Fortran进行批处理的方法剖析
- 格式:doc
- 大小:51.00 KB
- 文档页数:9



Fortran中批量处理文件的方法总结—循环读取目录下的所有符合条件的文件=====================一、简单的介绍在一年之前,我写过一个程序,主要是对Micaps资料进行批量处理,将逐日资料处理为旬、月的数据,在那个程序中,始终有一个问题困扰我,就是如何自动生成该读取的下一个文件名,这使我真正开始关注fortran中的批处理,时隔一年,决定写下这些文字,将我用到的一些fortran批处理的方法和大家共享,交流。
对于那些只要会用程序,不求其中原理的朋友,请马上跳过这些文字,直接去下载附件吧!程序里有使用说明,但是,如果你不懂原理,估计现成的程序你使用起来也会碰壁哦!这里所说的批处理是指对某一个目录下的指定后缀的文件的批量读取和处理。
我总结的批处理方法大概可以用下面这个示意图来说明:|||将文件目录写入一个文本文件,供fortran循环读取|————手动输入文件名|————运行程序之前命令行工具导出文件名|————程序运行后,未开始计算之前,生成文件名| ————调用CMD命令生成| ————GETFILEINFOQQ方法生成| ————调用WIN32API生成||在程序运行时动态生成文件名||对于第一种方法,我将主要介绍如何将目录写入文件,然后举出一个小的示例来验证。
第二种方法主要是说明其思路。
二、方法的介绍1、将文件目录写入一个文本文件,供fortran循环读取1.1、手动输入文件名这是最基本的方法啦,如果文件个数不多,而且文件名中包含了空格等特殊字符的话,建议使用这种方法,在这里就不多说啦,至于在fortran中的处理,等几个小方法介绍完之后会有一个例子来说明。
1.2、运行程序之前命令行工具导出文件名这是一个既高效又保险的方法,主要思路就是通过强大的CMD命令列出目录下的文件到一个指定的文件中,然后由fortran去循环读取该文件中的文件名信息,从而批量处理。
a、从运行工具打开你的CMD窗口;b、转到要处理的当前目录(可省略):CD /d 路径,如:CD /d e:\test这样可以快速到达e:\test目录c、使用DIR命令列出文件目录信息到指定的文件,通常使用的Dir *.*>新文件名这个命令在这里已经不能满足要求,因为会列出一堆对于我们处理而言无用的信息,现在要使用的命令是:DIR /b filter>newfile注意,其中的filter为文件筛选,必须自己修改为所需的,比如你可以把它改成*.txt,这样,就会列出当前目录下的所有txt结尾的文件了。

Fortran LU分解法是一种用于解线性方程组的算法,它可以将一个方阵分解为一个下三角矩阵和一个上三角矩阵的乘积。
这种分解方法可以用于高斯消元法、最小二乘法和特征值计算等多种应用中。
在Fortran中,LU分解可以通过调用预先定义好的子程序实现。
下面是一个示例程序,演示如何使用Fortran LU分解法解一个线性方程组:program LUdecompositionimplicit noneinteger, parameter :: n = 3real, dimension(n,n) :: A, L, Ureal, dimension(n) :: b, xinteger :: i, j, k! Input matrix A and vector bA = reshape([2.0, 1.0, 1.0, 6.0, 2.0, 1.0, -2.0, -1.0, 3.0], shape(A))b = [1.0, 2.0, 3.0]! LU decomposition of Acall lu(n, A, L, U)! Solve Ax=b using forward and backward substitutiondo i = 1, nx(i) = b(i) / L(i,i)end dodo i = n, 1, -1do j = i+1, nx(i) = x(i) - U(i,j) * x(j)end dox(i) = x(i) / U(i,i)end do! Output solution xprint *, "Solution: ", xend program LUdecomposition在上面的程序中,我们首先定义了一个3x3的矩阵A和一个3x1的向量b。
然后,我们调用预先定义的子程序lu对矩阵A进行LU分解,得到下三角矩阵L和上三角矩阵U。
接下来,我们使用前向和后向代入法解方程组Ax=b,得到解向量x。



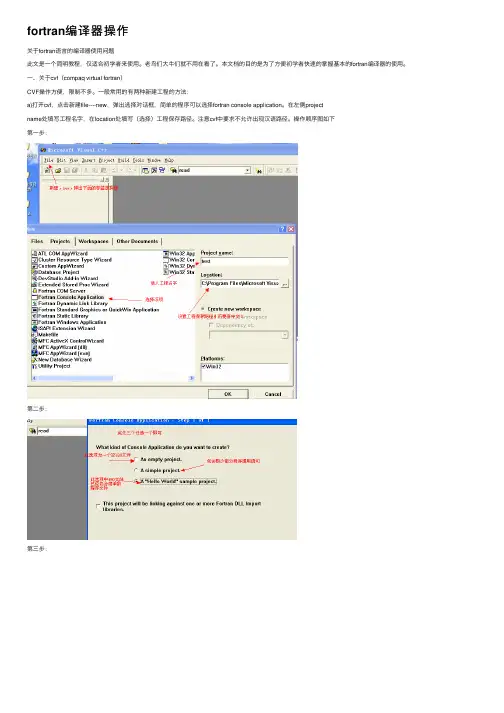
fortran编译器操作关于fortran语⾔的编译器使⽤问题此⽂是⼀个简明教程,仅适合初学者来使⽤。
⽼鸟们⼤⽜们就不⽤在看了。
本⽂档的⽬的是为了⽅便初学者快速的掌握基本的fortran编译器的使⽤。
⼀、关于cvf(compaq virtual fortran)CVF操作⽅便,限制不多。
⼀般常⽤的有两种新建⼯程的⽅法:a)打开cvf,点击新建file----new,弹出选择对话框,简单的程序可以选择fortran console application。
在左侧projectname处填写⼯程名字,在location处填写(选择)⼯程保存路径。
注意cvf中要求不允许出现汉语路径。
操作顺序图如下第⼀步:第⼆步:第三步:第四步:运⾏⾄此,所有步骤完成。
b)直接打开cvf,点击新建⽂档(new)然后单击保存,弹出保存对话框,选择保存路径及⽂件夹,⽂件名改为“⼯程名.f90”格式此处注意如果是fortran⾃由格式,请保存为*.f90或*.f95格式,如果是固定格式请保存为*.for或*.f格式。
因为编译器是根据后缀的不同调⽤不同的语⾔编译器,否则将出错。
