ODI+SNPW数据库表结构分析
- 格式:doc
- 大小:1.23 MB
- 文档页数:35



使用MySQL进行多维度数据分析和OLAP处理MySQL是一种常用的关系型数据库管理系统,具有强大的数据存储和查询能力。
除此之外,MySQL还允许进行多维度数据分析和OLAP(联机分析处理)操作,帮助用户深入挖掘数据背后的关联和规律。
本文将探讨如何使用MySQL进行多维度数据分析和OLAP处理,为读者提供有关这一主题的详细指南。
一、多维度数据分析概述多维度数据分析是一种从多个角度对数据进行分析的技术。
传统的数据分析通常只从一个维度进行分析,而多维度数据分析则能够从不同维度同时进行分析,使分析结果更全面和深入。
在MySQL中,多维度数据分析通常通过使用数据立方体(Data Cube)来实现。
数据立方体是一个多维数据模型,其中的每一维度都代表了不同的数据属性。
通过对数据立方体进行切割、钻取和汇总等操作,可以实现多维度数据分析。
二、构建数据立方体在对数据进行多维度分析之前,首先需要构建数据立方体。
在MySQL中,构建数据立方体的过程通常包括以下几个步骤:1. 定义维度和度量:维度是数据立方体中的属性,而度量则是用于度量、计算和分析数据的指标。
维度通常包括时间、地理位置、产品等,度量则包括销售额、利润等。
2. 创建数据表:根据定义的维度和度量,创建相应的数据表。
在数据表中,每行代表一个数据记录,每列代表一个属性。
确保数据表中包含了所有需要进行分析的属性。
3. 导入数据:将需要分析的数据导入到创建好的数据表中。
可以使用MySQL提供的命令行工具或者图形界面工具来进行数据导入。
4. 创建索引:为了提高数据查询的效率,需要对数据表中的关键字段创建索引。
索引能够加快数据的查找速度,减少数据库的查询时间。
5. 建立数据立方体:使用MySQL的数据立方体扩展工具或者自定义SQL语句,按照定义的维度和度量,构建数据立方体。
在数据立方体中,每个维度对应一个维度表,维度表中包含了唯一的维度值和维度属性。
同时,还需要创建度量表,度量表中存储了度量指标的值。

基因组学中的SNP分析SNP(Single Nucleotide Polymorphism)是指基因组中的单个核苷酸突变。
SNP分析是基因组学研究中的重要分析方法之一,为了更好地了解SNP分析在基因组学中的作用,我们需要从以下几个方面进行逐步的了解。
一、SNP的特征SNP是常见的继承性遗传变异,主要发生在基因组中7-10%的位置。
它具备许多有价值的特征,例如高度多态性、共有性基因性和容易鉴定性等。
SNP的多态性使其成为研究人类及其他物种遗传标记的优良素材。
SNP基于其出现的频率可以分为高频和低频。
高频SNP在人类人群中具有普遍性,低频SNP在某些群体中出现的频率很低。
SNP在基因组中的位置也非常有规律,即位于编码区、非编码区、隐形区,以及转录因子结合区等重要区域中。
二、SNP分析的方法SNP分析的方法根据分析的目的和数据场景不同,可以分为不同的方法。
常见的SNP分析技术包括测序分析、芯片分析和PCR分析等。
测序分析是快速发展的分析技术,包括全基因组测序和目标基因测序两种。
芯片分析是目前应用比较广泛的SNP分析技术,可快速、准确地进行大规模的SNP检测。
PCR分析适用于单个SNP的检测和测序后验证,具有快速、灵敏度高、操作简单等优点。
三、SNP分析的应用SNP分析在基因组学中的应用非常广泛,主要应用于以下几个方面:1、研究遗传多样性SNP在人群中的频率不同,可以用于描述人类、动植物的遗传多样性,推断人类或种群的出现时间及演化过程等。
2、研究遗传病理学SNP分析也可用于研究不同类型的疾病和病态的发生机制,便于快速准确地识别和分析疾病易感性基因。
3、研究药理学SNP分析也可以帮助研究药物代谢方面的基因,寻找药物作用机制、筛选新药等。
