SQL关系型数据库&结构化查询语言
- 格式:doc
- 大小:277.00 KB
- 文档页数:27

sql实验心得在进行SQL实验过程中,我学会了如何使用SQL(StructuredQuery Language)语言来管理和操作关系型数据库。
通过实践与掌握基本的SQL知识,我进一步提升了自己在数据库领域的能力和技术水平。
在这篇文章中,我将分享我在SQL实验中的心得和体会。
一、实验背景SQL是一种专门用于管理和操作关系型数据库的语言。
通过SQL,我们可以方便地进行数据的查询、插入、更新和删除等操作,实现对关系型数据库的有效管理。
在实验中,我主要使用的是MySQL数据库管理系统,结合SQL语言来完成各种数据库操作。
二、实验过程1. 数据库的连接与创建在实验开始时,我首先需要连接到MySQL数据库。
通过数据库连接工具,我输入相关的连接信息,例如数据库名称、用户名和密码等,成功连接到数据库后,便可以开始进行后续的实验操作。
接下来,我需要创建一个用于实验的数据库。
通过SQL的CREATE DATABASE语句,我可以轻松创建一个新的数据库,并指定数据库的名称。
例如,我可以使用以下语句创建一个名为"mydatabase"的数据库:CREATE DATABASE mydatabase;2. 表的创建与数据插入数据库中的数据存储在表中,因此在进行实验前,我需要先创建表,并将数据插入到表中。
通过SQL的CREATE TABLE语句,我可以定义表的结构和字段。
例如,我可以使用以下语句创建一个名为"employees"的员工表,并定义字段包括员工ID、姓名、职位和薪水等信息:CREATE TABLE employees (id INT PRIMARY KEY,name VARCHAR(50),position VARCHAR(50),salary DECIMAL(10,2));接下来,我可以使用INSERT INTO语句,将数据插入到表中。
例如,我可以使用以下语句向"employees"表中插入一条员工记录:INSERT INTO employees (id, name, position, salary)VALUES (1, 'John Smith', 'Manager', 5000.00);3. 数据查询与过滤数据查询是SQL中最常用且重要的操作之一。




数据库关系代数与SQL语句解析数据库关系代数是数据库管理系统中广泛应用于关系型数据库的一种计算机科学算法。
它是一种基于集合论的查询语言,用于描述在关系型数据库中执行查询操作的方法和规则。
SQL语句则是基于关系代数的查询语言,用于在关系式数据库管理系统中进行数据检索和操作的标准程序设计语言。
数据库关系代数提供了对关系数据库进行操作的一组基本操作。
这些操作包括选择、投影、并、交、差、笛卡尔积和自然连接等。
通过对这些基本操作的结合和嵌套使用,可以实现复杂的数据库查询和操作。
值得注意的是,虽然关系代数操作是一种抽象的计算方法,但在数据库管理系统中,它可以通过SQL语句来实现。
SQL(Structured Query Language)是一种标准化的关系数据库操作语言。
它由美国国家标准协会(ANSI)和国际标准化组织(ISO)定义。
SQL通过一系列的语句来描述对数据库的操作。
SQL语句包括数据定义语言(DDL)、数据操纵语言(DML)和数据控制语言(DCL)等不同类别。
数据定义语言(DDL)主要用于创建、修改和删除数据库、表、索引和视图等数据库对象。
DDL语句可以用来创建表、定义列、指定约束、创建索引等。
例如,CREATE DATABASE语句用于创建数据库,CREATE TABLE语句用于创建表。
数据操纵语言(DML)用于查询和操作表中的数据。
DML语句包括SELECT、INSERT、UPDATE和DELETE 等。
SELECT语句用于查询数据库中的数据,INSERT语句用于向表中插入数据,UPDATE语句用于更新表中的数据,DELETE语句用于删除表中的数据。
数据控制语言(DCL)用于定义数据库的安全性和完整性。
DCL语句包括GRANT和REVOKE等。
GRANT语句用于授予用户访问数据库的权限,REVOKE语句用于撤销用户的权限。
与关系代数对应的SQL语句可以通过对关系代数操作的转换来实现。
例如,关系代数中的选择操作可以通过SQL中的WHERE子句实现,关系代数中的投影操作通过SELECT语句实现,关系代数中的并操作可以通过SQL中的UNION操作来实现,关系代数中的笛卡尔积操作可以通过SQL中的JOIN操作来实现等等。


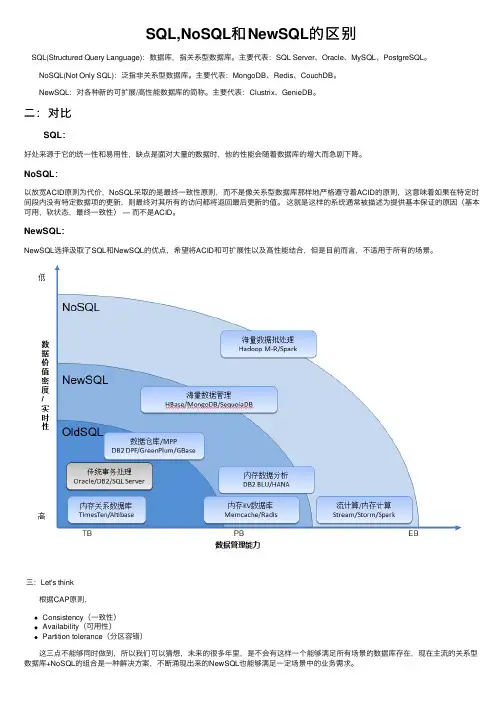
SQL,NoSQL和NewSQL的区别 SQL(Structured Query Language):数据库,指关系型数据库。
主要代表:SQL Server、Oracle、MySQL、PostgreSQL。
NoSQL(Not Only SQL):泛指⾮关系型数据库。
主要代表:MongoDB、Redis、CouchDB。
NewSQL:对各种新的可扩展/⾼性能数据库的简称。
主要代表:Clustrix、GenieDB。
⼆:对⽐ SQL:好处来源于它的统⼀性和易⽤性,缺点是⾯对⼤量的数据时,他的性能会随着数据库的增⼤⽽急剧下降。
NoSQL:以放宽ACID原则为代价,NoSQL采取的是最终⼀致性原则,⽽不是像关系型数据库那样地严格遵守着ACID的原则,这意味着如果在特定时间段内没有特定数据项的更新,则最终对其所有的访问都将返回最后更新的值。
这就是这样的系统通常被描述为提供基本保证的原因(基本可⽤,软状态,最终⼀致性) — ⽽不是ACID。
NewSQL:NewSQL选择汲取了SQL和NewSQL的优点,希望将ACID和可扩展性以及⾼性能结合,但是⽬前⽽⾔,不适⽤于所有的场景。
三:Let's think 根据CAP原则,Consistency(⼀致性)Availability(可⽤性)Partition tolerance(分区容错) 这三点不能够同时做到,所以我们可以猜想,未来的很多年⾥,是不会有这样⼀个能够满⾜所有场景的数据库存在,现在主流的关系型数据库+NoSQL的组合是⼀种解决⽅案,不断涌现出来的NewSQL也能够满⾜⼀定场景中的业务需求。
OldSql:传统关系型数据库NewSql:也是关系型数据库,吸收了传统关系型数据库和NoSql数据库的优点。
