星型模型和雪花模型(数据仓库设计模型)
- 格式:docx
- 大小:15.04 KB
- 文档页数:3

制造业数据仓库逻辑模型制造业数据仓库逻辑模型数据仓库是指将不同来源的数据进行整合、清洗和转换,以支持企业的决策分析和业务运营。
在制造业中,数据仓库的建立可以帮助企业更好地管理和分析生产过程中所涉及的各种数据,从而提高生产效率、降低成本、优化产品质量和增强市场竞争力。
制造业数据仓库的逻辑模型是指在数据仓库建设过程中,对于制造业特定的数据进行建模和设计的过程。
逻辑模型是数据仓库的核心,它定义了数据仓库中各个数据表之间的关系和属性,为数据仓库的实际构建提供了指导和依据。
1. 数据仓库的维度建模在制造业数据仓库的逻辑模型中,维度建模是非常重要的一部分。
维度是描述业务过程中的各个方面的属性,例如产品、时间、地点、客户等。
在制造业数据仓库中,常见的维度包括产品维度、时间维度、地点维度、客户维度、供应商维度等。
通过对这些维度进行建模,可以更好地了解制造业中各个环节的情况,从而进行决策分析和业务优化。
2. 事实表的设计事实表是制造业数据仓库逻辑模型中的另一个关键部分。
事实表是描述业务过程中所发生事件的表,例如销售订单、生产计划、库存变动等。
在制造业数据仓库中,常见的事实表包括销售事实表、生产事实表、库存事实表等。
事实表中的每一行代表一个特定的事件,行中的各个字段记录了该事件的属性和指标信息。
通过对事实表的设计,可以方便地进行各种分析和查询,从而帮助企业更好地了解和掌握制造过程中的各个环节和指标。
3. 星型模型和雪花模型星型模型和雪花模型是制造业数据仓库逻辑模型的两种常见的建模方法。
星型模型是一种简单的建模方式,其中只包含一个事实表和多个维度表,事实表和维度表之间通过外键进行关联。
星型模型的优点是结构简单、易于理解和查询。
雪花模型在星型模型的基础上进行了扩展,将维度表进一步细化,形成了多层级的关系。
雪花模型的优点是可以更好地表示业务过程中的复杂关系和层次结构。
4. 数据粒度的确定在制造业数据仓库的逻辑模型中,数据粒度的确定是非常重要的一步。

数据仓库设计与建模的星型模式与雪花模式比较引言:数据仓库在现代企业管理中起着至关重要的作用。
而在数据仓库的设计与建模过程中,星型模式与雪花模式是两种常见的数据模型。
本文将就这两种模式进行比较,并探讨它们在不同情境下的适用性。
一、什么是星型模式?星型模式是数据仓库设计中最简单、最常用的模型之一。
在星型模式中,一个中心的事实表围绕着多个维度表构成星型结构。
二、什么是雪花模式?与星型模式相比,雪花模式是一种更复杂、更灵活的数据模型。
在雪花模式中,事实表仍然是中心,但维度表之间通过额外的关联表连接在一起。
三、比较:可读性与复杂度从可读性的角度来看,星型模式比雪花模式更容易理解。
星型模式中的数据模型简单明了,因此更易于数据仓库初学者理解和使用。
而雪花模式则相对复杂一些,因为它包含更多的维度表和关联表。
四、比较:性能与灵活性在性能方面,星型模式更胜一筹。
因为星型模式的数据结构更简单,查询和分析都更快速。
而在雪花模式中,由于需要关联更多的表,查询的性能会稍差一些。
然而,在灵活性方面,雪花模式更具优势。
它提供了更多的维度表和关联表,使得数据仓库可以适应更多的复杂业务需求。
而星型模式则较为局限,可能无法满足某些特殊的业务需求。
五、比较:存储空间与规模扩展在存储空间方面,星型模式相对较少,因为它没有额外的关联表。
相比之下,雪花模式需要更多的存储空间来存储额外的关联表,因此在存储方面会占用更多的资源。
在规模扩展方面,星型模式由于简单的数据结构,易于扩展和管理。
而随着维度表的增加,雪花模式的规模扩展相对较为困难,需要更精细的设计和管理。
六、结论星型模式和雪花模式各有优劣,适用于不同的数据仓库设计和建模需求。
在数据结构简单、可读性和性能方面要求较高的情况下,星型模式是更好的选择。
而在需要更多的维度表、更灵活适应复杂业务需求以及存储空间相对充足的情况下,雪花模式则更为适合。
最后,数据仓库的设计与建模是一个复杂而关键的任务,需要结合具体情况和业务需求来选择合适的模式。

数据仓库设计与建模的星型模式与雪花模式比较数据仓库(Data Warehouse)是指集成多种不同来源、不同格式、不同结构的数据,并将其存储在一个统一的位置,以便企业进行分析和决策的过程。
在进行数据仓库的设计与建模时,有两种常见的模式可供选择,分别是星型模式和雪花模式。
本文将对这两种模式进行比较,探讨它们在不同情境下的优缺点。
1. 模式概述星型模式是指数据仓库的中心是一个事实表(Fact Table),周围围绕着多个维度表(Dimension Table)的设计结构。
事实表包含了与业务过程相关的事实数据,每个维度表则从不同角度对事实进行描述。
整个模式的结构形状类似于一个星座,因此被称为星型模式。
雪花模式在星型模式基础上进行了扩展,将维度表进一步归一化。
这意味着将维度表中的某些属性再次分拆成子维度表,形成更多层次的关系。
这样的模式结构使得数据仓库的模型更加灵活和精确,但也带来了一定的复杂性。
2. 异同比较在比较星型模式和雪花模式时,我们可以从以下几个方面进行讨论。
结构复杂性星型模式的结构相对简单,维度表和事实表之间的关联较为直接。
这使得数据检索和查询速度更快。
然而,雪花模式的结构更加复杂,维度表的层次结构增加了关联的复杂度。
因此,相较于星型模式,雪花模式的查询性能略低,但在需要更加精确分析的情况下,雪花模式更有优势。
存储效率由于雪花模式对维度表进行了归一化,消除了维度表中的重复数据,因此在存储空间利用效率上较星型模式更高。
然而,这也同时增加了数据表之间的连接和关联复杂性,使得查询时的性能稍低。
可维护性星型模式的维护相对简单。
由于其结构简洁明了,数据仓库的维护成本相对较低。
雪花模式虽然复杂,但它的归一化设计使得维度表的结构更加规范和独立,有利于维护。
然而,当数据仓库的规模增大时,雪花模式的维护工作可能会变得繁琐。
扩展性星型模式的扩展性相对较差。
如果需要增加新的维度表,需要对事实表进行扩展。
而雪花模式的扩展性较强,可以更方便地增加新的维度表,甚至可以继续进行维度表的归一化。

数据仓库建模方法论数据仓库建模是指将数据仓库中的数据按照某种标准和规范进行组织和管理的过程。
数据仓库建模方法论包括了多种方法和技术,用于帮助用户理解和分析数据仓库中的数据,从而支持决策制定和业务分析。
一、维度建模方法维度建模方法是数据仓库建模的核心方法之一,它以维度为核心,将数据按照维度进行组织和管理,从而提供给用户灵活和高效的数据查询和分析能力。
