第二章 k近邻算法
- 格式:pptx
- 大小:2.79 MB
- 文档页数:11

1.简述k最近邻算法的原理、算法流程以及优缺点一、什么是K近邻算法k近邻算法又称knn算法、最近邻算法,是一种用于分类和回归的非参数统计方法。
在这两种情况下,输入包含特征空间中的k个最接近的训练样本,这个k可以由你自己进行设置。
在knn分类中,输出是一个分类族群。
一个对象的分类是由其邻居的“多数表决”确定的,k个最近邻居(k为正整数,通常较小),所谓的多数表决指的是,在k个最近邻中,取与输入的类别相同最多的类别,作为输入的输出类别。
简而言之,k近邻算法采用测量不同特征值之间的距离方法进行分类。
knn算法还可以运用在回归预测中,这里的运用主要是指分类。
二、k近邻算法的优缺点和运用范围优点:精度高、对异常值不敏感、无数据输入假定。
缺点:计算复杂度高、空间复杂度高。
适用范围:数值型和标称型、如手写数字的分类等。
三、k近邻算法的工作原理假定存在一个样本数据集合,并且样本集中的数据每个都存在标签,也就是说,我们知道每一个样本数据和标签的对应关系。
输入一个需要分类的标签,判断输入的数据属于那个标签,我们提取出输入数据的特征与样本集的特征进行比较,然后通过算法计算出与输入数据最相似的k个样本,取k个样本中,出现次数最多的标签,作为输入数据的标签。
四、k近邻算法的一般流程(1)收集数据:可以使用任何方法,可以去一些数据集的网站进行下载数据。
(2)准备数据:距离计算所需要的数值,最好是结构化的数据格式(3)分析数据:可以使用任何方法(4)训练算法:此步骤不适用于k近邻算法(5)测试算法:计算错误率(6)使用算法:首先需要输入样本数据和结构化的输出结构(统一数据格式),然后运行k近邻算法判定输入数据属于哪一种类别。
五、k近邻算法的实现前言:在使用python实现k近邻算法的时候,需要使用到Numpy科学计算包。
如果想要在python中使用它,可以按照anaconda,这里包含了需要python需要经常使用到的科学计算库,如何安装。

机器学习经典分类算法——k-近邻算法(附python实现代码及数据集)⽬录⼯作原理存在⼀个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每⼀数据与所属分类的对应关系。
输⼊没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进⾏⽐较,然后算法提取样本集中特征最相似数据(最近邻)的分类特征。
⼀般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不⼤于20的整数。
最后选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
举个例⼦,现在我们⽤k-近邻算法来分类⼀部电影,判断它属于爱情⽚还是动作⽚。
现在已知六部电影的打⽃镜头、接吻镜头以及电影评估类型,如下图所⽰。
现在我们有⼀部电影,它有18个打⽃镜头、90个接吻镜头,想知道这部电影属于什么类型。
根据k-近邻算法,我们可以这么算。
⾸先计算未知电影与样本集中其他电影的距离(先不管这个距离如何算,后⾯会提到)。
现在我们得到了样本集中所有电影与未知电影的距离。
按照距离递增排序,可以找到k个距离最近的电影。
现在假定k=3,则三个最靠近的电影依次是He's Not Really into Dudes、Beautiful Woman、California Man。
python实现⾸先编写⼀个⽤于创建数据集和标签的函数,要注意的是该函数在实际⽤途上没有多⼤意义,仅⽤于测试代码。
def createDataSet():group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])labels = ['A','A','B','B']return group, labels然后是函数classify0(),该函数的功能是使⽤k-近邻算法将每组数据划分到某个类中,其伪代码如下:对未知类别属性的数据集中的每个点依次执⾏以下操作:(1)计算已知类别数据集中的点与当前点之间的距离;(2)按照距离递增次序排序;(3)选取与当前点距离最⼩的k个点;(4)确定前k个点所在类别的出现频率;(5)返回前k个点出现频率最⾼的类别作为当前点的预测分类。

