spark-Bench环境搭建文档
- 格式:docx
- 大小:274.88 KB
- 文档页数:4


Spark编译与部署(上)--基础环境搭建目录1运行环境说明 (3)1.1硬软件环境 (3)1.2集群网络环境 (3)1.3安装使用工具 (4)1.3.1Linux文件传输工具 (4)1.3.2Linux命令行执行工具 (4)2搭建样板机环境 (5)2.1安装操作系统 (6)2.2设置系统环境 (15)2.2.1设置机器名 (15)2.2.2设置IP地址 (15)2.2.3设置Host映射文件 (17)2.2.4关闭防火墙 (18)2.2.5关闭SElinux (19)2.3配置运行环境 (19)2.3.1更新OpenSSL (19)2.3.2修改SSH配置文件 (20)2.3.3增加hadoop组和用户 (21)2.3.4JDK安装及配置 (22)2.3.5Scala安装及配置 (24)3配置集群环境 (25)3.1复制样板机 (25)3.2设置机器名和IP地址 (26)3.3配置SSH无密码登录 (26)3.4设置机器启动模式(可选) (29)4问题解决 (30)4.1 安装C ENT OS64位虚拟机T HIS HOST SUPPORTS I NTEL VT-X, BUT I NTEL VT-X IS DISABLED (30)4.2 *** IS NOT IN THE SUDOERS FILE解决方法 (30)Spark编译与部署(上)--基础环境搭建1运行环境说明1.1硬软件环境●主机操作系统:Windows 64位,双核4线程,主频2.2G,10G内存●虚拟软件:VMware® Workstation 9.0.0 build-812388●虚拟机操作系统:CentOS6.5 64位,单核,1G内存●虚拟机运行环境:JDK:1.7.0_55 64位Hadoop:2.2.0(需要编译为64位)Scala:2.10.4Spark:1.1.0(需要编译)1.2集群网络环境集群包含三个节点,节点之间可以免密码SSH访问,节点IP地址和主机名分布如下:1.所有节点均是CentOS6.5 64bit系统,防火墙/SElinux均禁用,所有节点上均创建了一个hadoop用户,用户主目录是/home/hadoop,上传文件存放在/home/hadoop/upload 文件夹中。
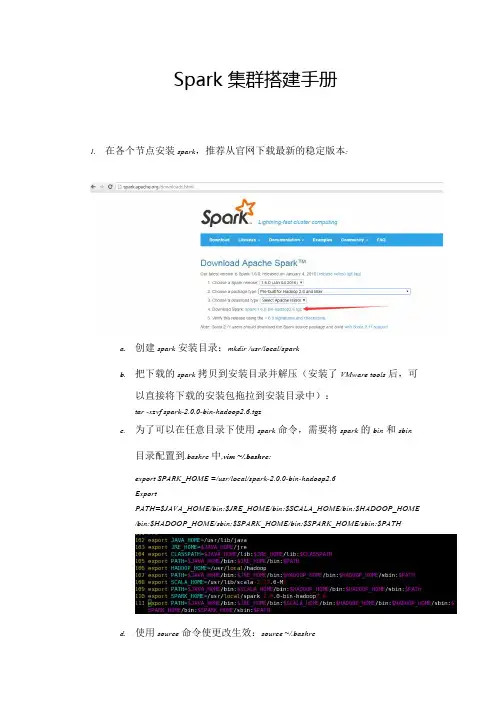
Spark集群搭建手册1.在各个节点安装spark,推荐从官网下载最新的稳定版本:a.创建spark安装目录:mkdir/usr/local/sparkb.把下载的spark拷贝到安装目录并解压(安装了VMware tools后,可以直接将下载的安装包拖拉到安装目录中):tar-xzvf spark-2.0.0-bin-hadoop2.6.tgzc.为了可以在任意目录下使用spark命令,需要将spark的bin和sbin目录配置到.bashrc中,vim~/.bashrc:export SPARK_HOME=/usr/local/spark-2.0.0-bin-hadoop2.6ExportPATH=$JAVA_HOME/bin:$JRE_HOME/bin:$SCALA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATHd.使用source命令使更改生效:source~/.bashrc2.在各个节点配置spark一下,配置文件都是在$SPARK_HOME/conf目录下:a.修改slaves文件,(若没有slaves文件可以cp slaves.template slaves创建),添加worker节点的Hostname,修改后内容如下:b.配置spark-env.sh,(若没有该文件可以cp spark-env.sh.template spark-env.sh创建),添加如下内容:export JAVA_HOME=/usr/lib/javaexport SCALA_HOME=/usr/lib/scala-2.12.0-M5export HADOOP_HOME=/usr/local/hadoopexport HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoopexport SPARK_MASTER_IP=masterexport SPARK_WORKER_MEMORY=1g新版的:(旧版的)修改后的内容如下:更详细的配置说明,请参考官方文档:/docs/latest/spark-standalone.html#cluster-launch-scriptsc.(可选)配置spark-defaults.sh:d.将主节点中的Spark目录复制到从节点的家目录中3.启动并验证spark集群:Spark只是一个计算框架,并不提供文件系统功能,故我们需要首先启动文件系统hdfs;在standalone模式下,我们并不需要启动yarn功能,故不需要启动yarn.a.用start-dfs.sh启动hdfsb.在hadoop集群启动成功的基础上,启动spark集群,常见的做法是在master节点上start-all.sh:c.使用jps在master和worker节点上验证spark集群是否正确启动:d.通过webui查看spark集群是否启动成功:http://master:8080。

spark部署环境搭建spark下载地址:hadoop下载地址:博主spark版本选择的是2.4.5 所以对应的hadoop版本是2.7.7下载之后直接上传到linux,解压之后就可以啦,不过⾸先要先配置java环境jdk必须在1.8以上配置好jdk后解压hadoop和spark然后进⼊spark⽬录运⾏./bin/spark-shell出现如上图所⽰边上spark环境部署好了然后做⼀个⼩测试在spark⽬录下创建两个⽂件,在⽂件中随便输⼊⼏个单词,然后统计下每个单词出现次数然后输⼊sc.textFile("in").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println)统计完成然后退出spark-shell再运⾏下spark提供的案例./bin/spark-submit \--class org.apache.spark.examples.SparkPi \--executor-memory 1G \--total-executor-cores 2 \./examples/jars/spark-examples_2.11-2.4.5.jar \100这是计算圆周率表⽰案例运⾏成功上⾯是spark单独使⽤,但是spark要和hadoop⼀起使⽤,所以要把spark运⾏到yarn上1.⾸先spark将应⽤提交各hadoop 的Resource Manager(资源管理器)2.