数据分布特征的测度
- 格式:ppt
- 大小:3.34 MB
- 文档页数:86
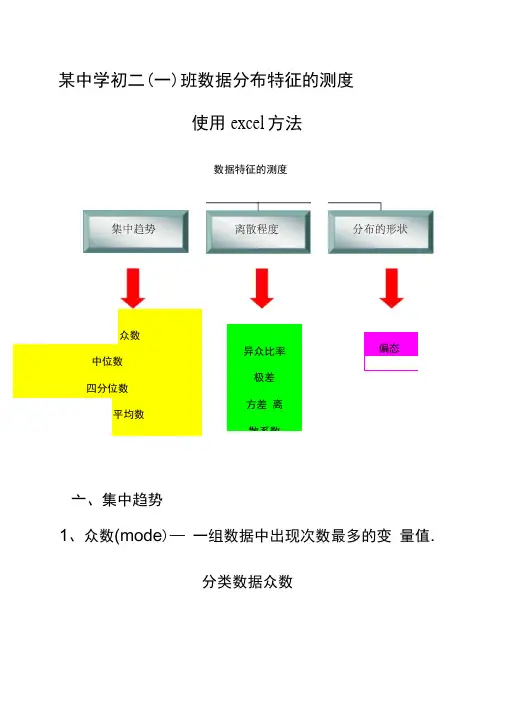
某中学初二(一)班数据分布特征的测度使用excel 方法数据特征的测度众数 中位数 四分位数平均数亠、集中趋势1、众数(mode )— 一组数据中出现次数最多的变 量值.分类数据众数偏态 峰态异众比率 极差 方差 离散系数制作:用frequency 函数求出语文成绩的频数一求 出各个分数段的比例一各个分数段的百分比.原始数据:原始数据一众数・xls2、中位数(median )-排序后处于中间位置上的值解:这里的变量为“成绩 分数段”,这是个分类变 量,不同的分数段就是变 量值。
所调查的初二一班 60人 中,60-69这个分数段的人 数最多,为23人,占全班 人数的38.33%,因此众数 为“ 60-69这一分数段”。
即:M=60-69这一分数段制作:对语文成绩进行降序排列一根据计算公式求得中位数/插入median函数求得中位数要求得这60名学生语文成绩的中位数有2种方法:方法一:1、首先对学生的语文成绩进行降序排列。
2、由于学生人数为偶数,所以位置计算公式二错误!位置=错误!—错误!= 30。
5语文成绩中位数=错误!= 68方法二:插入median函数一求得语文成绩中位数。
原始数据-中位数:原始数据一中位数。
XlS3、四分位数(quartile)—排序后处于25%和75%位置上的值.要求得这60名学生语文成绩的中位数有2种方法: 方法一:1、首先对学生的语文成绩进行升序排列。
2、由于学生人数为偶数,所以位置计算公式为:Q 位置二错误!=错误!= 15.25Q位置二错误!=错误!= 45。
75Q= 61+0.75 X( 62-61 ) =61。
75Q= 78+0。
25 X( 78—78) =78方法二:使用函数QUARTILE求出语文成绩的四分位数xls 原始数据一四分位数:原始数据-四分位数。
4、平均数(mean)加权平均数一初二(一)班语文总评成绩总评成绩=错误!原始数据一平均数:原始数据一平均数。




第四章数据分布特征的测度教学目的与要求:统计平均指标是表明总体数量特征的一个重要指标,它是将总体各单位标志值的差异抽象化,反映总体各单位标志值的一般水平,揭示总体分布的集中趋势。
变异指标是反映总体各单位标志值的差异程度,揭示总体分布离中趋势的又一重要数量特征指标。
通过本章的学习,要求理解统计平均指标的意义和作用;掌握各种统计平均指标的特点、应用条件、应用范围和计算方法;理解变异指标的意义和作用;掌握各种变异指标的性质和计算方法;能运用变异指标衡量平均数代表性的大小。
教学重点与难点:重点为各种平均指标和变异指标的概念、特点、应用条件、应用范围和计算方法。
难点是不同条件下平均指标和变异指标的计算。
统计数据经过整理和显示后,对数据分布的形状和特征就可以有一个大致的了解。
为进一步掌握数据分布的特征和规律,进行更深入的分析,还需要找到反映数据分布特征的各个代表值。
对一组数据分布的特征,可以从三个方面进行测度和描述:一是分布的集中趋势,反映各数据向其中心值靠拢和聚集的程度;二是分布的离散程度,反映各数据远离中心值的趋势;三是分布偏态和峰态,反映数据分布的形状。
这三个方面分别反映了数据分布特征的不同侧面。
第一节集中趋势的测度集中趋势是指一组数据向某一中心值靠拢的倾向,它反映了一组数据中心点的位置所在。
