计量经济学分析报告
- 格式:ppt
- 大小:384.00 KB
- 文档页数:17

一、实训背景随着我国经济的快速发展,经济计量分析在各个领域得到了广泛应用。
为了提高我们的实际操作能力,我们参加了经济计量分析实训。
本次实训旨在通过实际操作,使我们掌握经济计量分析的基本原理、方法及其应用,提高我们的数据分析能力。
二、实训内容1. 实训目标(1)掌握经济计量分析的基本原理和方法;(2)熟练运用计量经济学软件进行数据分析和建模;(3)提高对经济现象的观察、分析和解决问题的能力。
2. 实训内容(1)经济计量分析基本原理:介绍了经济计量分析的定义、发展历程、基本方法等;(2)计量经济学软件操作:讲解了EViews、Stata等软件的基本操作,包括数据导入、描述性统计、回归分析等;(3)实证分析:以我国某一行业为例,运用计量经济学方法对其经济现象进行实证分析,包括模型设定、数据收集、参数估计、模型检验等。
三、实训过程1. 数据收集(1)收集相关行业数据,包括行业产值、就业人数、固定资产等;(2)收集宏观经济数据,如GDP、通货膨胀率等;(3)收集行业政策、市场需求等定性数据。
2. 模型设定根据收集到的数据,结合经济学理论,设定计量经济学模型。
以行业产值为例,我们可以设定以下模型:Y = β0 + β1X1 + β2X2 + ε其中,Y表示行业产值,X1、X2为影响行业产值的关键因素,β0、β1、β2为模型参数,ε为误差项。
3. 参数估计运用计量经济学软件对模型进行参数估计,得到β0、β1、β2的估计值。
4. 模型检验对估计得到的模型进行检验,包括残差分析、t检验、F检验等。
5. 结果分析根据模型检验结果,对行业产值的影响因素进行分析,得出结论。
四、实训收获1. 理论知识得到巩固通过本次实训,我们对经济计量分析的基本原理、方法有了更深入的理解,为今后的学习和研究奠定了基础。
2. 实际操作能力提高掌握了计量经济学软件的操作方法,能够熟练运用计量经济学方法进行数据分析和建模。
3. 分析和解决问题的能力得到提升在实训过程中,我们面对实际问题,运用所学知识进行分析和解决,提高了我们的分析和解决问题的能力。

第1篇一、实验目的本次实验旨在通过多元线性回归模型,分析多个自变量与因变量之间的关系,掌握多元线性回归模型的基本原理、建模方法、参数估计以及模型检验等技能,提高运用计量经济学方法解决实际问题的能力。
二、实验背景随着经济的发展和社会的进步,影响一个变量的因素越来越多。
在经济学、管理学等领域,多元线性回归模型被广泛应用于分析多个变量之间的关系。
本实验以某地区居民消费支出为例,探讨影响居民消费支出的因素。
三、实验数据本实验数据来源于某地区统计局,包括以下变量:1. 消费支出(Y):表示居民年消费支出,单位为元;2. 家庭收入(X1):表示居民家庭年收入,单位为元;3. 房产价值(X2):表示居民家庭房产价值,单位为万元;4. 教育水平(X3):表示居民受教育程度,分为小学、初中、高中、大专及以上四个等级;5. 通货膨胀率(X4):表示居民消费价格指数,单位为百分比。
四、实验步骤1. 数据预处理:对数据进行清洗、缺失值处理和异常值处理,确保数据质量。
2. 模型设定:根据理论知识和实际情况,建立多元线性回归模型:Y = β0 + β1X1 + β2X2 + β3X3 + β4X4 + ε其中,Y为因变量,X1、X2、X3、X4为自变量,β0为截距项,β1、β2、β3、β4为回归系数,ε为误差项。
3. 模型估计:利用统计软件(如SPSS、R等)对模型进行参数估计,得到回归系数的估计值。
4. 模型检验:对估计得到的模型进行检验,包括以下内容:(1)拟合优度检验:通过计算R²、F统计量等指标,判断模型的整体拟合效果;(2)t检验:对回归系数进行显著性检验,判断各变量对因变量的影响是否显著;(3)方差膨胀因子(VIF)检验:检验模型是否存在多重共线性问题。
5. 结果分析:根据模型检验结果,分析各变量对因变量的影响程度和显著性,得出结论。
五、实验结果与分析1. 拟合优度检验:根据计算结果,R²为0.812,F统计量为30.456,P值为0.000,说明模型整体拟合效果较好。

计量经济学实验报告(一)
一、实验背景
计量经济学实验是一种采用经济理论和方法来设计实验的经济研究方法。
经济实验的主要目的是检验经济理论,比如检验假设和改进预测。
它还可以用于定性评价和定量评价政策方案和市场动态,以及验证行为经济学理论。
二、实验内容
本次实验通过一组独立的在线调查来研究人们对收入分配政策的态度。
调查中,受访者被要求就14种不同的收入分配政策支持、反对和中立做出反应。
这14种收入分配政策包括财政公平政策、税收和补贴政策、劳动力市场政策和参与机会政策等。
以及根据态度的强度来改变互动形式,不同类型的回答有不同的加分,比如更强烈的支持会比中立的有更多分数。
三、实验结果
实验结果显示,在14种收入分配政策中,受访者大部分表示支持或者反对。
最受支持的是劳动力市场政策,而最受反对的是税收和补贴政策。
同时,实验还发现,这14种收入分配政策受实验者支持或反对的原因大部分是经济实惠:如果一个政策能够为普通大众带来经济实惠,这个政策很可能受到受访者的支持。
此外,一些政策因其有助于实现平等收入而受到支持。
四、实验结论
本次实验结论清楚地表明,受访者支持或反对收入分配政策跟经济实惠有关。
当人们普遍受益于收入分配政策时,他们很可能支持这种政策。
另外,实验还发现,有些政策受支持的原因还在于它们有助于实现平等收入的目的。
本次实验不仅对计量经济学的理论和方法提供了有价值的信息,而且还为构建经济实证提供了重要的参考意见。
可以认为,经过本次实验的进一步检验和优化,可以发现更详细、更准确的数据,以便进一步检验和发展计量经济学的理论与方法。
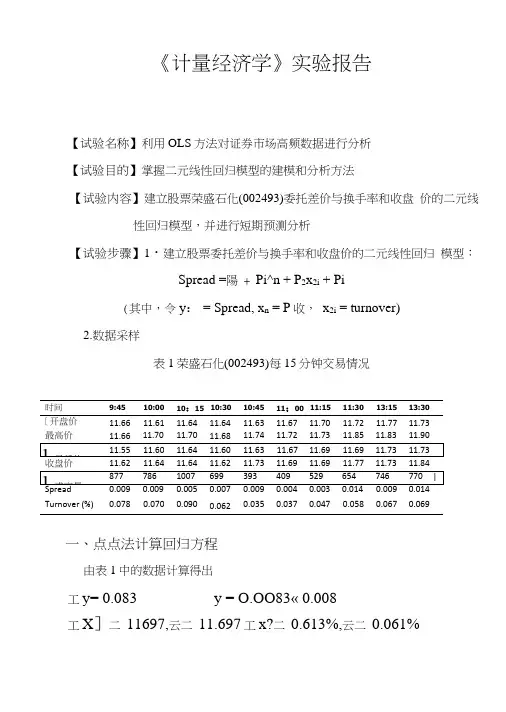
