oracle分析函数
- 格式:ppt
- 大小:586.00 KB
- 文档页数:90

ORACLE_分析函数大全Oracle分析函数是一种高级SQL函数,它可以在查询中实现一系列复杂的分析操作。
这些函数可以帮助我们在数据库中执行各种数据分析和报表生成任务。
本文将介绍Oracle数据库中的一些常用分析函数。
1.ROW_NUMBER函数:该函数为查询结果中的每一行分配一个唯一的数字。
可以用它对结果进行排序或分组。
例如,可以使用ROW_NUMBER函数在结果集中为每个员工计算唯一的编号。
2.RANK和DENSE_RANK函数:这两个函数用于计算结果集中每个行的排名。
RANK函数返回相同值的行具有相同的排名,并且下一个排名值将被跳过。
DENSE_RANK函数类似,但是下一个排名值不会被跳过。
G和LEAD函数:LAG函数返回结果集中指定列的前一个(上一个)行的值,而LEAD函数返回后一个(下一个)行的值。
这些函数通常用于计算增长率或发现趋势。
4.FIRST和LAST函数:这两个函数用于返回结果集中分组的第一个和最后一个行的值。
可以与GROUPBY子句一起使用。
5.CUME_DIST函数:该函数用于计算给定值的累积分布。
它返回值的累积分布在结果集中的位置(百分比)。
6.PERCENT_RANK函数:该函数用于计算结果集中每个行的百分位数排名。
它返回值的百分位数排名(0到1之间的小数)。
7. NTILE函数:该函数用于将结果集分成指定数量的桶(Bucket),并为每个行分配一个桶号。
通常用于将数据分组为更小的块。
8.LISTAGG函数:该函数将指定列的值连接成一个字符串,并使用指定的分隔符分隔每个值。
可以用它将多个值合并在一起形成一个字符串。
9.AVG、SUM、COUNT和MAX/MIN函数:这些是常见的聚合函数,可以在分析函数中使用。
它们用于计算结果集中的平均值、总和、计数和最大/最小值。
以上只是Oracle数据库中的一些常用分析函数。
还有其他一些分析函数,如PERCENTILE_CONT、PERCENTILE_DISC等可以用于更高级的分析计算。

Oracle分析函数Oracle分析函数实际上操作对象是查询出的数据集,也就是说不需二次查询数据库,实际上就是oracle实现了一些我们自身需要编码实现的统计功能,对于简化开发工作量有很大的帮助,特别在开发第三方报表软件时是非常有帮助的。
Oracle从8.1.6开始提供分析函数。
一、基本语法oracle分析函数的语法:function_name(arg1,arg2,...)over(<partition-clause> <order-by-clause ><windowing clause>)说明:1.partition-clause 数据记录集分组2.order-by-clause 数据记录集排序3.windowing clause 功能非常强大、比较复杂,定义分析函数在操作行的集合。
有三种开窗方式: range、row、specifying。
二、常用分析函数1. avg(distinct|all expression) 计算组内平均值,distinct 可去除组内重复数据select deptno,empno,sal,avg(sal) over (partition by deptno) avg_sal from t;DEPTNO EMPNO SAL AVG_SAL---------- ---------- ---------- ----------10 7782 2450 2916.666677839 5000 2916.666677934 1300 2916.6666720 7566 2975 21757902 3000 21757876 1100 21757369 800 21757788 3000 217530 7521 1250 1566.666677844 1500 1566.666677499 1600 1566.666677900 950 1566.666677698 2850 1566.666677654 1250 1566.666672.count(<distinct><*><expression>) 对组内数据进行计数3.rank() 和dense_rank()dense_rank()根据 order by 子句表达式的值,从查询返回的每一行,计算和其他行的相对位置,序号从 1 开始,有重复值时序号不跳号。

ORACLE中的ROW_NUMBEROVER分析函数的用法ROW_NUMBER(OVER(是ORACLE数据库中的一个分析函数,用来为结果集中的每一行分配一个唯一的序号。
ROW_NUMBER(OVER(的语法是:ROW_NUMBER( OVER ( [ PARTITION BY expr1 [, expr2, ...] ]ORDER BY clause )其中,PARTITIONBY子句可选,用来指定分区依据的列或表达式;ORDERBY子句用来指定排序的列或表达式。
ROW_NUMBER(OVER(常用在查询结果需要进行分页或者进行排序后获取前几行的场景中。
以下是ROW_NUMBER(OVER(的用法示例:示例1:查询员工表中每个部门的员工数,并按照员工数降序排序。
SELECT department_id, count(*) as employee_count,ROW_NUMBER( OVER (ORDER BY count(*) DESC) as rankFROM employeesGROUP BY department_idORDER BY count(*) DESC;在这个示例中,ROW_NUMBER(OVER(函数根据部门中的员工数进行降序排序,并为每个部门分配一个唯一的序号。
示例2:查询员工表中每个部门的员工数,并按照员工数降序排序,并且只返回前三名。
SELECT department_id, count(*) as employee_count,ROW_NUMBER( OVER (ORDER BY count(*) DESC) as rankFROM employeesGROUP BY department_idWHERE rank <= 3ORDER BY count(*) DESC;在这个示例中,ROW_NUMBER(OVER(函数的结果用于限制查询结果只返回前三名。
示例3:查询员工表中每个部门的员工信息,并按照部门和薪水进行排序。
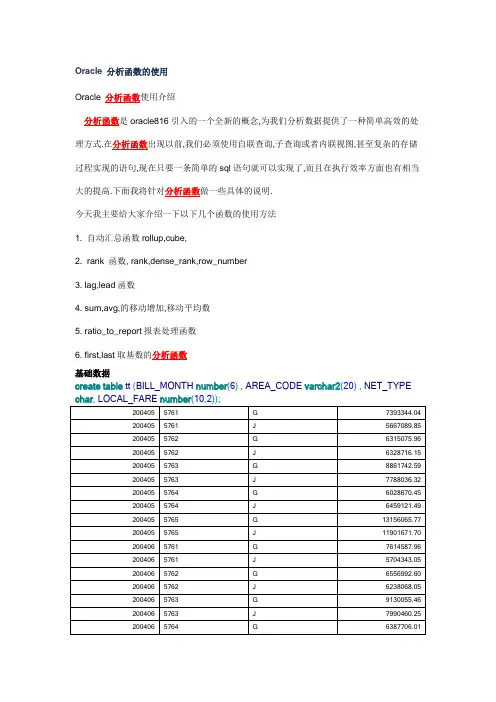
Oracle 分析函数的使用Oracle 分析函数使用介绍分析函数是oracle816引入的一个全新的概念,为我们分析数据提供了一种简单高效的处理方式.在分析函数出现以前,我们必须使用自联查询,子查询或者内联视图,甚至复杂的存储过程实现的语句,现在只要一条简单的sql语句就可以实现了,而且在执行效率方面也有相当大的提高.下面我将针对分析函数做一些具体的说明.今天我主要给大家介绍一下以下几个函数的使用方法1. 自动汇总函数rollup,cube,2. rank 函数, rank,dense_rank,row_number3. lag,lead函数4. sum,avg,的移动增加,移动平均数5. ratio_to_report报表处理函数6. first,last取基数的分析函数基础数据1. 