4、研究育种学SNP不仅可应用于人类、动植物的遗传多样性研究中,还可以帮助育种与遗传改良中研究重要基因资源。
四、SNP分析的未来SNP分析虽然已经在基因组学研究中得到了广泛的应用,但随着科技的不断进步,SNP分析的应用范围将会更广泛。

Affymetrix SNP芯片数据分析方案项目一、基本分析包括:芯片原始数据的处理和基因分型,我们给出有统计意义的SNP列表。
描述性统计,如minor allele frequency,Hardy-Weinberg equilibrium等。
显著性检验,实验组与对照组的差异,假阳性率(FDR)的计算等。
SNP的关联分析,建立线性模型或logistic回归模型等。
(所有的统计可以选择由SAS,SPSS,或S-Plus/R给出)项目二、Copy Number Variation(CNV)的计算。
CNV是目前的一个热点研究内容。
SNP芯片数据可以用于精确地计算CNV。
我们提供针对SNP芯片的基于CNAG(Copy Number Analyser for GeneChip), dChip(DNA-Chip Analyzer)和CNAT(Chromosome Copy Number Analysis Tool)等算法的CNV计算结果。
项目三、SNP注释通过SNP在染色体上的位置,利用寻找SNP可能影响的基因( or EST)。
我们也可以对相应基因进行功能的注释(gene ontology ,pathway和转录因子分析等),进而解释SNP可能的作用机理。
该部分可以参考常规表达谱芯片的分析。
项目四:基于模式识别的SNP挖掘传统的SNP挖掘使用统计学的方法来进行,往往在敏感性与特异性上有一定的限制。
利用一些模式识别/机器学习的方法可以更好解决SNP筛选问题。
我们提供基于决策树等SNP挖掘算法。
Hsiang-Yu Yuan et al. FASTSNP: an always up-to-date and extendable service for SNP function analysis and prioritization. Nucleic Acids Research 2006 34(Web Server issue):W635-W641项目五:诊断模型建立利用筛选到的SNP建立人工神经网络(ANN)、SVM、PAML等诊断模型,在临床上具有重要意义。
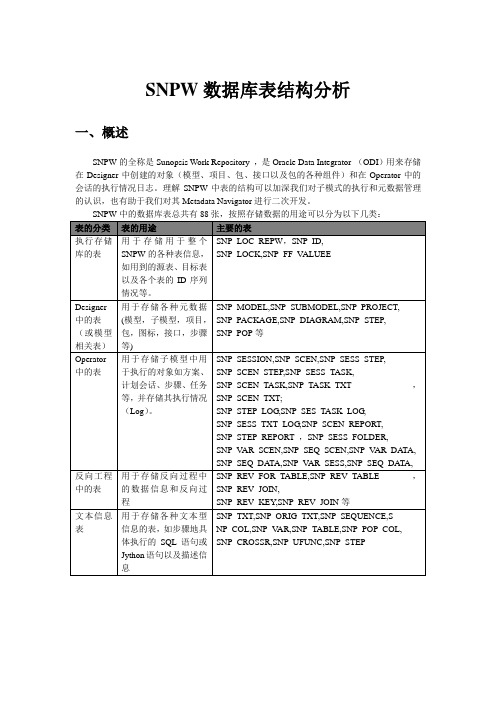
SNPW数据库表结构分析一、概述SNPW的全称是Sunopsis Work Repository ,是Oracle Data Integrator (ODI)用来存储在Designer中创建的对象(模型、项目、包、接口以及包的各种组件)和在Operator中的会话的执行情况日志。
理解SNPW中表的结构可以加深我们对子模式的执行和元数据管理的认识,也有助于我们对其Metadata Navigator进行二次开发。
二、Operator中的表1.表的分类对于我们监控平台来说,展示的绝大部分数据都来源于Operator相关表,我们可以对2.基本对象1)方案(Scenario):当包、接口、过程或变量等组件完成以后,它们会编译在一个方案之中,方案是可以按时间计划的执行的对象单元。
2)会话(Session):一个会话是一个由Agent来完成的一次执行(被执行的可以是方案、接口、包或过程等),一个会话由一些步骤(Step)组成,而每个步骤也可以由一些任务(task)组成。
3)步骤(Step):一个步骤是介于会话和任务之间的执行单元。
它对应了包或者方案之中的某一步骤。
当执行一个接口或者一个变量时,这个会话只包含一个会话步骤。
4)任务(task):任务是最小的执行单元。
