非参数回归r语言实现
- 格式:pdf
- 大小:288.11 KB
- 文档页数:19

R语言非参数方法:使用核回归平滑估计和K-NN(K近邻算法)分类预测心脏病数据原文链接:/?p=22181本文考虑一下基于核方法进行分类预测。
注意,在这里,我们不使用标准逻辑回归,它是参数模型。
非参数方法用于函数估计的非参数方法大致上有三种:核方法、局部多项式方法、样条方法。
非参的函数估计的优点在于稳健,对模型没有什么特定的假设,只是认为函数光滑,避免了模型选择带来的风险;但是,表达式复杂,难以解释,计算量大是非参的一个很大的毛病。
所以说使用非参有风险,选择需谨慎。
非参的想法很简单:函数在观测到的点取观测值的概率较大,用x 附近的值通过加权平均的办法估计函数f(x)的值。
核方法当加权的权重是某一函数的核,这种方法就是核方法,常见的有Nadaraya-Watson核估计与Gasser-Muller核估计方法,也就是很多教材里谈到的NW核估计与GM核估计,这里我们还是不谈核的选择,将一切的核估计都默认用Gauss核处理。
NW核估计形式为:GM核估计形式为:式中数据使用心脏病数据,预测急诊病人的心肌梗死,包含变量:心脏指数心搏量指数舒张压肺动脉压心室压力肺阻力是否存活既然我们知道核估计是什么,我们假设k是N(0,1)分布的密度。
在x点,使用带宽h,我们得到以下代码dnorm(( 心搏量指数-x)/bw, mean=0,sd=1)weighted.mean( 存活,w)}plot(u,v,ylim=0:1,当然,我们可以改变带宽。
Vectorize( mean_x(x,2))(u)我们观察到:带宽越小,我们得到的方差越大,偏差越小。
“越大的方差”在这里意味着越大的可变性(因为邻域越小,计算平均值的点就越少,估计值也就越不稳定),以及“偏差越小”,即期望值应该在x点计算,所以邻域越小越好。
使用光滑函数用R函数来计算这个核回归。
smooth( 心搏量指数, 存活, ban = 2*exp(1)我们可以复制之前的估计。

用R语言做非参数和半参数回归笔记由詹鹏整理,仅供交流和学习根据南京财经大学统计系孙瑞博副教授的课件修改,在此感谢孙老师的辛勤付出!教材为:Luke Keele: Semiparametric Regression for the Social Sciences. John Wiley & Sons, Ltd. 2008.-------------------------------------------------------------------------第一章 introduction: Global versus Local Statistic一、主要参考书目及说明1、Hardle(1994). Applied Nonparametic Regresstion. 较早的经典书2、Hardle etc (2004). Nonparametric and semiparametric models: an introduction. Springer. 结构清晰3、Li and Racine(2007). Nonparametric econometrics: Theory and Practice. Princeton. 较全面和深入的介绍,偏难4、Pagan and Ullah (1999). Nonparametric Econometrics. 经典5、Yatchew(2003). Semiparametric Regression for the Applied Econometrician. 例子不错6、高铁梅(2009). 计量经济分析方法与建模:EVIEWS应用及实例(第二版). 清华大学出版社. (P127/143)7、李雪松(2008). 高级计量经济学. 中国社会科学出版社. (P45 ch3)8、陈强(2010). 高级计量经济学及Stata应用. 