使用rollup函数的介绍select area_code,sum(local_fare) local_farefrom ttgroup by area_codeunion allselect'合计' area_code,sum(local_fare) local_fare from tt;1 0 UNION-ALL2 1 SORT (GROUP BY) (Cost=5 Card=1309 Bytes=24871)3 2 TABLE ACCESS (FULL) OF 'T' (Cost=2 Card=1309 Bytes=24871)4 1 SORT (AGGREGATE)5 4 TABLE ACCESS (FULL) OF 'T' (Cost=2 Card=1309 Bytes=17017)Statistics----------------------------------------------------------0 recursive calls0 db block gets6 consistent gets0 physical reads0 redo size561 bytes sent via SQL*Net to client503 bytes received via SQL*Net from client2 SQL*Net roundtrips to/from client1 sorts (memory)0 sorts (disk)6 rows processed下面是使用分析函数rollup得出的汇总数据的例子SQL> select nvl(area_code,'合计') area_code,sum(local_fare) local_fare2 from tt3 group by rollup(area_code);4 /AREA_CODE LOCAL_FARE---------- --------------5761 54225413.045762 52039619.605763 69186545.025764 53156768.465765 104548719.19合计333157065.31从上面的结果中我们很容易发现,每个统计数据所对应的行都会出现null,我们如何来区分到底是根据那个字段做的汇总呢,这时候,oracle的grouping函数就粉墨登场了.如果当前的汇总记录是利用该字段得出的,grouping函数就会返回1,否则返回01 select decode(grouping(area_code),1,'all area',to_char(area_code))area_code,2 decode(grouping(bill_month),1,'all month',bill_month) bill_month,3 sum(local_fare) local_fare4 from t5 group by cube(area_code,bill_month)6* order by area_code,bill_month nulls last07:07:29 SQL> /AREA_CODE BILL_MONTH LOCAL_FARE---------- --------------- --------------5761 200405 13060.435761 200406 13318.935761 200407 13710.275761 200408 14135.785761 all month 54225.415762 200405 12643.795762 200406 12795.065762 200407 13224.305762 200408 13376.475762 all month 52039.625763 200405 16649.785763 200406 17120.525763 200407 17487.495763 200408 17928.765763 all month 69186.545764 200405 12487.795764 200406 13295.195764 200407 13444.095764 200408 13929.695764 all month 53156.775765 200405 25057.745765 200406 26058.465765 200407 26301.885765 200408 27130.645765 all month 104548.72all area 200405 79899.532. rank函数的介绍问题2.我想查出这几个月份中各个地区的总话费的排名.为了将rank,dense_rank,row_number函数的差别显示出来,我们对已有的基础数据做一些修改,将5763的数据改成与5761的数据相同.1 update t t1 set local_fare = (2 select local_fare from t t23 where t1.bill_month = t2.bill_month4 and _type = _type5 and t2.area_code = '5761'6) where area_code = '5763'SQL> /update tt t1 set local_fare =(select local_fare from tt t2where t1.bill_month = t2.bill_monthand _type = _typeand t2.area_code ='5761')where area_code ='5763';8 rows updated.Elapsed: 00:00:00.01我们先使用rank函数来计算各个地区的话费排名.SQL> select area_code,sum(local_fare) local_fare,2 rank() over (order by sum(local_fare) desc) fare_rank3 from t4 group by area_codeselect area_code,sum(local_fare) local_fare,rank() over (order by sum(local_fare)desc) fare_rankfrom ttgroup by area_codeAREA_CODE LOCAL_FARE FARE_RANK---------- -------------- ----------5765 104548.72 15761 54225.41 25763 54225.41 25764 53156.77 45762 52039.62 5Elapsed: 00:00:00.01我们可以看到红色标注的地方出现了,跳位,排名3没有出现下面我们再看看dense_rank查询的结果.select area_code,sum(local_fare) local_fare,dense_rank() over (order by sum(local_fare)desc) fare_rankfrom ttgroup by area_code/AREA_CODE LOCAL_FARE FARE_RANK---------- -------------- ----------5765 104548.72 15761 54225.41 25763 54225.41 25764 53156.77 3 这是这里出现了第三名5762 52039.62 4Elapsed: 00:00:00.00在这个例子中,出现了一个第三名,这就是rank和dense_rank的差别,rank如果出现两个相同的数据,那么后面的数据就会直接跳过这个排名,而dense_rank则不会,差别更大的是,row_number哪怕是两个数据完全相同,排名也会不一样,这个特性在我们想找出对应没个条件的唯一记录的时候又很大用处select area_code,sum(local_fare) local_fare,row_number() over (order by sum(local_fare)desc) fare_rankfrom ttgroup by area_code/AREA_CODE LOCAL_FARE FARE_RANK---------- -------------- ----------5765 104548.72 15761 54225.41 25763 54225.41 35764 53156.77 45762 52039.62 5在row_nubmer函数中,我们发现,哪怕sum(local_fare)完全相同,我们还是得到了不一样排名,我们可以利用这个特性剔除数据库中的重复记录.这里的几个例子是为了说明这三个函数的基本用法。