测度集中趋势也就是寻找数据一般水平的代表值或中心值。
低层次数据的集中趋势测度值适用于高层次的测量数据,反过来,高层次数据的集中趋势测度值并不适用于低层次的测量数据。
因此,选用哪一个测度值来反映数据的集中趋势,要根据所掌握的数据的类型和特点来确定。
一、分类数据:众数(M o)众数是指一组数据中出现次数最多的变量值。
•出现次数最多的变量值•不受极端值的影响•一组数据可能没有众数或有几个众数•主要用于分类数据,也可用于顺序数据和数值型数据从分布的角度看,众数是具有明显集中趋势点的数值,一组数据分布的最高峰点所对应的数值即为众数。


第四章数据分布特征的测度一、选择题1.一组数据中出现频数最多的变量值称为()。
A.众数B.中位数C.四分位数D.均值2.下列关于众数的叙述,不正确的是()。
A.一组数据可能存在多个众数B.众数主要适用于分类数据C.一组数据的众数是唯一的D.众数不受极端值的影响3.一组数据排序后处于中间位置上的变量值称为()。
A.众数B.中位数C.四分位数D.均值4.一组数据排序后处于25%和75%位置上的值称为()。
A.众数 B.中位数C.四分位数D.均值5.非众数组的频数占总额数的比率称为()。
A.异众比率B.离散系数C.平均差D.标准差6.如果一个数据的标准分数是-2,表明该数据()。
A.比平均数高出2个标准差B.比平均数低2个标准差C.等于2倍的平均数D.等于2倍的标准差7.比较两组数据的离散程度最适合的统计量是()。
A.极差B.平均差C.标准差D.离散系数8.偏度系数测度了数据分布的非对称性程度。
如果一组数据的分布是对称的,则偏度系数()。
A.等于0 B.等于1 C.大于0 D.大于1 9.某专家小组成员的年龄分别为29,45,35,43,45,58,他们的年龄中位数为()。
A.45 B.40 C.44 D.3910.某居民小区准备建一个娱乐活动场所,为此,随机抽取了80户居民进行调查,其中表示赞成的有59户,表示中立的有12户,表示反对的有9户。
该组数据的中位数是()。
A.赞成B.59 C.中立D.1211.对于右偏分布,均值、中位数和众数之间的关系是()。
A .均值>中位数>众数B .中位数>均值>众数C .众数>中位数>均值D .众数>均值>中位数12.某班学生的大学英语平均成绩是70分,标准差是10分。
如果已知该班学生的考试分数为对称分布,可以判断成绩在60分~80分之间的学生大约占( )。
A .95%B .89%C .68%D .99%13.当一组数据中有一项为零时,不能计算( )。

第二章数据分布特征的测度对数据分布特征主要从三个方面进行测度和描述:一是分布的集中趋势,反映数据向其中心值靠拢或聚集的程度;二是分布的离散程度,反映各数据远离其中心值的趋势;三是分布的形状,反映数据分布的偏斜程度和峰度。
本章主要介绍如何使用函数以及“数据分析”工具对数据分布特征进行测度和描述。
第一节函数的介绍本节主要介绍在统计分析中需要用到的一些函数,其中包括我们本章(描述统计)中以及在概率分布、参数估计与假设检验、方差分析、相关与回归等分析中涉及到的函数,读者在后面章节的学习中可以参阅本节的内容。
一、统计计算中经常用到的函数(函数列表)★Excel为用户提供了数学、三角函数、统计函数、数据库函数、财务函数、工程函数、逻辑函数、文本函数、时间和日期函数、信息函数、查找和引用函数等10类300多种,可以满足多方面的需要。
其中,统计函数最多达78种;此外还有14种数据库函数,以及在统计中经常使用的数学函数20种,合计112种。