高教出版社. (ch23/24)【其他参看原ppt第一章】二、内容简介方法:——移动平均(moving average)——核光滑(Kernel smoothing)——K近邻光滑(K-NN)——局部多项式回归(Local Polynormal)——Loesss and Lowess——样条光滑(Smoothing Spline)——B-spline——Friedman Supersmoother模型:——非参数密度估计——非参数回归模型——非参数回归模型——时间序列的半参数模型——Panel data 的半参数模型——Quantile Regression三、不同的模型形式1、线性模型linear models2、Nonlinear in variables3、Nonlinear in parameters四、数据转换 Power transformation(对参数方法)In the GLM framework, models are equally prone(倾向于) to some misspecification (不规范) from an incorrect functional form.It would be prudent(谨慎的) to test that the effect of any independent variable of a model does not have a nonlinear effect. If it does have a nonlinear effect, analysts in the social science usually rely on Power Transformations to address nonlinearity. [ADD: 检验方法见Sanford Weisberg. Applied Linear Regression (Third Edition). A John Wiley & Sons, Inc., Publication.(本科的应用回归分析课教材)]----------------------------------------------------------------------------第二章 Nonparametric Density Estimation非参数密度估计一、三种方法1、直方图 Hiatogram2、Kernel density estimate3、K nearest-neighbors estimate二、Histogram 对直方图的一个数值解释Suppose x1,…xN – f(x), the density function f(x) is unknown.One can use the following function to estimate f(x)【与x的距离小于h的所有点的个数】三、Kernel density estimateBandwidth: h; Window width: 2h.1、Kernel function的条件The kernel function K(.) is a continuous function, symmetric(对称的) around zero, that integrates(积分) to unity and satisfies additional bounded conditions:(1) K() is symmetric around 0 and is continuous;(2) ,,;(3) Either(a) K(z)=0 if |z|>=z0 for z0Or(b) |z|K(z) à0 as ;(4) , where is a constant.2、主要函数形式3、置信区间其中,4、窗宽的选择实际应用中,。
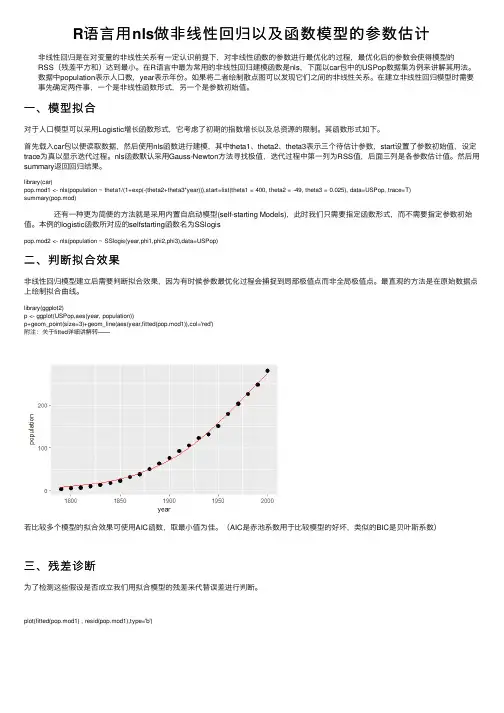
R语⾔⽤nls做⾮线性回归以及函数模型的参数估计⾮线性回归是在对变量的⾮线性关系有⼀定认识前提下,对⾮线性函数的参数进⾏最优化的过程,最优化后的参数会使得模型的RSS(残差平⽅和)达到最⼩。
在R语⾔中最为常⽤的⾮线性回归建模函数是nls,下⾯以car包中的USPop数据集为例来讲解其⽤法。
数据中population表⽰⼈⼝数,year表⽰年份。
如果将⼆者绘制散点图可以发现它们之间的⾮线性关系。
在建⽴⾮线性回归模型时需要事先确定两件事,⼀个是⾮线性函数形式,另⼀个是参数初始值。
⼀、模型拟合对于⼈⼝模型可以采⽤Logistic增长函数形式,它考虑了初期的指数增长以及总资源的限制。
其函数形式如下。
⾸先载⼊car包以便读取数据,然后使⽤nls函数进⾏建模,其中theta1、theta2、theta3表⽰三个待估计参数,start设置了参数初始值,设定trace为真以显⽰迭代过程。
nls函数默认采⽤Gauss-Newton⽅法寻找极值,迭代过程中第⼀列为RSS值,后⾯三列是各参数估计值。
然后⽤summary返回回归结果。
