模糊聚类分析之欧阳家百创编
- 格式:doc
- 大小:134.01 KB
- 文档页数:7
实验报告(一)一、实验内容模糊聚类在土地利用分区中的应用二、实验目的本次上机实习主要以指导学生掌握“如何应用模糊聚类方法进行土地利用规划分区”为目标。
三、实验方法本次试验是在Excel中实现。
利用《土地利用规划学》P114页数据,使用“欧氏距离法”、建模糊相似矩阵,并进行模糊聚类分析实现土地利用分区。
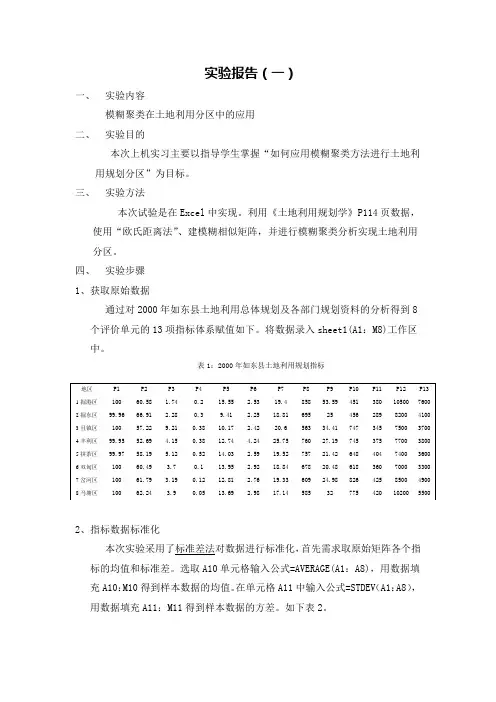
四、实验步骤1、获取原始数据通过对2000年如东县土地利用总体规划及各部门规划资料的分析得到8个评价单元的13项指标体系赋值如下。
将数据录入sheet1(A1:M8)工作区中。
表1:2000年如东县土地利用规划指标2、指标数据标准化本次实验采用了标准差法对数据进行标准化,首先需求取原始矩阵各个指标的均值和标准差。
选取A10单元格输入公式=AVERAGE(A1:A8),用数据填充A10:M10得到样本数据的均值。
在单元格A11中输入公式=STDEV(A1:A8),用数据填充A11:M11得到样本数据的方差。
如下表2。
表2:13个指标值得均值和标准差选取A13单元格输入公式=(A1-A$10)/A$11,并用数据填充A13:M20区域得到标准化矩阵如下表3。
表3:标准化数据矩阵3、求取模糊相似矩阵本次试验是通过欧氏距离法求取模糊相似矩阵。
其数学模型为:mr ij=1−c√∑(x ik−x jk)2k=1选取A23单元格输入公式=SQRT((A$13-A13)^2+(B$13-B13)^2+(C$13-C13)^2+(D$13-D13)^2+(E$13-E13)^2+(F$13-F13)^2+(G$13-G13)^2+(H$13-H13)^2+(I$13-I13)^2+(J$13-J13)^2+(K$13-K13)^2+(L$13-L13)^2+(M$13-M13)^2)求的d11,B23中输入公式=SQRT((A$14-A13)^2+(B$14-B13)^2+(C$14-C13)^2+(D$14-D13)^2+(E$14-E13)^2+(F$14-F13)^2+(G$14-G13)^2+(H$14-H13)^2+(I$14-I13)^2+(J$14-J13)^2+(K$14-K13)^2+(L$14-L13)^2+(M$14-M13)^2)q 求的d12。


模糊数学实验报告题目:模糊聚类分析在交通事故分析中的应用姓名 xxxxxxxxx学号 xxxxxxxxxxxx年级专业 xxxxxxxxxxxxx指导教师 xxxxxxxx20xx年x月xx日模糊聚类分析在交通事故分析中的应用姓名:xx 班级:xxxxxxxxx 学号:xxxxxxxxxxxxxxxxxxx摘要:在模糊集理论及模糊聚类分析方法的四个步骤基础上,深入研究了模糊聚类分析法步骤在交通事故分析中的应用。
通过对1999 年我国交通事故相关数据进行统计,运用模糊聚类分析方法中两种不同的方法得出相似关系矩阵,应用平方法计算传递闭包,最终作出模糊聚类分析,并对两种方法进行比较。
通过对交通事故进行分类,对掌握交通安全情况有很大的帮助。
关键词:模糊相似矩阵;传递闭包;模糊聚类分析;交通事故随着经济的迅速发展,人民的生活得到了极大的改善,单位用车和私家车就越来越多,随之而来的是交通事故发生也越来越多,已引起人们和有关部门的关注和重视。
本文在模糊理论基础上,选取1999 年我国交通事故相关数据,进行分析统计,运用模糊聚类分析方法做出模糊聚类分析。
希望通过对交通事故进行分类,对掌握交通安全情况有很大的帮助,特别在发现交通存在的问题后,分析结果可提供给相关部门参考,针对问题采取措施改善我国交通事故较多的现状。
1 选择统计指标数据采自2002 年中国统计年鉴,分析我国交通现状,选取交通事故中具有代表性的几种情况——汽车、摩托车、拖拉机、自行车、行人乘车作为五个类及即五个单元,对5 种行驶方式安全程度分类。
设 5 种行驶方式组成一个分类集合:分别代表汽车、摩托车、拖拉机、自行车、行人乘车。
每种行驶方式均采用代表性的方面(发生起数、死亡人数、受伤人数、损失折款)作为四项统计指标,即有:这里表示为第i 种行驶方式的第j 项指标。
这四项成绩指标为:发生起数,死亡人数,受伤人数,损失折款。
原始数据如表1 所示。
2 数据标准化数据标准化常采用公式,对数据进行处理。




模糊聚类分析的理论模糊聚类分析是一种基于模糊数学理论的聚类方法,它允许数据点属于多个类别,并且每个类别都有一个模糊度。