K-近邻算法目录一、K-近邻算法优缺点二、K.近邻算法工作原理及示例三、K-近邻算法的一般流程四、准备:使用Python导入数据通实施kNN分类算法六、示例L改进约会网站的配对结果七:示例2:手写识别系统K-近邻算法优缺点简单地说,K.近邻算法(又称KNN)采用测量不同特征值之间的距离方法进行分类。
其优缺点及适用数据范围如下:优点:精度高、对异常值不敏感、无数据输入假定。
缺点:计算复杂度高、空间复杂度高。
适用数据罐;数值型和标称型。
示例:手写识别系统3.测试算法:之前我们将数据处理成分类器可以识别的格式,现在我们将这些数据输入到分类器,检测分类器的执行效果。
def handwritingClassTest():hwLabels=[]trainingFileList=listdirCtrainingDigits*)#获取目录中的文件内容存储于列表中m=len(trainingFileList)trainingMat=zeros((m,1024))for i in range(m):fileNameStr二traininTFileList【ilfileStr二fileNameStr・split(?H01tftake off・txta trainingMat[i/]=i mg2vector('tra i n i ng Digits/%s,%fileNameStr)dassNumStr二int(fileStr・split(''HOI)#从文件名解析分类数字hwLabels.append(classNumStr)testFileList=listdir('testDigits')iterate through the test seterrorCount=0.0mTest=len(testFileList)for i in range(mTest):fileNameStr=testFileList[i]fileStr=fileNameStr.split('.')[O]#take off.txtclassNumStr=int(fileStr.split('_')vectorUnderTest=img2vector('testDigits/%s'%fileNameStr)classifierResult=classify Of^ectorUnderTest,trainingMat,hwLabels,3)print"the classifier came back with:%d,the real answer is:%d"%(classifierResult,classNumStr)if(classifierResult!=classNumStr):errorCount+=1.0print"\nthe total number of errors is:%d"%errorCountprint”\nthe total error rate is:%f"%(errorCount/float(mTest))示例:手写识别系统(2)上述代码所示的自包含函数handwritingClassTest。

机器学习:K-近邻算法(KNN)机器学习:K-近邻算法(KNN)⼀、KNN算法概述KNN作为⼀种有监督分类算法,是最简单的机器学习算法之⼀,顾名思义,其算法主体思想就是根据距离相近的邻居类别,来判定⾃⼰的所属类别。
算法的前提是需要有⼀个已被标记类别的训练数据集,具体的计算步骤分为⼀下三步:1、计算测试对象与训练集中所有对象的距离,可以是欧式距离、余弦距离等,⽐较常⽤的是较为简单的欧式距离;2、找出上步计算的距离中最近的K个对象,作为测试对象的邻居;3、找出K个对象中出现频率最⾼的对象,其所属的类别就是该测试对象所属的类别。
⼆、算法优缺点1、优点思想简单,易于理解,易于实现,⽆需估计参数,⽆需训练;适合对稀有事物进⾏分类;特别适合于多分类问题。
2、缺点懒惰算法,进⾏分类时计算量⼤,要扫描全部训练样本计算距离,内存开销⼤,评分慢;当样本不平衡时,如其中⼀个类别的样本较⼤,可能会导致对新样本计算近邻时,⼤容量样本占⼤多数,影响分类效果;可解释性较差,⽆法给出决策树那样的规则。
三、注意问题1、K值的设定K值设置过⼩会降低分类精度;若设置过⼤,且测试样本属于训练集中包含数据较少的类,则会增加噪声,降低分类效果。
通常,K值的设定采⽤交叉检验的⽅式(以K=1为基准)经验规则:K⼀般低于训练样本数的平⽅根。
2、优化问题压缩训练样本;确定最终的类别时,不是简单的采⽤投票法,⽽是进⾏加权投票,距离越近权重越⾼。