《计量经济学》实验报告【试验名称】利用OLS方法对证券市场高频数据进行分析【试验目的】掌握二元线性回归模型的建模和分析方法【试验内容】建立股票荣盛石化(002493)委托差价与换手率和收盘价的二元线性回归模型,并进行短期预测分析【试验步骤】1・建立股票委托差价与换手率和收盘价的二元线性回归模型:Spread =陽 + Pi^n + P2x2i + Pi(其中,令y: = Spread, x n = P收,x2i = turnover)2.数据采样表1荣盛石化(002493)每15分钟交易情况一、点点法计算回归方程由表1中的数据计算得出工y= 0.083 y = O.OO83« 0.008工X]二11697,云二11.697工x?二0.613%,云二0.061%(1) 编制工作表■ yx 2(%)• *> y_• • x :yX1X 2 0.001 -0.077 0.017 O.lxlO"55.9xl0~32 9x10"® 一7 7x10* 1.7x10“ -1.3xl0-5 0.001 -0.057 0.009 lxlO -6 3.2 xlO -38.1X10-9 -5.7xl0T9.0 xlO -8 -5.1x10^ 0003 -0.057 0.029 9x10^3.2x10^ 84x1 (T 81.7X1CT 4-8.7x10“ -1.7xlO -5 -0.001 -0.077 0.001 1x10"5.9x10-3lxlO -107.7 xlO -5 -l.OxlO -8 -7.7xl0? 0.001 0.033-0.026 lxlO -61.1x10-36 8x10"®3.3 xlO -5 -2.6x1 O'7 -8.6x1 OY ・0.004 -0.007 -0.024 1.6 xlO" 4.9 xlO -3 5.8X10-82.8x29.6x10-7 1.7x10“ -0.005 -0.007 -0.014 2.5 xlO -5 4.9 xlO -32.0 xW 83.5x10-5 7.0x10-7 9.8x10-7 | 0.006 0.073 •0.003 3 6x10*5.3x10—3 9xlO -10 4.4x107-1.8x10—7 -2.2x10“ 0.001 0.0330.006 lxlO^51.1 X 1 0"3 3.6 xlO -93 3x10*6X10-8 2.0 xlO -6 0.006 0.1430.0083.6 xlO"50.026 4x10"86x10*4.8 xlO"7l.lxlO"5(2) Ik 算统计量(3) 计算久、Dj 、D 2(4) 得出参数估计值A = —= 3.5xl0'3 Doa-y-\ • 0i — x? • 0? = -0.405综上所得,回归方程为:X =0.035x h +4.3x 21-0.405二、模型分析 (1)经济意义检验模型估计的结果说明,在假定其他变量不变的情况下,当收盘 价每增长1s ^=Ey2= 127x10-4S R =工£ =3.68x10“Sy?=工禺 y = 114x10"% =工衬=4.58xl0"2=x^y =L54x10'3 $2 =工若禺=-1.26xl0-5D.=S H %= 1.66x10“= 7.16xl0"s= 5.8xlO"10S“■ ■% S"元,委托差价(Spread)就会增长0.035元;在假定其他变量不变的情况下,当换手率(turnover)增长1个百分点时,委托差价(Spread)就会增长4.3元。

计量经济学分析报告论文题目:浙江城镇居民精神文化支出分析学院名称:经济与管理学院专业:国际经济与贸易班级:国贸101姓名:王璐璐学号*********** ***师:***【摘要】我国经济的腾跃带动了城镇居民精神文化支出的高速发展。
本文旨在根据我省城镇居民精神文化支出的相关经济数据,分析得出影响我省城镇居民精神消费的部分要素,从而对于浙江省城镇居民精神消费做出科学的判断。
【关键词】精神消费城镇居民多重共线性异方差自相关1 模型的选取和变量的选择1.1变量选取国内生产总值(x1):国内生产总值是衡量社会经济发展的指标,通过国内生产总值可以衡量浙江省城镇居民精神消费的力度。
浙江省城镇居民消费水平(x2):研究城镇居民的精神消费,与之相关的是城镇居民的消费水平,消费水平可以衡量城镇居民的消费能力与经济水平,通过它的研究可以更好的比较精神消费与消费水平的关系,防止过度消费现象的出现。
浙江省城镇居民家庭人均可支配收入(x3):指城镇居民家庭人均可用于最终消费支出和其它非义务性支出以及储蓄的总和,即居民家庭可以用来自由支配的收入。
它是家庭总收入扣除交纳的所得税、个人交纳的社会保障费以及调查户的记账补贴后的收入。
1.2样本数据采集根据我们对影响我省城镇居民精神消费的因素分析,以及解决我们提出的问题的需要,初步选取了以下三个解释变量:国内生产总值、浙江省城镇居民消费水平、浙江省城镇居民家庭人均可支配收入。
以下搜集了1994年-2009年最近15年的统计数据。
时间Y浙江省城镇居民旅游业消费X1国内生产总值X2浙江省城镇居民消费水平X3浙江省城镇居民家庭人均可支配收入1994 414.67 48197.8564447092 3852 3496.2 1995 464.02 60793.7292113314 4931 4283 1996 534.1 71176.5916539871 5532 4838.9 1997 599.8 78973.0349964915 5823 5160.3 1998 607 84402.27976892201 6109 5425.1 1999 614.78 89677.0547509045 6405 5854.02 2000 678.6 99214.55430847721 6850 6280 2001 708.3 109655.170558159 7161 6859.6 2002 739.7 120332.689274252 7486 7702.8 2003 684.9 135822.756149557 8060 8472.2 2004 731.8 159878.33791739 8912 9421.6 2005 737.1 184937.36896018 9644 10493 2006 766.4 216314.425939354 10682 11759.5 2007 906.90 265810.30584365 12211 13785.82008 849.36 314045.427086554 13845 15780.76 2009801.1340506.8673138651502517174.651.3模型及处理1.3.1建立模型根据以上各变量的设置,初步建立以下模型:Yi=c(1)+c(2)x1+c(3)x2+c(4)x3+u其中,Yi 代表浙江省城镇居民精神支出人均花费,x1代表国内生产总值,x2代表浙江省城镇居民消费水平,x3代表浙江省城镇居民家庭人均可支配收入。