这种方法在处理现实世界中的问题时非常有效,因为现实世界中的数据往往不是完全确定的,而是具有模糊性的。
模糊聚类分析的基本思想是将数据点分为若干个类别,使得每个数据点属于各个类别的程度不同。
这种程度可以用一个介于0和1之间的数来表示,0表示不属于该类别,1表示完全属于该类别。
这种模糊性使得模糊聚类分析能够更好地处理现实世界中的不确定性。
模糊聚类分析的理论基础是模糊集合论。
模糊集合论是一种扩展了传统集合论的数学理论,它允许集合的元素具有模糊性。
在模糊集合论中,一个元素属于一个集合的程度可以用一个隶属度函数来表示。
隶属度函数是一个介于0和1之间的数,它表示元素属于集合的程度。
模糊聚类分析的理论方法有很多种,其中最著名的是模糊C均值(FCM)算法。
FCM算法是一种基于目标函数的迭代算法,它通过最小化目标函数来得到最优的聚类结果。
目标函数通常是一个关于隶属度函数和聚类中心之间的距离的函数。
模糊聚类分析的理论应用非常广泛,它可以在很多领域中使用,例如图像处理、模式识别、数据挖掘等。
在图像处理中,模糊聚类分析可以用于图像分割、图像压缩等任务;在模式识别中,模糊聚类分析可以用于特征提取、分类等任务;在数据挖掘中,模糊聚类分析可以用于发现数据中的隐含规律、预测未来趋势等任务。
模糊聚类分析的理论还有很多需要进一步研究和发展的地方。
例如,如何提高模糊聚类分析的效率和准确性,如何处理大规模数据集,如何将模糊聚类分析与其他方法相结合等。
这些问题都需要进一步的研究和探索。
模糊聚类分析的理论是一种强大的聚类方法,它能够处理现实世界中的不确定性,并且具有广泛的应用前景。
通过不断的研究和发展,模糊聚类分析的理论将会更加完善,并且将会在更多的领域中得到应用。
模糊聚类分析的理论模糊聚类分析是一种基于模糊数学理论的聚类方法,它允许数据点属于多个类别,并且每个类别都有一个模糊度。

第二十一篇葡萄酒质量的影响因素分析时间:2021.02.03 创作:欧阳体2012年A题葡萄酒的评价确定葡萄酒质量时一般是通过聘请一批有资质的评酒员进行品评。
每个评酒员在对葡萄酒进行品尝后对其分类指标打分,然后求和得到其总分,从而确定葡萄酒的质量。
酿酒葡萄的好坏与所酿葡萄酒的质量有直接的关系,葡萄酒和酿酒葡萄检测的理化指标会在一定程度上反映葡萄酒和葡萄的质量。
附件1给出了某一年份一些葡萄酒的评价结果,附件2和附件3分别给出了该年份这些葡萄酒的和酿酒葡萄的成分数据。
请尝试建立数学模型讨论下列问题:1. 分析附件1中两组评酒员的评价结果有无显著性差异,哪一组结果更可信?2. 根据酿酒葡萄的理化指标和葡萄酒的质量对这些酿酒葡萄进行分级。
3. 分析酿酒葡萄与葡萄酒的理化指标之间的联系。
4.分析酿酒葡萄和葡萄酒的理化指标对葡萄酒质量的影响,并论证能否用葡萄和葡萄酒的理化指标来评价葡萄酒的质量?附件1:葡萄酒品尝评分表(含4个表格);附件2:葡萄和葡萄酒的理化指标(含2个表格);附件3:葡萄和葡萄酒的芳香物质(含4个表格);原题详见2012年全国大学生数学建模竞赛A题。
葡萄酒质量的影响因素分析*摘要:本文针对葡萄酒和葡萄质量的评价问题,通过t检验、模糊聚类分析、相关性分析等多种方法,综合分析了评酒员葡萄酒品尝评分结果、葡萄和葡萄酒的理化指标以及葡萄和葡萄酒的芳香物质数据,建立了葡萄和葡萄酒的理化指标对葡萄以及葡萄酒质量的影响关系多元线性回归数学模型,运用EXCEL、Matlab软件得出了酿酒葡萄和葡萄酒之间的理化关系。
最后,将模型结果和实际酿酒过程相结合,做出了根据酿酒葡萄和葡萄酒理化指标对葡萄酒质量进行评价的模型,对如何固化葡萄酒质量评判标准提出了相关可行性方案。
针对问题一,根据评酒员对葡萄酒品尝评分结果数据,分别对红葡萄和白葡萄,首先运用t检验分析建立了显著性差异的成对数据t检验模型,分析出两组评酒员的评酒结果具有显著性差异;再运用方差分析建立了方差分析模型,分析出第二组评酒员的评价结果更为可信。

第三篇评价、决策方法与模型近年来,围绕着评价与决策方法,各种相关知识不断渗入,使得评价与决策的方法不断丰富,相关研究也不断深入。
综合评价与决策逐渐成为一个多学科边缘交叉、相互渗透、多点支撑的新兴研究领域。
从某种意义上来讲,没有评价就没有决策。
评价是一种认知过程,是科学决策的前提,而决策是评价的最终目的。
目前流行的几种现代综合评价、决策方法包括模糊综合评价、层次分析法、数据包络分析法、决策分析法、人工神经网络评价法、灰色综合评价法、组合评价法等等。
各种评价、决策方法有简有繁,相互区别但又相互联系。
各种评价、决策方法各具特色,对某类具体问题选择评价、决策方法提供了借鉴。
