案例分析 江苏省各市经济发展水平的聚类分析
- 格式:doc
- 大小:164.50 KB
- 文档页数:5

中国产经CHINESE INDUSTRY &ECONOMY中国产经Chinese Industry &Economy摘要:近年来,我国经济快速发展,人民生活幸福感也不断提高,但不同地域的人民幸福感仍有较大差别。
经济的发展状况与人民幸福指数相关联,因此认清目前我国各省的经济发展状况显得尤为重要。
本文通过变量聚类法将搜集到的11个指标聚为知足充裕体验指数、公共服务体验指数和社会信心体验指数。
通过IML 计算3个类成分得分,对各省在3个类成分上分别排名,运用类成分进行系统聚类,将我国各省的经济发展水平划分为4类。
济发展水平最高的北京、上海归属第一类;经济发展水平较高的河北、天津等24个省份为第二类;经济发展水平一般的内蒙古、新疆等4个省为第三类;发展水平较低的西藏为第四类。
本文基于研究结果提出了相应的对策及建议,为进一步提高各省经济发展水平,提高人民幸福指数提供理论依据。
关键词:变量聚类;系统聚类;幸福指数一、问题背景(一)选题背景自改革开放至今,虽然我国的经济有了快速健康的发展,但各地区仍存有发展不平衡的态势。
党在十七大报告中明确指出:“逐步提高居民收入在国民收入分配中的比重,整顿分配秩序,逐步扭转收入分配差距扩大超势。
”为此,我们根据居民收入的不同种类,将收入状况趋同的地区进行了系统地分类,以找到解决当前面临的增加居民收入问题的突破口。
(二)选题意义为了更好地提高我国城乡居民的幸福感,清楚地认识我国各省的经济发展状况。
本文采用聚类分析法,对2017年我国31个省、市、自治区的经济发展状况进行了系统性的研究。
通过变量聚类法对我国各省的居民的可支配收入情况进行聚类。
通过选择合理的反应幸福指数的变量用主成分分析法进行排名,并用聚类分析法将幸福指数划分为生活质量与幸福、社会环境与幸福和自然环境与幸福三部分,合理地透视我国经济发展的区域性差异。
并基于研究结果,提出了相应的建议,为进一步提高人民生活幸福指数提供理论依据。
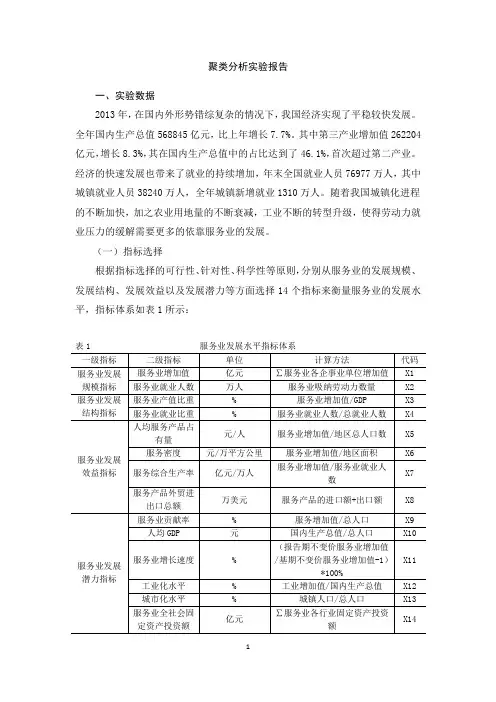
聚类分析实验报告一、实验数据2013年,在国内外形势错综复杂的情况下,我国经济实现了平稳较快发展。
全年国内生产总值568845亿元,比上年增长7.7%。
其中第三产业增加值262204亿元,增长8.3%,其在国内生产总值中的占比达到了46.1%,首次超过第二产业。
经济的快速发展也带来了就业的持续增加,年末全国就业人员76977万人,其中城镇就业人员38240万人,全年城镇新增就业1310万人。
随着我国城镇化进程的不断加快,加之农业用地量的不断衰减,工业不断的转型升级,使得劳动力就业压力的缓解需要更多的依靠服务业的发展。
(一)指标选择根据指标选择的可行性、针对性、科学性等原则,分别从服务业的发展规模、发展结构、发展效益以及发展潜力等方面选择14个指标来衡量服务业的发展水平,指标体系如表1所示:表1 服务业发展水平指标体系(二)指标数据本次实验采用的数据是我国31个省(市、自治区)2012年的数据,原数据均来自《2013中国统计年鉴》以及2013年各省(市、自治区)统计年鉴,不能直接获得的指标数据是通过对相关原始数据的换算求得。
原始数据如表2所示:表2(续)二、实验步骤本次实验是在SPSS中分别利用系统聚类法和K均值法进行聚类分析,具体步骤如下:(一)系统聚类法⒈在SPSS窗口中选择Analyze—Classify—Hierachical Cluster,调出系统聚类分析主界面,将变量X1-X14移入Variables框中。
在Cluster栏中选择Cases单选按钮,即对样品进行聚类(若选择Variables,则对变量进行聚类)。
在Display栏中选择Statistics和Plots复选框,这样在结果输出窗口中可以同时得到聚类结果统计量和统计图。
⒉点击Statistics按钮,设置在结果输出窗口中给出的聚类分析统计量。
这里选择系统默认值,点击Continue按钮,返回主界面。
⒊点击Plots按钮,设置结果输出窗口中给出的聚类分析统计图。

案例分析江苏省各市经济发展水平的聚类分析标题:案例分析:江苏省各市经济发展水平的聚类分析一、引言江苏省作为中国的重要经济大省,其各市的经济发展水平一直以来备受。
对江苏省各市经济发展水平进行准确的评估,不仅有助于我们理解各市的经济现状,也有助于制定针对性的经济发展策略。
本文采用聚类分析的方法,对江苏省各市的经济发展水平进行分类,并对其结果进行深入剖析。
二、数据来源与方法1、数据来源我们选取了江苏省各市的GDP、人均GDP、工业增加值、固定资产投资、社会消费品零售总额、出口总额、地方财政收入等经济指标作为数据来源。
这些数据均来自江苏省统计局发布的年度报告,具有权威性和准确性。
