数据库系统实现(第二版)答案ch6
- 格式:docx
- 大小:27.96 KB
- 文档页数:9

第1章数据概述一.选择题1.下列关于数据库管理系统的说法,错误的是CA.数据库管理系统与操作系统有关,操作系统的类型决定了能够运行的数据库管理系统的类型B.数据库管理系统对数据库文件的访问必须经过操作系统实现才能实现C.数据库应用程序可以不经过数据库管理系统而直接读取数据库文件D.数据库管理系统对用户隐藏了数据库文件的存放位置和文件名2.下列关于用文件管理数据的说法,错误的是DA.用文件管理数据,难以提供应用程序对数据的独立性B.当存储数据的文件名发生变化时,必须修改访问数据文件的应用程序C.用文件存储数据的方式难以实现数据访问的安全控制D.将相关的数据存储在一个文件中,有利于用户对数据进行分类,因此也可以加快用户操作数据的效率3.下列说法中,不属于数据库管理系统特征的是CA.提供了应用程序和数据的独立性B.所有的数据作为一个整体考虑,因此是相互关联的数据的集合C.用户访问数据时,需要知道存储数据的文件的物理信息D.能够保证数据库数据的可靠性,即使在存储数据的硬盘出现故障时,也能防止数据丢失5.在数据库系统中,数据库管理系统和操作系统之间的关系是DA.相互调用B.数据库管理系统调用操作系统C.操作系统调用数据库管理系统D.并发运行6.数据库系统的物理独立性是指DA.不会因为数据的变化而影响应用程序B.不会因为数据存储结构的变化而影响应用程序C.不会因为数据存储策略的变化而影响数据的存储结构D.不会因为数据逻辑结构的变化而影响应用程序7.数据库管理系统是数据库系统的核心,它负责有效地组织、存储和管理数据,它位于用户和操作系统之间,属于AA.系统软件B.工具软件C.应用软件D.数据软件8.数据库系统是由若干部分组成的。
下列不属于数据库系统组成部分的是BA.数据库B.操作系统C.应用程序D.数据库管理系统9.下列关于客户/服务器结构和文件服务器结构的描述,错误的是DA.客户/服务器结构将数据库存储在服务器端,文件服务器结构将数据存储在客户端B.客户/服务器结构返回给客户端的是处理后的结果数据,文件服务器结构返回给客户端的是包含客户所需数据的文件C.客户/服务器结构比文件服务器结构的网络开销小D.客户/服务器结构可以提供数据共享功能,而用文件服务器结构存储的数据不能共享数据库是相互关联的数据的集合,它用综合的方法组织数据,具有较小的数据冗余,可供多个用户共享,具有较高的数据独立性,具有安全控制机制,能够保证数据的安全、可靠,允许并发地使用数据库,能有效、及时地处理数据,并能保证数据的一致性和完整性。
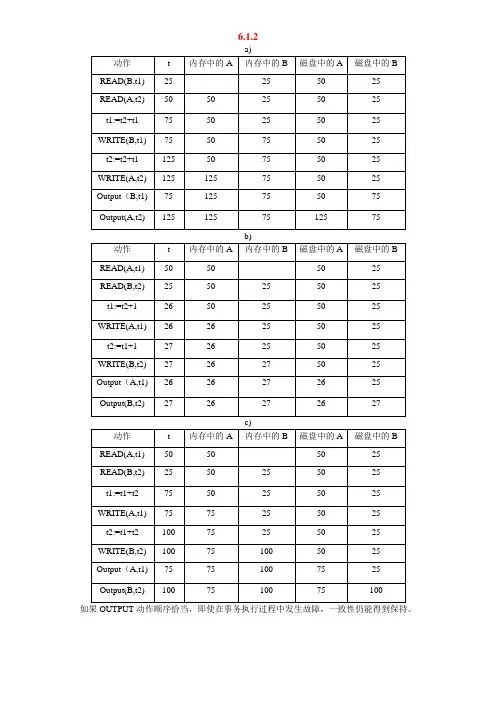
6.1.2如果OUTPUT动作顺序恰当,即使在事务执行过程中发生故障,一致性仍能得到保持。
6.2.3答案1若题目是:<START U>; <U,A,10>; <START T> ….则答案是a)首先扫描日志,发现事务T和U都未commit,将其连接到未完成事务列.按照未完成事务列,从后往前逐步扫描日志并执行undo操作,按照<U,A,10>将磁盘中A值写为10,将<ABORT T>和<ABORT U>写入日志中并刷新日志。
b)首先扫描日志,发现事务T已经commit,将其连接到已完成事务列,事务U未完成,将其连接到未完成事务列。
按照未完成事务列,从后往前扫描日志执行undo操作,按照<U,C,30>将磁盘中C值写为30,<U,A,10>将磁盘A值写为10。
将<ABORT U>写入日志中并刷新日志。
c)首先扫描日志,发现事务T已经commit,将其连接到已完成事务列,事务U未完成,将其连接到未完成事务列。
按照未完成事务列从后往前扫描日志执行undo操作,按照<U,E,50>将磁盘中E值写为50,<U,C,30>将磁盘中C值写为30,<U,A,10>将磁盘A值写为10。
将<ABORT U>写入日志中并刷新日志。
d)首先扫描日志,发现事务T、U已经commit,将其连接到已完成列,未完成列为空,不做任何操作。
答案2a) <START T>事务T、U未提交,要被撤销。
向后扫描日志,遇到记录<U,A,10>,于是将A在磁盘上的值存为10。