篇一:计量经济学实验报告 (1)计量经济学实验基于eviews的中国能源消费影响因素分析学院:班级:学号:姓名:基于e views的中国能源消费影响因素分析一、背景资料能源消费是指生产和生活所消耗的能源。
能源消费按人平均的占有量是衡量一个国家经济发展和人民生活水平的重要标志。
能源是支持经济增长的重要物质基础和生产要素。
能源消费量的不断增长,是现代化建设的重要条件。
我国能源工业的迅速发展和改革开放政策的实施,促使能源产品特别是石油作为一种国际性的特殊商品进入世界能源市场。
随着国民经济的发展和人口的增长,我国能源的供需矛盾日益紧张。
同时,煤炭、石油等常规能源的大量使用和核能的发展,又会造成环境的污染和生态平衡的破坏。
可以看出,它不仅是一个重大的技术、经济问题,而且以成为一个严重的政治问题。
在20世纪的最后二十年里,中国国内生产总值(gdp)翻了两番,但是能源消费仅翻了一番,平均的能源消费弹性仅为0.5左右。
然而自2002年进入新一轮的高速增长周期后,中国能源强度却不断上升,经济发展开始频频受到能源瓶颈问题的困扰。
鉴于此,研究能源问题不仅具有必要性和紧迫性,更具有很大的现实意义。
由于我国目前面临的所谓“能源危机”,主要是由于需求过大引起的,而我国作为世界上最大的发展中国家,人口众多,所需能源不可能完全依赖进口,所以,研究能源的需求显得更加重要。
二、影响因素设定根据西方经济学消费需求理论可知,影响消费需求的因素有:商品的价格、消费者收入水平、相关商品的价格、商品供给、消费者偏好以及消费者对商品价格的预期等。
对于相关商品价格的替代效应,我们认为其只存在能源品种内部之间,而消费者偏好及消费者对商品价格的预期数据差别较大,不容易进行搜集整理在此暂不涉及。
另外,发展经济学认为,来自知识、人力资本的积累水平所体现的技术进步不仅可以带动劳动产出的增长,而且会通过外部效应可以提高劳动力、自然资源、物质资本与生产要素的生产效率,消除其中收益递减的内在联系,带来递增的规模收益。

摘要:本文利用我国1985年以来的统计数字建立了可以通过各种检验的居民消费价格的模型,对我国居民消费价格指数进行实证分析。
通过对该模型的经济含义分析得出各主要因素对我国居民消费价格指数的影响程度,并针对现状提出自己的一些建议。
关键词:居民消费价格指数城镇居民农村居民一、引言CPI是英文“Consumer Price Index”的缩写,直译为“消费者价格指数”,在我国通常被称为“居民消费价格指数”。
CPI的定义决定了其所包含的统计内容,那就是居民日常消费的全部商品和服务项目。
日常生活中,我国城乡居民消费的商品和服务项目种类繁多,小到针头线脑,大到彩电汽车,有数百万种之多,由于人力和财力的限制,不可能也没有必要采用普查方式调查全部商品和服务项目的价格,世界各国都采用抽样调查方法进行调查。
作为学经济的本科阶段的学生,我们所理解的并不彻底,我们所能涉及的范围也很小,所以借由国家统计数据做以下分析,促使我们更好的掌握专业知识,了解国情,提高我们实际操作水平和理论联系实际、发现问题、分析问题、解决问题的能力。
二、影响因素的分析居民消费价格指数是反映一定时期内居民消费价格变动趋势和变动程度的相对数。
居民消费价格指数分为食品、衣着、家庭设备及用品、医疗保健、交通和通讯、娱乐教育和文化用品、居住、服务项目等八个大类。
国家规定325种必报商品和服务项目,其中,一般商品273种,餐饮业食品16种,服务项目36种。
该指数是综合了城市居民消费价格指数和农民消费价格指数计算取得。
利用居民消费价格指数,可以观察和分析消费品的零售价格和服务人格变动对城乡居民实际生活费支出的影响程度。
下面主要介绍一下城镇居民消费价格指数、农村居民消费价格指数、城镇居民人均消费价格支出、农村居民人均消费支出的影响:1、城镇居民消费价格指数(y1)2、农村居民消费价格指数(y2)3、城镇居民人均消费支出(x1)4、农村居民人均消费支出(x2)5、其他因素(用随机变量u来处理)三、模型:1、本文模型数据样本从1985—2006年:Y居民消费价格指数Y1城镇居民消费价格指数Y2农村居民消费价格指数X1 城镇居民人均消费支出X2农村居民人均消费支出年份1985 109.3 111.9 107.6 765 3491986 106.5 107 106.1 872 3781987 107.3 108.8 106.2 998 421 1988 118.8 120.7 117.5 1311 509 1989 118 116.3 119.3 1466 549 1990 103.1 101.3 104.5 1596 560 1991 103.4 105.1 102.3 1840 602 1992 106.4 108.6 104.7 2262 688 1993 114.7 116.1 113.7 2924 805 1994 124.1 125 123.4 3852 1038 1995 117.1 116.8 117.5 4931 1313 1996 108.3 108.8 107.9 5532 1626 1997 102.8 103.1 102.5 5823 1722 1998 99.2 99.4 99 6109 1730 1999 98.6 98.7 98.5 6405 1766 2000 100.4 100.8 99.9 6850 1860 2001 100.7 100.7 100.8 7113 1969 2002 99.2 99 99.6 7387 2062 2003 101.2 100.9 101.6 7901 2103 2004 103.9 103.3 104.8 8679 2301 2005 101.8 101.6 102.2 9410 2560 2006 101.5 101.5 101.5 10359 28482、基于以上数据,建立一下模型:Y=β1+β2y1+β3y2+β4x1+β5x2+u ①检验各变量是否为y的格兰杰原因Y y1Pairwise Granger Causality