webkit加载url过程分析
- 格式:pdf
- 大小:309.36 KB
- 文档页数:25

:网页加载过程网站速度详细分析很多文章都会说到网站速度对于用户转化的影响,速度慢的网站用户更容易离开,尤其是可以找到替代内容的情况下。
那么如何度量网站的加载速度呢,之前大家的做法是在页面的头部记一下时间:var start = new Date().getTime(),然后在页脚计算一下用掉的时间:var timeUse = new Date().getTime() – start,把这儿的timeUse用事件的方式提交到GA服务器:_gaq.push(['_trackEvent', 'timeUse', '/home.html', 'load', timeUse]),最后在GA的事件列表,看事件的平均值来评价页面的加载时间。
这样做,可以获得加载时间,但不完整,完整的页面加载是这样的:1、用户打开url链接2、浏览器查询url的dns地址3、提交url请求到服务器端4、服务器端处理5、传输处理好的html文本内容到浏览器6、浏览器解析html,并加载css,js,图片等内容7、加载完成,用户看到完整的页面内容前面的timeUse获取的其实是第6步操作的用时,2到5步的用时都无法获取,假设某个网站的dns查询慢,服务器端处理慢,还是会影响用户的体验,而这个是我们无法度量的。
其实dns查询,等待服务器处理等时间,作为浏览器是知道的,于是HTML5规范为这部分的查询,提供了接口,允许javascript来查询详细的用时,具体文档在这儿:https:///hg/webperf/raw-file/tip/specs/NavigationTiming/Ov erview.html#sec-navigation-timing-interface,调用的例子见这儿:/en/tutorials/webperformance/basics/,假设我们要获取当前页面的dns解析时间,只要:performance.timing.domainLookupEnd –performance.timing.domainLookupStart即可,目前支持该接口的浏览器有:firefox,chrome,IE9等对html5标准支持较好的浏览器。

windows下⽤QTwebkit解析html实现过程 环境 windows7 + VS2010 + QT5.2_opengl 配置开发环境 1、安装VS2010 2、安装QT 5.2 下载并安装QT5.2:Qt 5.2.1 for Windows 32-bit (VS 2010, OpenGL, 517 MB) 3、安装Visual Studio Add-in for QT5 下载地址:Visual Studio Add-in 1.2.2 for Qt5 4、配置VS 2010 配置路径:QT5 ==> "Qt Options" ==> "Qt Versions" ==> Add 默认路径为:C:\Qt\Qt5.2.0\5.2.0\msvc2010_opengl 解析html 1、建⽴QtWebkit⼯程 操作路径:VS2010 ==> File ==> New ==> Project ==> "Qt5 Projects" ==> "Qt Application" 注意事项 在"Project Settings"⾥⾯选中“WebKit”和“Webkit Widgets”选项: 2、添加头⽂件 #include <QtGui>#include <QtWebKit>#include <QWebView> 3、解析内容 3.1、解析http形式的url 使⽤QWebView的setUrl⽅法,⽰例如下: QWebView view; view.show(); view.setUrl(QUrl("/mikezhang")); 3.2、解析本地⽂件 使⽤QWebView的setUrl⽅法,⽰例如下: QWebView view; view.show(); view.setUrl(QUrl("file:///E:/tmp/1.html")); 3.3、解析html字符串 使⽤QWebView的setHtml⽅法,⽰例如下: QApplication app(argc, argv); QWebView view; view.show(); std::ifstream fin("E:/tmp/1.html"); std::stringstream buffer; buffer << fin.rdbuf(); fin.close(); view.setHtml(buffer.str().c_str()); 完整代码如下:复制代码代码如下:#include <QtGui>#include <QtWebKit>#include <QWebView>#include <fstream>#include <string>#include <sstream> int main(int argc, char *argv[]) { QApplication app(argc, argv); QWebView view; view.show(); // Method 1 : a remote url//view.setUrl(QUrl("/mikezhang")); // Method 2 : a local url //view.setUrl(QUrl("file:///E:/tmp/1.html")); // Method 3 : set html content std::ifstream fin("E:/tmp/1.html"); std::stringstream buffer; buffer << fin.rdbuf(); fin.close();view.setHtml(buffer.str().c_str()); return app.exec(); }。

浏览器地址栏输⼊URL后,⼀个完整的请求是什么样⼦的?⼤致流程1. URL 解析2. DNS 查询3. TCP 连接4. 处理请求5. 接受响应6. 渲染页⾯⼀、URL 解析 地址解析: ⾸先判断你输⼊的是⼀个合法的 URL 还是⼀个待搜索的关键词,并且根据你输⼊的内容进⾏⾃动完成、字符编码等操作。
HSTS 由于安全隐患,会使⽤ HSTS 强制客户端使⽤ HTTPS 访问页⾯。
详见:。
其他操作 浏览器还会进⾏⼀些额外的操作,⽐如安全检查、访问限制(之前国产浏览器限制 996.icu)。
检查缓存⼆、DNS 查询 基本步骤 1. 浏览器缓存 浏览器会先检查是否在缓存中,没有则调⽤系统库函数进⾏查询。
2. 操作系统缓存 操作系统也有⾃⼰的 DNS缓存,但在这之前,会向检查域名是否存在本地的 Hosts ⽂件⾥,没有则向 DNS 服务器发送查询请求。
3. 路由器缓存 路由器也有⾃⼰的缓存。
4. ISP DNS 缓存 ISP DNS 就是在客户端电脑上设置的⾸选 DNS 服务器,它们在⼤多数情况下都会有缓存。
根域名服务器查询 在前⾯所有步骤没有缓存的情况下,本地 DNS 服务器会将请求转发到互联⽹上的根域,下⾯这个图很好的诠释了整个流程: 需要注意的点1. 递归⽅式:⼀路查下去中间不返回,得到最终结果才返回信息(浏览器到本地DNS服务器的过程)2. 迭代⽅式,就是本地DNS服务器到根域名服务器查询的⽅式。
3. 什么是 DNS 劫持4. 前端 dns-prefetch 优化三、TCP 连接 TCP/IP 分为四层,在发送数据时,每层都要对数据进⾏封装: 1. 应⽤层:发送 HTTP 请求 在前⾯的步骤我们已经得到服务器的 IP 地址,浏览器会开始构造⼀个 HTTP 报⽂,其中包括:请求报头(Request Header):请求⽅法、⽬标地址、遵循的协议等等请求主体(其他参数) 其中需要注意的点:浏览器只能发送 GET、POST ⽅法,⽽打开⽹页使⽤的是 GET ⽅法 2. 传输层:TCP 传输报⽂ 传输层会发起⼀条到达服务器的 TCP 连接,为了⽅便传输,会对数据进⾏分割(以报⽂段为单位),并标记编号,⽅便服务器接受时能够准确地还原报⽂信息。
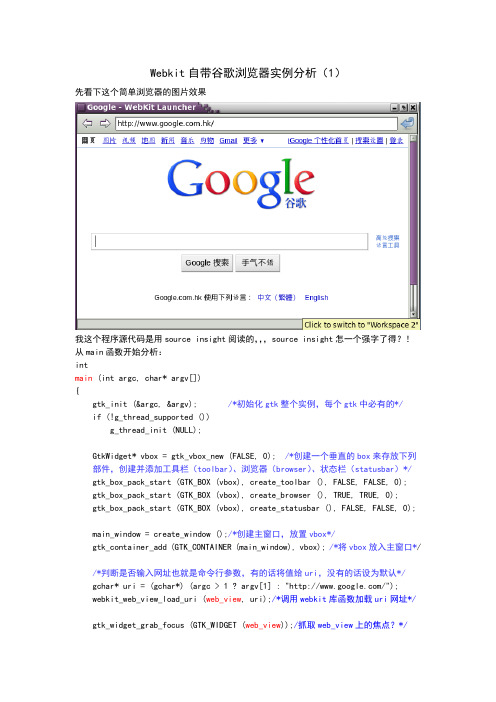
Webkit自带谷歌浏览器实例分析(1)先看下这个简单浏览器的图片效果我这个程序源代码是用source insight阅读的,,,source insight怎一个强字了得?!从main函数开始分析:intmain (int argc, char* argv[]){gtk_init (&argc, &argv); /*初始化gtk整个实例,每个gtk中必有的*/if (!g_thread_supported ())g_thread_init (NULL);GtkWidget* vbox = gtk_vbox_new (FALSE, 0); /*创建一个垂直的box来存放下列部件,创建并添加工具栏(toolbar)、浏览器(browser)、状态栏(statusbar)*/ gtk_box_pack_start (GTK_BOX (vbox), create_toolbar (), FALSE, FALSE, 0);gtk_box_pack_start (GTK_BOX (vbox), create_browser (), TRUE, TRUE, 0);gtk_box_pack_start (GTK_BOX (vbox), create_statusbar (), FALSE, FALSE, 0);main_window = create_window ();/*创建主窗口,放置vbox*/gtk_container_add (GTK_CONTAINER (main_window), vbox); /*将vbox放入主窗口*//*判断是否输入网址也就是命令行参数,有的话将值给uri,没有的话设为默认*/gchar* uri = (gchar*) (argc > 1 ? argv[1] : "/");webkit_web_view_load_uri (web_view, uri);/*调用webkit库函数加载uri网址*/ gtk_widget_grab_focus (GTK_WIDGET (web_view));/抓取web_view上的焦点?