iostat命令详解
- 格式:doc
- 大小:30.50 KB
- 文档页数:2

Linux高级系统调优使用perf和sysstat工具Linux是一种开放源代码的操作系统,具有很强的可定制性和可扩展性,因此被广泛应用于服务器和高性能计算领域。
随着软硬件技术的不断进步,对Linux系统的性能优化需求也越来越高。
在这篇文章中,我们将介绍如何使用perf和sysstat工具进行Linux高级系统调优。
一、perf工具的介绍和使用perf工具是Linux上的性能分析工具,可以对系统的各种资源进行跟踪和分析,以帮助开发人员深入了解系统的运行情况。
下面我们将介绍几个常用的perf命令。
1. perf topperf top命令可以显示当前运行进程中的资源消耗最多的函数,以及它们在代码中的位置。
这对于快速定位性能瓶颈非常有用。
2. perf recordperf record命令可以跟踪指定进程或命令的系统调用和函数调用,生成一个数据文件用于后续的分析。
例如,可以使用以下命令跟踪一个名为"example"的进程的系统调用:perf record -p example3. perf reportperf report命令可以分析perf record生成的数据文件,并以报告的形式展示各种性能指标。
它可以展示函数的调用关系、执行时间、资源占用等信息,帮助我们全面理解系统的性能状况。
二、sysstat工具的介绍和使用sysstat工具是Linux上的系统状态统计工具,可以收集和分析系统的各种资源使用情况,如CPU、内存、磁盘和网络等。
下面我们将介绍几个常用的sysstat命令。
1. sarsar命令用于收集和报告系统的各种资源使用情况,可以显示CPU 的利用率、内存的使用情况、磁盘的IO等信息。
例如,可以使用以下命令显示CPU的利用率和平均负载:sar -u2. iostatiostat命令用于显示磁盘IO的情况,可以查看磁盘的读写速度、IO 等待时间等信息。
例如,可以使用以下命令显示磁盘的IO情况:iostat -d3. mpstatmpstat命令用于显示多核CPU的利用率,可以查看每个核心的平均负载、用户态和内核态的CPU时间等信息。

Mac命令行中的系统监测和故障排除技巧在Mac命令行中,系统监测和故障排除是每个Mac用户都应该掌握的重要技能。
使用命令行可以更深入地了解系统的状态和性能,以及发现和解决潜在的问题。
本文将介绍一些常用的Mac命令行工具和技巧,帮助您监测系统并排除故障。
## 一、系统状态监测1. `top`命令:通过运行`top`命令可以实时监测系统中正在运行的进程和它们的资源消耗情况。
可以查看CPU利用率、内存使用情况以及磁盘IO等信息。
2. `htop`命令:`htop`是`top`的改进版本,提供了更友好的界面和更多的功能。
可以通过包管理器(如Homebrew)安装并使用`htop`命令。
3. `iostat`命令:`iostat`命令用于监测磁盘IO情况。
可以使用`iostat -d disk0`命令查看特定磁盘的IO性能。
4. `vm_stat`命令:`vm_stat`命令用于监测内存使用情况。
可以查看分页、压缩和空闲内存等信息,帮助您了解系统内存的状况。
5. `nettop`命令:`nettop`命令可以监测网络流量情况,包括每个进程的网络使用情况、连接状态等。
可以使用`nettop -P -L 1`命令实时查看网络活动。
## 二、进程管理和故障诊断1. `ps`命令:`ps`命令用于查看系统中正在运行的进程。
可以使用`ps aux`命令查看所有进程的详细信息,并通过进程标识符(PID)来终止或控制特定进程。
2. `kill`命令:`kill`命令用于终止正在运行的进程。
可以使用`kill PID`命令通过进程标识符终止特定进程。
添加`-9`参数可以强制终止进程。
3. `top`命令:前面提到的`top`命令不仅可以监测系统状态,还可以通过交互式界面来终止进程。
在`top`界面中按下`k`键,然后输入进程的PID和终止信号即可终止进程。
4. `lsof`命令:`lsof`命令用于列出当前系统打开的文件和网络连接。
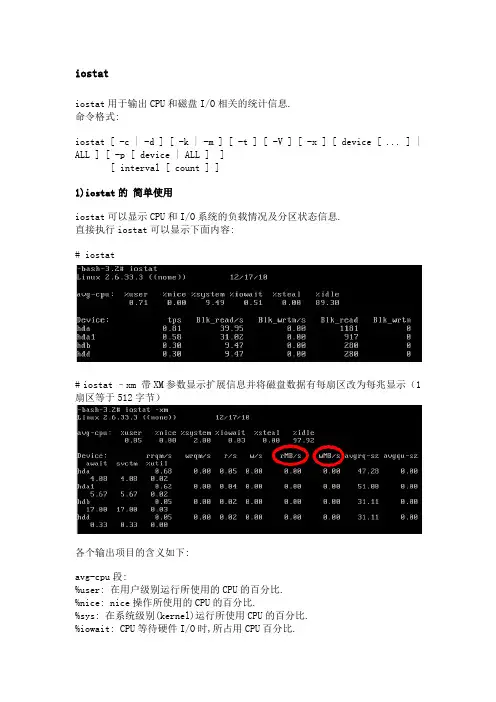