下面将这些函数名称及功能列表显示。
★本小节摘自: 安维默主编,《统计电算化》第34~37页,中国统计出版社,2000表2-1 可用于统计分析的函数(续2)1、函数的语法工作表函数包括两个部分:函数名和紧跟的一个或多个参数。
函数名,例如SUM和A VERAGE,表明函数要执行的操作;参数则指定函数所使用的值或单元格。
例如,在公式“=SUM(C3:C5)”中,SUM为函数名,C3:C5为参数。
此函数计算单元格C3、C4和C5中值的总和。
函数的参数可以为数值类型。
例如,公式“=SUM(327,209,176)”中的SUM 函数将数字327、209和176求和。
不过通常的做法是,先在工作表的单元格中输入使用的数字,然后将这些单元格作为函数的参数使用。
请注意函数参数两端的括号:开括号表示参数的开始,必须紧跟在函数名后。
如果在函数名和括号之间输入了空格或其他字符,那么Excel会显示错误信息“Microsoft Excel 在公式中发现了错误。

第四章数据分布特征的测度学习目的和要求:通过本章的学习,掌握数据分布特征的各种描述方法;掌握不同测度方法的特点、应用条件及应用场合;能利用所学的方法对统计数据作各种统计描述。
难点释疑:(一)算术平均数通常用来反映总体分布的集中趋势,调和平均数往往只作为算术平均数的变形来使用,即在已知标志总量而未知总体单位总量的情况下计算调和平均数;而几何平均数较适用于计算平均比率和平均速度。
(二)调和平均数虽然是根据标志值的倒数计算的,但其结果不等于算术平均数的倒数。
在计算和应用平均指标时,除了考虑数理方面的要求外,更重要的是要考虑其现实的经济意义。
(三)平均数的性质是简捷计算法的基础,也是计算标志变异指标的基础。
掌握中位数和众数与算术平均数的关系的目的是能够根据其中的两个平均数大体计算出第三个平均数,并判断总体的分布状态。
(四)全距、四分位差、平均差、标准差在反映标志变异程度方面各有优缺点。
全距是描述数据离散程度的最简单测度值,它计算简单,易于理解,但不能全面反映总体各单位标志值的差异程度。
标准差与平均差的意义基本相同,但在数学性质上比平均差要优越,所以,在反映标志变动度大小时,一般都采用标准差。
标准差是实际中应用最广泛的离散程度测度值。
(五)标准差系数的应用。
为了对比和分析不同平均水平总体的标志差异程度,就需要使用标准差系数。
它是标志变异的相对指标。
它既消除了变量数列变量值差异程度的影响,也消除了变量数列水平高低的影响。
练习题:(一)单项选择题(在下列备选答案中,只有一个是正确的,请将其顺序号填入括号内)1.平均指标反映了()。
①总体变量值分布的集中趋势②总体分布的离散特征③总体单位的集中趋势④总体变动趋势2.加权算术平均数的大小( )。
①受各组标志值的影响最大 ②受各组次数的影响最大③受各组权数系数的影响最大 ④受各组标志值和各组次数的共同影响3.在变量数列中,如果变量值较小的一组权数较大,则计算出来的算术平均数( )。

数据分布趋势的测度值数据分布趋势的测度值是用来描述数据集中数据分布特征的统计指标。
通过这些测度值,我们可以了解数据的分布模式,从而对数据进行进一步的分析和理解。
以下是常见的几种数据分布趋势的测度值。
1. 平均数(Mean):平均数是最常用的数据分布趋势测度值之一。
它表示数据集的平均值,是所有数据值的总和除以数据个数。
平均数的计算简单直观,但对极值的敏感性较高,一些极端值的存在可能会干扰平均数的表达。
