龙贝格积分
- 格式:docx
- 大小:184.20 KB
- 文档页数:8

龙贝格(Romberg )求积法1.算法理论Romberg 求积方法是以复化梯形公式为基础,应用Richardson 外推法导出的数值求积方法。
由复化梯形公式 )]()(2)([2222b f h a f a f h T +++=可以化为)]()]()([2[212112h a f h b f a f hT +++==)]([21211h a f h T ++一般地,把区间[a,b ]逐次分半k -1次,(k =1,2,……,n)区间长度(步长)为kk m a b h -=,其中mk =2k -1。
记k T =)1(k T由)1(k T =]))12(([21211)1(1∑=---++km j k k k h j a f h T 从而⎰badxx f )(=)1(kT-)(''122k f h a b ξ- (1)按Richardson 外推思想,可将(1)看成关于k h ,误差为)(2k h O 的一个近似公式,因而,复化梯形公式的误差公式为⎰badxx f )(-)1(k T =......4221++kkh K h K =∑∞=12i i k i h K (2)取1+k h =k h 21有 ⎰ba dx x f )(-)1(1+k T =∑∞=+121221i ik ii hK (3)误差为)(2jh O 的误差公式 )(j kT=)1(-j kT+141)1(1)1(------j j k j k T T2。
误差及收敛性分析(1)误差,对复化梯形公式误差估计时,是估计出每个子区间上的误差,然后将n 个子区间上的误差相加作为整个积分区间上的误差。
(2)收敛性,记h x i =∆,由于∑=++=ni i i n x f x f h f T 01))]()([2)(=))()((21101∑∑-==∆+∆n i ni i i i i x x f x x f上面两个累加式都是积分和,由于)(x f 在区间],[b a 上可积可知,只要],[b a 的分划的最大子区间的长度0→λ时,也即∞→n 时,它们的极限都等于积分值)(f I 。

梯形法的递推化和龙贝格算法
梯形法(Trapezoid Rule)是一种数值积分的方法,用于计算函数在给定区间上的定积分。
梯形法的递推化可以通过将区间等分为若干个小梯形来实现。
具体步骤如下:
1. 将给定区间[a, b]分成n个等距的子区间,每个子区间的宽度为h = (b - a) / n。
2. 计算每个子区间的矩形面积(等于底边长度乘以高度),然后将所有子区间的矩形面积相加,得到梯形法的近似积分值。
梯形法的递推公式可以表示为:
I = h/2 * [f(a) + 2*f(a+h) + 2*f(a+2h) + ... + 2*f(a+(n-1)h) + f(b)] 其中,f(x)为要积分的函数。
龙贝格算法(Romberg Integration)是一种数值积分的方法,可以通过多次应用梯形法来逐步提高积分结果的精度。
龙贝格算法的具体步骤如下:
1. 利用梯形法计算区间[a, b]上的第一次近似积分值T(1,1)。
2. 利用递推公式T(m, 1) = 1/2 * [ T(m-1, 1) + h(m-1) *
Sigma(2^(m-2) * f(a + (2k-1) * h(m-1))), k=1 to 2^(m-2)],计算T(m, 1),其中h(m-1)为区间[a, b]的步长。
3. 计算T(m, n) = T(m, n-1) + 1 / (4^(n-1) - 1) * ( T(m, n-1) - T(m-1, n-1) ),其中n > 1,m > n。
4. 重复步骤3,直到达到所需的精度要求。
龙贝格算法通过递归和递推来不断提高积分结果的精度,可以较快地得到比较准确的近似积分值。

龙贝格积分1. 算法原理采用复化求积公式计算时,为使截断误差不超过ε,需要估计被积函数高阶导数的最大值,从而确定把积分区间[]b a ,分成等长子区间的个数n 。
首先在整个区间[]b a ,上应用梯形公式,算出积分近似值T1;然后将[]b a ,分半,对 应用复化梯形公式算出T2;再将每个小区间分半,一般地,每次总是在前一次的基础上再将小区间分半,然后利用递推公式进行计算,直至相邻两个值之差小于允许误差为止。
实际计算中,常用ε≤-n n T T 2作为判别计算终止的条件。
若满足,则取n T f I 2][≈;否则将区间再分半进行计算,知道满足精度要求为止。
又经过推导可知,∑=-++=ni i i n n x x f h T T 112)2(221,在实际计算中,取kn 2=,则k a b h 2-=,112)1*2(2++--+=+k i i ab i a x x 。
所以,上式可以写为∑=++--+-+=+kk i k k ab i a f a b T T 211122)2)12((2211k开始计算时,取())()(21b f a f ab T +-=龙贝格算法是由递推算法得来的。
由梯形公式得出辛普森公式得出柯特斯公式最后得到龙贝格公式。
根据梯形法的误差公式,积分值n T 的截断误差大致与2h 成正比,因此步长减半后误差将减至四分之一,即有21114n n T T -≈-将上式移项整理,知2211()3n n n T T T -≈-由此可见,只要二分前后两个积分值n T 和2n T 相当接近,就可以保证计算保证结果计算结果2n T 的误差很小,这种直接用计算结果来估计误差的方法称作误差的事后估计法。
按上式,积分值2n T 的误差大致等于21()3n n T T -,如果用这个误差值作为2n T 的一种补偿,可以期望,所得的()222141333n n n n n T T T T T T =+-=-应当是更好的结果。