iostatiostat用于输出CPU和磁盘I/O相关的统计信息.命令格式:iostat [ -c | -d ] [ -k | -m ] [ -t ] [ -V ] [ -x ] [ device [ ... ] | ALL ] [ -p [ device | ALL ] ][ interval [ count ] ]1)iostat的简单使用iostat可以显示CPU和I/O系统的负载情况及分区状态信息.直接执行iostat可以显示下面内容:# iostat# iostat –xm 带XM参数显示扩展信息并将磁盘数据有每扇区改为每兆显示(1扇区等于512字节)各个输出项目的含义如下:avg-cpu段:%user: 在用户级别运行所使用的CPU的百分比.%nice: nice操作所使用的CPU的百分比.%sys: 在系统级别(kernel)运行所使用CPU的百分比.%iowait: CPU等待硬件I/O时,所占用CPU百分比.%idle: CPU空闲时间的百分比.Device段:tps: 每秒钟发送到的I/O请求数.Blk_read /s: 每秒读取的block数.Blk_wrtn/s: 每秒写入的block数.Blk_read: 读入的block总数.Blk_wrtn: 写入的block总数.2)iostat参数说明iostat各个参数说明:-c 仅显示CPU统计信息.与-d选项互斥.-d 仅显示磁盘统计信息.与-c选项互斥.-k 以K为单位显示每秒的磁盘请求数,默认单位块.-p device | ALL与-x选项互斥,用于显示块设备及系统分区的统计信息.也可以在-p后指定一个设备名,如:# iostat -p hda或显示所有设备# iostat -p ALL-t 在输出数据时,打印搜集数据的时间.-V 打印版本号和帮助信息.-x 输出扩展信息.3)iostat输出项目说明Blk_read读入块的当总数.Blk_wrtn写入块的总数.kB_read/s每秒从驱动器读入的数据量,单位为K.kB_wrtn/s每秒向驱动器写入的数据量,单位为K.kB_read读入的数据总量,单位为K.kB_wrtn写入的数据总量,单位为K.rrqm/s将读入请求合并后,每秒发送到设备的读入请求数.wrqm/s将写入请求合并后,每秒发送到设备的写入请求数.r/s每秒发送到设备的读入请求数.w/s每秒发送到设备的写入请求数.rsec/s每秒从设备读入的扇区数.wsec/s每秒向设备写入的扇区数.rkB/s每秒从设备读入的数据量,单位为K.wkB/s每秒向设备写入的数据量,单位为K.avgrq-sz发送到设备的请求的平均大小,单位是扇区.avgqu-sz发送到设备的请求的平均队列长度.awaitI/O请求平均执行时间.包括发送请求和执行的时间.单位是毫秒.svctm发送到设备的I/O请求的平均执行时间.单位是毫秒.%util在I/O请求发送到设备期间,占用CPU时间的百分比.用于显示设备的带宽利用率.当这个值接近100%时,表示设备带宽已经占满.。

iostat用法1. 介绍iostat是一个用于监控系统输入输出(I/O)性能的命令行工具。
它提供了有关磁盘、网络和CPU等设备的关键性能指标,可以帮助系统管理员进行性能优化和故障排除。
2. 安装和使用安装iostat通常是sysstat软件包的一部分,因此在大多数Linux发行版中都预装了该工具。
如果你的系统上没有安装iostat,你可以使用以下命令安装:# Ubuntu/Debiansudo apt-get install sysstat# CentOS/RHELsudo yum install sysstat使用要使用iostat命令,只需在终端中输入以下命令:iostat [选项] [时间间隔] [次数]•选项:iostat支持多个选项,用于指定要显示的特定信息。
常用选项包括:–-c:显示CPU利用率。
–-d:显示磁盘利用率。
–-n:显示网络利用率。
–-x:显示扩展统计信息,如每个设备的平均队列长度和服务时间等。
•时间间隔:指定统计信息更新的时间间隔,以秒为单位。
默认情况下,时间间隔是1秒。
•次数:指定要显示统计信息的次数。
默认情况下,iostat会持续显示统计信息,直到用户手动中断。
以下是一些常用的iostat命令示例:•显示CPU利用率:iostat -c•显示磁盘利用率:iostat -d•显示网络利用率:iostat -n•显示扩展统计信息:iostat -x•指定时间间隔和次数:iostat 5 3以上命令将每5秒显示一次统计信息,共显示3次。
3. 输出解读iostat的输出包含了各种关于系统性能的指标。
下面是一些常见的输出字段解读:•CPU利用率(%usr、%nice、%sys、%iowait、%irq、%soft、%steal、%guest、%gnice、%idle):–%usr:用户空间进程所占的CPU时间百分比。
–%nice:优先级较低的用户空间进程所占的CPU时间百分比。

报告中央处理器(CPU)的统计信息,整个系统、适配器、tty 设备、磁盘以及CD-ROM 的异步输入/输出(AIO)和输入/输出统计信息。
语法iostat [ -a ] [ -l ] [ -s ] [-t ] [ -T ] [ -z ] [ { -A [ -P ] [ -q | -Q ] } | { -d |-D [-R ] }[ -m ] [ Drives ... ] [ Interval] [ Count ]描述iostat 命令用来监视系统输入/输出设备负载,这通过观察与它们的平均传送速率相关的物理磁盘的活动时间来实现。