library(car)pop.mod1 <- nls(population ~ theta1/(1+exp(-(theta2+theta3*year))),start=list(theta1 = 400, theta2 = -49, theta3 = 0.025), data=USPop, trace=T)summary(pop.mod) 还有⼀种更为简便的⽅法就是采⽤内置⾃启动模型(self-starting Models),此时我们只需要指定函数形式,⽽不需要指定参数初始值。
本例的logistic函数所对应的selfstarting函数名为SSlogispop.mod2 <- nls(population ~ SSlogis(year,phi1,phi2,phi3),data=USPop)⼆、判断拟合效果⾮线性回归模型建⽴后需要判断拟合效果,因为有时候参数最优化过程会捕捉到局部极值点⽽⾮全局极值点。

7.1符号检验案例1:在显著性水平a=0.05的条件下,能否得出结论,每家超市周销售量的中位数等于450箱?0:中位数等于4501:中位数不等于450键入数据,将该变量命名a:a<-c(482,562,415,860,426,474,662,380,515,721)利用binom.test()函数做检验。
sum(a<450)表示数据中小于450的个数,alternative="two.sided"表示双侧检验:binom.test(sum(a<450),n=10,p=0.5,alternative="two.sided")程序结果截图如下:结论:P-值为0.3438,不能拒绝原假设。
案例2:厂商想要调查消费者更青睐奶香饼干还是咸香饼干。
0:消费者对奶香和咸香的偏好没有差异1:消费者对奶香和咸香的偏好有差异由于此案例分析的是分类型数据,而不是数值型数据,因此我们可以直接计算p 值:2*min(pbinom(2,12,0.5),1-pbinom(1,12,0.5))程序结果截图如下:结论:p-值为0.03857,拒绝原假设,消费者对两种口味的偏爱存在差异。
案例3:试分析两款手机的待机时长有无显著差异。
0:两款手机的待机时长没有差异1:两款手机的待机时长有差异输入数据x<-c(25,30,28,23,27,35,30,28,32,29,30,30,31,16)y<-c(19,32,21,19,25,31,31,26,30,25,28,31,25,25)采用成对符号检验,调用binom.test()做检验。
binom.test(sum(x<y),length(x))程序结果截图如下:结论:sum(x<y)表示样本x小于样本y的个数,计算出的p值大于0.05,无法拒绝原假设,可以认为两种手机的待机时长无显著差异。
另外,计算出的区间也包括0.5,也就是说,可以认为,x<y和x≥y的概率各占1/2,得出的结论也无法拒绝原假设,说明两种手机的待机时长无明显差异。

r语言nw核估计多元非参数模型下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!本店铺为大家提供各种类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you! In addition, this shop provides you with various types of practical materials, such as educational essays, diary appreciation, sentence excerpts, ancient poems, classic articles, topic composition, work summary, word parsing, copy excerpts, other materials and so on, want to know different data formats and writing methods, please pay attention!R语言NW核估计多元非参数模型引言在统计学和机器学习领域,非参数模型是一类不依赖于数据分布的模型,通常适用于复杂的数据结构和未知的数据生成过程。

r语言多组数据非参数检验-回复主题:R语言中多组数据的非参数检验引言:在统计学中,我们经常需要对不同组别的数据进行比较和分析。
而非参数检验是一种常用的方法,可以用于比较不同组别的数据,而不需要对数据具有特定的分布形式。
R语言是一种强大的统计分析工具,提供了多种非参数检验方法,使得我们可以轻松地进行多组数据的比较。
本文将以R语言为工具,一步一步介绍多组数据的非参数检验方法。
一、读取数据:首先,我们需要从外部文件或者直接在R中定义数据,用于后续的分析。