它对应了KM中的过程命令,例如一个过程,变量的赋值等。
5)文本描述(TEXT):是对任务要做什么工作的详细描述,通常一个任务可以对应多条文本描述。
6)执行计划,把方案(Scenario)和充当计划执行器的Agent用时间表的形式关联起来。
3.表的简要描述4.表之间的关系图5.具体的表结构5.1 SNP_PLAN_AGENT5.2 SNP_SESSION5.3 SNP_SESS_STEP会话执行的步骤,如果会话信息被删除,其步骤信息也会被级联删除。
VD = 变量声明VS = 变量赋值VE = 变量求值VP = 变量组装V = 变量刷新OE = 执行OS命令SE = 执行ODI的命令F = 流(映射)T = 过程(一则)MR = 对模型反向工程MC = 模型检查J = 日记5.4 SNP_SESS_TASK5.5 SNP_TASK_TXT与会话任务相关的文本信息。
SNP分析原理方法及其应用SNP(Single Nucleotide Polymorphism,单核苷酸多态性)是指在基因组中的一些位置上,不同个体之间存在的碱基差异,是常见的遗传变异形式之一、SNP分析是研究SNP在基因与表型之间关联性的方法,用于揭示SNP与遗传疾病、药物反应性等的关系。
本文将介绍SNP分析的原理、方法以及其应用。
一、SNP分析原理1.SNP检测技术:SNP检测技术包括基于DNA芯片的方法、测序技术、实时荧光PCR等。
其中,高通量测序技术是最常用的SNP检测方法,可以同时检测数千个SNP位点。
2.数据分析与统计学方法:通过SNP检测技术获得的数据可以分为基因型数据(AA、AB、BB等)和等位基因频率数据(A频率、B频率等)。
统计学方法常用的有卡方检验、线性回归、逻辑回归等,用于研究SNP与表型之间的关联性。
二、SNP分析方法1.关联分析:关联分析是研究SNP与表型之间关联性的基本方法。
常用的关联分析方法包括单基因型分析、单SNP分析、基因组关联分析(GWAS)等。
单基因型分析主要是比较单个SNP的基因型在表型不同组之间的差异;单SNP分析是研究单个SNP是否与表型相关;GWAS是通过分析数万个SNP与表型之间的关系来找到与表型相关的SNP。
2. 基因型预测:基因型预测是根据已有的SNP数据,通过统计模型来预测个体的基因型。
常用的基因型预测方法有HapMap、PLINK等。
3. 功能注释:功能注释是研究SNP位点的生物学功能,揭示SNP与基因功能、表达水平之间的关系。
常用的功能注释工具有Ensembl、RegulomeDB等。
三、SNP分析应用1.遗传疾病研究:SNP与遗传疾病之间存在着密切的关系。
通过SNP分析可以发现与遗传疾病相关的SNP位点,进一步揭示疾病发生的机制,为疾病的诊断、治疗提供依据。
2.药物反应性研究:个体对药物的反应性往往存在较大差异,这与个体的遗传背景密切相关。
使用生物大数据技术进行SNP关联分析的方法与工具推荐随着生物学研究的不断发展,基因组学数据的积累和可用性不断增加。
其中,单核苷酸多态性(SNP)是一类广泛存在于基因组中的遗传变异,是研究复杂性疾病和个体差异的重要标记。
SNP关联分析是一种常用的研究方法,可以帮助我们识别与疾病发展或生物表型相关的SNP。
本文将介绍使用生物大数据技术进行SNP关联分析的方法和一些推荐的工具。
这些工具可以加快分析过程并提供丰富的数据可视化和解释。
一、SNP数据预处理进行SNP关联分析之前,首要任务是预处理SNP数据。
这包括数据清洗、格式转换、去除无关变异和处理缺失数据等步骤。
常用的SNP数据预处理工具包括PLINK、VCFtools和GATK等。
1. PLINK(Purcell et al., 2007)是一个功能强大的工具集,用于进行基因组关联分析。