1.1 星型模型星型模型是最常见和简单的维度建模方法,它将数据仓库中的事实表和多个维度表通过共享主键的方式进行关联。
事实表包含了衡量业务过程中的事件或指标,而维度表包含了用于描述和过滤事实记录的属性。
星型模型的结构清晰,易于理解和使用,适用于绝大部分的数据仓库场景。
1.2 雪花型模型雪花型模型是在星型模型的基础上进行扩展和优化的一种模型,它通过拆分维度表中的属性,将其拆分为多个维度表和子维度表,从而使得数据仓库更加灵活和高效。
雪花型模型适用于维度表中的属性比较复杂和层次结构比较多的情况。
1.3 天际线模型天际线模型是一种比较先进和复杂的维度建模方法,它通过将事实表和维度表按照一定的规则进行分组和划分,从而实现多个星型模型之间的关联。
天际线模型适用于数据仓库中包含多个相互关联的业务过程和多个不同的粒度的情况。
二、多维建模方法多维建模方法是在维度建模方法基础上进行进一步抽象和简化的一种方法,它通过创建多维数据立方体和维度层次结构来组织和管理数据。
2.1 数据立方体数据立方体是多维建模的核心概念,它将数据按照事实和维度进行组织和管理,从而提供给用户直观和高效的数据查询和分析能力。
数据立方体包含了多个维度和度量,用户可以通过选择和组合维度和度量进行数据分析和挖掘。
2.2 维度层次结构维度层次结构是多维建模的关键技术,它通过将维度进行分层和组织,从而实现维度之间的关联和上下级关系。
维度层次结构可以有效地减少数据的冗余和复杂性,提高数据仓库的查询和分析效率。
三、模式设计方法模式设计方法是在维度建模方法和多维建模方法的基础上进行进一步的抽象和规范的一种方法,它通过定义模式和规则来组织和管理数据仓库中的数据。

数仓业务领域标准模型
在数据仓库业务领域,存在多种标准模型,包括维度模型、范式模型、星型模型、雪花模型、星座模型、Data Vault模型和Anchor模型等。
这些模型在数据存储、数据处理和分析方面具有不同的特点和适用场景。
1. 维度模型:维度模型是数据仓库中最常用的一种数据模型,由事实表和维度表组成。
事实表存储度量值,维度表存储相关属性,适用于Ad-Hoc查询和报告,方便分析多个维度之间的关系。
2. 范式模型:范式模型是关系型数据库中常用的一种数据模型,遵循数据库设计的范式理论,将数据存储在不同的表中,并通过键将它们连接起来,以避免数据冗余。
3. 星型模型:星型模型是一种基于维度模型的数据模型,由一个事实表和多个维度表组成,维度表和事实表通过外键连接。
4. 雪花模型:雪花模型是一种基于范式模型的数据模型,遵循高内聚、低耦合的原则,将不同的表分隔开来进行存储。
雪花模型适用于数据规模较小的情况,能够减少数据冗余,提高数据的完整性和一致性。
5. 星座模型:星座模型是对星型模型的扩展延伸,多张事实表共享维度表。
6. Data Vault模型:DataVault由Hub(关键核心业务实体)、Link(关系)、Satellite(实体属性)三部分组成,是Dan Linstedt发起创建的一
种模型方法论,它是在ER关系模型上的衍生,同时设计的出发点也是为了实现数据的整合,并非为数据决策分析直接使用。
7. Anchor模型:高度可扩展的模型,所有的扩展只是添加而不是修改,因此它将模型规范到6NF,基本变成了K-V结构模型。
这些标准模型在数据仓库业务领域中具有广泛的应用价值,可以根据具体业务需求选择合适的模型进行数据处理和分析。

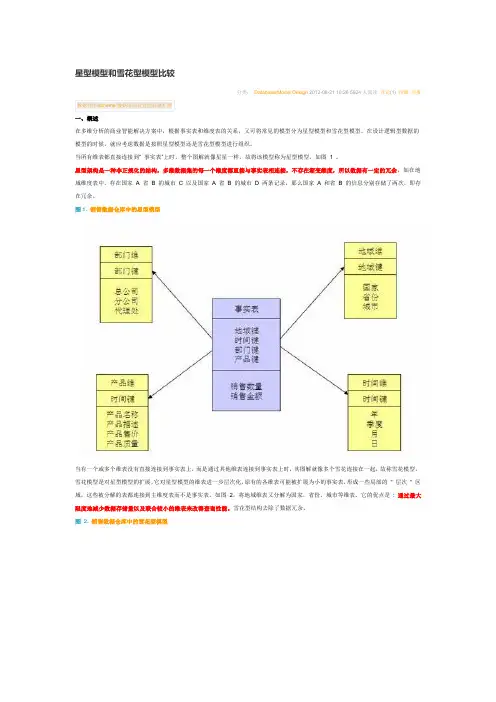
什么是星型模型和雪花型模型,以及区别⼀、概述在多维分析的商业智能解决⽅案中,根据事实表和维度表的关系,⼜可将常见的模型分为星型模型和雪花型模型。
在设计逻辑型数据的模型的时候,就应考虑数据是按照星型模型还是雪花型模型进⾏组织。
当所有维表都直接连接到“ 事实表”上时,整个图解就像星星⼀样,故将该模型称为星型模型,如图 1 。
星型架构是⼀种⾮正规化的结构,多维数据集的每⼀个维度都直接与事实表相连接,不存在渐变维度,所以数据有⼀定的冗余,如在地域维度表中,存在国家 A省 B 的城市 C 以及国家 A 省 B 的城市 D 两条记录,那么国家 A 和省 B 的信息分别存储了两次,即存在冗余。
图1.销售数据仓库中的星型模型当有⼀个或多个维表没有直接连接到事实表上,⽽是通过其他维表连接到事实表上时,其图解就像多个雪花连接在⼀起,故称雪花模型。
雪花模型是对星型模型的扩展。
它对星型模型的维表进⼀步层次化,原有的各维表可能被扩展为⼩的事实表,形成⼀些局部的 "层次 " 区域,这些被分解的表都连接到主维度表⽽不是事实表。
如图 2,将地域维表⼜分解为国家,省份,城市等维表。
它的优点是 :通过最⼤限度地减少数据存储量以及联合较⼩的维表来改善查询性能。
雪花型结构去除了数据冗余。
图 2.销售数据仓库中的雪花型模型星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此⼀般情况下效率⽐雪花型模型要⾼。
星型结构不⽤考虑很多正规化的因素,设计与实现都⽐较简单。
雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产⽣,所以效率不⼀定有星型模型⾼。
正规化也是⼀种⽐较复杂的过程,相应的数据库结构设计、数据的 ETL、以及后期的维护都要复杂⼀些。
因此在冗余可以接受的前提下,实际运⽤中星型模型使⽤更多,也更有效率。
⼆、使⽤选择星形模型(Star Schema)和雪花模型(Snowflake Schema)是数据仓库中常⽤到的两种⽅式,⽽它们之间的对⽐要从四个⾓度来进⾏讨论。

数据仓库设计与建模的星型模式与雪花模式比较在数据仓库设计与建模中,星型模式和雪花模式是两种常见的数据结构模式。
它们各自具有一定的特点和适用场景,下面将对这两种模式进行比较和分析。
一、星型模式星型模式是一种简单直观的模式,它采用星型结构,即一个中心事实表与多个维度表相连接。
中心事实表包含了业务过程中的核心事实和度量,而维度表则包含了事实表所需要的维度信息。
这种结构形成了一个星型的图形,因此得名星型模式。
星型模式的主要特点包括:1. 简单直观:星型模式的结构清晰,易于理解和维护。
2. 查询性能好:由于数据冗余较少,查询时的连接操作相对较少,查询性能较高。
3. 灵活性差:星型模式的结构较为单一,对业务需求的变化反应没有雪花模式灵活。
4. 扩展性差:当需要新增一个维度时,需要修改事实表结构,较难进行扩展。
二、雪花模式雪花模式是在星型模式的基础上进行扩展得到的一种模式,它通过将维度表进一步规范化,将复杂的维度表拆分成多个维度表和子维度表,从而形成了一个类似雪花的形状,因此得名雪花模式。