*//*现实整个主窗口,也就是浏览器窗口*/gtk_widget_show_all (main_window);gtk_main ();return 0;}主函数从前到后读下来基本没什么问题,只是对web_view有点困惑,于是找到定义的地方static WebKitWebView* web_view;/*很显然是一个全局静态变量*/在webkit的源码包中的gtk目录下的webkit下的Webkitwebview.h查找WebKitWebView:发现typedef struct _WebKitWebView WebKitWebView; struct _WebKitWebView的结构为:struct _WebKitWebView {GtkContainer parent_instance;/*< private >*/WebKitWebViewPrivate *priv;};依然不大懂,继续挖掘WebKitWebViewPrivate:真是有种取之不尽挖之不绝的感觉O(∩_∩)Otypedef struct _WebKitWebViewPrivate WebKitWebViewPrivate;再往下看终于看到曙光了:struct _WebKitWebViewPrivate {WebCore::Page* corePage; /*这个应该是核心页面吧*/WebKitWebSettings* webSettings; /*页面有关的设置木有细挖,水太深*/ WebKitWebInspector* webInspector; /*什么检查员?*/WebKitWebWindowFeatures* webWindowFeatures; /*Window的特性*/WebKitWebFrame* mainFrame; /*web主框架*/WebKitWebBackForwardList* backForwardList; /*保存前进后退的链表*/gint lastPopupXPosition;/*不太懂*/gint lastPopupYPosition;/*依然不太懂*/此处也省略很多};WebCore::Page*?是什么东东?真是一波未平一波又起,杯具之情油然而生,究竟何时是尽头,,,?放弃or继续走下去?其实本来想放弃的,但是想想都挖了这么深了,放弃了可惜哇,,,go ahead!继续挖:何为命名空间?据《c++primer》传言,一般大型程序或者库文件有很多全局变量,这些变量重名的概率是相当的高,所以就会引起名字冲突,《C++primer》起了个洋气的名字,叫“命名空间污染”,其实就是重名引起冲突而已。

Android WebView加载Chromium动态库的过程分析Chromium动态库的体积比较大,有27M左右,其中程序段和数据段分别占据25.65M和1.35M。
如果按照通常方式加载Chromium动态库,那么当有N个正在运行的App使用WebView时,系统需要为Chromium动态库分配的内存为(25.65 + N x 1.35)M。
这是非常可观的。
为此,Android使用了特殊的方式加载Chromium动态库。
本文接下来就详细分析这种特殊的加载方式。
为什么当有N个正在运行的App使用WebView时,系统需要为Chromium动态库分配的内存为(25.65 + N x 1.35)M呢?这是由于动态库的程序段是只读的,可以在多个进程之间进行共享,但是数据段一般是可读可写的,不能共享。
在 1.35M的数据段中,有 1.28M在Chromium动态库加载完成后就是只读的。
这1.28M数据包含有C++虚函数表,以及指针类型的常量等,它们在编译的时候会放在一个称为GNU_RELRO的Section中,如图1所示:如果我们将该GNU_RELRO Section看作是一般的数据段,那么系统就需要为每一个使用了WebView的App进程都分配一段1.28M大小的内存空间。
前面说到,这1.28M数据在Chromium动态库加载完成后就是只读的,那么有没有办法让它像程序段一样,在多个App 进程之间共享呢?只要能满足一个条件,那么答案就是肯定的。