Tests Date: 12/22/10 Time: 12:13 Sample: 1985 2006Lags: 2Null Hypothesis: Obs F-Statistic Prob.Y1 does not Granger Cause Y 20 4.56120 0.0283 Y does not Granger Cause Y1 3.37364 0.0617 P=0.0283<0.05 显著,y1是y的格兰杰原因Y y2Pairwise Granger Causality TestsDate: 12/22/10 Time: 12:13Sample: 1985 2006Lags: 2Null Hypothesis: Obs F-Statistic Prob.Y2 does not Granger Cause Y 20 3.86484 0.0443 Y does not Granger Cause Y2 5.07054 0.0208 P=0.0443<0.05 显著,y2是y的格兰杰原因Y x1Pairwise Granger Causality TestsDate: 12/22/10 Time: 12:13Sample: 1985 2006Lags: 2Null Hypothesis: Obs F-Statistic Prob.X1 does not Granger Cause Y 20 11.1781 0.0011 Y does not Granger Cause X1 2.80821 0.0921 P=0.0011<0.05 显著,x1是y的格兰杰原因Y x2Pairwise Granger Causality TestsDate: 12/22/10 Time: 12:13Sample: 1985 2006Lags: 2Null Hypothesis: Obs F-Statistic Prob.X2 does not Granger Cause Y 20 7.78739 0.0048Y does not Granger Cause X2 1.28602 0.3052P=0.0048<0.05 显著,x2是y的格兰杰原因经过格兰杰检验,4个解释变量均为y的格兰杰原因,可以作为解释变量②普通最小二乘法Dependent Variable: YMethod: Least SquaresDate: 12/22/10 Time: 12:25Sample: 1985 2006Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C -0.039682 0.405396 -0.097885 0.9232Y10.432584 0.010802 40.04835 0.0000 Y20.567086 0.010740 52.80087 0.0000 X1-9.56E-05 0.000104 -0.915566 0.3727X20.000357 0.000414 0.863621 0.3998R-squared 0.999884 Mean dependentvar 106.650AdjustedR-squared 0.999856 S.D. dependentvar 7.370388S.E. of regression 0.088378 Akaike infocriterion -1.817677Sum squaredresid 0.132781 Schwarz criterion -1.569713Log likelihood 24.99445 Hannan-Quinncriter. -1.759264F-statistic 36509.31 Durbin-Watsonstat 1.420561Prob(F-statistic) 0.000000由以上分析,初步建立模型为:Y=-0.039682+0.432584*y1+0.567086*y2-9.56*x1+0.000357 *x2R2的拟合程度为0.999884 F=36509.31③异方差的检验Ⅰ、white检验Heteroskedasticity Test: WhiteF-statistic 0.527426 Prob. F(14,7) 0.8540Obs*R-squared 11.29363 Prob.Chi-Square(14) 0.6628Scaled explainedSS 6.684989 Prob.Chi-Square(14) 0.9462Test Equation:Dependent Variable: RESID^2Method: Least Squares Date: 12/22/10 Time: 12:30 Sample: 1985 2006 Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C -0.793516 1.975576 -0.401663 0.6999Y1 0.010665 0.024387 0.437300 0.6751 Y1^2 0.000950 0.000831 1.144012 0.2902Y1*Y2 -0.001960 0.001686 -1.162006 0.2833Y1*X1 9.39E-06 1.67E-05 0.562184 0.5915Y1*X2 -3.22E-05 6.65E-05 -0.484229 0.6430Y2 -0.000172 0.035384 -0.004857 0.9963Y2^2 0.000972 0.000852 1.141293 0.2913Y2*X1 -4.95E-06 1.69E-05 -0.293341 0.7778Y2*X2 1.47E-05 6.91E-05 0.212909 0.8375X1 -0.000629 0.000692 -0.909063 0.3935X1^2 -4.47E-09 1.25E-07 -0.035782 0.9725X1*X2 1.39E-07 9.85E-07 0.141053 0.8918 X2 0.002533 0.002839 0.892048 0.4020X2^2 -4.71E-07 1.95E-06 -0.240981 0.8165R-squared 0.513347 