保存⽂件的路径和⽂件夹即为该⼯程所在的路径和⽂件夹。
同样不能有汉语。
⽰意图如下:第⼀步第⼆步、第三步、⾄此,所有的⼯程完成。
⼆、关于CVF的调试(debug)在相应代码编辑框左侧发灰⾊的竖线部分,⿏标变为反三⾓⽅向的形状时即可右键⿏标,选择insert/remove BreakPoint选项,在代码左侧可以看到⼀个红⾊的标⽰(代码⾏尽量不要设在代码最后。
可以设置到⾃认为可能发⽣错误的地⽅。
或者尽量靠前设置),此时就可以按F5进⼊调试状态。
可以在watch窗⼝查看各个变量,数组的值与内容。
按F11进⾏单步运⾏。
查看错误出处。
具体的更细致的调试,请参看相关⽂献或书籍。
这类书籍不少。
具体操作如下:6三、关于IVF (intel virtual fortran )编译器的使⽤由于ivf 要求⽐较严格,且⾃⾝不带IDE 窗⼝。

ABAQUS与FORTRA N论坛问题小结Q:索了一下论坛发现以前的问题都是不同类型的子程序,如UEL, UMA T...这样把它们放在一个.for文件里不会有误会,但是如果都是U EL的话,该怎么识别呢?A:subrout ine Umat()IF (CMNAME(1:4) .EQ. 'MAT1') THENCAL LUMAT_MA T1(argumen t_list)ELSE IF(CMNAME(1:4) .EQ. 'MAT2') THENCAL LUMAT_MA T2(argumen t_list)END IF上面是区分不同umat的方法,区分uel应该类似吧Q:行abaqus的时候出现这样的提示"Problem duringcompila tion - df.exe not found in PA TH."请问这是什么原因.A: 就是说找不到用于编译的df.exe文件(好像是Fort ran的编译运行文件),在Window s控制面板的“系统”里,打开高级属性,将系统的PAT H添加上Fo rtran的路径,最好也一并把I NCLUDE和LIB也都添加上对应的FORTRA N的路径。
Q: 如何在ABAQ US中调用用户子程序UM A TA:abaqusjob=*** user=*.for or *.objA: 装好fortr an编译器的前提下,有两种方式:1、命令行:abaqusjob=*.inp user=*.for或 abaqusjob=*.inp user=*.obj (可以由*.f90编译后得到)2、菜单格式:先运行CAE,在genera l设置中可以指定Umat用户子程序A: job=jobname user=yourfor tran.for(其它类型子程序)A:如果是本构的二次开发:*materia l, userQ: abaqusjob=job-name user={source-file | object-file}source-file和ob ject-file各是什么?A: fortran的源文件(.for)或者目标文件(.o)在comman d下面输入以上命令行就可以正常运行.用户子程序再调用别的for tran程序时,要加入abaq us 子程序中的in clude'ABA_PAR AM.INC'。

为了减少重复回答问题,特编此帖,并不定期添加和更新内容。
错误难免,欢迎讨论,仅供参考。
很多人问哪里可以找到Fortran 编译器,有不少热心学友提供网址,检验过这些链接,但是它们不一定总有效。
Fortran 编译器下载:CVF特汇集在这里。
虽然俺FTN95 (License: Free for personal use)以下操作,如无特别说明,都是以为例。
1. 如何加大Stack size?选Project => Settings => Link => Category: Output Stack allocationsReserve: 这里填新值(默认为1M若需要10M则填)2. 如何用Fortran 批量生成文件?设要生成4000个文件,文件名为AA1-AA4000,如何写循环生成文件命令呢?用内部文件:character(len=80) :: filename,forminteger :: ido i=1,4000select case (i)case (1:9)write(form,'(i1)') icase (10:99)write(form,'(i2)') i=>, 而不用写4000 次writecase (100:999)write(form,'(i3)') icase (1000:9999)write(form,'(i4)') iend selectwrite(filename,*) "AA",trim(form),".TXT"open(10,file=filename)write(10,*) iclose(10)end dostopend3.如何用Fortran 动态生成输出格式?设有一个数组data(100),输出时,希望每行输出num个数,而num由用户输入,如何实现?用内部文件:character(len=80) :: formreal :: data(100)integer :: i,numdata = (/ (i,i=1,100) /)/read(*,*) numwrite(form,*) "(",num,""write(*,form) data stopend4.MS 是不是很垃圾?是垃圾,其中Bug 太多,多到不可用的地步!在这个主题里,换了CVF后问题就没了的人已有相当的数目。

Fortran 批量处理文件程序中需要读取或处理大量文件的时候,在代码中写入大量的open语句就显得很笨重,如果文件很多(比如有1000个文件),这种方法根本不可行。
针对这种情况,介绍两种解决方法。