在R中,可以使用read.csv()函数读取csv格式的文件,或者使用read.table()函数读取其他格式的文件。
在本文中,我们假设我们已经读取了两组数据,分别命名为group1和group2。
二、描述性统计分析:在进行非参数检验之前,我们需要先对数据进行一定的描述性统计分析,以了解数据的分布状况和基本特征。
在R语言中,可以使用summary()函数来计算数据的各种统计量,如均值、中位数、四分位数等。
此外,我们还可以使用hist()函数绘制直方图,来观察数据的分布情况。
三、非参数检验方法选择:在进行非参数检验之前,我们需要根据数据的特点选择合适的非参数检验方法。
常用的非参数检验方法包括Wilcoxon秩和检验、Mann-Whitney U检验、Kruskal-Wallis单因素方差分析等。
在R语言中,可以使用wilcox.test()函数进行Wilcoxon秩和检验,使用wilcox.test()或者kruskal.test()函数进行多组数据的比较。
四、Wilcoxon秩和检验:假设我们要比较group1和group2两组数据之间的差异。
我们可以使用wilcox.test()函数进行Wilcoxon秩和检验。
该检验假设两组数据的分布形状相同,只有位置参数不同。
在R语言中,我们可以使用如下代码进行Wilcoxon秩和检验:wilcox.test(group1, group2, paired = FALSE)其中,group1和group2分别表示两组数据的向量,paired = FALSE表示两组数据是不相关的。


由詹鹏整理 ,仅供交流和学习根据南京财经大学统计系孙瑞博副教授的课件修改 ,在此感谢孙老师的辛勤付出!教材为:Luke Keele: Semiparametric Regression for the Social Sciences. John Wiley & Sons, Ltd. 2008.-------------------------------------------------------------------------第一章 introduction: Global versus Local Statistic一、主要参考书目及说明1、Hardle(1994). Applied Nonparametic Regresstion. 较早的经典书2、Hardle etc (2004). Nonparametric and semiparametric models: an introduction. Springer. 结构清晰3、Li and Racine(2007). Nonparametric econometrics: Theory and Practice. Princeton. 较全面和深入的介绍 ,偏难4、Pagan and Ullah (1999). Nonparametric Econometrics. 经典5、Yatchew(2003). Semiparametric Regression for the Applied Econometrician. 例子不错6、高铁梅(2009). 计量经济分析方法与建模:EVIEWS应用及实例(第二版). 清华大学出版社. (P127/143)7、李雪松(2008). 高级计量经济学. 中国社会科学出版社. (P45 ch3)8、陈强(2010). 高级计量经济学及Stata应用. 高教出版社. (ch23/24)【其他参看原ppt第一章】二、内容简介方法:——移动平均(moving average)——核光滑(Kernel smoothing)——K近邻光滑(K-NN)——局部多项式回归(Local Polynormal)——Loesss and Lowess——样条光滑(Smoothing Spline)——B-spline——Friedman Supersmoother模型:——非参数密度估计——非参数回归模型——非参数回归模型——时间序列的半参数模型——Panel data 的半参数模型——Quantile Regression三、不同的模型形式1、线性模型linear models2、Nonlinear in variables3、Nonlinear in parameters四、数据转换 Power transformation(对参数方法)In the GLM framework, models are equally prone(倾向于) to some misspecification (不规范) from an incorrect functional form.It would be prudent(谨慎的) to test that the effect of any independent variable of a model does not have a nonlinear effect. If it does have a nonlinear effect, analysts in the social science usually rely on Power Transformations to address nonlinearity.