Mean dependentvar 0.006035Adjusted R-squared -0.459959S.D. dependentvar 0.008698S.E. of regression 0.010510 Akaike infocriterion -6.054459 Sum squaredresid 0.000773 Schwarz criterion -5.310566Log likelihood 81.59905 Hannan-Quinncriter. -5.879220F-statistic 0.527426 Durbin-Watsonstat 3.341695Prob(F-statistic) 0.853973由于Obs*R-squared=11.29363>卡方0.05(5)=11.07,所以存在异方差,用加权最小二乘法消除异方差Ⅱ、加权最小二乘法消除异方差Dependent Variable: YMethod: Least SquaresDate: 12/22/10 Time: 12:37Sample: 1985 2006Included observations: 22Weighting series: WWeight type: Inverse standard deviation (EViews default scaling)Variable Coefficient Std. Error t-Statistic Prob.C -0.131244 0.136038 -0.964757 0.3482Y1 0.429947 0.002008 214.1169 0.0000 Y2 0.570375 0.002160 264.0622 0.0000X1 -0.000137 3.91E-05 -3.499721 0.0027X2 0.000517 0.000157 3.296181 0.0043 Weighted StatisticsR-squared 0.999989 Mean dependentvar 106.6536AdjustedR-squared 0.999986 S.D. dependentvar 129.1117S.E. of regression 0.027333 Akaike infocriterion -4.164758 Sum squaredresid 0.012700 Schwarz criterion -3.916794Log likelihood 50.81234 Hannan-Quinncriter. -4.106345F-statistic 384834.4 Durbin-Watsonstat 0.860182Prob(F-statistic) 0.000000 Weighted meandep. 106.0005 UnweightedStatisticsR-squared 0.999882 Mean dependentvar 106.6500AdjustedR-squared 0.999854 S.D. dependentvar 7.370388 S.E. of regression 0.089116 Sum squared resid 0.135010Durbin-Watsonstat 1.385850分析各变量是否存在相关性,并予以消除从上表(加权最小二乘法)的统计结果中可知,DW=0.860182 查表得DL=0.96 DU=1.80 0<DW<DL,所以,存在一介正自相关差分—消除Dependent Variable: DYMethod: Least SquaresDate: 12/22/10 Time: 12:50Sample (adjusted): 1986 2006Included observations: 21 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.C 0.004360 0.045369 0.096098 0.9246 DY10.425938 0.010577 40.27064 0.0000 DY20.572954 0.011062 51.79573 0.0000DX1-9.20E-05 0.000170 -0.540527 0.5963DX20.000367 0.000500 0.733528 0.4738 R-squared 0.999746 Mean dependent var -0.371429AdjustedR-squared 0.999683 S.D. dependent var 5.992507 S.E. of regression 0.106754 Akaike info criterion -1.432327 Sum squaredresid 0.182342 Schwarz criterion -1.183631 Log likelihood 20.03943 Hannan-Quinn criter. -1.378354F-statistic 15751.09 Durbin-Watson stat 2.05844 Prob(F-statistic) 0.000000由上表的统计结果可知:DW=2.05844,查表得DL=0.93 DU=1.81,DU<DW<4-DU,所以解释变量之间无自相关从上表中看得出:dx1的T统计结果是-0.540527,其绝对值小于T0.025(16)=2.120,且其系数符号与预期相反,这表明可能存在严重的多重共线性。

计量经济学》实验报告一、经济学理论概述1、需求是指消费者(家庭)在某一特定时期内,在每一价格水平时愿意而且能够购买的某种商品量。
需求是购买欲望与购买能力的统一。
2、需求定理是说明商品本身价格与其需求量之间关系的理论。
其基本内容是:在其他条件不变的情况下,一种商品的需求量与其本身价格之间成反方向变动,即需求量随着商品本身价格的上升而减少,随商品本身价格的下降而增加。
3、需求量的变动是指其他条件不变的情况下,商品本身价格变动所引起的需求量的变动。
需求量的变动表现为同一条需求曲线上的移动。
二、经济学理论的验证方法在此次试验中,我运用了Eviews和Excel软件对相关数据进行处理和分析。