雪花模式的主要特点包括:1. 灵活性好:雪花模式可以更灵活地适应业务需求的变化,通过拆分和规范化维度表,可以更方便地进行数据维度的扩展和变更。
2. 数据冗余多:由于雪花模式中维度表的规范化,数据冗余较多,存储开销相对较大。
3. 查询性能较差:因为需要进行多次连接操作,查询性能相对较低。
4. 维护复杂:由于数据结构较为复杂,对雪花模式进行维护和更新的难度相对较大。
三、模式选择选择星型模式还是雪花模式,在实际应用中需要根据具体情况进行权衡和选择。
下面列举一些常见情况:1. 数据规模小、查询性能要求高的情况,适合选择星型模式。
星型模式由于数据冗余少、连接操作少,相对来说查询性能较好。
2. 数据规模大、灵活性要求高的情况,适合选择雪花模式。
雪花模式可以更灵活地适应业务需求的变化,便于进行数据维度的扩展和变更。
3. 数据冗余和存储开销较大的情况,适合选择星型模式。

数据仓库中的多维数据建模与查询优化技术研究数据仓库作为企业数据管理的重要工具,扮演着集成、分析和查询大量数据的关键角色。
为了更高效地使用数据仓库中的数据,多维数据建模与查询优化技术成为研究的焦点。
本文将从数据仓库中多维数据建模和查询优化两个方面进行研究。
第一部分:多维数据建模在数据仓库中,多维数据建模是数据分析和决策的基础。
多维数据建模通过定义维度、度量和维表来描述数据仓库中的数据。
以下是一些常用的多维数据模型:1. 星型模型:星型模型是最常见的多维数据模型之一。
在星型模型中,事实表位于中心,围绕它是多个维度表。
这种模型结构简单,易于理解和维护,适用于规模较小的数据仓库。
2. 雪花模型:雪花模型是星型模型的扩展,通过将维度表进一步细分为多个子表来进行优化。
雪花模型的优点是可以节省存储空间,但查询性能相对较低。
3. 网络模型:网络模型是多维数据模型的另一种变体。
在网络模型中,维度表和事实表通过连接表进行关联。
这种模型结构复杂,适用于复杂的分析场景。
在进行多维数据建模时,需要根据具体业务需求选择合适的模型。
同时,还需要考虑数据的一致性和灵活性,以支持不同层次的数据分析和各种查询。
第二部分:查询优化技术数据仓库中的查询优化是提高系统性能和用户查询响应时间的关键。
以下是一些常用的查询优化技术:1. 聚集与分区:聚集和分区通过在事实表和维度表上创建预聚集和分区索引,以加速查询性能。
聚集和分区可以减少磁盘I/O访问次数,提高查询效率。
2. 查询重写:查询重写是对用户查询进行优化和重构的技术。
通过对查询语句进行重写,可以更高效地执行查询操作。
例如,使用子查询或连接查询代替嵌套循环,减少查询时间。
3. 数据压缩:数据压缩是另一种提高查询性能的关键技术。
将数据进行压缩可以减少存储空间的占用,并提高数据的读取速度。
4. 并行处理:并行处理是一种同时处理多个查询的技术。
通过将查询任务划分为多个子任务,并在多个处理单元上并行执行,可以提高查询效率。

数据库数据仓库设计实例星型模式与雪花模式数据库数据仓库设计实例:星型模式与雪花模式数据仓库是指一个用于集成、存储和管理企业中大量历史、不同来源的数据的数据库。
在设计数据仓库时,我们需要考虑到如何最好地组织数据以满足分析和查询的需求。
星型模式和雪花模式是两种常见的数据仓库设计模式,本文将介绍它们的特点、应用场景以及优缺点。
一、星型模式星型模式是最简单和最直接的数据仓库设计模式之一。
它由一个中心的事实表和多个与之相关的维度表组成。
在星型模式中,事实表包含着企业中的业务事实,如销售金额、销售数量等。
每一条记录都与一个或多个维度表关联,维度表包含着描述业务事实的维度属性,如时间、地点、产品等。
事实表和维度表之间通过外键关联。
星型模式的主要特点是简单、易于理解和查询性能较高。
通过将数据分散到多个维度表中,星型模式提供了更好的数据查询性能。
此外,星型模式还具有较好的扩展性,因为维度表之间是独立的,并可以根据需求进行增加或修改。
然而,星型模式也有一些缺点。
首先,维度表之间的关系相对简单,无法表达一些复杂的业务关系。
其次,事实表中的数据冗余较多,可能浪费存储空间。
最后,当数据模型变得更加复杂时,星型模式的设计和维护会变得困难。
二、雪花模式雪花模式是星型模式的一种扩展,它在维度表中引入了层次结构,使得维度表不再是扁平的结构,而是具有层级关系。
在雪花模式中,维度表不仅包含维度属性,还包含了维度属性之间的关系。
这些关系通过将维度表进一步规范化来实现,使得维度表呈现出树状结构。
如一个产品维度表可以包含产品组、产品类别、产品子类等属性。
雪花模式的主要优点是可以更好地表达复杂的业务关系和层次关系。
通过规范化维度表,我们可以灵活地组织数据,并支持更复杂的分析查询。
此外,雪花模式还可以提供更好的数据一致性和维护性。
然而,雪花模式也有一些缺点。
首先,相对于星型模式而言,查询性能可能会稍差一些。
由于维度表的层次结构,查询需要多次连接和搜索。

在实施过程中,维度设计会映射到一组关系表,可以把数据库模型分为星型模型和雪花模型,下面我们分别看一下这两种不同的模型。
星型模型:
中央表包含事实数据,多个表以中央表为中心呈放射状分布,它们通过数据库的主键和外键相互连接,是一种使用关系数据库实现多维分析空间的模式,其基本形式必须实现多维空间,以使用关系数据库的基本功能。
同时星型模型也是一种非正规化的模型,多维数据集的每一个维度直接与事实表连接,没有渐变维度,所以存在冗余数据。
在星型模型中,只需要扫描事实表就可以进行查询,主要的数据都在庞大的事实表中,所以查询效率较高,同时每个维度表和事实表关联,非常直观,很容易组合出各种查询。
雪花模型:
雪花模型在星型模型的基础上,维度表进一步规范化为子维度表,这些子维度表没有直接与事实表连接,而是通过其他维度表连接到事实表上,看起来就像一片雪花,故称雪花模型。
也就是说雪花模型是星型模型的进一步扩展,将其维度表扩展为更小的维度表,形成一种层次。
这样就通过最大限度的减少数据存储量以及联合较小的维度表来改善查询性能,且去除了星型模型中的冗余数据。
星型模型和雪花模型的特点比较:
合体。
比如中间处理层,可以用雪花模型降低冗余度,在数据集市层,采用星型模型方便提取数据,提高查询效率。
星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要高。
星型结构不用考虑很多正规化的因素,设计与实现都比较简单。
雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产生,所以效率不一定有星型模型高。
