二分图匹配――匈牙利算法和KM算法简介.
- 格式:ppt
- 大小:421.50 KB
- 文档页数:29

二分图的最大匹配、完美匹配和匈牙利算法August 1, 2013 / 算法这篇文章讲无权二分图(unweighted bipartite graph)的最大匹配(maximum matching)和完美匹配(perfect matching),以及用于求解匹配的匈牙利算法(Hungarian Algorithm);不讲带权二分图的最佳匹配。
二分图:简单来说,如果图中点可以被分为两组,并且使得所有边都跨越组的边界,则这就是一个二分图。
准确地说:把一个图的顶点划分为两个不相交集U和V,使得每一条边都分别连接U、V中的顶点。
如果存在这样的划分,则此图为一个二分图。
二分图的一个等价定义是:不含有「含奇数条边的环」的图。
图 1 是一个二分图。
为了清晰,我们以后都把它画成图 2 的形式。
匹配:在图论中,一个「匹配」(matching)是一个边的集合,其中任意两条边都没有公共顶点。
例如,图3、图 4 中红色的边就是图 2 的匹配。
我们定义匹配点、匹配边、未匹配点、非匹配边,它们的含义非常显然。
例如图 3 中 1、4、5、7 为匹配点,其他顶点为未匹配点;1-5、4-7为匹配边,其他边为非匹配边。
最大匹配:一个图所有匹配中,所含匹配边数最多的匹配,称为这个图的最大匹配。
图 4 是一个最大匹配,它包含 4 条匹配边。
完美匹配:如果一个图的某个匹配中,所有的顶点都是匹配点,那么它就是一个完美匹配。
图 4 是一个完美匹配。
显然,完美匹配一定是最大匹配(完美匹配的任何一个点都已经匹配,添加一条新的匹配边一定会与已有的匹配边冲突)。
但并非每个图都存在完美匹配。
举例来说:如下图所示,如果在某一对男孩和女孩之间存在相连的边,就意味着他们彼此喜欢。
是否可能让所有男孩和女孩两两配对,使得每对儿都互相喜欢呢?图论中,这就是完美匹配问题。
如果换一个说法:最多有多少互相喜欢的男孩/女孩可以配对儿?这就是最大匹配问题。
基本概念讲完了。

二分图的最大匹配完美匹配和匈牙利算法匈牙利算法是由匈牙利数学家Edmonds于1965年提出,因而得名。
匈牙利算法是基于Hall定理中充分性证明的思想,它是二部图匹配最常见的算法,该算法的核心就是寻找增广路径,它是一种用增广路径求二分图最大匹配的算法。
这篇文章讲无权二分图(unweighted bipartite graph)的最大匹配(maximum matching)和完美匹配(perfect matching),以及用于求解匹配的匈牙利算法(Hungarian Algorithm);不讲带权二分图的最佳匹配。
二分图:简单来说,如果图中点可以被分为两组,并且使得所有边都跨越组的边界,则这就是一个二分图。
准确地说:把一个图的顶点划分为两个不相交集U 和V ,使得每一条边都分别连接U、V 中的顶点。
如果存在这样的划分,则此图为一个二分图。
二分图的一个等价定义是:不含有「含奇数条边的环」的图。
图 1 是一个二分图。
为了清晰,我们以后都把它画成图 2 的形式。
匹配:在图论中,一个「匹配」(matching)是一个边的集合,其中任意两条边都没有公共顶点。
例如,图3、图4 中红色的边就是图 2 的匹配。
我们定义匹配点、匹配边、未匹配点、非匹配边,它们的含义非常显然。
例如图 3 中1、4、5、7 为匹配点,其他顶点为未匹配点;1-5、4-7为匹配边,其他边为非匹配边。
最大匹配:一个图所有匹配中,所含匹配边数最多的匹配,称为这个图的最大匹配。
