聚类分析案例
- 格式:docx
- 大小:248.79 KB
- 文档页数:4

案例分析江苏省各市经济发展水平的聚类分析标题:案例分析:江苏省各市经济发展水平的聚类分析一、引言江苏省作为中国的重要经济大省,其各市的经济发展水平一直以来备受。
对江苏省各市经济发展水平进行准确的评估,不仅有助于我们理解各市的经济现状,也有助于制定针对性的经济发展策略。
本文采用聚类分析的方法,对江苏省各市的经济发展水平进行分类,并对其结果进行深入剖析。
二、数据来源与方法1、数据来源我们选取了江苏省各市的GDP、人均GDP、工业增加值、固定资产投资、社会消费品零售总额、出口总额、地方财政收入等经济指标作为数据来源。
这些数据均来自江苏省统计局发布的年度报告,具有权威性和准确性。
2、方法选择考虑到数据的复杂性和多元性,我们选择采用聚类分析的方法对江苏省各市的经济发展水平进行分类。
聚类分析是一种无监督学习的方法,能够根据数据的相似性将数据集划分为不同的类别。
在聚类分析中,我们使用了K-means算法,这是一种常见的聚类算法,能够根据设定的类别数,将数据集划分为不同的类别。
三、结果与分析1、数据预处理在进行聚类分析之前,我们首先对收集到的数据进行预处理,包括缺失值填充、异常值处理以及标准化处理等。
经过预处理后的数据,能够更好地反映江苏省各市的经济发展水平。
2、聚类分析结果我们设定类别数为3,对江苏省各市的经济发展水平进行聚类分析。
经过多次尝试和调整,最终得到了较为合理的聚类结果。
该结果将江苏省各市划分为三个类别:高发展水平市、中发展水平市和低发展水平市。
3、结果分析(1)高发展水平市:这一类别的城市主要包括南京、苏州和无锡等城市。
这些城市的经济发展水平较高,各项经济指标均高于全省平均水平。
这些城市的经济结构较为合理,工业增加值和地方财政收入较高,显示出较强的经济实力和竞争力。
(2)中发展水平市:这一类别的城市主要包括常州、南通、徐州等城市。
这些城市的经济发展水平处于全省平均水平之上,但相较于高发展水平市还存在一定差距。

聚类分析的应用案例聚类分析是一种常用的数据分析方法,它可以帮助我们对数据进行分类和分组,发现数据中的潜在模式和规律。
在现实生活和工作中,聚类分析有着广泛的应用,下面我们将介绍几个聚类分析的应用案例。
首先,聚类分析在市场营销领域有着重要的应用。
在市场营销中,我们常常需要对顾客进行分类,以便针对不同类别的顾客制定不同的营销策略。
通过聚类分析,我们可以根据顾客的消费行为、偏好等特征将顾客进行分类,从而更好地理解顾客群体的特点,并针对性地开展营销活动,提高营销效果。
其次,聚类分析在医学领域也有着重要的应用。
在医学研究中,我们常常需要对疾病患者进行分类,以便更好地了解不同类型患者的病情特点和治疗效果。
通过聚类分析,我们可以根据患者的临床表现、病情指标等特征将患者进行分类,从而更好地指导临床诊断和治疗方案的制定,提高治疗效果和患者生存率。
此外,聚类分析还在推荐系统中有着重要的应用。
在电子商务平台和社交媒体平台上,推荐系统可以根据用户的行为和偏好向其推荐商品、信息等内容。
而聚类分析可以帮助推荐系统对用户进行分类,从而更好地理解用户的兴趣和偏好,提高推荐的准确性和个性化程度,增强用户体验。
最后,聚类分析还在金融领域有着重要的应用。
在金融风控和信用评估中,我们常常需要对客户进行分类,以便更好地评估客户的信用风险和制定个性化的信贷方案。
通过聚类分析,我们可以根据客户的财务状况、信用记录等特征将客户进行分类,从而更好地了解客户的信用状况,提高风险控制的精准度和效果。
总之,聚类分析在各个领域都有着重要的应用,它可以帮助我们更好地理解数据和问题的本质,发现数据中的潜在规律和价值信息,为决策提供科学依据。
随着数据科学和人工智能技术的不断发展,相信聚类分析的应用领域会越来越广泛,对我们的生活和工作产生越来越大的影响。

聚类分析案例范文聚类分析是一种无监督机器学习算法,它通过将数据集中的观测值分成不同的组或簇来发现数据之间的内在结构和相似性。
这种方法可以帮助我们理解数据集,发现隐藏的模式和关联性,并且可以应用于各种领域,包括市场细分、社交网络分析、生物信息学和图像处理等。
以下是一个关于使用聚类分析方法的案例研究,该案例介绍了如何使用聚类分析来帮助一家电商企业在众多商品中挖掘潜在的市场细分。
背景介绍:电商企业销售了大量商品,这些商品拥有不同的特征和属性。
该企业希望利用这些数据来了解他们的客户,并为不同的产品类型制定个性化的推广和营销策略。
为了实现这一目标,他们决定使用聚类分析方法来将客户细分成不同的群组,并理解他们的相似性和差异性。