然后Resource Manager 创建ApplicationMastor(应⽤管理器)3.Application Mastor向Resource Manager申请资源4.Resource Manager 返会Data Manger列表(这个列表不包含包括Application Mastor 的Data Manager)5.Application Mastor 选取Data Manager 创建Container(容器)6.Container创建完成后反向注册到Application Mastor7.Application Mastor 分解任务并且进⾏调度先启动hadoop1.修改hadoop的配置⽂件 /opt/module/hadoop/etc/hadoop/mapred-site.xmlcp mapred-site.xml.template mapred-site.xmlvi mapred-site.xml<configuration><!-- 通知框架MR使⽤YARN --><property><name></name><value>yarn</value></property></configuration>启动hadoop 然后运⾏ bin/spark-shell --master yarn-client还是报错出现上图修改 vim /opt/module/hadoop/etc/hadoop/yarn-site.xml <configuration><!-- Site specific YARN configuration properties --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property></configuration>启动hadoop然后运⾏ bin/spark-shell --master yarn-client出现Exception in thread "main" org.apache.spark.SparkException: When running with master 'yarn-client' either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment.这是由于我们没有在spark中配置hadoop的地址进⼊conf配置⽬录复制⼀个spark-env.sh.template 命名为spark-env.sh cp spark-env.sh.template spark-env.sh然后 vi spark-env.sh在最后⼀⾏添加hadoop的⽬录YARN_CONF_DIR=/opt/module/hadoop启动成功。

Spark报告金航1510122526Spark实验报告一、环境搭建1、下载scala2.11.4版本下载地址为:/download/2.11.4.html2、解压和安装:解压:tar -xvf scala-2.11.4.tgz安装:mv scala-2.11.4 ~/opt/3、编辑~/.bash_profile文件增加SCALA_HOME环境变量配置,export JAVA_HOME=/home/spark/opt/java/jdk1.6.0_37exportCLASSPATH=.:$JAVA_HOME/jre/lib:$JAVA_HOME/lib:$JAVA_HOME/lib/too ls.jarexport SCALA_HOME=/home/spark/opt/scala-2.11.4export HADOOP_HOME=/home/spark/opt/hadoop-2.6.0PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:${SCALA_HOME}/bin立即生效source ~/.bash_profile4、验证scala:scala -version5、copy到slave机器scp ~/.bash_profile spark10..45.56:~/.bash_profile6、下载spark,wget/spark-1.2.0-bin-hadoop2.4.tgz7、在master主机配置spark :将下载的spark-1.2.0-bin-hadoop2.4.tgz 解压到~/opt/即~/opt/spark-1.2.0-bin-hadoop2.4,配置环境变量SPARK_HOME# set java envexport JAVA_HOME=/home/spark/opt/java/jdk1.6.0_37exportCLASSPATH=.:$JAVA_HOME/jre/lib:$JAVA_HOME/lib:$JAVA_HOME/lib/tools.ja rexport SCALA_HOME=/home/spark/opt/scala-2.11.4export HADOOP_HOME=/home/spark/opt/hadoop-2.6.0export SPARK_HOME=/home/spark/opt/spark-1.2.0-bin-hadoop2.4PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:${SCALA_HOME}/bin:${SPARK_H OME}/bin:${HADOOP_HOME}/bin配置完成后使用source命令使配置生效进入spark conf目录:[sparkS1PA11 opt]$ cd spark-1.2.0-bin-hadoop2.4/[sparkS1PA11 spark-1.2.0-bin-hadoop2.4]$ lsbin conf data ec2 examples lib LICENSE logs NOTICE python README.md RELEASE sbin work[sparkS1PA11 spark-1.2.0-bin-hadoop2.4]$ cd conf/[sparkS1PA11 conf]$ lsfairscheduler.xml.template metrics.properties.template slaves.template spark-env.shlog4j.properties.template slaves spark-defaults.conf.templ ate spark-env.sh.templatefirst :修改slaves文件,增加两个slave节点S1PA11、S1PA222[sparkS1PA11 conf]$ vi slavesS1PA11S1PA222second:配置spark-env.sh首先把spark-env.sh.template copy spark-env.shvi spark-env.sh文件在最下面增加:export JAVA_HOME=/home/spark/opt/java/jdk1.6.0_37export