基于篇幅的限制,本篇仅对模糊聚类分析、模糊综合评价、层次分析法、决策分析法介绍其基本原理、模型建立和求解方法,并讨论各方法在经济管理中的应用。
第九章模糊聚类分析1965年,模糊理论的创始人,美国加利福尼亚大学伯克利分校的计算机和自动控制理论专家L.A.Zadeh教授发表了题为“Fuzzy Set”的论文,这标志着模糊信息处理的诞生,并于20世纪60年代在各科学会议上,从模糊信息处理观点出发,阐述了他的理论。
这一理论是描述和处理事务的模糊性和系统的不确定性,模拟人所特有的模糊逻辑思维功能,从定性到定量,创造了研究模糊性或不确定性问题的理论方法。
Zadeh教授在随后的研究工作中,准确地阐述了模糊性的含义,制定了刻画模糊性的数学方法。
即模糊集合、隶属度、隶属函数等,迄今已成为了一个较为完整的数学分支。
目前对模糊数学的研究十分活跃,模糊集合理论进一步丰富了经典数学的理论系统,为人们处理模糊信息提供了很多好的方法。
现在,模糊数学的公理化基础已经建立,正接受实践的检验,并进一步得到完善。
自从1976年模糊数学传入我国以来,通过广大模糊数学研究工作者的努力,模糊数学在我国得到了极大的发展,目前水平己居于世界前列。
模糊数学在实际应用中几乎涉及到了国民经济的各个领域及相关部门,模糊数学在医学、气象、环境、农业、能源、军事、经济管理和地质勘探等方面都得到了广泛的应用。


第四章 模糊聚类分析在数学上,根据事物的一定特征,并按一定要求和规律对事物进行分类的方法称为聚类分析,聚类分析的对象一定是尚未分类的群体,其理论产生于对事物进行分类的实际要求。
对带有模糊特征的事物进行聚类分析,使用的是模糊数学方法,因而称为模糊聚类分析法。
该法在生物、医学中应用较广,方法也多样,本章着重介绍以模糊相似关系为基础的聚类方法。
第一节 模糊聚类分析的步骤一、原始数据标准化由于实际问题中所收集的数据往往并不是闭区间[0,1]内的数,所以首先要把原始数据标准化,可以采用如下公式sxx x -=' 其中 x ---原始数据,x ---原始数据的平均值,s —原始数据的标准差这样得到的标准化数据还不一定落在 [0,1]内,若要把标准化数据压缩到[0,1]闭区间,可采用极值标准化公式minmax minx x x x x --='显然,当x =x min 时,则0='x 当x =x max 时,则1='x 二、建立模糊相似关系设Z={x 1 , x 2 , …, x n }是待分类事物的全体,设每一被分类的对象 x i 是由一组数据),,,(21im i i i x x x x = ),,2,1(n i =来表示,现在的问题是如何建立x i 和x j 之间的相似关系?按照实际情况,选用下列方法之一来表示x i 和x j :1.最大最小法()()∑∑===m k jk ikmk jk ikij x xx xr 11,max ,min2.几何平均最小法()∑∑==⋅=mk jkik mk jk ikij x x x xr 11,min3.算术平均最小法()()∑∑==+=mk jk ik mk jk ikij x x x xr 1121,min4.相关系数法∑∑∑===----=mk mk j jk i ikmk j jk i ikij x x x xx x x xr 11221)()())((其中∑==m k ik i x m x 11 ∑==mk jk j x m x 115.指数相关系数法∑=⎥⎥⎦⎤⎢⎢⎣⎡⎪⎪⎭⎫⎝⎛-⋅-=mk k jk ik ij S x x m r 1243exp 1 其中()∑=-=mk k ik k x x n S 121 ∑==nj jk k x n x 116.夹角余弦法∑∑∑===⋅⋅=m k mk jkikmk jkikij xx x xr 112217.数量积法⎪⎩⎪⎨⎧⋅=∑=mk jkikij x xMr 111时当时当j i j i ≠=其中M 是一个适当选择的正数,并且满足⎪⎭⎫⎝⎛⋅≥∑=m k jk ik x x M 1max8.距离法qmk q jk ik ij x x r 11⎪⎭⎫ ⎝⎛-=∑= 闵可夫斯基距离当q=1时,∑=-=mk jk ikij x xr 1海明距离当q=2时,∑=-=mk jk ijij x xr 12)( 欧氏距离9.非参数法令i ik ikx x x -=' j jk jk x x x -=' 集合},,,,,{2211jm imj i j i x x x x x x '''''' 中正数个数记为n + ,负数个数记为n -- : ⎪⎪⎭⎫⎝⎛+-+=-+-+n n n n r ij 121 10.绝对值减数法⎪⎩⎪⎨⎧--=∑=mk jk ik ij x x C r 111 时当时当j i j i ≠= 其中C 适当选择,使0≤r i j ≤1 11.绝对值指数法⎪⎭⎫ ⎝⎛--=∑=mk jkik ij x x r 1exp12.绝对值倒数法⎪⎩⎪⎨⎧-=∑=m k jk ik ij x x M r 11 时当时当j i j i ≠=其中M 是一个适当选择的正数,并且满足⎪⎭⎫⎝⎛-≤∑=m k jk ik x x M 1min以上各式中的ik x 为第 i 个点第k 个因子的值,jk x 为第 j 个点第k 个因子的值。
