第5章 抽样分布与抽样方法.
- 格式:ppt
- 大小:1.19 MB
- 文档页数:80

第5章抽样(8学时)第一节抽样的意义与作用一、抽样的概念1.总体总体(population)通常与构成它的元素共同定义:总体是构成它的所有元素的集合,元素则是构成总体的最基本单位。
2.样本样本(sample)就是从总体中按一定方式抽取出的—部分元素的集合。
或者说一个样本就是总体的一个子集。
3.抽样明白了总体和样本的概念,再来理解抽样的概念就十分容易了。
所谓抽样(sampling),指的是从组成某个总体的所有元素的集合中,按一定的方式选择或抽取一部分元素(即抽取总体的一个子集)的过程,或者说,抽样是从总体中按一定方式选择成抽取样本的过程。
4.抽样单位抽样单位(sampling unit)就是一次直接的抽样所使用的基本单位。
抽样单位与构成总体的元素有时是相同的,有时又是不同的。
5.抽样框抽样框(sampling frame)又称做抽样X围,它指的是一次直接抽样时总体中所有抽样单位的。
6.参数值参数值(parameter)也称为总体值,它是关于总体中某一变量的综合描述,或者说是总体中所有元素的某种特征的综合数量表现。
在统计中最常见的总体值是某一变量的平均值,7.统计值统计值(statistic)也称为样本值,它是关于样本中某一变量的综合描述,或者说是样本中所有元素的某种特征的综合数量表现。
样本值是从样本的所有元素中计算出来的,它是相应的总体值的估计量。
二、抽样的作用在社会研究中,抽样主要解决的是对象的选取问题,即如何从总体中选出一部分对象作为总体的代表的问题。
本章一开始我们就说过,一项社会研究若能对总体中的全部个体都进行了解,那当然是很好的。
但实际上广大研究人员在时间、经费、人力等方面遇到难题,甚至陷入困境,从而不得不在庞大的总体与有限的时间、人力、经费这二者之间寻求平衡。
以现代统计学和概率论为基础的现代抽样理论,以及不断发展、不断完善的各种抽样方法.正好适应了社会研究的发展和应用的需要,成为社会研究知识体系中必不可少的一部分内容。

抽样与抽样分布在统计学中,抽样是一种常用的数据收集方法,通过从总体中选择一部分样本来进行研究和分析。
抽样的目的是通过样本来推断总体的特征和性质。
在进行抽样时,我们需要了解抽样的方法和抽样分布的概念。
一、抽样方法1. 无偏抽样无偏抽样是指所有样本有相同被选中的机会。
这样可以确保样本的代表性,从而减小样本估计值和总体真值之间的误差。
常见的无偏抽样方法包括简单随机抽样、系统抽样和分层抽样等。
2. 有偏抽样有偏抽样是指样本的选择并不具有相等的机会。
这样可能导致样本的代表性不足,从而产生较大的估计误差。
有时,有偏抽样也可以用于特定的研究目的,但需要明确地说明和分析偏差带来的影响。
二、抽样分布1. 抽样分布的概念抽样分布是指统计量在各个可能样本上的取值分布。
统计量可以是样本均值、样本方差等。
抽样分布的性质对于进行统计推断和假设检验非常重要。
2. 样本均值的抽样分布样本均值的抽样分布在中心极限定理的条件下近似服从正态分布。
中心极限定理指出,当样本容量足够大时,无论总体分布如何,样本均值的抽样分布都会接近正态分布。
3. 样本比例的抽样分布样本比例的抽样分布在满足一些条件的情况下也近似服从正态分布。
这些条件包括样本容量足够大、总体比例接近0.5以及样本与总体之间的独立性等。
4. 样本方差的抽样分布样本方差的抽样分布不服从正态分布。
通常情况下,样本方差的抽样分布呈右偏态,即偏度大于0。
为了得到样本方差的抽样分布,可以使用抽样分布的近似分布,如卡方分布。
三、应用案例抽样与抽样分布的方法和理论在实际统计学中有广泛的应用。
以下是一些常见的应用案例:1. 调查研究在进行调查研究时,我们经常需要从总体中选择一部分样本进行问卷调查或面访。
通过利用抽样与抽样分布的方法,我们可以将样本的调查结果推广到总体中,从而得到总体的特征和性质。
2. 假设检验假设检验是统计学中常用的推断方法之一。
通过比较样本统计量与假设的总体参数值,我们可以判断假设的合理性。