方法一:考虑如下情形:假设存在100个文件,分别存储了1900-1999年的降雨量,现在需要计算着100年的总降雨量。
文件名为:前缀+年份+后缀,例如:降雨量-1900.dat、降雨量-1901.dat 。
由于文件名是有规律的,仅年份变化,可以用循环来一次读取文件。
program testinteger ireal s, acharacter(20):: filename='降雨量-1234.dat's = 0.0do i=1900, 1999!内部文件读写,将filename第8-11字符换为相应年份write(filename(8:11),'(i4)') iopen(11,file=filename)read(11,*) aclose(11)s = s + aend doend program这种方法优点是可以按顺序读取文件,缺陷也很明显,只能处理有规律的文件名。
方法二:如果文件名没有规律,使用另一种方法。
先用命令行指令将需要处理的文件的文件名写入另外一个文件当中:call system ('dir *.txt /b > 1.dat' )上述代码含义:找出工作目录下所有txt文件,将其文件名存入1.dat当中,注意二者的后缀不应相同(txt, dat)。
为了避免错误,需要事先删除无用的txt文件。
修改命令行指令,可以找出任意符合条件的文件,比如找出上例中存储降雨量的文件:call system ('dir 降雨量-*.dat /b > 1.txt' )完整代码如下:program testinteger ireal s, acharacter(512):: filename!文件1.dat中存储工作目录下所有txt文件列表call system ('dir *.txt /b > 1.dat' )s = 0.0open(10,file='1.dat')do!读取文件名read(10,'(a)',iostat=i) filenameif(i/=0) exitopen(11,file=filename)read(11,*) aclose(11)s = s + aend doclose(10,status='delete') !关闭并删除文件1.datend program方法二优点是不要求文件名称有很强规律性,缺点是处理每个文件的顺序是未知的。
!此程序为EOF程序! 运行时要改动前面的空间、时间格点以及文件路径,ks和kvt根据自己的需要进行改动!程序中自动去除缺省值并将其写回生成数据(生成数据中缺省值为-9999.0)!对程序中data_in到F的传递进行调整后此程序也可用于s-eof和mv-eof!PROGRAM EOFIMPLICIT NONEINTEGER,PARAMETER :: nt=12,nx=23,ny=34 ! you need change,NT为时间长度INTEGER,PARAMETER ::M=nt,KS=0,KVT=8 !kvt为输出的模态数! KS的设置:ks>0 计算前先将数据标准化,! ks=0时取距平,ks<0时不进行这一步处理INTEGER :: i,j ,MNH,N ,K,IM , m1REAL, allocatable,dimension(:,:,:)::DA TA_INREAL, allocatable,dimension(:,:)::F,S,ER,A,S1,F1CHARACTER(LEN=20) :: NOW , TRACKREAL :: land(nx,ny), D,A VE,PT(NX,NY,kvt) ,ran1TRACK='E:\aat\EA\' !输出的目标文件夹,默认为程序所在文件夹call time(now)print*, now!!1111111111读入数据并去掉缺省值11111111111111ALLOCA TE(DA TA_IN(NX,NY,NT))OPEN(1,file='E:\aat\EA\aat.eof.dat',access='direct',recl=nx*ny*nt) !****修改路径READ(1,rec=1) (((data_in(I,J,K),I=1,nx),J=1,ny),K=1,nt)CLOSE(1)!注意数据排列顺序!************做纬度加权平均,中、高纬度使用,热带或小范围不必******(未验证)!do j=1,ny!z(j)=0.+(real(j)-1.)*2.5/180.*3.1415926575 !使用时需要改动格距和起始纬度!data_in(:,j,:)=data_in(:,j,:)*sqrt(cos(z(j)))!enddoland=0.0N=NX*NYDO I=1,nxDO J=1,nyDO K=1,ntIF(abs(data_in(I,J,K))>99999.0)then !判断缺省值(注意条件)land(I,J)=-9999.0N=N-1EXITENDIFENDDOENDDOENDDOALLOCA TE(F(1:N,1:M))im=0DO I=1,nxDO J=1,nyIF(land(I,J)/=-9999.0)thenim=im+1F(IM,1:m)=data_in(I,J,1:m)ENDIFENDDOENDDOprint*, '空间点数' , nx*ny, '非缺省值空间点数:',im,NDEALLOCA TE(DA TA_IN)MNH=min(N,M)ALLOCA TE( A(MNH,MNH))ALLOCA TE(S(MNH,MNH))ALLOCA TE(ER(mnh,6))!222222222222222222计算过程22222222222222222222222CALL TRANSF(N,M,F,KS) !根据KS的设置,-1时跳出,0时距平,1时标准化print*,"**"CALL FORMA(N,M,MNH,F,A) !