第8讲 模糊关系(第四章 模糊关系与模糊聚类分析)一、模糊关系1.普通关系(1)直积(笛卡尔积,Descartes)定义4.1给定集合,A B ,由A 中元素和a B 中元素搭配起来的所有元素对构成的集合称为(,)a b b A B 与的直积,或笛卡尔(Descartes)乘积,记作A B ×,即{}(,)|,A B a b a A b B ×=∈∈ 类似地,可定义{}11(,,),1,,n n i i A A x x x A i n Δ××=∈= 211321111,R R R R R R R R R=×=×=×× (2)关系现实世界中存在各种各样的关系。
“父子关系”,“师生关系”,“数的大于等于关系”…,X Y 特点:涉及两个集合,y ,x X y Y ∀∈∈x ,与或者有关系,或者没关系,这就是普通关系。
,X Y X 定义4.2 给定论域,规定一个到的关系R X Y →Y R (记作),对任意y ,x X y Y ∈∈xRy x x ,与有关系,记作,与y c xR y 无关系记作,二者必居其一,且仅居其一。
R X 当时,X Y =称为上的关系。
对元素间的搭配施加某些限制,构成的集合就是A B ×的一个子集,这种联系就是所谓关系。
R X Y ⊆×定义 4.2 (等价定义)若',则称R X 为到的关系。
Y 例4.1 “大于等于“关系,记作“” ≥(,)x y R R ∀∈×,1, (,)0, x y x y x y ≥⎧≥=⎨<⎩例4.2 设表示教室里的全体男同学,Y 表示教室里的全体女同学。
X X Y ×表示什么?任意一个男同学和任意一个女同学组成的有序对构成的集合。
R ,则“同系”关系记为{}(,)|R x y x X y Y x y =∈∈,,且与同属一个系,显然R X Y ⊆×。
第二节 模糊聚类分析方法在科学技术、经济管理中常常要按一定的标准(相似程度或亲疏关系)进行分类。
例如,根据生物的某些性状可对生物分类,根据土壤的性质可对土壤分类等。
对所研究的事物按一定标准进行分类的数学方法称为聚类分析,它是多元统计“物以类聚”的一种分类方法。
由于科学技术、经济管理中的分类界限往往不分明,因此采用模糊聚类方法通常比较符合实际。
一、模糊聚类分析的一般步骤1、第一步:数据标准化[9](1) 数据矩阵设论域12{,,,}n U x x x =为被分类对象,每个对象又有m 个指标表示其性状,即12{,,,}i i i im x x x x = (1,2,,)i n =,于是,得到原始数据矩阵为111212122212m m n n nm x x x x x x x x x ⎛⎫⎪ ⎪ ⎪⎪⎝⎭。
其中nm x 表示第n 个分类对象的第m 个指标的原始数据。
(2) 数据标准化在实际问题中,不同的数据一般有不同的量纲,为了使不同的量纲也能进行比较,通常需要对数据做适当的变换。
但是,即使这样,得到的数据也不一定在区间[0,1]上。
因此,这里说的数据标准化,就是要根据模糊矩阵的要求,将数据压缩到区间[0,1]上。
通常有以下几种变换: ① 平移·标准差变换i k kikkx x x s -'= (1,2,,;1,2,i n k m ==其中 11n k i k i x x n ==∑,k s = 经过变换后,每个变量的均值为0,标准差为1,且消除了量纲的影响。
但是,再用得到的ikx '还不一定在区间[0,1]上。
② 平移·极差变换111m i n {}m a x {}m i n {}i k i k i nikik iki ni nx x x x x ≤≤≤≤≤≤''-''=''-,(1,2,,)k m =显然有01ikx ''≤≤,而且也消除了量纲的影响。
存档编号:中期论文题目:金融风险的预警指标体系研究综述专业:金融学院系:金融学院年级:09级学号:090301024姓名:周露晨指导教师:杨雪莱职称:副教授湖北经济学院教务处制摘要:在当前制度转轨、经济转型和金融全球化的大背景下,经济发展的同时存在的金融风险隐患不容小觑,而金融危机的出现常常是从金融指标的不景气开始的,建立完善的风险预警指标体系并采取有效措施对风险加以防范和化解尤为重要。
