基于Sphinx+MySQL的千万级数据全文检索(搜索引擎)架构设计
- 格式:doc
- 大小:88.50 KB
- 文档页数:7


[文章作者:张宴本文版本:v1.0 最后修改:2008.07.27 转载请注明原文链接:/post/360/]前言:本文阐述的是一款经过生产环境检验的千万级数据全文检索(搜索引擎)架构。
本文只列出前几章的内容节选,不提供全文内容。
在DELL PowerEdge 6850服务器(四颗64 位Inter Xeon MP 7110N处理器/ 8GB内存)、RedHat AS4 Linux操作系统、MySQL 5.1.26、MyISAM存储引擎、key_buffer=1024M环境下实测,单表1000万条记录的数据量(这张MySQL表拥有int、datetime、varchar、text等类型的10多个字段,只有主键,无其它索引),用主键(PRIMARY KEY)作为WHERE条件进行SQL查询,速度非常之快,只耗费0.01秒。
出自俄罗斯的开源全文搜索引擎软件Sphinx,单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为0.x秒(毫秒级)。
Sphinx创建索引的速度为:创建100万条记录的索引只需3~4分钟,创建1000万条记录的索引可以在50分钟内完成,而只包含最新10万条记录的增量索引,重建一次只需几十秒。
基于以上几点,我设计出了这套搜索引擎架构。
在生产环境运行了一周,效果非常不错。
有时间我会专为配合Sphinx搜索引擎,开发一个逻辑简单、速度快、占用内存低、非表锁的MySQL存储引擎插件,用来代替MyISAM引擎,以解决MyISAM存储引擎在频繁更新操作时的锁表延迟问题。
另外,分布式搜索技术上已无任何问题。
一、搜索引擎架构设计:1、搜索引擎架构图:2、搜索引擎架构设计思路:(1)、调用方式最简化:尽量方便前端Web工程师,只需要一条简单的SQL语句“SELECT ... FROM myisam_table JOIN sphinx_table ON (sphinx_table.sphinx_id=myisam_table.id) WHERE query='...';”即可实现高效搜索。

PHP+Mysql+Sphinx高效的站内搜索引擎搭建详释●为什么要使用Sphinx假设你现在运营着一个论坛,论坛数据已经超过100W,很多用户都反映论坛搜索的速度非常慢,那么这时你就可以考虑使用Sphinx了(当然其他的全文检索程序或方法也行)。
●Sphinx是什么Sphinx由俄罗斯人Andrew Aksyonoff 开发的高性能全文搜索软件包,在GPL与商业协议双许可协议下发行。
全文检索是指以文档的全部文本信息作为检索对象的一种信息检索技术。
检索的对象有可能是文章的标题,也有可能是文章的作者,也有可能是文章摘要或内容。
●Sphinx的特性高速索引(在新款CPU上,近10 MB/秒);高速搜索(2-4G的文本量中平均查询速度不到0.1秒);高可用性(单CPU上最大可支持100 GB的文本,100M文档); 提供良好的相关性排名;支持分布式搜索; 提供文档摘要生成; 提供从MySQL内部的插件式存储引擎上搜索; 支持布尔,短语, 和近义词查询; 支持每个文档多个全文检索域(默认最大32个); 支持每个文档多属性; 支持断词; 支持单字节编码与UTF-8编码;●下载并安装Sphinx打开网址/news/7/52/ 找到适合自己的操作系统的版本,比如我是Windows 那么我就可以下载Coreseek Win32通用版本,Linux下可以下载源码包,自己编译安装。
这里解释下为什么我们下载的程序叫Coreseek,Coreseek是基于Sphinx开发的一款软件,对Sphinx做了一些改动,在中文方面支持得比Sphinx好,所以我们使用之。
下载完成后,将程序解压到你想解压的地方,比如我就想解压到E盘根目录,之后修改目录名为Coreseek,大功告成Coreseek安装完成了,安装的目录是在E:\coreseek\。
●使用Sphinx我要使用Sphinx需要做以下几件事1)首先得有数据2)建立Sphinx配置文件3)生成索引4)启动Sphinx5)使用之(调用api或search.exe程序进行查询)第1步:(导入数据)我们建立测试所需要用到得数据库、表以及数据,篇幅有限,这些在附件中都有,下载后导入MySQL即可。

Sphinx 全文搜索引擎1:索引与全文索引的概念数据库中,表中的行特别多,如何快速的查询某一行,或者某一个文章中的单词,索引--->查询速度快全文索引-->针对文章内容中的单词各做索引2:mysql支不支持全文索引?答:支持, 但是A:innoDB引擎在5.5,及之前的版本不支持(5.7实测可以在innodb上建fulltext),只能在myisam 引擎上用fulltextB: mysql的全文索引功能不够强大C: 无法对中文进行合理的全文索引----- mysql.无法进行中文分词.注意:全文索引的停止词停止词是指出现频率极高的单词, 不予索引.如果某单词出现频率50%以上,列为停止词或者是经过统计的常用词,也列为停止词---如is, are , she, he, this 等等就像中文中: “的”,”是”,”呵呵”总结: 我们要对中文做全文搜索引擎,需要解决2个问题1: 性能提高,用第3方的全文搜索引擎工具,如sphinx, solr等2: 中文分词! (如mmseg)编译安装sphinx+mmseg == coreseek官网: 0: 安装工具包yum install make gcc gcc-c++ libtool autoconf automake imake libxml2-devel expat-devel1: 下载解压源码,ls查看csft-4.1 mmseg-3.2.14 README.txt testpack其中--csft-4.1是修改适应了中文环境后的sphinxMmseg 是中文分词插件Testpack是测试用的软件包2: 先安装mmseg2.1: cd mmseg2.2: 执行bootstrap脚本2.3: ./configure --prefix=/usr/local/mmseg2.4: make && make install3: 再安装sphinx(coreseek)3.1: 到其目录下执行buildconf.sh3.2: ./configure --prefix=/usr/local/sphinx--with-mysql=/usr/local/mysql--with-mmseg--with-mmseg-includes=/usr/local/mmseg/include/mmseg/--with-mmseg-libs=/usr/local/mmseg/lib/3.3: make installSphinx的使用分三个部分:1: 数据源---要让sphinx知道,查哪些数据,即针对哪些数据做索引(可以定义多个源)2: 索引配置--针对哪个源做索引, 索引文件放在哪个目录?? 等等3: 搜索服务器----sphinx可以在某个端口(默认9312),以其自身的协议,与外部程序做交互.