求协方差矩阵Aprint*,"***"CALL JCB(MNH,A,S,0.0000001) !雅可比过关法求特征值特征向量print*,"****" !最后这个EPS的值控制计算精度,越小精度越高CALL ARRANG(MNH,A,ER,S) !按照特征值大小排序print*,"*****"DEALLOCA TE( A)CALL TCOEFF(KVT,N,M,MNH,S,F,ER) !给出时间序列和标准化的空间场print*,"******"ALLOCA TE(S1(MNH,MNH))ALLOCA TE(F1(N,M))!33333********数据输出**********333333333 !输出数据为标准化后的时间序列及相应的空间场!求时间序列的标准差,时间序列除以标准差,空间乘以该标准差IF (M>=N) THENDO K=1,KVTA VE=SUM(F(K,1:M))/REAL(M)F1(K,1:M)=F(K,1:M)-A VED= SQRT(SUM(F1(K,1:M)*F1(K,1:M))/REAL(M))F(K,1:M)= F(K,1:M)/D !时间S(K,1:N)= S(K,1:N)*D !空间ENDDOm1=0DO i=1,nxDO j=1,nyIF(land(i,j).eq.0.0)thenm1=m1+1PT(i,j,1:kvt)=S(1:kvt,m1)ELSEPT(i,j,1:kvt)=-9999.00ENDIFENDDOENDDOOPEN (1,file=TRIM(track)//'pt.dat',access='direct',recl=NX*NY)DO k=1,KVTWRITE(1,rec=k)((PT(i,j,k),i=1,nx),j=1,ny)ENDDOCLOSE(1)OPEN (2,FILE=TRIM(track)//'PC.DA T',ACCESS='DIRECT',RECL=M)DO K=1,KVTWRITE(2,REC=K) ((F(K,1:M)))ENDDOCLOSE(2)ELSEDO K=1,KVTA VE=SUM(S(1:M,K))/REAL(M)S1(1:M,K)=S(1:M,K)-A VED= SQRT( SUM(S1(1:M,K)*S1(1:M,K))/REAL(M))S(1:M,K)=S(1:M,K)/D !时间F(1:N,K)=F(1:N,K)*D !空间ENDDOm1=0DO i=1,nxDO j=1,nyIF(land(i,j).eq.0.0)thenm1=m1+1PT(i,j,1:kvt)=F(m1,1:kvt)ELSEPT(i,j,1:kvt)=-9999.00ENDIFENDDOENDDOOPEN (1,file=TRIM(track)//'PT.dat',access='direct',recl=NX*NY)DO k=1,KVTWRITE(1,rec=k) ((PT(i,j,k),i=1,nx),j=1,ny)ENDDOCLOSE(1)OPEN (2,FILE=TRIM(track)//'PC.DA T',ACCESS='DIRECT',RECL=KVT) DO K=1,MWRITE(2,REC=K) ((S(K,1:KVT)))ENDDOCLOSE(2)OPEN(3,FILE=TRIM(TRACK)//'PC10.TXT')DO K=1,MWRITE(3,'(8F16.4)') S(K,1:KVT)ENDDOENDIFcall time(now)print*, now ,'OK!'ENDPROGRAM!######################################!! !! 以下为计算过程调用的5个子程序!! !!######################################!!11111111111111111!根据KS的设置进行初步处理SUBROUTINE TRANSF(N,M,F,KS)IMPLICIT NONE! THIS SUBROUTINE PROVIDES INITIAL F BY KSINTEGER ::KS, I,M,NREAL ::F(N,M),A VF(N),DF(N)A VF=0.0DF=0.0IF(KS>0 .or. KS ==0) then !根据KS的设置,-1时跳出,0时距平,1时标准化DO I=1,NA VF(I)=SUM(F(I,1:M)/M)F(I,1:M)=F(I,1:M)-A VF(I)ENDDOIF(KS==0) RETURNDO I=1,NDF(I)=SUM(F(I,1:M)*F(I,1:M))DF(I)=SQRT(DF(I)/M)F(I,1:M)=F(I,1:M)/DF(I)ENDDOENDIFRETURNEND!!22222222222222222222222222222222求协方差矩阵ASUBROUTINE FORMA(N,M,MNH,F,A)IMPLICIT NONE! THIS SUBROUTINE FORMS A BY FINTEGER :: I,J,M,N,MNHREAL :: F(N,M),A(MNH,MNH)A=0.0IF(M<N) THENDO I=1,MDO J=I,MA(I,J)=SUM(F(1:N,I)*F(1:N,J))A(J,I)=A(I,J)ENDDOENDDOELSEDO I=1,NDO J=I,NA(I,J)=SUM(F(I,1:M)*F(J,1:M))A(J,I)=A(I,J)ENDDOENDDOENDIFRETURNEND!!333333333333333333333333333333333333333雅可比过关法求特征值特征向量SUBROUTINE JCB(N,A,S,EPS)IMPLICIT NONE! THIS SUBROUTINE COMPUTS EIGENV ALUES! AND EIGENVECTORS OF A RETUERN SINTEGER :: I,J,K,N,L ,I1REAL ::A(N,N),S(N,N)REAL :: EPS,G,S1,S2,S3,V1,V2,V3,ST,CT,IP,IQ,U,IQ1S=0.DO 30 I=1,NDO 30 J=1,IIF(I-J) 20,10,2010 S(I,J)=1.GO TO 3020 S(I,J)=0.S(J,I)=0.30 CONTINUEG=0.DO 40 I=2,NI1=I-1DO 40 J=1,I140 G=G+2.