本文主要对国内外学者对于金融风险及其对风险预警指标体系的研究进行了一些分类、总结及论述。
关键词:金融风险风险防范金融监管风险预警指标一、金融风险及其预警系统概述金融风险,指任何有可能导致企业或机构财务损失的风险。
一家金融机构发生的风险所带来的后果,往往超过对其自身的影响。
金融机构在具体的金融交易活动中出现的风险,有可能对该金融机构的生存构成威胁;具体的一家金融机构因经营不善而出现危机,有可能对整个金融体系的稳健运行构成威胁;一旦发生系统风险,金融体系运转失灵,必然会导致全社会经济秩序的混乱,甚至引发严重的政治危机。
金融风险主要分为系统风险和非系统风险两大类。
金融危机是伴随着金融风险产生的,通常能够有效地通过大幅度变化来预兆金融危机的金融指标包括:货币供应增长率、实际利率、通货膨胀率、国内信贷增长率、实际GDP 增长率、财政收支差额/GDP、外汇储备可供进口月数、外汇储备/短期外债、贸易差额/外债总额、实际汇率及波动程度、外国直接投资/外债、经常项目/GDO、贸易差额/GDP、外汇储备/GDP、外债总额/GDP、短期资本流入/GDP、股市价格指数波动幅度、不良资产/银行总资产、银行资本充足率等。
金融安全作为国家经济安全的核心,而确保金融安全的核心是金融系统性风险的防范与控制。
建立一个有效的金融危机早期预警系统模型,是各国政府、国际金融组织及学术界研究金融安全及金融系统性风险问题时最为关注的问题之一。
建立金融危机早期预警系统模型的意义在于,通过定量分析模型,找出金融危机发生的条件和能够预测该条件的一组经济金融指标,然后通过监测这一系列可测经济金融指标对金融危机进行早期预警,以防范金融危机的发生,确保金融体系安全稳健地运行。
第三章模糊聚類分析壹、何謂聚類分析聚類分析是研究事物分類的一種多元分析方法。
在日常生活中,我們時常要把所接觸到的事物(樣本),按其性質、用途等進行分類,這種分類過程我們稱為聚類分析。
(闕頌廉,民83)貳、聚類分析的應用模糊聚類分析是當前在模糊數學中應用最多的幾個方法之一,可以將研究的樣本進行合理的分類,如產品的分類就常常用聚類分析來進行,另聚類分析也可用來進行判別分析和預測(林傑斌等。
民76)。
所以,也被廣泛地應用於天氣預報、地震預測、地質探勘、運動員心理素質分類、河川水質污染程度等方面。
參、普通的等價關係在談聚類分析之前,應先介紹相似關係和等價關係:一.自反性對任意Uu∈,都有R)u,u(∈,即集合中任一個元素u都與自身有某相同性質的關係,則稱R是自反關係,相對應的矩陣稱為自反矩陣。
另數學表示意義為:A中的元素關於R具有”自反性”,即。
例:若U 為同一種族的集合,而集合中每一個人u ,皆與自身有同一種族之關係,這種性質則稱為自反性。
二. 對稱性如果ji ,R )u ,u (,R )u ,u (i j j i ≠∈∈必有。
即u i 與u j 有存在某種關係,若將兩個元素之位置對調,則即u j 與u i 也必有符合這層關係,則稱R 有對稱關係,相對應的矩陣為對稱矩陣。
另數學表示意義為:A 中的元素關於R 具有”對稱性”,即yRx xRy ,A y ,x 且若∈∀。
例:若甲和乙是同學關係,則乙和甲必也是同學關係,這種關係則稱為對稱性。
三. 傳遞性如果能由R )w u (R )w v (R )v u (∈∈∈,,推導出,及,。
即u 與v 有存在某一關係,而v 與w 也有這同一種關係存在,則即u 與w 也必有符合這層關係存在,則稱R 有傳遞關係,相對應的矩陣為傳遞矩陣。
另數學表示意義為:A 中的元素關於R 具有”傳遞性”,即。
例:若甲和乙是同一種族關係,而乙和丙也是同一種族關係,則甲和丙必有同一種族關係,這種則稱為具有傳遞性關係。
1.模糊聚类分析模型环境区域的污染情况由污染物在4个要素中的含量超标程度来衡量。
设这5个环境区域的污染数据为1x =(80, 10, 6, 2), 2x =(50, 1, 6, 4), 3x =(90, 6, 4, 6), 4x =(40, 5, 7, 3), 5x =(10, 1, 2, 4). 试用模糊传递闭包法对X 进行分类。