2、方法选择考虑到数据的复杂性和多元性,我们选择采用聚类分析的方法对江苏省各市的经济发展水平进行分类。
聚类分析是一种无监督学习的方法,能够根据数据的相似性将数据集划分为不同的类别。
在聚类分析中,我们使用了K-means算法,这是一种常见的聚类算法,能够根据设定的类别数,将数据集划分为不同的类别。
三、结果与分析1、数据预处理在进行聚类分析之前,我们首先对收集到的数据进行预处理,包括缺失值填充、异常值处理以及标准化处理等。
经过预处理后的数据,能够更好地反映江苏省各市的经济发展水平。
2、聚类分析结果我们设定类别数为3,对江苏省各市的经济发展水平进行聚类分析。
经过多次尝试和调整,最终得到了较为合理的聚类结果。
该结果将江苏省各市划分为三个类别:高发展水平市、中发展水平市和低发展水平市。
3、结果分析(1)高发展水平市:这一类别的城市主要包括南京、苏州和无锡等城市。
这些城市的经济发展水平较高,各项经济指标均高于全省平均水平。
这些城市的经济结构较为合理,工业增加值和地方财政收入较高,显示出较强的经济实力和竞争力。
(2)中发展水平市:这一类别的城市主要包括常州、南通、徐州等城市。
这些城市的经济发展水平处于全省平均水平之上,但相较于高发展水平市还存在一定差距。


全国30市自治区经济发展水平综合评价——基于因子分析和聚类分析近年来,我国经济发展迅速,全国各地区也呈现出不同程度的经济发展水平。
为了对全国30个市自治区的经济发展水平进行综合评价,基于因子分析和聚类分析的方法被广泛应用。
首先,我们通过因子分析的方法对数据进行降维和综合评价。
因子分析将多个变量综合为少数几个因子,并可以解释这些因子与原始变量之间的关系。
我们选择了GDP总量、人均GDP、产业结构、基础设施建设、外资吸引等指标作为评价经济发展水平的变量。
通过因子分析,我们可以得到几个综合指标,用于评价各个市自治区的经济发展水平。
接着,我们可以利用聚类分析的方法进行分类。
聚类分析是将样本划分为几个相似的类别,每个类别内的样本相似度高,而类别间的相似度较低。
我们可以通过聚类分析得到若干个类别,这些类别可以代表不同的经济发展水平。
通过将市自治区进行分类,可以更加直观地展示各地区之间的差异,也可以为地方政府提供参考。
最后,我们可以将因子分析和聚类分析的结果进行综合。
通过对因子得分和聚类结果的比较,可以得到更加准确的综合评价。
在综合评价的过程中,我们可以进一步分析各个市自治区的优势和劣势,以及存在的问题和潜在的发展机会。
这些分析结果可以为地方政府提供经济发展策略和政策的参考。
在实施全国30市自治区经济发展水平综合评价的过程中,我们需要充分考虑指标的选择和权重的确定。
指标的选择应当代表经济发展的各个方面,权重的确定应当根据实际情况和专家意见综合考虑。
另外,我们需要注意数据的可靠性和准确性,以及分析方法的合理性和可操作性。
总之,基于因子分析和聚类分析的方法可以对全国30市自治区的经济发展水平进行综合评价。
这种方法能够降低数据的维度,提取出关键的因子,并对样本进行分类。
通过综合分析和评价,可以为决策者提供参考,促进经济发展水平的提高。

经济统计数据的聚类分析方法引言:经济统计数据是经济研究和政策制定的重要基础,通过对经济数据的分析和解读,可以帮助我们了解经济的发展趋势、结构特征以及潜在问题。
而聚类分析作为一种常用的数据分析方法,可以将相似的经济指标归为一类,帮助我们更好地理解经济数据的内在联系和规律。
本文将介绍经济统计数据的聚类分析方法,探讨其在经济研究中的应用。
一、聚类分析的基本原理聚类分析是一种无监督学习方法,它通过对数据集进行分组,将相似的样本归为一类。
其基本原理是通过计算样本之间的相似性或距离,将相似性较高的样本划分为同一类别。
聚类分析可以帮助我们发现数据集中的内在结构,并将数据集划分为若干个互不重叠的类别。
二、经济统计数据的聚类分析方法在进行经济统计数据的聚类分析时,首先需要选择适当的指标。
常用的指标包括国内生产总值、消费者物价指数、劳动力参与率等。
接下来,我们可以使用不同的聚类算法对这些指标进行分析。
1. K-means聚类算法K-means是一种常用的聚类算法,它将数据集分为K个互不重叠的类别。
该算法首先随机选择K个初始聚类中心,然后通过计算每个样本与聚类中心的距离,将样本分配给距离最近的聚类中心。
接着,更新聚类中心的位置,并迭代上述过程,直到聚类中心的位置不再发生变化。
K-means算法对初始聚类中心的选择较为敏感,因此需要进行多次试验,选取最优的结果。
2. 层次聚类算法层次聚类算法是一种自底向上的聚类方法,它首先将每个样本视为一个独立的类别,然后通过计算样本之间的相似性,逐步将相似的样本合并为一类。
该算法可以生成一个聚类树状图,帮助我们观察不同层次的聚类结果。
层次聚类算法的优点是不需要预先指定聚类个数,但是计算复杂度较高。
3. 密度聚类算法密度聚类算法是一种基于样本密度的聚类方法,它将样本空间划分为具有高密度的区域和低密度的区域。