*A(I,J)*A(I,J)S1=SQRT(G)print*,"999"S2=EPS/FLOA T(N)*S1S3=S1L=050 S3=S3/FLOA T(N)60 DO 130 IQ=2,NIQ1=IQ-1DO 130 IP=1,IQ1IF(ABS(A(IP,IQ)).LT.S3) GOTO 130L=1V1=A(IP,IP)V2=A(IP,IQ)V3=A(IQ,IQ)U=0.5*(V1-V3)IF(U.EQ.0.0) G=1.IF(ABS(U).GE.1E-10) G=-SIGN(1.,U)*V2/SQRT(V2*V2+U*U)ST=G/SQRT(2.*(1.+SQRT(1.-G*G)))CT=SQRT(1.-ST*ST)!PRINT*,V2*V2+U*U,1.-G*G,1.-ST*STDO 110 I=1,NG=A(I,IP)*CT-A(I,IQ)*STA(I,IQ)=A(I,IP)*ST+A(I,IQ)*CTA(I,IP)=GG=S(I,IP)*CT-S(I,IQ)*STS(I,IQ)=S(I,IP)*ST+S(I,IQ)*CT110 S(I,IP)=GDO 120 I=1,NA(IP,I)=A(I,IP)120 A(IQ,I)=A(I,IQ)G=2.*V2*ST*CTA(IP,IP)=V1*CT*CT+V3*ST*ST-GA(IQ,IQ)=V1*ST*ST+V3*CT*CT+GA(IP,IQ)=(V1-V3)*ST*CT+V2*(CT*CT-ST*ST)A(IQ,IP)=A(IP,IQ)130 CONTINUEIF(L-1) 150,140,150140 L=0GO TO 60150 IF(S3.GT.S2) GOTO 50RETURNEND!!444444444444444444444444444444444444444按照特征值大小排序SUBROUTINE ARRANG(MNH,A,ER,S)IMPLICIT NONE! THIS SUBROUTINE PROVIDES A SERIES OF EIGENV ALUES ! FROM MAX TO MININTEGER :: MNH,K1,K2,I ,MNH1REAL :: A(MNH,MNH),ER(mnh,6),S(MNH,MNH)REAL :: TR,CTR=0.0DO I=1,MNHTR=TR+A(I,I)ER(I,1)=A(I,I)ENDDOMNH1=MNH-1DO K1=MNH1,1,-1DO K2=K1,MNH1IF(ER(K2,1).LT.ER(K2+1,1)) THENC=ER(K2+1,1)ER(K2+1,1)=ER(K2,1)ER(K2,1)=CDO I=1,MNHC=S(I,K2+1)S(I,K2+1)=S(I,K2)S(I,K2)=CENDDOENDIFENDDOENDDOER(1,2)=ER(1,1)DO I=2,mnhER(I,2)=ER(I-1,2)+ER(I,1)enddoCONTINUEer(:,5)=er(:,1)*sqrt(2/real(mnh))er(:,6)=er(:,5)/TR*100ER(:,3)=ER(:,1)/TR*100ER(:,4)=ER(:,2)/TR*100OPEN(119,file="E:\aat\EA\eigenvalues.txt")DO i=1,mnhWRITE(119,'(2f16.2,4f16.6)') er(i,1),er(i,2),er(i,3),er(i,4),er(i,5),er(i,6)ENDDOCLOSE(119)RETURNEND!!555555555555555555555555555求Y!给出时间序列和标准化的空间场SUBROUTINE TCOEFF(KVT,N,M,MNH,S,F,ER)IMPLICIT NONE! THIS SUBROUTINE PROVIDES EIGENVECTORS (M.GE.N,SA VED IN S;! M.L T.N,SA VED IN F) AND ITS STANDARD TIME COEFFICENTS SERIES (M.GE.N, ! SA VED IN F; M.LT.N,SA VED IN S)INTEGER :: i,j,k,M,N,JS ,MNH,IS,KVTREAL :: S(MNH,MNH),F(N,M),V(MNH),ER(mnh,6) REAL :: CDO J=1,KVTC=0.C=SUM(S(:,J)*S(:,J))C=SQRT(C)S(:,J)=S(:,J)/CENDDOIF(N.LE.M) THENDO J=1,MV(1:N)=F(1:N,J)F(1:N,J)=0.DO IS=1,KVTF(IS,J)=SUM(V(1:N)*S(1:N,IS))ENDDOENDDOELSEDO I=1,NV(1:M)=F(I,1:M)F(I,1:M)=0.DO JS=1,KVTF(I,JS)=SUM(V(1:M)*S(1:M,JS))ENDDOENDDODO JS=1,KVTS(1:M,JS)=S(1:m,JS)*SQRT(ER(JS,1))F(1:N,JS)=F(1:N,JS)/SQRT(ER(JS,1))ENDDOENDIFRETURNEND。