SCALA_HOME=/home/spark/opt/scala-2.11.4export SPARK_MASTER_IP=10.58.44.47export SPARK_WORKER_MEMORY=2gexport HADOOP_CONF_DIR=/home/spark/opt/hadoop-2.6.0/etc/hadoopHADOOP_CONF_DIR是Hadoop配置文件目录,SPARK_MASTER_IP主机IP地址,SPARK_WORKER_MEMORY是worker使用的最大存完成配置后,将spark目录copy slave机器scp -r~/opt/spark-1.2.0-bin-hadoop2.4 spark10..45.56:~/opt/8、启动spark分布式集群并查看信息[sparkS1PA11 sbin]$ ./start-all.sh查看:[sparkS1PA11 sbin]$ jps31233 ResourceManager27201 Jps30498 NameNode30733 SecondaryNameNode5648 Worker5399 Master15888 JobHistoryServer如果HDFS没有启动,启动起来.查看slave节点:[sparkS1PA222 scala]$ jps20352 Bootstrap30737 NodeManager7219 Jps30482 DataNode29500 Bootstrap757 Worker9、页面查看集群状况:进去spark集群的web管理页面,访问因为我们看到两个worker节点,因为master和slave都是worker节点我们进入spark的bin目录,启动spark-shell控制台访问master:4040/,我们可以看到spark WEBUI页面spark集群环境搭建成功了10、运行spark-shell 测试之前我们在/tmp目录上传了一个README.txt文件,我们现在就用spark读取hdfs 中README.txt文件取得hdfs文件:count下READM.txt文件中文字总数,我们过滤README.txt包括The单词有多个我们算出来一共有4个The单词我们通过wc也算出来有4个The单词我们再实现下Hadoop wordcount功能:首先对读取的readmeFile执行以下命令:其次使用collect命令提交并执行job:我们看下WEBUI界面执行效果:二、统计单词个数例子,使用spark apiWordCount:步骤1:val sc = new SparkContext(args(0),“WordCount”,System.getenv(“SPARK_HOME”),Seq(System.getenv(“SPARK_TEST_JAR”)))val textFile = sc.textFile(args(1))val inputFormatClass = classOf[SequenceFileInputFormat[Text,Text]] var hadoopRdd = sc.hadoopRDD(conf, inputFormatClass, classOf[Text], classOf[Text])步骤3:val result = hadoopRdd.flatMap{case(key, value) => value.toString().split(“\\s+”);}.map(word => (word, 1)). reduceByKey (_ + _)将产生的RDD数据集保存到HDFS上。

spark环境搭建流程下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by theeditor. I hope that after you download them,they can help yousolve practical problems. The document can be customized andmodified after downloading,please adjust and use it according toactual needs, thank you!In addition, our shop provides you with various types ofpractical materials,such as educational essays, diaryappreciation,sentence excerpts,ancient poems,classic articles,topic composition,work summary,word parsing,copy excerpts,other materials and so on,want to know different data formats andwriting methods,please pay attention!1. 安装 Java检查系统是否已安装 Java,如果没有则需要安装。

For Windows安装hadoopHADOOP_HOME=G:\zhangrui\bigdata\hadoop-2.7.3安装spark添加spark/bin到path变量,这样就能在命令提示行执行spark-shell 、spark-submit等命令了安装scala安装scala eclipse安装sbt添加sbt/bin到path环境变量在命令提示行执行sbt命令,等执行完成。
在C:\Users\zhangrui\.sbt\0.13新建plugins目录,新建sbt.build文件,内容为:addSbtPlugin("com.typesafe.sbteclipse" % "sbteclipse-plugin" % "2.4.0")addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.11.2")在命令提示行重新执行sbt,等待执行结束。
运行在eclipse的workspace,新建一个工程目录,比如sparkdemo,还新建一个build.sbt文件,内容如下:importAssemblyKeys._assemblySettingsname := "spark_demo"version := "1.0"scalaVersion := "2.11.8"EclipseKeys.createSrc := EclipseCreateSrc.Default + EclipseCreateSrc.ResourcelibraryDependencies += "org.apache.spark" % "spark-core_2.10" % "1.5.2"命令提示行下进入该目录,执行先执行sbt,在执行eclipse。

