节点的右子节点。
4.重复步骤3,直到当前节点为空且栈为空。
2. 算法实现下面是使用Python编写的中序遍历的非递归算法实现:class TreeNode:def __init__(self, val=0, left=None, right=None):self.val = valself.left = leftself.right = rightdef inorderTraversal(root):stack = []result = []current = rootwhile current or stack:while current:stack.append(current)current = current.leftcurrent = stack.pop()result.append(current.val)current = current.rightreturn result3. 算法分析时间复杂度中序遍历的非递归算法的时间复杂度为O(n),其中n为二叉树中节点的个数。
这是因为每个节点都会被访问一次。
空间复杂度中序遍历的非递归算法的空间复杂度取决于栈的大小,即最坏情况下需要存储整棵树的节点。
所以空间复杂度为O(n),其中n为二叉树中节点的个数。
4. 示例考虑以下二叉树:1\2/3使用上述算法进行中序遍历,结果为[1, 3, 2]。

《数据结构》实验报告学号2015011512 姓名胡明禹专业数学与应用数学时间2018.5.8一、实验题目实验6 二叉树的遍历二、实验目的1. 掌握二叉树的存储思想与建立算法2. 掌握二叉树各种遍历方法的实现思想3. 实现二叉链表的递归遍历算法与非递归遍历算法三、算法设计分析(一)实验内容1.从键盘输入数据,建立一颗含有n个结点的二叉树2.从对二叉树进行先序,中序和后序遍历的递归算法实现,输出遍历序列3.实现先序遍历或中序遍历的非递归算法实现(二)总体设计此处给出主要函数功能、及函数间调用关系的的描述。
例如:①先序创建二叉树函数②先序遍历函数③中序遍历函数④后序遍历函数⑤前序遍历非递归算法⑥中序遍历非递归算法其功能描述如下:(1)主函数:统筹调用各个函数以实现相应功能void main()(2)①先序创建二叉树Status CreateBiTree(BiTree &T){char ch;scanf("%c",&ch);if(ch==' ')T=NULL;else{if(!(T = (BiTNode *)malloc(sizeof(BiTNode))))exit(OVERFLOW); T->data = ch;CreateBiTree(T->lchild);CreateBiTree(T->rchild);}return OK;}②先序遍历Status PreOrderTraverse(BiTree T,Status(*Visit)(TElemType e)) {if(T){if(Visit(T->data))if(PreOrderTraverse(T->lchild,Visit))if(PreOrderTraverse(T->rchild,Visit)) return OK;return ERROR;}else return OK;}③中序遍历Status InOrderTraverse(BiTree T,Status(*Visit)(TElemType e)) {if(T){if(InOrderTraverse(T->lchild,Visit))if(Visit(T->data))if(InOrderTraverse(T->rchild,Visit)) return OK;return ERROR;}else return OK;}④后序遍历函数Status PostOrderTraverse(BiTree T,Status(*Visit)(TElemType e)) {if(T){if(PostOrderTraverse(T->lchild,Visit))if(PostOrderTraverse(T->rchild,Visit))if(Visit(T->data))return OK;return ERROR;}else return OK;}⑤先序遍历非递归算法Status IPreOrderTraverse(BiTree T,Status(*Visit)(TElemType e)) {BiTree p;p=T;int NUM=-1;BiTNode *stack[30];while(p||NUM>0){Visit(p->data);NUM++;stack[NUM]=p;p=p->lchild;while(!p&&NUM>-1){p=stack[NUM];NUM--;p=p->rchild;}}return OK;}⑥中序遍历非递归算法Status IInOrderTraverse(BiTree T,Status(*Visit)(TElemType e)) {BiTree p;p=T;int NUM=0;BiTNode *stack[30];while(p||NUM>0){if(p){stack[NUM++]=p;p=p->lchild;}else{NUM--;p=stack[NUM];if(!Visit(p->data)) return ERROR;p=p->rchild;}}return OK;四、实验测试结果及结果分析(一)测试结果(此处给出程序运行截图)(二)结果分析成功完成了题目的基本操作。

