TeslaK提供深度学习框架基准测试平台
- 格式:pdf
- 大小:427.21 KB
- 文档页数:2

第38卷第5期 计算机应用与软件Vol 38No.52021年5月 ComputerApplicationsandSoftwareMay2021基于IndyLSTM的锂电池充电剩余时间预测杜京义 刘 鑫 柳庆莉 王佳程(西安科技大学电气与控制工程学院 陕西西安710054)收稿日期:2019-08-13。
杜京义,教授,主研领域:故障诊断,安全生产与监测,智能控制。
刘鑫,硕士。
柳庆莉,硕士。
王佳程,硕士。
摘 要 传统模型在锂电池充电剩余时间预测中的泛化能力受到一定约束。
针对此问题,提出一种基于独立长短期记忆循环神经网络(IndyLSTM)的锂电池充电剩余时间预测方法。
通过对锂电池充电过程数据的分析,利用IndyLSTM在处理序列化数据时可以长期记忆历史数据的优势,对充电剩余时间进行预测。
采用美国国家航空航天局(NASA)公开的电池数据,与常规的LSTM和SVR模型进行实验对比,IndyLSTM预测结果在准确性和稳定性方面表现更好。
关键词 IndyLSTM 锂电池 充电剩余时间 LSTM SVR中图分类号 TP183 文献标志码 A DOI:10.3969/j.issn.1000 386x.2021.05.018PREDICTIONOFREMAININGTIMEOFLITHIUMBATTERYCHARGINGBASEDONINDYLSTMDuJingyi LiuXin LiuQingli WangJiacheng(SchoolofElectricalandControlEngineering,Xi’anUniversityofScienceandTechnology,Xi’an710054,Shaanxi,China)Abstract Thetraditionalmodelhasacertainconstraintonthegeneralizationabilityoflithiumbatterychargingremainingtimeprediction.Aimingatthisproblem,amethodforpredictingtheremainingtimeoflithiumbatterychargingbasedonindependentlong termandshort termmemorycycleneuralnetwork(IndyLSTM)isproposed.Byanalyzingthedataofthechargingprocessofthelithiumbattery,themethodusedIndyLSTMtopredicttheadvantageofthehistoricaldatawhenprocessingtheserializeddata,anditpredictedtheremainingtimeofcharging.UsingthebatterydatapublishedbytheNationalAeronauticsandSpaceAdministration(NASA),comparedwiththeconventionalLSTMandSVRmodels,theIndyLSTMpredictionsperformedbetterintermsofpredictionaccuracyandstability.Keywords IndyLSTM Lithiumbattery Chargeremainingtime LSTM SVR0 引 言锂电池由于具备循环使用寿命长、无记忆效应、能量密度高、自放电率低和高性价比等优势,已被广泛应用于工业、日常生活等领域[1]。

《大模型时代的基础架构:大模型算力中心建设指南》阅读札记目录一、内容描述 (2)二、大模型时代的背景与发展趋势 (3)三、基础架构的重要性 (4)四、大模型算力中心建设指南 (6)4.1 总体架构设计 (8)4.2 硬件设备选型与配置 (9)4.3 软件系统架构规划 (10)4.4 数据存储与处理方案 (12)五、算力中心的实施与优化 (14)5.1 实施步骤与方法 (15)5.2 优化策略与措施 (16)六、案例分析与学习 (17)6.1 成功案例分享 (18)6.2 经验教训总结 (19)七、大模型算力中心的挑战与对策 (21)7.1 技术挑战与解决方案 (22)7.2 管理挑战与对策建议 (24)八、未来发展趋势与展望 (26)8.1 技术发展趋势预测 (28)8.2 行业应用前景展望 (29)九、结语 (30)一、内容描述在当今数字化浪潮中,大模型算力中心已成为推动人工智能、云计算、大数据等技术领域飞速发展的核心驱动力。
当我们将目光投向这个领域的建设与应用时,不禁要思考:如何构建一个高效、稳定且具备可扩展性的算力中心?《大模型时代的基础架构:大模型算力中心建设指南》一书为我们提供了宝贵的参考与启示。
书中开篇即对大模型算力中心的建设理念进行了深入剖析,大模型算力中心不仅仅是一个技术系统的堆砌,更是一个复杂的多维度、多层次的网络结构。
在这个体系中,数据传输、计算资源管理、存储设备、网络带宽等多个环节相互依存,共同构成了一个高效运转的整体。
在内容描述部分,作者详细阐述了算力中心的核心组件及其功能。
从高性能计算机的序列式排列到分布式存储系统的并行处理机制,再到智能化的能源管理系统,每一个细节都体现了作者对大模型算力中心建设的深刻理解与独到见解。
书中还结合了大量实际案例和最新技术动态,帮助读者更好地理解这些组件的工作原理和应用场景。
值得一提的是,作者在书中提出的“弹性扩展”理念令人印象深刻。
随着人工智能技术的不断进步和应用场景的日益丰富,算力中心需要能够灵活应对各种变化与挑战。


HPC 及深度學習應用APR 2017TESLA P100 效能指南現代的高效運算(HPC)資料中心是解決部分全球最重要之科學與工程挑戰的關鍵。
NVIDIA® Tesla®加速運算平台利用領先業界的應用程式支援這些現代化資料中心,促進 HPC 與 AI 工作負載。
Tesla P100 GPU 是現代資料中心的引擎,能以更少的伺服器展現突破性效能,進而實現更快的解析能力,並大幅降低成本。
每一個 HPC 資料中心都能自 Tesla 平台獲益。
在廣泛的領域中有超過 400 個HPC 應用程式,採用 GPU 最佳化,包括所有前 10 大 HPC 應用程式和各種主要深度學習架構。
採用加速 GPU 應用程式的研究領域包括:超過 400 個 HPC 應用及所有深度學習架構皆是採用加速 GPU。
>若想要取得最新 GPU 加速應用目錄,請造訪:/teslaapps>若想要立即在 GPU 上使用簡易指示,快速執行廣泛的加速應用,請造訪:/gpu-ready-apps分子動力(MD)代表 HPC 資料中心的大部分工作負載。
100% 頂尖 MD 應用皆是採用 GPU 加速,以使科學家能進行從前僅有 CPU 版本之傳統應用項目無法執行的模擬工作。
在執行 MD 應用時,配備 Tesla P100 GPU 的資料中心可節省高達 60% 的伺服器取得成本。