oracle常⽤的分析函数常⽤的分析函数如下所列:row_number() over(partition by ... order by ...)rank() over(partition by ... order by ...)dense_rank() over(partition by ... order by ...)count() over(partition by ... order by ...)max() over(partition by ... order by ...)min() over(partition by ... order by ...)sum() over(partition by ... order by ...)avg() over(partition by ... order by ...)first_value() over(partition by ... order by ...)last_value() over(partition by ... order by ...)lag() over(partition by ... order by ...)lead() over(partition by ... order by ...)⼀、Oracle分析函数简介:在⽇常的⽣产环境中,我们接触得⽐较多的是OLTP系统(即Online Transaction Process),这些系统的特点是具备实时要求,或者⾄少说对响应的时间多长有⼀定的要求;其次这些系统的业务逻辑⼀般⽐较复杂,可能需要经过多次的运算。
⽐如我们经常接触到的电⼦商城。
在这些系统之外,还有⼀种称之为OLAP的系统(即Online Aanalyse Process),这些系统⼀般⽤于系统决策使⽤。
通常和数据仓库、数据分析、数据挖掘等概念联系在⼀起。
这些系统的特点是数据量⼤,对实时响应的要求不⾼或者根本不关注这⽅⾯的要求,以查询、统计操作为主。

Oracle分析函数-排序排列(rank、dense_rank、row_number、ntile)(1)rank函数返回⼀个唯⼀的值,除⾮遇到相同的数据时,此时所有相同数据的排名是⼀样的,同时会在最后⼀条相同记录和下⼀条不同记录的排名之间空出排名。
(2)dense_rank函数返回⼀个唯⼀的值,除⾮当碰到相同数据时,此时所有相同数据的排名都是⼀样的。
(3)row_number函数返回⼀个唯⼀的值,当碰到相同数据时,排名按照记录集中记录的顺序依次递增。
(4)ntile是要把查询得到的结果平均分为⼏组,如果不平均则分给第⼀组。
例如:create table s_score( s_id number(6),score number(4,2));insert into s_score values(001,98);insert into s_score values(002,66.5);insert into s_score values(003,99);insert into s_score values(004,98);insert into s_score values(005,98);insert into s_score values(006,80);selects_id,score,rank() over(order by score desc) rank --按照成绩排名,纯排名,dense_rank() over(order by score desc) dense_rank --按照成绩排名,相同成绩排名⼀致,row_number() over(order by score desc) row_number --按照成绩依次排名,ntile(3) over (order by score desc) group_s --按照分数划分成绩梯队from s_score;排名/排序的时候,有时候,我们会想到利⽤伪列row_num,利⽤row_num确实可以解决某些场景下的问题(但是相对也⽐较复杂),⽽且有些场景下的问题却很难解决。

Oracle之分析函数⼀、分析函数 1、分析函数 分析函数是Oracle专门⽤于解决复杂报表统计需求的功能强⼤的函数,它可以在数据中进⾏分组然后计算基于组的某种统计值,并且每⼀组的每⼀⾏都可以返回⼀个统计值。
2、分析函数和聚合函数的区别 普通的聚合函数⽤group by分组,每个分组返回⼀个统计值,⽽分析函数采⽤partition by分组,并且每组每⾏都可以返回⼀个统计值。
3、分析函数的形式 分析函数带有⼀个开窗函数over(),包含分析⼦句。
分析⼦句⼜由下⾯三部分组成: partition by :分组⼦句,表⽰分析函数的计算范围,不同的组互不相⼲; ORDER BY:排序⼦句,表⽰分组后,组内的排序⽅式; ROWS/RANGE:窗⼝⼦句,是在分组(PARTITION BY)后,组内的⼦分组(也称窗⼝),此时分析函数的计算范围窗⼝,⽽不是PARTITON。
窗⼝有两种,ROWS和RANGE; 使⽤形式如下:OVER(PARTITION BY xxx PORDER BY yyy ROWS BETWEEN rowStart AND rowEnd) 注:窗⼝⼦句在这⾥我只说rows⽅式的窗⼝,range⽅式和滑动窗⼝也不提。
⼆、OVER() 函数 1、sql 查询语句的 order by 和 OVER() 函数中的 ORDER BY 的执⾏顺序 分析函数是在整个sql查询结束后(sql语句中的order by的执⾏⽐较特殊)再进⾏的操作, 也就是说sql语句中的order by也会影响分析函数的执⾏结果: [1] 两者⼀致:如果sql语句中的order by满⾜分析函数分析时要求的排序,那么sql语句中的排序将先执⾏,分析函数在分析时就不必再排序; [2] 两者不⼀致:如果sql语句中的order by不满⾜分析函数分析时要求的排序,那么sql语句中的排序将最后在分析函数分析结束后执⾏排序。
2、分析函数中的分组/排序/窗⼝分析函数包含三个分析⼦句:分组(partition by),排序(order by),窗⼝(rows/range)窗⼝就是分析函数分析时要处理的数据范围,就拿sum来说,它是sum窗⼝中的记录⽽不是整个分组中的记录,因此我们在想得到某个栏位的累计值时,我们需要把窗⼝指定到该分组中的第⼀⾏数据到当前⾏, 如果你指定该窗⼝从该分组中的第⼀⾏到最后⼀⾏,那么该组中的每⼀个sum值都会⼀样,即整个组的总和。

Oracle 11g r2分析函数新特性简介(二)分析函数LISTAGG在11gr2中,Oracle分析函数的功能进一步增强。
这篇介绍新增的分析函数LISTAGG。
