第4章 统计数据的分布特征(集中趋势度量法) 应用统计学
- 格式:ppt
- 大小:183.00 KB
- 文档页数:20

统计学(第六版)期末考试考点梳理统计学(第六版)期末考试考点梳理第⼀章导论1.1.1 什么是统计学统计学是收集、处理、分析、解释数据并从数据中得出结论的科学。
数据分析所⽤的⽅法分为描述统计⽅法和推断统计⽅法。
1.2 统计数据的类型1.2.1 分类数据、顺序数据、数值型数据按照所采⽤的计算尺度不同,可以将统计数据分为分类数据、顺序数据、数值型数据。
分类数据:只能归于某⼀类别的⾮数字型数据,它是对事物进⾏分类的结果,数据表现为类别,是⽤⽂字来表⽰。
例如:⽀付⽅式、性别、企业类型等。
顺序数据:只能归于某⼀有序类别的⾮数字型数据。
例如:员⼯对改⾰措施的态度、产品等级、受教育程度等。
数值型数据:按数字尺度测量的观测值,其结果表现为具体的数值。
例如:年龄、⼯资、产量等。
统计数据⼤体上可分为品质数据(定性数据)和数量数据(定量数据、数值型数据)。
1.2.2 观测数据和实验数据按照统计数据的收集⽅法,可以分为观测数据和实验数据。
观测数据:通过调查或观测⽽收集的数据。
例如:降⾬量、GDP、家庭收⼊等。
实验数据:在实验中控制实验对象⽽收集到的数据。
例如:医药实验数据、化学实验数据等。
1.2.3 截⾯数据和时间序列数据按照被描述的现象与时间的关系,可分类截⾯数据和时间序列数据。
截⾯数据:在相同或近似相同的时间点上收集的数据。
例如:2012年我国各省市的GDP。
时间序列数据:同⼀现象在不同的时间收集的数据。
例如:2000-2012年湖北省的GDP。
1.3.1 总体和样本总体:包含所研究的全部个体(数据)的集合。
样本:从总体中抽取的⼀部分元素的集合。
1.3.2 参数和统计量参数:⽤来描述总体特征的概括性数字度量。
统计量:⽤类描述样本特征的概括性数字度量。
例如:某研究机构准备从某乡镇5万个家庭中抽取1000个家庭⽤于推断该乡镇所有农村居民家庭的年⼈均纯收⼊。
这项研究的总体是5万个家庭;样本是1000个家庭;参数是5万个家庭的⼈均纯收⼊;统计量是1000个家庭的⼈均纯收⼊。

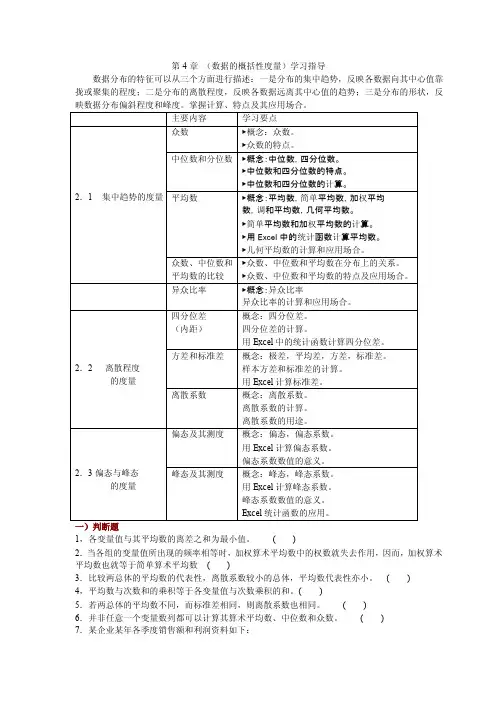
第4章(数据的概括性度量)学习指导数据分布的特征可以从三个方面进行描述:一是分布的集中趋势,反映各数据向其中心值靠拢或聚集的程度;二是分布的离散程度,反映各数据远离其中心值的趋势;三是分布的形状,反映数据分布偏斜程度和峰度。
掌握计算、特点及其应用场合。
主要内容学习要点2.1 集中趋势的度量众数▶概念:众数。
▶众数的特点。
中位数和分位数▶概念:中位数,四分位数。
▶中位数和四分位数的特点。
▶中位数和四分位数的计算。
平均数▶概念:平均数,简单平均数,加权平均数,调和平均数,几何平均数。
▶简单平均数和加权平均数的计算。
▶用Excel中的统计函数计算平均数。
▶几何平均数的计算和应用场合。
众数、中位数和平均数的比较▶众数、中位数和平均数在分布上的关系。
▶众数、中位数和平均数的特点及应用场合。
异众比率▶概念:异众比率异众比率的计算和应用场合。
2.2离散程度的度量四分位差(内距)概念:四分位差。
四分位差的计算。
用Excel中的统计函数计算四分位差。
方差和标准差概念:极差,平均差,方差,标准差。
样本方差和标准差的计算。
用Excel计算标准差。
离散系数概念:离散系数。
离散系数的计算。
离散系数的用途。
2.3偏态与峰态的度量偏态及其测度概念:偏态,偏态系数。