该算法通过计算每个样本周围的密度,并将密度较高的样本作为核心对象,进而将其邻近的样本归为一类。

江苏区域经济发展差异泰尔指数分析区域经济发展差异是一个全球性的问题,世界各地经济发展过程中都曾面临此问题。
改革开放至今,江苏备受区域经济发展差异的困扰,特别是苏北地区由于基础设施薄弱、经济结构单一等诸多因素,经济发展相对落后,并且与苏南的发展差距日趋扩大。
本文利用泰尔指数分析江苏区域经济发展差异,力求找出制约苏北经济发展的因素,并提出对策建议。
关键词:区域经济GDP 泰尔指数贡献率江苏区域经济发展差异分析研究区域经济差异,必须选择适当的测度指标。
衡量区域经济发展的方法很多,有绝对差异和相对差异之分。
常用的绝对差异测算方法有标准差、极差、平均差等;常用的相对差异测算方法有变异系数、加权变异系数、基尼系数和泰尔指数等。
本文采用泰尔指数来测算江苏区域经济发展差异。
(一)泰尔(Theil)指数泰尔指数又称泰尔熵、泰尔系数,它是运用信息理论推出的一个可以按加法分解的不平等指数。
泰尔指数的算法有多种,因采用的权数不同,加权计算产生不同泰尔指数。
泰尔指数的计算公式为:式中:yi为i区域研究指标所占的比重;pi为权数。
泰尔系数T越大,表示各区域间经济发展水平差异越大;反之,就表示各区域间经济发展水平差异越小。
泰尔指数的优点在于可以细分区域间差异和区域内差异,可以按组内差距和组间差距进行分解,将组内与组间的差距或不平等综合成总体的差距。
把江苏的总体差异进行分解,泰尔指数分解如下:T=T1+T2即总体差异T=区域间差异T1+区域内差异T2。
以江苏省为例,具体计算如下:T1=NS•In(ns/GDPs)+nm•In(nm/GDPm)+nn•In(nn/GDPn)T2=ns•Ts+nm•Tm+nn•TnT=T1+T2=T1+ns•Ts+nm•Tm+nn•Tn方程两边同除以T,得:式中:TS、TM、TN分别表示苏南、苏中、苏北地区的泰尔指数;GDPi 表示某市GDP占江苏省GDP的比重;GDPs、GDPm、GDPn分别表示苏南、苏中、苏北地区GDP占江苏省GDP的比重;ni表示某市人口占江苏省人口的比重;ns、nm、nn分别表示苏南、苏中、苏北地区人口占江苏省人口的比重;、、、分别为地区间、苏南、苏中、苏北对总体差异的贡献率。

聚类分析法在区域经济划分中的应用_以江苏省作实证研究_魏炜2008年10月号市场周刊·理论研究一、引言江苏省的经济在全国是处于领先地位的,但是省内各地区的经济发展并不平衡,存在着明显的地区差异。
为了快速、有效地解决差异带来的种种经济问题,姚泽清、赵喜仓等人已经对江苏省作出了区域经济划分并得出了不同的分类标准。
较之已有的区域划分,本文考虑了更全面的指标,搜集了更新的数据,运用主成分分析和聚类分析相结合的方法对数据处理,结合江苏省省情将13市划分为5类,使得分类更为合理、更符合实际,为现阶段地市经济发展和平衡区域差异提供了一定的依据。
二、评价体系的建立评价一个地区的经济发展水平,必须建立适当的指标体系。
结合江苏省省情,参照国内外经济评价的资料,本文选取了有关城市基本情况、经济发展、工业化、城市化、对外贸易、教育通讯、基础设施以及可持续发展的33项指标来进行评价,具体指标如下:1、基本情况:年末总人口(万人)、土地面积(平方公里)。
2、综合经济:地区生产总值(亿元)、第一产业生产总值(亿元)、第二产业生产总值(亿元)、工业生产总值(亿元)、第三产业生产总值(亿元)、人均地区生产总值(元)、利税总额(亿元)、利润总额(亿元)、财政收入(亿元)、财政支出(亿元)。
3、工业化水平:工业企业个数(个)、工业总产值(亿元)、工业增加值(亿元)。
4、对内对外贸易:城镇固定资产投资额(亿元)、进出口总额(亿元)、出口总额(亿元)、实际外商直接投资额(万美元)。
5、生活水平及城市基础设施:教育事业支出(亿元)、社会消费品零售总额(亿元)、在岗职工平均工资(元)、农民人均纯收入(元)、农民人均生活消费品支出(元)、邮电业务总量(亿元)、移动电话用户(万户)、国际互联网用户(万户)、各类技术专业人员(万人)、公共图书馆(个)、卫生机构数(个)。
6、可持续发展:环境污染治理投资额(万元)、工业固体废物综合利用率(%)、三废综合利用产品产值(万元)。