正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的 ETL、以及后期的维护都要复杂一些。
因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
二、使用选择星形模型(Star Schema)和雪花模型(Snowflake Schema)是数据仓库中常用到的两种方式,而它们之间的对比要从四个角度来进行讨论。
1.数据优化雪花模型使用的是规范化数据,也就是说数据在数据库内部是组织好的,以便消除冗余,因此它能够有效地减少数据量。
通过引用完整性,其业务层级和维度都将存储在数据模型之中。
▲图1 雪花模型相比较而言,星形模型实用的是反规范化数据。
在星形模型中,维度直接指的是事实表,业务层级不会通过维度之间的参照完整性来部署。
▲图2 星形模型2.业务模型主键是一个单独的唯一键(数据属性),为特殊数据所选择。
在上面的例子中,Advertiser_ID就将是一个主键。
外键(参考属性)仅仅是一个表中的字段,用来匹配其他维度表中的主键。
在我们所引用的例子中,Advertiser_ID将是Account_dimension的一个外键。
在雪花模型中,数据模型的业务层级是由一个不同维度表主键-外键的关系来代表的。
而在星形模型中,所有必要的维度表在事实表中都只拥有外键。
3.性能第三个区别在于性能的不同。
雪花模型在维度表、事实表之间的连接很多,因此性能方面会比较低。
举个例子,如果你想要知道Advertiser 的详细信息,雪花模型就会请求许多信息,比如Advertiser Name、ID以及那些广告主和客户表的地址需要连接起来,然后再与事实表连接。
而星形模型的连接就少的多,在这个模型中,如果你需要上述信息,你只要将Advertiser的维度表和事实表连接即可。
数据仓库设计与建模的星座模型与星型模型比较传统上,数据仓库的设计与建模是数据管理和分析的关键步骤。
为了使数据仓库能够更好地支持决策和分析需求,不同的模型方法被提出和实践。
其中,星座模型和星型模型是两种常用的数据仓库设计和建模方法。
本文将对这两种模型进行比较,并讨论它们在不同环境下的适用性和局限性。
一、星座模型星座模型,也称为雪花模型,是一种以事实表为中心,围绕其展开的多维模型。
在星座模型中,事实表是数据仓库的核心,用于存储事实事件的指标数据。
而维度表则是用来描述事实表中指标的上下文信息,如时间、地点、产品等。
星座模型的主要特点是简单直观,易于理解和使用。
星座模型的优点在于:1. 数据冗余度低:通过将共同属性的维度表分离,可以减少冗余数据的存储和管理。
2. 简单的查询:星座模型的结构简单,查询性能较高,适用于快速的多维分析。
3. 灵活性强:星座模型的扩展性好,能够根据需要灵活地添加或删除维度。
然而,星座模型也存在一些限制:1. 表关系复杂:由于星座模型采用了多个维度表与一个事实表的关系,处理表关系较为复杂,增加了数据仓库的维护难度。
2. 存储空间浪费:星座模型中可能存在重复存储的问题,因为相同属性的维度可以出现在多个维度表中。
二、星型模型相对于星座模型,星型模型更加简单和直观。
在星型模型中,每个维度都有一个独立的表,而事实表则连接所有维度表。
星型模型的特点是结构清晰,易于理解和管理。
星型模型的优点包括:1. 数据模型简单:由于每个维度都有一个独立的表,星型模型的结构更加清晰明了,便于理解和管理。
2. 使用方便:星型模型的查询和分析相对简单,易于使用和操作。
然而,星型模型也有其局限性:1. 数据冗余度高:由于每个维度表都存储了冗余的数据,导致存储空间的浪费。
2. 查询性能低:与星座模型相比,星型模型在多维查询和分析方面性能相对较低。
三、适用性和局限性无论是星座模型还是星型模型,都有各自的适用场景和局限性。
数据仓库设计与建模的星座模型与星型模型比较随着信息时代的到来,数据的积累和分析成为企业决策和发展的重要依据。
数据仓库的建设成为了企业重要的信息系统之一。
在数据仓库的设计与建模中,星座模型和星型模型是常见的两种建模方法。
本文将对这两种建模方法进行比较,探讨它们的优缺点和适用范围。
一、星座模型星座模型,又称为雪花模型,是一种比较常见的数据仓库建模方法。
它通过将事实表和维度表进行规范化设计,降低了数据冗余和重复存储的问题。
在星座模型中,事实表是数据仓库中最重要的组成部分,它包含了与业务相关的度量和指标,例如销售额、利润等。
维度表则包含了业务特征或属性,例如时间、地域、产品等。
维度表通过主键与事实表进行关联,构成了一个星型结构。
星座模型的优点在于结构清晰、易于理解和维护。
由于事实表和维度表的规范化设计,数据冗余和存储问题得到了一定程度的解决。
同时,星座模型可以灵活地适应不同业务需求,可以根据需要进行维度的添加或删除,便于数据的扩展和更新。
然而,星座模型也存在一些不足之处。
首先,由于规范化设计,星座模型在处理复杂的关系和联接查询时,可能会导致性能的下降。
其次,星座模型对于多对多关系的处理比较困难,可能需要引入中间表来解决这个问题。
此外,由于维度表的数量较大,数据库的查询和维护会变得复杂,需要更多的时间和资源。
二、星型模型星型模型,是另一种常见的数据仓库建模方法。
它与星座模型的区别在于,星型模型将维度表进行了冗余存储,即将事实表和维度表通过冗余关系进行直接关联。
这种设计方法使得数据查询和联接更加简单和高效。
在星型模型中,事实表依然是数据仓库的核心,而维度表则通过冗余关系与事实表直接关联。
星型模型的优点在于简单、高效、易于理解和维护。
由于冗余关系的设计,星型模型的查询和联接操作更加方便和快速,适合处理复杂的关系和多对多的数据关联。
此外,星型模型的维护成本相对较低,由于维度表的冗余存储,减少了数据库查询和联接的负担。
数据仓库建模一、概述数据仓库建模是指根据业务需求,将原始数据进行整理、转换和存储,以便于数据分析和决策支持。
本文将详细介绍数据仓库建模的标准格式,包括数据仓库架构、维度建模和事实表设计等方面的内容。
二、数据仓库架构1. 数据仓库层次结构数据仓库通常由三层构成:操作型数据层、数据仓库层和数据展示层。
操作型数据层用于存储原始数据,数据仓库层用于存储经过整理和转换的数据,数据展示层用于展示数据分析结果。
2. 数据仓库模型数据仓库模型采用星型模型或者雪花模型。
星型模型由一个中心的事实表和多个维度表组成,每一个维度表与事实表通过外键关联。
雪花模型在星型模型的基础上,将维度表进一步规范化,形成多个层次的维度表。
三、维度建模1. 维度表设计维度表包含业务过程中的维度属性,如时间、地点、产品等。
每一个维度表应包含一个主键和多个属性列,属性列用于描述维度的特征。