用Excel计算偏态系数。
偏态系数数值的意义。
峰态及其测度概念:峰态,峰态系数。
用Excel计算峰态系数。
峰态系数数值的意义。
Excel统计函数的应用。
一)判断题1,各变量值与其平均数的离差之和为最小值。
( )2.当各组的变量值所出现的频率相等时,加权算术平均数中的权数就失去作用,因而,加权算术平均数也就等于简单算术平均数( )3.比较两总体的平均数的代表性,离散系数较小的总体,平均数代表性亦小。
( )4,平均数与次数和的乘积等于各变量值与次数乘积的和。
( )5.若两总体的平均数不同,而标准差相同,则离散系数也相同。
( )6.并非任意一个变量数列都可以计算其算术平均数、中位数和众数。






第四章思考与习题一、思考题1.什么是集中趋势?测度集中趋势常用指标有哪些?2.算术均值.众数和中位数有何关系?3.什么是几何平均数?其适用场合是什么?4.什么叫离散趋势?测度离散趋势常用指标有哪些?5.为什么要计算离散系数?二、练习题(一)填空题1.统计数据分布的特征,可以从三个方面进行测度和描述:一是分布的__________,反映所有数据向其中心值靠拢或聚集的程度;二是分布的__________,反映各数据远离其中心值的趋势;三是分布的__________,反映数据分布的形状。
2.在某城市随机抽取13个家庭,调查得到每个家庭的人均月收入数据如下:1080.750.1080.850.960.2000.1050.1080.760.1080.950.1080.660,则其众数为,中位数为。
3.算术均值有两个重要数学性质:各变量值与其算术均值的__________等于零;各变量值与其算术均值的__________等于最小值。
4.简单算术均值是__________的特例。
4.几何均值主要用于计算__________的平均。
5.在一组数据分布中,当算术均值大于中位数大于众数时属于________分布;当算术均值小于中位数小于众数时属于________分布。
6.__________是各变量值与其均值离差平方的平均数,是测度数值型数据__________最主要的方法。
7.为了比较人数不等的两个班级学生的学习成绩的优劣,需要计算__________;而为了说明哪个班级学生的学习成绩比较整齐,则需要计算________。
8.偏态是对数据分布__________或__________的测度;而峰度是对数据分布_________的测度。
(二)判断题1.众数的大小只取决于众数组与相邻组次数的多少。
()2.当总体单位数n为奇数时,中位数=(n+1)/2。
()3.根据组距分组数据计算的均值是一个近似值。
()4.若已知甲企业工资的标准差小于乙企业,则可断言:甲企业平均工资的代表性好于乙企业。

第三章数据资料的统计描述:统计表和统计图第一节定性资料的统计描述知识点:1、统计分组就是根据统计研究的需要,将统计总体按照一定的标志区分为若干组成部分的一种统计方法。
2、定性数据的频数、频率、百分数、累计频数、累积频率的概念及计算。
3、定性数据频数分布表示方法主要有条形图、扇形图。
第二节定量数据的统计描述知识点:1、定量数据频数分布表的编制:(1)整理原始资料;(2)确定变量数列的形式;(3)编制组距式变量数列。
应注意的问题:确定组距,确定组限。
考查的区间式分组数据按“上组限不在组内”的原则确定。
2、定量数据的频数、频率、百分数、累积频数、累计频率的概念及计算。
3、定量数据频数分布表示方法主要有直方图、折线图和曲线图三种。