可实现强⼀致性(传统关系型DB优点),具有强的⽔平可扩展性(NoSql DB优点)NoSql:⾯向互联⽹应⽤,如web2.0,半结构化,⾮结构化数据的存储图5-6 ⼤数据引发数据处理架构变⾰图5-7 关系数据库、NoSQL和NewSQL数据库产品分类图SQLSQL是关系型数据库管理系统(RDBMS),顾名思义,它是围绕关系代数和元组关系演算构建的。

sql数据库as用法-回复SQL数据库AS用法详解SQL(Structured Query Language)是用于管理和操作关系型数据库的标准语言。
它提供了创建、查询、更新和删除数据库中数据的功能。
在SQL 中,AS是一个重要的关键字,它用于给查询结果集或表创建一个别名。
在本文中,我们将深入探讨AS的用法,并逐步回答与其相关的问题。
一、AS的基本用法AS关键字可用于为表、列和结果集创建别名。
其基本语法如下:1. 列别名SELECT column_name AS alias_nameFROM table_name;在上述语法中,column_name是要被别名代替的列名,alias_name是指定的别名。
使用别名可以为结果集的列提供更具描述性的名称。
例如,我们可以使用AS来为"customer_name"列创建别名"name",如下所示:SELECT customer_name AS nameFROM customers;2. 表别名在一些复杂的查询中,多个表可能需要进行连接。
为了简化查询语句并提高可读性,AS关键字也可以用于为表创建别名。
其语法如下:SELECT column_nameFROM table_name AS alias_name;在上述语法中,column_name是需要检索的列名,table_name是要从中检索数据的表名,alias_name是为表创建的别名。
通过为表创建别名,我们可以更方便地引用这些表。
例如,我们可以使用AS为"orders"表创建别名"o",如下所示:SELECT o.order_id, c.customer_nameFROM orders AS oJOIN customers AS c ON o.customer_id = c.customer_id;在上述查询中,我们可以通过"o"和"c"来引用"orders"和"customers"表,使得查询语句更加简洁和易读。

关系型数据库与NoSQL的对⽐SQL(结构化的查询语⾔)数据库是过去四⼗年间存储数据的主要⽅式。
20世纪90年代末随着Web应⽤和MySQL、PostgreSQL和SQLite等开源数据库的兴起,⽤户爆炸式的增长。
NoSQL数据库⾃从20世纪60年代就已经存在了,直到MongoDB, CouchDB, Redis 和 Apache Cassandra等数据库的流⾏才获取了更多的关注。
你可以很容易地找到许多关于如何使⽤⼀款特定的SQL或NoSQL的教程,但是很少有讨论你为什么优先的使⽤⼀款⽽不适⽤另⼀款。
我希望我能够填补这个空⽩。
在这篇⽂章中将会介绍它们之间的不同。
在中,我们将会根据典型的场景来确定最佳的选择。
⼤多数的例⼦都适⽤于流⾏的关系型数据库和 NoSQL数据库.其它的SQL/NoSQL也是类似的,但是在语法和特点上会有⼀些细微的差别。
SQL与NoSQL之间的战争在我们进⼀步讨论之前,我们先不去考虑各种观点......观点⼀:NoSQL将会取代SQL这个观点就像是说船将会取代汽车,因为船是⼀种新的技术⼀样,这是不可能发⽣的事情。
SQL和NoSQL有着相同的⽬标:存储数据。
它们存储数据的⽅式不同,这可能会影响到你开发的项⽬,⼀种会简化你的开发,⼀种会阻碍你的开发。
尽管⽬前NoSQL数据库⾮常的⽕爆,但是NoSQL是不能取代SQL的--它仅仅是SQL的⼀种替代品。
观点⼆:NoSQL要⽐SQL好/坏⼀些项⽬可能会更适合使⽤SQL数据库,然⽽⼀些项⽬可能会⽐较适合使⽤NoSQL,有些项⽬使⽤哪⼀种都可以很好地达到预期的效果。
本⽂不⽀持任何⼀⽅,因为没有⼀种⽅式可以使⽤到所有的项⽬中去。
观点三:SQL与NoSQL之间有明显的差别这个观点并不是很正确。
⼀些SQL数据库也采⽤了NoSQL数据库的特性,反之亦然。
在选择数据库⽅⾯的界限变得越来越模糊了,并且⼀些新的混合型数据库将会在不久的将来提供更多的选择。

使用SQL构建和管理关系型数据库的步骤第一章:数据库的概述与设计1.1 数据库的定义和分类数据库是指存储有组织的数据的集合,按照数据结构和数据之间的联系进行组织和管理,以便于数据的存储、检索、修改和删除。
根据数据之间的关系,数据库可以分为关系型数据库、层次型数据库、网络型数据库等。
1.2 关系型数据库的特点和优势关系型数据库是一种以表格形式存储数据的数据库管理系统。
它的特点有:数据以表格的形式进行组织,每个表格包含多个字段,每个字段包含一个数据项;表格之间通过关系进行连接,形成关系。
关系型数据库的优势包括:数据之间的关系清晰,易于理解和维护;SQL语言成熟且易学,支持丰富的操作功能。
1.3 数据库设计的基本原则数据库设计是指通过分析和确定数据的组织结构、数据之间的联系以及对数据的操作,从而满足用户的需求。
数据库设计的基本原则包括:数据完整性原则,确保数据的准确性和一致性;数据冗余性原则,避免数据的重复和冗余;数据安全性原则,保护数据的机密性和完整性;数据的可扩展性原则,支持新增、修改和删除数据的操作。
第二章:SQL语言的基础2.1 SQL语言的概述SQL(Structured Query Language)是一种用于管理关系型数据库的语言。
它可以进行数据的查询、插入、更新、删除等操作。
SQL语言包括数据定义语言(DDL)、数据查询语言(DQL)、数据操作语言(DML)和数据控制语言(DCL)等部分。
2.2 SQL语言的基本语法SQL语言有一些基本的语法规则,例如使用关键字、使用分号结束语句、使用单行注释等。
SQL语句通常由关键字、参数和运算符组成,关键字用于指定要操作的对象,参数用于指定具体的值,运算符用于进行逻辑和数学运算。
2.3 常用的SQL语句常用的SQL语句包括:创建数据库和表格的语句、插入数据和更新数据的语句、查询数据的语句、删除数据和表格的语句等。
例如,创建表格的语句可以使用CREATE TABLE语句,插入数据的语句可以使用INSERT INTO语句,查询数据的语句可以使用SELECT语句。
常见关系型数据库一、什么是关系型数据库关系型数据库(Relational Database)是一种基于关系模型的数据库管理系统。
关系模型由一组表格(表)组成,每个表格由行和列组成,行表示记录,列表示字段。
关系型数据库使用结构化查询语言(SQL)操作数据,数据之间的关系通过主键和外键进行定义和维护。