数据收集:该企业从其销售系统中收集了一份包含多个属性的数据集。
这些属性包括:年龄、性别、购买历史、购买频率、平均订单金额等。
这些属性可以反映客户的购买行为和偏好。
数据预处理:在进行聚类分析之前,需要对数据进行预处理。
这包括对缺失值进行处理、进行数值归一化等。
然后,根据业务需求,选择适当的聚类算法和合适的距离度量方法。
聚类分析过程:在本案例中,采用了一种常见的聚类方法--K均值聚类算法,该算法通过计算数据点之间的欧氏距离来度量它们之间的相似度。
首先,选择合适的K值(聚类簇的个数)。
然后,在初始阶段,随机选择K个点作为聚类中心。
再通过计算每个数据点与聚类中心的距离,并将其归类到最近的聚类簇。
接下来,根据已经分配到每个聚类中的数据点,重新计算新的聚类中心。
这个过程将迭代,直到达到停止准则,如聚类中心不再变化或达到最大迭代次数。
聚类结果分析:在完成聚类过程后,可以根据每个聚类中心的特征和属性,对数据集进行可视化和解释。
这将帮助企业理解各个群组的特征和差异,并从中提取有价值的洞察力。
进而,企业可以根据不同群组的特征制定个性化的营销策略,提高销售和客户满意度。
总结:通过使用聚类分析方法,该电商企业成功地将其客户细分为几个不同的群组。

层次聚类分析案例层次聚类分析是一种常用的数据挖掘技术,它通过对数据集进行分层聚类,将相似的数据点归为一类,从而实现对数据的有效分类和分析。
本文将以一个实际案例为例,介绍层次聚类分析的应用过程和方法。
案例背景。
某电商平台希望对其用户进行分类,以便更好地进行个性化推荐和营销活动。
为了实现这一目标,我们将运用层次聚类分析方法对用户进行分类,并找出具有相似特征的用户群体。
数据准备。
首先,我们需要收集用户的相关数据,包括用户的购买记录、浏览记录、点击记录、收藏记录等。
这些数据将构成我们的样本集合,用于进行层次聚类分析。
数据预处理。
在进行层次聚类分析之前,我们需要对数据进行预处理,包括数据清洗、数据标准化等工作。
通过数据预处理,我们可以排除异常值和噪声,使得数据更加适合进行聚类分析。
层次聚类分析。
在数据预处理完成之后,我们将使用层次聚类分析算法对用户进行分类。
该算法通过计算不同用户之间的相似度,将相似度较高的用户归为一类。
通过层次聚类分析,我们可以得到用户的不同分类结果,从而实现对用户群体的有效划分。
结果分析。
最后,我们将对层次聚类分析的结果进行分析和解释。
通过对不同用户群体的特征和行为进行分析,我们可以更好地理解用户群体的特点和需求,为电商平台的个性化推荐和营销活动提供有力的支持。
总结。
通过本案例的介绍,我们可以看到层次聚类分析在用户分类和群体分析中的重要作用。
通过对数据的分层聚类,我们可以更好地理解用户群体的特征和行为,为个性化推荐和营销活动提供有力的支持。
希望本文能够对层次聚类分析的应用有所启发,为相关领域的研究和实践提供参考和借鉴。
结语。
层次聚类分析是一种强大的数据挖掘工具,它在用户分类、群体分析等领域具有广泛的应用前景。
通过本文的介绍,相信读者对层次聚类分析有了更深入的理解,希望大家能够在实际应用中灵活运用层次聚类分析方法,为相关问题的解决提供更好的支持。


聚类分析案例聚类分析是一种常见的数据分析方法,它能够将数据集中的观测值划分为若干个类别,使得同一类别内的观测值相似度较高,不同类别之间的观测值相似度较低。
聚类分析在市场细分、社交网络分析、医学图像分析等领域都有着广泛的应用。
本文将以一个实际的案例来介绍聚类分析的应用过程。
案例背景:某电商平台希望对其用户进行细分,以便更好地了解用户需求,精准推荐商品。
为此,他们收集了用户的浏览、购买、评价等行为数据,希望通过聚类分析将用户分成不同的群体。
数据准备:首先,我们需要对数据进行清洗和整理。
去除缺失值、异常值,对数据进行标准化处理,以便消除不同维度之间的量纲影响。
然后,我们可以利用主成分分析(PCA)等方法对数据进行降维,以便更好地展现数据的内在结构。
模型选择:在数据准备完成后,我们需要选择合适的聚类算法。
常见的聚类算法包括K均值聚类、层次聚类、密度聚类等。
在本案例中,我们选择了K均值聚类算法,因为该算法简单易实现,并且适用于大规模数据。
聚类分析:经过数据准备和模型选择后,我们开始进行聚类分析。
首先,我们需要确定聚类的数量K。
这里我们可以采用肘部法则、轮廓系数等方法来确定最佳的K值。
然后,我们利用K均值聚类算法对数据进行分组,得到每个用户所属的类别。
结果解释:得到聚类结果后,我们需要对每个类别进行解释和分析。
通过对每个类别的特征进行比较,我们可以揭示出不同类别用户的行为特点和偏好。