11gr2还新增了一个分析函数LISTAGG,这个函数的功能实现字符串的连接在11gr2中,Oracle终于实现了这个分析函数:SQL> select * from v$version;BANNER--------------------------------------------------------------------------------Oracle Database11gEnterprise Edition Release11.2.0.1.0 - 64bit ProductionPL/SQL Release 11.2.0.1.0 - ProductionCORE 11.2.0.1.0 ProductionTNS for Linux: Version 11.2.0.1.0 - ProductionNLSRTL Version 11.2.0.1.0 - ProductionSQL> create table t (id number, name varchar2(30), type varchar2(20));表已创建。
SQL> insert into t select rownum, object_name, object_type from dba_objects;已创建71968行。
SQL> commit;提交完成。
SQL> select listagg(name, ',') within group (order by id)2 from t3 where rownum < 10;LISTAGG(NAME,',')WITHINGROUP(ORDERBYID)-------------------------------------------------------------------------------------------SYS_C00644,SYS_LOB0000000528C00002$$,KOTTB$,SYS_C00645,SYS_LOB0000000532C00002$$,KOTAD$,SYS_C00646,SYS_L OB0000000536C00002$$,KOTMD$SQL> select type, listagg(name, ',') within group (order by id) name2 from t3 where type in ('DIRECTORY', 'JAVA SOURCE', 'SCHEDULE')4 group by type;TYPE NAME-------------------- ---------------------------------------------------------------------DIRECTORY ORACLE_OCM_CONFIG_DIR,DATA_PUMP_DIR,XMLDIRJAVA SOURCE dbFWTrace,schedFileWatcherJavaSCHEDULE DAILY_PURGE_SCHEDULE,FILE_WATCHER_SCHEDULE,BSLN_MAINTAIN_STATS_SCHEDSQL> select name,2 listagg(name, ',') within group (order by id) over(partition by type) s_name3 from t4 where type in ('DIRECTORY', 'JAVA SOURCE', 'SCHEDULE');NAME S_NAME本文URL地址:/database/Oracle/201410/45457.htm------------------------- -----------------------------------------------------------ORACLE_OCM_CONFIG_DIR ORACLE_OCM_CONFIG_DIR,DATA_PUMP_DIR,XMLDIRDATA_PUMP_DIR ORACLE_OCM_CONFIG_DIR,DATA_PUMP_DIR,XMLDIRXMLDIR ORACLE_OCM_CONFIG_DIR,DATA_PUMP_DIR,XMLDIRdbFWTrace dbFWTrace,schedFileWatcherJavaschedFileWatcherJava dbFWTrace,schedFileWatcherJavaDAILY_PURGE_SCHEDULE DAILY_PURGE_SCHEDULE,FILE_WATCHER_SCHEDULE,BSLN_MAINTAIN_STATS_SCHEDFILE_WATCHER_SCHEDULE DAILY_PURGE_SCHEDULE,FILE_WATCHER_SCHEDULE,BSLN_MAINTAIN_STATS_SCHED BSLN_MAINTAIN_STATS_SCHED DAILY_PURGE_SCHEDULE,FILE_WATCHER_SCHEDULE,BSLN_MAINTAIN_STATS_SCHED 已选择8行。

Oracle分析函数Over()阅读⽬录⼀、Over()分析函数1、rank()/dense_rank over(partition by ... order by ...)2、min()/max() over(partition by ...)3、lead()/lag() over(partition by ... order by ...) 取前⾯/后⾯第n⾏记录4、FIRST_VALUE/LAST_VALUE() OVER(PARTITION BY ...) 取⾸尾记录5、ROW_NUMBER() OVER(PARTITION BY.. ORDER BY ..) 排序(应⽤:分页)6、sum/avg/count() over(partition by ..)7、 rows/range between … preceding and … following 上下范围内求值rows between … preceding and … following⼆、其他1、NULLS FIRST/LAST 将空值字段记录放到最前或最后显⽰2、NTILE(n)3、keep(dense_rank first/last)回到顶部⼀、Over()分析函数说明:聚合函数(如sum()、max()等)可以计算基于组的某种聚合值,但是聚合函数对于某个组只能返回⼀⾏记录。
若想对于某组返回多⾏记录,则需要使⽤分析函数。
1、rank()/dense_rank over(partition by ... order by ...)说明:over()在什么条件之上; partition by 按哪个字段划分组; order by 按哪个字段排序;注意: (1)使⽤rank()/dense_rank() 时,必须要带order by否则⾮法 (2)rank()/dense_rank()分级的区别: rank(): 跳跃排序,如果有两个第⼀级时,接下来就是第三级。

Oracle数据库分析函数⽤法⽬录1、什么是窗⼝函数?2、窗⼝函数——开窗3、⼀些分析函数的使⽤⽅法4、OVER()参数——分组函数5、OVER()参数——排序函数1、什么是窗⼝函数?窗⼝函数也属于分析函数。
Oracle从8.1.6开始提供窗⼝函数,窗⼝函数⽤于计算基于组的某种聚合值,窗⼝函数指定了分析函数⼯作的数据窗⼝⼤⼩,这个数据窗⼝⼤⼩可能会随着⾏的变化⽽变化。
与聚合函数的不同之处是:对于每个组返回多⾏,⽽聚合函数对于每个组只返回⼀⾏基本语法: ‹分析函数› over (partition by ‹⽤于分组的列名› order by ‹⽤于排序的列名›)。
语法中的‹分析函数›主要由序列函数(rank、dense_rank和row_number等组成)与聚合函数(sum、avg、count、max和min等)作为窗⼝函数组成。
从窗⼝函数组成上看,它是group by 和 order by的功能组合,group by分组汇总后改变了表的⾏数,⼀⾏只有⼀个类别,⽽partiition by则不会减少原表中的⾏数。
恰如窗⼝函数的组成,它同时具有分组和排序的功能,且不减少原表的⾏数。