Spark开发环境搭建和作业提交Spark⾼可⽤集群搭建在所有节点上下载或上传spark⽂件,解压缩安装,建⽴软连接配置所有节点spark安装⽬录下的spark-evn.sh⽂件配置slaves配置spark-default.conf配置所有节点的环境变量spark-evn.sh[root@node01 conf]# mv spark-env.sh.template spark-env.sh[root@node01 conf]# vi spark-env.sh加⼊export JAVA_HOME=/usr/local/jdk#export SCALA_HOME=/software/scala-2.11.8export HADOOP_HOME=/usr/local/hadoopexport HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop#Spark历史服务分配的内存尺⼨#export SPARK_DAEMON_MEMORY=512m#下⾯的这⼀项就是Spark的⾼可⽤配置,如果是配置master的⾼可⽤,master就必须有;如果是slave的⾼可⽤,slave就必须有;但是建议都配置。
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181 -Dspark.deploy.zookeeper.dir=/spark" #当启⽤了Spark的⾼可⽤之后,下⾯的这⼀项应该被注释掉(即不能再被启⽤,后⾯通过提交应⽤时使⽤--master参数指定⾼可⽤集群节点)#export SPARK_MASTER_IP=master01#export SPARK_WORKER_MEMORY=1500m#export SPARK_EXECUTOR_MEMORY=100m-Dspark.deploy.recoveryMode=ZOOKEEPER #说明整个集群状态是通过zookeeper来维护的,整个集群状态的恢复也是通过zookeeper来维护的。
spark本地开发环境搭建及打包配置在idea中新建⼯程删除新项⽬的src,创建moudle在⽗pom中添加spark和scala依赖,我们项⽬中⽤scala开发模型,建议scala,开发体验会更好(java、python也可以)<?xml version="1.0" encoding="UTF-8"?><project xmlns="/POM/4.0.0"xmlns:xsi="/2001/XMLSchema-instance"xsi:schemaLocation="/POM/4.0.0 /xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.shaozhiqi.bigdata</groupId><artifactId>spark-demo01</artifactId><packaging>pom</packaging><version>1.0-SNAPSHOT</version><modules><module>spark-core</module></modules><properties><piler.source>1.8</piler.source><piler.target>1.8</piler.target><scala.version>2.11.7</scala.version><spark.version>2.4.3</spark.version><encoding>UTF-8</encoding></properties><dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>${spark.version}</version></dependency></dependencies></project>在我们Moudle中配置打包插件<?xml version="1.0" encoding="UTF-8"?><project xmlns="/POM/4.0.0"xmlns:xsi="/2001/XMLSchema-instance"xsi:schemaLocation="/POM/4.0.0 /xsd/maven-4.0.0.xsd"><parent><artifactId>spark-demo01</artifactId><groupId>com.shaozhiqi.bigdata</groupId><version>1.0-SNAPSHOT</version></parent><modelVersion>4.0.0</modelVersion><artifactId>spark-core</artifactId><build><pluginManagement><plugins><!-- 编译scala的插件 --><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.2.2</version></plugin></plugins></pluginManagement><plugins><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><executions><execution><id>scala-compile-first</id><phase>process-resources</phase><goals><goal>add-source</goal><goal>compile</goal></goals></execution><execution><id>scala-test-compile</id><phase>process-test-resources</phase><goals><goal>testCompile</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><executions><execution><phase>compile</phase><goals><goal>compile</goal></goals></execution></executions></plugin><!-- 打包插件 --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.2.1</version><configuration><transformers><!-- add Main-Class to manifest file --><transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><!--you can add you want to need the main class--><!