1、拟合优度检验——可决系数R2统计量回归平方和反应了总离差平方和中可由样本回归线解释的部分,它越大,参差平方和越小,表明样本回归线与样本观测值的拟合程度越高。
2、方程总体线性的显着性检验——F检验(1)方程总体线性的显着性检验,旨在对模型中被解释变量与解释变量之间的线性关系在总体上是否显着成立作出判断。
(2)给定显着性水平α,查表得到临界值Fα(k,n-k-1),根据样本求出F统计量的数值后,可通过F>Fα(k,n-k-1) (或F ≤Fα(k,n-k-1))来拒绝(或接受)原假设H0,以判定原方程总体上的线性关系是否显着成立。
3、变量的显着性检验——t检验4、异方差性的检验——怀特检验怀特检验不需要排序,对任何形式的异方差都适用。
5、序列相关性的检验——图示法和回归检验法6、多重共线性的检验——逐步回归法以Y为被解释变量,逐个引入解释变量,构成回归模型,进行模型估计。
三、验证步骤1、确定变量(1)被解释变量“货币流通量”在模型中用“Y”表示。
(2)解释变量①“货币贷款额”在模型中用“X”表示;1②“居民消费价格指数”在模型中用“2X ”表示;③把由于各种原因未考虑到和无法度量的因素归入随机误差项,在模型中用“μ”。

计量经济学实验报告
标题:基于地区人民收入与犯罪率的实证分析
摘要:
本实验报告旨在使用计量经济学方法对地区的人民收入与犯罪率之间的关系进行实证分析。
通过收集该地区多年的相关数据,并建立合适的计量模型,我们得出了以下结论:在控制其他因素的情况下,人民收入对犯罪率具有显著的负向影响。
这一研究结果对相关当局在制定犯罪预防政策时具有重要的指导意义。
1.引言
犯罪问题一直是社会关注的焦点。
了解犯罪率的影响因素对改善社会治安具有重要的意义。
本实验以地区为例,通过实证分析人民收入对犯罪率的影响,希望为相关当局提供制定犯罪预防政策的参考。

【精品】《计量经济学》实验报告
一、实验目的
通过本实验,了解计量经济学的基本概念,认识计量经济学的应用,以及如何利用统计软件STATA进行计量经济学的研究。
二、实验内容
本次实验利用国外一项有关家庭经济收支的调查资料,分析收入与消费的关系,研究对收入的影响因素。
三、实验方法
(1)调查资料:国外家庭收支资料是由100个家庭的收支情况数据组成,其中包括这100个家庭的收入、消费、家庭编号、家庭购买力等。
(2)计量模型:在该实验中,建立二元线性回归模型:
(3)计量经济学的应用:利用STATA软件进行实证分析,以估计该家庭收入与消费的关系,并进一步研究影响收入的因素。
四、实验结果
(1)估计结果:家庭收入与消费的估计结果如下:
模型结果:Y=0.697+2.154X
线性拟合结果:R2=0.811,p=0.000
(2)影响收入的因素:利用STATA软件回归分析发现,家庭购买力、家庭编号等因素影响家庭收入。
五、实验结论
通过本次实验,我们可以得出以下结论:
(1)计量经济学是一种有效的用来研究家庭收入与消费关系的方法。
(2)家庭收入与消费显著正相关,即家庭收入越高,消费也越高。
(3)家庭购买力以及家庭编号等因素对家庭收入有显著影响。

计量经济学实践报告-影响我国汽车销售价格因素的分析1. 引言本文旨在对我国汽车销售价格的影响因素进行分析。
通过计量经济学的实践方法,我们将探讨汽车销售价格与各种经济要素之间的关系,以及这些因素对汽车价格的影响程度。
2. 数据和方法我们收集并分析了与汽车销售价格相关的数据,包括汽车型号、销售地区、生产成本、市场需求等信息。
使用多元线性回归模型,我们对这些数据进行了统计分析,并得出了一些初步结论。
3. 结果与讨论在我们的分析中,发现以下因素可能对我国汽车销售价格产生影响:3.1 型号与品牌不同汽车型号和品牌之间的销售价格存在差异。
一般来说,高端品牌和豪华型号的汽车销售价格较高,而经济型车辆则价格较低。
3.2 地区差异不同地区的汽车销售价格也存在差异。
一些发达地区的销售价格可能更高,而一些经济欠发达地区的销售价格较低。
这可能与当地经济发展水平、人口密度等因素有关。
3.3 生产成本和利润率汽车的生产成本和企业的利润率也会影响销售价格。
较高的生产成本和利润率可能会导致汽车销售价格上涨。
3.4 市场需求汽车市场需求的变化也会对销售价格产生影响。
当市场需求较高时,汽车销售价格可能会上涨;而市场需求不足时,销售价格可能会下降。
4. 结论通过计量经济学的实践分析,我们得出以下结论:我国汽车销售价格受多种因素影响,包括汽车型号和品牌、地区差异、生产成本和利润率以及市场需求。
在制定汽车销售策略和制定价格策略时,企业需要考虑这些因素的影响。
此外,政府也可以通过调整相关政策来引导汽车市场的稳定和健康发展。
参考文献[1] 作者1. (年份). 文章标题. 期刊名称, 卷号(期号), 页码范围.[2] 作者2. (年份). 文章标题. 期刊名称, 卷号(期号), 页码范围.。
计量经济学、统计案例分析报告RStudio J I A N G S U U N I V E R S I T Y统计调查与案例分析报告——能源消费的影响因素分析学院: 财经学院班级: 统计1001姓名: ZYM学号: 31008120…指导老师: ………2013年 1 月 8 日能源消费的影响因素调查分析报告内容摘要对于经济高速发展的发展中国家而言,能源就是国家的命脉。
随着国民经济的发展,能源供需矛盾日益尖锐,能源问题逐步成为国家间竞争和冲突的重要根源。
总而言之,研究能源消费问题是迫切和必要的。
关键词:能源消费能源生产计量经济学模型能源战略一、研究背景介绍及研究目的但是,我国人口众多,人均能源占有量不及同期发达国我国是一个能源大国,家的1/5。
能源是任何一个国家经济发展不可缺失的物质基础。
随着我国人口的继续增长,经济的快速发展,能源消费量的增加是必然的,而与年俱增的能源消费对环境造成的破坏也越来越严重。
因此,怎样优化能源利用结构,开发利用清洁能源,就成为我国经济发展的当务之急。
这就需要我们清楚了解能源供需形势,做好影响能源消费因素分析,为能源规划及政策的制定提供科学依据,保证我国国民经济又好又快地发展。
二、数据来源和相关说明根据西方经济学消费需求理论,影响消费需求的因素有:商品的价格、消费者收入水平、相关商品的价格、商品供给。
消费者偏好以及消费者对商品价格的预期等。