解 :由题设知特性指标矩阵为:*80106250164906464057310124X ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦ 数据规格化:最大规格化'ij ijjx x M =其中: 12max(,,...,)j j j nj M x x x =构造模糊相似矩阵: 采用最大最小法来构造模糊相似矩阵55()ij R r ⨯=,利用平方自合成方法求传递闭包t (R )依次计算248,,R R R , 由于84R R =,所以4()t R R =210.630.620.630.530.6310.560.700.530.620.5610.620.530.630.700.6210.530.530.530.530.531R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦,410.630.620.630.530.6310.620.700.530.620.6210.620.530.630.700.6210.530.530.530.530.531R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦=8R选取适当的置信水平值[0,1]λ∈, 按λ截矩阵进行动态聚类。
把()t R 中的元素从大到小的顺序编排如下: 1>0.70>0.63>062>053. 依次取λ=1, 0.70, 0.63, 062, 053,得11000001000()0010*******0001t R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦,此时X 被分为5类:{1x },{2x },{3x },{4x },{5x }0.71000001010()001000101000001t R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦,此时X 被分为4类:{1x },{2x ,4x },{3x },{5x }0.631101011010()001001101000001t R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦,此时X 被分为3类:{1x ,2x ,4x },{3x },{5x }0.621111011110()111101111000001t R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦,此时X 被分为2类:{1x ,2x ,4x ,3x },{5x }0.531111111111()111111111111111t R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦,此时X 被分为1类:{12345,,,,x x x x x }Matlab 程序如下:%数据规格化MATLAB 程序 a=[80 10 6 2 50 1 6 4 90 6 4 6 40 5 7 3 10 1 2 4]; mu=max(a)for i=1:5for j=1:4r(i,j)=a(i,j)/mu(j);endendr%采用最大最小法构造相似矩阵r=[0.8889 1.0000 0.8571 0.33330.5556 0.1000 0.8571 0.66671.0000 0.6000 0.5714 1.00000.4444 0.5000 1.0000 0.50000.1111 0.1000 0.2857 0.6667];b=r';for i=1:5for j=1:5R(i,j)=sum(min([r(i,:);b(:,j)']))/sum(max([r(i,:);b(:,j)'])); endendR%利用平方自合成方法求传递闭包t(R)矩阵合成的MATLAB 函数function rhat=hech(r);n=length(r);for i=1:nfor j=1:nrhat(i,j)=max(min([r(i,:);r(:,j)']));endend求模糊等价矩阵和聚类的程序R=[ 1.0000 0.5409 0.6206 0.6299 0.24320.5409 1.0000 0.5478 0.6985 0.53390.6206 0.5478 1.0000 0.5599 0.36690.6299 0.6985 0.5599 1.0000 0.38180.2432 0.5339 0.3669 0.3818 1.0000];R1=hech (R)R2=hech (R1)R3=hech (R2)bh=zeros(5);bh(find(R2>0.7))=12.模糊综合评判模型某烟草公司对某部门员工进行的年终评定,关于考核的具体操作过程,以对一名员工的考核为例。