OVER 关键字表⽰把函数当成窗⼝函数⽽不是聚合函数。
SQL 标准允许将所有聚合函数⽤做窗⼝函数,使⽤ OVER 关键字来区分这两种⽤法。
2、窗⼝函数——开窗OVER 关键字后的括号中经常添加选项⽤以改变进⾏聚合运算的窗⼝范围。
如果 OVER 关键字后的括号中的选项为空,则窗⼝函数会对结果集中的所有⾏进⾏聚合运算。
分析函数 over(partition by 列名 order by 列名 rows between 开始位置 and 结束位置)为什么叫开窗呢?因为在over()括号中的,partition() 函数可以将查询到的数据进⾏单独开⼀个窗⼝处理。
譬如,查询每个班级的学⽣的排名情况,查询每个国家的历年⼈⼝等,诸如此类,都是在查询到的每⼀个班级、每⼀个国家中都开⼀个窗⼝,单独去执⾏命令。

oracle分析函数Oracle数据库提供了强大的分析函数,这些函数可以用于执行高级数据分析,并得出有关数据集的统计信息。
以下是一些常用的Oracle分析函数:1.ROW_NUMBER(函数ROW_NUMBER(函数返回一个表示每行排序位置的数字。
它通常与ORDERBY子句一起使用,以确定每行的位置。
例如,以下查询将为每个销售订单返回一个唯一的数字,并按订单日期进行排序:```SELECT order_id, order_date, ROW_NUMBER( OVER (ORDER BY order_date) as row_numFROM sales_orders;```2.RANK(函数RANK(函数用于计算一组值的排名。
它将返回一个表示每个值排名的数字,如果有重复的值,则会跳过下一个排名。
例如,以下查询将为每个销售订单返回一个唯一的数字,并按订单总额进行排名:```SELECT order_id, order_total, RANK( OVER (ORDER BYorder_total DESC) as rank_numFROM sales_orders;```3.DENSE_RANK(函数DENSE_RANK(函数类似于RANK(函数,但它不会跳过下一个排名。
如果有两个值具有相同的排名,则它们都将返回相同的排名。
例如,以下查询将为每个销售订单返回一个唯一的数字,并按订单总额进行排名:```SELECT order_id, order_total, DENSE_RANK( OVER (ORDER BY order_total DESC) as dense_rank_numFROM sales_orders;```G(函数和LEAD(函数LAG(函数和LEAD(函数用于访问当前行前一个或后一个行的数据。
例如,以下查询将为每个销售订单返回一个唯一的数字,并显示前一个订单的订单日期和后一个订单的订单日期:```SELECT order_id, order_date, LAG(order_date) OVER (ORDER BY order_date) as prev_order_date,LEAD(order_date) OVER (ORDER BY order_date) asnext_order_dateFROM sales_orders;```5.SUM(函数和AVG(函数SUM(函数和AVG(函数用于计算一组值的总和和平均值。
Oracle analysis function(Oracle分析函数)ORACLE advanced function application- grouping function1, ROLLUPTotal, subtotal -- statistical standards and the corresponding dimension of the packet- decrease from right to left: group by rollup (a, B, c): A, B, C; a, B (C; a (b total), C subtotal total);--1)CALL VPD_PKG.SET_CONTEXT_COMPID ('-1');SELECT, A.VPD_COMPID, TO_CHAR (A.TTIME,'MM'), COUNT (*)FROM XTBILL2011 AGROUP, BY, ROLLUP (A.VPD_COMPID, TO_CHAR (A.TTIME,'MM'));--2) partial rollup groupingFor after grouping, sum of a.typeidSELECT, A.DWDH, A.YEAR, A.TYPEID, COUNT (*)FROM XTYWBILL AGROUP, BY, A.DWDH, A.YEAR, ROLLUP (A.TYPEID);2, CUBE--rollup can only "right to left", such as the need for a full range of dimensions for statistics, you need to use the cube function--1)SELECT, A.VPD_COMPID, TO_CHAR (A.TTIME,'MM'), COUNT (*)FROM XTBILL2011 AGROUP, BY, CUBE (A.VPD_COMPID, TO_CHAR (A.TTIME,'MM'));--2) cube: can summaries and subtotals do not need to remove some.SELECT, A.VPD_COMPID, TO_CHAR (A.TTIME,'MM'), COUNT (*)FROM XTBILL2011 AGROUP, BY, A.VPD_COMPID, CUBE (TO_CHAR (A.TTIME,'MM'));3, GROUPING SETS- Description: focus only on some dimensions of the single packet, subtotal--group, by, grouping, sets (a, B, c) are equivalent to group,by, a, group, by, B, group, by, C- these three groups of union all results--1)SELECT, A.VPD_COMPID, TO_CHAR (A.TTIME,'MM'), COUNT (*) FROM XTBILL2011 AGROUP, BY, GROUPING, SETS (A.VPD_COMPID, TO_CHAR(A.TTIME,'MM'));--2) partial grouping sets grouping- sum based on group by, only pay attention to the subtotal SELECT, A.DWDH, A.YEAR, A.TYPEID, COUNT (*)FROM XTYWBILL AGROUP, BY, A.DWDH, GROUPING, SETS (A.YEAR, A.TYPEID); SELECT, A.VPD_COMPID, TO_CHAR (A.TTIME,'MM'), COUNT (*) FROM XTBILL2011 AGROUP, BY, A.VPD_COMPID, GROUPING, SETS (TO_CHAR(A.TTIME,'MM'));4, CUBE, ROLLUP as the parameters of GROUPING SETS--grouping sets operations are grouped only on single