TESLA 平台及適用 MD 的 P100 的關鍵功能>搭載 P100 的伺服器,最多可取代 40 部適用 HOOMD-Blue、LAMMPS、AMBER、GROMACS 和 NAMD 等應用的 CPU 伺服器>100% 頂尖 MD 應用項目皆採用加速 GPU>FFT 和 BLAS 等關鍵數學程式庫>每一個 GPU 之單精度效能高達每秒 11 TFLOPS>每一個 GPU 之記憶體頻寬高達每秒 732 GB檢視所有相關的應用項目:/molecular-dynamics-appsHOOMD-BLUE循序寫入 GPU 的粒子動力封裝版本1.3.3加速功能CPU 和 GPU 可用版本延展性多 GPU 和多節點更多資訊/hoomd-blueLAMMPS典型粒子動力封裝版本2016加速功能Lennard-Jones、Gay-Berne、Tersoff 更多勢能延展性多 GPU 和多節點更多資訊/lammpsGROMACS模擬含複雜連結互動的生物模型分子版本5.1.2加速功能PME ,顯性與隱性溶劑延展性多 GPU 和多節點擴展至 4xP100更多資訊/gromacs黃色在生物分子上模擬分子動力的程式套件版本16.3加速功能PMEMD 顯性溶劑和 GB 、顯性及隱性溶劑、REMD 、aMD延展性多 GPU 和多節點更多資訊/amberNAMD專為高效模擬大分子系統而設計版本2.11加速功能PME 全靜電和眾多模擬功能延展性高達 100M 原子,多 GPU,擴展為 2xP100更多資訊/namd量子化學(QC)模擬是探索新藥物與原料的關鍵,且會耗費大部分 HPC 資料中心的工作負載。
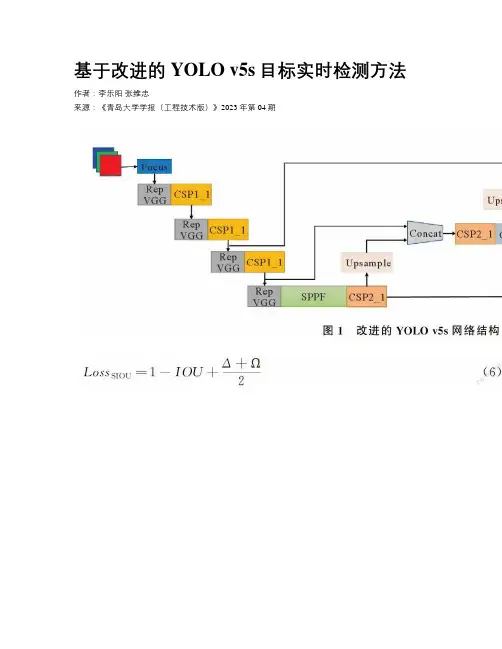
基于改进的YOLO v5s目标实时检测方法作者:李乐阳张维忠来源:《青岛大学学报(工程技术版)》2023年第04期摘要:針对包裹单件分离领域存在的包裹识别不准确、实时性差及效率低等问题,本文提出一种基于改进的YOLO v5s算法的包裹检测模型。
将RepVGG模块融入特征提取网络,降低网络参数的计算量,将损失函数CIOU优化为SIOU,引入真实框和预测框之间的向量角度,提升模型准确性。
实验结果表明,在包裹检测任务中,该模型的准确率可达到95.2%,召回率达到90.3%,检测速度达到136.9帧每秒(frames per second,FPS),可实时精确地检测传送带上的各类包裹,包括检测难度较大的异形件,能够满足实际需求。
该研究具有一定的实际应用价值。
关键词:YOLO v5s;快递包裹检测;目标检测;单件分离中图分类号:TP391.4文献标识码:A收稿日期:2023-06-13;修回日期:2023-10-30基金项目:市级专项扶持资金(202001PTXM14)作者简介:李乐阳(1996-),女,硕士研究生,主要研究方向为计算机视觉。
通信作者:张维忠(1963-),男,教授,硕士生导师,主要研究方向为计算机视觉,人工智能与大数据等。
Email:*********************近年来,电商平台带动了快递行业的高速发展,传统的包裹分离逐渐从人力分拣过渡到使用智能算法自动化处理,不仅提高了物流效率,还减少了人力资源的需求,降低了成本。
在包裹分离领域,德国西门子公司设计了单件分离系统[1],该系统由包裹检测模块和传送带控制模块组成,采用基于视觉的包裹检测方法,计算包裹在传送带上的位置,通过启动传送带进行分离,可方便地应用于自动化包裹分拣生产线上,但实时性较差,不能满足实际应用的需求。
杨赛[2]参照西门子系统,利用RGB-D相机,使用连通区域标记法对深度图像进行包裹分割,此方法效率较高,但错误分割的概率较大;海康威视开发了基于RGB-D相机与深度学习技术的包裹单件分离设备,将包裹定位分割算法整合到相机内部,完成包裹定位与分割的计算过程,但存在单个相机成本较高、分离不理想的情况。


第13卷㊀第10期Vol.13No.10㊀㊀智㊀能㊀计㊀算㊀机㊀与㊀应㊀用IntelligentComputerandApplications㊀㊀2023年10月㊀Oct.2023㊀㊀㊀㊀㊀㊀文章编号:2095-2163(2023)10-0083-05中图分类号:TP391文献标志码:A基于YOLOv5的高分辨率遥感图像目标检测算法李在瑞,郑永果,东野长磊(山东科技大学计算机科学与工程学院,山东青岛266590)摘㊀要:针对高分辨率遥感图像中物体排布密集㊁尺度变化较大等特性,提出一种目标检测算法R-YOLOv5㊂算法在YOLOv5模型基础上首先将跨阶段局部扩张结构作用于主干网络,采用一种加强的特征提取方式,通过整合空洞卷积和密集连接,来缓解模型对密集分布目标的漏检问题;其次,在主干网络的瓶颈部分结合Transformer模块来增强特征的表达,突出目标区域;最后,引入多尺度特征融合模块,解决多尺度特征融合时存在的不一致性问题,以提高模型的检测效果㊂在公开的遥感图像检测数据集DIOR的实验结果表明,R-YOLOv5算法平均精度均值(mAP)达到80.6%,具有良好的检测性能㊂关键词:遥感图像;目标检测;分布密集;YOLO;空洞卷积ObjectdetectionalgorithmforhighresolutionremotesensingimagebasedonYOLOv5LIZairui,ZHENGYongguo,DONGYEChanglei(CollegeofComputerScienceandEngineering,ShandongUniversityofScienceandTechnology,QingdaoShandong266590,China)ʌAbstractɔAimingatthecharacteristicsofdensedistributionandlargescalevariationofobjectsinhigh-resolutionremotesensingimages,anobjectdetectionalgorithmR-YOLOv5isproposed.OnthebasisofYOLOv5model,thealgorithmfirstlyintroducesCrossStagePartialDilatedNetworkinthebackbonenetwork,whichadoptsanenhancedfeatureextractionmethodtoalleviatetheproblemofundetecteddensedistributedtargetsbyintegratingdilatedconvolutionanddenseconnection.Secondly,inthebottleneckpartofthebackbonenetwork,theTransformermoduleiscombinedtoenhancetheexpressionoffeaturesandhighlightthetargetarea.Finally,multi-scalefeaturefusionmoduleisintroducedtosolvetheinconsistencyprobleminmulti-scalefeaturefusiontoimprovethedetectioneffectofthemodel.TheexperimentalresultsonpublicremotesensingimagedetectiondatasetDIORshowthattheMAPofR-YOLOv5reaches80.6%,whichhasgooddetectionperformance.