[ADD: 检验方法见Sanford Weisberg. Applied Linear Regression (Third Edition). A John Wiley & Sons, Inc., Publication.(本科的应用回归分析课教材)]----------------------------------------------------------------------------第二章Nonparametric Density Estimation非参数密度估计一、三种方法1、直方图 Hiatogram2、Kernel density estimate3、K nearest-neighbors estimate二、Histogram 对直方图的一个数值解释Suppose x1,…xN – f(x), the density function f(x) is unknown.One can use the following function to estimate f(x)【与x的距离小于h的所有点的个数】三、Kernel density estimateBandwidth: h; Window width: 2h.1、Kernel function的条件The kernel function K(.) is a continuous function, symmetric(对称的) around zero, that integrates(积分) to unity and satisfies additional bounded conditions:(1) K() is symmetric around 0 and is continuous;(2) ,,;(3) Either(a) K(z)=0 if |z|>=z0 for z0Or(b) |z|K(z) à0 as;(4) , where is a constant.2、主要函数形式3、置信区间其中 ,4、窗宽的选择实际应用中 ,。

非参数回归r语言-概述说明以及解释1.引言1.1 概述非参数回归是一种不依赖于特定函数形式的回归分析方法,它不需要对数据的分布做出假设。
相比于传统的参数回归方法,非参数回归更加灵活,能够更好地拟合复杂的数据模式。
在实际应用中,非参数回归可以有效地处理非线性关系、异常值和数据噪音等问题,因此受到越来越多研究者和数据分析师的青睐。
本文将重点介绍在R语言中如何进行非参数回归分析,包括常用的非参数回归方法、分析步骤以及如何利用R语言中的工具进行非参数回归分析。
同时,我们将讨论非参数回归的优缺点,以及对R语言在非参数回归中的意义和展望非参数回归的发展。
希望本文能够帮助读者更加深入地了解非参数回归方法,并在实践中灵活运用。
1.2 文章结构本文分为引言、正文和结论三部分。
在引言部分,将包括概述、文章结构和目的等内容,为读者提供对非参数回归和R语言的整体了解。
在正文部分,将介绍什么是非参数回归、在R语言中如何进行非参数回归分析以及非参数回归的优缺点。
最后,在结论部分将对非参数回归的应用进行总结,探讨R语言在非参数回归中的意义,以及展望非参数回归的发展前景。
通过以上结构,读者将逐步深入了解非参数回归和R语言在该领域的应用和发展。
1.3 目的本文旨在探讨非参数回归在数据分析中的应用,特别是在R语言环境下的实现方法。
通过深入了解非参数回归的概念、原理和优缺点,读者可以更全面地了解这一方法在处理不确定性较大、数据分布不规律的情况下的优势和局限性。
此外,本文还旨在介绍R语言中如何进行非参数回归分析,帮助读者学习如何利用这一工具进行数据建模和预测分析。
最终,通过对非参数回归的应用和发展的展望,希望能够激发更多的研究者和数据分析师对于这一领域的兴趣,推动非参数回归方法在实际应用中的进一步发展和创新。
2.正文2.1 什么是非参数回归非参数回归是一种用于建立数据之间关系的统计方法,它不对数据的分布做出任何假设。