iostat 命令生成的报告可以用来更改系统配置来更好地平衡物理磁盘和适配器之间的输入/输出负载。
每次运行iostat 命令时,就报告所有的统计信息。
报告由tty and CPU 标题行以及接下来的tty 或异步I/O 和CPU 统计信息行组成。
在多处理器系统上,CPU 统计信息是系统范围计算的,是所有处理器的平均值。
带有系统中当前活动的CPU 数量和活动的磁盘数量的眉行显示在输出结果的开始部分。
如果指定-s 标志,则显示系统眉行,接下来的一行是整个系统的统计信息。
系统主机名显示在系统眉行中。
如果指定-a 标志,就会显示一个适配器头行,随后是一行适配器的统计信息。
这后面将回有一个磁盘头行和连接到适配器的所有磁盘/CD-ROM 的统计信息。
为所有与系统连接的磁盘适配器生成这种报告。
显示一个磁盘头行,随后是一行配置的磁盘的统计信息。
如果指定PhysicalVolume 参数,则只显示那些指定的名称。
如果指定PhysicalVolume 参数,则可以指定一个或者更多的字母或者字母数字的物理卷。
如果指定PhysicalVolume 参数,就会显示tty 和CPU 报告并且磁盘报告包含指定驱动器的统计信息。
如果没有发现指定逻辑驱动器名,则报告将列出指定的名称并且显示没有找到驱动器的消息。


1.确定磁盘使用率$ iostat -T 2 10System configuration: lcpu=8 drives=29 paths=52 vdisks=0tty: tin tout avg-cpu: % user % sys % idle % iowait time0.0 377.0 77.6 6.1 16.2 0.1 11:35:45Disks: % tm_act Kbps tps Kb_read Kb_wrtn timehdisk5 78.0 6080.0 439.0 12048 112 11:35:45hdisk4 79.5 11856.5 453.5 23564 149 11:35:45hdisk6 19.0 1664.0 13.0 3328 0 11:35:45$% tm_act 物理磁盘活动的时间百分比KBPS 某块磁盘传输数据的总量(读或写)tps 某块物理磁盘每秒钟IO 传输的数量Kb_read 从磁盘上读取数据的总量Kb_wrtn 写入磁盘的数据总量如果%tm_act 字段显示磁盘非常忙,并且Kbps 字段显示持续的大量数据传输,应考虑散布数据跨越多个磁盘。
该命令支持动态的配置改变。
如果发现到配置改变,iostat 报告发出一个警告,并刷新最新的系统配置。
其中% tm_act是指活动时间,kbps是在统计时间内所有Kb_read与Kb_wrtn之和除以时间的值,即每秒传输的字节数如果% tm_act常过70%却只有很低的Kbps,系统可能是有比较多的LV碎片或文件碎片,当都高时则系统正常。
tps表示每秒的IO数,不同的磁盘系统其可承受的IO数不同。
如果一块磁盘的活动率超过70%,可以通过转移一部分的磁盘活动压力到另一个磁盘上,或者通过多个磁盘驱动器来扩展I/O压力来获得更高的性能。
$ iostat -D hdisk0 (查看某一磁盘的情况)System configuration: lcpu=8 drives=29 paths=52 vdisks=0hdisk0 xfer: %tm_act bps tps bread bwrtn4.6 58.3K 8.8 16.5K 41.9Kread: rps avgserv minserv maxserv timeouts fails3.5 5.8 0.3 67.8 0 0write: wps avgserv minserv maxserv timeouts fails5.3 11.2 0.6 114.9 0 0queue: avgtime mintime maxtime avgwqsz avgsqsz sqfull136.8 0.0 388.4 0.2 0.0 3.8--------------------------------------------------------------------------------如果使用启用多路径I/O [multi-path input-output (MPIO)]的设备,可使用iostat -m 命令显示每条相关路径的统计信息。

linux 查看读写磁盘的函数
在Linux系统中,有多种命令和工具可以用来查看磁盘的读写情况。
以下是一些常用的方法:
1. 使用 iostat 命令。
iostat 是一个用于监视系统磁盘活动的命令行工具。
可以使用以下命令来安装 iostat:
sudo apt install sysstat # for Ubuntu/Debian.