聚类分析⽅法详细介绍和举例聚类分析例如:下表是1999年中国省、⾃治区的城市规模结构特征的⼀些数据,可通过聚类分析将这些省、⾃治区进⾏分类,具体过程如下:省、⾃治区⾸位城市规模(万⼈)城市⾸位度四城市指数基尼系数城市规模中位值(万⼈)京津冀699.70 1.4371 0.9364 0.7804 10.880 ⼭西179.46 1.8982 1.0006 0.5870 11.780 内蒙古111.13 1.4180 0.6772 0.5158 17.775 辽宁389.60 1.9182 0.8541 0.5762 26.320 吉林211.34 1.7880 1.0798 0.4569 19.705 ⿊龙江259.00 2.3059 0.3417 0.5076 23.480⼀、聚类分析的数据处理1、地理数据的对数变换:原始数据⾃然对数变换省、⾃治区⾸位城市规模(万⼈)城市⾸位度四城市指数基尼系数城市规模中位值(万⼈)⾸位城市规模(万⼈)城市⾸位度四城市指数基尼系数城市规模中位值(万⼈)京津冀699.7 1.4371 0.9364 0.7804 10.88 6.5507 0.3626 -0.0657 -0.2479 2.3869 ⼭西179.46 1.8982 1.0006 0.587 11.78 5.1900 0.6409 0.0006 -0.5327 2.4664 内蒙古111.13 1.418 0.6772 0.5158 17.775 4.7107 0.3492 -0.3898 -0.6620 2.8778 辽宁389.6 1.9182 0.8541 0.5762 26.32 5.9651 0.6514 -0.1577 -0.5513 3.2703 吉林211.34 1.788 1.0798 0.4569 19.705 5.3535 0.5811 0.0768 -0.7833 2.9809 ⿊龙江259 2.3059 0.3417 0.5076 23.48 5.5568 0.8355 -1.0738 -0.6781 3.1561 2、地理数据标准化:⾃然对数变换标准差标准化数据⾸位城市规模(万⼈)城市⾸位度四城市指数基尼系数城市规模中位值(万⼈)⾸位城市规模(万⼈)城市⾸位度四城市指数基尼系数城市规模中位值(万⼈)6.5507 0.3626 -0.0657 -0.2479 2.3869 1.5572 -1.1123 0.4753 1.7739 -1.30255.1900 0.6409 0.0006 -0.5327 2.4664 -0.5698 0.3795 0.6309 0.2335 -1.08204.7107 0.3492 -0.3898 -0.6620 2.8778 -1.3189 -1.1841 -0.2851 -0.4660 0.05935.9651 0.6514 -0.1577 -0.5513 3.2703 0.6419 0.4356 0.2594 0.1330 1.14835.3535 0.5811 0.0768 -0.7833 2.9809 -0.3142 0.0588 0.8096 -1.1218 0.34535.5568 0.8355 -1.0738 -0.6781 3.1561 0.0037 1.4225 -1.8900 -0.5526 0.8316⼆、采⽤欧⽒距离,求出欧式距离系数欧式距离系数表d1 d2 d3 d4 d5 d6 d1 0d2 1.3561 0d3 1.7735 1.0618 0d4 1.5479 1.1484 1.2891 0d5 1.7936 0.9027 0.9235 0.8460 0d6 2.2091 1.5525 1.5312 1.1464 1.4006 0三、最短距离法进⾏聚类分析如下:第⼀步:以欧式距离作为分类统计量,得出初始距离矩阵D(0)D(0)表G1 G2 G3 G4 G5 G2 1.3561G3 1.7735 1.0618G4 1.5479 1.1484 1.2891G5 1.7936 0.9027 0.9235 0.8460G6 2.2091 1.5525 1.5312 1.1464 1.4006第⼆步:在D(0)中,最⼩元素为D54=0.846,将G5与G4合并成⼀新类G7,G7={G5,G4},然后在计算新类G7与其它各类间的距离D7,1= min(d41,d51)=min(1.5479, 1.7936)= 1.5479D7,2= min(d42,d52) = min(1.1484,0.9027)= 0.9027D7,3= min(d43,d53) = min(1.2891, 0.9235)= 0.9235D7,6= min(d64,d65) = min(1.1464, 1.4006)= 1.1464第三步:作D (1)表,先从D(0)表中删除G4,G5类所在⾏列的所有元素,然后再把新计算出来的G7与其它类间的距离D71,D72,D73填到D (0)中,得D(I)表第四步:在D (1)中,最⼩元素为D72=0.9027,将G7与G2合并成⼀新类G8,G8={G2,G7}={G2,G4,G5},然后在计算新类G8与其它各类间的距离D8,1= min(d21,d71)= min(1.3561, 1.5479)= 1.3561 D8,3= min(d23,d73) = min(1.0618, 0.9235)= 0.9235 D8,6= min(d62,d76)= min(1.5525, 1.1464)= 1.1464第五步:作D (2)表,先从D(1)表中删除G2,G7类所在⾏列的所有元素,然后再把新计算出来的G8与其它类间的距离D81,D83,D86填到D (2)中,得D(2)表D (2)表G1 G3 G6 G3 1.7735 G6 2.2091 1.5312 G81.35610.92351.1464第六步:在D (2)中,最⼩元素为D38=0.9235,将G8与G3合并成⼀新类G9,G9={G3,G8},然后在计算新类G9与其它各类间的距离D9,1= min(d13,d18) = min(1.7735, 1.3561)= 1.3561 D9,6= min(d36,d86) = min(1.5312, 1.1464)= 1.1464第七步:作D (3)表,先从D(2)表中删除G3,G8类所在⾏列的所有元素,然后再把新计算出来的G9与其它类间的距离D91 ,D96填到D (3)中,得D(3)表第⼋步:在D (3)中,最⼩元素为D69= 1.1464,将G6与G9合并成⼀新类G10,G10={G6,G9},然后在计算新类G10与其它各类间的距离D10,1= min(d16,d69) = min(2.2091, 1.1464)= 1.1464第九步:作D (4)表,先从D(3)表中删除G6,G9类所在⾏列的所有元素,然后再把新计算出来的G10与其它类间的距离D10,1填到D (4)中,得D(4)表D (1)表G1 G2 G3G6G2 1.3561 G3 1.7735 1.0618 G6 2.2091 1.5525 1.5312 G71.54790.90270.9235 1.1464D (3)表G1 G6 G6 2.2091 G9 1.3561 1.1464D(4)表G1G10 1.1464G11={G10.G1}由此表可知,G10和G1类最后合成了⼀类,计算过程结束。


全国各省经济的聚类分析摘要 (2)引言 (2)一聚类分析 (2)二聚类分析的优点 (2)三聚类分析相比较于其他分析方法而言 (2)实验方案 (3)1.1数据统计 (3)1.2聚类分析 (3)表1 (4)2结果分析与讨论 (5)表2 (5)表3 (6)表4 (6)表5 (7)图1 (8)总结 (8)小结 (9)参考文献 (9)摘要:改革开放以来,中国各省市在经济发展方面都取得了显著的成绩。
这篇论文利用SPSS软件对全国31个省、直辖市、自治区(浙江、湖南、甘肃除外)的主要经济指标进行聚类分析,将其经济分成4种类型,并对浙江、湖南、甘肃进行类型判别分析。
通过这两个方法对全国各省进行经济分类。
本文选取了7项经济指标作为决定经济类型的影响因素,各项数据均来自2010年国家统计年鉴。
分析结果表明:北京市和上海市为第一类经济类型;江苏省和山东省为第三类型;广东省为第四类经济;其他25个省、直辖市、自治区均属于第二类型。
关键词:聚类分析、经济类型引言:一聚类分析(cluster analysis)是一组将研究对象分为相对同质的群组(clusters)的统计分析技术。
聚类分析区别于分类分析(classification analysis) ,后者是有监督的学习。
它直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。
系统聚类分析又称集群分析,是聚类分析中应用最广的一种方法,它根据样本的多指标(变量)、多个观察数据,定量地确定样品、指标之间存在的相似性或亲疏关系,并据此连结这些样品或指标,归成大小类群,构成分类树状图或冰柱图。
二聚类分析的优点:聚类分析简单、直观;主要应用于探索性的研究,其分析的结果可以提供多个可能的解,选择最终的解需要研究者的主观判断和后续的分析;不管实际数据中是否真正存在不同的类别,利用聚类分析都能得到分成若干类别的解;聚类分析的解完全依赖于研究者所选择的聚类变量,增加或删除一些变量对最终的解都可能产生实质性的影响。
关于江苏省城市化水平的聚类分析摘要:本文结合江苏省具体情况,收集相关资料,运用聚类分析法建立模型来研究江苏省13个城市的城市化进程,选取11个反映城市化进程的典型指标进行聚类分析,将13个城市进行分类,反映出江苏省各城市的城市化发展水平和进程,并对分类结果进行分析,提出相关可行性建议,也为政府制定相关决策提供理论依据。
关键词:江苏省各市;城市化;主要指标;聚类分析一、城市化主要特征城市化是一个非常复杂的社会经济现象,它是城镇数量和市镇人口不断增加,并引起产业结构、就业结构和人们生活方式日趋现代化的历史过程,其主要特征:在城市数量、规模和密度方面,表现为城市数量不断增加,城市规模逐渐扩大,城市密度不断提高。
在人口方面,表现为市镇人口比重不断上升,乡村人口比重逐步下降。
在就业结构方面,表现为农业从业人员比重下降,非农业从业人员比重上升。
在产值结构方面,表现为第一产业产值比重逐渐下降,第二、三产业产值比重逐渐上升。
在居民生活质量和环境方面,表现为人们收入水平和消费水平不断提高,消费结构日趋优化,生活服务设施日益健全,生活环境逐步改善。