具体的步骤:1: 数据源典型配置source test {type = mysqlsql_host = localhostsql_user = rootsql_pass =sql_db = testsql_query_pre = set names utf8sql_query_pre = set session query_cache_type=offsql_query = select id,catid,pubtime,title,content from newssql_attr_uint = idsql_attr_uint = catidsql_attr_timestamp = pubtimesql_query_info = select * from news where id=$id}2: 索引典型配置index test {type = plainsource = testpath = /usr/local/sphinx/var/data/test #生成索引放在哪docinfo = externcharset_dictpath = /usr/local/mmseg/etc/charset_type = zh_cn.utf-8}2.1: 生成索引文件/path/sphinx/bin/indexer -c ./etc/sphinx.test.conf test (test是索引名)2.2: 查询测试A:在命令下,用path/bin/search -c ./path/conf 关键词B:开启搜索服务器,利用客户端连接搜索服务器来查询,见下3: 配置搜索服务器接口,启动搜索服务器searchd {listen = localhost:9312pid_file = /usr/local/sphinx/var/log/searchd.pidlog = /usr/local/sphinx/var/log/test.logquery_log =/usr/local/sphinx/var/log/test.query.logclient_timeout = 5max_children = 5max_matches = 1000seamless_rotate = 1}3.2 : 使用客户端连接搜索服务器1)系统testpack包里带的sphinxapi.php2)编译php的sphinx扩展1: 官方搜索下载sphinx扩展的压缩包并解压(假设解析在/usr/local/src/sphinx) 2: /path/php/bin/phpize 执行3: configure --with-php-config=/xxx/path/php/bin/php-config出错: e rror: Cannot find libsphinxclient headers错误原因: 没有预告编译libsphinxclient4: 解决3中的错误cd /usr/local/src/sphinx/api/libsphixclient/目录下# sh buildconf.sh# ./configure# make && make install5: 编译php的sphinx.so扩展# cd /path/to/sphinx1.3.0/#./configure --with-php-config=/usr/local/php/bin/php-config --with-sphinx# make && make install6: 编辑php.ini,把sphinx.so扩展引入并重启apache, 如果是php-fpm方式运行,则重启php-fpm进程查询分3部分1: 查询2: 过滤3: 排序1.1: 查询的模式查询的模式直接影响查询结果,SPH_MA TCH_ALL, 匹配所有查询词(默认模式);SPH_MA TCH_ANY, 匹配查询词中的任意一个;SPH_MA TCH_PHRASE, 将整个查询看作一个词组,要求按顺序完整匹配;SPH_MA TCH_BOOLEAN, 将查询看作一个布尔表达式SPH_MA TCH_ALL->Query(‘西瓜南瓜’) // 文档中有西瓜并且有南瓜才被选中SPH_MA TCH_ANY //->Query(‘西瓜南瓜’) // 文档中有西瓜或有南瓜被选中S PH_MA TCH_PHRASE // 严格理解为两词连续如内容”西瓜南瓜东瓜”->Query(‘西瓜南瓜’), 可以命中->Query(‘西瓜东瓜’), 不能命中, 因为西瓜东瓜两词不连续如果你觉得切换模式麻烦,可用BOOLEAN模式SPH_MA TCH_BOOLAN / /这个模式,能达到上3个模式的效果,需要在查询词之间做表达式如words1 & words2 则等同SPH_MA TCH_ALLWords1 | words2 则,等同SPH_MA TCH_ANYWords1 << word2 则是word1,word2都要有,且words1出现在word2前面1.2: 按字段查询如:要求只查content字段中的”西瓜”关键词“西瓜”====>”@content 西瓜”注意: 按字段查询需要把查询模式设置成”SPH_MA TCH_EXTNEDED”2 按属性过滤SetIDRange($min,$max); // 按id的范围过滤SetFilter($attr,$values=array(),$exclue=false); //SetFilterRange ( $attribute, $min, $max, $exclude=false )SetFilterFloatRange (设置浮点数范围)SetLimits($offset,$limits) //设置偏移量及取出条目例:->SetIDRange(2,3);->SetLimits(2,2); 取第3-4条->SetFilter(‘catid’,array(3,4),false) ; 以catid in (3,4) 为条件进行过滤->SetFilter(‘catid’,array(3,4),true) ; 以catid not in (3,4) 为条件,进行过滤注意:如果setLimits中碰到”per-query max_matches=0 out of bounds (per-server max_matches=1000)”错误,可以通过给setLimits指定第3个参数为大于0的整数,来解决.3: 按属性或权重排序排序模式:SPH_SORT_RELEV ANCE 模式, 按相关度降序排列(最好的匹配排在最前面)SPH_SORT_ATTR_DESC 模式, 按属性降序排列(属性值越大的越是排在前面)SPH_SORT_ATTR_ASC 模式, 按属性升序排列(属性值越小的越是排在前面)SPH_SORT_TIME_SEGMENTS 模式, 先按时间段(最近一小时/天/周/月)降序,再按相关度降序SPH_SORT_EXTENDED 模式, 按一种类似SQL的方式将列组合起来,升序或降序排列。

使用MySQL进行全文搜索的方法及工具推荐引言:数据发展的快速增长以及信息化的需求使得全文搜索变得越来越重要。