它可以处理各种格式的SNP数据,包括PED/MAP、BED等,并提供了丰富的数据处理和统计分析功能。
2. VCFtools是一个专门用于VCF格式(Variant Call Format,常用于常见SNP格式)的SNP数据处理工具。
它可以用来过滤、格式转换、计算遗传群体统计信息等。
3. GATK(Genome Analysis Toolkit)是一个广泛使用的工具包,用于分析高通量测序数据。
它可以进行SNP/Indel检测、变异质量评估、基于家系或群体的SNP筛选等。
二、SNP关联分析SNP关联分析是通过比较个体的基因型和表型来寻找与表型相关的SNP。
这一步骤通常涉及人群结构分析、关联测试和多重比较校正等。
1. 人群结构分析可以帮助去除由于人群混合导致的伪关联。
常用的人群结构分析工具包括ADMIXTURE和STRUCTURE等。
这些工具可以将样本划分为亚群,并提供每个样本在亚群中的成分比例。
2. 关联测试是判断SNP与表型之间是否存在相关性的关键步骤。
一种常见的关联测试方法是单SNP关联分析,可以使用PLINK、SNPTEST或GEMMA等工具进行。
如何使用MySQL进行数据的多维分析和挖掘MySQL是一种常用的关系型数据库管理系统,其灵活性和功能强大使得它成为数据分析和挖掘的理想工具。
本文将介绍如何使用MySQL进行数据的多维分析和挖掘,并讨论相关的技术和方法。
一、数据的多维分析多维分析是指通过对多个变量进行分析和比较来揭示数据的复杂关系和规律。
在MySQL中,通过使用数据透视表(Pivot Table)和统计函数,可以进行多维分析。
下面将分别介绍这两个方法。
1. 数据透视表数据透视表是一种通过对数据进行旋转和聚合来实现多维分析的方法。
在MySQL中,可以使用PIVOT和UNPIVOT函数来实现数据透视表的功能。
首先,使用PIVOT函数将数据按照指定的字段进行旋转,然后使用统计函数对旋转后的数据进行聚合。
例如,可以通过以下语句将销售数据按照产品和地区进行透视:SELECT *FROM (SELECT Product, Region, SUM(Sales) AS TotalSalesFROM SalesTableGROUP BY Product, Region) AS PivotTablePIVOT (SUM(TotalSales) FOR Region IN ('North', 'South', 'East', 'West')) AS P;上述语句将销售数据按照产品和地区透视,并计算各地区的总销售额。
2. 统计函数MySQL提供了一系列的统计函数,可以对数据进行汇总和分析。
常用的统计函数包括SUM、AVG、COUNT、MAX和MIN等。
这些函数可以用于计算各个维度上的数据汇总和统计值,从而实现多维数据的分析。
例如,可以使用以下语句计算不同产品的平均销售额和总销售额:SELECT Product, AVG(Sales) AS AverageSales, SUM(Sales) AS TotalSalesFROM SalesTableGROUP BY Product;上述语句将按照产品对销售数据进行分组,并计算每个产品的平均销售额和总销售额。
SNP数据结果说明文档一、数据结果说明数据结果均在Data results文件夹中Raw data为原始数据1.结尾为samplesheet.xls文件为样本说明文件2.结尾为样本编号_FinalReport.txt的文件为每个样本的分型结果数据每列的含义:SNP_ID: SNP名称其余列为每个样本的分型数据3.