第8章 自然语言理解
- 格式:pdf
- 大小:591.24 KB
- 文档页数:23




一分词概述语言学中一般将“词”定义为“能够独立运用的,有意义的最小语法单元”。
自然语言中句子是由词组成的,而计算机要理解和处理自然语言就是从词这一步开始的。
汉语不同于西文,在一个汉语句子中,词与词之间没有明显的分隔符(如空格)。
此外,汉语的词法约束很不规范,而且千变万化,就给汉语分词带来了很大的麻烦。
正是由于汉语分词的困难及其在中文信息自动处理中的重要地位,自70 年代末以来,许多人投入到了汉语自动分词的研究工作中来,也出现了好多具有应用前景的分词方法。
1.1 汉语分词的歧义汉语分词是汉语分析以及计算机处理汉语的一大难点,导致汉语分词精度不高的原因一般有:词语(抑或说汉语分析基本单位)的界定、词典范围、分词中因为算法问题产生的歧义。
分词过程中歧义产生的根源可归结为以下三类:(1)由自然语言的二义性所引起的歧义,称为第一类歧义。
如:“乒乓球拍卖完了”可切分为“乒乓球/拍卖/完了”又可以切分为“乒乓球拍/卖/完了”。
这两种切分形式无论在语法上还是语义上都是正确的,就是人工分词也会产生歧义,只有结合上下文才能给出正确的切分。
(2)由机器自动分词产生的特有歧义,称为第二类歧义。
如:“在这种环境下工作是太可怕了”用机器切分可以切分为“在/这种/环境/下工/作/是/太/可怕/了”也可以切分为,“在/这种/环境/下/工作/是/太/可怕/了”。
对本句来说,只有第二种切分是正确的,用人工分词是不可能产生歧义的,歧义是由于机器机械切分产生的。
(3)由于分词词典的大小而引起的歧义,称为第三种歧义。
如:“王小二是一个农民”用机器切分被分为“王/小/二/是/一个/农民”,这里“王小二”是一个人名,在汉语中应是一个词,所以这个切分是错误的。
由于机器自动切分是依据分词词典进行的,故词典中没有的词,就不可能被正确切分,分词词典不可能也没有必要包括所有的词(如人名、地名),同时,词典中所包括的词越多,就会产生新的歧义。
例如“发展社会主义的新乡村”,新乡是一个地名,若词典中有该词,则“新乡村”是一个歧义字段。



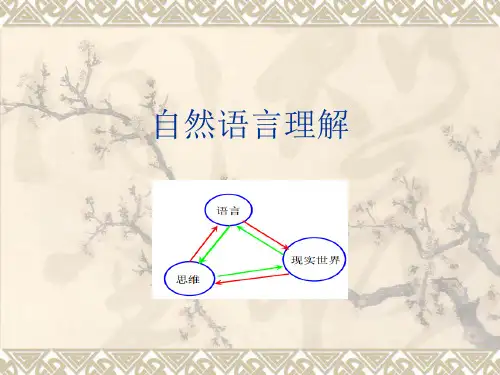
什么是自然语言理解
自然语言理解(NLU)是人工智能的重要研究领域之一,其
目标是模仿人类理解语言的能力。
它旨在使计算机能够通过识别、理解和解释自然语言来获取有用信息或完成特定任务。
自然语言理解可以为人力资源和监督学习提供数据和洞察,使其能够有效地回答问题,发现潜在的意义和关系,并能够预测各种可能的结果。
它可以帮助机器发现新的概念,例如将抽象概念翻译成具体表达。
NLU可以分为三个基本步骤:词汇分析,语法分析和形式语
义分析。
在词汇分析级别,NLU系统会标记文本中的每一个词,以此确定句子的意义。
在语法分析级别,它会通过检测句子中包含的语法结构(例如主语、宾语和定语),来确定句子的类型和意义。
在形式语义分析级别,NLU系统会尝试分析
句子的深层含义,例如分析话语者的目的或整体上下文。
NLU最近被广泛应用于语音识别、机器翻译、聊天机器人等
领域。
它可以帮助机器理解口头语言,有效地回答问题,并与人进行实时交流,从而提高人机交互的效率。
它还可以帮助发现隐藏在文本中的意义。
总之,自然语言理解为机器提供了更好的理解人类话语的能力,它可以更有效地处理语音识别、机器翻译、聊天机器人等任务,并提高人机交互的效率。