全文搜索是指通过检索文本内容,从中找出符合用户查询条件的相关的信息。
在数据库领域,MySQL作为一种常见的关系型数据库,也提供了全文搜索的功能。
本文将介绍使用MySQL进行全文搜索的方法,并推荐一些相关的工具。
一、MySQL全文搜索的基本原理MySQL的全文搜索基于InnoDB存储引擎提供的全文索引功能。
它使用倒排索引技术,将要搜索的文本按照单词进行分割,并建立索引。
用户可以通过MATCH() AGAINST()语句进行全文搜索操作。
1. 创建全文索引在MySQL中,要使用全文搜索功能,需要将文本字段添加全文检索索引。
可以采用两种方式:自然语言模式和布尔模式。
自然语言模式:CREATE FULLTEXT INDEX index_name ON table_name (column_name);布尔模式:CREATE FULLTEXT INDEX index_name ON table_name (column_name) WITH PARSER ngram;2. 使用MATCH() AGAINST()语句进行全文搜索MATCH()函数用于指定要搜索的字段,AGAINST()函数用于指定搜索关键词。
可以使用布尔运算符AND、OR和NOT进行组合查询。
SELECT * FROM table_name WHERE MATCH(column_name)AGAINST('keyword');二、MySQL全文搜索的工具除了MySQL自身提供的全文搜索功能,还有一些第三方工具可以增强MySQL的全文搜索能力。
下面推荐几个常用的工具。
1. ElasticsearchElasticsearch是一个基于Lucene的全文搜索引擎。
它具备分布式搜索、实时搜索、高可靠性等特点,可以快速地处理大规模的数据。

基于Sphinx构建准实时更新的分布式通用搜索引擎平台标签:搜索引擎、分布式、Sphinx、MySQL、并发前言:有不少网友希望阅读全文,我将该文档整理了一下,分享出来。
文档解压后大小为7.33M,共19页。
已经指出:一是MySQL本身的并发能力有限,在200~300个并发连接下,查询和更新就比较慢了;二是由于MySQL表的主键与Sphinx索引的ID一一对应,从而无法跨多表建立整站查询,而且新增加类别还得修改配置文件,比较麻烦;三是因为和MySQL集成,无法发挥出Sphinx的优势。
虽然如此,但对于一些写入量不大的搜索应用,已经足够了,或许对很多人会有帮助。
正文:索引擎平台,已经在生产环境运行9个月以上,经过运营中的不断完善与改进,目前已形成了一套可扩展的分布式通用站内搜索引擎框架。
CMS、视频、论坛等产品发生的增、删、改操作,文本内容实时写入自API查询接口,支持亿级数据的索引、分布式、中文分词、高亮显示、自动摘要、准实时(1分钟内)增量索引更新。
下面是Sphinx新的搜索架构中技术关键点实现方式的一些介绍,与大家分享、交流一下:1、一元分词和中文分词的结合:①、一元分词位于索引更新模块。
Sphinx索引引擎对于CJK(中日韩)语言(必须是UTF-8编码)支持一元切分,假设【反恐行动是国产主视角射击网络游戏】这段文字,Sphinx会将其切成【反恐行动是国产主视角射击网络游戏】,然后对每个字建立反向索引。
如果用这句话中包含的字组成一个不存在的词语,例如【恐动】,也会被搜索到,所以搜索时,需要加引号,例如搜索【"反恐行动"】,就能完全匹配连在一起的四个字,不连续的【"恐动"】就不会被搜索到。
但是,这样还有一个问题,搜索【"反恐行动游戏"】或【"国产网络游戏"】就会搜索不到。
对于这个问题,采用位于搜索查询模块的中文分词来处理。

Sphinx+MySQL5.1x+SphinxSE+mmseg中文分词搜索引擎架构搭建手记研究了一下sphinx,发现真是个好东西,先来几句废话,什么是SphinxSphinx 是一个在GPLv2 下发布的一个全文检索引擎,一般而言,Sphinx是一个独立的搜索引擎,意图为其他应用提供高速、低空间占用、高结果相关度的全文搜索功能。
Sphinx可以非常容易的与SQL数据库和脚本语言集成。
当前系统内置MySQL和PostgreSQL 数据库数据源的支持,也支持从标准输入读取特定格式的XML数据。
通过修改源代码,用户可以自行增加新的数据源(例如:其他类型的DBMS的原生支持)。
Sphinx的特性高速的建立索引(在当代CPU上,峰值性能可达到10 MB/秒);高性能的搜索(在2 – 4GB 的文本数据上,平均每次检索响应时间小于0.1秒);可处理海量数据(目前已知可以处理超过100 GB的文本数据, 在单一CPU的系统上可处理100 M 文档);提供了优秀的相关度算法,基于短语相似度和统计(BM25)的复合Ranking方法; 支持分布式搜索;provides document exceprts generation;可作为MySQL的存储引擎提供搜索服务;支持布尔、短语、词语相似度等多种检索模式;文档支持多个全文检索字段(最大不超过32个);文档支持多个额外的属性信息(例如:分组信息,时间戳等);停止词查询;支持单一字节编码和UTF-8编码;原生的MySQL支持(同时支持MyISAM 和InnoDB );原生的PostgreSQL 支持.更多特性参考手册。
原生MySQL存储引擎检索流程:基于Sphinx存储引擎检索:开始本文以CentOS5.5+mysql-5.1.55+sphinx-0.9.9(coreseek-3.2.14.tar.gz)为例介绍Sphinx+MySQL5.1x+SphinxSE存储引擎+mmseg中文分词搜索引擎架构搭建过程。

基于Sphinx构建Web站内全文搜索系统的研究的开题报告一、研究背景与意义随着互联网内容的爆炸式增长,网站上的信息海量化已成为常态。
如何快速、准确地检索所需的信息,成为了用户的重要需求。
然而,大部分网站的搜索功能存在以下几个问题:1. 搜索结果不准确或不完整,无法满足用户需求;2. 搜索速度慢,甚至出现500等错误,让用户无法使用;3. 不支持搜索指定类型的文件,如PDF、Word文档等;4. 不支持中文全文搜索,存在乱码等问题。
为了解决这些问题,建设一个高效、准确、全面的Web站内全文搜索系统变得愈加必要。
Sphinx是一种全文搜索引擎。
它采用高效的索引和查询算法,支持快速、准确地搜索大量关键词和文本。
与其他搜索引擎相比,Sphinx有如下优势:1. 支持分布式架构,可以横向扩展;2. 网站访问量大时,Sphinx能够快速响应;3. 支持多语言搜索,并且中文搜索支持良好;4. 可以针对不同类型的文件进行全文搜索;5. 支持多种查询方式,满足不同的搜索需求。
因此,本研究旨在探究基于Sphinx构建Web站内全文搜索系统的实现方式及其优化方法,以提高网站搜索的效率和准确性。
二、研究目标与方法本研究的主要目标是:1. 研究Sphinx搜索引擎的技术原理;2. 学习Web站内全文搜索系统的开发方法;3. 建立基于Sphinx的搜索引擎,并与网站进行集成;4. 对Sphinx搜索引擎进行优化,提高搜索效率和准确性。