columns without providing aggregate functionality, and if grouping sets is required, aggregate functionality is provided,- then you can use rollup or cube as the parameters of the grouping sets, such as the following statement to provide aggregate functionality:SELECT, A.VPD_COMPID, TO_CHAR (A.TTIME,'MM'), AS, TTIME, COUNT (*)FROM XTBILL2011 AGROUP, BY, GROUPING, SETS (ROLLUP (A.VPD_COMPID), ROLLUP (TO_CHAR (A.TTIME,'MM'));This statement yields two total rows, because rollup or cube is the parameter of grouping sets, which is equivalent to eachUnion all for --rollup and cube operations. So the above statement is equivalent to:SELECT, A.VPD_COMPID, NULL, AS, TTIME, COUNT (*)FROM XTBILL2011 AGROUP BY ROLLUP (A.VPD_COMPID)UNION ALLSELECT, NULL, TO_CHAR (A.TTIME,'MM'), COUNT (*)FROM XTBILL2011 AGROUP, BY, ROLLUP (TO_CHAR (A.TTIME,'MM'));5, combination column grouping brief introduction:- grouping methods: rollup (a, B, c), <=>group, by, a, B, C, group, by, a, B, group, by, null- grouping methods: rollup (a, (B, c)), <=>group, by, a, B, C, group, by, a, group, by, null- grouping mode: rollup (a, B),汇总(C)< = >组,B、C组,B;;组,C组由;组;C组为空;——分组方式:汇总(A,B),(C)分组集< = >组,B、C组,C;C 组的;——分组方式:汇总(一),汇总(B),汇总(C)<= >组由;组B;C组;组的,B组,C;;组B、C;A,B,C组;组由空6、分组函数——为了区别哪些是小计,分组函数派上用场了!选择a.vpd_compid,to_char(a.ttime,'mm '),计数(*),分组(a.vpd_compid),分组(to_char(a.ttime,'mm ')),解码(分组(a.vpd_compid),1,“所有单位',a.vpd_compid)vpd_compid,解码(to_char(a.ttime,'mm '),1,“所有月份',to_char(a.ttime,'mm '))时间从xtbill2011一组汇总(a.vpd_compid,to_char(a.ttime,'mm '));——过滤某些分组结果选择a.vpd_compid,to_char(a.ttime,'mm '),计数(*),分组(a.vpd_compid),分组(to_char(a.ttime,'mm ')),解码(分组(a.vpd_compid),1,“所有单位',a.vpd_compid)vpd_compid,解码(to_char(a.ttime,'mm '),1,“所有月份',to_char(a.ttime,'mm '))时间从xtbill2011一组汇总(a.vpd_compid,to_char(a.ttime,'mm '))具有分组(a.vpd_compid)= 1或分组(to_char(a.ttime,'mm '))= 0;7、grouping_id函数——可用汇总或立方体与grouping_id组合运用,过滤出想要的分组统计信息选择a.vpd_compid,to_char(a.ttime,'mm”),grouping_id (a.vpd_compid,to_char(a.ttime,'mm ')),计数(*)从xtbill2011一集团通过立方体(a.vpd_compid,to_char(a.ttime,'mm '))有grouping_id(a.vpd_compid,to_char(a.ttime,'mm '))= 2;——1,2,3,0——grouping_id(A,B,C)过滤分组结果分组级别位向量grouping_id结果A,B,C 0 0 0 0A,B 0 0 1 10,1,1,3汇总1 1 1 78、group_id函数——判断重复的分组选择a.vpd_compid,to_char(a.ttime,'mm”)为时间,group_id() ID,计数(*)从xtbill2011一通过分组套组(汇总(a.vpd_compid),汇总(to_char(a.ttime,'mm ')))有group_id() = 0;9、实例应用说明:下拉表;创建表T(order_date日期--订购日期order_no号--订购号order_book VARCHAR2(10),--订购书籍order_fee号--订单总金额order_num数);插入T选择to_date('2010-05-01 ','yyyy-mm-dd ')+水平,trunc(dbms_random。
oracle的分析函数和开窗函数over()⼀什么是分析函数1 概念 分析函数是Oracle专门⽤于解决复杂报表统计需求的功能强⼤的函数,它可以在数据中进⾏分组然后计算基于组的某种统计值,并且每⼀组的每⼀⾏都可以返回⼀个统计值。
2 和聚合函数的区别普通的聚合函数⽤group by分组,每个分组返回⼀个统计值,⽽分析函数采⽤partition by分组,并且每组每⾏都可以返回⼀个统计值。
3 开窗函数开窗函数指定了函数所能影响的窗⼝范围,也就是说在这个窗⼝范围中都可以受到函数的影响,有些分析函数就是开窗函数。
4 分析函数语法function_name (<argument>,<argument>...)OVER(<PARTITION-Clause><ORDER-BY-Clause><Windowing-Clause>)语法解释:1. function_name:对窗⼝中的数据进⾏操作,Oracle常⽤的分析函数有(这⾥就列举了⼀些常⽤的,其实有很多)①聚合函数sum:⼀个组中数据累积和min:⼀个组中数据最⼩值max:⼀个组中数据最⼤值avg:⼀个组中数据平均值count:⼀个组中数据累积计数②排名函数 row_number( ):返回⼀个唯⼀的值,当碰到相同数据时,排名按照记录集中记录的顺序依次递增。
rank( ):返回⼀个唯⼀的值,当碰到相同的数据时,此时所有相同数据的排名是⼀样的,同时会在最后⼀条相同记录和下⼀条不同记录的排名之间空出排名。
dense_rank( ):返回⼀个唯⼀的值,当碰到相同数据时,此时所有相同数据的排名都是⼀样的,同时会在最后⼀条相同记录和下⼀条不同记录的排名之间紧邻递增。