Part_I_Fortran语言基础数值分析程序设计Part I F ortran语言基础COMPAQ VISUAL FORTRAN 6.50编译器的使用0.1 编译器简介高级语言以及汇编语言的程序代码在没有转换成机器代码前,计算机是无法执行的。
编译器的功能是将高级语言的程序代码翻译成计算机可执行的机器码,也就是生成扩展名为EXE, COM的文件。
0.2 Visual Fortran的使用Visual Fortran起源于Microsoft的Fortran PowerStation 4.0,这套工具后来卖给Digital公司继续开发,第二个版本称为Digital Visual Fortran 5.0,Digital 被Compaq并购之后,接下来的版本6.0和6.5称为Compaq Visual Fortran。
下面的介绍以Compaq Visual Fortran 6.5作范例。
Visual Fortran被组合在一个叫做Microsoft Visual Studio的图形接口开发环境中。
Visual Studio提供一个统一的使用接口,这个接口包括文字编辑功能、Project管理功能、调试工具等。
而编译器则被组合到Visual Studio中,VF和VC++使用相同的使用接口。
Visual Fortran 6.5除了完全支持Fortran 95的语法外,扩展功能方面提供了完整的Windows程序开发工具,专业版还含有IMSL数值计算连接库。
另外还可以和VC++直接互相连接使用,也就是把Fortran和C语言的程序代码混合编译成一个执行文件。
安装好Compaq Visual Fortran后,运行Developer Studio就可以开始编译Fortran程序了。
数值分析程序设计——Fortran基础运行Developer Studio启动Visual Fortran,默认程序名称为Compaq Visual Fortran 6.5选择File菜单中的New选项在弹出的对话框中,选择Project标签。
Fortran中批量处理文件的方法总结—循环读取目录下的所有符合条件的文件=====================一、简单的介绍在一年之前,我写过一个程序,主要是对Micaps资料进行批量处理,将逐日资料处理为旬、月的数据,在那个程序中,始终有一个问题困扰我,就是如何自动生成该读取的下一个文件名,这使我真正开始关注fortran中的批处理,时隔一年,决定写下这些文字,将我用到的一些fortran批处理的方法和大家共享,交流。
对于那些只要会用程序,不求其中原理的朋友,请马上跳过这些文字,直接去下载附件吧!程序里有使用说明,但是,如果你不懂原理,估计现成的程序你使用起来也会碰壁哦!这里所说的批处理是指对某一个目录下的指定后缀的文件的批量读取和处理。
我总结的批处理方法大概可以用下面这个示意图来说明:|||将文件目录写入一个文本文件,供fortran循环读取|————手动输入文件名|————运行程序之前命令行工具导出文件名|————程序运行后,未开始计算之前,生成文件名| ————调用CMD命令生成| ————GETFILEINFOQQ方法生成| ————调用WIN32API生成||在程序运行时动态生成文件名||对于第一种方法,我将主要介绍如何将目录写入文件,然后举出一个小的示例来验证。
第二种方法主要是说明其思路。
二、方法的介绍1、将文件目录写入一个文本文件,供fortran循环读取1.1、手动输入文件名这是最基本的方法啦,如果文件个数不多,而且文件名中包含了空格等特殊字符的话,建议使用这种方法,在这里就不多说啦,至于在fortran中的处理,等几个小方法介绍完之后会有一个例子来说明。
1.2、运行程序之前命令行工具导出文件名这是一个既高效又保险的方法,主要思路就是通过强大的CMD命令列出目录下的文件到一个指定的文件中,然后由fortran去循环读取该文件中的文件名信息,从而批量处理。
a、从运行工具打开你的CMD窗口;b、转到要处理的当前目录(可省略):CD /d 路径,如:CD /d e:\test这样可以快速到达e:\test目录c、使用DIR命令列出文件目录信息到指定的文件,通常使用的Dir *.*>新文件名这个命令在这里已经不能满足要求,因为会列出一堆对于我们处理而言无用的信息,现在要使用的命令是:DIR /b filter>newfile注意,其中的filter为文件筛选,必须自己修改为所需的,比如你可以把它改成*.txt,这样,就会列出当前目录下的所有txt结尾的文件了。
fortran 简明教程Fortran是世界上最早的高级程序设计语言之一,广泛应用于科学计算、工程和数值分析等领域。
以下是Fortran的简明教程:1. 程序结构:一个Fortran程序由不同的程序单元组成,包括主程序、子程序和模块等。
每个程序单元都以END结束。
主程序是程序的入口点,可以包含变量声明、执行语句和控制语句等。
子程序可以包含函数和子例程,用于执行特定的任务。
模块用于提供程序中的公共代码和数据。
2. 变量声明:在Fortran中,变量必须先声明后使用。
变量类型包括整数型、实数型、字符型等。
例如,声明一个整数型变量可以这样写:INTEGER :: x3. 执行语句:执行语句用于控制程序的流程和执行顺序。
Fortran提供了多种控制语句,如IF语句、DO循环、WHILE循环等。
例如,使用IF语句进行条件判断:IF (x > 0) THEN y = x x ELSE y = -x x END IF4. 输入输出:Fortran提供了基本的输入输出功能。
可以使用READ语句从标准输入读取数据,使用WRITE语句将数据输出到标准输出。