ʌKeywordsɔremotesensingimage;objectdetection;densedistribution;YOLO;dilatedconvolution作者简介:李在瑞(1998-),男,硕士研究生,主要研究方向:计算机视觉;郑永果(1963-),男,博士,教授,主要研究方向:虚拟现实与可视化㊁图像处理与模式识别;东野长磊(1978-),男,博士,副教授,主要研究方向:医学图像处理㊁计算机视觉㊂通讯作者:郑永果㊀㊀Email:skd991317@sdust.edu.cn收稿日期:2022-11-050㊀引㊀言近些年,随着卫星及遥感技术的发展,遥感图像的目标检测在城市规划㊁灾情救援㊁车辆监控等各种实际应用中起到了至关重要的作用[1]㊂深度学习技术的迅速发展,使得目标检测有了重大突破,许多高性能的神经网络算法被提出[2]㊂目前,基于深度学习的目标检测算法可以大致分为二阶段算法和一阶段算法两类,二阶段算法专注于提升模型对目标的检测精度,一阶段方法则在追求精度的基础上又兼顾了检测速度㊂二阶段算法的经典模型是FastR-CNN[3],其使用RegionProposalNetwork(RPN)来选择对象的候选边界框,随后又进一步筛选出较为准确的目标区域㊂特征金字塔网络(FPN)[4]使用类似金字塔的结构来学习不同尺度的特征㊂Tridentnet[5]通过引入扩展卷积来改变大小最佳的感受野,并基于不同大小的感受野构造多分支结构,从而解决多尺度检测问题㊂一阶段模型中,SSD[6]增加了多个卷积层,以获得多尺度特征图进行预测,并设计不同大小的先验边界框以更好地检测目标㊂YOLOv4[7]采用了更为高效的csp-darknet作为主干网络并设计多尺度预测㊂TPH-YOLOv5[8]则将Transformer与网络相结合,增强模型提取特征的能力㊂以上算法虽然在识别自然图像时都表现出了良好的效果,但由于遥感图像存在背景复杂㊁目标尺度变化范围大㊁物体分布密集等检测难题[9],通用目标检测算法对高分辨率遥感图像的检测具有很大的局限性[10]㊂为解决上述问题,本文基于YOLOv5框架,提出特征信息补充与加强以及多尺度融合的方法,以增强模型的检测能力㊂1㊀相关工作1.1㊀YOLOv5模型随着YOLO系列网络的提出,其在各种视觉检测任务中展现了出色的性能㊂其中,YOLOv5主干网络是由Focus模块㊁CSP结构以及SPP模块组合而成㊂Focus模型会对图片进行切片操作,在宽和高两个维度上每隔一个像素取一个值,从而使特征图的通道数变为原来的4倍,能够在最大程度减少信息损失的同时实现两倍下采样㊂YOLOv5在CSPNet[11]的基础上重新设计csp结构,并在原本的darknet网络中大量插入该结构㊂spp模块对特征图做不同大小的池化操作,从而在原特征图的基础上融合不同感受野,丰富上下文信息[12]㊂YOLOv5在Nick部分结构参考了FPN和PAN㊂首先,设计自顶向下路径来融合网络中不同层次的特征,将包含丰富语义信息的深层特征向下传递与浅层结合,能够提高模型对多尺度目标的检测能力;后又增加自底向上的金字塔结构,把浅层特征映射到深层网络,补充检测目标的细节及空间信息,进一步提升模型的检测效果㊂同时,在nick部分应用csp2_x结构,使用X个卷积模块替代残差单元㊂Head部分则对图片进行预测与分类,YOLOv5设计3种尺寸的特征图来检测大中小不同种类的目标,最后通过非极大值抑制来筛选预测框,实现检测过程㊂1.2㊀Transformer模块Transformer模块早先广泛应用于NLP领域,通过自注意力机制来捕获序列元素之间的依赖关系,在可并行性和特征提取方面展现了出色的性能[13]㊂近些年来,许多计算机视觉的学者开始将其作用于图像相关的研究上㊂Parmar等人提出ImageTransformer[14]算法,基于Transformer解码器用于图像生成任务;随后VisionTransformer[15]被提出,并首次在大型图像数据集上展现出超越卷积网络的性能,在图像分类方面具有较强的泛化能力;SwinTransformer[16]则采用移动窗口的机制来计算注意力,有效解决了传统Transformer模块中计算复杂度较高的问题,并通过不同窗口之间的特征交互提取到更为丰富的语义信息㊂Transformer由编码器和解码器两部分组成,基本原理是通过将图片展开成一维,得到图像特征张量,输入到编码器部分使用多头自注意力学习目标特征,增强图像中目标的语义信息,再利用解码器与解码器协同训练,学习注意力规律来强化目标和特征之间的关联关系,进而提升检测效果㊂2㊀R-YOLOv5遥感图像目标检测算法R-YOLOv5目标检测算法结构如图1所示㊂首先,在YOLOv5的主干网络CSPDarkNet中使用跨阶段局部扩张结构,替代原本的跨阶段局部网络结构;其次,在主干网络的输出特征图瓶颈部分结合Transformer模块中的编码器;最后,在原本的Nick部分嵌入多尺度特征融合模块㊂S P PT R -B o t t l e n e c k C S P D 1_3C S P 1_1C o n vF o c u sT R -B o t t l e n e c k C S P D 1_3S P PC S PD 2_1C o n c a tC o n c a tC o n vC S PD 2_1C o n c a tC S PD 2_1C o n vT R -B o t t l e n e c kC S PD 2_1C S P D 2_1C o n c a tM S FC a tM a x p o o lM a x p o o l M a x p o o lP r e d i t i o nM S FC o n vC o n v C o n vC a tS o f t M a xC o n v C o n vC a tC a tC o n vC o n v2*C o n v6?D i l a t e d C o n vC S PD 1_XC S PD 2_X X *C o n v6?D i l a t e dC o n vX 个残差单元图1㊀R-YOLOv5算法结构Fig.1㊀R-YOLOv5algorithmstructure48智㊀能㊀计㊀算㊀机㊀与㊀应㊀用㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀第13卷㊀2.1㊀跨阶段局部扩张结构跨阶段局部网络结构(CrossStagePartialStructure,CSP)被大量应用到YOLOv4的主干网络,YOLOv5又在v4的基础上将其与nick部分结合㊂CSP结构包括两个分支:一是将输入特征图进行X个残差单元的卷积操作,另一部分进行简单的3∗3卷积计算特征后,与上一分支结合㊂CSP结构能够增强网络的特征提取能力,使模型获取到更为丰富的语义信息㊂针对遥感图像中检测目标尺度变化较大,物体分布密集的特性,对CSP结构进行改进,提出跨阶段局部扩张结构(CrossStagePartialDilatedStructure,CSPD),如图2所示㊂首先,保持残差单元分支不变,在另一分支中使用6个连续的扩张卷积,扩张率分别为3㊁6㊁12㊁18㊁24,来获取同一特征图的不同感受野,从而覆盖遥感图像中各种不同尺度的检测对象㊂其次,当图像中目标分布较为紧密时,使用扩张卷积会丢失特征信息,为了避免检测对象的漏检现象,在连续的6个扩张卷积基础上采用密集连接结构,将原特征图与每层的卷积分别做逐个元素的加操作,从而加强特征的传播,丰富语义信息㊂X 个残差单元C o n c a tD =3D =6D =12D =18D=24图2㊀跨阶段局部扩张模块结构图Fig.2㊀CrossStagePartialDilatedmodule2.2㊀瓶颈Transformer结构YOLOv5主干网络分别输出3个不同层次大小的特征图,作为后续多尺度特征融合部分的输入㊂将主干网络中负责输出特征图的瓶颈(Bottleneck)部分与Transformer模块中的编码器相结合(如图3所示),提出瓶颈Transformer结构(TR-Bottleneck),提高模型对语义信息的提取能力,丰富图像全局信息,抑制背景对目标识别的影响㊂首先,将图片做切分并降低维度,即将原本H∗W∗C的图像变为N∗(P2∗C)的Tokens,其中N=HW∗P2;随后输入Encoder中的多头注意力机制,进一步做特征提取,如式(1)所示:AttenQ,K,V()=softmaxQKT㊀dkæèçöø÷V(1)式中:Q㊁K㊁V分别为输入多头注意力的查询向量㊁键向量㊁值向量,dk代表特征维度㊂将查询向量与键向量相乘后,经过softmax激活函数并归一化处理,再与V相乘加权,得到输出结果㊂最后输入由两个全连接层及激活函数组成的MLP(前馈神经网络)得到整个Transformer模块的输出特征,并与Bottlenck结构的特征信息结合㊂T R -B o t t l e n e c kM u l t i -H e a dA t t e n t i o nC o n v C o n v C o n vC o n vC o n vB nR e L U*2C o n c a tT r a n s f o r m e r M L P图3㊀瓶颈Transformer模块结构图Fig.3㊀Transformerbottleneckmodule2.3㊀多尺度特征融合模块YOLOv5输出的3种尺寸的特征图,分别对应大中小不同的检测对象,高层语义信息中检测大目标,低层语义信息中检测小目标,而遥感图像中往往既有大目标又有小目标㊂特征融合时,由于不同层间特征的不一致性,将会影响最后的检测结果㊂为了缓解上述问题,更好的让网络利用高低层语义信息,在nick部分的最后,嵌入多尺度特征融合模块(MultiScaleFeatureFusionModule,MSF),如图4所示㊂S o f t M a x压缩压缩压缩图4㊀多尺度特征融合模块结构图Fig.4㊀Multi-scalefeaturefusionmodule㊀㊀首先将3种尺寸的特征图进行采样操作,调整到同一尺寸;再根据通道维度整合并接入SoftMax函数生成权重参数;最后3层特征分别乘上各自的权重参数,得到融合后的特征,表达如式(2)所示:f=ð3i=1SoftMax(cat(x1x2x3)) xi(2)式中:x1㊁x2㊁x3分别为3种尺寸的特征图,cat表示对特征图做通道维度的整合, 表示点乘操作,f则为最终的输出特征㊂58第10期李在瑞,等:基于yolov5的高分辨率遥感图像目标检测算法3㊀实验3.1㊀实验环境与数据集实验在linux系统下进行,所用GPU为TeslaP100,显存16G,深度学习框架为pytorch㊂实验所用遥感数据集为DIOR,其中包括23463张图像,训练与测试各取一半的样本㊂3.2㊀评价指标实验采用平均精度均值(mAP)㊁平均精确率(AP)作为评估指标,AP和mAP是可以反映多类别目标全局检测精度的指标在文献中被广泛用于评估多类别目标检测性能表达如式(2)㊁(3)所示:AP=ʏ10pR()dR(3)mAP=1NðiAPi(4)㊀㊀其中,平均精度AP表示的是计算单类目标P-R曲线下面积的结果,p为精确率,R为召回率;而mAP是所有类别AP的平均值;N为检测目标的类别总数;APi表示第i个类别的平均检测精度㊂3.3㊀算法流程如图5所示,R-YOLOv5算法首先对输入的遥感图像进行预处理,扩展图像数据;其次,根据模型配置文件搭建网络结构,读取训练参数,并根据训练结果更新网络参数;最后,加载训练权重与测试数据集,输出模型的预测图像㊂搭建网络读取参数输出结果更新参数训练模型训练集测试集数据预处理归一化数据扩充遥感图像图5㊀R-YOLOv5算法流程图Fig.5㊀R-YOLOv5algorithmflowchart3.4㊀实验结果表1为本文算法R-YOLOv5与不同目标检测模型在DIOR数据集下的实验结果㊂其中包括一阶段模型Faster-RCNN,以SSD㊁RetinaNet㊁YOLOv4为代表的二阶段模型,及无锚方法YOLOX㊂表1㊀DIOR数据集下对比试验Tab.1㊀ResultsonDiordataset%METHODFaster-RCNNSSDRetinaNetYOLOv4YOLOXR-YOLOv5Expresswayservicearea656490898093Basketballcourt717690878992Tenniscourt777687889092golffield706585747286Groundtrackfield626983828188Stadium946181707480Chimney896681807682Airport687279807192Dam595775706181Baseballfield927274858481Windmill446670838992Airplane916068738584Trainstation405561634875Expresswaytollstation555359717183Harbor544959635267Overpass514857626166Ship215947858891bridge223037444455Storagetank734734637076Vehicle302721444958MAP61.585866.9272.6971.780.6㊀㊀由表1可知,R-YOLOv5对飞机㊁机场㊁船㊁桥㊁车辆等密集分布㊁大小尺度不一目标的精度均有不同程度的提高,具有良好的表现㊂图6所示为R-YOLOv5对密集分布㊁大小尺度不一目标的效果图㊂这两种情况在检测过程中都较易对目标错检或漏检,模型识别的难度较大㊂如图68智㊀能㊀计㊀算㊀机㊀与㊀应㊀用㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀第13卷㊀6(a)㊁(b)中飞机与油罐的分布较为密集,模型对此类目标能够较为全面的做出识别;图6(c)㊁(d)中车辆与桥梁㊁棒球场与网球场等各类物体的尺度变化给模型带来了检测难题,结果表明,R-YOLOv5可以较为准确的检测出目标对象㊂(a )飞机场(b )油罐场(c )车辆与桥梁(d )棒球场与网球场图6㊀R-YOLOv5检测结果Fig.6㊀R-YOLOv5detectionresult4㊀结束语基于高分辨率遥感图像存在检测对象密集度高㊁大小不一等问题㊂本文提出R-YOLOv5算法,通过扩大感受野和增强特征信息以及改善特征融合来提高模型对密集物体以及多尺度目标的检测精度㊂实验表明,本文提出的目标检测算法在遥感数据集上具有较好的识别能力㊂参考文献[1]SCHILLINGH,dULATOVD,NIESSNERR,etal.Detectionofvehiclesinmultisensordataviamultibranchconvolutionalneuralnetworks[J].IEEEEJournalofSelectedTopicsinAppliedEarthObservationsandRemoteSensing,2018,11(1):4299-4316.