四、python中scikit-learn对KNN算法的应⽤#KNN调⽤import numpy as npfrom sklearn import datasetsiris = datasets.load_iris()iris_X = iris.datairis_y = iris.targetnp.unique(iris_y)# Split iris data in train and test data# A random permutation, to split the data randomlynp.random.seed(0)# permutation随机⽣成⼀个范围内的序列indices = np.random.permutation(len(iris_X))# 通过随机序列将数据随机进⾏测试集和训练集的划分iris_X_train = iris_X[indices[:-10]]iris_y_train = iris_y[indices[:-10]]iris_X_test = iris_X[indices[-10:]]iris_y_test = iris_y[indices[-10:]]# Create and fit a nearest-neighbor classifierfrom sklearn.neighbors import KNeighborsClassifierknn = KNeighborsClassifier()knn.fit(iris_X_train, iris_y_train)KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',metric_params=None, n_jobs=1, n_neighbors=5, p=2,weights='uniform')knn.predict(iris_X_test)print iris_y_testKNeighborsClassifier⽅法中含有8个参数(以下前两个常⽤):n_neighbors : int, optional (default = 5):K的取值,默认的邻居数量是5;weights:确定近邻的权重,“uniform”权重⼀样,“distance”指权重为距离的倒数,默认情况下是权重相等。

第一部分、K近邻算法1.1、什么是K近邻算法何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1时,算法便成了最近邻算法,即寻找最近的那个邻居。
为何要找邻居?打个比方来说,假设你来到一个陌生的村庄,现在你要找到与你有着相似特征的人群融入他们,所谓入伙。
用官方的话来说,所谓K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居),这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
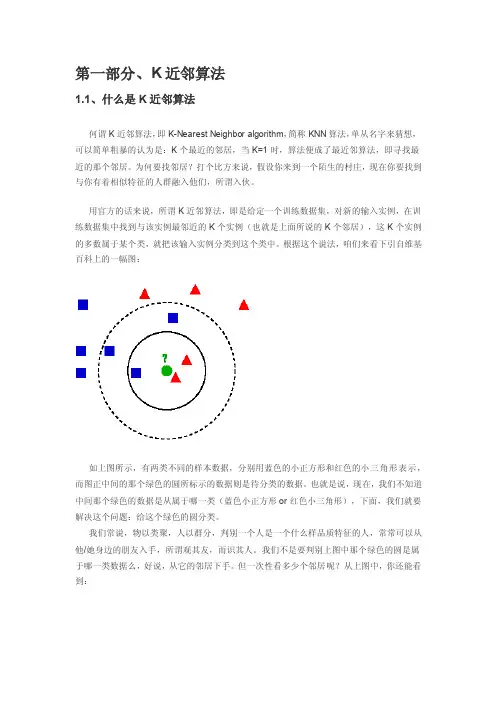
根据这个说法,咱们来看下引自维基百科上的一幅图:如上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。
也就是说,现在,我们不知道中间那个绿色的数据是从属于哪一类(蓝色小正方形or红色小三角形),下面,我们就要解决这个问题:给这个绿色的圆分类。
我们常说,物以类聚,人以群分,判别一个人是一个什么样品质特征的人,常常可以从他/她身边的朋友入手,所谓观其友,而识其人。
我们不是要判别上图中那个绿色的圆是属于哪一类数据么,好说,从它的邻居下手。
但一次性看多少个邻居呢?从上图中,你还能看到:∙如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
∙如果K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
于此我们看到,当无法判定当前待分类点是从属于已知分类中的哪一类时,我们可以依据统计学的理论看它所处的位置特征,衡量它周围邻居的权重,而把它归为(或分配)到权重更大的那一类。
这就是K近邻算法的核心思想。
1.2、近邻的距离度量表示法上文第一节,我们看到,K近邻算法的核心在于找到实例点的邻居,这个时候,问题就接踵而至了,如何找到邻居,邻居的判定标准是什么,用什么来度量。
![[课件]K最近邻方法PPT](https://uimg.taocdn.com/a117df25eff9aef8941e0646.webp)