结尾为Samples T able.txt的文件为每个样本的call Rate值情况数据每列的含义:Index: 数据编号Sample ID: 样本编号Call Rate: 样本的call Rate值Gender: 样本的性别p05 Grn: 百分之五分位数时A等位基因的强度p50Grn: 百分之五十分位数时A等位基因的强度p95 Grn: 百分之九十五分位数时A等位基因的强度p05 Red: 百分之五分位数时B等位基因的强度p50Red: 百分之五十分位数时B等位基因的强度p95 Red: 百分之九十五分位数时B等位基因的强度p10 GC: 此样本所有SNP 百分之十分位数的Gen Call scoreP50 GC: 此样本所有SNP百分之五十分位数的Gen Call score Rep Error Rate,PC Error Rate,PPC Error Rate,Subset结果并不给出所以略过.Aux: 用户自己设置的SNP辅助值Genotype for exm-IND11-102094357: exm-IND11-102094357的基因型Array Info.Sentrix ID: 芯片条形码IDArray Info.Sentrix Position: 样本在芯片上的位置4.DNAReport.csv 包含AA,AB 等位基因频率等5.Plink文件夹中是转化为plink格式的数据。
/doc/585616010.html,V 分析说明:此分析为收费项目用penncnv软件做CNV分析包括/doc/585616010.html,V,CNVR的区域、CN 值、所含SNP位点数、基因注释等。
SNPW数据库表结构分析
一、概述
SNPW的全称是Sunopsis Work Repository ,是Oracle Data Integrator (ODI)用来存储在Designer中创建的对象(模型、项目、包、接口以及包的各种组件)和在Operator中的会话的执行情况日志。
理解SNPW中表的结构可以加深我们对子模式的执行和元数据管理的认识,也有助于我们对其Metadata Navigator进行二次开发。
二、Operator中的表
1.表的分类
对于我们监控平台来说,展示的绝大部分数据都来源于Operator相关表,我们可以对
2.基本对象
1)方案(Scenario):当包、接口、过程或变量等组件完成以后,它们会编译在一个方案之
中,方案是可以按时间计划的执行的对象单元。
2)会话(Session):一个会话是一个由Agent来完成的一次执行(被执行的可以是方案、接
口、包或过程等),一个会话由一些步骤(Step)组成,而每个步骤也可以由一些任务(task)组成。
3)步骤(Step):一个步骤是介于会话和任务之间的执行单元。
它对应了包或者方案之中
的某一步骤。
当执行一个接口或者一个变量时,这个会话只包含一个会话步骤。
4)任务(task):任务是最小的执行单元。
它对应了KM中的过程命令,例如一个过程,变
量的赋值等。
5)文本描述(TEXT):是对任务要做什么工作的详细描述,通常一个任务可以对应多条
文本描述。
6)执行计划,把方案(Scenario)和充当计划执行器的Agent用时间表的形式关联起来。
3.表的简要描述
4.表之间的关系图
5.具体的表结构
5.1 SNP_PLAN_AGENT
5.2 SNP_SESSION
5.3 SNP_SESS_STEP
会话执行的步骤,如果会话信息被删除,其步骤信息也会被级联删除。
VD = 变量声明
VS = 变量赋值
VE = 变量求值
VP = 变量组装
V = 变量刷新
OE = 执行OS命令
SE = 执行ODI的命令
F = 流(映射)
T = 过程(一则)
MR = 对模型反向工程
MC = 模型检查
J = 日记
5.4 SNP_SESS_TASK
5.5 SNP_TASK_TXT
与会话任务相关的文本信息。
包括在任务被代理所解释执行前任务的代码。
5.6.SNP_STEP_LOG
会话的所有执行步骤历史,也可以在ODI的Operator中“所有执行”可以看到。