[2]CHENJ,YUEA,WANGC,etal.Windturbineextractionfromhighspatialresolutionremotesensingimagesbasedonsaliencydetection[J].JournalofAppliedRemoteSensing,2018,12(1):016041.[3]GIRSHICKR.Fastr-cnn[C]//ProceedingsoftheIEEEinternationalconferenceoncomputervision.2015:1440-1448.[4]LINTY,DOLL RP,GIRSHICKR,etal.Featurepyramidnetworksforobjectdetection[C]//ProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition.2017:2117-2125.[5]LIY,CHENY,WANGN,etal.Scale-awaretridentnetworksforobjectdetection[C]//ProceedingsoftheIEEE/CVFinternationalconferenceoncomputervision.2019:6054-6063.[6]LIUW,ANGUELOVD,ERHAND,etal.Ssd:Singleshotmultiboxdetector[C]//ComputerVision-ECCV2016:14thEuropeanConference,Amsterdam,TheNetherlands,October11-14,2016,Proceedings,PartI14.SpringerInternationalPublishing,2016:21-37.[7]BOCHKOVSKIYA,WANGCY,LIAOHYM.Yolov4:Optimalspeedandaccuracyofobjectdetection[J].arXivpreprintarXiv:2004.10934,2020.[8]ZHUX,LYUS,WANGX,etal.TPH-YOLOv5:ImprovedYOLOv5basedontransformerpredictionheadforobjectdetectionondrone-capturedscenarios[C]//ProceedingsoftheIEEE/CVFinternationalconferenceoncomputervision.2021:2778.[9]ZHANGG,LUS,ZHANGW.CAD-Net:Acontext0awaredetectionnetworkforobjectsinremotesensingimagery[J].IEEETransactionsonGeoscienceandRemoteSensing,2019,57(12):10015-10024.[10]ZHENGZ,LEIL,SUNH,etal.Areviewofremotesensingimageobjectdetectionalgorithmsbasedondeeplearning[C]//2020IEEE5thInternationalConferenceonImage,VisionandComputing(ICIVC).IEEE,2020:34-43.[11]WANGCY,LIAOHYM,WUYH,etal.CSPNet:AnewbackbonethatcanenhancelearningcapabilityofCNN[C]//ProceedingsoftheIEEE/CVFconferenceoncomputervisionandpatternrecognitionworkshops.2020:390-391.[12]CAOL,ZHANGX,WANGZ,etal.Multianglerotationobjectdetectionforremotesensingimagebasedonmodifiedfeaturepyramidnetworks[J].InternationalJournalofRemoteSensing,2021,42(14):5253-5276.[13]WANGC,BAIX,WANGS,etal.MultiscaleVisualattentionnetworksforobjectdetectioninVHRremotesensingimages[J].IEEEGeoscienceandRemoteSensingLetters,2018,16(2):310-314.[14]PARMARN,VASWANIA,USZKOREITJ,etal.Imagetransformer[C]//Internationalconferenceonmachinelearning.PMLR,2018:4055-4064.[15]DOSOVITSKIYA,BEYERL,KOLESNIKOVA,etal.Animageisworth16ˑ16words:Transformersforimagerecognitionatscale[J].arXivpreprintarXiv:2010.11929,2020.[16]LIUZ,LINY,CAOY,etal.Swintransformer:Hierarchicalvisiontransformerusingshiftedwindows[C]//ProceedingsoftheIEEE/CVFinternationalconferenceoncomputervision.2021:10012-10022.78第10期李在瑞,等:基于yolov5的高分辨率遥感图像目标检测算法。

预训练模型1 预训练模型由来预训练模型是深度学习架构,已经过训练以执⾏⼤量数据上的特定任务(例如,识别图⽚中的分类问题)。
这种训练不容易执⾏,并且通常需要⼤量资源,超出许多可⽤于深度学习模型的⼈可⽤的资源,我就没有⼤批次GPU。
在谈论预训练模型时,通常指的是在训练的CNN(⽤于视觉相关任务的架构)。
ImageNet数据集包含超过1400万个图像,其中120万个图像分为1000个类别(⼤约100万个图像含边界框和注释)。
2 预训练模型定义那么什么是预训练模型?这是在训练结束时结果⽐较好的⼀组权重值,研究⼈员分享出来供其他⼈使⽤。
我们可以在github上找到许多具有权重的库,但是获取预训练模型的最简单⽅法可能是直接来⾃您选择的深度学习库。
现在,上⾯是预训练模型的规范定义。
您还可以找到预训练的模型来执⾏其他任务,例如或。
此外,最近研究⼈员已开始突破预训练模型的界限。
在⾃然语⾔处理(使⽤⽂本的模型)的上下⽂中,我们已经有⼀段时间使⽤嵌⼊层。
Word嵌⼊是⼀组数字的表⽰,其中的想法是类似的单词将以某种有⽤的⽅式表达。
例如,我们可能希望'鹰派','鹰','蓝杰伊'的表现形式有⼀些相似之处,并且在其他⽅⾯也有所不同。
⽤⽮量表⽰单词的开创性论⽂是,这篇嵌⼊层的论⽂是我最喜欢的论⽂之⼀,最早源于80年代,Geoffrey Hinton 的。
尽管通过对⼤型数据集进⾏训练获得的单词的表⽰⾮常有⽤(并且以与预训练模型类似的⽅式共享),但是将单词嵌⼊作为预训练模型会有点拉伸。
然⽽,通过和,真正的预训练模型已经到达NLP世界。