在传统的参数回归中,我们通常会假设数据服从某种特定的分布,比如正态分布,然后通过参数估计来拟合模型。

用R语言做非参数非参数统计是一种统计学方法,不依赖于数据的分布假设。
相比于参数统计,非参数统计更加灵活,可以处理各种类型的数据。
在R语言中,有很多函数和包可以用来进行非参数统计分析。
首先,我们可以使用Wilcoxon秩和检验(Mann-Whitney U检验)来比较两组独立样本的中位数差异。
Wilcoxon秩和检验是一种非参数的假设检验方法,适用于两组样本的中位数比较。
在R语言中,使用wilcox.test(函数可以进行Wilcoxon秩和检验。
例如,假设我们有两组样本x和y,我们可以使用以下代码进行Wilcoxon秩和检验:```Rx<-c(1,2,3,4,5)y<-c(6,7,8,9,10)result <- wilcox.test(x, y)print(result)```这段代码将计算两组样本的Wilcoxon秩和检验结果,并打印输出。
除了Wilcoxon秩和检验,我们还可以使用Kruskal-Wallis检验来比较多组样本的中位数差异。
Kruskal-Wallis检验是一种非参数的方差分析方法,适用于多组样本的中位数比较。
在R语言中,使用kruskal.test(函数可以进行Kruskal-Wallis检验。
例如,假设我们有三组样本x、y和z,我们可以使用以下代码进行Kruskal-Wallis检验:```Rx<-c(1,2,3,4,5)y<-c(6,7,8,9,10)z<-c(11,12,13,14,15)result <- kruskal.test(list(x, y, z))print(result)```这段代码将计算三组样本的Kruskal-Wallis检验结果,并打印输出。
另外,对于变量间的相关性检验,我们可以使用Spearman秩相关系数。
Spearman秩相关系数是一种非参数的相关性分析方法,适用于非线性关系的变量间的相关性分析。

r语言3组非参数检验-回复R语言是一个功能强大的统计编程语言,广泛应用于数据分析、统计建模和可视化等领域。
在数据分析中,我们经常需要进行假设检验来判断样本数据是否符合某种分布或两个样本数据是否具有显著差异。
其中一种常用的假设检验方法是非参数检验,它不对数据的分布做出要求,因此适用于各种类型的数据。
本文将以R语言为工具,介绍非参数检验的相关概念和步骤,并以具体例子进行演示。
一、非参数检验的基本概念非参数检验是一种统计方法,不对数据的分布做出假设,根据样本数据的秩次或拟合程度进行假设检验。
它的优势在于能够处理非正态分布或存在异常值的数据。
常见的非参数检验方法包括Wilcoxon符号秩检验、Mann-Whitney U检验、Kruskal-Wallis单因素方差分析等。
二、Wilcoxon符号秩检验Wilcoxon符号秩检验是一种非参数检验方法,用于比较两个相关样本的差异性。
它的原假设是两个样本的差异性中位数为零,备择假设是两个样本差异性的中位数不为零。
下面是Wilcoxon符号秩检验的步骤:1.导入数据和包:使用R语言进行数据分析时,首先需要导入相关的数据和包。
如有需要,可以使用install.packages()函数安装所需的包。
2.准备数据:将需要进行Wilcoxon符号秩检验的数据存储为两个向量或数据框的形式。
3.执行Wilcoxon符号秩检验:使用wilcox.test()函数执行Wilcoxon符号秩检验,并将两个样本的数据作为输入。
4.解读结果:根据检验结果的p值,判断两组样本差异是否显著。
通常取显著性水平为0.05,若p值小于0.05,可以拒绝原假设,认为两个样本的差异是显著的。
三、Mann-Whitney U检验Mann-Whitney U检验是一种非参数检验方法,用于比较两个独立样本的差异性。
它的原假设是两个样本的分布相同,备择假设是两个样本的分布不同。
Mann-Whitney U检验的步骤如下:1.导入数据和包:与Wilcoxon符号秩检验一样,首先需要导入相关的数据和包。
⽤R语⾔做回归分析使⽤R做回归分析整体上是⽐较常规的⼀类数据分析内容,下⾯我们具体的了解⽤R语⾔做回归分析的过程。
⾸先,我们先构造⼀个分析的数据集x<-data.frame(y=c(102,115,124,135,148,156,162,176,183,195),var1=runif(10,min=1,max=50),var2=runif(10,min=100,max=200),var3=c(235,321,412,511,654,745,821,932,1020,1123))接下来,我们进⾏简单的⼀元回归分析,选择y作为因变量,var1作为⾃变量。