例如,读取一个实数并输出到屏幕:READ(,) x WRITE(,) x5. 数组和矩阵:Fortran支持一维和多维数组,以及矩阵运算。
例如,声明一个二维实数数组并赋值:REAL :: A(3,3) A =RESHAPE((/1,2,3,4,5,6,7,8,9/), (/3,3/))6. 子程序和模块:子程序可以用于封装特定的功能或算法,并在主程序中调用。
模块可以包含公共的函数、子例程和变量等,用于提供可重用的代码和数据。
7. 调试和优化:Fortran提供了多种调试工具和技术,如断点、单步执行、变量监视等。
还可以使用性能分析工具来检查程序的性能瓶颈并进行优化。
以上是Fortran的简明教程,希望能帮助您快速入门Fortran编程。
Fortran中批量处理文件的方法总结—循环读取目录下的所有符合条件的文件=====================一、简单的介绍在一年之前,我写过一个程序,主要是对Micaps资料进行批量处理,将逐日资料处理为旬、月的数据,在那个程序中,始终有一个问题困扰我,就是如何自动生成该读取的下一个文件名,这使我真正开始关注fortran中的批处理,时隔一年,决定写下这些文字,将我用到的一些fortran批处理的方法和大家共享,交流。
对于那些只要会用程序,不求其中原理的朋友,请马上跳过这些文字,直接去下载附件吧!程序里有使用说明,但是,如果你不懂原理,估计现成的程序你使用起来也会碰壁哦!这里所说的批处理是指对某一个目录下的指定后缀的文件的批量读取和处理。
我总结的批处理方法大概可以用下面这个示意图来说明:|||将文件目录写入一个文本文件,供fortran循环读取|————手动输入文件名|————运行程序之前命令行工具导出文件名|————程序运行后,未开始计算之前,生成文件名| ————调用CMD命令生成| ————GETFILEINFOQQ方法生成| ————调用WIN32API生成||在程序运行时动态生成文件名||对于第一种方法,我将主要介绍如何将目录写入文件,然后举出一个小的示例来验证。
第二种方法主要是说明其思路。
二、方法的介绍1、将文件目录写入一个文本文件,供fortran循环读取1.1、手动输入文件名这是最基本的方法啦,如果文件个数不多,而且文件名中包含了空格等特殊字符的话,建议使用这种方法,在这里就不多说啦,至于在fortran中的处理,等几个小方法介绍完之后会有一个例子来说明。
1.2、运行程序之前命令行工具导出文件名这是一个既高效又保险的方法,主要思路就是通过强大的CMD命令列出目录下的文件到一个指定的文件中,然后由fortran去循环读取该文件中的文件名信息,从而批量处理。
a、从运行工具打开你的CMD窗口;b、转到要处理的当前目录(可省略):CD /d 路径,如:CD /d e:\test这样可以快速到达e:\test目录c、使用DIR命令列出文件目录信息到指定的文件,通常使用的Dir *.*>新文件名这个命令在这里已经不能满足要求,因为会列出一堆对于我们处理而言无用的信息,现在要使用的命令是:DIR /b filter>newfile注意,其中的filter为文件筛选,必须自己修改为所需的,比如你可以把它改成*.txt,这样,就会列出当前目录下的所有txt结尾的文件了。
Newfile就是你需要存放文件名的那个文件,比如可以是dir.txt,这样就成了 dir/b*.txt>dir.txt,就会把当前目录下的所有文件都列出到dir.txt文件中,当然,由于dir.txt 也在当前目录,所以也会被算进去,这在处理的时候是需要注意的,下面几种方法中同样考虑了这个问题。
你可以选择手动删掉,或者把dir.txt这个文件存到其他地方去,或者,不要和你需要的文件具有相同的后缀也行,比如:dir /b *.txt>e:\dir.txt (假设当前目录是e:\test)如果省略了第二步中的转到当前目录的话,就需要在dir命令后输入完整的路径了,而且新生成的文件也要选择有权限建立新文件的地方存放,比如你在c:\users目录下输入:dir /b e:\test\*.txt>e:\dir.txt,这个命令和上面先转到e:\test目录下的效果是一样的。
现在你是不是比较好奇,/b 是干嘛的,其实就是只列出文件名,不要其他的附件信息,比如创建时间,文件大小等等这些对于我们批处理无关的信息。
如果你想包含某个目录下的子目录,那么,就可以这样写:Dir /b/s filter>newfile/s就表示包含子目录,但是,这样会有一个问题,那就是,批处理的时候必须获得正确的路径才能操作,这样得到的子目录里面的文件不会有任何标志说他是来自子目录的,因此fortran处理的时候就无法判断了,所以,如果包含了子目录,那么请用下面的命令:Dir /a-d/b/s filter>newfile现在去看看新生成的文件吧,怎么样,很惊喜吧!懂了这个方法,下面一部分的第一个方法对你来说就是小菜一碟啦。
如果你使用的win7(或vista)系统,而且无法正常使用CVF编译器的话,那么第一部分到这里就算结束啦,除非,你会在其他fortran编译器中调用WIN32API。
1.3、程序运行后,未开始计算之前生成文件名1.3.1、在程序中调用CMD命令这个方法其实就是上一个方法的进化版,只不过变成了在程序运行的时候调用命令自动生成,这样整个过程显得少一点,只需要在程序里设置好相关的参数即可。