最后,记录<ABORT U>和<ABORT T>被写到日志中且日志被刷新。
b) <COMMIT T>事务T已提交,U未提交,要被撤销。
向后扫描日志,首先遇到记录<U,C,30>,于是将C在磁盘上的值存为30。


《数据库系统及应用》(第二版)习题解答习题一1.什么是数据库?数据库是相互关联的数据的集合,它用综合的方法组织数据,具有较小的数据冗余,可供多个用户共享,具有较高的数据独立性,具有安全控制机制,能够保证数据的安全、可靠,允许并发地使用数据库,能有效、及时地处理数据,并能保证数据的一致性和完整性。
2.简要概述数据库、数据库管理系统和数据库系统各自的含义。
数据库、数据库管理系统和数据库系统是三个不同的概念,数据库强调的是相互关联的数据,数据库管理系统是管理数据库的系统软件,而数据库系统强调的是基于数据库的计算机应用系统。
3.数据独立性的含义是什么?数据独立性是指数据的组织和存储方法与应用程序互不依赖、彼此独立的特性。
这种特性使数据的组织和存储方法与应用程序互不依赖,从而大大降低应用程序的开发代价和维护代价。
4.数据完整性的含义是什么?保证数据正确的特性在数据库中称之为数据完整性。
5.简要概述数据库管理员的职责。
数据库管理员的职责可以概括如下:(1)首先在数据库规划阶段要参与选择和评价与数据库有关的计算机软件和硬件,要与数据库用户共同确定数据库系统的目标和数据库应用需求,要确定数据库的开发计划;(2)在数据库设计阶段要负责数据库标准的制定和共用数据字典的研制,要负责各级数据库模式的设计,负责数据库安全、可靠方面的设计;(3)在数据库运行阶段首先要负责对用户进行数据库方面的培训;负责数据库的转储和恢复;负责对数据库中的数据进行维护;负责监视数据库的性能,并调整、改善数据库的性能,提高系统的效率;继续负责数据库安全系统的管理;在运行过程中发现问题、解决问题。
6.文件系统用于数据管理存在哪些明显的缺陷?文件系统用于数据管理明显存在如下缺陷:(1)数据冗余大。
这是因为每个文件都是为特定的用途设计的,因此就会造成同样的数据在多个文件中重复存储。
(2)数据不一致性。
这往往是由数据冗余造成的,在进行更新时,稍不谨慎就会造成同一数据在不同文件中的不一致。

目录第1部分课程的教与学第2部分各章习题解答及自测题第1章数据库概论1.1 基本内容分析1.2 教材中习题1的解答1.3 自测题1.4 自测题答案第2章关系模型和关系运算理论2.1基本内容分析2.2 教材中习题2的解答2.3 自测题2.4 自测题答案第3章关系数据库语言SQL3.1基本内容分析3.2 教材中习题3的解答3.3 自测题3.4 自测题答案第4章关系数据库的规范化设计4.1基本内容分析4.2 教材中习题4的解答4.3 自测题4.4 自测题答案第5章数据库设计与ER模型5.1基本内容分析5.2 教材中习题5的解答5.3 自测题5.4 自测题答案第6章数据库的存储结构6.1基本内容分析6.2 教材中习题6的解答第7章系统实现技术7.1基本内容分析7.2 教材中习题7的解答7.3 自测题7.4 自测题答案第8章对象数据库系统8.1基本内容分析8.2 教材中习题8的解答8.3 自测题8.4 自测题答案第9章分布式数据库系统9.1基本内容分析9.2 教材中习题9的解答9.3 自测题9.4 自测题答案第10章中间件技术10.1基本内容分析10.2 教材中习题10的解答10.3 自测题及答案第11章数据库与WWW11.1基本内容分析11.2 教材中习题11的解答第12章 XML技术12.1基本内容分析12.2 教材中习题12的解答学习推荐书目1.国内出版的数据库教材(1)施伯乐,丁宝康,汪卫. 数据库系统教程(第2版). 北京:高等教育出版社,2003(2)丁宝康,董健全. 数据库实用教程(第2版). 北京:清华大学出版社,2003(3)施伯乐,丁宝康. 数据库技术. 北京:科学出版社,2002(4)王能斌. 数据库系统教程(上、下册). 北京:电子工业出版社,2002(5)闪四清. 数据库系统原理与应用教程. 北京:清华大学出版社,2001(6)萨师煊,王珊. 数据库系统概论(第3版). 