所有的步骤都可以在SNP_SESS_STEP表中看到,但是只有已经执行的步骤在SNP_SESS_STEP_LOG表可以看到。
5.7 SNP_SESS_TASK_LOG
任务执行相关的日志信息;
所有的任务都可以在SNP_SESS_TASK表中看到,但是只有已经执行的步骤在
5.8 SNP_SESS_TXT_LOG 与方案任务相关的文本字符串;
5.9 SNP_SCEN
5.10 SNP_SCEN_STEP
VD = 变量声明
VS = 变量赋值
VE = 变量求值
VP = 变量组装
V = 变量刷新
OE = 执行OS命令
SE = 执行ODI的命令
F = 流(映射)
T = 过程(一则)
MR = 对模型反向工程
MC = 模型检查
J = 日记
5.11 SNP_SCEN_TASK
方案(Scenario)步骤(Step)中的具体执行任务。
5.12 SNP_SCEN_TXT
5.13 SNP_SCEN_REPORT
5.14 SNP_STEP_REPORT
方案的所有步骤的执行历史,可以查看其开始时间,持续时间,返回代码,增删改查的记录数。
5. 15 SNP_EXP_TXT
用于存储执行过程中抛出的异常信息。
5.16 SNP_V AR_SCEN
方案中所用到的变量。
5.17 SNP_SEQ_SCEN
5.18 SNP_SESS_FOLDER
该文件夹用于组织基于关键字的会话,当装载方案时,一个会话的关键字被指定。
5.19 SNP_V AR_DATA
5.20 SNP_SEQ_DATA
5.21 SNP_V AR_SESS 会话中所用到的变量。
5.22 SNP_SEQ_SESS
三、Designer中的表
Designer中的表(或者叫与模型相关的表有)约有17张,我们只对其中核心的几张表的结构进行详细的分析。
1.基本对象
1)模型(Model):模型是一系列数据存储的集合,而每个数据存储都有物理模式(Phiscial
Schema)的数据结构与之对应。
2)数据存储(Datastore):数据存储用表结构描述数据,由行(Columns)组成。
数据存储
在ODI中被定义被关系模型。
3)项目(Project):项目是就是一组在ODI中开发出来对象的集合。
包、接口、变量、序
列、过程、知识模块等都是项目中的对象。
4)文件夹(Folder):以文件夹和子文件夹的形式来对项目中的对象进行组织和归类。
一个
项目可以有多个Folder。
5)包(Package):包是ODI对最大执行单元,一个包可以由一系列在执行图中组织过的
步骤组成。
6)步骤(Step):步骤按照类型可以被分为几类:接口、过程、变量、ODI工具、模型、
子模型和数据存储。
7)接口(Interface):一个接口由一系列规则组成,这些规则定义了数据存储的加载或者从
一个或多个源到一个临时目标的同步。
2.表的简要描述
3.表之间的关系图
4.具体的表结构
4.1 SNP_MODEL
模型和它们的属性,每个模型对应一行,一个物理模型包含数据库的数据存储(文件或者数据库表)定义信息,但不包含连接信息。
4.2 SNP_PROJECT
4.3 SNP_FOLDER
4.4 SNP_PACKAGE
项目中某个文件夹下的包。
4.5 SNP_STEP
用来描述package中的动作(action)及其顺序(有次序的动作在包中可以称之为步骤),包中所包含的序列化动作可以是:
1)执行一个接口(interface)
2)执行一个过程(procedure)
3)刷新一个变量
4)设置一个变量
5)求解一个变量
6)对模型进行反向工程
7)在模型中检查数据
8)执行一个OS命令
4.6 SNP_POP
接口(最常用的对象)。
4.7 SNP_TABLE
四、监控平台中的数据来源。