本文运用聚类分析法建立模型来研究江苏省13个城市的城市化水平。
二、聚类分析的含义聚类分析又称群分析,它是对样品或指标进行分类的一种多元统计方法。
聚类分析是将分类对象置于一个多维空间中,按照它们空间关系的亲疏程度进行分类。
通俗的讲,聚类分析就是根据事物彼此不同的属性进行辨认,将具有相似属性的事物聚为一类,使得同一类的事物具有高度的相似性。
在实际研究中,既可以对样本个体进行聚类,也可以对研究变量进行聚类,对样本个体进行聚类,在市场研究中,聚类常用于市场细分研究,寻找不同目标市场及其构成者特征,也可以用于确定产品各属性的同质性。
三、江苏省城市化水平的聚类分析一个地区的城市化发展水平,主要由该地区的经济发展、社会发展、基础设施建设和环境保护等方面反映。
因此我们从人口城市化、经济城市化、生活质量城市化、地域景观城市化、环境状态城市化这几个方面构建城市化发展水平评价指标体系。
聚类分析法经典案例聚类分析法是一种常用的数据分析方法,它通过对数据进行分类和分组,帮助我们发现数据中的内在规律和特征。
在实际应用中,聚类分析法被广泛运用于市场营销、社交网络分析、医学诊断、图像处理等领域。
下面,我们将介绍一些聚类分析法的经典案例,帮助大家更好地理解和应用这一方法。
首先,我们来看一个市场营销领域的案例。
某公司想要对其客户进行分类,以便更好地制定营销策略。
他们收集了客户的消费行为、年龄、性别、地理位置等数据,并利用聚类分析法对客户进行了分组。
通过分析,他们发现客户可以被分为三大类,高消费高端用户、中等消费稳定用户和低消费新用户。
有了这些分类信息,公司可以针对不同类型的客户制定不同的营销策略,提高市场营销效率。
其次,我们来看一个社交网络分析的案例。
一家社交媒体公司希望了解用户在平台上的行为和兴趣,以便更好地推荐内容和广告。
他们利用用户的浏览记录、点赞行为、评论信息等数据,通过聚类分析法将用户分为几个群体。
通过分析,他们发现用户可以被分为电影爱好者、音乐迷、美食达人等不同类型的群体。
有了这些分类信息,社交媒体公司可以更精准地为用户推荐内容和广告,提高用户满意度和广告点击率。
再次,我们来看一个医学诊断的案例。
医院收集了患者的临床症状、实验室检查结果、病史等数据,希望通过聚类分析法对患者进行分类,以便更好地制定治疗方案。
通过分析,他们发现患者可以被分为几个病情严重程度不同的群体。
有了这些分类信息,医生可以更好地制定个性化的治疗方案,提高治疗效果和患者生存率。
最后,我们来看一个图像处理的案例。
一家无人驾驶车辆公司希望通过图像识别技术对道路上的车辆和行人进行分类,以便更好地进行交通管理和安全预警。
他们利用摄像头采集的图像数据,通过聚类分析法将道路上的车辆和行人进行分类。
通过分析,他们可以更准确地识别不同类型的车辆和行人,并做出相应的交通管理和安全预警措施。
通过以上经典案例的介绍,我们可以看到聚类分析法在不同领域的广泛应用。
全国21个城市社会经济发展指标的聚类分析社会经济发展是一个复杂而多样的过程,可以用各种指标来反映不同城市的发展水平和特点。
通过对全国21个城市的社会经济发展指标进行聚类分析,可以帮助我们更好地了解城市发展的现状和趋势。
首先,我们需要选择适当的指标来衡量城市的社会经济发展。
常见的指标包括人均GDP、城市化率、人口规模、教育水平、就业率、收入水平等。
这些指标代表了一个城市的经济实力、人口规模、教育质量和就业机会等重要方面。
接下来,我们可以使用聚类分析方法对这些指标进行分析。
聚类分析是一种无监督学习的方法,它基于样本间的相似性将样本划分为多个组别。
在这个问题中,我们的样本是21个城市,指标是城市的社会经济发展指标。
聚类分析的主要步骤包括:1.数据准备:将21个城市的社会经济发展指标整理成一个数据矩阵,每个城市对应一行数据,每个指标对应一列数据。
2.数据标准化:对于不同的指标,它们的量纲、单位和范围可能不同,为了进行比较和分析,我们需要对数据进行标准化处理,使得每个指标都具有相同的量纲和范围。
3. 聚类方法选择:选择适当的聚类方法来对数据进行分组。
常见的聚类方法包括K-means聚类、层次聚类等。
不同的聚类方法有不同的特点和适用性,需要根据实际情况选择。
4.聚类分析:根据选择的聚类方法,将数据进行聚类分析。
聚类分析的目标是将21个城市划分为几个组别,使得同一组别内的城市相似度较高,而不同组别之间的城市相似度较低。
5.分析结果解释:对聚类结果进行解释和分析。
可以对每个组别的城市进行比较,分析它们的特点和发展趋势。
也可以对不同指标的贡献度进行分析,找出主要影响城市发展的指标。
通过以上步骤,我们可以对全国21个城市的社会经济发展指标进行聚类分析,得到一些有关城市发展的重要结论。
这些结论可以为政府和决策者提供信息和参考,帮助他们了解不同城市的发展状况和问题,并采取有效的措施来促进城市的发展和改善。