比如,某一类用户可能更倾向于购买高价值商品,而另一类用户更注重商品的品质和口碑。
应用建议:最后,我们可以根据聚类结果给出相应的应用建议。
比如,对于高价值用户群体,电商平台可以加大对其的推荐力度,提供更多的个性化服务;对于偏好品质和口碑的用户群体,可以加强品牌营销和口碑传播,以吸引更多类似用户。
总结:通过本案例的介绍,我们可以看到聚类分析在用户细分和个性化推荐方面的重要作用。
通过对用户行为数据的聚类分析,电商平台可以更好地了解用户需求,提供更精准的推荐服务,从而提升用户满意度和交易量。

聚类分析应用案例
简介
聚类分析是一种无监督研究方法,旨在将数据样本划分为具有相似特征的群组或类别。
在许多领域中,聚类分析被广泛应用于数据分析、模式识别和信息检索等任务。
本文将介绍聚类分析在实际应用中的一些案例。
零售行业中的市场细分
零售行业需要了解其客户群体的特征以制定有效的营销策略。
通过聚类分析,可以将顾客细分为不同的群组,例如消费惯相似的群体、购买力相近的群体等。
基于这些细分结果,零售商可以有针对性地开展宣传活动、提供个性化服务,从而提高市场竞争力。
医疗领域中的疾病分类
在医疗领域,聚类分析可以用于疾病分类和诊断。
通过对患者的症状、体征和病史等信息进行聚类,可以将患者群体划分为具有相似疾病特征的子群。
这有助于医生进行更精确的诊断和制定个性化的治疗方案。
社交媒体分析中的用户群体划分
在社交媒体分析中,聚类分析可用于划分用户群体,了解不同用户的兴趣、行为模式和需求。
以这些群体为基础,企业可以更好地理解目标用户,并设计出更精准的推广活动和产品策略。
金融领域中的风险管理
在金融领域,聚类分析可以用于风险管理。
通过对客户的财务信息、投资偏好和风险承受能力等进行聚类,可以将客户划分为不同的风险群体。
这可以帮助金融机构识别高风险客户,并采取相应的风险控制措施。
总结
聚类分析是一种强大而灵活的数据分析工具,在各个领域都有广泛的应用。
本文介绍了其在零售行业、医疗领域、社交媒体分析和金融领域中的应用案例。
聚类分析可以帮助我们理解数据的内在结构、找到相似的群体,并基于这些群体进行个性化的决策和策略制定。

聚类分析的应用案例聚类分析是一种常用的数据分析方法,它可以将数据集中的对象分成不同的类别或簇,使得同一类内的对象相似度较高,而不同类别之间的对象相似度较低。
聚类分析广泛应用于市场分析、社交网络分析、生物信息学、医学诊断等领域。
本文将介绍几个聚类分析的应用案例,以便更好地理解聚类分析在实际问题中的应用。
首先,聚类分析在市场分析中的应用。
在市场营销中,企业需要了解消费者的偏好和行为,以便更好地制定营销策略。
通过对消费者数据进行聚类分析,可以将消费者分成不同的群体,从而更好地理解他们的需求和行为模式。
例如,一家零售商可以通过聚类分析将消费者分成价格敏感型、品牌忠诚型、功能导向型等不同的群体,从而有针对性地进行促销活动和产品定位。
其次,聚类分析在社交网络分析中的应用。
随着社交网络的兴起,人们在社交网络上的行为数据变得越来越丰富。
通过对社交网络数据进行聚类分析,可以发现不同的社交群体和用户行为模式。
例如,一家社交网络平台可以通过聚类分析将用户分成信息分享型、社交互动型、内容创作型等不同的群体,从而更好地满足用户需求,提高用户留存和活跃度。
再次,聚类分析在生物信息学中的应用。
生物信息学是研究生物学数据的计算机科学领域,其中大量的生物数据需要进行分析和挖掘。
通过对生物数据进行聚类分析,可以发现不同的基因型、蛋白质结构等生物特征。
例如,通过对癌症患者的基因数据进行聚类分析,可以发现不同的癌症亚型和治疗方案,为临床诊断和治疗提供重要参考。
最后,聚类分析在医学诊断中的应用。
在医学诊断中,医生需要根据患者的症状和检查数据进行疾病诊断。
通过对患者数据进行聚类分析,可以发现不同的疾病类型和临床表现。
例如,通过对心脏病患者的临床数据进行聚类分析,可以发现不同的心脏病亚型和治疗方案,为临床诊断和治疗提供重要参考。
综上所述,聚类分析在市场分析、社交网络分析、生物信息学、医学诊断等领域都有重要的应用价值。
通过对不同领域的应用案例进行分析,可以更好地理解聚类分析的原理和方法,为实际问题的解决提供重要参考。
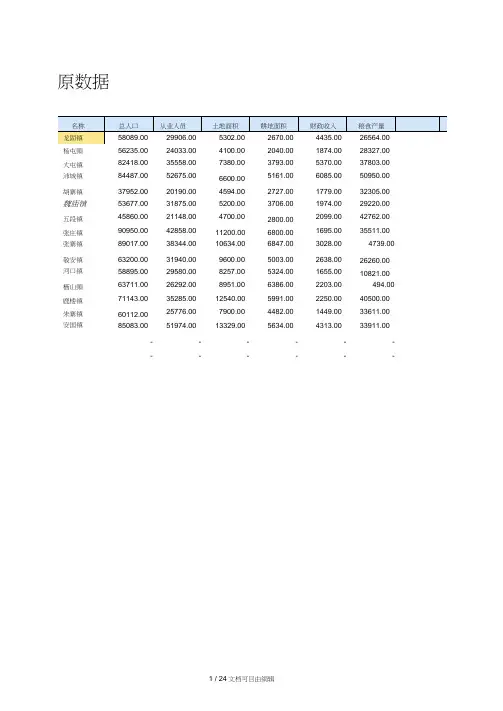