图 4 是一个最大匹配,它包含4 条匹配边。
完美匹配:如果一个图的某个匹配中,所有的顶点都是匹配点,那么它就是一个完美匹配。
图 4 是一个完美匹配。
显然,完美匹配一定是最大匹配(完美匹配的任何一个点都已经匹配,添加一条新的匹配边一定会与已有的匹配边冲突)。
但并非每个图都存在完美匹配。
举例来说:如下图所示,如果在某一对男孩和女孩之间存在相连的边,就意味着他们彼此喜欢。
是否可能让所有男孩和女孩两两配对,使得每对儿都互相喜欢呢?图论中,这就是完美匹配问题。



数学建模匈牙利算法数学建模是一门重要的学科,它将数学方法应用于实际问题的解决。
匈牙利算法是一种经典的组合优化算法,常用于解决二分图最大匹配问题。
下面将介绍匈牙利算法的原理和应用,并探讨其在数学建模中的重要性。
匈牙利算法是二分图匹配问题的经典算法之一,它可用于解决寻找最大匹配的问题。
二分图是指一个图的顶点可以分为两个不相交的集合,并且图中的每条边都连接一对不同集合中的顶点。
在匈牙利算法中,我们需要找到一个最大的匹配,即找到尽可能多的边,使得这些边两端的顶点都不是同一个顶点的匹配。
匈牙利算法的基本思路是通过不断增加匹配的大小来找到最大匹配。
算法不断尝试将未匹配的顶点与相邻的未匹配的顶点相连,直到无法再增加匹配为止。
其核心思想是通过交替路径来增加匹配的大小,直到找到一个最大匹配。
具体来说,匈牙利算法的实现主要包括以下几个步骤:1. 初始化:将所有的匹配边置为0,标记顶点为未访问状态。
2. 从未匹配的左侧顶点开始,尝试匹配:对于每个未匹配的左侧顶点,开始一次深度优先搜索,尝试将其与相邻的未匹配的右侧顶点进行匹配。
如果找到一条匹配路径,则将路径上的所有边都进行匹配。
3. 如果存在未匹配的左侧顶点,则继续查找增广路径;否则算法结束,匹配完成。
匈牙利算法的时间复杂度为O(n^3),其中n为顶点数。
虽然在理论上其时间复杂度较高,但在实际应用中,匈牙利算法通常能够在较短的时间内找到最大匹配。
在数学建模中,匈牙利算法常被应用于解决资源分配、作业调度、人员安排等问题。
在作业调度中,我们需要找到最优的作业分配方案,以最大化效率或最小化成本。
匈牙利算法可以帮助我们找到最优的作业调度方案,从而有效地利用资源和提高效率。
匈牙利算法是一种重要的组合优化算法,常用于解决二分图最大匹配等问题。
在数学建模中,它可以帮助我们解决各种资源分配和调度问题,提高效率和降低成本。
深入理解和掌握匈牙利算法对于数学建模领域具有重要意义。

⼆分图匹配--匈⽛利算法⼆分图匹配--匈⽛利算法⼆分图匹配匈⽛利算法基本定义:⼆分图 —— 对于⽆向图G=(V,E),如果存在⼀个划分使V中的顶点分为两个互不相交的⼦集,且每个⼦集中任意两点间不存在边 ϵ∈E,则称图G为⼀个⼆分图。
⼆分图的充要条件是,G⾄少有两个顶点,且所有回路长度为偶数。
匹配 —— 边的集合,其中任意两条边都不存在公共顶点。
匹配边即是匹配中的元素,匹配点是匹配边的顶点,同样⾮匹配边,⾮匹配点相反定义。
最⼤匹配——在图的所有匹配中,包含最多边的匹配成为最⼤匹配 完美匹配——如果在⼀个匹配中所有的点都是匹配点,那么该匹配称为完美匹配。
附注:所有的完美匹配都是最⼤匹配,最⼤匹配不⼀定是完美匹配。
假设完美匹配不是最⼤匹配,那么最⼤匹配⼀定存在不属于完美匹配中的边,⽽图的所有顶点都在完美匹配中,不可能找到更多的边,所以假设不成⽴,及完美匹配⼀定是最⼤匹配。
交替路——从⼀个未匹配点出发,依次经过⾮匹配边,匹配边,⾮匹配边…形成的路径称为交替路,交替路不会形成环。