它们往往⾮常强⼤,围绕着⾸先训练语⾔模型(在某种意义上理解某种语⾔中的⽂本⽽不仅仅是单词之间的相似性)的概念,并将其作为更⾼级任务的基础。
有⼀种⾮常好的⽅法可以在⼤量数据上训练语⾔模型,⽽不需要对数据集进⾏⼈⼯注释。
这意味着我们可以在尽可能多的数据上训练语⾔模型,⽐如整个维基百科!然后我们可以为特定任务(例如,情感分析)构建分类器并对模型进⾏微调,其中获取数据的成本更⾼。

基于改进Faster -RCNN 的目标检测算法研究□闫新庆杨喻涵陆桂明华北水利水电大学信息工程学院T 互联网+技术In tern et Technology _______________________________________________________________【摘要】 目标检测是图像处理领域一个重要的研究方向,深度学习方法需要大量数据进行训练,训练的繁杂和复杂的网络结构限制了目标检测的速度。
本文基于Faster RCNN 的网络架构,创新性提出了丨ight tail Faster RCNN 网络架构。
light tail Faster RCNN 算法在保证精度的情况下,大大提升了处理速度。
在本文的设计中,通过将网络结构中的全连接层改为1*1的卷积层,来达到速度 的提升。
本文实验在PASCAL V 〇C 数据集上进行,较经典网络模型,在识别率略低的情况下,速率提升了一倍多。
在总体性能上显 著优于经典目标检测算法,通过对比实验的方法比较验证了本文提出方法的有效性。
【关键词】 目标检测 Faster RCNN 深度学习Abstract: Target detection is an important research direction in the field of image processing. Deep learning methods require a large amount of data for training, and the complex and complex network structure of training limits the speed of target detection. Based on the network architecture of Faster RCNN, this paper innovatively proposes the light tail Faster RCNN network architecture. The Light tail Faster RCNN algorithm greatly improves the processing speed while ensuring accuracy. In the design of this article, the speed is improved by changing the fully connected layer in the network structure to a 1 *1 convolutional layer. The experiment in this article is carried out on the PASCAL VOC data set. Compared with the classic network model, the speed is more than doubled when the recognition rate is slightly lower. The overall performance is significantly better than the classic target detection algorithm. The method comparison of the comparative experiment verifies the effectiveness of the method proposed in this paper.Keywords: Target detection ; Faster RCNN ; Deep learning引言目标检测与视频分析和图像理解有着密切的联系,近年来受到了广泛的关注。

深度学习技术在网络入侵检测中的应用案例简介•本案例中,北京邮电大学移动互联网安全技术国家工程实验室研究团队致力于将最新的深度学习技术应用于网络入侵检测,积极探索利用人工智能解决网络安全问题的新思路。
•本案例中使用的NVIDIA GPU:10块 Tesla K80。
Case Introduction•In this case, the research team belongs to the National Engineering Laboratory for Mobile Network Security Technologies, Beijing University of Posts and Telecommunications. They devote to applying the latest deep learning technology to network intrusion detection, and actively exploring new ideas of using artificial intelligence to solve cyber security problems.•The major product utilized in the case is 10 NVIDIA Tesla K80 GPUs.现状从全球范围来看,网络空间安全形势不容乐观。
继早期的蠕虫病毒、特洛伊木马和僵尸网络之后,近年来又兴起了被称为APT(高级持续威胁)的新型网络攻击手段。
2017年上半年,勒索病毒WannaCry更是在全球范围内肆虐,通过网络造成一场严重的灾难。
最新统计数据显示,WannaCry勒索病毒至少感染了150个国家的30万台电脑,波及了众多行业,包括金融、能源、医疗等,造成经济损失约达80亿美元,成为多年以来影响力最大的病毒之一。
简言之,不断爆发的大规模网络攻击一方面证明了传统安全防护技术的缺陷和不足,另一方面则呼唤着新一代网络安全技术的出现。
测试服务器gpu的简单命令-概述说明以及解释1.引言1.1 概述概述部分应该简要介绍本文的主题和内容。
可以参考以下范例来撰写概述内容:在当今科技发展迅猛的时代,GPU(图形处理器)已经成为计算机领域中不可或缺的重要组件。
GPU测试服务器作为测试和评估GPU性能、功能和稳定性的关键工具,对于开发人员和研究人员来说具有重要意义。
本文将简要介绍GPU测试服务器的基本概念、作用以及其在计算机领域中的重要性。
接下来,我们将探讨如何使用简单的命令来进行GPU测试,并为读者提供一些常用的测试指南和技巧。
通过本文的阅读,读者将能够了解如何更好地利用GPU测试服务器来提升计算机性能和应用程序的表现。
文章结构部分的内容可以按照以下方式进行编写:1.2 文章结构本文将按照以下结构进行阐述和讨论:1. 引言:在引言部分,将对测试服务器GPU的背景、意义和重要性进行简要介绍,并明确本文的目的。
2. 正文:在正文部分,将分为两个主要部分进行讨论。
2.1 GPU测试服务器的介绍:本部分将详细介绍GPU测试服务器的概念、原理和应用范围。
包括对GPU测试服务器的定义、工作原理和优势进行阐述,并举例说明GPU测试服务器在不同领域的实际应用。