第五章抽样与抽样分布一、单项选择题(以下每小题各有四项备选答案,其中只有一项是正确的。
)1.抽样推断的主要目的是( )。
A.用统计量来推算总体参数B.对调查单位作深入研究C.计算和控制抽样误差D.广泛运用数学方法[答案] A[解析] 抽样调查是指从总体中按随机原则抽取部分单位作为样本,进行观察研究,并根据这部分单位的调查结果来推断总体,以达到认识总体的一种统计调查方法,因此,抽样推断的主要目的是用已知的统计量来推算未知的总体参数。
2.抽样调查中,无法消除的误差是( )。
A.抽样误差B.责任心误差C.登记误差D.系统性误差[答案] A[解析] 抽样误差是指在遵循了随机原则的条件下,不包括登记误差和系统性误差在内的,用样本指标代表总体指标而产生的不可避免的误差。
3.在其他条件相同的情况下,重复抽样的抽样平均误差和不重复抽样相比,( )。
A.前者一定小于后者B.前者一定大于后者C.两者相等D.前者可能大于,也可能小于后者[答案] B[解析] 以抽样平均数的抽样平均误差为例进行说明:在重复抽样条件下,抽样平均数的平均误差的计算公式:;在不重复抽样条件下,抽样平均数的平均误差的计算公式:。
因为,故。
4.拟分别对甲、乙两个地区大学毕业生在试用期的工薪收入进行抽样调查。
据估计甲地区大学毕业生试用期月工薪的方差要比乙区高出一倍。
在样本量和抽样方法相同的情况下,甲区的抽样误差要比乙区高( )。
A.41.4% B.42.4% C.46.8% D.48.8%[答案] A[解析] 假设乙地区的大学毕业生试用期月工薪的方差为σ2,甲地区的大学毕业生试用期月工薪的方差为2σ2,则:,那么,在样本量和抽样方法相同的,情况下,甲区的抽样误差要比乙区高=41.4%。
5.对某天生产的2000件电子元件的耐用时间进行全面检测,又抽取5%进行抽样复测,资料如表5-1所示。
表5-1耐用时间(小时) 全面检测(支) 抽样复测(支)3000以下3000~4000 4000~5000 50600990230505000以上总计36020018100规定耐用时间在3000小时以下为不合格品,则该电子元件合格率的抽样平均误差为( )。