增⼴路——起点和终点都是未匹配点的交替路。
因为交替路是⾮匹配边、匹配边交替出现的,⽽增⼴路两端节点都是⾮匹配点,所以增⼴路⼀定有奇数条边。
⽽且增⼴路中的节点(除去两端节点)都是匹配点,所属的匹配边都在增⼴路径上,没有其他相连的匹配边,因此如果把增⼴路径中的匹配边和⾮匹配边的“⾝份”交换,就可以获得⼀个更⼤的匹配(该过程称为改进匹配)。
⽰例图Fig1_09_09.JPG注释:Fig3是⼀个⼆分图G=(V,E),V={1,2,3,4,5,6,7,8},E={(1,7),(1,5),(2,6),(3,5),(3,8),(4,5),(4,6)},该图可以重绘成Fig4,V可分成两个⼦集V={V1,V2},V1={1,2,3,4},V2={5,6,7,8}。
Fig4中的红⾊边集合就是⼀个匹配{(1,5),(4,6),(3,8)}Fig2中是最⼤匹配Fig1中红⾊边集合是完美匹配Fig1中交替路举例(4-6-2-7-1-5)Fig4中增⼴路(2-6-4-5-1-7)匈⽛利树匈⽛利树中从根节点到叶节点的路径均是交替路,且匈⽛利树的叶节点都是匹配点。

⼆分图的最⼤匹配—匈⽛利算法【基本概念】:⼆分图:⼆分图⼆分图⼜称作⼆部图,是图论中的⼀种特殊模型。
设G=(V,E)是⼀个⽆向图,如果顶点V可分割为两个互不相交的⼦集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G为⼀个⼆分图。
⽆向图G为⼆分图的充分必要条件是,G⾄少有两个顶点,且其所有回路的长度均为偶数。
最⼤匹配最⼤匹配:给定⼀个⼆分图G,在G的⼀个⼦图M中,M的边集中的任意两条边都不依附于同⼀个顶点,则称M是⼀个匹配. 选择这样的边数最⼤的⼦集称为图的最⼤匹配问题,如果⼀个匹配中,图中的每个顶点都和图中某条边相关联,则称此匹配为完全匹配,也称作完备匹配.最⼩覆盖:最⼩覆盖要求⽤最少的点(X集合或Y集合的都⾏)让每条边都⾄少和其中⼀个点关联。
可以证明:最少的点(即覆盖数)=最⼤匹配数最⼩路径覆盖:⽤尽量少的不相交简单路径覆盖有向⽆环图G的所有结点。
解决此类问题可以建⽴⼀个⼆分图模型。
把所有顶点i拆成两个:X结点集中的i 和Y结点集中的i',如果有边i->j,则在⼆分图中引⼊边i->j',设⼆分图最⼤匹配为m,则结果就是n-m。
增⼴路(增⼴轨):(增⼴轨):增⼴路若P是图G中⼀条连通两个未匹配顶点的路径,并且属于M的边和不属于M的边(即已匹配和待匹配的边)在P上交替出现,则称P为相对于M的⼀条增⼴路径(举例来说,有A、B集合,增⼴路由A中⼀个点通向B中⼀个点,再由B中这个点通向A中⼀个点……交替进⾏)。
增⼴路径的性质:1 有奇数条边。
2 起点在⼆分图的左半边,终点在右半边。
3 路径上的点⼀定是⼀个在左半边,⼀个在右半边,交替出现。
(其实⼆分图的性质就决定了这⼀点,因为⼆分图同⼀边的点之间没有边相连,不要忘记哦。
)4 整条路径上没有重复的点。
5 起点和终点都是⽬前还没有配对的点,⽽其它所有点都是已经配好对的。

二分图的最优匹配(KM算法)KM算法用来解决最大权匹配问题:在一个二分图内,左顶点为X,右顶点为Y,现对于每组左右连接XiYj有权wij,求一种匹配使得所有wij的和最大。
基本原理该算法是通过给每个顶点一个标号(叫做顶标)来把求最大权匹配的问题转化为求完备匹配的问题的。
设顶点Xi的顶标为A[ i ],顶点Yj的顶标为B[ j ],顶点Xi与Yj之间的边权为w[i,j]。
在算法执行过程中的任一时刻,对于任一条边(i,j),A[ i ]+B[j]>=w[i,j]始终成立。