本研究的方法为:1. 研究相关文献,了解Sphinx搜索引擎的基本原理、应用场景和优劣势;2. 设计Web站内全文搜索系统的系统架构、关键技术和接口规范;3. 根据系统设计,使用Python编写基于Sphinx的搜索引擎,并进行调试和测试;4. 针对搜索效率和准确性等方面进行优化,包括索引优化、查询优化、分布式架构优化等等;5. 与网站进行集成测试,在实际环境中验证搜索功能和性能。
三、预期成果与意义本研究的预期成果为:1. 建立一个基于Sphinx的Web站内全文搜索系统,实现搜索速度快、准确度高和支持多种文件格式的搜索;2. 完成Sphinx搜索引擎的优化工作,提高搜索效率和准确性;3. 提供搜索系统的使用文档和测试报告。
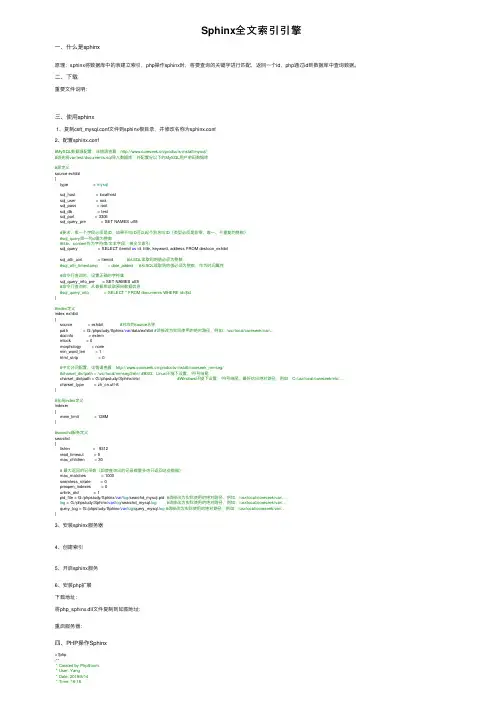
Sphinx全⽂索引引擎⼀、什么是sphinx原理:sphinx将数据库中的表建⽴索引,php操作sphinx时,将要查询的关键字进⾏匹配,返回⼀个id,php通过id到数据库中查询数据。
⼆、下载重要⽂件说明:三、使⽤sphinx1、复制csft_mysql.conf⽂件到sphinx根⽬录,并修改名称为sphinx.conf2、配置sphinx.conf#MySQL数据源配置,详情请查看:/products-install/mysql/#请先将var/test/documents.sql导⼊数据库,并配置好以下的MySQL⽤户密码数据库#源定义source exhibit{type = mysqlsql_host = localhostsql_user = rootsql_pass = rootsql_db = testsql_port = 3306sql_query_pre = SET NAMES utf8#要求:第⼀个字段必须是ID,如果不叫ID可以起个别名叫ID(类型必须是⾮零、唯⼀、不重复的整数)#sql_query第⼀列id需为整数#title、content作为字符串/⽂本字段,被全⽂索引sql_query = SELECT itemid as id, title, keyword, address FROM destoon_exhibitsql_attr_uint = itemid #从SQL读取到的值必须为整数#sql_attr_timestamp = date_added #从SQL读取到的值必须为整数,作为时间属性#命令⾏查询时,设置正确的字符集sql_query_info_pre = SET NAMES utf8#命令⾏查询时,从数据库读取原始数据信息#sql_query_info = SELECT * FROM documents WHERE id=$id}#index定义index exhibit{source = exhibit #对应的source名称path = G:/phpstudy/Sphinx/var/data/exhibit #请修改为实际使⽤的绝对路径,例如:/usr/local/coreseek/var/...docinfo = externmlock = 0morphology = nonemin_word_len = 1html_strip = 0#中⽂分词配置,详情请查看:/products-install/coreseek_mmseg/#charset_dictpath = /usr/local/mmseg3/etc/ #BSD、Linux环境下设置,/符号结尾charset_dictpath = G:/phpstudy/Sphinx/etc/ #Windows环境下设置,/符号结尾,最好给出绝对路径,例如:C:/usr/local/coreseek/etc/...charset_type = zh_cn.utf-8}#全局index定义indexer{mem_limit = 128M}#searchd服务定义searchd{listen = 9312read_timeout = 5max_children = 30# 最⼤返回的记录数(即使查询出的记录数量多也只返回这些数据)max_matches = 1000seamless_rotate = 0preopen_indexes = 0unlink_old = 1pid_file = G:/phpstudy/Sphinx/var/log/searchd_mysql.pid #请修改为实际使⽤的绝对路径,例如:/usr/local/coreseek/var/...log = G:/phpstudy/Sphinx/var/log/searchd_mysql.log#请修改为实际使⽤的绝对路径,例如:/usr/local/coreseek/var/...query_log = G:/phpstudy/Sphinx/var/log/query_mysql.log#请修改为实际使⽤的绝对路径,例如:/usr/local/coreseek/var/...}3、安装sphinx服务器4、创建索引5、开启sphinx服务6、安装php扩展下载地址:将php_sphinx.dll⽂件复制到如图地址:重启服务器:四、PHP操作Sphinx<?php/*** Created by PhpStorm.* User: Yang* Date: 2019/8/14* Time: 16:16*/$sphinx = new SphinxClient();//设置searchd的主机名和TCP端⼝$sphinx->SetServer("localhost", 9312);//设置连接超时$sphinx->SetConnectTimeout(3);//控制搜索结果集的返回格式$sphinx->SetArrayResult(true);//设置全⽂查询的匹配模式/*SPH_MATCH_ALL 匹配所有查询词(默认模式).SPH_MATCH_ANY 匹配查询词中的任意⼀个.SPH_MATCH_PHRASE 将整个查询看作⼀个词组,要求按顺序完整匹配.SPH_MATCH_BOOLEAN 将查询看作⼀个布尔表达式.SPH_MATCH_EXTENDED 将查询看作⼀个Sphinx内部查询语⾔的表达式.SPH_MATCH_FULLSCAN 使⽤完全扫描,忽略查询词汇.SPH_MATCH_EXTENDED2 类似 SPH_MATCH_EXTENDED ,并⽀持评分和权重.*/$sphinx->SetMatchMode(SPH_MATCH_ANY);$q = "2017";$result = $sphinx->Query($q);var_dump($result['matches']);$id_array = array_column($result['matches'], "id");$ids = implode(",", $id_array);echo$ids;array(20) {[0]=>array(3) {["id"]=>string(4) "9388"["weight"]=>int(2574)["attrs"]=>array(1) {["addtime"]=>string(10) "1488729600"}}[1]=>array(3) {["id"]=>string(5) "24571"["weight"]=>int(2574)["attrs"]=>array(1) {["addtime"]=>string(10) "1488729600"}}[2]=>array(3) {["id"]=>string(2) "68"["weight"]=>int(2569)["attrs"]=>array(1) {["addtime"]=>string(10) "1504195200"}}[3]=>array(3) {["id"]=>string(2) "81"["weight"]=>int(2569)["attrs"]=>array(1) {["addtime"]=>string(10) "1504195200"}}...}9388,24571,68,81,3186,3213,3278,3444,3470,3645,3785,3843,3890,3907,4120,4164,4182,4212,4235,4568注意:要通过定时器定时建⽴索引。