主键与事实表进行关联。
2. 事实表设计事实表包含业务过程中的度量指标,如销售额、订购数量等。
每一个事实表应包含一个主键和多个度量列,度量列用于存储度量指标的数值。
主键与维度表进行关联。
3. 维度建模技巧维度建模过程中,需要注意以下几点:- 维度表应具备高度可重用性,便于在不同的事实表中使用。
- 维度表的属性列应具备高度一致性和完整性,便于数据分析和查询。
- 维度表的属性列应具备高度可扩展性,便于根据业务需求进行扩展。
四、事实表设计1. 事实表类型事实表分为事务型事实表和积累型事实表。
事务型事实表记录每一个业务事件的详细信息,积累型事实表记录业务事件的累计值。
2. 事实表度量粒度事实表度量粒度应根据业务需求进行确定。
普通情况下,度量粒度应尽可能细化,以便于进行更详细的数据分析。
但也需要考虑数据存储和查询效率的问题。
3. 事实表的度量指标事实表的度量指标应根据业务需求进行确定。
度量指标应具备可度量性、可加性和可分解性等特性,便于进行数据分析和计算。
五、数据仓库建模工具数据仓库建模过程中,可以使用一些建模工具辅助设计和管理数据仓库,如PowerDesigner、ERwin等。
数据仓库中的数据模型设计与优化数据仓库是指将企业的各种数据进行整合、清洗和加工,形成供决策支持和分析的统一数据源。
而数据模型设计是数据仓库开发的重要环节,它决定了数据仓库的结构、组织方式和性能优化。
一、数据仓库的设计原则1.1 单一事实表数据仓库通常由事实表和维度表组成,事实表记录了业务中的主要事实和指标,而维度表则用于描述事实所处的背景信息。
在数据模型设计中,一个明确的原则是尽量将事实表设计为单一的,即每个事实表只包含一种类型的事实。
这样可以避免冗余的数据和复杂的关联关系,提高查询性能。
1.2 星型模型和雪花模型在数据模型设计中,常用的两种模型是星型模型和雪花模型。
星型模型采用了以一个或多个事实表为中心,周围围绕着多个维度表构成的星形结构,简洁明了,易于理解和查询。
而雪花模型在星型模型的基础上进一步标准化了维度表,将其拆分成多张表,从而减少数据冗余。
选择采用哪种模型需要根据具体业务需求和数据特点做出合理的判断。
1.3 维度的层次结构维度表是数据仓库中最重要的组成部分,它用于描述事实所处的背景信息,如时间、地理位置、产品等。
在维度表的设计中,一个重要的考虑因素是维度的层次结构。
比如时间维度可以按照年、季度、月等层次进行划分,产品维度可以按照品类、品牌、型号等层次进行划分。
合理的维度层次结构可以提高数据仓库的查询效率和用户体验。
二、数据模型设计的优化技巧2.1 行列存储在数据仓库中,数据通常以行为单位进行存储和查询。
然而,当数据量达到一定规模时,行存储方式会造成大量的IO操作和数据冗余。
为了提高查询效率和节省存储空间,可以采用列存储的方式,即将相同列的数据连续存储在一起,从而减少IO操作和数据冗余。
2.2 分区和分桶数据仓库中的数据量通常非常庞大,为了提高查询效率,可以采用分区和分桶的技术。
分区是指将数据按照某个规则划分成多个逻辑部分,如按照时间、地理位置等划分。
而分桶是指在每个分区中将数据再划分成多个小的数据块,从而减小每次查询的数据量。
数据仓库设计与建模的星座模型与星型模型比较在数据仓库的设计与建模中,星座模型和星型模型是两种常见的建模方式。
本文将对两种模型进行比较,并探讨它们各自的特点、适用场景以及优缺点。
1. 星座模型(Snowflake Model)星座模型是一种多维数据结构,通过将一个维度分解成多个表来实现,每个表包含一个维度的不同层次。
这种分解可以减少冗余数据,在某些情况下提供更高的查询性能。
星座模型将维度按照具体层级进行规范化,使得维度的关系更加清晰。
例如,在一个销售数据仓库中,星座模型可能将“产品”维度拆分成“产品类别”、“产品子类别”和“产品”的三个表。
这样,可以更加灵活地进行查询和分析,同时减少了存储空间的使用。
星座模型适用于维度层次较多、维度之间关系复杂的情况。
它的优点包括:- 结构清晰:通过规范化维度表,星座模型使数据仓库的结构更加清晰易懂,便于维护和管理。
- 灵活性高:由于每个维度都可以单独查询,星座模型允许用户根据具体需求自由组合维度,进行灵活的数据分析。
- 存储效率高:星座模型通过减少冗余数据来提高存储效率,减少了不必要的存储开销。
- 数据更新复杂:由于维度的规范化,当需要更新维度数据时,需要同时更新多张表,增加了数据更新的复杂性。
- 查询性能不稳定:在某些情况下,由于多张表之间的关联操作,星座模型可能导致查询性能不稳定,特别是对于复杂查询。
2. 星型模型(Star Model)星型模型是一种层次化的数据结构,将事实表与多个维度表通过外键进行连接,形成一个中心的事实表与多个维度表之间的星状结构。
星型模型将事实和维度分离,将计算型数据和描述型数据分开存储,使得数据仓库更加适用于分析与报表功能。
以销售数据仓库为例,星型模型将“产品”、“时间”和“地区”等维度表与“销售事实”表通过外键关联。
这样,可以通过事实表快速查询到各个维度的对应数据,进行精确的数据分析和报表生成。
星型模型适用于维度相对简单、维度之间关系较为简单的情况。
星形模型和雪花模型星形模型和雪花模型数据仓库是多维数据库,它扩展了关系数据库模型,以星形架构为主要结构方式的,并在它的基础上,扩展出理论雪花形架构和数据星座等方式,但不管是哪一种架构,维度表、事实表和事实表中的量度都是必不可少的组成要素1 星形架构星形模型是最常用的数据仓库设计结构的实现模式,它使数据仓库形成了一个集成系统,为最终用户提供报表服务,为用户提供分析服务对象。
星形模式通过使用一个包含主题的事实表和多个包含事实的非正规化描述的维度表来支持各种决策查询。
星形模型可以采用关系型数据库结构,模型的核心是事实表,围绕事实表的是维度表。
通过事实表将各种不同的维度表连接起来,各个维度表都连接到中央事实表。
维度表中的对象通过事实表与另一维度表中的对象相关联这样就能建立各个维度表对象之间的联系。
每一个维度表通过一个主键与事实表进行连接。
事实表主要包含了描述特定商业事件的数据,即某些特定商业事件的度量值。
一般情况下,事实表中的数据不允许修改,新的数据只是简单地添加进事实表中,维度表主要包含了存储在事实表中数据的特征数据。
每一个维度表利用维度关键字通过事实表中的外键约束于事实表中的某一行,实现与事实表的关联,这就要求事实表中的外键不能为空,这与一般数据库中外键允许为空是不同的。
这种结构使用户能够很容易地从维度表中的数据分析开始,获得维度关键字,以便连接到中心的事实表,进行查询,这样就可以减少在事实表中扫描的数据量,以提高查询性能。