实现二叉链表存储结构下二叉树的先序遍历的非递归算法要实现二叉链表存储结构下二叉树的先序遍历的非递归算法,可以使用栈来辅助存储节点。
首先,创建一个空栈,并将树的根节点压入栈中。
然后,循环执行以下步骤,直到栈为空:1. 弹出栈顶的节点,并访问该节点。
2. 若该节点存在右子节点,则将右子节点压入栈中。
3. 若该节点存在左子节点,则将左子节点压入栈中。
注:先将右子节点压入栈中,再将左子节点压入栈中的原因是,出栈操作时会先访问左子节点。
下面是使用Python语言实现的例子:```pythonclass TreeNode:def __init__(self, value):self.val = valueself.left = Noneself.right = Nonedef preorderTraversal(root):if root is None:return []stack = []result = []node = rootwhile stack or node:while node:result.append(node.val)stack.append(node)node = node.leftnode = stack.pop()node = node.rightreturn result```这里的树节点类为`TreeNode`,其中包含节点的值属性`val`,以及左子节点和右子节点属性`left`和`right`。
`preorderTraversal`函数为非递归的先序遍历实现,输入参数为二叉树的根节点。
函数中使用了一个栈`stack`来存储节点,以及一个列表`result`来存储遍历结果。
在函数中,先判断根节点是否为None。
如果是,则直接返回空列表。
然后,创建一个空栈和结果列表。
接下来,用一个`while`循环来执行上述的遍历过程。
循环的条件是栈`stack`不为空或者当前节点`node`不为None。

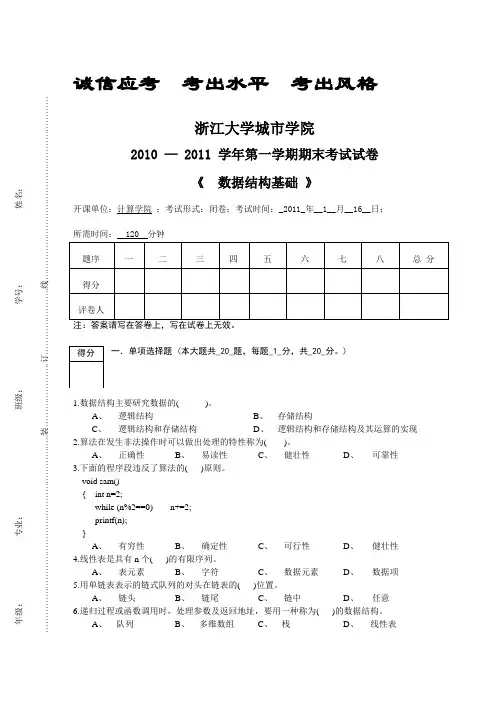
诚信应考 考出水平 考出风格浙江大学城市学院2010 — 2011 学年第一学期期末考试试卷《 数据结构基础 》开课单位:计算学院 ;考试形式:闭卷;考试时间:_2011_年__1__月__16__日; 所需时间: 120 分钟 题序 一 二 三 四 五 六 七 八 总 分 得分 评卷人注:答案请写在答卷上,写在试卷上无效。
一.单项选择题 (本大题共_20_题,每题_1_分,共_20_分。
)1.数据结构主要研究数据的( )。
A 、 逻辑结构B 、 存储结构C 、 逻辑结构和存储结构D 、 逻辑结构和存储结构及其运算的实现 2.算法在发生非法操作时可以做出处理的特性称为( )。
A 、 正确性B 、 易读性C 、 健壮性D 、 可靠性 3.下面的程序段违反了算法的( )原则。
void sam() { int n=2;while (n%2==0) n+=2; printf(n); }A 、 有穷性B 、 确定性C 、 可行性D 、 健壮性 4.线性表是具有n 个( )的有限序列。
A 、 表元素B 、 字符C 、 数据元素D 、 数据项 5.用单链表表示的链式队列的对头在链表的( )位置。
A 、 链头B 、 链尾C 、 链中D 、 任意 6.递归过程或函数调用时,处理参数及返回地址,要用一种称为( )的数据结构。
A 、 队列B 、 多维数组C 、 栈D 、 线性表得分年级:_____________ 专业:_____________________ 班级:_________________ 学号:_______________ 姓名:__________________ …………………………………………………………..装………………….订…………………..线………………………………………………………7.以下叙述中哪个选项是不正确的。
( )A 、 顺序存储方式只能用于存储线性结构。
B 、 顺序查找法适用于存储结构为顺序或链接存储的线性表。