强大的开源全文检索引擎——Sphinx
乔楚
【期刊名称】《程序员》
【年(卷),期】2011(000)003
【摘要】随着互联网的发展,Web2.0带来了信息的井喷,我们可以接触和处理的数据越来越丰富,规模也越来越庞大。
不管是互联网网站还是企业自身,都需要对大量的数据进行管理和分析,并且用户对信息的组织、查询、可寻性、及时性的要求也越来越高,这一切都离不开全文检索引擎。
【总页数】2页(P126-127)
【作者】乔楚
【作者单位】不详
【正文语种】中文
【中图分类】TP393
【相关文献】
1.开源全文检索引擎Lucene本地化实践研究 [J], 吴鹏飞;马凤娟;李文革;郭鹏
2.基于Heritrix和Sphinx的购物比较搜索引擎研究 [J], 李远远;吕焱飞
3.基于Sphinx+MySql+Python的站内搜索引擎的设计与实现 [J], 周安
4.Sphinx+ Python +Oracle构建全文检索系统 [J], 徐佳男
5.基于Sphinx的社交网络搜索引擎的设计与分析 [J], 孙逸敏
因版权原因,仅展示原文概要,查看原文内容请购买。

使用MySQL进行全文检索与搜索引擎集成随着互联网的发展与普及,全文检索和搜索引擎的重要性也日益凸显。
全文检索是指通过对文本内容进行分析和索引,实现对文本内容的快速、精确和全面的搜索和查询。
而搜索引擎则是基于全文检索技术,通过对互联网上广泛的信息进行索引和搜索,为用户提供快捷、准确的搜索结果。
而在实际应用中,MySQL作为一种强大的关系型数据库管理系统,也经常需要用于实现全文检索和搜索引擎的功能。
本文将讨论使用MySQL进行全文检索与搜索引擎集成的相关内容,包括原理介绍、技术实现和应用案例等。
一、全文检索原理介绍全文检索的目标是实现对文档内容的全面搜索与查询。
其基本原理是通过对文档进行分词,将分词结果构建倒排索引,然后根据用户的搜索关键词,在倒排索引中查询相关文档,并按照一定的排序算法返回给用户。
常用的全文检索算法有BM25、TF-IDF等。
1. 分词分词是全文检索的第一步,指将待索引文档进行分割成一个个有意义的单词,也称为词项。
常见的分词方法有基于词典的分词、最大匹配法等。
例如,将句子“这是一篇使用MySQL进行全文检索的文章”分词为["这", "是", "一篇", "使用", "MySQL", "进行", "全文检索", "的", "文章"]。
2. 倒排索引倒排索引是全文检索中的核心数据结构,用于快速查找包含某个单词的文档。
它的原理是将文档中的每个单词和它所出现的文档建立映射关系。
通过倒排索引,可以快速找到包含某个单词的文档,并同时支持多个单词的查询。
3. 相关性排序全文检索的关键是根据用户的搜索关键词计算文档的相关性得分,并按照得分进行排序。
常见的相关性计算算法有BM25、TF-IDF等。
通过相关性排序,可以将与用户搜索关键词最相关的文档排在前面,提高搜索结果的准确性。
MySQL中的全文检索和搜索引擎的集成使用方法引言在当今信息爆炸的时代,搜索引擎成为了人们获取信息的重要途径之一。
对于开发人员来说,如何在自己的应用程序中实现高效的全文检索功能成了一个重要的问题。
而MySQL作为最流行的关系型数据库之一,提供了全文检索的功能,同时也支持与搜索引擎的集成。
本文将深入探讨MySQL中的全文检索和搜索引擎的集成使用方法。
一、MySQL中的全文检索功能全文检索是指从文本中搜索出符合特定条件的关键词或句子。
MySQL中的全文检索功能可以帮助我们快速、准确地从大量文本中找到需要的信息。
MySQL的全文检索功能主要有以下几种用法:1. 使用LIKE语句进行模糊匹配在MySQL中,可以使用LIKE语句进行模糊匹配。
例如,我们可以通过以下语句实现对某字段中包含特定关键词的记录的搜索:SELECT * FROM table_name WHERE field_name LIKE '%keyword%';这种方式可以实现简单的关键词匹配,但效率较低,不适用于处理大量数据或者需要高效搜索的场景。
2. 使用全文检索索引(FULLTEXT index)MySQL提供了FULLTEXT index类型来支持全文检索功能。
我们可以在创建表时为某一列添加FULLTEXT索引,然后使用MATCH AGAINST语句进行全文检索。
下面是示例代码:CREATE TABLE table_name (id INT PRIMARY KEY,content TEXT,FULLTEXT(content));SELECT * FROM table_name WHERE MATCH(content) AGAINST('keyword');通过FULLTEXT索引的方式,我们可以更快速地实现全文检索,并且可以使用一些高级特性,如布尔搜索、通配符搜索等。
3. 配置全文检索参数为了更好地使用全文检索功能,我们可以通过配置一些参数来优化全文检索的效果。
本文由我司收集整编,推荐下载,如有疑问,请与我司联系PHP+MySQL+sphinx+scws实现全文检索2017/12/10 160 [root@MevHost sphinxb]# mkdir -p /usr/local/src/sphinx[root@MevHost sphinxb]# cd /usr/local/src/sphinx [root@MevHost sphinxb]# tar -xf sphinx-2.2.11-release.tar.gz [root@MevHost sphinxb]# cd sphinx-2.2.11-release// 这里是指定安装的目录,还有引用mysql,(我这里是mariadb的安装目录)[root@MevHost sphinxb]# ./configure --prefix=/usr/local/sphinx2 --with-mysql=/usr/local/mariadb/[root@MevHost sphinxb]# make make install 安装sphinx客户端这个要安装上,不然安装PHP安装sphinx扩展时会出现报错[root@MevHost sphinxb]# cd /usr/local/src/sphinx/sphinx-2.2.11-release/api/libsphinxclient //sphinx-2.2.11-release目录下[root@MevHost sphinxb]# ./configure --prefix=/usr/local/sphinx2/libsphinxclient [root@MevHost sphinxb]# make make install 为PHP安装sphinx扩展[root@MevHost sphinxb]# cd /usr/local/src/sphinx[root@MevHost sphinxb]# tar zxvf sphinx-1.3.1.tgz [root@MevHost sphinxb]# cd sphinx-1.3.1 [root@MevHost sphinxb]# phpize [root@MevHost sphinxb]# ./configure --with-sphinx=/usr/local/sphinx2/libsphinxclient --with-php-config=/usr/local/php/bin/php-config [root@MevHost sphinxb]# make make install//成功后再php.ini 添加extension=sphinx.so PHP7版本sphinx扩展下载下载地址 git.php/?p=pecl/search_engine/sphinx.git;a=shortlog;h=refs/heads/php7 [root@MevHost sphinxb]# tar -jxvf scws-1.2.3.tar.bz2[root@MevHost sphinxb]# mkdir /usr/local/scws [root@MevHost sphinxb]# cd scws-1.2.3 [root@MevHost sphinxb]# ./configure --prefix=/usr/local/scws/ [root@MevHost sphinxb]# make make install 为PHP安装scws扩展[root@MevHost sphinxb]# cd /usr/local/src/sphinx/scws-1.2.3/phpext [root@MevHost sphinxb]# phpize [root@MevHost sphinxb]# ./configure --with-php-config=/usr/local/php/bin/php-config[root@MevHost sphinxb]# make make install // 在php.ini 加入extension = scws.soscws.default.charset=utf-8scws.default.fpath = /usr/local/scws/etc 安装scws词库。
千万级Discuz!数据全文检索方案(Sphinx)前言:康盛创想的Discuz!从创立之初即以提高产品效率为突破口,随着编译模板,语法生成内核,数据缓存和自动更新机制等独创或独有技术的应用,和坚固的数据结构及最少化数据库查询设计,使得Discuz! 可以在极为繁忙的服务器环境下快速高效稳定运行。
由于Discuz!产品依赖MySQL数据库性能,在全文检索方面如果仅仅依靠MySQL的LIKE %关键词% 语句无法取得理想的成绩。
本文阐述经过Discuz!生产环境考验的构建在Sphinx基础上的千万级Discuz!数据全文检索解决方案。
出自俄罗斯的开源全文搜索引擎软件Sphinx在单一索引达到4千万条记录情况下的查询速度仍为0.x秒甚至0.0x秒级别。
Sphinx创建索引的速度约五分钟处理百万条记录,对于每分钟的增量索引重建只需要几十秒,每日的增量索引合并到主索引也只需一分钟左右。
此构架基础上的Discuz!高负载站点,已成功解决搜索速度慢、经常锁表、无法分布式搜索等问题。
千万级Discuz!数据全文检索方案(Sphinx)适用于繁忙的站点并且论坛访问者有大量的搜索需求,本方案主要解决搜索缓慢问题。
本文环境以CentOS 5为基准。
初始化一次全部索引,按系统计划任务crontab定时方式,每5分钟重建一次增量索引(增量索引不与主索引合并),每日凌晨3:30建立一次昨日比较的增量索引(合并到主索引中)。
主索引建立在磁盘目录/data/sphdata,增量索引建立在内存/dev/shm/中避免大量的I/O操作,由于帖子编辑限制,全部索引每两个月重建一次。
目录千万级Discuz!数据全文检索方案(Sphinx) (1)Sphinx快速介绍 (2)一、Sphinx全文检索方案构架图 (3)二、Sphinx中文分词 (4)三、Sphinx安装步骤 (4)1.安装、升级所需的程序库 (4)2.创建安装文件夹并下载源代码 (4)3.安装MMseg中文分词 (4)4.安装CSFT(Sphinx的CoreSeek修改版) (5)5.编译Sphinx过程可能出现的错误 (5)a)无法找到mysql路径 (5)b)无法找到libiconv (5)c)无法找到libmysqlclient.so.15 (5)d)php 5.2.11版本的api BUG (5)e)生成索引时容易发生磁盘空间不足写入失败的错误 (5)6.安装为php扩展(可选) (6)7.安装SphinxSE存储引擎(可选) (6)四、Sphinx配置 (6)1.mmseg中文分词词库 (6)a)词典格式 (6)b)词库生成方法 (7)2.创建sphinx数据目录结构 (7)3.创建sphinx.conf配置文件 (7)4.mmseg.ini分词配置文件 (14)5.建立Sphinx增量索引数据表 (14)6.书写常用的sphinx控制命令到sh文件 (14)7.创建相应的文件结构,初始化Sphinx的全部索引 (17)8.启动sphinx (17)9.设置计划任务项 (17)10.设置开机启动项 (17)五、通过命令行测试搜索 (17)六、通过php api调用Sphinx搜索 (18)七、通过MySQL的SphinxSE存储引擎调用Sphinx搜索(可选) (19)八、Sphinx数据占用量统计 (19)Sphinx快速介绍Sphinx是独立的搜索服务端,不依赖MySQL,当Sphinx和MySQL结合部署时,Sphinx的数据来源为MySQL。
MySQL中全文索引和搜索引擎的选择和集成导言:在大数据时代,数据的快速查询和搜索变得越来越重要。
针对MySQL数据库中的全文搜索需求,我们需要选择合适的全文索引和搜索引擎,并将其与MySQL集成,以实现高效的全文索引搜索功能。
本文将探讨MySQL中全文索引和搜索引擎的选择和集成方法,帮助读者在实践中做出最佳决策。
1. MySQL中的全文索引全文索引是一种将指定的关键词与文本内容相关联的技术,使得在大量文本数据中进行快速的关键字搜索成为可能。
MySQL提供了多种全文索引实现方式,包括全文索引类型和插件。
1.1 全文索引类型MySQL 5.6及以上版本提供了InnoDB和MyISAM两种全文索引类型,每种类型都有其各自的优缺点。