第三节探索性数据分析——茎叶图知识点:1、基本茎叶图的理解及编制第四节相关表与相关图知识点:1、相关表,反映定性变量与定量变量之间的相关关系。
2、散点图,反映两个定量变量之间的相关关系。
根据散点图判断两个变量的相关关系。
第四章数据资料的统计描述:数值计算第一节集中趋势知识点:关于单值式分组和区间式分组数据的1、平均数的计算,包括算术平均数,几何平均数,调和平均数2、众数的计算3、中位数、四分位数的计算4、(补充知识点)平均数、众数、中位数三者之间的关系5、百分位数的计算6、截尾均值的计算第二节离散测度知识点:1、极差的计算2、关于单值式分组和区间式分组数据的四分位数差的计算3、关于单值式分组和区间式分组数据的方差、标准差的计算4、变异系数的计算5、(补充知识点)偏度、峰度的含义及计算第三节协方差与相关系数知识点:1、样本协方差的含义及计算2、相关系数的含义及计算第四节相对位置测度与奇异点知识点:1、数据的标准化处理2、奇异点的诊断:利用契比雪夫定理和经验规则第五节探索性分析——5点描述与箱线图知识点:1、5点描述法的理解2、箱线图的理解与运用第三章习题:一、填空题1、在对数据资料进行统计描述时,______反映了各个组中每一项目出现的次数,______反映了各个组中项目发生的比例。

第四章 静态指标分析法(一)一、填空题1、数据分布集中趋势的测度值(指标)主要有、和。
其中和用于测度品质数据集中趋势的分布特征,用于测度数值型数据集中趋势的分布特征。
2、标准差是反映的最主要指标(测度值)。
3、几何平均数是计算和的比较适用的一种方法。
4、当两组数据的平均数不等时,要比较其数据的差异程度大小,需要计算。
5、在测定数据分布特征时,如果M M e X 0==,则认为数据呈分布。
6、当一组工人的月平均工资悬殊较大时,用他们工资的比其算术平均数更能代表全部工人工资的总体水平。
二.选择题单选题:1.反映的时间状况不同,总量指标可分为( )A 总量指标和时点总量指标B 时点总量指标和时期总量指标C 时期总量指标和时间指标D 实物量指标和价值量指标2、某厂1999年完成产值200万元,2000年计划增长10%,实际完成了231万元,超额完成( )A 5.5%B 5%C 115.5%D 15.5%3、在同一变量数列中,当标志值(变量值)比较大的次数较多时,计算出来的平均数( )A 接近标志值小的一方B 接近标志值大的一方C 接近次数少的一方D 接近哪一方无法判断4、在计算平均数时,权数的意义和作用是不变的,而权数的具体表现( )A 可变的B 总是各组单位数C 总是各组标志总量D 总是各组标志值 5、1998年某厂甲车间工人的月平均工资为520元,乙车间工人的月平均工资为540元,1999年各车间的工资水平不变,但甲车间的工人占全部工人的比重由原来的40%提高到了60%,则1999年两车间工人的总平均工资比1998年( )A 提高B 不变C 降低D 不能做结论 6、在变异指标(离散程度测度值)中,其数值越小,则( )A 说明变量值越分散,平均数代表性越低B 说明变量值越集中,平均数代表性越高C 说明变量值越分散,平均数代表性越高D 说明变量值越集中,平均数代表性越低7、有甲、乙两数列,已知甲数列:07.7,70==甲甲σX ;乙数列:41.3,7==乙乙σX 根据以上资料可直接判断( )A 甲数列的平均数代表性大B 乙数列的平均数代表性大C 两数列的平均数代表性相同D 不能直接判别8、杭州地区每百人手机拥有量为90部,这个指标是 ( )A 、比例相对指标B 、比较相对指标C 、结构相对指标D 