江苏省各市概况江苏省,中国的一个省份,位于长江三角洲地区,拥有丰富的自然资源和悠久的历史文化。
江苏省有许多城市,每个城市都有其独特的特点和魅力。
南京,江苏省的省会城市,是中国历史文化名城之一,有着悠久的历史和文化。
南京是中国重要的综合性工业基地,也是中国重要的交通枢纽,拥有现代化的基础设施和便利的交通网络。
南京的美食也很有名,如南京盐水鸭、金陵糕团、夫子庙小吃等。
苏州,江苏省的重要城市之一,是中国著名的园林城市和旅游城市。
苏州园林是中国园林艺术的代表,有着精美的设计和独特的风格。
苏州的丝绸、刺绣、玉雕等手工艺品也很有名。
无锡,江苏省的重要城市之一,是中国重要的制造业基地和旅游城市。
无锡的制造业发达,拥有许多知名企业,如海澜集团、红豆集团等。
无锡的旅游资源也十分丰富,如太湖风景区、灵山大佛等。
徐州,江苏省的重要城市之一,是中国重要的能源基地和交通枢纽。
徐州的煤炭、电力、机械等产业发达,拥有许多大型企业。
徐州的云龙湖风景区也是一处美丽的旅游景点。
除了以上几个城市,江苏省还有扬州、南通、常州、镇江、泰州等城市,每个城市都有其独特的魅力和特点。
江苏省各市的经济、文化、社会等各个方面都在不断发展和进步,展现出越来越繁荣的景象。
江苏省对外贸易概况江苏省,位于中国东部沿海,自古以来就是中国的重要经济中心。
近年来,江苏省的对外贸易发展迅速,成为了中国对外贸易的重要一环。
一、江苏省对外贸易概况江苏省的对外贸易一直保持稳定增长。
根据最新统计数据,2022年江苏省的货物进出口总额达到了5.5万亿元人民币,同比增长5.8%。
其中,出口总额为3.3万亿元,同比增长9.9%;进口总额为2.2万亿元,同比增长0.9%。
二、主要贸易伙伴江苏省的主要贸易伙伴包括欧盟、美国、东盟、日本等。
其中,对欧盟的贸易额最大,占江苏省对外贸易总额的近三成。
江苏省与“一带一路”沿线国家的贸易往来也日益密切,成为江苏省对外贸易的新增长点。
三、主要出口商品江苏省的主要出口商品包括机电产品、高新技术产品、传统纺织服装等。
案例分析江苏省各市经济发展水平的聚类分析
(赵海兵编写)
[摘要] 改革开放以来,我国经济取得了举世瞩目的发展。
但由于历史、地理以及国家政策导向等原因,地区间的经济水平差异显著。
这不仅体现在东部地区和西部地区的差异,不同省或自治区之间的差异,还体现在同一个省份不同地市间的差异。
做好这些差异经济体的分类,有利于经济政策的针对性和有效性,有利于区域间的合作和优势互补。
本文通过选取江苏省13个地市的国民经济主要指标的经济指标,对处在不同经济发展水平的各个地市进行聚类分析,从而将江苏省划分为三个经济发展水平不同的经济区域,结果供有关决策部门参考。
一、问题的提出
改革开放30年来,我国经济取得了很大的发展。
但同时经济发展中也存在着很多问题,这些问题越来越成为我国经济持续发展的障碍。
地区发展不平衡就是众多问题中的一个。
发达城市都集中东部地区,广大中西部地区和农村地区长期处在不发达状态。
地区发展的失衡使得我国经济难以取得全面的发展,造成的后果是我国经济总量和总体发展速度十分显著,但人均水平长期徘徊在世界的中下层次,大多数人口难以享受到改革的成果。
另外,地区发展的失衡使得人口过度迅速地向少数发达城市集中,已经造成这些城市处于负荷运作,给这些城市的治安、环境和居住条件等带来了巨大的挑战,给城市居住和生活水平造成严重的影响。
也由于地区之间发展的失衡,使得各地区之间的经济难以形成一个顺畅的经济链,从而形成一个良性的经济发展循环体。
要解决好这个问题,首要的问题是对全国范围内,各省市范围内的经济体进行分类,正确划分发达经济体和不发达经济体,进而制定出有针对性的经济政策。
本文对2007年江苏省的13个地市的国民经济进行了聚类分析,试探讨依据本文选取的若干主要经济指标进行的分类是否与传统上将江苏省划分为苏南、苏中和苏北三部分是否一致。
结果供有关决策部门参考。
二、数据分析
基于搜集到的统计资料,为了得出2007年江苏省的13个地市的国民经济分布规律,在众多衡量经济水平的指标中我们将采用下列指标:
x:年末户籍人口(万人)
1
x:城镇化率(%)
2
x:地区生产总值GDP(亿元)
3
x:第三产业占GDP的比重(%)
4
x:城镇固定资产投资额(亿元)
5
x:社会消费品零售总额(亿元)
6
x:城市居民人均可支配收入(元)
7
x:恩格尔系数(城市)(%)
8
x:农村居民人均纯收入(元)
9
x:恩格尔系数(农村)(%)
10
下面的表格是2007年江苏省各市国民经济主要指标值。
现运用SAS软件对上述数据进行聚类分析。
注意,SAS中没有菜单命令来进行聚类分析,所以我们只能编写程序来进行聚类分析。
data jiangsu07;
input dis $ x1-x10;
cards;
南京617.17 76.8 3283.73 48.4 1443.40 1380.46 20317 35.3 8020 37.4