这个条件就是所有的App进程都在相同的虚拟地址空间加载Chromium动态库。
在这种情况下,就可以在系统启动的过程中,创建一个临时进程,并且在这个进程中加载Chromium动态库。
假设Chromium动态库的加载地址为Base Address。
加载完成后,将Chromium动态库的GNU_RELRO Section的内容Dump 出来,并且写入到一个文件中去。
以后App进程加载Chromium动态库时,都将Chromium动态库加载地址Base Address上,并且使用内存映射的方式将前面Dump出来的GNU_RELRO文件代替Chromium 动态库的GNU_RELRO Section。

WebKit 的JavaScript 引擎简介————基于基于WebKit-r29753腾讯研究院无线中心/无线浏览器组周晓波(xiaobozhou )1.概述1.1.浏览器浏览器是用于展示远程信息并提供有限修改能力的客户端程序。
事实上,世界上第一个浏览器是一个远程格式化编辑器,其修改权限是很大的。
而目前浏览提提供的修改能力很弱,对修改的权限控制、对修改内容的处理等更多的集中在服务器端。
因此,可以说现在的浏览器主要任务是更高效的、更标准的处理和显示远程信息。
浏览器的这些主要工作都是由内核完成的。
浏览器对远程信息的显示并不是随意的,因为远程信息(通常是网页)是一种格式化的信息,即这些信息不仅包括内容,而且包括结构和显示样式。
浏览器需要根据信息的格式化指令(如html 的标签)来对信息的结构进行理解,理解出来的每一部分称为一个元素。
所谓结构化就是信息各部分之间的层级关系,类似书本的章节。
然后,浏览器根据样式指令(如style 标签或属性等)来决定(或建议,因为不一定每个指定的样式都能满足)某一元素的样式。
再后,浏览器根据当前视窗的大小,以及元素之间的关系,以各个元素的样式(如大小)为约束条件,来输出每个元素的绝对位置等信息。
最后,调用平台相关的接口来把每个元素在屏幕上画出来。
如果用户利用JavaScript 改变了某个部分,浏览器就重复最后三步操作。
上述过程中,第一步是解析标记语言,其结果是形成DOM 树,第二步称为渲染(Render),其结果是产生Render 树,第三步称为布局(Layout ),其结果是决定远程信息的最终样子。
这三步是浏览器内核的核心功能。
在每次加载一个页面时都会执行;而JavaScript 扮演的角色就是在不再次加载的情况下推动上述三步的执行,这是通过对DOM 树的修改来实现的。
图1展示了一个页面解析的基本过程。
这里涉及到几个中间实体:页面源文件、DOM 图1:网页解析基本过程。
浏览器打开URL的方式和加载过程不同浏览器的工作方式不完全一样,大体上,浏览器的核心是浏览器引擎,目前市场占有率最高的几种浏览器几乎都使用了不同的浏览器引擎:IE使用的是Trident、Firefox使用的是Gecko、Safari和Chrome使用的是Webkit。
不同的浏览器引擎对W3C的规范支持不尽相同。
下面讲诉浏览器从输入URL地址开始到页面完全可用的大致过程。
1.连接到URL所在服务器用户在地址栏中输入一个URL,并单击GO按钮要求浏览器打开该URL后,浏览器做的第一件事情是寻找该URL所在服务器,通过向DNS服务器查询,浏览器可以获得该URL所在网站的IP地址。
然后,浏览器向该地址发起连接请求,建立到服务器的连接。
2.获取页面对应的HTML文档当连接建立后,浏览器向服务器发送HTTP请求,请求URL对应的HTML文档。
不管请求的URL是一个静态的HTML文件,还是一个动态脚本(ASPX、PHP或JSP),服务器返回给浏览器的一定是HTML文档。
该HTML文档就是浏览器需要呈现的页面3.解析文档并获取所需要的资源浏览器在获取HTML文档后会对文档进行解析,目的是知道该页面需要哪些资源以及生成DOM树。
生成DOM树的工作与下载页面上需要的其它资源同时进行。
大致来说,浏览器会逐行分析HTML文档,一旦发现一个标签,就会根据标签的要求分配对指定资源的下载。
当DOM树生成后,DOMContentLoaded事件被触发。
首先,理论上浏览器并行下载页面需要的所有资源会带来最好的性能体验,但由于服务器要保证对尽可能多的用户的支持,因此HTTP/1.1规定了每个客户端只能与每个服务器建立2个连接。
其次,并非所有的元件都可以被并行下载。
一般情况下,页面中包含两类需要被执行的JavaScript脚本,一类是直接用<script>标签标识的内嵌的JS语句;另一类则是引用外部的JS文件4.页面上的JS文件与CSS文件5.Onload事件当HTML文档解析完成,生成了DOM树,所有页面需要的资源文件都已经成功下载和执行后,浏览器会发出Onload事件并回调HTML文档中的onload函数。