北京:高等教育出版社,2000(7)庄成三,洪玫,杨秋辉. 数据库系统原理及其应用. 北京:电子工业出版社,20002.出版的国外数据库教材(中文版或影印版)(1)Silberschatz A,Korth H F,Sudarshan S. 数据库系统概念(第4版). 杨冬青,唐世渭等译. 北京:机械工业出版社,2003(2)Elmasri R A,Navathe S B. 数据库系统基础(第3版). 邵佩英,张坤龙等译. 北京:人民邮电出版社,2002(3)Lewis P M,Bernstein A,Kifer M. Databases and Transaction Processing:An Application-Oriented Approach, Addison-Wesley, 2002(影印版, 北京:高等教育出版社;中文版,施伯乐等译,即将由电子工业出版社出版)(4)Hoffer J A,Prescott M B,McFadden F R. Modern Database Management. 6th ed. Prentice Hall, 2002(中文版,施伯乐等译,即将由电子工业出版社出版)3.上机实习教材(1)廖疆星,张艳钗,肖金星. PowerBuilder 8.0 & SQL Server 2000数据库管理系统管理与实现. 北京:冶金工业出版社,2002(2)伍俊良. PowerBuilder课程设计与系统开发案例. 北京:清华大学出版社,20034.学习指导书(1)丁宝康,董健全,汪卫,曾宇昆. 数据库系统教程习题解答及上机指导. 北京:高等教育出版社,2003(2)丁宝康,张守志,严勇. 数据库技术学习指导书. 北京:科学出版社,2003(3)丁宝康,董健全,曾宇昆. 数据库实用教程习题解答. 北京:清华大学出版社,2003 (4)丁宝康. 数据库原理题典. 长春:吉林大学出版社,2002(5)丁宝康,陈坚,许建军,楼晓鸿. 数据库原理辅导与练习. 北京:经济科学出版社,2001第1部分课程的教与学1.课程性质与设置目的现在,数据库已是信息化社会中信息资源与开发利用的基础,因而数据库是计算机教育的一门重要课程,是高等院校计算机和信息类专业的一门专业基础课。

第2部分各章习题解答及自测题第1章数据库概论1.1 基本内容分析1.1.1 本章的重要概念(1)DB、DBMS和DBS的定义(2)数据管理技术的发展阶段人工管理阶段、文件系统阶段、数据库系统阶段和高级数据库技术阶段等各阶段的特点。
(3)数据描述概念设计、逻辑设计和物理设计等各阶段中数据描述的术语,概念设计中实体间二元联系的描述(1:1,1:N,M:N)。
(4)数据模型数据模型的定义,两类数据模型,逻辑模型的形式定义,ER模型,层次模型、网状模型、关系模型和面向对象模型的数据结构以及联系的实现方式。
(5)DB的体系结构三级结构,两级映像,两级数据独立性,体系结构各个层次中记录的联系。
(6)DBMSDBMS的工作模式、主要功能和模块组成。
(7)DBSDBS的组成,DBA,DBS的全局结构,DBS结构的分类。
(1)教材P23的图1.24(四种逻辑数据模型的比较)。
(2)教材P25的图1.27(DB的体系结构)。
(3)教材P28的图1.29(DBMS的工作模式)。
(4)教材P33的图1.31(DBS的全局结构)。
1.2 教材中习题1的解答1.1 名词解释·逻辑数据:指程序员或用户用以操作的数据形式。
·物理数据:指存储设备上存储的数据。
·联系的元数:与一个联系有关的实体集个数,称为联系的元数。
·1:1联系:如果实体集E1中每个实体至多和实体集E2中的一个实体有联系,反之亦然,那么E1和E2的联系称为“1:1联系”。
·1:N联系:如果实体集E1中每个实体可以与实体集E2中任意个(零个或多个)实体有联系,而E2中每个实体至多和E1中一个实体有联系,那么E1和E2的联系是“1:N联系”。
·M:N联系:如果实体集E1中每个实体可以与实体集E2中任意个(零个或多个)实体有联系,反之亦然,那么E1和E2的联系称为“M:N联系”。
·数据模型:能表示实体类型及实体间联系的模型称为“数据模型”。