龙贝格积分公式
龙贝格积分公式,是数学中常见的一种积分方法。
它通过分割区间,将被积函数转化为$Polynomial$(多项式)的形式,并通过加权平均的方式求出积分值。
这种方法被广泛应用于科学计算领域,如物理、化学等。
龙贝格积分公式是从重复使用$Simpson$和$Mid-point$公式推导而来的。
该公式基于分治思想,将整个区间分成若干个子区间,并对每个子区间进行逐层递推,最终得出整个区间的积分值。
在推导龙贝格积分公式时,需要利用“函数逼近”的思想,即将被积函数转化为多项式的形式。
这样可以大大简化计算,减小误差,并提高计算精度。
公式的具体计算过程如下:
假设被积函数为$f(x)$,积分区间为$[a,b]$,将积分区间均分成$2^n$个小区间,在每个小区间上做$Simpson$公式近似积分,得到$S_{2^n}$,即:
$$S_{2^n}=\frac{4^nS_{2^{n-1}}-S_{2^{n-1}}}{4^n-1}$$
其中,$S_{2^n}$为$n$级逼近值,$S_{2^{n-1}}$为$n-1$级逼近值。
根据上式,可得$S_{2^1}$,然后再计算$S_{2^2}$,$S_{2^3}$,以此类推,递归地计算$n$级逼近值,直到计算所得值与精确值的差别小于预先设定的精度要求为止。
龙贝格积分公式没有强制要求$f(x)$连续可微,又由于是基于函数逼近的方式进行积分,精度高且计算速度快,因此被广泛应用。
总之,龙贝格积分公式是一种有效的求解复杂积分问题的方法,在处理高维积分时,具有更大的优势。

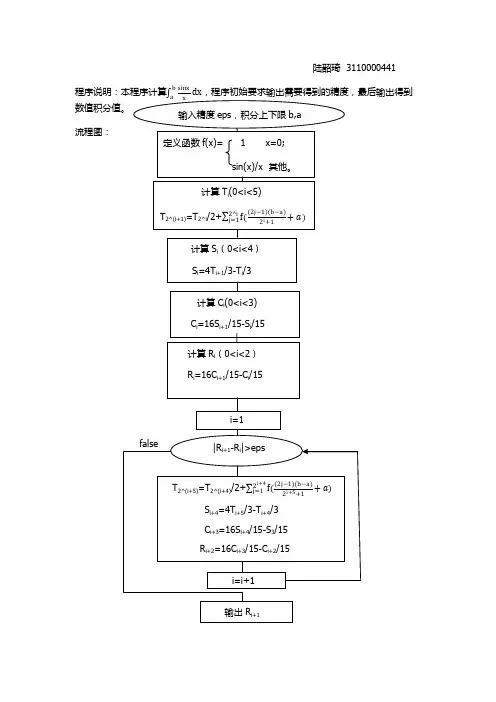

龙贝格算法一、问题分析1、1龙贝格积分题目要求学生运用龙贝格算法解决实际问题(塑料雨篷曲线满足函数y(x)=l sin (tx),则给定雨篷得长度后,求所需要平板材料得长度).二、方法原理2、1龙贝格积分原理龙贝格算法就是由递推算法得来得。
由梯形公式得出辛普生公式得出柯特斯公式最后得到龙贝格公式.在变步长得过程中探讨梯形法得计算规律.设将求积区间[a,b]分为n个等分,则一共有n+1个等分点,n.这里用表示复化梯形法求得得积分值,其下标n 表示等分数。
先考察下一个字段[],其中点,在该子段上二分前后两个积分值显然有下列关系将这一关系式关于k从0到n-1累加求与,即可导出下列递推公式需要强调指出得就是,上式中得代表二分前得步长,而梯形法得算法简单,但精度低,收敛速度缓慢,如何提高收敛速度以节省计算量,自然式人们极为关心得.根据梯形法得误差公式,积分值得截断误差大致与成正比,因此步长减半后误差将减至四分之一,既有将上式移项整理,知由此可见,只要二分前后两个积分值与相当接近,就可以保证计算保证结果计算结果得误差很小,这种直接用计算结果来估计误差得方法称作误差得事后估计法。
ﻩ按上式,积分值得误差大致等于,如果用这个误差值作为得一种补偿,可以期望,所得得应当就是更好得结果。
ﻩ按上式,组合得到得近似值直接验证,用梯形二分前后得两个积分值与按式组合,结果得到辛普生法得积分值。
再考察辛普生法。
其截断误差与成正比.因此,若将步长折半,则误差相应得减至十六分之一。
既有由此得不难验证,上式右端得值其实就等于,就就是说,用辛普生法二分前后得两个积分值与,在按上式再做线性组合,结果得到柯特斯法得积分值,既有重复同样得手续,依据斯科特法得误差公式可进一步导出龙贝格公式应当注意龙贝格公式已经不属于牛顿—柯特斯公式得范畴.在步长二分得过程中运用公式加工三次,就能将粗糙得积分值逐步加工成精度较高得龙贝格,或者说,将收敛缓慢得梯形值序列加工成熟练迅速得龙贝格值序列,这种加速方法称龙贝格算法。