----><mainClass>com.shaozhiqi.bigdata.spark.WordCount</mainClass></transformer></transformers><createDependencyReducedPom>false</createDependencyReducedPom></configuration><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><filters><filter><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters></configuration></execution></executions></plugin></plugins></build></project>安装scala开发插件到idea安装后重启设置scalasdk,选我们新建的moudleimage.png新建scala对象编写代码:def main(args: Array[String]): Unit = {//1.创建配置信息val conf =new SparkConf().setAppName("wordcount").setMaster("local[*]")//2.创建sparkcontextval sc= new SparkContext(conf)//3.处理业务数据,我们统计每个单词的个数// 我们要在集群上尝试所以就将textFile的参数参数化,如果在本地执⾏则写本地的绝对路径 val lines=sc.textFile("G:\\temp\\input.txt")val words=lines.flatMap(_.split(" "))val keyMap=words.map((_, 1))val result =keyMap.reduceByKey(_+_)result.foreach(println)//4.关闭连接sc.stop()}本地调测试(1233,1)(llll,1)(hhh,1)(ddd,2)(55,2)(,1)(kkkk,1)(jjj,1)。
Spark开发环境搭建1.创建maven⼯程创建project--Java创建module--maven2.添加依赖<dependencies><!--spark依赖--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.3.0</version></dependency><!--scala依赖--><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>2.11.8</version></dependency><!--Hadoop 依赖--><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.3</version></dependency></dependencies>3.添加scala⽀持选择scala 2.11 版本4.编写spark代码--测试WordCountpackage com.sparkcoreimport org.apache.spark.{SparkConf, SparkContext}object WordCount {def main(args: Array[String]): Unit = {//第⼀步:创建sparkConfval conf = new SparkConf()//设置spark的运⾏模式:本地模式(⽤来测试),standalone(spark集群模式),yarn,Mesos,k8s //通常情况下:⽤本地模式测试(开发环境),⽤yarn部署(⽣产环境)//从spark2.3版本起⽀持k8s模式,未来spark程序⼤多会运⾏在k8s集群上//本地模式:local[x];x=1,代表启动⼀个线程,// X=2代表启动两个线程,x=* 代表启动跟所在机器cpu核数相等的线程数//注意:不能使⽤local[1],原因:spark本地模式是通过多线程来模拟分布式运⾏.setMaster("local[*]").setAppName("wordcount")//第⼆步:创建sparkContextval sc = new SparkContext(conf)//第三步:通过sparkcontext读取数据,⽣成rdd//4:尽可能与CPU核数对应val rdd=sc.textFile("d:\\test\\01.txt",4)//path:代表⽂件存储路径 minPartitions:最⼩分区数//分区是spark进⾏并⾏计算的基础println(rdd)//第四步:把rdd作为⼀个集合,进⾏各种运算rdd.map(line=>line.split(" ")).groupBy(x=>x).map(kv=>(kv._1,kv._2.size)).collect().foreach(println)}}总结:Application: 利⽤sparkApi进⾏的计算Submit:提交,把写好的spark应⽤提交给executor执⾏Executor:就是运⾏spark任务的机器的代称Jetty:web服务器(区别于tomcat,轻量级,可做嵌⼊式开发)DAG:有向⽆环图在计算机中图是⼀种数据结构:由边和顶点组成,其中边⽤来表⽰关系,顶点⽤来表⽰单位(数据)在spark中⽤DAG来表⽰计算任务。

Spark2.1.0完全分布式环境搭建1.选取三台服务器(CentOS系统64位) 114.55.246.88 主节点 114.55.246.77 从节点 114.55.246.93 从节点之后的操作如果是⽤普通⽤户操作的话也必须知道root⽤户的密码,因为有些操作是得⽤root⽤户操作。
如果是⽤root⽤户操作的话就不存在以上问题。
我是⽤root⽤户操作的。
2.修改hosts⽂件 修改三台服务器的hosts⽂件。
vi /etc/hosts 在原⽂件的基础最后⾯加上:114.55.246.88 Master114.55.246.77 Slave1114.55.246.93 Slave2 修改完成后保存执⾏如下命令。
source /etc/hosts3.ssh⽆密码验证配置 3.1安装和启动ssh协议 我们需要两个服务:ssh和rsync。
可以通过下⾯命令查看是否已经安装: rpm -qa|grep openssh rpm -qa|grep rsync 如果没有安装ssh和rsync,可以通过下⾯命令进⾏安装: yum install ssh (安装ssh协议) yum install rsync (rsync是⼀个远程数据同步⼯具,可通过LAN/WAN快速同步多台主机间的⽂件) service sshd restart (启动服务) 3.2 配置Master⽆密码登录所有Salve 配置Master节点,以下是在Master节点的配置操作。