星形模式虽然是一个关系模型,但是它不是一个规范化的模型。
在星形模式中,维度表被故意地非规范化了,这是星形模式与OLTP系统中关系模式的基本区别。
使用星形模式主要有两方面的原因:提高查询的效率。
采用星形模式设计的数据仓库的优点是由于数据的组织已经过预处理,主要数据都在庞大的事实表中,所以只要扫描事实表就可以进行查询,而不必把多个庞大的表联接起来,查询访问效率较高,同时由于维表一般都很小,甚至可以放在高速缓存中,与事实表进行连接时其速度较快,便于用户理解;对于非计算机专业的用户而言,星形模式比较直观,通过分析星形模式,很容易组合出各种查询。
We are often told that one of the benefits of OBI EE is the speed and ease of development. Data sources can easily be added into the system, users can then quickly build queries and the results are easy to distribute. While I completely support this, to me this leaves a few questions when you go beyond the slick sales demos: do we need a Data Warehouse? How do we deal with data quality? How do we test? How do we ensure our great looking reports get from our development environment to our production environment and still display the same data?This posting just concentrates on the Data Warehouse. Think of the project if we didn’t need a Data Warehouse, initially in terms of cost: no database license required, no ETL/Data Warehouse development required, no ongoing maintenance and maybe in the eyes of the business no black hole of money and time where the hairy developers go away, grumble about data quality and take longer than everyone thought. Think of all this new way from a business point of view: there is a new reporting requirement, they sit down with a business analyst, add the data source into the physical and then business model, graphically create the joins, and 10 minutes later the data is on the CEO’s dashboard, marvelous, and not a hairy developer type to be found anywhere in the process, so no cost and no hold-ups. But wait a minute: why have we been spending money developing Data Warehouses over the past couple of decades?What was the Data Warehouse actually doing?For starters, they prevented queries being run against the live transactional systems. Query and analysis tools can be very powerful, and hence can generate complex queries. If each of these queries was being run against the live systems then performance would be impacted, plus the reporting system would be dependent on all the systems being live all the time. Thus loading all the data into a ‘reporting database’ protected the transactional systems.(我们应该防止SQL query直接在我们的transactional systems 上运行,这样会影响我们的application system)But what about our real-time Data Warehouse, managers need up to the minute information to make informed decisions? Real-time Data Warehouses can be a double-edged sword, it is great to have up the minute information, but the downside is that reports keep on changing; it becomes more difficult to reconcile information or to get a consistent view of the organization. Sometimes it is actually useful to have a static view of the data for 24 hours. Real-time Data Warehousing can also be implemented using replication