关系型数据库具有以下特点:1.结构化数据存储:关系型数据库将数据存储在表格中,每个表格由行和列组成,表格中的数据具有结构性,可以通过行和列的组合快速检索和查询数据。
2.数据一致性:关系型数据库使用事务来保证数据的一致性,事务具有原子性、一致性、隔离性和持久性四个特性,保证了数据的完整性和可靠性。
3.数据完整性:关系型数据库支持定义关系之间的完整性约束,如主键、外键、唯一性约束、默认值约束等,确保数据的完整性和正确性。
4.查询功能强大:关系型数据库使用结构化查询语言(SQL)进行数据操作和查询,支持复杂的数据查询、统计和排序等功能,方便用户对数据进行灵活的操作和分析。
二、常见的关系型数据库产品2.1 MySQLMySQL是一款开源的关系型数据库管理系统,由瑞典MySQL AB公司开发,并逐渐发展成为全球最流行的关系型数据库之一。
MySQL具有以下特点:•开源免费:MySQL以其开源和免费的特性,在全球范围内获得了广泛应用。
•高性能:MySQL通过优化的数据库引擎和查询优化器实现了高性能的数据访问速度,能够处理大规模数据并发访问。
•安全性:MySQL提供了完善的权限管理和访问控制机制,可以对用户和角色进行细粒度的权限控制,保障数据的安全性。
2.2 OracleOracle是一款全球知名的关系型数据库管理系统,由美国Oracle公司开发。
Oracle具有以下特点:•企业级数据库:Oracle适用于大型企业级应用,具有良好的可扩展性和可靠性,能够处理高并发的数据访问需求。
•数据安全性:Oracle提供了强大的数据安全性功能,包括身份验证、访问控制、加密、审计等,保护数据不被非法用户访问。
sql 规则和范式
SQL规则和范式是数据库设计和管理中非常重要的概念。
首先,让我们来谈谈SQL规则。
SQL是结构化查询语言的缩写,它是一种
用于管理关系型数据库的标准化语言。
SQL规则是指在编写SQL语
句时需要遵循的一系列规则和约定,以确保数据库操作的准确性和
一致性。
这些规则包括语法规则、数据类型规则、约束规则等。
例如,SQL语句必须按照特定的语法结构编写,数据类型必须与字段
定义一致,约束条件必须满足数据库设计的要求等。
接下来是范式的概念。
范式是用来规范化数据库设计的一组原则,旨在减少数据冗余和提高数据的一致性。
常见的范式包括第一
范式(1NF)、第二范式(2NF)、第三范式(3NF)等。
第一范式要求每个字段具有原子性,不可再分;第二范式要求每个非主键字段
完全依赖于全部主键而不是部分主键;第三范式要求每个字段都直
接依赖于主键,而不是依赖于其他非主键字段。
在SQL中,范式的应用可以提高数据库的性能和可维护性,减
少数据冗余和提高数据的完整性。
但是,过度范式化也可能导致查
询性能下降,需要在设计数据库时权衡范式化和性能之间的关系。
总的来说,SQL规则和范式是数据库设计和管理中非常重要的概念,它们能够帮助我们设计出高效、可靠的数据库结构,提高数据的一致性和完整性。
在实际应用中,需要根据具体的业务需求和性能要求来灵活运用这些原则。
SQL语言的组成1. 什么是SQL语言SQL(结构化查询语言)是一种专门用于管理关系型数据库的语言。
它是用于创建、操作和管理关系型数据库中的表、视图、索引等对象的标准化语言。
2. SQL语言的组成SQL语言主要由以下几个组成部分构成:(1) 数据定义语言(DDL)DDL是SQL语言的一部分,用于定义、修改和删除数据库对象。
DDL包括以下常用关键字: - CREATE: 创建数据库对象(表、视图、索引等) - ALTER: 修改数据库对象的结构 - DROP: 删除数据库对象通过DDL语句,我们可以创建表、定义表的结构、修改表的结构,以及删除不再需要的表等。
(2) 数据操作语言(DML)DML是SQL语言的一部分,用于操作(增删改查)数据库中的数据。
DML包括以下常用关键字: - INSERT: 向表中插入数据 - DELETE: 从表中删除数据 - UPDATE: 修改表中的数据 - SELECT: 从表中查询数据通过DML语句,我们可以向表中插入新的数据、删除表中的数据、修改表中的数据,以及从表中查询所需的数据。
(3) 数据查询语言(DQL)DQL是SQL语言的一部分,用于从关系型数据库中进行查询操作。
DQL只包括SELECT关键字,用于从表中查询数据。
DQL语句可以使用WHERE子句来指定查询条件,以便过滤所检索的结果。
(4) 数据控制语言(DCL)DCL是SQL语言的一部分,用于控制数据库用户的访问权限和管理数据库的完整性约束。
DCL包括以下常用关键字: - GRANT: 授予用户对数据库对象的特定权限 - REVOKE: 撤销用户对数据库对象的特定权限通过DCL语句,我们可以为数据库用户授予或撤销特定的权限,以便管理数据库的安全性。
(5) 数据事务控制语言(TCL)TCL是SQL语言的一部分,用于控制数据库事务的提交、回滚和保存点的设置。
TCL包括以下常用关键字: - COMMIT: 提交事务 - ROLLBACK: 回滚事务 - SAVEPOINT: 设置保存点通过TCL语句,我们可以控制数据库事务的执行和结果,以确保数据的一致性和完整性。
关系型数据库与文档型数据库的对比与选择引言:在当今的信息时代,数据管理和存储已变得至关重要。
随着企业信息量的迅速增长,对于高效和可靠的数据管理系统的需求也日益增加。
关系型数据库(RDBMS)和文档型数据库(NoSQL)成为如今主流的数据库系统之一。
本文将对关系型数据库和文档型数据库进行对比,并给出选择的建议。
第一部分:关系型数据库关系型数据库是传统的数据库管理系统,采用表格(或称之为关系)来组织和存储数据。
关系型数据库使用结构化查询语言(SQL)来定义和操作数据。
以下是关系型数据库的一些优势和劣势。
优势:1. 数据一致性:关系型数据库采用严格的结构和规则,确保数据的一致性和完整性。
2. 灵活性:通过使用SQL查询语言,用户可以方便地对数据进行复杂的查询和分析。
3. 数据关系:通过使用表格和外键来建立数据之间的关系,关系型数据库可以处理复杂的数据模型。
劣势:1. 扩展性:关系型数据库的扩展性相对较差,对大规模数据的处理能力有限。
2. 存储方式:表格的结构需要严格的定义,在某些情况下这可能不够灵活。
3. 性能问题:在处理大量事务和并发访问时,关系型数据库可能出现性能瓶颈。
第二部分:文档型数据库文档型数据库是一种NoSQL数据库,它使用类似JSON或XML的格式存储数据。
文档型数据库提供了一种松散的结构,允许灵活存储和查询数据。
以下是文档型数据库的优势和劣势。
优势:1. 灵活性:文档型数据库的存储结构非常灵活,可以根据需求动态地改变数据模型。