1)在Master节点上⽣成密码对,在Master节点上执⾏以下命令: ssh-keygen -t rsa -P '' ⽣成的密钥对:id_rsa和id_rsa.pub,默认存储在"/root/.ssh"⽬录下。
2)接着在Master节点上做如下配置,把id_rsa.pub追加到授权的key⾥⾯去。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys 3)修改ssh配置⽂件"/etc/ssh/sshd_config"的下列内容,将以下内容的注释去掉: RSAAuthentication yes # 启⽤ RSA 认证 PubkeyAuthentication yes # 启⽤公钥私钥配对认证⽅式 AuthorizedKeysFile .ssh/authorized_keys # 公钥⽂件路径(和上⾯⽣成的⽂件同) 4)重启ssh服务,才能使刚才设置有效。
Spark平台搭建配置文档前言:为搭建Spark平台准备Hadoop集群。
虚拟化软件、实验虚拟机准备1. VMware Workstation 11注册码/key :1F04Z-6D111-7Z029-AV0Q4-3AEH8***便于向vShpere管理的esxi服务器上传在PC机中配置好虚拟机,便于把调试好的试验环境迁移到生产环境。
2.模版机安装OS:ubuntu-14.04.1-desktop-amd64.iso***在Ubuntu 中安装VMwareTools以便于在宿主机和虚拟机之间共享内存,可以互相拷贝文本和文件,这个功能很方便,具体参见《Linux虚拟机中手动安装或升级 VMware Tools》。
备注:lolo用户密码为loujianlou,这个安装时候设置,自定义。
(一)登陆和使用系统备注:以下用vim和gedit修改相应脚本文件均可,如果是命令行就用vim,如果是图形界面就用gedit。
1.进入root用户权限lolo@lolo-virtual-machine:~$sudo -sroot@lolo-virtual-machine:~# apt-get install vim2.修改lightdm.conf环境变量root@lolo-virtual-machine:~# vim /etc/lightdm/lightdm.conf[SeatDefaults]user-session=ubuntugreeter-session=unity-greeter备注:允许用户登陆并关闭guest用户:greeter-show-manual-login=trueallow-guest=false3.启动root账号root@lolo-virtual-machine:~# sudopasswd root设置密码:ljlroot@lolo-virtual-machine:~#gedit /root/.profile打开文件后找到“mesg n”,将其更改为“tty -s &&mesg n”在刚修改完root权限自动登录后,发现开机出现以下提示:Error found when loading /root/.profilestdin:is not a tty…………解决方法:在终端中用命令:root@lolo-virtual-machine:~#reboot –h now4.安装JDK:jdk-8u45-linux-x64.tar.gzroot@lolo-virtual-machine: ~# mkdir /usr/lib/javaroot@lolo-virtual-machine:~# mv /root/Downloads/jdk-8u45-linux-x64.tar.gz /usr/lib/java root@lolo-virtual-machine: ~# cd /usr/lib/javaroot@lolo-virtual-machine:/usr/lib/java# tar -xvf jdk-8u45-linux-x64.tar.gzroot@lolo-virtual-machine:~# vim ~/.bashrc“i”加入:export JAVA_HOME=/usr/lib/java/jdk1.8.0_45export JRE_HOME=${JAVA_HOME}/jreexport CLASS_PATH=.:${JAVA_HOME}/lib:${JRE_HOME}/libexport PATH=${JAVA_HOME}/bin:$PATH敲“esc” 键输入“:wq”保存退出。
Spark⼊门之环境搭建本教程是虚拟机搭建Spark环境和⽤idea编写脚本⼀、前提准备需要已经有搭建好的虚拟机环境,具体见教程需要已经安装了idea或着eclipse(教程以idea为例)⼆、环境搭建1、下载Spark安装包(我下载的 spark-3.0.1-bin-hadoop2.7.tgz)下载地址2、上传到虚拟机并解压(没备注就是主节点运⾏)tar -zxvf spark-3.0.1-bin-hadoop2.7.tgz3、修改权限chown -R hadoop /export/server/spark-3.0.1-bin-hadoop2.7chgrp -R hadoop /export/server/spark-3.0.1-bin-hadoop2.74、创建软连接ln -s /export/server/spark-3.0.1-bin-hadoop2.7 /export/server/spark5、启动spark交互式窗⼝/export/server/spark/bin/spark-shell还是很炫酷的哈哈哈,出现这个说明spark环境就搭建好了吗?漏6、配置Spark集群cd /export/server/spark/confmv slaves.template slavesvim slaves添加node02node03node047.