2. over:关键字,⽤于标识分析函数3. Partition-Clause:分区⼦句,根据分区表达式的条件逻辑将单个结果集分成N组格式: partition by...... 4. Order-by-Clause:排序⼦句,⽤于对分区中的数据进⾏排序格式:order by......5. Windowing-Clause:窗⼝⼦句,⽤于定义function在其上操作的⾏的集合,即function所影响的范围格式:order by字段名 range|rows between边界规则1 AND边界规则2边界规则的取值如下表所⽰:可取值说明CURRENT ROW当前⾏N PRECEDING前N⾏UNBOUNDED PRECEDING⼀直到第⼀条记录N FOLLOWING后N⾏UNBOUNDED FOLLOWING⼀直到最后⼀条记录 注意:RANGE表⽰按照值的范围进⾏范围的定义,⽽ROWS表⽰按照⾏的范围进⾏范围的定义⼆分析函数和开窗函数实例1 创建表格并插⼊数据--创建表格create table student(name varchar2(20),city varchar2(20),age int,salary int)--插⼊数据INSERT INTO student(name,city,age,salary) VALUES('Kebi','JiangSu',20,3000);INSERT INTO student(name,city,age,salary) VALUES('James','ChengDu',21,4000);INSERT INTO student(name,city,age,salary) VALUES('Denglun','BeiJing',22,3500);INSERT INTO student(name,city,age,salary) VALUES('Yangmi','London',21,2500);INSERT INTO student(name,city,age,salary) VALUES('Nana','NewYork',22,1000);INSERT INTO student(name,city,age,salary) VALUES('Sunli','BeiJing',20,3000);INSERT INTO student(name,city,age,salary) VALUES('Dengchao','London',22,1500);INSERT INTO student(name,city,age,salary) VALUES('Huge','JiangSu',20,2800);INSERT INTO student(name,city,age,salary) VALUES('Pengyuyan','BeiJing',24,4500);INSERT INTO student(name,city,age,salary) VALUES('Baoluo','London',25,8500);INSERT INTO student(name,city,age,salary) VALUES('Huting','ChengDu',25,3000);INSERT INTO student(name,city,age,salary) VALUES('Hurenxiang','JiangSu',23,2500);表格创建完后,查看表格中的内容2 聚合函数和开窗函数①单⼀的聚合函数count 案例:如果要求出student表中⼀共多少⼈select count(name) from student得到的结果 从上表中看出,得到的结果是⼀个值,即为student表中⼀共12个⼈②聚合函数count和开窗函数over( )的联合使⽤ 案例:如果查询每个⼯资⼩于4000元的员⼯信息(姓名,城市以及⼯资),并在每⾏中都显⽰所有⼯资⼩于4000元的员⼯个数 第⼀种实现⽅式:通过⼦查询实现select name,city ,salary,(select count(salary) from student where salary <4000) ⼯资⼩于4000⼈数from studentwhere salary <4000第⼆种实现⽅式:开窗函数over( )实现select name, city, salary,count(*) over()from studentwhere salary <4000解释⼀下:开窗函数count(*)over( )是对查询结果的每⼀⾏都返回所有符合条件⾏的条数;over关键字后的括号中的选项为空,则开窗函数会对结果集中的所有⾏进⾏聚合运算;over关键字后的括号中的选项为不为空,则按照括号中的范围进⾏聚合运算。
Oracle分析函数与分组关键字的用法以下是我以前工作中做报表常用的几个函数,在此分享一下,希望对大家有帮助。
(一)分析函数●row_numberPurposeROW_NUMBER is an analytic function. It assigns a unique number to each row to which it is applied (either each row in the partition or each row returned by the query), in the ordered sequence of rows specified in the order_by_clause, beginning with 1.You cannot use ROW_NUMBER or any other analytic function for expr. That is, you can use other built-in function expressions for expr, but you cannot nest analytic functions.按部门分组后根据工资排序,序号rn特征:连续、无并列select t.*, row_number() over(partitionby t.deptno orderby sal desc) rn from emp t;●rankPurposeRANK calculates the rank of a value in a group of values. Rows with equal values for the ranking criteria receive the same rank. Oracle then adds the number of tied rows to the tied rank to calculate the next rank. Therefore, the ranks may not be consecutive numbers.•As an aggregate function, RANK calculates the rank of a hypothetical row identified by the arguments of the function with respect to a given sort specification. The arguments of the function must all evaluate to constant expressions within each aggregate group, because they identify a single row within each group. The constant argument expressions and the expressions in the ORDER BY clause of the aggregate match by position. Therefore, the number of arguments must be the same and their types must be compatible.As an analytic function, RANK computes the rank of each row returned from a query with respect to the other rows returned by the query, based on the values of the value_exprs in the order_by_clause.