2. 扩展性:文档型数据库在处理大规模和分布式数据时具有良好的扩展性能力。
3. 性能:文档型数据库通过使用键值对来存储和索引数据,能够实现快速的数据读写。
劣势:1. 缺乏严格的结构:文档型数据库的数据模型比较灵活,缺乏严格的数据结构限制,可能会导致数据的一致性问题。
2. 查询复杂性:由于缺乏SQL查询语言的支持,使用复杂查询和分析可能比较困难。
3. 高级功能限制:与关系型数据库相比,文档型数据库在某些高级功能方面可能有所欠缺。
摘要在关系型数据库中,结构化查询语言SQL 的同一条查询语句可能面临着许多等功能的执行计划。
如何快速、准确地从众多可选计划中选取最优计划,提高数据库的查询效率,从关系型数据库问世之日起一直是人们研究的重点。
代价评估的作用是为了在查询执行之前估算出其运行时的代价。
设计一个代价评估模型应遵循以下原则:该模型应能快速而准确地估算出一个逻辑计划的运行代价;应具备一定的错误恢复能力,即系统在执行查询过程中,如果发现目前执行的是次优计划时,系统将采取一定的弥补措施并防止下次出现类似的错误。
对于代价评估系统,统计数据的维护应尽量少开销系统资源,尽量少要人工干预。
为了能够准确地估算出逻辑计划的运行代价,需要维护待查询表中的数据统计信息,了解表中数据的分布和索引的相关数据。
描述数据的分布信息有很多方法,目前的商用数据库管理系统基本上都采取等深直方图技术。
借助这些统计信息,代价评估模型可以更好地估算出中间结果集大小,进而得到磁盘I/O 的代价。
针对目前达梦(Da Meng,DM)数据库管理系统所支持的各种逻辑操作符,提出了代价的计算公式;对统计数据的产生、维护提出了一套管理方案。
在目前研究的基础上,对执行过程中次优计划的检测及相应的处理,提出了一些改进。
在代价评估模型实现的过程中,对达梦数据库管理系统的查询模块做出了一些修改。
测试结果表明,改进后的查询系统能够更加合理地选择逻辑计划,从而提高系统的响应速度。
关键词:数据库,查询优化,代价评估,动态优化IAbstractRelational query languages provi de a high level “declarative” interface to access data stored in relational databases. For each input query, the optimizer has a number of alternative plans. To choose the best one from a set of candidate plans has been the primary research ever since the RDBMS.A cost estimation model is to estimate the cost of any given plan without executing it. The cost here may refer to CPU time, I/O cost, memory usage, etc. Cost estimation should be efficient since it is repeatedly revoked during the optimization process. For a number of reasons, cost estimation may give inaccurate result and query optimizer may producesub-optimal query plans, leading to a significant degradation of performance. Actions should be taken to detect sub-optimal plans and recover from such errors. Furthermore, similar mistakes should be avoided in future. Cost estimation model also need a convenient and low-cost approach to maintain statistical summaries.To get the exact cost for a given plan, statistics on accessed tables should be collected. There are many ways to describe this information, and equal-depth histogram is the most used in commercial DBMS. We can estimate the intermediate cardinality then I/O cost with these information.In this paper, We proposed compute formulas for logical operators in DM DBMS, an approach to get and maintain the statistics, as well as an improvement method to detect and tackle sub-optimal plan selection.In order to implement this cost estimation model, we improved the query engine of DM. Experiments showed that with this cost estimation model, DM can choose execution plan more reasonable, which brings better performance.Key words:database, query optimization, cost estimation, dynamic optimizationII独创性声明本人声明所呈交的学位论文是我个人在导师指导下进行的研究工作及取得的研究成果。