2.2 GPU测试服务器的配置:本部分将详细介绍GPU测试服务器的配置要求和常用组件,包括GPU型号、CPU型号、内存容量等。
同时,还将介绍如何选择适合的GPU测试服务器配置,并提供一些配置优化的建议。
3. 结论:在结论部分,将对GPU测试服务器的重要性进行总结,并展望其未来发展趋势。
通过总结本文的内容,强调GPU测试服务器在加速计算、提升性能等方面的重要作用,并探讨未来GPU测试服务器可能的发展方向。
通过以上文章结构的安排,读者可以清晰地了解本文的内容和结构,方便阅读和理解。
每个部分的内容都将有助于读者对测试服务器GPU的简单命令有更全面的了解。
1.3 目的本文的目的是介绍一些简单的命令,用于测试服务器上的GPU性能。
人工智能大模型研究分析报告目录1. 内容综述 (2)1.1 研究背景 (3)1.2 研究目的 (4)1.3 研究方法 (4)2. 人工智能大模型概述 (6)2.1 人工智能大模型的发展历程 (7)2.2 人工智能大模型的特点和优势 (8)2.3 人工智能大模型的应用领域 (9)3. 人工智能大模型的技术架构与实现 (11)3.1 深度学习基础 (13)3.2 大型神经网络模型 (15)3.3 分布式训练技术 (16)4. 人工智能大模型面临的挑战与问题 (17)4.1 计算资源需求 (19)4.2 数据隐私与安全问题 (21)4.3 可解释性和可信度问题 (22)5. 人工智能大模型在各行业的应用案例分析 (23)5.1 医疗健康领域 (25)5.2 金融领域 (27)5.3 制造业领域 (29)6. 对未来发展趋势的展望与建议 (31)6.1 技术创新趋势 (32)6.2 政策环境影响 (34)6.3 提升AI大模型应用的建议 (36)7. 结论与总结 (37)1. 内容综述本次“人工智能大模型研究分析报告”旨在全面剖析当前人工智能领域内的大模型趋势及其发展前景。
报告从技术演进、应用场景、伦理挑战三个核心维度展开,力求为读者提供一个多角度的理解和洞见。
在技术演进方面,报告详细追踪了从传统机器学习算法到深度学习,直至目前占主导地位的大模型架构的转变过程。
描述了大模型如何通过利用大规模并行计算资源(如TPUs和GPU),结合海量数据训练,实现了在多样化的复杂任务中取得超越人类专家的性能。
还分析了不同大模型之间的比较,以及它们在效率、通用性和特定任务上的优势。
应用场景的讨论探讨了大模型可能在生物医药研发、金融风险预测、自动驾驶、自然语言处理等领域带来的影响与变革。
通过案例实践,报告展示了精确预测、不良事件预防、实时决策支持等享受大模型的实际应用可能性,并对这些领域未来的创新趋势进行了预测。
在伦理与法律框架方面,报告深入探讨了大模型可能带来的一系列挑战,包括偏见放大、隐私侵犯、算法不透明等议题。
英伟达产品介绍的框架
1. 图形处理器(GPU),英伟达的GPU是其核心产品,广泛应
用于游戏、虚拟现实、数据中心和人工智能等领域。
GPU具备高性
能并行计算能力,可加速图形渲染和复杂计算任务。
2. 游戏平台,英伟达的游戏平台包括GeForce系列显卡和相关
软件。
GeForce显卡提供卓越的图形性能和游戏体验,支持实时光
线追踪和人工智能技术,为游戏玩家带来逼真的视觉效果和流畅的
游戏画面。
3. 数据中心解决方案,英伟达的数据中心产品主要包括Tesla GPU加速器和相关软件。
Tesla GPU加速器具备强大的并行计算能力,可加速深度学习、科学计算和大数据分析等任务。
英伟达还提供了
深度学习框架和库,如CUDA、cuDNN和TensorRT,帮助用户优化和
加速机器学习模型的训练和推理。
4. 自动驾驶平台,英伟达的自动驾驶平台包括Drive AGX系统
和相关软件。
Drive AGX系统是一种全面的自动驾驶计算平台,集
成了英伟达的GPU和其他关键技术,提供高性能的计算和感知能力,支持车辆的自主导航和智能驾驶功能。
5. 人工智能解决方案,英伟达的人工智能解决方案涵盖了从边缘设备到数据中心的全链路。
英伟达提供了Jetson系列嵌入式计算模块,用于边缘设备上的实时智能推理。
同时,英伟达的GPU和数据中心产品可用于训练和优化深度学习模型。
总结起来,英伟达的产品框架包括图形处理器、游戏平台、数据中心解决方案、自动驾驶平台和人工智能解决方案。
这些产品覆盖了多个领域,为用户提供了高性能的计算和图形处理能力,推动了人工智能和科学计算的发展。
2024年2月Electric Power Information and Communication Technology Feb. 2024 中图分类号:TP394.1文献标志码:A文章编号:2095-641X(2024)02-034-06DOI:10.16543/j.2095-641x.electric.power.ict.2024.02.05著录格式:李建康,韩帅,陈没,等.基于深度学习的输电通道入侵物体识别方法研究[J].电力信息与通信技术,2024,22(2):34-39.基于深度学习的输电通道入侵物体识别方法研究李建康1,韩帅2,陈没2,廖思卓2,王道累1,赵文彬1(1.上海电力大学能源与机械工程学院,上海市浦东新区201306;2.中国电力科学研究院有限公司,北京市海淀区100192)Research on Intrusion Object Recognition Method of Transmission CorridorBased on Deep LearningLI Jiankang1, HAN Shuai2, CHEN Mo2, LIAO Sizhuo2, WANG Daolei1, ZHAO Wenbin1(1. College of Energy and Mechanical Engineering, Shanghai University of Electric Power, Pudong New Area, Shanghai 201306, China;2. China Electric Power Research Institute, Haidian District, Beijing 100192, China)摘要:针对输电通道在线监测过程中入侵物体大小差异巨大、部分图像对比度低等问题,结合异物图像的特征,提出了一种基于目标检测算法的输电通道入侵物体识别方法。
Tesla K80提供深度学习框架基准测试平台
案例简介
•本案例中香港浸会大学计算机科学系异构计算实验室使用Tesla K80集群对目前主流的五大深
度学习框架(Caffe,CNTK,MXNet,
TensorFlow和Torch)进行性能基准评测。
•In this case, researchers from the Heterogeneous Computing Laboratory of The Department of
Computer Science, Hong Kong Baptist University
conducted a comprehensive benchmarking and
comparative study on the running performance of
five state-of-the-art deep learning frameworks
(Caffe, CNTK, MXNet, TensorFlow and Torch) by
using the Tesla K80 cluster.