InnoDB是一种事务性数据库引擎,具有ACID特性,支持数据的并发处理和高可靠性。
在InnoDB中,全文索引是基于倒排索引实现的,对于大规模的数据集和高并发的读写操作,InnoDB全文索引表现出了更好的性能。
然而,在某些特定场景下,速度仍然不足以满足需求。
MyISAM则是MySQL的默认存储引擎,全文索引基于B树和倒排索引的组合实现。
相较于InnoDB,MyISAM在全文索引的查询效率上可能更高。
然而,MyISAM在事务支持和数据安全方面的表现较差。
因此,在选择全文索引类型时,我们需要综合考虑具体的业务需求,权衡各种因素。
1.2 全文索引插件除了MySQL自带的全文索引类型之外,我们还可以选择一些第三方插件来支持全文索引功能。
比较著名的插件包括Sphinx和Elasticsearch。
Sphinx是一个开源的全文搜索引擎,其与MySQL的集成相对简单。
它具有快速、稳定的优点,并支持多种全文索引功能,如模糊搜索、排序和分页等。
Sphinx 可以通过安装插件和配置文件,与MySQL进行数据同步和索引构建。
然后,我们可以通过Sphinx提供的API接口,实现高效的全文搜索功能。
基于MySQL的千万级数据全文检索架构设计摘要:在互联网高速发展的今天,企业需要面对海量数据。
而如何将庞大的数据快速准确地呈现给用户,就成为了企业所面临的一个难题。
本文介绍了一种千万级的数据全文检索架构设计,该方案通过结合数据库中海量表对其数据进行检索、分析、处理并展示结果,同时对部分查询结果进行深度解析,以提高整体性能。
本文首先对全文检索系统架构进行简要概述,然后从三个方面展开论述:查询引擎、索引引擎和查询解析引擎。
其中三个方面分别介绍了核心架构设计的核心思想和架构特点,并对该方案中所涉及的核心技术及实现原理给出了详细介绍。
关键词:全文检索;查询引擎;1背景随着互联网的发展,海量数据不断涌现,数据爆炸式增长的同时,我们却在苦苦寻找着更加优质高效、成本更低的解决方案。
面对海量的数据,我们需要进行快速且精准地检索。
本文介绍基于 MySQL 全文检索系统架构的核心思想及核心技术,通过结合数据库中海量表对其数据进行检索、分析、处理并展示结果,同时对部分查询结果进行深度解析,以提高整体性能。
2关键技术介绍2.1查询设计对查询的响应过程分为三个步骤:查询引擎、索引引擎和解析引擎。
其中索引引擎负责将数据库中的表进行存储和读取,以方便用户快速的获取所需数据;而解析引擎则是对查询得到的数据进行分析和处理,并在需要时显示给用户。
2.2索引模块针对数据库中海量表中存在的冗余记录,以及大量重复记录等数据,索引引擎将对其进一步过滤、合并、删除,以减少其对数据库系统的影响;而索引库则是通过在一定范围内增加索引元素实现索引库管理,在需要时提供方便的查询功能。
3架构设计的核心思想及架构特点架构通过将数据库与MySQL相结合,实现对数据的直接显示输出;同时利用存储引擎对查询结果进行处理,并将所有查询结果展示给用户以方便用户查询。
核心思想通过对数据库中的海量表进行存储和读取,可以将数据库中存在的数据直接展现给用户,以提高用户体验;索引引擎索引引擎采用了层次式结构,可以保证在不同层次提供不同类型索引。
Sphinx+Python+Oracle构建全文检索系统摘要目前,很多大型企业的CRM系统在构建时都是采用Oracle作为数据库,本文正是为这类系统提供一个可以作为参考实现的基于Sphinx的站内全文检索系统的实现方法。
关键词全文检索;Sphinx;站内检索1 Sphinx简介Sphinx是一个在GPLv2下分发的全文检索软件包,是SQL Phrase Index的缩写。
它最初开发的目的是为了在数据库驱动的网站中寻找解决索引质量、搜索性能等各方面的问题而开发的一个高性能独立的全文搜索软件包,所以它可以非常容易的与SQL数据库集成,为数据库驱动的网站提供高质量、高性能的站内搜索。
当前,Sphinx系统内置了MySQL和PostgreSQL数据库数据源的支持,也支持从管道标准输入读取特定格式的XML数据。
但是,目前Sphinx还不支持直接将Oeacle数据库作为数据源,但在最新的版本中,添加了Python数据源支持,这极大的扩展了数据源的来源,我们可以操作Python脚本作为数据源来获取Oracle中的数据。
2 Python数据源操作Oracle数据库的设计与实现考虑到安全、性能等因素,目前,很多大型的网站,尤其是大型企业的CRM 系统,在数据库构建方面都采用了Oracle数据库。
基于此,我的研究正是基于Oracle构建的大型企业CRM系统,借助Sphinx软件包提供全文搜索功能,同时结合MMSeg中文分词软件包来为网站生成一个功能强大的站内搜索引擎。
2.1系统目标本系统要实现一个基于Oracle数据库构建的企业CRM系统的高效的全文检索系统,并保证查询性能和查询结果的准确性,具体应满足以下两方面要求:1)在数据量较大时具有较高的查询性能,在海量数据检索时仍能保持较快的响应速度和准确率;2)以CRM系统在Oracle数据库中所存储的数据为检索目标,系统提供易于操作和使用的查询接口,用户可以通过该系统检索CRM系统上所有的网页内容。
[文章作者:张宴本文版本:v1.0 最后修改:2008.07.27 转载请注明原文链接:/post/360/]
前言:本文阐述的是一款经过生产环境检验的千万级数据全文检索(搜索引擎)架构。
本文只列出前几章的内容节选,不提供全文内容。
在DELL PowerEdge 6850服务器(四颗64 位Inter Xeon MP 7110N处理器/ 8GB内存)、RedHat AS4 Linux操作系统、MySQL 5.1.26、MyISAM存储引擎、key_buffer=1024M环境下实测,单表1000万条记录的数据量(这张MySQL表拥有int、datetime、varchar、text等类型的10多个字段,只有主键,无其它索引),用主键(PRIMARY KEY)作为WHERE条件进行SQL查询,速度非常之快,只耗费0.01秒。
出自俄罗斯的开源全文搜索引擎软件Sphinx,单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为0.x秒(毫秒级)。
Sphinx创建索引的速度为:创建100万条记录的索引只需3~4分钟,创建1000万条记录的索引可以在50分钟内完成,而只包含最新10万条记录的增量索引,重建一次只需几十秒。
基于以上几点,我设计出了这套搜索引擎架构。
在生产环境运行了一周,效果非常不错。
有时间我会专为配合Sphinx搜索引擎,开发一个逻辑简单、速度快、占用内存低、非表锁的MySQL存储引擎插件,用来代替MyISAM引擎,以解决MyISAM存储引擎在频繁更新操作时的锁表延迟问题。
另外,分布式搜索技术上已无任何问题。
一、搜索引擎架构设计:
1、搜索引擎架构图:
2、搜索引擎架构设计思路:
(1)、调用方式最简化:
尽量方便前端Web工程师,只需要一条简单的SQL语句“SELECT ... FROM myisam_table JOIN sphinx_table ON (sphinx_table.sphinx_id=myisam_table.id) WHERE query='...';”即可实现高效搜索。