从输⼊URL到页⾯加载发⽣了什么?输⼊URL到页⾯加载发⽣了什么?通过连接这个过程,然后针对性地对每个过程进⾏优化,最终实现的就是我们的前端性能优化。
本篇⽂章主要介绍⼀些基础性的概念,很少涉及真正的性能优化。
具体过程?打开浏览器,输⼊URL,到页⾯展⽰出来,这个中间⼤致经历了这些过程:1. 输⼊URL2. DNS解析3. TCP握⼿4. HTTP请求5. HTTP响应返回数据6. 浏览器解析并渲染页⾯上⾯粗劣的介绍了输⼊URL到页⾯加载的⼤致过程,但是缺少更加详细的过程,事实上w3c给我们提供了⼀个接⼝performance.timing更加详细地介绍了每个过程,并且可以通过这个过程获取页⾯性能数据。
如下图所⽰:上图的过程⼤致可以分为三个⼤的阶段:1. 缓存相关:主要包括Prompt for unload,redirect和App cache3个过程2. ⽹络相关:主要包括DNS,TCP和HTTP(Request,Response)3个过程3. 浏览器相关:主要包括Processing和onload两个过程通过将整个过程细分为3个⼤的阶段,然后再每个阶段每个阶段介绍,这样⽅便我们记忆和理解。
缓存相关1、卸载已有的页⾯(Prompt for unload)我们在页⾯中输⼊URL时,⾸先会卸载掉原来的页⾯。
这是为了释放页⾯占据的内存,否则没请求⼀次URL都占据⼀份内存,会导致浏览器占据内存越来越⼤。
2、重定向(redirect)所谓的重定向实际上就是先从本地缓存中去查找请求的内容,如果本地缓存中有则直接使⽤,如果没有则向服务器进⾏请求(这只是简单的理解,实际上如何获取数据是存在缓存策略的)。
事实上,每次从服务器获取到⽂件,⽂件会被暂时存放到⼀个指定区域,当我们下次再次请求这个⽂件时,浏览器会⾸先从这个区域查看是否已经存在过这个⽂件,如果已经存在,则不需要再次进⾏请求数据。
3、App cache⽹络相关4、DNSDNS(Domain Name System)域名系统,顾名思义是⽤来解析域名系统的。
Chromium网页URL加载过程分析Chromium在Browser进程中为网页创建了一个Frame Tree之后,会将网页的URL发送给Render进程进行加载。
Render进程接收到网页URL加载请求之后,会做一些必要的初始化工作,然后请求Browser进程下载网页的内容。
Browser进程一边下载网页内容,一边又通过共享内存将网页内容传递给Render进程解析,也就是创建DOM Tree。
本文接下来就分析网页URL的加载过程。
Render进程之所以要请求Browser进程下载网页的内容,是因为Render进程没有网络访问权限。
出于安全考虑,Chromium将Render进程启动在一个受限环境中,使得Render进程没有网络访问权限。
那为什么不是Browser进程主动下载好网页内容再交给Render进程解析呢?这是因为Render进程是通过WebKit加载网页URL的,WebKit不关心自己所在的进程是否有网络访问权限,它通过特定的接口访问网络。
这个特定接口由WebKit的使用者,也就是Render进程中的Content模块实现。
Content模块在实现这个接口的时候,会通过IPC 请求Browser进程下载网络的内容。
这种设计方式使得WebKit可以灵活地使用:既可以在有网络访问权限的进程中使用,也可以在没有网络访问权限的进程中使用,并且使用方式是统一的。
从前面一文可以知道,Browser进程中为要加载的网页创建了一个Frame Tree之后,会向Render进程发送一个类型为FrameMsg_Navigate的IPC消息。
Render进程接收到这个IPC消息之后,处理流程如图1所示:Render进程执行了一些初始化工作之后,就向Browser进程发送一个类型为ResourceHostMsg_RequestResource的IPC消息。
Browser进程收到这个IPC消息之后,就会通过HTTP协议请求Web服务器将网页的内容返回来。
浅谈WebViewWebView(网络视图)能加载显示网页,可以将其视为一个浏览器。
它使用了WebKit渲染引擎加载显示网页,实现WebView有以下两种不同的方法:第一种方法的步骤:1.在要Activity中实例化WebView组件:WebView webView = new WebView(this);2.调用WebView的loadUrl()方法,设置WevView要显示的网页:互联网用:webView.loadUrl("");本地文件用:webView.loadUrl("file:///android_asset/XX.html"); 本地文件存放在:assets 文件中3.调用Activity的setContentView( )方法来显示网页视图4.用WebView点链接看了很多页以后为了让WebView支持回退功能,需要覆盖覆盖Activity 类的onKeyDown()方法,如果不做任何处理,点击系统回退剪键,整个浏览器会调用finish()而结束自身,而不是回退到上一页面5.需要在AndroidManifest.xml文件中添加权限,否则会出现Web page not available错误。