这个方法的关键在于SYSTEMQQ函数的使用,这是CVF编译器封装的调用CMD命令的一个函数,存在于DFLIB库中,其语法命令为:result = SYSTEMQQ(commandline)commandline:表示需要进行的CMD操作,字符串形式,函数中的实际长度由传入的参数决定,input类型(表示输入为参数);Results:一个逻辑型变量(logical(4)),如果成功为true,失败为false(不解的是程序中要实现的东西都是正常的,比如仅仅传入dir命令,返回的结果仍然为F,请高手赐教)给出一个简单的例子:USE DFLIBLOGICAL(4)resultresult = SYSTEMQQ('copy e:\dir.txt e:\test\dir.txt')这个命令将第一个路径中的文件复制到为第二个路径中的文件。
通过这个例子再结合上面一个方法,就可以很方法便的构造出我们需要用来批处理的子函数,关键语句如下所示:subroutine ListToFile(fPath,outPut)character*(*),InTent(In):: fPath,outPutcharacter*100CMDLOGICAL(4) resCMD="dir/a-d/b/s "//trim(fPath)//" >"//trim(outPut)res=SYSTEMQQ(CMD)endsubroutine其中传入的是文件筛选值和输出的路径,这个方法也是我在第一部分中最为推荐的一个方法了,代码简洁高效,能够输出完整的路径,可以包含子文件夹,唯一的缺点就是输出的文件个数不能直接在程序中调用(方便循环),需要在批处理的时候使用其他方法来判断文件是否读取结束。
1.3.2、使用GETFILEINFOQQ方法生成文件目录该方法是下面一个方法的进化版,是由CVF对WIN32的API进行了封装,这样,我们就可以通过简单的调用函数来实现一些面向对象的功能。
简单的翻译了一下官方给出的GETFILEINFOQQ函数信息:Module: USE DFLIB (存在于DFLIB库中)语法简介:Syntaxresult = GETFILEINFOQQ (files, buffer, handle)files :输入类型的字符型变量,表示你需要查找的路径(也就是我们上面方法中的筛选值),同样可以使用*或者?这样的通配符。
buffer :在函数运行中会获得一个值,可供输出使用,这个值就是所找到的文件的相关信息,属于FILE$INFO类型的变量(该类型定义于:fortran安装路径DF98\INCLUDE路径下),其结构如下:TYPE FILE$INFOINTEGER(4)CREATIONINTEGER(4)LASTWRITEINTEGER(4)LASTACCESSINTEGER(4)LENGTHINTEGER(4)PERMITCHARACTER(255)NAMEEND TYPE FILE$INFOhandle :接受输入和输出整型变量,表示文件控制信息(同样在DFLIB中定义),包含以下内容:FILE$FIRST - First matching file found.FILE$LAST - Previous file was the last valid file.FILE$ERROR - No matching file found.Results: 返回值是一个整型变量(integer(4)),表示的不含空格的文件名长度,如果文件未找到,则返回0。
了解了以上信息,我们就可以通过编程进行循环调用这个函数,每找到一个符合条件的文件,就把他输入到指定路径的文件中去,注意,凡是input类型的变量都必须传入数值,否则会出错。
如果你比较有探索精神,就试着用这个介绍和思路来编程一下吧,子程序如下所示(完整的请下载附件)Subroutine GetFileList(cFileName,outPut,iFile)UseDFLib,only:GetFileInfoQQ,GetLastErrorQQ,FILE$INFO,FILE$LAST,FILE$ERROR,FILE$ FIRST,ERR$NOMEM,ERR$NOENT,FILE$DIR !引入库函数Implicit None!根据上面的语法介绍来定义变量Character*(*),Intent(In)::cFileName !筛选值character*(*),intent(In)::output !输出路径Integer,Intent(InOut)::iFile !记录已经找到几个文件TYPE (FILE$INFO) info !找到的文件的信息INTEGER(4)::Wildhandle,length !文件控制信息,文件大小,Wildhandle = FILE$FIRSTiFile = 0DOWHILE (.TRUE.) !循环找文件length = GetFileInfoQQ(cFileName,info,Wildhandle) !调用函数找文件!如果遇到错误或者不能再找到不同的文件,则进入选择,准备退出IF ((Wildhandle .EQ. FILE$LAST) .OR.(Wildhandle .EQ. FILE$ERROR)) THEN SELECT CASE (GetLastErrorQQ())CASE (ERR$NOMEM) !//内存不足iFile = - 1ReturnCASE (ERR$NOENT) !//碰到通配符序列尾,正常退出ReturnCASE DEFAULTiFile = 0ReturnEND SELECTEND IFiFile= iFile + 1Call WriteFileName( Trim() ,outPut, iFile) !调用子函数输出文件名ENDDOEnd Subroutine GetFileList注意,在调用子函数输出文件名时,要做一些处理,主要是判断文件是否存在(不存在则新建,如果是第一次找到,而且文件存在,则覆盖,否则追加),以及找到的是否为我们自己建立的这个dir.txt文件(如果是,则忽略,找到的文件数量-1)这个方法也不错,如果不需要子目录的信息,其优越性不亚于上一种方法,因为该子函数能够直接返回找到的文件数量。