实验题目2 Romberg 积分法摘要考虑积分()()b aI f f x dx =⎰欲求其近似值,可以采用如下公式: (复化)梯形公式 11[()()]2n ii i hT f x f x-+==+∑2()12b a E h f η-''=-[,]a b η∈ (复化)辛卜生公式 11102[()4()()]6n i i i i hS f x f x f x -++==++∑4(4)()1802b a h E f η-⎛⎫=- ⎪⎝⎭ [,]a b η∈ (复化)柯特斯公式 111042[7()32()12()90n i i i i hC f x f x f x -++==+++∑31432()7()]i i f xf x +++6(6)2()()9454b a h E f η-⎛⎫=- ⎪⎝⎭[,]a b η∈ 这里,梯形公式显得算法简单,具有如下递推关系121021()22n n n i i h T T f x -+==+∑因此,很容易实现从低阶的计算结果推算出高阶的近似值,而只需要花费较少的附加函数计算。
但是,由于梯形公式收敛阶较低,收敛速度缓慢。
所以,如何提高收敛速度,自然是人们极为关心的课题。
为此,记0,k T 为将区间[,]a b 进行2k等份的复化梯形积分结果,1,k T 为将区间[,]a b 进行2k等份的复化辛卜生积分结果,2,k T 为将区间[,]a b 进行2k等份的复化柯特斯积分结果。
根据李查逊(Richardson )外推加速方法,可得到1,11,,0,1,2,40,1,2,41m m k m km k m k T T T m -+-=-⎛⎫=⎪=-⎝⎭可以证明,如果()f x 充分光滑,则有,lim ()m k k T I f →∞= (m 固定),0lim ()m m T I f →∞=这是一个收敛速度更快的一个数值求积公式,我们称为龙贝格积分法。

实验名称实验4实验地点6A-XXX 实验类型设计实验学时 2 实验日期20 /X/X ★撰写注意:版面格式已设置好(不得更改),填入内容即可。
一、实验目的
1.龙贝格积分
二、实验内容
1.实验任务
1.龙贝格积分
2.程序设计
1)数据输入(输入哪些数据、个数、类型、来源、输入方式)
const double eps=0.000005;
const int MaxD=100;
double f(double), double a, double b
2)数据存储(输入数据在内存中的存储)
函数
double f1(double x)
double f2(double x)
double f3(double x)
void Romberg(double f(double), double a, double b)
3)数据处理(说明处理步骤。
若不是非常简单,需要绘制流程图)
1.输入要处理的数据进入变量中
2.进行函数处理
3.输出函数处理结果
4)数据输出(贴图:程序运行结果截图。
图幅大小适当,不能太大)。
龙贝格(Romberg )求积法1.算法理论Romberg 求积方法是以复化梯形公式为基础,应用Richardson 外推法导出的数值求积方法。
由复化梯形公式 )]()(2)([2222b f h a f a f h T +++=可以化为)]()]()([2[212112h a f h b f a f hT +++==)]([21211h a f h T ++一般地,把区间[a,b]逐次分半k -1次,(k =1,2,……,n )区间长度(步长)为kk m a b h -=,其中mk =2k -1。
记k T =)1(k T 由)1(k T =]))12(([21211)1(1∑=---++km j k k k h j a f h T 从而⎰badxx f )(=)1(kT-)(''122k f h a b ξ- (1)按Richardson 外推思想,可将(1)看成关于k h ,误差为)(2k h O 的一个近似公式,因而,复化梯形公式的误差公式为⎰badxx f )(-)1(k T =......4221++k k h K h K =∑∞=12i i k i h K (2)取1+k h =k h 21有 ⎰ba dx x f )(-)1(1+k T =∑∞=+121221i ik ii hK (3)误差为)(2jh O 的误差公式 )(j kT=)1(-j kT+141)1(1)1(------j j k j k T T2.误差及收敛性分析(1)误差,对复化梯形公式误差估计时,是估计出每个子区间上的误差,然后将n 个子区间上的误差相加作为整个积分区间上的误差。
(2)收敛性,记h x i =∆,由于∑=++=ni i i n x f x f h f T 01))]()([2)(=))()((21101∑∑-==∆+∆n i ni i i i i x x f x x f上面两个累加式都是积分和,由于)(x f 在区间],[b a 上可积可知,只要],[b a 的分划的最大子区间的长度0→λ时,也即∞→n 时,它们的极限都等于积分值)(f I 。