附件5模板二目录第一章系统需求1第二章分析方法原理2第三章分析数据说明2第四章算法实现2第五章预测结果分析25.1 聚类成两个簇:25.2 聚类成三个簇6结论6参考文献6结束语6(注:此目录应该是自动生成的)第一章系统需求介绍选题的背景以及意义第二章分析方法原理介绍使用的相关分析方法的理论基础第三章分析数据说明介绍各分析数据的含义,各数值的分布情况等第四章算法实现依据分析方法原理介绍各关键的实现步骤第五章预测结果分析对聚类的各个情况进行分析:5.1 聚类成两个簇:划分为两个簇,每个簇区分其他簇特征是:图5.4聚类中心聚类结果通过分类总结特征如表5.6进行归纳概括,总结出10个客户群的特征,根据特征类型对用户群命名,并提出相应的营销策略.第1类:本地中高价值群,总通话次数大于平均通话次数,客户入网时间长人数虽不多但也要保留改客户群,以提高企业的竞争力.应该提供本地套餐,向其提供体验式的服务,引导他们进行增值业务方面的消费.以保留改客户群,本群对长话漫游不敏感,我们应该提升他们的长话消费.以提高总体消费,具体方式可以采用促销和体验式服务.第2类:业务中高价值群,本群的特点是,长途,漫游通话,本地通话一般,工作时通话占比大.针对此类客户,我们应该提供好的套餐,这套餐要适合长话和漫游的同时也适应本地通话.提供全套服务,以提升客户的消费,达到保留客户的目的.第3类:典型低价值群体,该群体所占比例大,也是高危群体, 人数占总预流样本中数的85.7%以上,所以要特别关注,应该促进该客户群的月消费,多提供套餐服务,提高客户的月通话数.我们可以通过市话套餐的推广提升他们的月均消费额,向其提供体验式的服务,引导他们进行增值业务方面的消费.第4类:本地业务型中价值,本地通话量较大,通话时间长,工作时间通话量大,基本无长途和漫游通话,主要通过主动联系他人,很少得到他人联系.客户忠诚度相对较高.针对此用户群我们应该提供工作型服务套餐,促进客户消费来保留该客户群.第5类:商务中价值,国内长途通话多,本地通话一般,优惠时间通话较多.提供好的优惠政策,采用漫游优惠类套餐,稳定客户长期在网.第6类:典型的商务型中价值,该预流客户类型的本地通话一般,但是漫游通话比较多,所以要保留这一类客户要采用漫游优惠类套餐,为客户提供好的漫游服务,稳定客户长期在网;漫游通话次数多,表明该类客户长期在外,因此可以提供机场绿色通道、预订酒店等类辅助服务第7类:本地工作群高价值,该类型客户通话时间长,本地通话占总通话的90%以上,工作通话多,基本无漫游通话,客户入网时间短.该类型客户的发展对公司的发展很有帮助,该类型客户要需要好的本地服务,所以我们应该采取本地套餐服务,来改善客户对企业的看法,从而保留客户.第8类:本地中价值,本地中价值客户是一个很大的消费群体,我们应该以提升他们的月消费为主,提高IP通话的使用率,培养他们的消费需求,具体方式可以采用促销和体验式服务.,第9类:中低价值,长途和漫游通话相对较多,本地通话一般,工作通话占总通话的一半.客户入网时间较长.该类型客户是元老级的,对电信的原有服务了如指掌.所以要留住该类型客户只有提出新型的客服服务,来激发客户的兴趣.以为该客户的漫游、长途和IP 电话较多,要提供好的长话漫游服务,来保留该类型客户.第10类:本地和长途通话都一般,工作通话占比大,客户群体也占的多,该类客户上班期间通话多,我们应该提供好的忙时服务,提供客户消费,来保留客户.经过上面对每类的分析也了解到,上面10类客户主要业务是主叫,被叫的所占比例小,流失的可能性大.所针对上面的所以客户我们应该提供好的套餐和彩铃服务,以提高他们的被叫率来达到保留客户的目的.5.2 聚类成三个簇结论参考文献结束语。
模糊数学实验报告
欧阳家百(2021.03.07)
题目:模糊聚类分析在交通事故分析中的应用
姓名 xxxxxxxxx
学号 xxxxxxxxxxxx
年级专业 xxxxxxxxxxxxx
指导教师 xxxxxxxx
20xx年x月xx日
模糊聚类分析在交通事故分析中的应用
姓名:xx 班级:xxxxxxxxx 学号:xxxxxxxxxxxxxxxxxxx 摘要:在模糊集理论及模糊聚类分析方法的四个步骤基础上,深入研究了模糊聚类分析法步骤在交通事故分析中的应用。
通过对1999 年我国交通事故相关数据进行统计,运用模糊聚类分析方法中两种不同的方法得出相似关系矩阵,应用平方法计算传递闭包,最终作出模糊聚类分析,并对两种方法进行比较。
通过对交通事故进行分类,对掌握交通安全情况有很大的帮助。
关键词:模糊相似矩阵;传递闭包;模糊聚类分析;交通事故
随着经济的迅速发展,人民的生活得到了极大的改善,单位用车和私家车就越来越多,随之而来的是交通事故发生也越来越多,已引起人们和有关部门的关注和重视。