按部门分组后根据工资排序,序号rn特征:不连续、有并列select t.*, rank() over(partitionby t.deptno orderby sal desc) rn from emp t;dense_rankPurposeDENSE_RANK computes the rank of a row in an ordered group of rows. The ranks are consecutive integers beginning with 1. The largest rank value is the number of unique values returned by the query. Rank values are not skipped in the event of ties. Rows with equal values for the ranking criteria receive the same rank.As an aggregate function, DENSE_RANK calculates the dense rank of a hypothetical row identified by the arguments of the function with respect to a given sort specification. The arguments of the function must all evaluate to constant expressions within each aggregate group, because they identify a single row within each group. The constant argument expressions and the expressions in the order_by_clause of the aggregate match by position. Therefore, the number of arguments must be the same and types must be compatible.As an analytic function, DENSE_RANK computes the rank of each row returned from a query with respect to the other rows, based on the values of the value_exprs in the order_by_clause.按部门分组后根据工资排序,序号rn特征:连续、有并列select t.*, dense_rank() over(partitionby t.deptno orderby sal desc) rn from emp t;(二)分组函数根据查询结果观察三者的区别,grouping sets用起来更灵活。
ORACLE_分析函数大全1.SUM:计算指定列的总和。
用法:SUM(column) OVER (PARTITION BY expression ORDER BY expression)2.AVG:计算指定列的平均值。
用法:AVG(column) OVER (PARTITION BY expression ORDER BY expression)3.COUNT:计算指定列的记录数。
用法:COUNT(column) OVER (PARTITION BY expression ORDER BY expression)4.MAX:计算指定列的最大值。
用法:MAX(column) OVER (PARTITION BY expression ORDER BY expression)5.MIN:计算指定列的最小值。
用法:MIN(column) OVER (PARTITION BY expression ORDER BY expression)6.FIRST_VALUE:计算指定列的第一个值。
用法:FIRST_VALUE(column) OVER (PARTITION BY expression ORDER BY expression)ST_VALUE:计算指定列的最后一个值。
用法:LAST_VALUE(column) OVER (PARTITION BY expression ORDER BY expression)8.LEAD:返回指定行后的值。
用法:LEAD(column, offset, default) OVER (PARTITION BY expression ORDER BY expression)G:返回指定行前的值。
用法:LAG(column, offset, default) OVER (PARTITION BY expression ORDER BY expression)10.RANK:计算指定列的排名(相同值有相同的排名,相同排名后续排名跳过)。
Oracle10gR2分析函数(中英对照版)Orac c le100gR2分析函函数(Translat t ing By ca a izhuoyi)说明明:1、 2、 1 A Ana agg callewind calc of ro 分析分组⼀⾏物理Ana ORD befo in th 分析有wh 数只Ana repo 分析anaana原⽂中底⾊原⽂中淡蓝⾊nalytic Fu alytic function regate funct ed a window dow of rows culations for ows or a log 析函数通过将组返回多⾏值⾏都对应有⼀理⾏进⾏度量alytic functio DER BY claus ore the analy he select list 析函数是查询here ,gro 只能⽤于sel alytic functio orting aggre 析函数通常⽤alytic_fun alytic_fun 为黄的部分翻⾊字体的⽂字unctionsns compute tions in that w and is def s is defined. the current ical interval 将⾏分组后,再值。
分析函数根⼀个在⾏上滑量,也可以使ns are the la se. All joins ytic function t or ORDER B 询中除需要在up by ,和h ect 列或ord ns are comm gates. ⽤于计算数据nction::=nction([ 翻译存在商榷字,不宜翻译an aggrega they return fined by the The window row. Window such as tim 再计算这些分根据analyt 滑动的窗⼝。
该使⽤逻辑区间ast set of op and all WHER s are proces BY clause.在最终处理的o having ⼦句der by ⼦句monly used 据累积值,数=arguments 榷之处,请⼤⼤家踊跃提意意见;译,保持原样样。