原数据名称总人口从业人员土地面积耕地面积财政收入粮食产量龙固镇58089.0029906.005302.002670.004435.0026564.00杨屯頸56235.0024033.004100.002040.001874.0028327.00大屯镇82418.0035558.007380.003793.005370.0037803.00沛城镇84487.0052675.006600.005161.006085.0050950.00胡寨镇37952.0020190.004594.002727.001779.0032305.00魏庙镇53677.0031875.005200.003706.001974.0029220.00五段镇45860.0021148.004700.002800.002099.0042762.00张庄镇90950.0042858.0011200.006800.001695.0035511.00张寨镇89017.0038344.0010634.006847.003028.004739.00敬安镇63200.0031940.009600.005003.002638.0026260.00河口镇58895.0029580.008257.005324.001655.0010821.00栖山頸63711.0026292.008951.006386.002203.00494.00鹿楼镇71143.0035285.0012540.005991.002250.0040500.00朱寨镇60112.0025776.007900.004482.001449.0033611.00安国镇85083.0051974.0013329.005634.004313.0033911.00------------1・1样本聚类(Q聚类)JJU .00 Ib^.UU Jbbll.UU 30方0D 4739.00.00.00至统嶷类分析:统才蛍.00.00.00.00 ◎无迥)' •单一方买⑤鬆类»(Bj:最小惑数勉:[缝绫II取希II帮助I聚类表通过系数做出其散点图群集成员案例群集数使用平均联接(组间)的树状图重新调整距离聚类合并1.2变量聚类(R 聚类)近似矩阵案例矩阵文件输入总人口从业人 员土地面积耕地面 积 财政收 入粮食产 量总人口 1.000 .857 .698 .714 .512 .043 从业人.8571.000.597.570.643.277员土地面.698.5971.000.856.044-.147积耕地面.714.570.8561.000 -.001-.335积21M8.C0 U70J.C0 2EO3.C0 GEODCO羽丸d 31940 2^60CO 26292 CO劇a 标皿35265 CO®EXal|N):5776 CO 引97」CO卡方血 0计砲• |転瓦ndzn 距阉O 二分卷回:咖SUB忝统蟹凭分析:力链厂沱屯<3丄)I 卿符弓也丄刼碇到01全距归4255B.C011ZOD.CO 咖 3427G2.C01SK.C0 2S511.CO[齢]躺般|/总人口 少丛业人员 少土地面枳 炉辭地而枳细 Q...方法妙财政收.512 .643 .044 001 1.000 .342 入粮食产.043 .277 -147 335 .342 1.000 量聚类表群集成员案例粮您产蜀财政收入耕地面枳土地面枳从业人员总人口使用平均联接(纽间)的树状图2. K—均值聚类原数据描述统计量:均值聚类分析:…冈星H 初始聚类中心(!)ffl gNOVA 表(A)■■“ ••“ ••“ •■“ •••• •■“ ・•••••••••••••••••••••••••• •••• •••• IN极小值 极大值均值 标准差身髙月平均增长19.3411.03 1.88422. 5634率2体重月平均增长19.4950. 30 5. 6363 11. 718率14胸围月平均增长19.1611.81 1.49582. 7933率9坐髙月平均增长19.1411.27 1. 71112. 8070率9有效的N (列表19状态)66153049J714212-.12513K3-.046697卅K 均佰垦艮分・・・区)|E 标准©O[竝]确用|缺失值@按列表排除个案也)O按对排除个案Q输出结果:初始聚类中心迭代历史记录4a.由于聚类中心内没有改动或改动较小而达到收敛。

聚类分析法经典案例
聚类分析是一种常用的数据分析方法,它能够将相似的观察对象分为一组,并将不相似的对象分为不同的组。
下面将介绍一个经典的聚类分析案例。
在电信行业,客户流失是一个非常重要的问题。
为了降低客户流失率,一家电信公司希望通过聚类分析来识别客户流失的特征,以便进行有针对性的营销策略。
首先,该公司收集了一些客户数据,如客户的年龄、性别、月平均消费金额、通话时长等。
然后,利用聚类分析方法,将客户分为不同的组。
在这个案例中,我们可以采用k-means聚类算法。
通过聚类分析,该公司发现了三个客户群体。