KM算法的正确性基于以下定理:若由二分图中所有满足A[ i ]+B[j]=w[i,j]的边(i,j)构成的子图(称做相等子图)有完备匹配,那么这个完备匹配就是二分图的最大权匹配。
首先解释下什么是完备匹配,所谓的完备匹配就是在二部图中,X点集中的所有点都有对应的匹配或者是Y点集中所有的点都有对应的匹配,则称该匹配为完备匹配。
这个定理是显然的。
因为对于二分图的任意一个匹配,如果它包含于相等子图,那么它的边权和等于所有顶点的顶标和;如果它有的边不包含于相等子图,那么它的边权和小于所有顶点的顶标和。
所以相等子图的完备匹配一定是二分图的最大权匹配。
初始时为了使A[ i ]+B[j]>=w[i,j]恒成立,令A[ i ]为所有与顶点Xi关联的边的最大权,B[j]=0。
如果当前的相等子图没有完备匹配,就按下面的方法修改顶标以使扩大相等子图,直到相等子图具有完备匹配为止。
我们求当前相等子图的完备匹配失败了,是因为对于某个X顶点,我们找不到一条从它出发的交错路。
这时我们获得了一棵交错树,它的叶子结点全部是X顶点。
现在我们把交错树中X顶点的顶标全都减小某个值d,Y顶点的顶标全都增加同一个值d,那么我们会发现:1)两端都在交错树中的边(i,j),A[ i ]+B[j]的值没有变化。
也就是说,它原来属于相等子图,现在仍属于相等子图。
2)两端都不在交错树中的边(i,j),A[ i ]和B[j]都没有变化。


二分图如果是没有权值的,求最大匹配。
则是用匈牙利算法求最大匹配。
如果带了权值,求最大或者最小权匹配,则必须用KM算法。
其实最大和最小权匹配都是一样的问题。
只要会求最大匹配,如果要求最小权匹配,则将权值取相反数,再把结果取相反数,那么最小权匹配就求出来了。
KM算法及其难理解。
看了几天还无头绪。
先拿上一直采用的KM算法模板,按照吉林大学的模板写的。
试试了好多次感觉都没有出错。
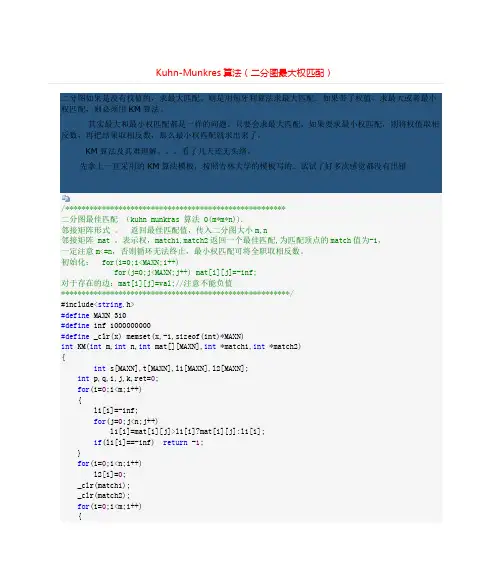
/******************************************************二分图最佳匹配(kuhn munkras 算法O(m*m*n)).邻接矩阵形式。
返回最佳匹配值,传入二分图大小m,n邻接矩阵mat ,表示权,match1,match2返回一个最佳匹配,为匹配顶点的match 值为-1,一定注意m<=n,否则循环无法终止,最小权匹配可将全职取相反数。
初始化:for(i=0;i<MAXN;i++)for(j=0;j<MAXN;j++) mat[i][j]=-inf;对于存在的边:mat[i][j]=val;//注意不能负值********************************************************/#include<string.h>#define MAXN 310#define inf 1000000000#define _clr(x) memset(x,-1,sizeof(int)*MAXN)int KM(int m,int n,int mat[][MAXN],int *match1,int *match2){int s[MAXN],t[MAXN],l1[MAXN],l2[MAXN];int p,q,i,j,k,ret=0;for(i=0;i<m;i++){l1[i]=-inf;for(j=0;j<n;j++)l1[i]=mat[i][j]>l1[i]?mat[i][j]:l1[i];if(l1[i]==-inf) return -1;}for(i=0;i<n;i++)l2[i]=0;_clr(match1);_clr(match2);for(i=0;i<m;i++){_clr(t);p=0;q=0;for(s[0]=i;p<=q&&match1[i]<0;p++){for(k=s[p],j=0;j<n&&match1[i]<0;j++){if(l1[k]+l2[j]==mat[k][j]&&t[j]<0){s[++q]=match2[j];t[j]=k;if(s[q]<0){for(p=j;p>=0;j=p){match2[j]=k=t[j];p=match1[k];match1[k]=j;}}}}}if(match1[i]<0){i--;p=inf;for(k=0;k<=q;k++){for(j=0;j<n;j++){if(t[j]<0&&l1[s[k]]+l2[j]-mat[s[k]][j]<p)p=l1[s[k]]+l2[j]-mat[s[k]][j];}}for(j=0;j<n;j++)l2[j]+=t[j]<0?0:p;for(k=0;k<=q;k++)l1[s[k]]-=p;}}for(i=0;i<m;i++)ret+=mat[i][match1[i]];return ret;}下面是从网上的博客摘抄的一些零散的总结。
二分图如果是没有权值的,求最大匹配。
则是用匈牙利算法求最大匹配。
如果带了权值,求最大或者最小权匹配,则必须用KM算法。
其实最大和最小权匹配都是一样的问题。
只要会求最大匹配,如果要求最小权匹配,则将权值取相反数,再把结果取相反数,那么最小权匹配就求出来了。
KM算法及其难理解。
看了几天还无头绪。
先拿上一直采用的KM算法模板,按照吉林大学的模板写的。
试试了好多次感觉都没有出错。
/******************************************************二分图最佳匹配(kuhn munkras 算法 O(m*m*n)).邻接矩阵形式。
返回最佳匹配值,传入二分图大小m,n邻接矩阵 mat ,表示权,match1,match2返回一个最佳匹配,为匹配顶点的match值为-1,一定注意m<=n,否则循环无法终止,最小权匹配可将全职取相反数。
初始化: for(i=0;i<MAXN;i++)for(j=0;j<MAXN;j++) mat[i][j]=-inf;对于存在的边:mat[i][j]=val;//注意不能负值********************************************************/#include<string.h>#define MAXN 310#define inf 1000000000#define _clr(x) memset(x,-1,sizeof(int)*MAXN)int KM(int m,int n,int mat[][MAXN],int *match1,int *match2){int s[MAXN],t[MAXN],l1[MAXN],l2[MAXN];int p,q,i,j,k,ret=0;for(i=0;i<m;i++){l1[i]=-inf;for(j=0;j<n;j++)l1[i]=mat[i][j]>l1[i]?mat[i][j]:l1[i];if(l1[i]==-inf) return -1;}for(i=0;i<n;i++)l2[i]=0;_clr(match1);_clr(match2);for(i=0;i<m;i++){_clr(t);p=0;q=0;for(s[0]=i;p<=q&&match1[i]<0;p++){for(k=s[p],j=0;j<n&&match1[i]<0;j++){if(l1[k]+l2[j]==mat[k][j]&&t[j]<0){s[++q]=match2[j];t[j]=k;if(s[q]<0){for(p=j;p>=0;j=p){match2[j]=k=t[j];p=match1[k];match1[k]=j;}}}}}if(match1[i]<0){i--;p=inf;for(k=0;k<=q;k++){for(j=0;j<n;j++){if(t[j]<0&&l1[s[k]]+l2[j]-mat[s[k]][j]<p) p=l1[s[k]]+l2[j]-mat[s[k]][j];}}for(j=0;j<n;j++)l2[j]+=t[j]<0?0:p;for(k=0;k<=q;k++)l1[s[k]]-=p;}}for(i=0;i<m;i++)ret+=mat[i][match1[i]];return ret;}下面是从网上的博客摘抄的一些零散的总结。
匈牙利算法详解
匈牙利算法是一种解决二分图最大匹配问题的经典算法,也叫做增广路算法。
它的基本思想是从左侧一端开始,依次匹配左侧点,直到无法添加匹配为止。
在匹配过程中,每次都通过BFS 寻找增广路径,即可以让已有的匹配变得更优或添加新的匹配。
增广路的长度必须为奇数,因为必须从未匹配的左侧点开始,交替经过已匹配的右侧点和未匹配的左侧点,最后再到达未匹配的右侧点。
当没有找到增广路径时,匹配结束。
匈牙利算法的具体实现可以使用DFS 或BFS,这里以BFS 为例。
算法步骤如下:
1. 从左侧一个未匹配的点开始,依次找增广路径。
如果找到,就将路径上的匹配状态翻转(即已匹配变未匹配,未匹配变已匹配),并继续找增广路径;如果找不到,就说明已经完成匹配。
2. 使用BFS 寻找增广路径。
从左侧的某个未匹配点开始,依次搜索路径中未匹配的右侧点。
如果找到右侧未匹配点,则说明找到了增广路径;否则,将已搜过的左侧点打上标记,以免重复搜索。
如果找到增广路径,就将路径的左侧和右侧点的匹配状态翻转。
3. 重复步骤1 和2,直到找不到增广路径为止。
匈牙利算法的时间复杂度为O(VE),其中V 和E 分别为二分图中的左侧点数和右侧点数。
实际运行效率很高,可以处理百万级别的数据。
匈⽛利算法(⼆分图)---------------------------------------------------------------------题材⼤多来⾃⽹络,本篇由神犇整理基本概念—⼆分图⼆分图:是图论中的⼀种特殊模型。
若能将⽆向图G=(V,E)的顶点V划分为两个交集为空的顶点集,并且任意边的两个端点都分属于两个集合,则称图G为⼀个为⼆分图。
匹配:⼀个匹配即⼀个包含若⼲条边的集合,且其中任意两条边没有公共端点。
如下图,图3的红边即为图2的⼀个匹配。
1 最⼤匹配在G的⼀个⼦图M中,M的边集中的任意两条边都不依附于同⼀个顶点,则称M是⼀个匹配。
选择这样的边数最⼤的⼦集称为图的最⼤匹配问题,最⼤匹配的边数称为最⼤匹配数.如果⼀个匹配中,图中的每个顶点都和图中某条边相关联,则称此匹配为完全匹配,也称作完备匹配。
如果在左右两边加上源汇点后,图G等价于⼀个⽹络流,最⼤匹配问题可以转为最⼤流的问题。
解决此问的匈⽛利算法的本质就是寻找最⼤流的增⼴路径。