中序遍历非递归算法一、前言在二叉树的遍历中,中序遍历是一种重要的遍历方式。
中序遍历非递归算法是指不使用递归函数,通过循环和栈等数据结构实现对二叉树进行中序遍历。
本文将详细介绍中序遍历非递归算法的实现过程和相关知识点。
二、中序遍历的定义在二叉树中,对每个节点的访问顺序有三种方式:先访问左子树,再访问根节点,最后访问右子树;先访问根节点,再访问左子树和右子树;先访问左子树和右子树,最后访问根节点。
这三种方式分别称为前序遍历、中序遍历和后序遍历。
其中,中序遍历是指按照“先访问左子树,再访问根节点,最后访问右子树”的顺序进行访问。
三、中序遍历非递归算法的思路1. 定义一个空的辅助栈;2. 从二叉树的跟节点开始循环:a. 将当前节点压入辅助栈;b. 如果当前节点存在左孩子,则将当前节点设置为其左孩子,继续循环;c. 如果当前节点不存在左孩子,则从辅助栈中弹出一个节点,并将该节点的值输出;d. 如果被弹出的节点存在右孩子,则将当前节点设置为其右孩子,继续循环;e. 如果被弹出的节点不存在右孩子,则回到步骤c。
四、中序遍历非递归算法的实现1. 定义一个空的辅助栈和一个指向二叉树跟节点的指针cur;2. 对于每个节点,如果该节点不为空或者辅助栈不为空,则进行循环:a. 如果当前节点不为空,则将其压入辅助栈中,并将当前节点更新为其左孩子;b. 如果当前节点为空,则从辅助栈中弹出一个元素,并输出该元素的值;i. 将当前节点更新为被弹出元素的右孩子。
3. 循环结束后,即可完成对二叉树的中序遍历。
五、代码实现以下是Java语言实现中序遍历非递归算法的代码:```public static void inOrder(TreeNode root) {Stack<TreeNode> stack = new Stack<>();TreeNode cur = root;while (cur != null || !stack.isEmpty()) {if (cur != null) {stack.push(cur);cur = cur.left;} else {cur = stack.pop();System.out.print(cur.val + " ");cur = cur.right;}}}```六、时间和空间复杂度中序遍历非递归算法的时间复杂度为O(n),其中n为二叉树节点的个数。
二叉树的递归及非递归的遍历及其应用二叉树是一种常见的数据结构,由节点和边组成,每个节点最多有两个子节点,分别称为左子节点和右子节点。
递归和非递归是两种遍历二叉树的方法,递归是通过递归函数实现,而非递归则利用栈的数据结构来实现。
二叉树的遍历是指按照一定的顺序访问二叉树中的每个节点。
常见的遍历方式有前序遍历、中序遍历和后序遍历。
1.前序遍历(Preorder Traversal):在前序遍历中,首先访问根节点,然后递归地遍历左子树和右子树。
遍历顺序为:根节点-左子树-右子树。
2.中序遍历(Inorder Traversal):在中序遍历中,首先递归地遍历左子树,然后访问根节点,最后递归地遍历右子树。
遍历顺序为:左子树-根节点-右子树。
3.后序遍历(Postorder Traversal):在后序遍历中,首先递归地遍历左子树和右子树,最后访问根节点。
遍历顺序为:左子树-右子树-根节点。
递归遍历方法的实现相对简单,但可能存在性能问题,因为递归调用会导致函数的调用和返回开销,尤其是在处理大规模二叉树时。
而非递归遍历方法则能够通过利用栈的特性,在迭代过程中模拟函数调用栈,避免了函数调用的性能开销。
非递归遍历二叉树的方法通常利用栈来实现。
遍历过程中,将节点按照遍历顺序入栈,然后访问栈顶元素,并将其出栈。
对于前序遍历和中序遍历,入栈顺序不同,而对于后序遍历,需要维护一个已访问标记来标识节点是否已访问过。
以下是非递归遍历二叉树的示例代码(以前序遍历为例):```pythonclass TreeNode:def __init__(self, val=0, left=None, right=None):self.val = valself.left = leftself.right = rightdef preorderTraversal(root): if not root:return []stack = []result = []stack.append(root)while stack:node = stack.pop()result.append(node.val)if node.right:stack.append(node.right)if node.left:stack.append(node.left)return result```在实际应用中,二叉树的遍历方法有很多应用。