数据库:用来存储数据的仓库,英文表示为database,简称DB数据:数字、文字、图片、视频、音频、文本等等,在计算机科中能输入到计算机并能被计算处理的符号的总称数据库的管理系统:简称DBMS【介于用户和操作系统之间一层管理软件.主要负责用户与数据库之间沟通】现今流行的的数据库管理系统1、小型Access【Office软件产品之一】、VF…2、中型SQLServer【Microsoft微软】、MySQL【瑞典一个小公司出品】、DB2【IBM公司】3、大型Oracle【甲骨文公司】…数据库管理包括1、数据的定义部分【包括创建数据库、修改数据库、删除数据库、创建数据表、修改表结构、删除数据表、添加/删除约束条件】2、数据的操纵部分【对数据的处理(添加数据、修改数据、删除数据、查询数据等)】3、数据库的运行和管理4、数据库的建立和维护数据库系统:用户【后台开发人员】----数据库管理系统----数据库管理员----数据库注意:用户通过数据库管理系统操作数据库,数据库管理员可以通过数据库管理系统操作数据库,也可以直接操作数据库通常目前使用的数据库管理系统都是关系型数据库关系型数据库中存放一个或者多个关系,每一个关系就是一张二维表不同的关系表存在一些关系1、一对一关系2、一对多关系3、多对多关系关系表:以二维表形式存在,不同的数据表之间存在关系元组【记录】:存放在二维表中的一行记录,任何一张表中没有完全相同的记录属性【字段】:存放在二维表中的一列信息,同一字段的属性名称不能相同域【字段值】:存放在二维表中的属性值,同一列的数据值类型必须一致主码【主键】:用来唯一标识某一行记录的属性,主键尽可能不参与任何业务逻辑,跟实际功能无关,任何数据表中都要有主键############################################################################### sql server 2005版本1)sql server 2005企业版:只能安装windows server操作系统.如:windows server 20032)sql server 2005个人版: 可以安装win xp,windows 2000/2003,windows vista3)sql server 2005简装版:随Microsoft Visual Studio 2005安装的.4)sql server 2005开发版:5)sql server 2005工作组版############################################################################### SQL语言:标准的结构化查询语言【所有数据库管理系统通用的标准语言】使用数据库管理系统【SQLServer为例】1、安装SQLServer数据库【SQLServer2005开发板的安装】对于32位操作系统安装X86,对于64位系统安装X64,由于SQLServer2005自带客户端管理界面,先安装Tools文件夹中的客户端管理界面,再安装Server文件夹中的服务器2、开启服务注意:安装SQLServer数据库会生成相关服务,默认情况下服务是自动并且开启,为了保证系统的顺畅运行,习惯将服务都设置成手动,不需要的服务可以暂时关闭服务启动类型1)自动:windows运行时服务会自动开启2)手动:当需要时,用户手动去点击服务才会开启3)禁用:服务不允许使用.注:最好将sql server服务设置为手动方式.其中:SQL Server(MSSQLServer)服务是运行数据库必须要开启的,其中小括号中的内容可能在家用电脑中名字有所区别(命名实例SQLServer)我的电脑右键----管理---服务和应用程序---服务---找到SQL Server(MSSQLServer)服务双击----点击启动-----确定3、打开SQLServer进入登录界面开始---程序---SQLServer---SQLServer Management注意:安装数据库过程中如果选择登录模式为【混合模式SQLServer身份登录】通过用户名sa和密码可以直接登录如果数据库过程中如果选择登录模式为【Windows模式登录】不需要用户名密码直接登录进入数据库后再自行设置登录名和密码以及所属权限设置登录名和密码以及所属权限:以Windows模式登录---安全性---登录名---右键新建登录名---设置名字和密码---服务器角色处选择sysadmin---确定---断开连接重新进入登录界面---选择SQLServer身份登录---输入登录名和密码---确定自带的系统数据库:1)master: 存放数据库的启动和配置信息2)model: 是一个模版数据库,新建的数据库都以它为模版.3)tempdb: 存放临时数据的.4)msdb: 存放任务的周期性执行数据库:主要由数据文件,日志文件组成.数据文件:分为主数据文件和次数据文件主数据文件:它的扩展名为.mdf,存放数据库的配置信息和一般数据次数据文件:它的扩展名为.ndf,用来辅助主文件不足的.日志文件:它的扩展名为.ldf.用来存放日志信息,利用日志文件可以进行数据恢复。
注:主数据文件有且仅有一个、次文件可以没有、也可以有多个,日志文件至少有一个,也可以有多个。
注:登录服务名称中可以输入计算机名或者计算机ip或者.表示登录本地sql server 数据库常用的数据类型int 整型--4字节=4*8=32位范围:-2^31~2^31-1char 字符型--静态长度varchar 字符型--动态长度numeric(m,n) m表示整数和小数位数,n表示小数的位数.如:numeric(4,1)datetime 时间日期型text 存放大量文本image 存放二进制文件,如:声音,图像等.约束:保证数据的完整型和一致性主键(primary key):唯一标识表中一条记录.一个表只有一个主键,不能为空,也不能重复.唯一(unique):一个表可以有多个唯一,可以为空,但只能空一次,不能重复.检查(check):检查字段的取值范围如: 年龄>=18 and 年龄<=60,年龄是表中字段性别='男' or 性别='女',性别是表中字段,字符型用单引号引上。
空(null):表示字段的内容可以不填写.非空(not null):表示字段的内容必须要填写默认(default):事先给字段设置好的一个值,当用户不填写时,会自动填入设好的值。
如果填写就会复盖设好的值.标识列(identity):一个表只有一个标识列,它可以产生连续且唯一的编号,并且递增产生。
某字段设置标识列之后,用户给该字段插入值或修改值.字段类型必须是整型外键(foreign key):需要2个表,用一个表字段参考于另一个表另一个字段.建外键的表为子表(外键表),被参考的表为主表(主键表),要求主表被参考的字段为主键或唯一约束,子表的字段类型要与主表的字段类型要相同。