配置mastercd /export/server/spark/confmv spark-env.sh.template spark-env.shvim spark-env.sh增加如下内容:## 设置JAVA安装⽬录JAVA_HOME=/linmob/install/jdk1.8.0_141## HADOOP软件配置⽂件⽬录,读取HDFS上⽂件和运⾏Spark在YARN集群时需要,先提前配上HADOOP_CONF_DIR=/linmob/install/hadoop-3.1.4/etc/hadoopYARN_CONF_DIR=/linmob/install/hadoop-3.1.4/etc/hadoop## 指定spark⽼⼤Master的IP和提交任务的通信端⼝#SPARK_MASTER_HOST=node01SPARK_MASTER_PORT=7077SPARK_MASTER_WEBUI_PORT=8080SPARK_WORKER_CORES=1SPARK_WORKER_MEMORY=1gSPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2## 配置spark历史⽇志存储地址SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node01:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"8、将配置好的将 Spark 安装包分发给集群中其它机器,命令如下:cd /export/server/scp -r spark-3.0.1-bin-hadoop2.7 hadoop@node02:$PWDscp -r spark-3.0.1-bin-hadoop2.7 hadoop@node03:$PWDscp -r spark-3.0.1-bin-hadoop2.7 hadoop@node04:$PWD9、创建软连接(每个节点都运⾏⼀遍)ln -s /export/server/spark-3.0.1-bin-hadoop2.7 /export/server/spark10、配置Yarn历史服务器并关闭资源检查vim /export/server/hadoop/etc/hadoop/yarn-site.xml少的部分补上<configuration><!-- 配置yarn主节点的位置 --><property><name>yarn.resourcemanager.hostname</name><value>node01</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 设置yarn集群的内存分配⽅案 --><property><name>yarn.nodemanager.resource.memory-mb</name><value>20480</value></property><property><name>yarn.scheduler.minimum-allocation-mb</name><value>2048</value></property><property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>2.1</value></property><!-- 开启⽇志聚合功能 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 设置聚合⽇志在hdfs上的保存时间 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property><!-- 设置yarn历史服务器地址 --><property><name>yarn.log.server.url</name><value>http://node1:19888/jobhistory/logs</value></property><!-- 关闭yarn内存检查 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property></configuration>注意:如果之前没有配置,现在配置了需要分发并重启yarn(重启需要每个节点都运⾏)cd /export/server/hadoop/etc/hadoopscp -r yarn-site.xml hadoop@node02:$PWDscp -r yarn-site.xml hadoop@node03:$PWDscp -r yarn-site.xml hadoop@node04:$PWD/export/server/hadoop/sbin/stop-yarn.sh/export/server/hadoop/sbin/start-yarn.sh11、配置Spark的历史服务器和Yarn的整合cd /export/server/spark/confmv spark-defaults.conf.template spark-defaults.confvim spark-defaults.conf添加spark.eventLog.enabled truespark.eventLog.dir hdfs://node01:8020/sparklog/press truespark.yarn.historyServer.address node01:18080⼿动创建hadoop fs -mkdir -p /sparklog12、修改⽇志级别cd /export/server/spark/confmv log4j.properties.template log4j.propertiesvim log4j.properties修改分发-可选,如果只在node1上提交spark任务到yarn,那么不需要分发cd /export/server/spark/confscp -r spark-env.sh hadoop@node02:$PWDscp -r spark-env.sh hadoop@node03:$PWDscp -r spark-env.sh hadoop@node04:$PWDscp -r spark-defaults.conf hadoop@node02:$PWDscp -r spark-defaults.conf hadoop@node03:$PWDscp -r spark-defaults.conf hadoop@node04:$PWDscp -r log4j.properties hadoop@node02:$PWDscp -r log4j.properties hadoop@node03:$PWDscp -r log4j.properties hadoop@node04:$PWD13、配置依赖的Spark的jar包hadoop fs -mkdir -p /spark/jars/hadoop fs -put /export/server/spark/jars/* /spark/jars/vim /export/server/spark/conf/spark-defaults.conf添加内容spark.yarn.jars hdfs://node1:8020/spark/jars/*分发同步-可选cd /export/server/spark/confscp -r spark-defaults.conf hadoop@node02:$PWD scp -r spark-defaults.conf hadoop@node03:$PWDscp -r spark-defaults.conf hadoop@node04:$PWD 14、启动服务- 启动HDFS和YARN服务,在主节点上启动spark集群/export/server/spark/sbin/start-all.sh-启动MRHistoryServer服务,在node01执⾏命令mr-jobhistory-daemon.sh start historyserver- 启动Spark HistoryServer服务,,在node01执⾏命令/export/server/spark/sbin/start-history-server.sh15、测试看下个博客三、总结:在主节点上启动spark集群/export/server/spark/sbin/start-all.sh在主节点上停⽌spark集群/export/server/spark/sbin/stop-all.shspark: 4040 任务运⾏web-ui界⾯端⼝spark: 8080 spark集群web-ui界⾯端⼝spark: 7077 spark提交任务时的通信端⼝hadoop: 50070集群web-ui界⾯端⼝hadoop:8020/9000(⽼版本) ⽂件上传下载通信端⼝。