⼀元线性回归的简单原理:假设有关系y=c+bx+e,其中c+bx 是y随x变化的部分,e是随机误差。
可以很容易的⽤函数lm()求出回归参数b,c并作相应的假设检验。
model<-lm(y~var1,data=x)summary(model)Call:lm(formula = x$y ~ x$var1 + 1)Residuals:Min 1Q Median 3Q Max-47.630 -18.654 -3.089 21.889 52.326Coefficients:Estimate Std. Error t value Pr(>|t|)(Intercept) 168.4453 15.2812 11.023 1.96e-09 ***x$var1 -0.4947 0.4747 -1.042 0.311Signif. codes: 0 ‘’ 0.001 ‘’ 0.01 ‘’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 30.98 on 18 degrees of freedomMultiple R-squared: 0.05692, Adjusted R-squared: 0.004525F-statistic: 1.086 on 1 and 18 DF, p-value: 0.3111从回归的结果来看,p值为0.311,变量var1不不显著,正常情况下p值⼩于0.05则认为有⾼的显著性⽔平。
非参数统计r语言非参数统计是一种统计学方法,它不依赖于数据的具体分布形式,而是通过对数据的排序、排列、秩次等进行分析来得出结论。
在统计学中,非参数统计方法常常用于处理那些不满足正态分布假设的数据,或者对数据分布形式不确定的情况下进行分析。
R语言是一种广泛应用于数据分析和统计学领域的编程语言,它提供了丰富的数据处理、统计分析和可视化工具,使得非参数统计方法的应用变得更加方便和高效。
下面将介绍一些常见的非参数统计方法在R语言中的实现。
首先是Wilcoxon秩和检验,也称为Mann-Whitney U检验,用于比较两组独立样本的中位数是否有显著差异。
在R语言中,可以使用wilcox.test()函数进行计算,通过设置参数来指定要进行的检验类型,例如单侧检验、双侧检验等。
其次是Kruskal-Wallis检验,用于比较多组独立样本的中位数是否有显著差异。
在R语言中,可以使用kruskal.test()函数进行计算,通过将多组数据传入函数中进行比较,得出检验的结果和统计量。
另外,对于非参数统计中的秩相关检验,如Spearman秩相关系数检验和Kendall秩相关系数检验,也可以在R语言中进行计算。
通过使用cor.test()函数,可以计算两组数据的秩相关系数并进行假设检验,得出相关性的显著性。
除此之外,R语言中还提供了一些其他非参数统计方法的实现,如符号检验、秩和检验、秩秩相关检验等。
这些方法的应用可以帮助研究人员在数据分析中更全面地考虑数据的性质和假设,从而得出更可靠的统计结论。
总的来说,非参数统计方法在R语言中的应用丰富多样,可以满足不同数据分析的需求,帮助研究人员更好地理解数据的特征和结构,为科学研究和决策提供支持。
通过掌握R语言中的非参数统计方法,可以更好地应对实际数据分析中的挑战,为数据科学的发展和应用做出贡献。
r语言多组数据非参数检验-回复标题:使用R语言进行多组数据的非参数检验在统计分析中,非参数检验是一种重要的工具,它不需要对数据分布做出任何假设。
在R语言中,我们可以方便地进行多组数据的非参数检验。
以下是一步一步的详细指导。
一、理解非参数检验非参数检验主要用于比较两组或多组数据的分布是否存在显著差异,而无需对数据的总体分布做出特定的假设。
这使得非参数检验在处理异常值、偏态分布或者样本量较小的数据时具有优势。
二、准备数据在进行非参数检验之前,我们需要先准备好数据。
假设我们有三组数据,分别存储在变量group1, group2, group3中。
Rset.seed(123)group1 <- rnorm(20, mean = 50, sd = 10)group2 <- rnorm(20, mean = 60, sd = 10)group3 <- rnorm(20, mean = 70, sd = 10)这里我们使用了R的随机数生成函数rnorm生成了三组正态分布的数据。