机器学习:k-NN算法(也叫k近邻算法)⼀、kNN算法基础# kNN:k-Nearest Neighboors# 多⽤于解决分类问题 1)特点:1. 是机器学习中唯⼀⼀个不需要训练过程的算法,可以别认为是没有模型的算法,也可以认为训练数据集就是模型本⾝;2. 思想极度简单;3. 应⽤数学知识少(近乎为零);4. 效果少;5. 可以解释机械学习算法使⽤过程中的很多细节问题6. 更完整的刻画机械学习应⽤的流程; 2)思想:根本思想:两个样本,如果它们的特征⾜够相似,它们就有更⾼的概率属于同⼀个类别;问题:根据现有训练数据集,判断新的样本属于哪种类型;⽅法/思路:1. 求新样本点在样本空间内与所有训练样本的欧拉距离;2. 对欧拉距离排序,找出最近的k个点;3. 对k个点分类统计,看哪种类型的点数量最多,此类型即为对新样本的预测类型; 3)代码实现过程:⽰例代码:import numpy as npimport matplotlib.pyplot as pltraw_data_x = [[3.3935, 2.3312],[3.1101, 1.7815],[1.3438, 3.3684],[3.5823, 4.6792],[2.2804, 2.8670],[7.4234, 4.6965],[5.7451, 3.5340],[9.1722, 2.5111],[7.7928, 3.4241],[7.9398, 0.7916]]raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]# 训练集样本的datax_train = np.array(raw_data_x)# 训练集样本的labely_train = np.array(raw_data_y)# 1)绘制训练集样本与新样本的散点图# 根据样本类型(0、1两种类型),绘制所有样本的各特征点plt.scatter(x_train[y_train == 0, 0], x_train[y_train == 0, 1], color = 'g')plt.scatter(x_train[y_train == 1, 0], x_train[y_train == 1, 1], color = 'r')# 新样本x = np.array([8.0936, 3.3657])# 将新样本的特征点绘制在训练集的样本空间plt.scatter(x[0], x[1], color = 'b')plt.show()# 2)在特征空间中,计算训练集样本中的所有点与新样本的点的欧拉距离from math import sqrt# math模块下的sqrt函数:对数值开平⽅sqrt(number)distances = []for x_train in x_train:d = sqrt(np.sum((x - x_train) ** 2))distances.append(d)# 也可以⽤list的⽣成表达式实现:# distances = [sqrt(np.sum((x - x_train) ** 2)) for x_train in x_train]# 3)找出距离新样本最近的k个点,并得到对新样本的预测类型nearest = np.argsort(distances)k = 6# 找出距离最近的k个点的类型topK_y = [y_train[i] for i in nearest[:k]]# 根据类别对k个点的数量进⾏统计from collections import Countervotes = Counter(topK_y)# 获取所需的预测类型:predict_ypredict_y = votes.most_common(1)[0][0]封装好的Python代码:import numpy as npfrom math import sqrtfrom collections import Counterdef kNN_classify(k, X_train, y_train, x):assert 1 <= k <= X_train.shape[0],"k must be valid"assert X_train.shape[0] == y_train.shape[0], \"the size of X_train nust equal to the size of y_train"assert X-train.shape[1] == x.shape[0],\"the feature