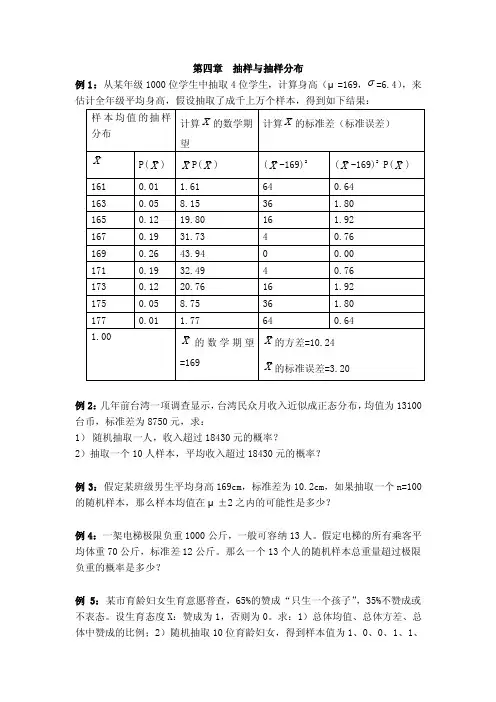
第四章抽样与抽样分布例1:从某年级1000位学生中抽取4位学生,计算身高(μ=169, =6.4),来估计全年级平均身高,假设抽取了成千上万个样本,得到如下结果:例2:几年前台湾一项调查显示,台湾民众月收入近似成正态分布,均值为13100台币,标准差为8750元,求:1)随机抽取一人,收入超过18430元的概率?2)抽取一个10人样本,平均收入超过18430元的概率?例3:假定某班级男生平均身高169cm,标准差为10.2cm,如果抽取一个n=100的随机样本,那么样本均值在μ±2之内的可能性是多少?例4:一架电梯极限负重1000公斤,一般可容纳13人。
假定电梯的所有乘客平均体重70公斤,标准差12公斤。
那么一个13个人的随机样本总重量超过极限负重的概率是多少?例5:某市育龄妇女生育意愿普查,65%的赞成“只生一个孩子”,35%不赞成或不表态。
设生育态度X:赞成为1,否则为0。
求:1)总体均值、总体方差、总体中赞成的比例;2)随机抽取10位育龄妇女,得到样本值为1、0、0、1、1、1、0、1、1、1,求样本均值、样本中赞成比例。
解:1)计算见下表2)样本均值=7/10=0.7,样本中赞成比例=7/10=0.7例6:学校选人大代表,结果有60%的选民投了我院院长而当选。
假定选举之前有人做了预测,抽取了一个n=30的随机样本进行民意测验,如果样本中只有半数一下的比例支持院长,于是得出院长失败的结果,显然这一预测是一个倒霉的预测。
那么,抽取到以上倒霉样本的概率是多少呢?即错误预测的可能性是多少?如果将样本量增到100,再计算错误概率。
例7:某中学学生男女人数相同,现随机从中抽取15名学生,问男生人数大于10的概率是多少?四、样本方差的抽样分布设随机变量x 1,x 2,x 3…..x i 相互独立且服从同一正态分布,则将这些随机变量标准化,再计算它们的平方和,得到卡方值2χ,其服从于自由度为n-1的卡方分布:2χ=2222312()()().....()i x x x x μμμμσσσσ----++++=2211()kii x μσ=-∑分子分母同乘n-1,进一步整理得2χ=22(1)n s σ-~2χ(n-1)练习题:1、某专业学生的年龄分布是右偏的,均值为22,标准差为4.45,如果采用重复抽样的方法从该专业学生中抽取容量为100的样本,则样本均值的抽样分布为?2、从均值为50,标准差为5的正态总体中抽取容量为25的样本,则样本均值超过51的概率为?3、某企业声明企业人均收入为5500元,标准差为550元。

第5章等概率整群抽样到目前为止,我们假定所有抽样程序中的总体是实现给定的,我们要做的就是从这个给定的总体中抽取一个合适的样本,而这些样本中包含一定的单元。
但单元要被很好的定义并非易事,甚至再总体被很好定义的时候也是如此。
列举单元的方法多种多样,并且我们所选取的单元很可能包含了更小的单元。
假定我们想调查包含10000户家庭的某个社区中拥有自行车的住户数目,那么我们可以做一个样本容量为400个家庭的简单随机抽样,我们也可以把这个社区分为500个街区,每个街区20户家庭,然后从这个500个街区中随机的抽取20个街区作为样本。
后者实际上就是一个整群抽样。
500个街区称为初级抽样单位(PSU)或群。
街区中的家庭称为次级抽样单位(SSU)。
通常,SSU也是总体的元素。
这个有400个家庭构成的整群抽样样本的精度不及简单随机抽样样本;因为一些街区主要是由一些拥有自行车的住户构成,而一些街区的住户主要是由退休人员构成(不拥有自行车)。
处于同意街区的20户家庭并不能想随机样本的20户家庭一样反映整个社区的多样性。
因此,整群样本中的每一个观测单元所提供的信息少于随机样本。
但是,调查同一街区的20户家庭比随机调查整个社区的20户家庭要便宜很多,容易很多,因此,整群样本中,每一单元所取得的信息多于SRS中每一单元所获得的信息。
在整群抽样中,总体中的个体元素仅仅当它所属的群被抽样时它才被入样。
这个入样的群(抽样单元PSU)不同于观测单元(SSU),并且在计算整群抽样样本的标准误时,两者的容量被考虑。
为什么使用整群抽样?1、构造一个列举所有观测单元的抽样框可能就是困难、昂贵或不可能的。
我们不可能列出某一区域内所有蜜蜂或某一商场的所有顾客:就算我们能列举出北部某针叶林的所有树木或某一城市中的所有个人,但其耗时且昂贵。
2、总体在地域上分布广泛或者误群是自然产生的,如家庭或学校。
若目标总体是美国所有护理所的居民,则调查入样的某个护理所的全体居民比调查SRS中的等量居民要便宜很多:在SRS的护理所居民调查中,你可能不得不为了调查一个居民而去拜访他所在的护理所。