sudo yum install sysstat # for CentOS/RHEL.
然后可以使用以下命令来查看磁盘的读写情况:
iostat -x 1。
这个命令将每秒更新一次磁盘活动情况,包括每个磁盘的读写速度、I/O等待时间等信息。
2. 使用 vmstat 命令。
vmstat 是一个用于监视系统虚拟内存、进程、磁盘、CPU 活动的命令行工具。
可以使用以下命令来查看磁盘的读写情况:
vmstat 1。
这个命令将每秒更新一次系统整体的活动情况,包括磁盘的读写情况。
3. 使用 sar 命令。
sar 是一个系统活动报告工具,可以用来收集、报告、保存系统活动情况,包括磁盘的读写情况。
可以使用以下命令来安装sar:
sudo apt install sysstat # for Ubuntu/Debian.
sudo yum install sysstat # for CentOS/RHEL.
然后可以使用以下命令来查看磁盘的读写情况:
sar -d 1。
这个命令将每秒更新一次磁盘的读写情况。
以上是一些常用的方法来查看Linux系统中磁盘的读写情况的命令和工具。
希望这些信息对你有所帮助。

macOS终端命令中的系统性能监控指令在使用macOS系统时,终端命令是一个强大的工具,可用于执行各种任务和调整系统设置。
除了常见的命令外,macOS终端还提供了一些系统性能监控指令,可以帮助我们实时了解和管理系统的运行状态。
本文将介绍几个常用的系统性能监控指令,并演示其用法。
1. toptop命令是一个实时的系统监控指令,可用于查看系统的进程和资源占用情况。
在终端中输入"top"命令后,会显示一个动态的进程列表,其中包含进程的ID、CPU使用率、内存占用等信息。
可以使用键盘上的“q”键退出top命令。
2. vm_statvm_stat命令用于显示系统虚拟内存的统计信息,包括页面大小、空闲页面数量、活跃和非活跃页面数量等。
通过运行"vm_stat"命令,可以得到一个详细的内存统计报告。
该命令特别适用于检测内存压力和内存泄漏等问题。
3. iostatiostat命令可用于监控系统的磁盘输入输出性能。
通过输入"iostat"命令,可以获取磁盘的平均响应时间、传输速率和读写次数等信息。
此外,iostat命令还可以显示CPU使用率和网络传输速率等相关信息。
4. nettopnettop命令用于查看系统的网络活动情况。
通过输入"nettop"命令,可以获得一个实时的网络流量监控界面,显示当前连接的进程、传输速率、数据包数量等信息。
使用"nettop"命令可以帮助我们追踪应用程序的网络使用情况,以及检测潜在的网络问题。
5. sarsar命令是一个强大的系统性能监控工具,可以提供关于CPU、内存、磁盘、网络等方面的详细统计信息。
通过运行"sar"命令,可以定期收集和显示系统资源的使用情况,同时还可以生成报告和图表,以便进一步分析和调优系统性能。
6. activity monitor虽然activity monitor不是一个终端命令,但它是macOS系统自带的一个图形化系统监控工具,可提供更直观和详细的系统性能信息。

Linux中查看CPU、内存和IO的占⽤情况对于服务器的监控,主要还是查看CPU、内存以及IO的占⽤情况,在此做个简单的了解⼀、常⽤命令1、top命令top命令应该是使⽤⽐较多的⼀个,可以看到CPU和内存的占⽤情况以及进程的PID,进⼊top页⾯后,⼤写的字母P和M分别是按照CPU占⽤和内存占⽤排序显⽰。
2、free命令free命令在查看内存使⽤情况是也是⽤的⽐较多。
3、ps命令ps -aux | sort -k4nr | head -Nhead -N可以指定显⽰的⾏数,默认显⽰10⾏。
ps -aux中参数a指all,即所有的进程;u指userid,即执⾏该进程的⽤户id;x指显⽰所有程序,不以终端机来区分。
sort -k4nr中k代表根据哪⼀个关键词排序,后⾯的数字4表⽰按照第四列排序;n代表numberic sort,指根据其数值排序;r代表reverse,指反向⽐较结果,因为输出时默认是从⼩到⼤,⽤了反向后就是从⼤到⼩。
上述命令%MEM是第四列,故是按照内存占⽤情况列举内存占⽤最多的N⾏进程;%CPU是第三列,查看CPU占⽤情况的话,⽤k3即可。