、强度相对指标 9、某组数据呈正态分布,计算出算术平均数为5,中位数为7,则该数据分布为 ( ) A 、左偏分布 B 、右偏分布 C 、对称分布 D 、无法判断10、加权算术平均数的大小 ( )A 主要受各组标志值大小的影响,与各组次数多少无关;B 主要受各组次数多少的影响,与各组标志值大小无关;C 既与各组标志值大小无关,也与各组次数多少无关;D 既与各组标志值大小有关,也受各组次数多少的影响11、已知一分配数列,最小组限为30元,最大组限为200元,不可能是平均数的为 ( ) A 、50元 B 、80元 C 、120元 D 、210元12、比较两个单位的资料,甲的标准差小于乙的标准差,则 ( ) A 两个单位的平均数代表性相同 B 甲单位平均数代表性大于乙单位C 乙单位平均数代表性大于甲单位D 不能确定哪个单位的平均数代表性大 13、若单项数列的所有标志值都增加常数9,而次数都减少三分之一,则其算术平均数 ( ) A 、增加9 B 、增加6C 、减少三分之一 D 、增加三分之二 14、如果数据分布很不均匀,则应编制( )A 开口组B 闭口组C 等距数列D 异距数列 15、计算总量指标的基本原则是:( ) A 总体性B 全面性C 同质性D 可比性16、某企业的职工工资分为四组:800元以下;800-1000元;1000—1500元;1500以上,则1500元以上这组组中值应近似为()A1500元 B 1600元 C 1750元D 2000元 17、统计分组的首要问题是( )A 选择分组变量和确定组限B 按品质标志分组C 运用多个标志进行分组,形成一个分组体系D 善于运用复合分组18、某连续变量数列,其末组为开口组,下限为200,又知其邻组的组中值为170,则末组组中值为( )A 230B 260C 185D 215 19、分配数列中,靠近中间的变量值分布的次数少,靠近两端的变量值分布的次数多,这种分布的类型是( )A 钟型分布B U 型分布C J 型分布D 倒J 型分布 20、要了解上海市居民家庭的开支情况,最合适的调查方式是:() A 普查B 抽样调查C 典型调查D 重点调查21、已知两个同类企业的职工平均工资的标准差分别为5元和6元,而平均工资分别为3000元,3500元则两企业的工资离散程度为 ( )A 甲大于乙B 乙大于甲C 一样的D 无法判断 22、加权算术平均数的大小取决于( )A 变量值B 频数C 变量值和频数D 频率23、如果所有标志值的频数都减少为原来的1/5,而标志值仍然不变.那么算术平均数( ) A 不变 B 扩大到5倍 C 减少为原来的1/5 D 不能预测其变化 24、 计算平均比率最好用 ( )A 算术平均数B 调和平均数C 几何平均数D 中位数25、若两数列的标准差相等而平均数不同,在比较两数列的离散程度大小时,应采用() A 全距 B 平均差 C 标准差 D 标准差系数26、若n=20,∑∑==2080,2002x x ,标准差为( )A 2B 4C 1.5D 327、已知某总体3215,3256==eMM,则数据的分布形态为( )A左偏分布B正态分布 C 右偏分布DU型分布28、一次小型出口商品洽谈会,所有厂商的平均成交额的方差为156.25万元,标准差系数为14.2%,则平均成交额为( )万元A11 B 177.5 C 22.19 D 8826、欲粗略了解我国钢铁生产的基本情况,调查了上钢、鞍钢等十几个大型的钢铁企业,这是()A普查B重点调查C典型调查D抽样调查多选题:1.某企业计划2000年成本降低率为8%,实际降低了10%。