第一组客户是高消费高通话客户,他们的平均消费金额和通话时长都很高。
第二组客户是低消费低通话客户,他们的平均消费金额和通话时长都很低。
第三组客户是高消费低通话客户,他们的平均消费金额很高,但通话时长很低。
利用聚类分析的结果,该公司能够采取有针对性的营销策略。
对于高消费高通话客户,他们可能是该公司的忠诚客户,可以通过提供一些优惠或奖励来保持他们的忠诚度。
对于低消费低通话客户,可以通过提供更具吸引力的套餐或增加服务内容来激发他们的消费需求。
对于高消费低通话客户,可以通过了解他们的通话行为,推出更适合他们的通话套餐,以增加他们的通话时长。
通过这个案例,我们可以看到聚类分析在客户流失预测和营销策略中的重要作用。
它可以帮助企业快速识别不同类型的客户,有针对性地制定相应的营销策略,提高客户满意度和忠诚度,降低客户流失率。
聚类分析还可以应用于其他领域,如金融、医疗等,具有广泛的应用前景。

聚类算法在大数据分析中的应用案例随着互联网的不断发展和普及,数据量也在不断增加。
随着数据量的增加,传统的数据处理和分析方法已经不能满足我们的需求。
于是,聚类算法作为一种有效的大数据分析方法,应运而生。
本文将着重探讨聚类算法在大数据分析中的应用案例。
一、什么是聚类算法聚类算法是一种分类算法,用来将数据点分为几个类别,每个类别包含一组具有相似特征的数据点。
聚类算法的目标是让每个类别尽可能地相似,而且不同类别之间尽可能不同。
聚类算法的应用十分广泛,如医学诊断、商业推荐、模式识别等。
二、聚类算法的应用案例1. 电商推荐随着电商业务的不断发展,如何为用户提供精准、个性化的推荐成为了各大电商平台的重要任务。
聚类算法正是为此提供了一个很好的解决方案。
以淘宝为例,淘宝的推荐策略主要是基于聚类算法实现。
淘宝首先根据用户行为数据,如浏览、购买、评价、收藏等进行数据预处理,然后利用聚类算法对用户进行分组,将相似的用户聚类在一起,最后根据不同用户群体的喜好和行为给用户推荐相应的商品。
2. 医学诊断在医学领域,聚类算法可以用于研究疾病的发病机理、预测病情发展趋势、分析医疗资源分布等。
例如,在乳腺癌的临床医学中,利用聚类算法可以将患者分为不同的亚型,根据患者的基因表达数据、临床表现数据以及治疗方案数据等特征,建立一个乳腺癌分类模型,从而指导医生制定针对性更强的治疗方案,提高患者的治愈率和生存率。
3. 金融领域在金融领域,聚类算法可以用于确定用户行为的类型、预测用户的金融需求、识别欺诈交易等。
举个例子,聚类算法可以用于分析用户的消费行为,将用户分为不同的消费群体,分析用户消费行为的变化趋势以及每个群体的特点,从而制定更为精准的市场营销策略。
4. 传感器数据分析在一些工业生产和工程领域,会使用传感器等设备进行数据采集和分析。
这些设备产生的数据量庞大,且具有高维的特性,如何高效地分析这些数据是一个重要的问题。
聚类算法可以用于分析传感器数据,确定数据的分布情况和异常点,从而为生产和工程管理提供实时监控和决策支持。
聚类分析及判别分析案例⼀、案例背景随着现代⼈⼒资源管理理论的迅速发展,绩效考评技术⽔平也在不断提⾼。
绩效的多因性、多维性,要求对绩效实施多标准⼤样本科学有效的评价。
对企业来说,对上千⼈进⾏多达50~60个标准的考核是很常见的现象。
但是,⽬前多标准⼤样本⼤型企业绩效考评问题仍然困扰着许多⼈⼒资源管理从业⼈员。
为此,有必要将当今国际上最流⾏的视窗统计软件SPSS应⽤于绩效考评之中。
在分析企业员⼯绩效⽔平时,由于员⼯绩效⽔平的指标很多,各指标之间还有⼀定的关联性,缺乏有效的⽅法进⾏⽐较。
⽬前较理想的⽅法是⾮参数统计⽅法。
本⽂将列举某企业的具体情况确定适当的考核标准,采⽤主成分分析以及聚类分析⽅法,⽐较出各员⼯绩效⽔平,从⽽为企业绩效管理提供⼀定的科学依据。
最后采⽤判别分析建⽴判别函数,同时与原分类进⾏⽐较。
聚类分析⼆、绩效考评的模型建⽴1、为了分析某企业绩效⽔平,按照综合性、可⽐性、实⽤性和易操作性的选取指标原则,本⽂选择了影响某企业绩效⽔平的成果、⾏为、态度等6个经济指标(见表1)。
2、对某企业,搜集整理了28名员⼯2009年第1季度的数据资料。
构建1个28×6维的矩阵(见表2)。
3、应⽤SPSS数据统计分析系统⾸先对变量进⾏及主成分分析,找到样本的主成分及各变量在成分中的得分。
去结果中的表3、表4、表5备⽤。
表 5成份得分系数矩阵a成份1 2Zscore(X1) .227 -.295Zscore(X2) .228 -.221Zscore(X3) .224 -.297Zscore(X4) .177 -.173Zscore(X5) .186 .572Zscore(X6) .185 .587提取⽅法 :主成份。