(2)、创建索引、查询速度快:
①、Sphinx Search 是由俄罗斯人Andrew Aksyonoff 开发的高性能全文搜索软件包,在GPL与商业协议双许可协议下发行。
Sphinx的特征:
•Sphinx支持高速建立索引(可达10MB/秒,而Lucene建立索引的速度是1.8MB/秒)•高性能搜索(在2-4 GB的文本上搜索,平均0.1秒内获得结果)
•高扩展性(实测最高可对100GB的文本建立索引,单一索引可包含1亿条记录)
•支持分布式检索
•支持基于短语和基于统计的复合结果排序机制
•支持任意数量的文件字段(数值属性或全文检索属性)
•支持不同的搜索模式(“完全匹配”,“短语匹配”和“任一匹配”)
•支持作为Mysql的存储引擎
②、通过国外《High Performance MySQL》专家组的测试可以看出,根据主键进行查询的类似“SELECT ... FROM ... WHERE id = ...”的SQL语句(其中id为PRIMARY KEY),每秒钟能够处理10000次以上的查询,而普通的SELECT查询每秒只能处理几十次到几百次:
③、Sphinx不负责文本字段的存储。
假设将数据库的id、date、title、body字段,用sphinx 建立搜索索引。
根据关键字、时间、类别、范围等信息查询一下sphinx,sphinx只会将查询结果的ID号等非文本信息告诉我们。
要显示title、body等信息,还需要根据此ID号去查询MySQL数据库,或者从Memcachedb等其他的存储中取得。
安装SphinxSE作为MySQL 的存储引擎,将MySQL与Sphinx结合起来,是一种便捷的方法。
创建一张Sphinx类型表,将MyISAM表的主键ID和Sphinx表的ID作一个JOIN联合查询。
这样,对于MyISAM表来所,只相当于一个WHERE id=...的主键查询,WHERE后的条件都交给Sphinx去处理,可以充分发挥两者的优势,实现高速搜索查询。
(3)、按服务类型进行分离:
为了保证数据的一致性,我在配置Sphinx读取索引源的MySQL数据库时,进行了锁表。
Sphinx读取索引源的过程会耗费一定时间,由于MyISAM存储引擎的读锁和写锁是互斥的,为了避免写操作被长时间阻塞,导致数据库同步落后跟不上,我将提供“搜索查询服务”的和提供“索引源服务”的MySQL数据库进行了分开。
监听3306端口的MySQL提供“搜索查询服务”,监听3406端口的MySQL提供“索引源服务”。
(4)、“主索引+增量索引”更新方式:
一般网站的特征:信息发布较为频繁;刚发布完的信息被编辑、修改的可能性大;两天以前的老帖变动性较小。
基于这个特征,我设计了Sphinx主索引和增量索引。
对于前天17:00之前的记录建立主索引,每天凌晨自动重建一次主索引;对于前天17:00之后到当前最新的记录,间隔3分钟自动重建一次增量索引。
(5)、“Ext3文件系统+tmpfs内存文件系统”相结合:
为了避免每3分钟重建增量索引导致磁盘IO较重,从而引起系统负载上升,我将主索
引文件创建在磁盘,增量索引文件创建在tmpfs内存文件系统“/dev/shm/”内。
“/dev/shm/”内的文件全部驻留在内存中,读写速度非常快。
但是,重启服务器会导致“/dev/shm/”内的文件丢失,针对这个问题,我会在服务器开机时自动创建“/dev/shm/”内目录结构和Sphinx增量索引。
(6)、中文分词词库:
我根据“自整理的中文分词库”+“搜狗拼音输入法细胞词库”+“LibMMSeg高频字库”+... 综合整理成一份中文分词词库,出于某些考虑暂不提供。
你可以使用LibMMSeg自带的中文分词词库。
二、MySQL+Sphinx+SphinxSE安装步骤:
1、安装python支持(以下针对CentOS系统,其他Linux系统请使用相应的方法安装)yum install -y python python-devel
2、编译安装LibMMSeg(LibMMSeg是为Sphinx全文搜索引擎设计的中文分词软件包,其在GPL协议下发行的中文分词法,采用Chih-Hao Tsai的MMSEG算法。
LibMMSeg在本文中用来生成中文分词词库。
)
以下压缩包“sphinx-0.9.8-rc2-chinese.zip”中包含mmseg-0.7.3.tar.gz、sphinx-0.9.8-rc2.tar.gz以及中文分词补丁。
下载文件
点击这里下载文件
unzip sphinx-0.9.8-rc2-chinese.zip
tar zxvf mmseg-0.7.3.tar.gz
cd mmseg-0.7.3/
./configure
make
make install
cd ../
3、编译安装MySQL 5.1.26-rc、Sphinx、SphinxSE存储引擎
wget
/get/Downloads/MySQL-5.1/mysql-5.1.26-rc.tar.gz/from/http://mirror.x10. com/mirror/mysql/
tar zxvf mysql-5.1.26-rc.tar.gz
tar zxvf sphinx-0.9.8-rc2.tar.gz
cd sphinx-0.9.8-rc2/
patch -p1 < ../sphinx-0.98rc2.zhcn-support.patch
patch -p1 < ../fix-crash-in-excerpts.patch
cp -rf mysqlse ../mysql-5.1.26-rc/storage/sphinx
cd ../
cd mysql-5.1.26-rc/
sh BUILD/autorun.sh
./configure --with-plugins=sphinx --prefix=/usr/local/mysql-search/ --enable-assembler --with-extra-charsets=complex --enable-thread-safe-client --with-big-tables --with-readline --with-ssl --with-embedded-server --enable-local-infile
make && make install
cd ../
cd sphinx-0.9.8-rc2/
CPPFLAGS=-I/usr/include/python2.4
LDFLAGS=-lpython2.4
./configure --prefix=/usr/local/sphinx --with-mysql=/usr/local/mysql-search
make
make install
cd ../
mv /usr/local/sphinx/etc/sphinx.conf /usr/local/sphinx/etc/sphinx.conf.old
第二章第3节之后的正文内容不予公布,全文的目录如下(共24页):。