上图中的最⼤匹配如下图红边所⽰:2 最优匹配最优匹配⼜称为带权最⼤匹配,是指在带有权值边的⼆分图中,求⼀个匹配使得匹配边上的权值和最⼤。
⼀般X和Y集合顶点个数相同,最优匹配也是⼀个完备匹配,即每个顶点都被匹配。
如果个数不相等,可以通过补点加0边实现转化。
⼀般使⽤KM算法解决该问题。
3 最⼩覆盖⼆分图的最⼩覆盖分为最⼩顶点覆盖和最⼩路径覆盖:①最⼩顶点覆盖是指最少的顶点数使得⼆分图G中的每条边都⾄少与其中⼀个点相关联,⼆分图的最⼩顶点覆盖数=⼆分图的最⼤匹配数;②最⼩路径覆盖也称为最⼩边覆盖,是指⽤尽量少的不相交简单路径覆盖⼆分图中的所有顶点。
⼆分图的最⼩路径覆盖数=|V|-⼆分图的最⼤匹配数;4 最⼤独⽴集最⼤独⽴集是指寻找⼀个点集,使得其中任意两点在图中⽆对应边。
对于⼀般图来说,最⼤独⽴集是⼀个NP完全问题,对于⼆分图来说最⼤独⽴集=|V|-⼆分图的最⼤匹配数。
km(kuhn-munkres)算法的具体表达KM算法,即Kuhn-Munkres算法(又称为匈牙利算法),是一种用于求解二分图最大权匹配问题的经典算法。
它由Eugene L. Lawler于1960年首次提出,后来由James Munkres在1957年独立发表,因此常称为Kuhn-Munkres算法。
二分图最大权匹配问题是指给定一个带权二分图,要求在图中选取权重之和最大的边集合,使得任意两条边不属于同一个顶点。
其中,带权二分图是指图的每条边都带有一个非负权重。
KM算法使用了两个关键的概念:交错树和相等子图。
交错树是指一个T=(S,P)的有向树,其中S是原二分图的所有顶点的集合,P是树中的边集合。
相等子图是指原二分图的一个子图,其中T中所有入树边的权重之和等于所有出树边的权重之和。
KM算法具体的步骤如下:1.初始化:将图中所有边的权重初始化为0,构建了一个初始的交错树T=(X,Y)(其中X,Y分别表示两个顶点集合)。
2.判断相等子图:对于T中的每个顶点x,如果存在一条满足lx+ly=W(其中lx是x在T中所有入树边的权重之和,ly是x在T中所有出树边的权重之和,W是x在原图G中的权重),则把x加入到相等子图中。
3.寻找未匹配节点:在相等子图中寻找未匹配节点,并标记为未父节点。
4.寻找增广路:如果存在未匹配节点,则从中选择一个起始节点,寻找一条与之交替出现的边构成的路径,使路径的最后一个边是一条与未匹配节点关联的边。
这样的路径称为增广路。
5.修改标号:对于相等子图中的每个顶点x,从已匹配节点中选择一个与之关联的顶点y,并计算d=min(lx+ly-w)(其中w是x和y之间的边的权重),为了使增广路更优,将T中所有x节点的入树边的权重减去d,将T中所有y节点的出树边的权重加上d。
6.更新交错树:将增广路中的所有边和T中的所有非树边进行调整,得到新的交错树。
7.重复步骤3-6,直到没有未匹配节点为止。
⼆分图匹配之最佳匹配——KM算法今天也⼤致学了下KM算法,⽤于求⼆分图匹配的最佳匹配。
何为最佳?我们能⽤匈⽛利算法对⼆分图进⾏最⼤匹配,但匹配的⽅式不唯⼀,如果我们假设每条边有权值,那么⼀定会存在⼀个最⼤权值的匹配情况,但对于KM算法的话这个情况有点特殊,这个匹配情况是要在完全匹配(就是各个点都能⼀⼀对应另⼀个点)情况下的前提。
⾃然,KM算法跟匈⽛利算法有相似之处。
其算法步骤如下:1.⽤邻接矩阵(或其他⽅法也⾏啦)来储存图,注意:如果只是想求最⼤权值匹配⽽不要求是完全匹配的话,请把各个不相连的边的权值设置为0。
2.运⽤贪⼼算法初始化标杆。
3.运⽤匈⽛利算法找到完备匹配。
4.如果找不到,则通过修改标杆,增加⼀些边。
5.重复3,4的步骤,直到完全匹配时可结束。