本文在模糊理论基础上,选取1999 年我国交通事故相关数据,进行分析统计,运用模糊聚类分析方法做出模糊聚类分析。
希望通过对交通事故进行分类,对掌握交通安全情况有很大的帮助,特别在发现交通存在的问题后,分析结果可提供给相关部门参考,针对问题采取措施改善我国交通事故较多的现状。
1 选择统计指标
数据采自2002 年中国统计年鉴,分析我国交通现状,选取交通事故中具有代表性的几种情况——汽车、摩托车、拖拉机、自行车、行人乘车作为五个类及即五个单元,对 5 种行驶方式安全程度分类。
设 5 种行驶方式组成一个分类集合:
分别代表汽车、摩托车、拖拉机、自行车、行人乘车。
每种行驶方式均采用代表性的方面(发生起数、死亡人数、受伤人数、损失折款)作为四项统计指标,即有:
这里表示为第i 种行驶方式的第
j 项指标。
这四项成绩指标为:发生起数,死亡人数,受伤人数,损失折款。
原始数据如表1 所示。
2 数据标准化
数据标准化常采用公式,对数据进行处理。
本文采用较为精确的极差转化方法对数据标准化。
首先,对数据进行偏差转换。
由偏差转换公式:
于是,原始数据可转换为表2。
而后,对表 2 中的数据应用极差化法,从而可得到标准化数据。
由极差化法公式:
则标准化后的数据如表3 所示。
3 应用最大最小法进行聚类分析
最大最小法公式为:
将标准化后数据代入上式,得相似关系矩阵:
应用平方法求得传递闭包
由上可知是模糊等价矩阵,是传递闭包,即。
可得如下分类:
当时,将U分成一类。
当时,将U分成二类。
当时,将U分成三类。
当时,将U分成四类。
当时,将U 分成五类。
聚类图如图1 所示。
结果分析:在应用最大最小法分类结果中,按进行分类,由于过分强调 5 种行驶方式统计指标上的差异,而没有注意到各指标的相互影响关系,没有真正起到分类的作用,因而不可取。
按及分类又完全忽视了 5 种行驶方式上所表现出的各种差异,分类太粗。
本例的模糊聚类按、
分类比较不仅将具有相同特征统计指标的行驶方式归并到了一块,而且还将不同特征统计指标的行驶方式区分开来。
4 应用夹角余弦法进行聚类分析
夹角余弦公式为:
将标准化后数据代入上式,得模糊相似关系矩阵:
应用平方法求得传递闭包。
可得如下分类:
当时,将U分成一类。
当时,将U分成二类。
当时,将U分成三类。
当时,将U分成四类。
当时,将U 分成五类。
聚类图如图2 所示。
结果分析:在应用夹角余弦法分类结果中,按
进行分类,由于过分强调 5 种行驶方式统计指标上的差异,而没有注意到各指标的相互影响关系,没有真正起到分类的作用,因而不可取。
按及分类又完全忽视了 5 种行驶方式上所表现出的各种差异,分类太粗。
本例的模糊聚类按、分类比较不仅将具有相同特征统计指标的行驶方式归并到了一块,而且还将不同特征统计指标的行驶方式区分开来。
行驶方式的分类利于分析交通运输中何种方式比较安全。
从例子中可以看出,通过对1999 年我国交通事故基本情况进行聚类分析,可以了解到汽车这种交通工具的事故指标较高;摩托车、自行车、行人乘车这三种行驶方式的事故指标比较接近,各项指标属一般;拖拉机这种交通工具的事故指标较低。
5 总结
本文通过应用聚类分析中的两种不同的方法进行交通事故的分析,在应用的过程得知最大最小法的计算过程较为简便,夹角
余弦的计算过程较为复杂,两种方法的数据存在着差异,相对比较夹角余弦的分析数据较精确。
6附录代码部分:(m文件)
F-JIR.m
Function[R]=F_JIR(cs,X)
%模糊聚类分析建立模糊相似矩阵
%X,数据矩阵
%cs=1,最大最小法
%cs=2,夹角余弦法
[n,m]=size(X)%获得矩阵的行列数
R=[];
If(cs==1)%最大最小法
for(i=1:n)for(j=1:m)fz=0;fm=0;
for(k=1:m)
if(X(j,k)<0)R=[];return;end
if(X(j,k)<X(i,k))x=X(i,k);
else x=X(j,k);end
fz=fz+x;
end
for(k=1:m)
if(X(i,k)>X(j,k))x=X(i,k);
else x=X(j,k);end;end
fm=fm+x;
R(i,j)=fz/fm;
end;end
elseif(cs==2)%夹角余弦法
for(i=1:n)for(j=1:n)xi=0;xj=0;
for(k=1:m)xi=xi+X(i,k)^2;xj=xj+X(j,k)^2;end s=sqrt(xi*xj);R(i,j)=0;
for(k=1:m)R(i,j)=R(i,j)+X(i,k)*X(j,k);end
R(i,j)=R(i,j)/s;
end;end;end。