注意:SQLServer注释分2种:--注释内容单行/*注释内容*/多行数据的定义语言:对创建数据库、使用数据库、数据表的创建、修改数据表的结构、添加约束条件通过命令对数据库操作:打开并登录数据库管理系统----工具栏新建查询---为SQL文件创建目录---起名---确定1、创建数据库create database 数据库的名称;例如:create database myDB;数据文件(主文件.mdf,次文件.ndf)和日志文件(.ldf)create database 数据库名on(name=逻辑名1,filename='路径+文件名.mdf',size=初始值MB,maxsize=最大值MB,filegrowth=x%|xMB),(name=逻辑名2,filename='路径+文件名.ndf',size=初始值MB,maxsize=最大值MB,filegrowth=x%|XMB),...log on(name=逻辑名3,filename='路径+文件名.ldf',size=初始值MB,maxsize=最大值MBM,filegrowth=x%|XMB)注:name,filename不能省略,可以省略size=1MB,maxsize=不受限制,filegrowth=10% name逻辑名不能重复.name和filename 一一对应的例如:create database MyDBon(name=MyDB_MDF_data,filename='F:\MyDB_MDF_data.mdf',size=5MB,maxsize=100MB,filegrowth=20%),(name=MyDB_NDF _data,filename='F:\MyDB_NDF_data.ndf',size=5MB,maxsize=100MB,filegrowth=20%)log on(name=MyDB_log,filename='F:\MyDB_log.ldf',size=5MB,maxsize=100MB,filegrowth=20%)如图【F盘目录下生成如下文件】############################################################################### 2、使用数据库use 数据库的名称;例如:use myDB;3、删除数据库drop database 数据库名;例如:drop database myDB;数据库在使用状态下,无法删除,先使用其它数据库,然后再删除4、修改数据库给现有的数据库的新增一个数据文件alter database 数据库名add file(name=逻辑名,filename=’路径+文件名.ndf',size=初始值MB,maxsize=最大值MB,filegrowth=X%|XMB)例如:alter database MyDBadd file(name=MyDB_NDF_data,filename='F:\MyDB_NDF_data.ndf',size=10MB,maxsize=200MB,filegrowth=10MB)增加一个日志文件alter database 数据库名add log file(name=逻辑名,filename='路径+文件名.ldf',size =初值MB,maxsize=最大值MB,filegrowth=X%|XMB)例如:alter database MyDBadd log file(name=MyDB_log,filename='F:\MyDB_log.ldf')修改数据库的参数alter database 数据库名modify file(name=逻辑名,size=初值MB,maxsize= 最大值MB,filegrowth=X%|XMB)注:filename不能修改,一次最好修改一个参数例如:alter database MyDBmodify file(name=MyDB_log,size=10MB)删除数据中的文件alter database 数据库名remove file 逻辑名例如:alter database MyDB remove MyDB_log;修改数据库名exec sp_renamedb '旧数据库名','新数据库名'例如:exec sp_renamedb'MyDB','MyDataBase';查看数据库信息exec sp_helpdb 数据库名例如:exec sp_helpdb MyDataBase;############################################################################### 通过数据库管理系统创建数据表在所选数据库上右键---新建表---为表设置列名以及类型【常见的类型:varchar字符串、char 字符、int整数、float小数、datetime日期等】注意:创建表必须为表中设置一个唯一标识的列【主键】:在要设置主键的列上右键---选择设置主键【主键是不能为空】---确定设置主键自增长:要想通过数据库自动为我们维护主键唯一:前提主键必须为整数int类型,选择主键列在下面的窗口中找到标识规范---选择是否标识【是】,出现标识增量【每次添加记录主键会自增长的数】和标识种子【主键起始值】############################################################################### 通过命令行创建数据表create table 表名(列名1 列的类型1 primary key identity(1,2),列名2 列的类型2,列名3 列的类型3,列名4 列的类型4);例如:create table t_user(userOID int identity(1,1)primary key,userName varchar(22),userAge int,userSex char(2),userBirth datetime,userSary float);其中primary key表示主键identity(1,2)表示自增长【参数1:表示标识种子,参数2:表示标识增量】注意:主键如果想要设置自增长,主键列必须为整数类型表结构如下用户表修改表的结构1、修改表结构添加列【为表中添加列,实际上修改原有表的结构】alter table 表名add 列名列的类型;例如:alter table t_user add userContext char(2);2、修改表结构列的类型【修改的是表中列的类型】alter table 表名alter column 要修改的列名修改后列的类型;例如:alter table t_user alter column userContext varchar(50);3、修改表结构删除列alter table 表名drop column 要删除的列名;例如:alter table t_user drop column userContext;如果想要修改表【列】名称exec sp_rename '表名.