features like Change Data Capture in the database if required.Data Warehouses also offer a number of functional advantages:They can store historic data that may have been archived from the transactional system.They can store the history of dimensions, so facts can be correctly categorized when they happened.They can store data from different systems.They can store the data in a way that makes it easy and efficient for users to query, this means that a large volume of data can be accessed and used effectively.They can use features like partitioning, bitmap indexes, and materialized views to further speed up those queries.What were those hairy developers actually doing?They are writing ETL programs (or using a tool to) transforming the data from a number of disparate systems, and possibly a number of disparate organisations so that it can be presented in a unified model. This process can be easy for a small young company, however for larger company; with a history of acquisition this is far more complex. The reason this process can take such a long time is that it can be very hard to combine data from different systems. In the world of OBI EE we would create a join between the different tables – this is great in theory, but only really works if the keys are aligned between the systems. Generally they are not. Add to this the fact that the data qualities maybe of poor quality and suddenly you find that the join is ‘losing’ a large number of records, or they are being incorrectly categorized.The ETL process, and the hairy developers, will address this process and actually get in a state it can be compared across systems. I have worked on projects where the ETL team have lead/driven the business in the whole data quality and cleansing process.So to turn the argument on its head, if we can do all this with the ETL process and in our Data Warehouse, and this does add value, why are we hacking things together in OBI EE, surely then everything should be done at the back end? Again there is some truth in this, if we are going to define complex time series calculations, and we can do them during the ETL phase, then it supports the ‘one version of the truth’, it means everyone will be using the same calculation and it can be rigorously tested.If we had no constraints on time or money we may do everything at the back-end, or in the ETL, however the reality of it is that there just isn’t time (or money), or we often don’t know what the requirements are until later in the project. If we have written the ETL code and it is tested and working correctly and the business decides it needs another calculation then it may be a lot more practical to write it in situ in the report, or in the business model than to rework (and hence retest) the ETL code.