无锡461.74 67.4 3858.54 40.1 1180.74 1134.75 20898 39.8 10026 37.6
常州357.38 60.9 1881.28 37.0 748.89 610.85 19089 35.0 9033 38.0
苏州624.43 65.6 5700.85 34.6 1704.27 1250.05 21260 37.9 10475 35.7
镇江268.78 59.6 1206.69 36.4 363.73 331.36 16775 38.7 7668 39.4
南通766.13 48.6 2111.88 35.1 633.94 736.54 16451 38.5 6905 37.9
扬州459.25 50.2 1311.89 35.3 438.35 418.90 15057 37.9 6586 38.9
泰州500.70 47.6 1201.82 33.2 347.73 321.07 14940 43.1 6469 38.1
徐州940.95 45.8 1679.56 36.0 769.59 543.01 14875 34.9 5534 39.0
连云港482.23 40.5 618.18 36.2 409.56 249.08 13254 38.9 4828 43.7
淮安534.00 39.9 765.23 34.8 394.91 269.40 12164 38.9 5010 43.2
盐城809.79 43.7 1371.26 34.1 470.06 433.74 13857 38.5 6092 41.7
宿迁531.53 34.1 542.00 32.0 256.18 158.87 9468 42.4 4783 46.0
proc cluster data= jiangsu standard method=cen outtree=otree pseudo ccc; id dis;
proc tree data=otree out=gotree nclusters=4;
run;
图1. 重心法的聚类图
图2. ward法的聚类图
图3. 最短距离法的聚类图
图1~3给出了在欧氏距离下分别用重心法、最短距离法和离差平方和(ward)法分析结果的聚类图。
重心法得到的结果和ward方法一致,但,就类和类的之间区别程度而言,重心法的效果没有ward法的好。
最短距离法的结果跟ward的不一致,且,就类和类的之间区别程度而言,其效果远差于ward法和重心法。
我们也尝试了使用类平均法、最长距离法及中间距离法。
他们的聚类图结果类似于重心法,这里为了简洁起见就没有呈现。
三、结果分析
从表3可以看出,按照2007年的10个经济指标,江苏省13个地市可以划分为四类。
第一类为经济发达地区,第二类为中等以上经济区,第三类为中等以下经济区,第四类为低经济区。
第一类中的南京是江苏省的省会城市,也是历史悠久的经济重城,人口相对聚集,所以经济发展水平较高,这是与实际情况相一致的。
苏州和无锡地理环境优越,地理位置上是最接近上海的两个城市,受到上海经济的辐射和影响,在经济发展链上起到了承接和转移的作用,所以近年来经济发展迅速。
第二类中的常州相对除无锡和苏州外离上海距离最近,且地理环境也比较优越。
而镇江离省会南京市比较近。
镇江和扬州都是近代历史重镇,经济文化底蕴比较深厚,因此经济属于中等以上。
第三类都是在苏北地区,相对而言地理环境和气候差一些,近代一直处于较不发达状态。
其中的南通市与上海市较近,但两地之间隔了长江,2008年两市之间新建了大桥,希望这能给南通市的发展带来新的契机。
第四类中的地市也是都处于苏北的地区,远离其它经济重心。
其中的连云港市虽然靠近沿海,但由于自身经济改革开放起步晚,与其他发达地区距离较远,因此,相对江苏其他得天独厚的城市而言,很难短期内独立发展成一个发达地区。
因此他们是江苏省中经济最落后的地区。
四、建议
针对以上对江苏省13个地市特点的分析,我们建议从以下方面来搞好江苏省的经济:
1.继续坚持苏锡常作为上海的下游的角色。
今年来,上海大力发展金融业、物流业等服务
行业,一些食品加工、纺织行业等轻工业都需要向外转移,苏锡常应继续发展自己地理位置的优势,加大引资的力度,发展好自己的经济,同时也要注意吸引人才,提升自己的经济层次,为将来的长三角一体化做相应的准备。
2.大力发展南京市的经济,增强南京市的辐射作用。
常州以西地区由于远离了上海,因此
接受不到上海的辐射作用。
大力发展南京市的经济,增强南京地区的经济活力,不仅能带动江苏省的大片经济区域的发展,也能带动安徽省的马鞍山、合肥市和芜湖市等经济区域的发展,为中部地区的发展做贡献。
3.联合发展徐州和连云港市的经济,使他们成为苏北的一个强劲的经济板块,带动、推动
苏北经济的发展。
利用徐州作为重工业城市和连云港市作为港口城市的优势,实现两市的优势互补。