自然语言理解(NLU)是指计算机系统对人类语言进行理解和解释的过程。
它涉及到从语言中提取出意义、逻辑和情感等信息,使得计算机能够像人类一样理解并与之进行交互。
在深入探讨自然语言理解的层次之前,让我们先简要地了解一下自然语言理解的定义。
自然语言理解是指计算机能够解析和理解人类自然语言的能力,包括对语义、语法、逻辑和语用的理解。
它旨在使计算机能够准确地理解并处理人类语言的各种含义和目的,从而能够进行智能的对话和决策。
自然语言理解的层次可以分为几个层次,从简单到复杂逐步深入。
首先是基本的语义理解,计算机需要能够识别出句子中的实体、动作和关系等基本信息。
其次是逻辑推理,计算机需要能够根据语句之间的逻辑关系进行推理和推断。
再次是情感理解,计算机需要能够识别出句子中表达的情感色彩和态度,如正面情感、负面情感或中性情感等。
最后是语境理解,计算机需要能够根据上下文和语境来理解句子的真实含义和目的。
在实际的应用中,自然语言理解的层次可以根据具体的任务和需求进行不同的扩展和深化。
例如在智能客服系统中,自然语言理解需要能够理解用户的问题并给出准确的回答;在智能文本分析系统中,自然语言理解需要能够理解文本中的信息并进行分类和关联分析等。
个人观点来说,自然语言理解是人工智能领域非常核心和关键的一个领域。
随着人工智能技术的不断发展和普及,自然语言理解的能力将极大地改变人机交互的方式,并在各种应用领域发挥着重要作用。
自然语言理解是计算机理解和处理人类语言的重要能力,它涉及到基本的语义理解、逻辑推理、情感理解和语境理解等多个层次,并在实际应用中发挥着重要的作用。
希望通过本文的介绍,你能对自然语言理解有一个更深入和全面的了解。
自然语言理解(NLU)是指计算机系统对人类语言进行理解和解释的过程。
它涉及到从语言中提取出意义、逻辑和情感等信息,使得计算机能够像人类一样理解并与之进行交互。
在深入探讨自然语言理解的层次之前,让我们先简要地了解一下自然语言理解的定义。

自然语言理解教学大纲教材:自然语言理解赵海清华大学出版社第1章:自然语言处理概要1.概念和术语包括什么是自然语言、自然语言处理和自然语言理解的关系、以及计算语言学。
2.自然语言处理技术的挑战自然语言处理被迫需要承担两类知识一一常识知识与语言学知识的处理和解析任务。
后者属于自然语言处理这一领域独一无二的需求。
3.机器翻译4.语言处理层次形态分析、句法分析、语义分析、语用分析、篇章分析、世界知识分析5.应用型自然语言处理人机对话系统6.自然语言处理的学术出版体系国际计算语言学会(AC1)等第2章:n元语言模型1.概率论基础首先回顾概率论的基本知识,如联合概率、条件概率、贝叶斯等。
2.语言模型用于语言生成语言生成的过程称为解码。
n元语言模型给出的是n元组出现的概率,因此合理或正确的语言现象必然有更大的概率或似然,这一观察是语言模型能在预测性解码任务之中发挥作用的关键。
3.n元语言模型的工作方式n元机制、马尔可夫假设4.评价指标困惑度5.n元语言模型的平滑方法1aP1aCe平滑、Good-TUring平滑、Je1inek-MerCer平滑、KatZ平滑、KneSer-Ney平滑、Pitman-YOr平滑6.非n元机制的平滑方法缓存、跳词、聚类7.平滑方法的经验结果对比几种平滑技巧的组合效果,以及对比它们在困惑度和语音识别的单词准确率上的差异。
8.n元语言模型的建模工具介绍了一些常用的平滑工具包第3章:语言编码表示1.独热表示用独热码表示语言符号2.特征函数一个文本对象样本基于词一级的独热表示就是展示n元组本身,因此这个部分也称之为n元组特征,它也是自然语言最直接、最基本的特征。
3.通用特征模板在实际机器学习模型建立过程中,会用到成千上万维的特征向量,故而涉及成千上万个特征函数,如果这些函数要一个个定义,建模过程将会变得烦琐不堪。
因此,实际上,特征函数可以按照定义属性进行分组,这样统一定义的一组特征函数(对应于特征向量维度上的一个片段)称之为特征模板。
自然语言理解综述
自然语言理解(Natural Language Understanding)是人工智能
领域中,研究如何使计算机能够理解和处理自然语言的一项重要任务。
它涉及以人类语言为输入,并将其转换为机器可理解的形式,以便进
行进一步的处理和分析。
自然语言理解的目标是使计算机能够理解和解释人类语言的含义,包括语法、词义、语义和上下文等方面。
这种理解能力使计算机能够
根据用户的指令或问题,准确理解其意图并做出相关响应。
自然语言理解涉及各种技术和方法,包括文本分析、句法分析、
语义分析、语义角色标注、语义关系抽取等。
这些技术通过模型训练
和算法优化,使计算机能够根据上下文和语义规则对文本进行解析和
理解。
自然语言理解在许多应用领域中起着重要的作用,例如智能助理、机器翻译、智能客服、信息检索等。
通过自然语言理解,计算机能够
处理人类语言,并从中获取信息,为用户提供更好的服务和支持。
尽管自然语言理解在过去几十年中取得了显著的进展,但其挑战
仍然存在。
由于自然语言的复杂性和多义性,理解自然语言仍然是一
个非常困难的问题。
因此,研究人员一直在努力改进自然语言理解的
精度和效率,并开展更深入的研究,以应对更复杂的语言环境。
总而言之,自然语言理解是一项富有挑战性又具有广泛应用前景
的研究领域。
随着人工智能的发展,我们可以期待自然语言理解在各
个领域中发挥越来越重要的作用。