构成得分。
a. 系数已被标准化。
4、从表3中可得到前两个成分的特征值⼤于1,分别为3.944和1.08,所以选取两个主成分。
根据累计贡献率超过80%的⼀般选取原则,主成分1和主成分2的累计贡献率已达到了83.74%的⽔平,表明原来6个变量反映的信息可由两个主成分反映83.74%。
文章透彻解读聚类分析及案例实操目录一、聚类分析概述 (3)1. 聚类分析定义 (4)1.1 聚类分析是一种无监督学习方法 (4)1.2 目的是将相似的对象组合在一起 (5)2. 聚类分析分类 (6)2.1 根据数据类型分为数值聚类和类别聚类 (7)2.2 根据目标函数分为划分聚类和层次聚类 (9)二、聚类分析理论基础 (10)1. 距离度量方法 (11)1.1 欧氏距离 (13)1.2 曼哈顿距离 (14)1.3 余弦相似度 (15)1.4 皮尔逊相关系数 (16)2. 聚类有效性指标 (17)三、聚类分析算法 (18)1. K-均值聚类 (19)1.1 算法原理 (21)1.2 算法步骤 (22)1.3 收敛条件和异常值处理 (24)2. 层次聚类 (25)2.1 算法原理 (26)2.2 算法步骤 (27)2.3 凝聚度量和链接度量 (28)四、案例实操 (30)1. 客户分群 (31)1.1 数据准备 (33)1.2 聚类结果分析 (34)1.3 结果应用 (35)2. 商品推荐 (36)2.1 数据准备 (37)2.2 聚类结果分析 (38)2.3 结果应用 (39)3. 新闻分类 (40)3.1 数据准备 (41)3.2 聚类结果分析 (42)3.3 结果应用 (44)五、聚类分析应用场景 (45)1. 市场细分 (46)2. 社交网络分析 (47)3. 生物信息学 (48)4. 图像识别 (49)六、讨论与展望 (51)1. 聚类分析的局限性 (52)2. 未来发展方向 (53)一、聚类分析概述聚类分析是一种无监督学习方法,旨在将相似的对象组合在一起,形成不同的组或簇。
它根据数据的内在结构或特征,而非预先定义的类别对数据进行分组。
这种方法在数据挖掘、机器学习、市场细分、社交网络分析等领域具有广泛的应用。
特征选择:从数据集中选择合适的特征,以便更好地表示数据的分布和模式。
距离度量:确定一个合适的距离度量方法,用于衡量数据点之间的相似程度。
聚类分析法经典案例聚类分析法是一种常用的数据分析方法,它通过对数据进行分类和分组,帮助我们发现数据中的内在规律和特征。
在实际应用中,聚类分析法被广泛运用于市场营销、社交网络分析、医学诊断、图像处理等领域。
下面,我们将介绍一些聚类分析法的经典案例,帮助大家更好地理解和应用这一方法。
首先,我们来看一个市场营销领域的案例。
某公司想要对其客户进行分类,以便更好地制定营销策略。
他们收集了客户的消费行为、年龄、性别、地理位置等数据,并利用聚类分析法对客户进行了分组。
通过分析,他们发现客户可以被分为三大类,高消费高端用户、中等消费稳定用户和低消费新用户。
有了这些分类信息,公司可以针对不同类型的客户制定不同的营销策略,提高市场营销效率。
其次,我们来看一个社交网络分析的案例。
一家社交媒体公司希望了解用户在平台上的行为和兴趣,以便更好地推荐内容和广告。
他们利用用户的浏览记录、点赞行为、评论信息等数据,通过聚类分析法将用户分为几个群体。
通过分析,他们发现用户可以被分为电影爱好者、音乐迷、美食达人等不同类型的群体。
有了这些分类信息,社交媒体公司可以更精准地为用户推荐内容和广告,提高用户满意度和广告点击率。
再次,我们来看一个医学诊断的案例。
医院收集了患者的临床症状、实验室检查结果、病史等数据,希望通过聚类分析法对患者进行分类,以便更好地制定治疗方案。
通过分析,他们发现患者可以被分为几个病情严重程度不同的群体。
有了这些分类信息,医生可以更好地制定个性化的治疗方案,提高治疗效果和患者生存率。
最后,我们来看一个图像处理的案例。
一家无人驾驶车辆公司希望通过图像识别技术对道路上的车辆和行人进行分类,以便更好地进行交通管理和安全预警。
他们利用摄像头采集的图像数据,通过聚类分析法将道路上的车辆和行人进行分类。
通过分析,他们可以更准确地识别不同类型的车辆和行人,并做出相应的交通管理和安全预警措施。
通过以上经典案例的介绍,我们可以看到聚类分析法在不同领域的广泛应用。
K-Means聚类分析一、实验方法K-Means聚类分析二、实验目的根据2001年全国31省市自治区各类小康和现代化指数的数据,用Spass对地区进行K-Means 聚类分析。