number of x must be equal to X_train"distances = [sprt(np.sum((x_train - x) ** 2)) for x_train in X_train]nearest = np.argsort(distances)topK_y = [y_train[i] for i in nearest[:k]]vates = Counter(topK_y)return votes.most_common(1)[0][0] # assert:表⽰声明;此处对4个参数进⾏限定;代码中的其它Python知识:1. math模块下的sprt()⽅法:对数开平⽅;from math import sqrtprint(sprt(9))# 32. collections模块下的Counter()⽅法:对列表中的数据进⾏分类统计,⽣产⼀个Counter对象;from collections import Countermy_list = [0, 0, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3]print(Counter(my_list))# ⼀个Counter对象:Counter({0: 2, 1: 3, 2: 4, 3: 5})3. Counter对象的most_common()⽅法:Counter.most_common(n),返回Counter对象中数量最多的n种数据,返回⼀个list,list的每个元素为⼀个tuple;from collections import Countermy_list = [0, 0, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3]votes = Counter(my_list)print(votes.most_common(2))# [(3, 5), (2, 4)]⼆、总结 1)k近邻算法的作⽤ 1、解决分类问题,⽽且天然可以解决多分类问题; 2、也可以解决回归问题,其中scikit-learn库中封装的KNeighborsRegressor,就是解决回归问题; 2)缺点缺点1:效率低下1. 原因:如果训练集有m个样本,n个特征,预测每⼀个新样本,需要计算与m个样本的距离,每计算⼀个距离,要使⽤n个时间复杂度,则计算m个样本的距离,使⽤m * n个时间复杂度;2. 算法的时间复杂度:反映了程序执⾏时间随输⼊规模增长⽽增长的量级,在很⼤程度上能很好反映出算法的优劣与否。

k近邻算法知识点总结1. 原理k近邻算法的原理很简单,它基于以下假设:相似的样本具有相似的特征。
算法的基本思想是根据新样本与训练集中样本的距离来确定新样本的类别。
具体来说,对于分类问题,当有一个新样本需要分类时,算法先计算该样本与训练集中每个样本的距离,然后选取距离最近的k个样本,根据它们的类别进行投票决定新样本的类别。
通常采用多数表决的方式,即选择k个样本中出现最多次数的类别作为新样本的类别。
对于回归问题,k近邻算法同样是计算新样本与训练集中每个样本的距离,然后选取距离最近的k个样本,根据这k个样本的值来预测新样本的值。
一般采用平均值来作为预测值。
2. 算法流程k近邻算法的流程可以分为以下几个步骤:(1)计算距离:对于每个测试样本,计算它与训练集中每个样本的距离,可以使用欧几里德距离、曼哈顿距离、余弦距离等。
(2)选择k个邻居:根据距离的大小,选择与测试样本最近的k个训练样本。
(3)投票决策:对于分类问题,选择k个邻居中出现次数最多的类别作为测试样本的类别;对于回归问题,计算k个邻居的平均值作为测试样本的预测值。
3. 算法优缺点k近邻算法有以下优点:(1)简单易理解:算法的原理简单,易于理解和实现。
(2)适用性广泛:适用于分类和回归问题,对于多分类和多标签等问题同样有效。
(3)没有训练过程:算法不需要训练数据,只需要存储训练样本用于预测。
但是,k近邻算法也有一些缺点:(1)计算复杂度高:对于大规模数据集,需要计算测试样本与每个训练样本的距离,计算量大。
(2)需要大量内存:算法需要存储整个训练集,对内存需求较大。
(3)对异常值敏感:算法对异常值敏感,可能导致误分类。
4. 参数选择k近邻算法的性能受k值的影响,因此选择合适的k值对算法的准确性至关重要。
一般来说,k值的选择与具体问题相关,需要通过交叉验证等方法进行选择。