4、iostat命令以磁盘为单位查看io情况,个⼈常⽤iostat -xdm 1来查看5、pidstat命令统计进程的状态,⾃然也包括进程的IO状况,个⼈常⽤pidstat -urd 1-u:CPU使⽤率-r:缺页及内存信息-d:IO信息-t:有需要的话也可以以线程为统计单位查看进程IO状况的还有iotop命令⼆、如何在发⽣OOM时⾃动dump内存快照1、问题背景在运维服务器的时候会遇到⼀些java进程报错“ng.OutOfMemoryError”然后进程死掉的情况,对于Java我了解的不多,但是当问题发⽣的时候起码需要知道是什么对象太多导致的OOM,所以在发⽣OOM时能有⼀份dump内存快照对于排查问题就很重要了。
2、配置当发⽣OOM时,进程会死掉,但是并不是说是JVM完全来不及处理然后就突然进程就没了,也就是说这个机制不是JVM⾃⼰触发的,是受到控制的。

fortran中iostat的用法在Fortran中,iostat是一个非常重要的内置函数,用于获取输入和输出状态。
它提供了有关输入和输出操作的信息,例如输入和输出操作的次数、等待时间和错误状态等。
iostat函数在Fortran程序中非常有用,因为它可以帮助我们更好地理解程序执行过程中输入和输出操作的性能。
要使用iostat函数,需要将其与循环结构和条件语句相结合,以便在需要时获取输入和输出状态。
下面是一个简单的示例程序,演示了如何使用iostat函数获取输入和输出状态:```fortranprogramiostat_exampleimplicitnoneinteger::ios,iostat,count=0!打开文件以进行输入操作open(unit=10,file="input_file.txt",status="old",iostat=iostat)if(iostat/=0)thenprint*,"Erroropeninginputfile"stopendif!循环读取输入文件中的数据,并使用iostat函数获取状态信息dowhile(1)read(10,*,iostat=iostat)data_valueif(iostat/=0)thenprint*,"Endoffilereached"exitendifcount=count+1if(count==10)then!等待一段时间后再次读取数据pause'Waitforawhile'count=0endifenddo!关闭文件以进行输出操作close(10,iostat=iostat)if(iostat/=0)thenprint*,"Errorclosingfile"stopendifendprogramiostat_example```在上面的示例程序中,我们首先使用open语句打开一个文件以进行输入操作。
Linux 系统由若干主要物理组件组成,如CPU、内存、网卡和存储设备。
要有效地管理Linux 环境,您应该能够以合理的精度测量这些资源的各种指标—每个组件处理多少资源、是否存在瓶颈等。
下面我们介绍下linux资源监控有关的一些命令:内存:top、free、vmstat、mpstat、iostat、sar、pmapCPU :top、vmstat、mpstat、iostat、sarI/O :vmstat、mpstat、iostat、sar进程:ipcs、ipcrm系统运行负载:uptime、w1,top运行top 命令后,CPU 使用状态会以全屏的方式显示,并且会处在对话的模式–用基于top 的命令,可以控制显示方式等等。
退出top 的命令为q (在top 运行中敲q 键一次)。
作用:top命令用来显示执行中的程序进程,使用权限是所有用户。
格式:top [-] [d delay] [q] [c] [S] [s] [i] [n]主要参数:d:指定更新的间隔,以秒计算。
q:没有任何延迟的更新。
如果使用者有超级用户,则top命令将会以最高的优先序执行。
c:显示进程完整的路径与名称。
S:累积模式,会将己完成或消失的子行程的CPU时间累积起来。
s:安全模式。
i:不显示任何闲置(Idle)或无用(Zombie)的行程。
n:显示更新的次数,完成后将会退出top。
第一行表示的项目依次为当前时间、系统启动时间、当前系统登录用户数目、平均负载(最近1,5,15分钟)。
第二行显示的是所有启动的进程、目前运行的、挂起(Sleeping)的和无用(Zombie)的进程。
第三行显示的是目前CPU的使用情况,包括系统占用的比例、用户使用比例、闲置(Idle)比例。
第四行显示物理内存的使用情况,包括总的可以使用的内存、已用内存、空闲内存、缓冲区占用的内存。
第五行显示交换分区使用情况,包括总的交换分区、使用的、空闲的和用于高速缓存的大小。
linux系统中查看服务器负载和资源占用情况的命令
在Linux系统中,可以使用以下命令来查看服务器的负载和资源占用情况:
1. top:这是一个常用的命令,可以实时显示系统中各个进程的资源占用状况,包括CPU使用率、内存使用率等。
在top命令的界面中,还可以通过交互式命令进行排序、过滤等操作。
2. ps:用于查看当前进程的状态信息,包括进程ID、CPU使用率、内存使用率等。
ps命令可以通过不同的选项来筛选进程,例如ps aux 可以显示所有进程的详细信息,ps -ef可以显示所有进程的详细信息和父进程ID。
3. free:用于显示系统内存的使用情况,包括物理内存、交换空间等。
free命令还可以显示已使用的内存数量、空闲内存数量等。
4. df:用于显示磁盘的使用情况,包括已用空间、可用空间、挂载点等。
df命令还可以显示磁盘的I/O操作统计信息。
5. ifstat:用于显示网络接口的流量信息,包括上传和下载速度、丢包率等。
ifstat命令可以实时监控网络接口的状态和性能。
6. iostat:用于显示CPU使用率和磁盘I/O统计信息,包括平均响应时间、读写速度等。
iostat命令可以用于监控系统的磁盘性能和CPU使用情况。
这些命令都是Linux系统中常用的监控工具,可以帮助管理员了解服务器的负载和资源占用情况,从而进行相应的优化和调整。
学会在macOS终端中进行系统监控和报警在现代科技高速发展的时代,计算机系统已经成为人们日常生活中不可或缺的工具。
尤其是在大数据、云计算等领域,计算机系统的稳定性和安全性显得尤为重要。
因此,学会在macOS终端中进行系统监控和报警,对于保障计算机系统的正常运行具有重要意义。
本文将介绍几种常用的方法和工具,帮助读者掌握在macOS终端中进行系统监控和报警的技巧。
一、系统监控1. top命令在macOS终端中,可以使用top命令实时监控系统的运行情况。
top命令可以显示当前正在运行的进程、CPU的使用情况、内存的使用情况等。
通过观察top命令的输出,可以及时发现系统运行异常或者资源占用过高的情况,并进行相应的处理。
2. vm_stat命令vm_stat命令用于显示系统虚拟内存的统计信息。
通过观察vm_stat 命令的输出,可以了解系统内存分页、交换分区等情况,及时发现内存压力过大或者交换空间不足的问题。
3. iostat命令iostat命令可以用来监控系统的磁盘和CPU的使用情况。
通过观察iostat命令的输出,可以了解系统磁盘的读写速度、CPU的利用率等指标,及时发现磁盘或CPU资源不足的情况。
二、系统报警1. shell脚本shell脚本是一种可以在macOS终端中执行的脚本语言,非常适合用于系统报警。
通过编写shell脚本,可以监控系统指定的状态或者指标,并在满足特定条件时发送报警信息。
比如,可以编写一个shell脚本,定时检测系统的CPU利用率是否超过阈值,如果超过则发送报警邮件给管理员。
2. cron定时任务macOS终端提供了cron定时任务功能,可以用来定时执行指定的shell脚本。
通过设置cron定时任务,可以定期运行系统监控脚本,及时发现系统异常情况并进行报警处理。
3. third-party软件除了使用自己编写的shell脚本外,还可以使用一些第三方的系统监控和报警软件。
比如,Monit、Nagios等软件都可以在macOS终端中进行安装和配置,并提供强大的系统监控和报警功能。
kill,killall,top,free,vmstat,iostat,watch命令Linux 中的kill命令⽤来终⽌指定的进程(terminate a process)的运⾏,是Linux下进程管理的常⽤命令。
通常,终⽌⼀个前台进程可以使⽤Ctrl+C 键,但是,对于⼀个后台进程就须⽤kill命令来终⽌,我们就需要先使⽤ps/pidof/pstree/top等⼯具获取进程PID,然后使⽤kill命令来杀掉该进程。
kill 命令是通过向进程发送指定的信号来结束相应进程的。
在默认情况下,采⽤编号为15的TERM信号。
TERM信号将终⽌所有不能捕获该信号的进程。
对于那些可以捕获该信号的进程就要⽤编号为9的kill信号,强⾏“杀掉”该进程。
1.命令格式:kill[参数][进程号]2.命令功能:发送指定的信号到相应进程。
不指定型号将发送SIGTERM(15)终⽌指定进程。
如果任⽆法终⽌该程序可⽤“-KILL” 参数,其发送的信号为SIGKILL(9) ,将强制结束进程,使⽤ps命令或者jobs 命令可以查看进程号。
root⽤户将影响⽤户的进程,⾮root⽤户只能影响⾃⼰的进程。
3.命令参数:-l 信号,若果不加信号的编号参数,则使⽤“-l”参数会列出全部的信号名称-a 当处理当前进程时,不限制命令名和进程号的对应关系-p 指定kill 命令只打印相关进程的进程号,⽽不发送任何信号-s 指定发送信号-u 指定⽤户注意:1、kill命令可以带信号号码选项,也可以不带。