另外,发展经济学认为,来自知识,人力资本的积累水平所体现的技术进步不仅可以带动劳动产出的增长,而且会通过外部效应可以提高劳动力、自然资源、物质资本与生产要素的生产效率,消除其中收益递减的内在联系,带来递增的规模效应。
由于目前没有比较科学的资本价格数据,所以这里我们引入能源消费总量、能源生产总量、全国生活能源消费总量、城镇居民可支配收入、工业能源消费总量五个变量对影响能源消费的因素进行分析。
1、能源消费总量,在模型中用Y来表示。
是指一次性能源消费总量,由煤炭、石油、天然气等组成(单位:万吨标准煤)。
粮食产量的影响因素分析一、问题的提出改革开放以来,中国经济迅速发展,人口增长迅猛,对粮食的需求日益增加。
粮食产量无疑成了影响中国经济发展的重大因素。
同时,粮食的产量直接关系到农业劳动力的生活水平,因此,“三农”问题成为中国经济研究的热点问题,提高粮食产量,关注农村居民收入迫在眉睫。
为此,本文将就粮食产量影响因素进行分析,希望从中发现一些对粮食产量关键作用的因素。
二.研究方案与数据的搜集统计通过对影响粮食产量的主要因素的分析,把影响农民收入的因素主要归结与以下几个方面:农业化肥施用量,粮食播种面积,成灾面积,农业机械总动力,农业劳动力。
通过查找中国统计年鉴,我们得到如下的统计资料:注:这里由于没有从事粮食生产的农业劳动数据,用第一产业劳动力替代。
资料来源:《中国统计年鉴》(1985,2009)三、模型的估计、检验、确认对模型有如下假设:1.零均值: 0)(=i u E n i ,,3,2,1 =2.同方差无自相关:3.随机扰动项与解释变量不相关:0),(=i ji u X Cov k j ,,3,2 =4.无多重共线性5. 残差的正态性:显然这些假设是不可能完全成立的,所以必须对其进行检验。
残差的正态性检验已完成。
主要需要检验的有:一、多重共线性检验。
二、异方差性检验。
三、自相关性检验。
由于现有知识有限,只能对检验出来的一种情况进行修正,其它的暂不做修正,只做检验。
我们将基于以上数据进行分析。
(1)利用Eviews5.0作OLS 估计的结果为:Dependent Variable: Y Method: Least Squares Date: 12/26/11 Time: 12:41 Sample: 1985 2009 Included observations: 25Variable Coefficient Std. Error t-Statistic Prob.C -26695.08 7507.527 -3.555775 0.0021 X1 5.994511 0.609713 9.831685 0.0000 X2 0.536701 0.057858 9.276245 0.0000 X3 -0.135873 0.029720 -4.571732 0.0002 X4 0.090822 0.042053 -2.159696 0.0438 X5-0.0073900.070511-0.1048140.9176R-squared0.980829 Mean dependent var 44945.64 Adjusted R-squared 0.975783 S.D. dependent var 4150.729 S.E. of regression 645.9230 Akaike info criterion 15.98480 Sum squared resid 7927113. Schwarz criterion 16.27733 Log likelihood -193.8100 F-statistic 194.4114 Durbin-Watson stat1.715679 Prob(F-statistic)0.000000⎩⎨⎧≠===--=ki k i u u E Eu u Eu u E u u COV k i k k i i k i ,0,),()])([(),(2σ),0(~2σμN iY= -26695.08+5.994511X1+0.536701X2+-0.135873X3+0.090822 X4+-0.007390X5 (7507.527) (0.609713) (0.057858)(0.029720) (0.042053) (0.070511) T =(-3.555775)(9.831685) (9.276245) (-4.571732) (-2.159696) (-0.104814)R-Squared=0.980829df=19从上面的估计的结果可以看出:可决系数R-Squared=0. 980829,表明模型在整体的拟和非常好。
计量经济学实验报告(多元线性回归分析)实验2:多元线性回归分析实验目的:学习利用Eviews建立多元线性回归模型,研究64国家婴儿死亡率与妇女文盲率之间的关系。
一、实验内容:1、先验的预期CM和各个变量之间的关系.2、做CM对FLR的回归,得到回归结果。
3、做CM对FLR和PGNP的回归,得到回归结果。
4、做CM对FLR,PGNP和TFR的回归结果,并给出ANOVA。
5、根据各种回归结果,选择哪个模型?为什么?6、如果回归模型(4)是正确的模型,但却估计了(2)或(3),会有什么后果?7、假定做了(2)的回归,如何决定增加变量PGNP和TFR?使用了哪种检验?给出必要的计算结果。
二、实验报告———-多元线性回归分析1、问题提出婴儿死亡率(CM)是指婴儿出生后不满周岁死亡人数同出生人数的比率.一般以年度为计算单位,以千分比表示。
婴儿死亡率是反映一个国家和民族的居民健康水平和社会经济发展水平的重要指标,特别是妇幼保健工作水平的重要指标。
婴儿死亡率(CM)的高低是一个国家或地区社会经济多方面因素协调发展的结果。
由于世界各国婴儿死亡率差别很大,所以就64个国家社会综合发展状况,针对性的研究婴儿死亡率(CM)与女性识字率(FLR)、人均GNP(PGNP)、总生育率(TFR)之间的关系2.指标选择本次实验研究婴儿死亡率与妇女文盲率之间的关系,故应采用婴儿死亡率(CM)和女性识字率(FLR)作为指标。
但影响婴儿死亡率的因素较复杂,尤其是经济发展状况、总生育率等也会对其产生重要影响,考虑到实验的准确性,故引入人均GNP(PGNP)和总生育率(TFR)相关数据。
3。
数据来源数据来源:教师提供4。
数据处理此次实验可直接使用数据,无需进行数据处理。