此外,距离的度量方式也是影响算法性能的重要因素,常用的距离度量方式有欧几里德距离、曼哈顿距离、余弦距离等,选择合适的距离度量方式对算法的性能也有影响。


模式识别作业K近邻算法姓名:班级:学号:二零一一年十二月K近邻算法一、K近邻基本描述:K近邻就是在N个样本中,找出x 的K个近邻。
设这N个样本中,来自Wc类的样本有Nc个,若K1,K2,…Kc分别是K个近邻中属于W1,W2,…,Wc类的样本数,则我们可以定义判别函数为:g i x=k i,i=1,2,3,…,c决策规则为:若g j x=maxk ii则决策x∈w j。
这就是K近邻的基本规则。
二、基本算法流程如下:(1)取A[1]~A[k]作为x的初始临近,计算与测试样本x间的欧氏距离d(x,A[ i ]),i=1~k;(2)按d(x,A[ i ])升序排序,计算最远样本与x间的距离D←max{ d (x,A[ j ])},j=1~k;(3)for(i=k+1;i<=n; i++)(4)计算A[ i ]与x间的距离d(x,A[ i ]);(5)if d(x,A[ i ])<D(6)then 用A[ i ]代替最远样本;(7)按d(x,A[ i ])升序排序,计算最远样本与x间的距离D← max{ d (x,A[ j ])},j=1~i;(8)计算前k个样本A[ i ],i=1~k所属类别的概率,具有最大概率的类别即为样本x的类。
三、实验结果:导入iris训练样本之后得到的结果由图可以得知我们算得的结果为第一类的聚类准确率为1.0000,第二类聚类的准确率为0.93333,第三类聚类的准确率为0.93333。
总体准确率为0.93333。
四、程序源代码#include<stdio.h>#include<math.h>#define n 60#define k 5struct distance{float d;intnum;}dist[n];voidselectsort(struct distance *b) {inti,j;struct distance temp;for(i=0;i<=n-2;i++){for(j=i+1;j<=n-1;j++){if(b[j].d<b[i].d){temp=b[j];b[j]=b[i];b[i]=temp;}}}}int count(struct distance *a){int i,c1=0,c2=0,c3=0;for(i=0;i<k;i++){if(a[i].num==1)c1=c1+1;else if(a[i].num==2)c2=c2+1;elsec3=c3+1;}for(i=0;i<20;i++)dist[i].num=1;for(i=20;i<40;i++)dist[i].num=2;for(i=40;i<60;i++)dist[i].num=3;if(c1>=(k/2+1))return(1);else if(c2>=(k/2+1))return(2);else if(c3>=(k/2+1))return(3);else return(0);}void rate(inta,intb,int c){printf("第一类的聚类正确率为%f\n",a/30.0);printf("第二类的聚类正确率为%f\n",b/30.0);printf("第三类的聚类正确率为%f\n",c/30.0);printf("总体正确率为%f\n",(a+b+c)/90.0);}void main(){int i,j,kind,c1,c2,c3;c1=c2=c3=0;float train[n][6],test[n+30][6];for(i=0;i<20;i++)dist[i].num=1;for(i=20;i<40;i++)dist[i].num=2;for(i=40;i<60;i++)dist[i].num=3;FILE *fp;if((fp=fopen("train.txt","r"))==NULL)printf("error!\n");for(i=0;i<n;i++){for(j=0;j<6;j++)fscanf(fp,"%f",&train[i][j]);}fclose(fp); //iris训练样本导入if((fp=fopen("test.txt","r"))==NULL)printf("error!