表中要修改的列名','新修改的列名','column';exec sp_rename '旧表名','新表名';############################################################################### 删除数据表drop table 表名;例如:drop table t_user;数据表的复制1、复制整张表select * into 新表名from 旧表名;例如:select*into tt_user from t_user;2、只复制表结构不要数据内容select * into 新表名from 旧表名where 1 = 0;例如:select*into ttt_user from t_user where 1 = 0;注意:复制表只能复制表的结构以及数据,但是无法对表的约束进行复制,需要为新表重新添加约束条件############################################################################### 数据表的约束条件基本形式alter table 表名add constraint 约束名约束条件;注意:同一数据库下的表约束名不能相同1、主键约束alter table 表名add constraint 约束名primary key(要设置主键的字段名);例如:alter table t_user add constraint pk primary key(userOID);2、默认约束alter table 表名add constraint 约束名default 默认值for 要设置默认的字段名;例如:alter table t_user add constraint df default'女'for userSex;注意:默认值的类型要和设置该字段的类型一致3、唯一约束:属于业务逻辑功能,类似主键alter table 表名add constraint 约束名unique(要设置唯一的字段名);例如:alter table t_user add constraint un unique(userName);4、检查约束alter table 表名add constraint 约束名check(要设置检查的表达式);例如:alter table t_user add constraint ck check(userAge<=22 or userAge>=34); alter table t_user add constraint c_k check(userAge>=0 and userAge<=74);5、外键约束通常存在不同关系的两张表,多方存放一方的唯一标识alter table 外键所在表名add constraint 约束名foreign key(要设置约束列名)references 另一张表名(另一张表主键名);例如:alter table t_user add constraint fg foreign key(userGroupID)references t_userGroup (userGroupOID);注:设置外键约束的表数据删除后才能删除另一张表对应主键删除约束alter table 表名drop constraint 约束名;例如:alter table t_user drop constraint pk;alter table 表名nocheck constraint 约束名;例如:alter table t_user nocheck constraint ck;激活约束alter table 表名check constraint 约束名;例如:alter table t_user check constraint ck;注:激活和关闭约束适合于外键和检查约束############################################################################### 数据的操纵1、添加数据插入表中全部记录【表中有多少列,就需要插入多少值,并且插入的记录要和定义表中列的类型一致】insert into 表名values(列的值1,列的值2,列的值3,列的值4,......);例如:insert into t_user values('张三',22,'女','2012-12-12',2222.222);插入表中部分记录【插入的记录要和定义表中列的类型一致】insert into 表名(指定要插入的列名1,列名2,.....) values (列的值1,列的值2,......); 例如:insert into t_user (userName,userAge,userSex)values('张三',22,'女'); 2、修改修改表中所属列的所有记录update 表名set 要修改的列名=要修改列的值;例如:update t_user set userName='李四';根据条件修改表中所属列的记录update 表名set 要修改的列名=要修改列的值where 条件;update 表名set 要修改的列名=要修改列的值where 条件1 and 条件2,......;update 表名set 要修改的列名=要修改列的值where 条件1 or 条件2,......;例如:update t_user set userSary=7777.74 where userOID=1;update t_user set userSary=7777.74 where userAge>22 and userAge<44; update t_user set userSary=7777.74 where userAge<31 or userAge>47;删除表中所有记录------初始化数据表delete from 表名;truncate table 【删除速度快,不写入日志中,删除后不可恢复】例如:delete from t_user;truncate table t_user;根据条件删除表中所属的记录delete from 员工表where 条件;delete from 员工表where 条件1 and 条件2,......;delete from 