(不能将所有的工作都放在ETL mapping当中做)This is where OBI EE and an iterative development methodology come in. In a typical BI/DW project requirements are initially stated at the outset of the project, then they are then added to, changed and refined throughout the process. Users do not know what they want to report against until they see the data in a report in front of them – it is only then can they see the possibilities. To take the example of the calculation and how this could be implemented using this methodology and OBI EE: initially it could be prototyped directly in Answers. It could then be reviewed, refined and tested. Once agreed the calculation could be added to the business model, this way it would be available to all the users and they could add it to reports, this may lead to changes, or finding cases where it doesn’t work correctly. If the calculation becomes a core part of the system, is found to be stable and performance could be improved by materializing it, then it may be added to the Data Warehouse and hence the ETL code. We find that as the requirement becomes more stable it filters fromfront-end tools back into the database Data Warehouse.This gives us the foundation of our methodology for approaching projects. It is initially important to gather and then implement/prototype the core or high priority requirements in the first few iterations of development, our understanding of these requirements only needs to be ‘good enough’ at this point and it is important to get them in front of the users. OBI EE can be used to do this. As they are then reviewed and refined they can be incorporated further into the system.Once we requirements reach a certain stability they can be passed back toward the back-end of the system on future development iterations. This means that the more complex coding tasks, the ones that take time can be carried out on better understood requirements. This is where the Data Warehouse fits in and where it still can and does add value.Importantly OBI EE gives us the ability to handle these changes seamlessly, we can change the physical objects supporting the business model. Mark wrote a series of postings about this process entitled Migrating OBIEE Logical Models to use a Data Warehouse, these describe how to re-wire the business model to a Data Warehouse.So this means that old school ways, such as Data Warehousing, are not dead, interesting the latest Kimball Design Tip (I think you have to subscribe to get access –it’s free) discusses how names of the concepts of what we now call BI&DW have changed. What will make a project successful is finding a balance between how to optimally use each of the technologies, depending on user requirements, complexity and quality of source data and a myriad of other factors, and most importantly having a methodology that can stitch these approaches together.。