如果没有信号号码,kill命令就会发出终⽌信号(15),这个信号可以被进程捕获,使得进程在退出之前可以清理并释放资源。
也可以⽤kill向进程发送特定的信号。
例如:kill -2 123它的效果等同于在前台运⾏PID为123的进程时按下Ctrl+C键。
但是,普通⽤户只能使⽤不带signal参数的kill命令或最多使⽤-9信号。
2、kill可以带有进程ID号作为参数。
查看磁盘io状况的命令随着计算机技术的发展,磁盘io的重要性也越来越大。
磁盘io 是指磁盘的读取和写入操作。
如果磁盘的io能够得到有效的利用,将会大大提升计算机的性能,从而使计算机更加高效地工作。
要想更有效地查看磁盘io状况,就需要使用一些命令行工具。
在Linux系统中,有一些常用的命令用于查看磁盘io状况。
本文将对这些命令进行介绍,从而帮助读者更好地利用这些命令来查看磁盘io状况。
第一个命令是iostat。
iostat是一个用于查看磁盘io状况的命令,可以查看磁盘的读写速率、平均请求大小和繁忙程度等信息。
该命令的语法如下:iostat [options] [disks]该命令默认情况下会显示当前磁盘io的详细信息,如果指定了具体的磁盘,则会显示指定磁盘的io信息。
第二个命令是iotop。
iotop是一个用于实时查看磁盘io状况的命令,可以显示磁盘io请求的来源、相关的进程及io的流量等信息。
iotop的语法如下:iotop [options]该命令默认情况下会持续显示当前系统的磁盘io情况,可以通过指定参数来定制想要查看的内容。
第三个命令是iowait。
iowait是一个用于查看磁盘io的等待时间的命令,可以查看磁盘io请求的等待时间并按照时间排序,从而分析潜在的io性能瓶颈。
该命令的语法如下:iowait [options]该命令默认情况下会显示当前系统的磁盘io等待时间信息,可以通过指定参数来定制想要查看的内容。
第四个命令是iotrace。
iotrace是一个用于跟踪磁盘io请求的命令,可以查看io发出的时间、发出到完成的时间间隔等信息。
该命令的语法如下:iotrace [options]该命令默认情况下会跟踪当前磁盘io请求的信息,可以通过指定参数来定制想要查看的内容。
到目前为止,我们已经介绍了四个常用的命令来查看磁盘io状况,它们分别是iostat、iotop、iowait和iotrace。
iostat命令详解
2009-11-02 20:41
iostat [ -c | -d ] [ -k ] [ -t ] [ -V ] [ -x [ device ] ] [ interval [ count ] ]基本语法: iostat <options> interval count
option - 让你指定所需信息的设备,像磁盘、cpu或者终端(-d , -c , -t or -tdc ) 。
x 选项给出了完整的统计结果。
iostat的默认参数是tdc(terminal, disk, and CPU)。
如果任何其他的选项被指定,这个默认参数将被完全替代。
interval –统计运行的间隔时间(秒), count –统计运行的次数
其中,-c为汇报CPU的使用情况;-d为汇报磁盘的使用情况;-k表示每秒按kilobytes 字节显示数据;-t为打印汇报的时间;-v表示打印出版本信息和用法;-x device指定要统计的设备名称,默认为所有的设备;
iostat -d -k -t 2
Device: 显示磁盘名称
tps: 表示每秒钟输出到物理磁盘的传输次数。
一次传输就是一个对物理磁盘的 I/O 请求。
多个逻辑请求可被并为对磁盘的一个单一 I/O 请求。
传输具有中等的大小。
kB_read/s: 每秒从磁盘读取的数据量,单位为KB。
kB_wrtn/s: 每秒从写入磁盘的数据量,单位为KB。
Kb_read: 读取的 KB 总数。
Kb_wrtn: 写入的 KB 总数
iostat -x 1 10
rrqm/s:每秒进行 merge 的读操作数目。
即 delta(rmerge)/s
wrqm/s:每秒进行 merge 的写操作数目。
即 delta(wmerge)/s
r/s:每秒完成的读 I/O 设备次数。
即 delta(rio)/s
w/s:每秒完成的写 I/O 设备次数。
即 delta(wio)/s
rsec/s:每秒读扇区数。
即 delta(rsect)/s
wsec/s: 每秒写扇区数。