2. 中位数(Median):中位数是将一组数据按照大小顺序排列后,处于中间位置的数值。
中位数的计算方式相对简单,不受极端值的影响,适用于数据分布不均匀的情况。
中位数可以提供数据集的位置测度值,可以帮助我们判断数据是否集中在某个范围内。
3. 众数(Mode):众数是数据集中出现频率最高的数值。
众数可以提供数据集的出现频率测度值,可以帮助我们了解数据集的集中性和数据重复的情况。
一个数据集可能有一个众数,也可能有多个众数,甚至没有众数。
4. 方差(Variance):方差是数据离散程度的度量,用于测量数据分布的集中性。
方差越大,表示数据的分散程度越高,反之亦然。
方差的计算需要用到每个数据点与均值之间的差值,因此对极值比较敏感。
5. 标准差(Standard Deviation):标准差是方差的正平方根,用于衡量数据的分散程度。
标准差与方差的性质一致,但它的单位与原始数据的单位一致,更容易理解和比较。
6. 四分位数(Quartiles):四分位数是将一组数据分成四个等分的数值点。
第一个四分位数(Q1)是将数据集分为四个区域后,处于第一区域末尾的数值点;中位数是第二个四分位数(Q2);第三个四分位数(Q3)是将数据集分为四个区域后,处于第三区域末尾的数值点。
四分位数可以提供数据集的位置测度,帮助我们理解数据集分布的形态、分位间的差异等。
7. 偏度(Skewness):偏度是用来描述数据分布的偏态程度。
正偏表示数据集右侧的尾部较长,负偏表示数据集左侧的尾部较长。

第四章数据分布特征的测度【教学要求】了解绝对数和相对数的概念及作用,掌握绝对数的种类、相对数的种类及应用;掌握集中趋势的测度方法,掌握算术平均数、调和平均数、几何平均数、众数、中位数的计算方法及应用;掌握离散程度的测度方法,理解全距、四分位差、异众比率、平均差的概念及计算方法,掌握标准差、离散系数的计算方法及应用;了解偏态与峰度的测度方法。
【知识点】绝对数、相对数、术平均数、调和平均数、几何平均数、众数、中位数、全距、四分位差、异众比率、平均差、标准差、离散系数【本章重点】相对数的种类及应用;算术平均数、调和平均数、几何平均数、众数、中位数的计算方法及应用;理解全距、四分位差、异众比率、平均差的概念及计算方法,掌握标准差、离散系数的计算方法及应用。
【本章难点】算术平均数、调和平均数、几何平均数、众数、中位数的计算方法及应用;理解全距、四分位差、异众比率、平均差的概念及计算方法,掌握标准差、离散系数的计算方法及应用。
【教学内容】第一节绝对数和相对数统计指标就其具体内容来讲非常多,可谓成千上万,但从其基本形式看,则不外乎总量指标、相对指标和平均指标三种类型,统称统计综合指标。
一、绝对数(一)绝对数的概念和种类1、绝对数的作用主要表现在:(1)绝对数可以反映一个国家、地区、部门或单位的基本情况(2)绝对数是制定政策、编制计划以及进行科学管理的重要依据(3)绝对数是计算相对数和平均数的基础相对数和平均数是由两个有联系的总量指标对比计算出来的统计综合指标,无论是相对指标还是平均指标,都是总量指标的派生指标,没有总量指标就不会有相对指标和平均指标。
例如,职工劳动生产率、职工平均工资、宏观经济增长速度、国民经济发展的重要比例关系、农作物单位面积产量等都是在总量指标的基础上计算出来的。
(二)绝对数的种类1、按反映总体内容不同分为总体单位总量和总体标志总量。
例、某业企业职工人数1,000人,工资总额1980,000元。