员工表where 条件1 or 条件2,......;例如:delete from t_user where userOID=1;delete from t_user where userAge>22 and userAge<44;delete from t_user where userAge<31 or userAge>47;############################################################################### 4、查询【简单的基本查询】查询表中所有记录select * from 表名;例如:select*from t_user;查询表中指定列的所有记录select 列名1,列名2,..... from 表名;例如:select userName,userSex from t_user;根据条件查询表中指定列的所有记录select 列名1,列名2,..... from 表名where 条件;select 列名1,列名2,..... from 表名where 条件1 and 条件2,......;select 列名1,列名2,..... from 表名where 条件1 or 条件2,......;例如:select userName,userSex from t_user where userOID = 1;select userName,userSex from t_user where userAge>22 and userAge<44; select userName,userSex from t_user where userAge<31 or userAge>47;############################################################################### 关于查询格式select 字段1,...字段n from 表名where 条件group by 字段having 分组条件order by 字段asc | desc其中:*表示所有字段例如:select*from t_user;只显示某几个字段【字段列表,字段之间用逗号分开】例如:select userName,userSex from t_user;运算符:注:sql server 2005:"+"不仅表示字符串连接,也表示加运算.>、<、>=、<=、!=不等于、<>不等于、=等于+、-、*、/and 表示与相当于语言中&&or 表示或相当于语言中||not 表示非--相当于语言中!例如:select userName,userSex from t_user where userAge>22 and userAge<44; select userName,userSex from t_user where userAge<31 or userAge>47; select userName,userSex from t_user where not userAge=11;select userName,userSex,userSary+subSidySary from t_user;字段的别名空格分开例如:select *,userSary+subSidySary sumSary from t_user;as 分开例如:select *,userSary+subSidySary as sumSary from t_user;'字段别名'=字段名例如:select*,sumSary=userSary+subSidySary from t_user;between and【表示范围】相当于字段>=值1 and 字段<=值2例如:select*from t_user where userAge between 11 and 22;相当于select*from t_user where userAge>=11 and userAge<=22;in 表示集合,是否在集合中字段in(值1,...值n)例如:select*from t_user where userAge=18 or userAge=11 or userAge=22; 相当于select*from t_user where userAge in(18,11,22);not in 与in相反.例如:select*from t_user where userAge not in(11,18,13);模糊查询:查询姓李的人的所有信息select * from 表名where userName like '李%';例如:select*from t_user where userName like'李%';查询姓名最后一个字为'明'的人的所有信息select * from 表名where userName like '%明';例如:select*from t_user where userName like'%明';查询姓名中间文字为'明'字的人的所有信息select * from 表名where userName like '_明_';例如:select*from t_user where userName like'_明_';查询名字含有李字的人的所有信息例如:select*from t_user where userName like'%李%';排除姓李的人的所有信息例如:select*from t_user where userName like'[^李]%%'指定姓李的人的所有信息例如:select*from t_user where userName like'[李]%%'其中Like修饰符使用了简单的正则表达式,引用几种种通配符% 匹配任何数目的字符,甚至零个字符_ 精确匹配一个字符[]指定单个字符的范围[^]排除指定字符的范围not like 与like 相反查询名字第二个字不是李字的人的所有信息例如:select*from t_user where userName not like'_李%'查询名字中含有”_”的记录例如:select*from t_user where userName like'%_%'查询结果有误select*from t_user where userName like'%[_]%'[^]通配符select*from t_user where userName like'_[李]_';select*from t_user where userName like'_[^李]_';逃逸字:查询的内容中当包含通配时,将通配符做为一个普通字符处理。