\n");for(i=0;i<(150-n);i++){for(j=0;j<6;j++)fscanf(fp,"%f",&test[i][j]);}fclose(fp); //导入测试样本for(j=0;j<90;j++){for(i=0;i<60;i++){dist[i].d=sqrt(pow(test[j][1]-train[i][1],2)+pow(test[j][2]-train[i][2],2)+pow(test[j][ 3]-train[i][3],2)+pow(test[j][4]-train[i][4],2)); //欧氏距离}selectsort(dist);kind=count(dist);printf("第%d 个测试样本属于第%d 类\n",j+1,kind);if(j>=0&&j<=29&&kind==1)c1++;else if(j>29&&j<=59&&kind==2)c2++;else if(j>59&&j<90&&kind==3)c3++;}rate(c1,c2,c3);}。
K-近邻算法⼀、概述k-近邻算法(k-Nearest Neighbour algorithm),⼜称为KNN算法,是数据挖掘技术中原理最简单的算法。
KNN 的⼯作原理:给定⼀个已知标签类别的训练数据集,输⼊没有标签的新数据后,在训练数据集中找到与新数据最邻近的k个实例,如果这k个实例的多数属于某个类别,那么新数据就属于这个类别。
可以简单理解为:由那些离X最近的k个点来投票决定X归为哪⼀类。
图1 图1中有红⾊三⾓和蓝⾊⽅块两种类别,我们现在需要判断绿⾊圆点属于哪种类别当k=3时,绿⾊圆点属于红⾊三⾓这种类别;当k=5时,绿⾊圆点属于蓝⾊⽅块这种类别。
举个简单的例⼦,可以⽤k-近邻算法分类⼀个电影是爱情⽚还是动作⽚。
(打⽃镜头和接吻镜头数量为虚构)电影名称打⽃镜头接吻镜头电影类型⽆问西东1101爱情⽚后来的我们589爱情⽚前任31297爱情⽚红海⾏动1085动作⽚唐⼈街探案1129动作⽚战狼21158动作⽚新电影2467?表1 每部电影的打⽃镜头数、接吻镜头数和电影分类表1就是我们已有的数据集合,也就是训练样本集。
这个数据集有两个特征——打⽃镜头数和接吻镜头数。
除此之外,我们也知道每部电影的所属类型,即分类标签。
粗略看来,接吻镜头多的就是爱情⽚,打⽃镜头多的就是动作⽚。
以我们多年的经验来看,这个分类还算合理。
如果现在给我⼀部新的电影,告诉我电影中的打⽃镜头和接吻镜头分别是多少,那么我可以根据你给出的信息进⾏判断,这部电影是属于爱情⽚还是动作⽚。
⽽k-近邻算法也可以像我们⼈⼀样做到这⼀点。
但是,这仅仅是两个特征,如果把特征扩⼤到N个呢?我们⼈类还能凭经验“⼀眼看出”电影的所属类别吗?想想就知道这是⼀个⾮常困难的事情,但算法可以,这就是算法的魅⼒所在。
我们已经知道k-近邻算法的⼯作原理,根据特征⽐较,然后提取样本集中特征最相似数据(最近邻)的分类标签。
那么如何进⾏⽐较呢?⽐如表1中新出的电影,我们该如何判断他所属的电影类别呢?如图2所⽰。
k- 最近邻算法摘要:1.K-最近邻算法的定义和原理2.K-最近邻算法的计算方法3.K-最近邻算法的应用场景4.K-最近邻算法的优缺点正文:1.K-最近邻算法的定义和原理K-最近邻(K-Nearest Neighbors,简称KNN)算法是一种基于相似度度量的聚类分析方法。
该算法的基本思想是:在数据集中,每个数据点都与距离它最近的K 个数据点属于同一类别。
这里的K 是一个超参数,可以根据实际问题和数据情况进行调整。
KNN 算法的主要步骤包括数据预处理、计算距离、确定最近邻和进行分类等。
2.K-最近邻算法的计算方法计算K-最近邻算法的过程可以分为以下几个步骤:(1)数据预处理:将原始数据转换为适用于计算距离的格式,如数值型数据。
(2)计算距离:采用欧氏距离、曼哈顿距离等方法计算数据点之间的距离。
(3)确定最近邻:对每个数据点,找到距离最近的K 个数据点。
(4)进行分类:根据最近邻的数据点所属的类别,对目标数据点进行分类。
3.K-最近邻算法的应用场景K-最近邻算法广泛应用于数据挖掘、机器学习、模式识别等领域。
常见的应用场景包括:(1)分类:将数据点划分到不同的类别中。
(2)回归:根据特征值预测目标值。
(3)降维:通过将高维数据映射到低维空间,减少计算复杂度和噪声干扰。
4.K-最近邻算法的优缺点K-最近邻算法具有以下优缺点:优点:(1)简单易懂,易于实现。
(2)对数据规模和分布没有特殊要求。
(3)对噪声不敏感,具有较好的鲁棒性。
缺点:(1)计算复杂度高,尤其是大规模数据集。
(2)对离群点和噪声敏感。