即 delta(wsect)/s
rkB/s: 每秒读K字节数。
是 rsect/s 的一半,因为每扇区大小为512字节。
(需要计算)
wkB/s:每秒写K字节数。
是 wsect/s 的一半。
(需要计算)
avgrq-sz:平均每次设备I/O操作的数据大小 (扇区)。
delta(rsect+wsect)/delta(rio+wio)
avgqu-sz:平均I/O队列长度。
即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。
await:平均每次设备I/O操作的等待时间 (毫秒)。
即
delta(ruse+wuse)/delta(rio+wio)
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。
即 delta(use)/delta(rio+wio) %util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。
即 delta(use)/s/1000 (因为use的单位为毫秒)
svctm 一般要小于 await (因为同时等待的请求的等待时间被重复计算了),svctm 的大小一般和磁盘性能有关,CPU/内存的负荷也会对其有影响,请求过多也会间接导致 svctm 的增加。
await 的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出
模式。
如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于svctm,说明 I/O 队列太长,应用得到的响应时间变慢,如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核 elevator 算法,优化应用,或者升级 CPU。
队列长度(avgqu-sz)也可作为衡量系统 I/O 负荷的指标,但由于 avgqu-sz 是按照单位时间的平均值,所以不能反映瞬间的 I/O 洪水。
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
同时可以结合vmstat 查看查看b参数(等待资源的进程数)和wa参数(IO等待所占用的CPU 时间的百分比,高过30%时IO压力高)
I/O 系统 vs. 超市排队)
举一个例子,我们在超市排队 checkout 时,怎么决定该去哪个交款台呢? 首当是看排的队人数,5个人总比20人要快吧? 除了数人头,我们也常常看看前面人购买的东西多少,如果前面有个采购了一星期食品的大妈,那么可以考虑换个队排了。
还有就是收银员的速度了,如果碰上了连钱都点不清楚的新手,那就有的等了。
另外,时机也很重要,可能 5 分钟前还人满为患的收款台,现在已是人去楼空,这时候交款可是很爽啊,当然,前提是那过去的 5 分钟里所做的事情比排队要有意义 (不过我还没发现什么事情比排队还无聊的)。
I/O 系统也和超市排队有很多类似之处:
r/s+w/s 类似于交款人的总数
平均队列长度(avgqu-sz)类似于单位时间里平均排队人的个数
平均服务时间(svctm)类似于收银员的收款速度
平均等待时间(await)类似于平均每人的等待时间
平均I/O数据(avgrq-sz)类似于平均每人所买的东西多少
I/O 操作率 (%util)类似于收款台前有人排队的时间比例。
我们可以根据这些数据分析出 I/O 请求的模式,以及 I/O 的速度和响应时间。
%iowait IO等待所占用的CPU时间的百分比
Show the percentage of time that the CPU or CPUs were idle during which the system had an outstanding disk I/O request.
%uitl
Percentage of CPU time during which I/O requests were issued to the device (bandwidth utilization for the device).
Device saturation occurs when this value is close to 100%.
%idle
Show the percentage of time that the CPU or CPUs were idle and the system did not have an outstanding disk I/O request.。