Spark集群环境搭建——部署Spark集群在前⾯我们已经准备了三台服务器,并做好初始化,配置好jdk与免密登录等。
并且已经安装好了hadoop集群。
如果还没有配置好的,参考我前⾯两篇博客:Spark集群环境搭建——服务器环境初始化:Spark集群环境搭建——Hadoop集群环境搭建:集群规划:搭建Spark集群1、下载:官⽹地址:下载地址:cd /data/apps/shell/softwarewget https:///spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz --no-check-certificate2、解压安装:tar xf spark-3.1.2-bin-hadoop3.2.tgzmv spark-3.1.2-bin-hadoop3.2 /data/apps/spark-3.1.2编辑环境变量:vim /etc/profile## SPARK_HOMEexport SPARK_HOME=/data/apps/spark-3.1.2export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin加载使⽣效:source /etc/profile3、修改配置:进⼊conf⽬录:cd /data/apps/spark-3.1.2/confmv spark-defaults.conf.template spark-defaults.confmv spark-env.sh.template spark-env.shmv log4j.properties.template log4j.properties修改slaves⽂件,添加从机vim slavesdev-spark-master-206dev-spark-slave-171dev-spark-slave-172修改spark-defaults.confvim spark-defaults.confspark.master spark://dev-spark-master-206:7077spark.serializer org.apache.spark.serializer.KryoSerializerspark.driver.memory 1g修改spark-env.shvim spark-env.shexport JAVA_HOME=/usr/java/jdk1.8.0_162export HADOOP_HOME=/data/apps/hadoop-3.2.2/export HADOOP_CONF_DIR=/data/apps/hadoop-3.2.2/etc/hadoopexport SPARK_DIST_CLASSPATH=$(/data/apps/hadoop-3.2.2/bin/hadoop classpath)export SPARK_MASTER_HOST=dev-spark-master-206export SPARK_MASTER_PORT=70774、解决与Hadoop冲突这⾥要注意,备注:在$HADOOP_HOME/sbin 及 $SPARK_HOME/sbin 下都有 start-all.sh 和 stop-all.sh ⽂件,如果同时加载到环境变量,会有冲突,我们选择改掉其中⼀个:在输⼊ start-all.sh / stop-all.sh 命令时,谁的搜索路径在前⾯就先执⾏谁,此时会产⽣冲突。
Spark-Bench运行环境搭建
按照官方文档进行第3.1步系统环境配置的时候会出现几个错误,在这里一一解决
1、首先是wikixmlj的编译和安装问题,这个wikixmlj工程经过maven编译(即直接执行
mvn package命令,我觉得-Dmaven.test.skip=true应该是不需要的)后会在其target 目录下生产一个wikixmlj-1.0-SNAPSHOT.jar文件,接下来执行mvn install命令去安装这个jar包时就会报错。
所以我通过以下命令手动安装jar的方式在maven的本地仓库中安装wikixmlj-1.0-SNAPSHOT.jar:
mvn install:install-file -DgroupId=edu.jhu.nlp -DartifactId=wikixmlj
-Dversion=1.0-SNAPSHOT -Dpackaging=jar -Dfile=.\classes\artifacts\wikixmlj_.jar\wikixmlj.jar
注:因为在后面编译SparkBench工程中,需要依赖wikixmlj-1.0-SNAPSHOT.jar,所以必须在maven仓库中先安装这个jar包。
而这个jar在网上是下载不到的,所以我只能把它github上的源码工程clone下来,然后再用idea编译,然后再打包jar包
2、第一步搞定后,在编译整个SparkBench工程(即直接在工程根目录执行./build-all.sh
命令)时也会出错,首先是在编译第一个子工程Common工程时出现问题:
其实这个问题是由于你的Spark-Bench工程是由jdk-1.8.0编译,而现在你本地只有jdk-1.7.0,所以就报了这个错,我通过将父工程的pom.xml文件中的jdk编译原版本和目标版本版本全部由1.8换成1.7后,这个问题得以解决。
3、jdk版本的问题解决后,还有一个问题,就是在编译KmeanApp这个子工程时会出现一
个语法错误,在Kmeans.src.main.java.KmeansAppJava.java文件中:
在内部类中只能使用final关键字修饰的外部变量,所以这个的clusters需要声明为final
类型。
总结:至此在搭建SparkBench运行环境的所有问题都得到了解决,所以接下来需要再重新执行./build-all.sh命令即可。
就会出现:
此时会在各个子工程的target目录下出现相应的打包好的子工程jar包。
SparkBench 的运行环境就搭建完毕了。