浅析一种二叉树非递归遍历算法的C语言实现论文一种二叉树非递归遍历算法的C语言实现论文导读:本论文是一篇关于一种二叉树非递归遍历算法的C语言实现的优秀论文范文,对正在写有关于递归论文的写有一定的参考和指导作用,摘要:针对二叉树的链式存储结构,分析了二叉树的各种遍历算法,探讨了递归算法的递推消除理由,提出了一种改善的非递归遍历算法并用C语言予以实现。
关键词:二叉树;遍历算法;非递归;C语言实现1009-3044(2014)01-0223-031 概述树形结构是一种非常常见的数据结构,而二叉树又是其中最重要的一种树形结构。
二叉树的遍历是指按照一定的规则和次序将二叉树中的每一个结点都访问一次,既不能重复,也不能漏掉。
一般而言,对二叉树的遍历有前序遍历、中序遍历、后序遍历和按层遍历等几种方式。
在具体的算法设计上,以上遍历方式一般采取递归算法来实现,该文将探讨采用非递归算法来实现二叉树的遍历。
2 二叉树的数据结构描述二叉树作为一种非线性结构,每个结点最多有一个双亲结点和两个子结点。
二叉树可以采用顺序存储结构和链式存储结构。
对于完全二叉树而言,采用顺序存储是非常方便并且节省空间的,但是对于大部分的非完全二叉树而言,采用顺序存储将导致空间浪费严重且结构混乱、效率低下。
因此,更多的时候,大家都更愿意用链式存储结构来表示二叉树,这样结构更加清晰,尤其是对于一种二叉树非递归遍历算法的C语言实现由写论文的好帮手.zbjy.提供,.左右子树的描述和双亲节点的描述更加方便。
该文中拟采用链式结构来表示二叉树。
用链式存储结构来表示二叉树,一个结点至少由3个域组成,即数据域、左子结点域和右子结点域(如图1所示)。
3 二叉树的遍历及递归算法实现3.1 二叉树的遍历二叉树的遍历就是一个不漏的访问树中的每个结点,同时也不能重复。
所谓“访问”,就是指对结点的数据域进行某种操作,比如说读取、删除、更新、求该节点深度等等。
对于二叉树中的任意一个部分,都可以把它看作三部分,根节点、左子树、右子树,我们用D表示访问跟结点,用L表示遍历左子树,用R表示遍历右子树,则共有以下6种遍历方式[1]。
树和二叉树1 按先序遍历的扩展序列建立一棵二叉树的存储结构。
设计思想:先序遍历为:先访问根节点,先序遍历左子数,先序遍历右子数完整代码见附件。
伪代码为:bool BITREE::CreateBiTree(BiTree &T){ /*先序序列建立二叉树*/char ch;scanf("%c",&ch);if (ch=='*')T = NULL;else {if (!(T = (BiTNode *)malloc(sizeof(BiTNode))))return ERROR;T->data = ch;CreateBiTree(T->lchild);CreateBiTree(T->rchild);}return OK;}2 分别实现二叉树先序、中序、后序遍历的递归算法。
设计思想:先序遍历为:访问根节点,先序遍历左子数,先序遍历右子数中序遍历为:中序遍历左子数,访问根节点,中序遍历右子数后序遍历为:后序遍历左子数,后序遍历右子数,访问根节点完整代码见附件。
伪代码为:Status BITREE::PreOrderTraverse(BiTree T, Status(*Visit)(TElemType)) { /*先序遍历二叉树的递归算法*/if (T){if(Visit(T->data))if(PreOrderTraverse(T->lchild, Visit))if(PreOrderTraverse(T->rchild, Visit))return OK;return ERROR;}elsereturn OK;}Status BITREE::InOrderTraverse(BiTree T, Status(*Visit)(TElemType)) { /*中序遍历二叉树的递归算法*/if(T){if(InOrderTraverse(T->lchild, Visit))if(Visit(T->data))if(InOrderTraverse(T->rchild, Visit))return OK;return ERROR;}else return OK;}Status BITREE::PostOrderTraverse(BiTree T, Status(*Visit)(TElemType)) { /*后序遍历二叉树的递归算法*/if(T){if(PostOrderTraverse(T->lchild, Visit))if(PostOrderTraverse(T->rchild, Visit))if(Visit(T->data))return OK;return ERROR;}else return OK;}3 实现二叉树中序遍历的非递归算法。