5。
先验的预期CM 和各个变量之间的关系 【题1】 5-1预期CM 与FLR 存在负相关关系。
一方面,女性受教育程度越高,其知识越丰富,自我保护意识和能力就越强,则更善于保护自己和婴儿;另一方面,女性教育程度越高,其就业机会与收入获得途径就越多,可以更好的保障自己和婴儿的生活.因此,我们预期FLR 的提高会导致CM 降低。
计量经济学实验报告小组成员:财政支出的计量经济学分析一、综述:人口口增长将给财政支出带来的压力,表现在人口总量的增加必然要求政府增加各种最基本的社会公共需求,否则将降低国民享有的公共服务及社会福利水平。
从长期趋势考查,各国的物价水平呈上升趋势,政府财政支出因此而逐年增长是不争的事实,并且在政府规模日趋扩大的情况下,物价上升将引起公共支出更快地增长。
物价影响财政支出增长还表现在物价总水平的起伏,尤其是剧烈动荡的时期。
当物价总水平下降时,通常反映经济不景气、失业增加,政府财政的转移支出将扩大,或是增加对社会的失业和基本生活补贴,或是对一些重要的国民经济部门给以补贴。
以下数据来自2013统计年鉴财政支出(Y) GDP(X1)人口数(X2)物价指数(X3)1997 9233.56 78973.0 123626 102.81998 10798.18 84402.3 124761 99.21999 13187.67 89677.1 125786 98.62000 15886.50 99214.6 126743 100.42001 18902.58 109655.2 127627 100.72002 22053.15 120332.7 128453 99.22003 24649.95 135822.8 129227 101.22004 28486.89 159878.3 129988 103.92005 33930.28 183084.8 130756 101.82006 40422.73 216314.4 131448 101.52007 49781.35 265810.3 132129 104.82008 62592.66 314045.4 132802 105.92009 76299.93 340902.8 133450 99.32010 89874.16 401512.8 134091 103.32011 109247.79 473104.1 134735 105.42012 125,952.97 519470.10 135404 102.6本文获取了我国从1997年到2012年的统计数据,Y为我国1997年至今2012年的财政支出,X1为GDP数,X2为人口数,X3为物价指数。
计量经济学实验报告回归分析计量经济学实验报告:回归分析一、实验目的本实验旨在通过运用计量经济学方法,对收集到的数据进行分析,研究自变量与因变量之间的关系,并估计回归模型中的参数。
通过回归分析,我们可以深入了解变量之间的关系,为预测和决策提供依据。
二、实验原理回归分析是一种常用的统计方法,用于研究自变量与因变量之间的线性或非线性关系。
在回归分析中,我们通过最小二乘法等估计方法,得到回归模型中未知参数的估计值。
根据估计的参数,我们可以对因变量进行预测,并分析自变量对因变量的影响程度。
三、实验步骤1.数据收集:收集包含自变量与因变量的数据集。
数据可以来自数据库、调查、实验等。
2.数据预处理:对收集到的数据进行清洗、整理和格式化,以确保数据的质量和适用性。
3.模型选择:根据问题的特点和数据的特性,选择合适的回归模型。
常见的回归模型包括线性回归模型、多元回归模型、岭回归模型等。
4.模型估计:运用最小二乘法等估计方法,对选择的回归模型进行估计,得到模型中未知参数的估计值。
5.模型检验:对估计后的模型进行检验,以确保模型的适用性和可靠性。
常见的检验方法包括残差分析、拟合优度检验等。
6.预测与分析:根据估计的模型参数,对因变量进行预测,并分析自变量对因变量的影响程度。
四、实验结果与分析1.数据收集与预处理本次实验选取了某网站的销售数据作为样本,数据包含了商品价格、销量、评价等指标。
在数据预处理阶段,我们剔除了缺失值和异常值,以确保数据的完整性和准确性。
2.模型选择与估计考虑到商品价格和销量之间的关系可能存在非线性关系,我们选择了多元回归模型进行建模。
采用最小二乘法进行模型估计,得到的估计结果如下:销量 = 100000 + 10000 * 价格 + 5000 * 评价 + 随机扰动项3.模型检验对估计后的模型进行残差分析,发现残差分布较为均匀,且均在合理范围内。
同时,拟合优度检验也表明模型对数据的拟合程度较高。
计量经济学实验报告 stata
《计量经济学实验报告:利用 Stata 进行数据分析与解释》
引言
计量经济学是经济学中的一个重要分支,它通过运用数学和统计工具来分析经济现象。
在实际研究中,经济学家们经常需要进行数据分析和解释,以验证经济理论和政策的有效性。
而 Stata 是一款广泛应用于计量经济学领域的统计软件,它提供了丰富的数据分析工具和功能,可以帮助经济学家们进行高效的数据处理和解释。
实验设计
为了展示 Stata 在计量经济学研究中的应用,我们设计了一个实验来分析劳动力市场的收入差距。
我们收集了一份包含个体收入、教育水平、工作经验等变量的数据集,并使用 Stata 进行数据清洗和整理。
接着,我们运用多元线性回归模型来分析收入与教育水平、工作经验之间的关系,并使用 Stata 的回归诊断工具来检验模型的假设和稳健性。
数据分析与解释
通过 Stata 的数据分析功能,我们得出了以下结论:教育水平和工作经验对个体收入有显著的正向影响,即受教育程度越高、工作经验越丰富的个体,其收入水平也越高。
而且,我们还发现了一些其他影响收入的因素,比如性别、种族等。
通过 Stata 的回归结果输出和图表工具,我们可以清晰地展示这些影响因素对个体收入的影响程度和方向,为我们进一步的研究和政策制定提供了重要的参考依据。
结论
本实验充分展示了 Stata 在计量经济学研究中的重要作用。
通过 Stata 的数据处理、回归分析和可视化工具,我们可以高效地进行数据分析和解释,为经济现象提供科学的解释和政策建议。
因此,我们鼓励经济学家们在其研究中充分利用 Stata 这一强大的工具,以提高研究的科学性和可信度。