R语⾔学习笔记—K近邻算法K近邻算法(KNN)是指⼀个样本如果在特征空间中的K个最相邻的样本中的⼤多数属于某⼀个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
即每个样本都可以⽤它最接近的k个邻居来代表。
KNN算法适合分类,也适合回归。
KNN算法⼴泛应⽤在推荐系统、语义搜索、异常检测。
KNN算法分类原理图:图中绿⾊的圆点是归属在红⾊三⾓还是蓝⾊⽅块⼀类?如果K=5(离绿⾊圆点最近的5个邻居,虚线圈内),则有3个蓝⾊⽅块是绿⾊圆点的“最近邻居”,⽐例为3/5,因此绿⾊圆点应当划归到蓝⾊⽅块⼀类;如果K=3(离绿⾊圆点最近的3个邻居,实线圈内),则有两个红⾊三⾓是绿⾊圆点的“最近邻居”,⽐例为2/3,那么绿⾊圆点应当划归到红⾊三⾓⼀类。
由上看出,该⽅法在定类决策上只依据最邻近的⼀个或者⼏个样本的类别来决定待分样本所属的类别。
KNN算法实现步骤:1. 数据预处理2. 构建训练集与测试集数据3. 设定参数,如K值(K⼀般选取样本数据量的平⽅根即可,3~10)4. 维护⼀个⼤⼩为K的的按距离(欧⽒距离)由⼤到⼩的优先级队列,⽤于存储最近邻训练元组。
随机从训练元组中选取K个元组作为初始的最近邻元组,分别计算测试元组到这K个元组的距离将训练元组标号和距离存⼊优先级队列5. 遍历训练元组集,计算当前训练元组与测试元组的距离L,将所得距离L与优先级队列中的最⼤距离Lmax6. 进⾏⽐较。
若L>=Lmax,则舍弃该元组,遍历下⼀个元组。
若L < Lmax,删除优先级队列中最⼤距离的元组,将当前训练元组存⼊优先级队列7. 遍历完毕,计算优先级队列中K个元组的多数类,并将其作为测试元组的类别8. 测试元组集测试完毕后计算误差率,继续设定不同的K值重新进⾏训练,最后取误差率最⼩的K值。
R语⾔实现过程:R语⾔中进⾏K近邻算法分析的函数包有class包中的knn函数、caret包中的train函数和kknn包中的kknn函数knn(train, test, cl, k = 1, l = 0, prob = FALSE, use.all = TRUE)参数含义:train:含有训练集的矩阵或数据框test:含有测试集的矩阵或数据框cl:对训练集进⾏分类的因⼦变量k:邻居个数l:有限决策的最⼩投票数prob:是否计算预测组别的概率use.all:控制节点的处理办法,即如果有多个第K近的点与待判样本点的距离相等,默认情况下将这些点都作为判别样本点;当该参数设置为FALSE时,则随机选择⼀个点作为第K近的判别点。
【机器学习】k-近邻算法以及算法实例时间 2015-01-26 14:31:00 博客园-原创精华区原文/jtianwen2014/p/4249003.html主题算法数据挖掘机器学习中常常要用到分类算法,在诸多的分类算法中有一种算法名为k-近邻算法,也称为kNN算法。
一、kNN算法的工作原理二、适用情况三、算法实例及讲解---1.收集数据---2.准备数据---3.设计算法分析数据---4.测试算法一、kNN算法的工作原理官方解释:存在一个样本数据集,也称作训练样本集,并且样本中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系,输入没有标签的新数据后,将新数据的每个特征与样本集中的数据对应的特征进行比较,然后算法提取样本集中特征最相似的数据(最近邻)的分类标签。
一般来说,我们只选择样本集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数,最后,选择k个最相似的数据中出现次数最多的分类,作为新数据的分类。
我的理解:k-近邻算法就是根据“新数据的分类取决于它的邻居”进行的,比如邻居中大多数都是退伍军人,那么这个人也极有可能是退伍军人。
而算法的目的就是先找出它的邻居,然后分析这几位邻居大多数的分类,极有可能就是它本省的分类。
二、适用情况优点:精度高,对异常数据不敏感(你的类别是由邻居中的大多数决定的,一个异常邻居并不能影响太大),无数据输入假定;缺点:计算发杂度高(需要计算新的数据点与样本集中每个数据的“距离”,以判断是否是前k个邻居),空间复杂度高(巨大的矩阵);适用数据范围:数值型(目标变量可以从无限的数值集合中取值)和标称型(目标变量只有在有限目标集中取值)。
三、算法实例及讲解例子中的案例摘《机器学习实战》一书中的,代码例子是用python编写的(需要matplotlib和numpy库),不过重在算法,只要算法明白了,用其他语言都是可以写出来的:海伦一直使用在线约会网站寻找合适自己的约会对象。