•本案例中用到NVIDIA GPU:16块 Tesla K80
背景
香港浸会大学异构计算实验室从2007年开始则研究GPU并行计算,在GPU计算与高性能计算领域有丰富的科研和实践经验。
我们团队在各个应用领域的GPU优化算法都有较丰富的科研成果,如网络编码算法,基因匹配算法,机器学习算法等都取得突破性的性能提升。
我们团队在2014年与华为合作研究的深度学习的分布式计算框架。
基于CXXNET框架,研发出基于MPI的分布式深度学习框架。
同时,该框架也成功应用于ImageNet大规模图片识别的模型训练。
当前,各大知名公司和研究单位开源优秀的深度学习框架,而各个框架在单GPU节点和多GPU节点的性能表现各不相同。
香港浸会大学异构计算实验室对各大框架在Tesla GPU集群上进行性能基准评测。
在未来,深度学习框架由于出发点各不相同,在各种硬件资源下表现的性能也表现各异。
我们采用取长补短的方式,对相关算法进行优化,使得深度学习框架可以更加充分地利用硬件资源,提高模型训练或测试速度。
挑战
深度学习算法在GPU上的优化很大情况下依赖于NVIDIA提供的cuDNN和cuBLAS软件库,然而不同厂商在设计自己的深度学习框架时在软件库使用和资源调度上存在较大的差异,所以在同样的硬件环境下,所表现出来的性能也有所不同。
对于终端用户来讲,在众多深度学习框架中,较难选择较高性能的框架;对于研究人员来讲,每个框架都有自己的实现方法,很难知道哪一种实现方法已经是state-of-the-art。
基于这两个问题,提供一个深度学习框架的性能基准评测是很有必要的。
深度学习社区的发展迅速,深度学习框架的更新迭代也非常之快,而每一次新的迭代出现的性能也存在差异。
使得用户使用深度学习框架训练模型时间效率低下或无法发挥实际硬件的计算能力。
为快速评估出各个框架在一些通用的深度学习模型上的性能表现,我们设计基于Tesla K80硬件平台的性能基准测试,在同样的硬件环境下,评测5大深度学习框架在同样的深度网络模型的性能表现。
以最公平的评测方式为用户展示性能测试结果比较,并持续更进框架版本更新,让用户在选择深度学习框架时对性能的表现有一个直观理解。
我们设计3类主流的深度神经网络(全连接网,卷积网和循环网络),每一种网络应用在主流的公开数据集上(MNIST,Cifar10,ImageNet和PTB)进行模型训练。
如果只有一个GPU的情况下,所有测试的Case只能串行执行, 对所有框架的性能评测需要1周左右的时间,如此长的时间周期非常不利于与深度学习框架的更新保持同步,同时也大大地影响对深度学习框架的性能分析。
方案
16个节点的Tesla K80 GPU使我们对多个深度学习框架在性能上的全面评测成为可能。
首先,在单GPU节点的性能评估上,可以使用16个节点对不同的深度学习框架并行测试,以快速产生结果。
其次,对不同的深度学习框架可以在单机多卡的环境下进行性能评估,以对比不同框架在单机多卡的扩展性。
最后,在跨机器的分布式计算的性能评估也成为现实,利用8台服务器,每台服务器部署2个Tesla K80,测试不同框架在分布式环境下的性能表现。
首先,在单GPU的性能评估上,不同的深度学习框架可以利用16块Tesla K80共32个GPU同时进行性能测试。
我们总需要对6种不同的深度网络,每种深度网络需要跑5组不同的mini-batch大小,共有5个深度学习框架,即需测试150次。
在单GPU的环境下,这150次只能串行进行,需要持续1周左右时间才能测试完毕,而利用Tesla K80的8节点集群(每节点2块K80),把150次测试用例平均到每个GPU上,这样即把测试时间缩短为原来的1/32,大大地提高的测试效率。
其次,不同深度学习框架在多GPU环境下的性能表现也不同,8节点的K80集群为我们提供了单机4个GPU的测试环境,以评估单机多卡的性能表现。
在单机多卡的模型训练中,通常需要进行数据同步,而数据同时则需要将数据通过PCI-e进行传输。
但目前PCI-e的速度远比GPU的计算性能要差,导致PCI-e的数据传输容易成为性能瓶颈,因此不同框架在数据同步方面会采取一些优化方案以减少PCI-e的数据传输。
不同的框架则有不同的优化策略,通过性能的基准评测,我们可以测试出在哪些Case上怎样的策略是最优的。
最后,在深度学习框架的应用上,当需要处理更大型的任务时,往往需要多台GPU服务器协同工作以完成任务。
深度学习框架也具备这样的特点,在分布式计算环境下,与单机多卡的环境类似,也需要进行数据同步,这不仅需要依赖于PCI-e的数据传输,还依赖于以太网或IB网的数据传输,使用分布式模型训练带来更大的挑战。
因此,每个框架为减少网络传输和PCI-e传输对数据和算法的优化也各不相同。
8台K80服务器也为我们提供这样的测试环境,以评估各个框架在分布式环境下的扩展性。
深度学习框架在GPU计算平台上的性能表现直接影响到用户在进行模型训练或推理时的效率,而深度学习的训练过程中,通常需要对深度网络的层数,每层节点数,连接结构和一些超参数等进行调整以达到最佳的表达能力,这就需要进行快速迭代来提高效率。
因此,深度学习框架在某一个操作或某一个算法的性能提升直接关系到深度学习研究和开发人员的工作效率。
我们使用提供的基于K80硬件环境下的性能基准测试则提供一个全面的评估,使用户更方便选择最优性能的框架,而对开发人员,即可以根据相应的性能劣势进一步地优化,提高硬件资源使用率。
目前,基于18块K80集群,我们只需要3天时间即可对5大深度学习框架进行全面的性能比较。
影响
通过16块K80集群,我们的基准测试可以大大地缩短评测周期,快速地响应深度学习框架的更新,为用户和开发者提供一个全面的性能比较。
目前我们开放的深度学习框架的性能基准评测已引起了Google,微软和亚马逊等大公司和学者的关注。
在我们开放的性能评估的基础上,各大公司对其开源的深度学习框架的性能劣势做进一步的优化和性能提升。
他们对性能进行优化后便集成进新版本中,我们又可以其新发布的版本快速地进行性能评估。
这对整个深度学习框架的研究和开发是一个良性的循环。