三、实验数据综合指数社会结构经济与技术发展人口素质生活质量法制与治安北京93.2 100 94.7 108.4 97.4 55.5上海92.3 95.1 92.7 112 95.4 57.5天津87.9 93.4 88.7 98 90 62.7浙江80.9 89.4 85.1 78.5 86.6 58广东79.2 90.4 86.9 65.9 86.5 59.4江苏77.8 82.1 74.8 81.2 75.9 74.6辽宁76.3 85.8 65.7 93.1 68.1 69.6福建72.4 83.4 71.7 67.7 76 60.4山东71.7 70.8 67 75.7 70.2 77.2黑龙江70.1 78.1 55.7 82.1 67.6 71吉林67.9 81.1 51.8 85.8 56.8 68.1湖北65.9 73.5 48.7 79.9 56 79陕西65.9 71.5 48.2 81.9 51.7 85.8河北65 60.1 52.4 75.6 66.4 76.6山西64.1 73.2 41 73 57.3 87.8海南64.1 71.6 46.2 61.8 54.5 100重庆64 69.7 41.9 76.2 63.2 77.9内蒙古63.2 73.5 42.2 78.2 50.2 81.4湖南60.9 60.5 40.3 73.9 56.4 84.4青海59.9 73.8 43.7 63.9 47 80.1四川59.3 60.7 43.5 71.9 50.6 78.5宁夏58.2 73.5 45.9 67.1 46.7 61.6新疆64.7 71.2 57.2 75.1 57.3 64.6安徽56.7 61.3 41.2 63.5 52.5 72.6云南56.7 59.4 49.8 59.8 48.1 72.3甘肃56.6 66 36.6 66.2 45.8 79.4 四、分析方法与结果表一31个省市自治区小康和现代化指数的K-Means聚类分析结果(一)初始聚类中心聚类1 2 3综合指数79.20 92.30 51.10社会结构90.40 95.10 61.90经济与技术发展86.90 92.70 31.50人口素质65.90 112.00 56.00生活质量86.50 95.40 41.00法制与治安59.40 57.50 75.60ANOVA聚类误差均方自由度均方自由度F 显著性综合指数1633.823 2 22.518 28 72.556 .000 社会结构1539.872 2 47.312 28 32.547 .000 经济与技术发展4381.296 2 56.760 28 77.190 .000 人口素质1817.856 2 74.363 28 24.446 .000 生活质量3315.174 2 59.276 28 55.928 .000 法制与治安530.188 2 76.284 28 6.950 .004由于已选择聚类以使不同聚类中个案之间的差异最大化,因此 F 检验只应该用于描述目的。
聚类分析的应用案例聚类分析是一种常用的数据挖掘技术,它可以将数据集中的对象按照其相似性进行分类,从而找出数据中的潜在模式和结构。
聚类分析在各个领域都有着广泛的应用,例如市场营销、医学诊断、社交网络分析等。
本文将介绍几个聚类分析在实际应用中的案例,帮助读者更好地理解和应用这一技术。
首先,聚类分析在市场营销中的应用案例。
假设一个公司希望对其客户进行细分,以便更好地定制营销策略。
通过聚类分析,可以将客户按照其购买行为、偏好等特征进行分类,从而识别出不同的客户群体。
比如,通过聚类分析可以将客户分为价值型客户、潜在客户、忠诚客户等不同的群体,然后针对不同的群体制定相应的营销策略,提高营销效果。
其次,聚类分析在医学诊断中的应用案例也非常广泛。
医学领域的数据往往包含大量的特征和变量,通过聚类分析可以将患者按照其症状、生理指标等特征进行分类,从而辅助医生进行诊断和治疗。
例如,通过聚类分析可以将患者分为不同的疾病类型或病情严重程度,帮助医生更好地制定个性化的治疗方案,提高治疗效果。
另外,聚类分析在社交网络分析中也有着重要的应用价值。
随着社交网络的快速发展,人们在社交网络上产生了大量的数据,通过聚类分析可以将用户按照其兴趣、行为等特征进行分类,从而挖掘出不同的用户群体和社交圈子。
这对于社交网络平台来说,可以帮助他们更好地推荐好友、内容等,提高用户的粘性和使用体验。
综上所述,聚类分析在市场营销、医学诊断、社交网络分析等领域都有着重要的应用价值。
通过聚类分析,可以帮助人们更好地理解和利用数据,发现数据中的潜在模式和结构,为决策提供科学依据。