<uses-permission android:name="android.permission.INTERNET" />下面是具体例子:MainActivity.java1package com.android.webview.activity;23import android.app.Activity;4import android.os.Bundle;5import android.view.KeyEvent;6import android.webkit.WebView;78public class MainActivity extends Activity {9private WebView webview;10@Override11public void onCreate(Bundle savedInstanceState) {12super.onCreate(savedInstanceState);13//实例化WebView对象14 webview = new WebView(this);15//设置WebView属性,能够执行Javascript脚本16 webview.getSettings().setJavaScriptEnabled(true);17//加载需要显示的网页18 webview.loadUrl("/");19//设置Web视图20 setContentView(webview);21 }2223@Override24//设置回退25//覆盖Activity类的onKeyDown(int keyCoder,KeyEvent event)方法26public boolean onKeyDown(int keyCode, KeyEvent event) {27if ((keyCode == KeyEvent.KEYCODE_BACK) && webview.canGoBack()) {28 webview.goBack(); //goBack()表示返回WebView的上一页面29return true;30 }31return false;32}在AndroidManifest.xml文件中的17行添加权限33<?xml version="1.0"encoding="utf-8"?>34<manifest xmlns:android="/apk/res/android"35package="com.android.webview.activity"36android:versionCode="1"37android:versionName="1.0">38<uses-sdk android:minSdkVersion="10"/>3940<application android:icon="@drawable/icon"android:label="@string/app_name">41<activity android:name=".MainActivity"42android:label="@string/app_name">43<intent-filter>44<action android:name="android.intent.action.MAIN"/>45<category android:name="UNCHER"/>46</intent-filter>47</activity>48</application>49<uses-permission android:name="android.permission.INTERNET"/>50</manifest>效果图:第二种方法的步骤:1、在布局文件中声明WebView2、在Activity中实例化WebView3、调用WebView的loadUrl( )方法,设置WevView要显示的网页4、为了让WebView能够响应超链接功能,调用setWebViewClient( )方法,设置 WebView 视图5、用WebView点链接看了很多页以后为了让WebView支持回退功能,需要覆盖覆盖Activity 类的onKeyDown()方法,如果不做任何处理,点击系统回退剪键,整个浏览器会调用finish()而结束自身,而不是回退到上一页面6、需要在AndroidManifest.xml文件中添加权限,否则出现Web page not available错误。