三、Kruskal-Wallis H检验Kruskal-Wallis H检验是一种常用的非参数检验方法,用于比较两组或多组数据的分布是否相同。
在R中,我们可以使用kruskal.test函数来进行Kruskal-Wallis H检验。
Rdata <- c(group1, group2, group3)group <- factor(rep(c("group1", "group2", "group3"), each = length(group1)))kruskal.test(data ~ group)在这个例子中,我们首先将三组数据合并到一个向量data中,然后创建了一个因子group来表示每个数据点所属的组别。
最后,我们使用kruskal.test函数进行了Kruskal-Wallis H检验。
图灵社区:阅读:【译文】R语言非线性回归初步R语言非线性回归入门作者 Lionel Hertzog在一簇散点中拟合一条回归线(即线性回归)是数据分析的基本方法之一。
有时,线性模型能很好地拟合数据,但在某些(很多)情形下,变量间的关系未必是线性的。
这时,一般有三类方法解决这个问题: (1) 通过变换数据使得其关系线性化, (2) 用多项式或者比较复杂的样条来拟合数据, (3) 用非线性函数来拟合数据从标题你应该已经猜到非线性回归是本文的重点什么是非线性回归在非线性回归中,分析师通常采用一个确定的函数形式和相应的参数来拟合数据。
最常用的参数估计方法是利用非线性最小二乘法(R中的nls函数)。
该方法使用线性函数来逼近非线性函数,并且通过不断迭代这个过程来得到参数的最优解(本段来自维基百科)。
非线性回归的良好性质之一是估计出的参数都有清晰的解释(如Michaelis-Menten模型的Vmax是指最大速率),而变换数据后得到的线性模型其参数往往难以解释。
非线性最小二乘拟合首先,我们以Michaelis-Menten方程为例。
# 生成一些仿真数据set.seed(20160227)x <- seq(0, 50, 1)y <- ((runif(1, 10, 20)*x)/(runif(1, 0, 10)+x)) + rnorm(51, 0, 1) # 对于一些简单的模型,nls函数可以自动找到合适的参数初值m <- nls(y ~ a*x/(b+x))# 计算模型的拟合优度cor(y, predict(m))[1] 0.9496598# 将结果可视化plot(x, y)lines(x, predict(m), lty = 2, col = "red", lwd = 3)输出的图片如下:选择适宜的迭代初值在非线性回归中,找到合适的迭代初值对于整个模型算法的收敛性而言至关重要。
r语言多组数据非参数检验-回复R语言多组数据非参数检验是一种常用的统计分析方法,适用于未满足正态分布假设的情况。
本文将以此为主题,从介绍非参数检验的背景和原理,到详细讲解R语言中多组数据非参数检验的步骤,一步一步回答读者的疑问。
一、非参数检验的背景和原理非参数检验是一种不基于总体分布假设的统计方法,主要用于比较两个或多个组之间的差异。
相比于参数检验,非参数检验更为灵活,适用范围更广。
非参数检验的原理是通过对数据进行排序和秩次变换,来忽略数据分布的形状和特征,只关注于数据的顺序关系,从而进行统计推断。
二、R语言中多组数据非参数检验的步骤在R语言中,进行多组数据的非参数检验可以使用多种函数,下面将一步一步介绍具体的操作步骤。
1. 导入数据首先,需要将数据导入R语言中,并将其存储为矩阵或数据框的形式。
可以使用`read.csv()`或`read.table()`函数将数据从外部文件导入,也可以直接使用`data.frame()`函数手动创建数据框。
2. 定义分组变量根据研究设计,将数据分组。
通常可以使用向量或因子变量的形式定义分组变量,例如:group <- c("A", "A", "A", "B", "B", "B")。
3. 进行非参数检验R语言中有多个函数可以进行非参数检验,根据研究目的和数据类型的不同,选择合适的函数。
常用的函数有:- wilcox.test(): 用于比较两个独立样本之间的差异,返回Wilcoxon秩和检验的结果。
- kruskal.test(): 用于比较多个独立样本之间的差异,返回Kruskal-Wallis 检验的结果。
- friedman.test(): 用于比较多个相关样本之间的差异,返回Friedman 秩和检验的结果。
这些函数都有相似的参数,包括x(数据向量或因子)、y(分组变量)和alternative(备择假设),可以根据需要进行设置。