随着数据挖掘技术的不断发展,相信聚类分析在更多的领域将会有着更广泛的应用。
聚类分析案例聚类分析是一种数据分析方法,用于将数据集中的对象分成不同的群组,使得群组内的对象相似度较高,而不同群组之间的相似度较低。
以下是一个聚类分析的案例。
假设一个公司试图了解他们的客户群体,以便更好地进行市场细分和定位。
该公司采集了一系列与客户相关的特征,比如年龄、性别、购买行为等。
他们打算使用聚类分析来将这些客户划分为不同的群组,以便更好地了解每个群组的特征和需求。
首先,该公司需要对数据进行预处理。
他们将删除一些不相关或重复的特征,并对缺失数据进行填充。
然后,他们需要选择一个合适的聚类算法来检测潜在的群组结构。
在这个案例中,他们选择了k-means算法,因为它是一个简单而高效的方法,适用于大规模数据集。
接下来,他们需要选择聚类的数量。
为了确定最佳的聚类数量,他们使用了“肘部法则”。
该方法计算了不同聚类数量下的聚类误差平方和(SSE),并绘制了一个聚类数量和SSE的折线图。
根据折线图,他们选择了一个聚类数量,使得SSE的降幅明显减缓的那个点。
在这个案例中,他们选择了5个聚类。
最后,他们使用选定的聚类数量运行k-means算法,并获取每个客户所属的聚类。
然后,他们对每个聚类进行分析,比如计算平均年龄、男女比例、购买偏好等。
通过对聚类结果的比较,他们可以发现不同群组之间的差异和相似之处,从而得出关于每个群组的特征和需求的结论。
通过这个聚类分析,该公司发现客户群体可以分为以下几个群组:青年女性购买群体、中年男性购买群体、中老年女性购买群体、青年男性购买群体和普通购买群体。
他们发现不同群组的平均年龄、男女比例和购买偏好存在显著差异,这为他们的市场细分和推广战略提供了有力的支持。
综上所述,聚类分析是一个有用的数据分析方法,可以帮助企业了解客户群体的特征和需求,从而更好地进行市场细分和定位。
通过对数据的预处理、选择合适的聚类算法和聚类数量,以及对聚类结果的分析,企业可以获得有关客户群体的深入洞察,并为营销决策提供有力的支持。
SPSS软件操作实例——某移动公司客户细分模型
数据准备:数据来源于telco.sav,如图1所示,Customer_ID表示客户编号,Peak_mins表示工作日上班时期电话时长,OffPeak_mins表示工作日下班时期电话时长等。
图1 telco.sav数据
分析目的:对移动手机用户进行细分,了解不同用户群体的消费习惯,以更好的对其进行定制性的业务推销,所以需要运用聚类分析。
操作步骤:
1,从菜单中选择【文件】——【打开】——【数据】,在打开数据窗口中选择数据位置以及文件类型,将数据telco.sav导入SPSS软件中,如图2所示。
图2 打开数据菜单选项
2,从菜单中选择【分析】——【描述统计】——【描述】,然后在描述性窗口中,将需要标准化的变量选到右边的“变量列表”,勾选“将标准化得分另存为变量”,点确定,如图3所示。
图3 数据标准化
3,从菜单中选择【分析】——【分类】——【K-均值聚类】,在K-均值聚类分析窗口中将标准化之后的结果选入右边“变量列表”,客户编号选入“个案标记依据”,聚类数改为5。
点击迭代按钮,在迭代窗口将最大迭代次数改为100,点击继续。
点击保存按钮,在保存窗口勾选“聚类成员”、“与聚类中心的距离”,点击继续。
点击选项按钮,在选项窗口勾选“ANOV A表”、“每个个案的聚类信息”,点击继续。
点击确定按钮,运行聚类分析,如图4所示。
图4 聚类分析操作
由最终聚类中心表可得最终分成的5个类它们各自的均值。
第一类:依据总通话时间长,上班通话时间长,国际通话时间长等特征,将第一类命名为高端商用客户。
第二类:依据其在各项指标中均较低,将第二类命名为不常使用客户。
第三类:依据总通话和上班通话时间居中等特征,将第三类命名为中端商用客户。
第四类:依据下班通话时间最长等特征,将第四类命名为日常客户。
第五类:依据平均每次通话时间最长等特征,将第五类命名为长聊客户。
由ANOVA表可根据F值大小近似得到哪些变量对聚类有贡献,本例题中重要程度排序为:总通话时长>工作日上班时期电话时长>工作日下班时期电话时
长>平均每次通话时长>国际电话时长>周末电话时长。
同时Sig.值都为0,说明各变量对聚类均有显著地贡献(经常用Sig.值是否小于0.05来检验聚类结果是否好)。
结论
经过数据标准化以及K-均值聚类分析,最终我们基本实现了本次分析的目的,较为成功的对某移动电话客户进行了细分,初步了解了各类型用户的手机话费消费习惯,对日后经营有一定的指导意义。
该移动运营商,可参考不同类型用户群体的手机话费习惯提出有针对性的话费服务,使经营目标达到最优。