⼀⾔不合地冒出了个标杆??标杆是什么???在解释这个问题之前,我们先来假设⼀个很简单的情况,⽤我们⼈类伟⼤的智能思维去思考思考。
如上的⼀个⼆分图,我们要求它的最⼤权值匹配(最佳匹配)我们可以思索思索⼆分图最佳匹配还是⼆分图匹配,所以跟和匈⽛利算法思路差不多⼆分图是特殊的⽹络流,最佳匹配相当于求最⼤(⼩)费⽤最⼤流,所以FF⽅法也能实现所以我们可以把这匈⽛利算法和FF⽅法结合起来FF⽅法⾥⾯,我们每次是找最长(短)路进⾏通流所以⼆分图匹配⾥⾯我们也找最⼤边进⾏连边!但是遇到某个点被匹配了两次怎么办?那就⽤匈⽛利算法进⾏更改匹配!这就是KM算法的思路了:尽量找最⼤的边进⾏连边,如果不能则换⼀条较⼤的。
所以,根据KM算法的思路,我们⼀开始要对边权值最⼤的进⾏连线,那问题就来了,我们如何让计算机知道该点对应的权值最⼤的边是哪⼀条?或许我们可以通过某种⽅式记录边的另⼀端点,但是呢,后⾯还要涉及改边,⼜要记录边权值总和,⽽这个记录端点⽅法似乎有点⿇烦,于是KM采⽤了⼀种⼗分巧妙的办法(也是KM算法思想的精髓):添加标杆(顶标)是怎样⼦呢?我们对左边每个点Xi和右边每个点Yi添加标杆Cx和Cy。
二分图最大权匹配 KM算法KM算法的正确性基于以下定理:若由二分图中所有满足A[i]+B[i]=w[i][j]的边C(i,j)构成的子图(即相等子图)有完备匹配,那么这个完备匹配就是二分图的最大权匹配基本概念1.完备匹配设G=V1,V2,E为二分图,|V1|=|V2|,M为G中的一个最大匹配,且|M|=V1,则称M为V1到V2的完备匹配。
通俗的理解,就是把V1中所有的点都匹配完2.可行顶标对于左边的点设为LX[maxn]数组,右边的点设为LY[maxn]数组,w[i][j]表示 v[i] 到 v[j] 的权值3.相等子图相等子图为完备匹配中所有的匹配,即全部V1中的点和与V1中的点匹配的V2中的点,但是边只包含 LX[i]+LY[j]=W[i][j]的边4.最优完备匹配最优完备匹配就是在完备匹配的条件下求解权值最大或者最小,若由二分图中所有满足A[i]+B[i]=W[i][j]的边C(i,j)构成的相等子图有完备匹配,那么这个完备匹配就是二分图的最大权匹配因为对于二分图的任意一个匹配,如果它包含相等子图,那么它的边权和等于所有顶点的顶标和;如果它有边不包含于相等子图,那么它的边权和小于所有顶点的顶标和,所以相等子图的完备匹配,一定是二分图的最大权匹配。
5.交错树对V1中的一个顶点进行匹配的时候,所标记过的V1,V2中的点以及连线,形成一个树状的图KM算法原理1.基本原理该算法是通过给每个顶点一个标号(叫做顶标)来把求最大权匹配的问题转化为求完备匹配的问题。
设顶点V1的顶标lx[i],V2顶点的顶标为LY[j],顶点V1的i与V2的j之间的边权为V(i,j)。
在算法执行的过程中,对于任一条边C(i,j),LX[i]+LY[i]=V[i,j]始终成立2.基本流程(1)初始化时为了使 LX[i] + LY[j] = V [i,j]恒成立,将V1的点的标号记为与其相连的最大边权值,V2的点标号记为0 (2)用匈牙利算法在相等子图寻找完备匹配(3)若未找到完备匹配,则修改可行顶标的值,扩充相等子图(4)重复(2)(3)直到找到相等子图的完备匹配为止3.这里值得注意的是找完备匹配不难理解,主要是进行可行顶标的修改扩充相等子图朴素的实现方法:时间复杂度为O(n4)——需要找O(n)次增广路,每次增广最多需要修改O(n)次顶标,每次修改顶标时由于要枚举边来求d值,复杂度为O(n2)。