第1章数据概述一.选择题1.下列关于数据库管理系统的说法,错误的是CA.数据库管理系统与操作系统有关,操作系统的类型决定了能够运行的数据库管理系统的类型B.数据库管理系统对数据库文件的访问必须经过操作系统实现才能实现C.数据库应用程序可以不经过数据库管理系统而直接读取数据库文件D.数据库管理系统对用户隐藏了数据库文件的存放位置和文件名2.下列关于用文件管理数据的说法,错误的是DA.用文件管理数据,难以提供应用程序对数据的独立性B.当存储数据的文件名发生变化时,必须修改访问数据文件的应用程序C.用文件存储数据的方式难以实现数据访问的安全控制D.将相关的数据存储在一个文件中,有利于用户对数据进行分类,因此也可以加快用户操作数据的效率3.下列说法中,不属于数据库管理系统特征的是CA.提供了应用程序和数据的独立性B.所有的数据作为一个整体考虑,因此是相互关联的数据的集合C.用户访问数据时,需要知道存储数据的文件的物理信息D.能够保证数据库数据的可靠性,即使在存储数据的硬盘出现故障时,也能防止数据丢失5.在数据库系统中,数据库管理系统和操作系统之间的关系是DA.相互调用B.数据库管理系统调用操作系统C.操作系统调用数据库管理系统D.并发运行6.数据库系统的物理独立性是指DA.不会因为数据的变化而影响应用程序B.不会因为数据存储结构的变化而影响应用程序C.不会因为数据存储策略的变化而影响数据的存储结构D.不会因为数据逻辑结构的变化而影响应用程序7.数据库管理系统是数据库系统的核心,它负责有效地组织、存储和管理数据,它位于用户和操作系统之间,属于AA.系统软件B.工具软件C.应用软件D.数据软件8.数据库系统是由若干部分组成的。
下列不属于数据库系统组成部分的是BA.数据库B.操作系统C.应用程序D.数据库管理系统9.下列关于客户/服务器结构和文件服务器结构的描述,错误的是DA.客户/服务器结构将数据库存储在服务器端,文件服务器结构将数据存储在客户端B.客户/服务器结构返回给客户端的是处理后的结果数据,文件服务器结构返回给客户端的是包含客户所需数据的文件C.客户/服务器结构比文件服务器结构的网络开销小D.客户/服务器结构可以提供数据共享功能,而用文件服务器结构存储的数据不能共享数据库是相互关联的数据的集合,它用综合的方法组织数据,具有较小的数据冗余,可供多个用户共享,具有较高的数据独立性,具有安全控制机制,能够保证数据的安全、可靠,允许并发地使用数据库,能有效、及时地处理数据,并能保证数据的一致性和完整性。

第1章数据概述一•选择题1 •下列关于数据库管理系统的说法,错误的是CA. 数据库管理系统与操作系统有关,操作系统的类型决定了能够运行的数据库管理系统的类型B. 数据库管理系统对数据库文件的访问必须经过操作系统实现才能实现C. 数据库应用程序可以不经过数据库管理系统而直接读取数据库文件D. 数据库管理系统对用户隐藏了数据库文件的存放位置和文件名2•下列关于用文件管理数据的说法,错误的是DA. 用文件管理数据,难以提供应用程序对数据的独立性B. 当存储数据的文件名发生变化时,必须修改访问数据文件的应用程序C. 用文件存储数据的方式难以实现数据访问的安全控制D. 将相关的数据存储在一个文件中,有利于用户对数据进行分类,因此也可以加快用户操作数据的效率3 •下列说法中,不属于数据库管理系统特征的是CA. 提供了应用程序和数据的独立性B. 所有的数据作为一个整体考虑,因此是相互关联的数据的集合C. 用户访问数据时,需要知道存储数据的文件的物理信息D. 能够保证数据库数据的可靠性,即使在存储数据的硬盘岀现故障时,也能防止数据丢失5 •在数据库系统中,数据库管理系统和操作系统之间的关系是DA. 相互调用B. 数据库管理系统调用操作系统C. 操作系统调用数据库管理系统D. 并发运行6.数据库系统的物理独立性是指DA. 不会因为数据的变化而影响应用程序B. 不会因为数据存储结构的变化而影响应用程序C. 不会因为数据存储策略的变化而影响数据的存储结构D. 不会因为数据逻辑结构的变化而影响应用程序7 •数据库管理系统是数据库系统的核心,它负责有效地组织、存储和管理数据,它位于用户和操作系统之间,属于AA. 系统软件B.工具软件C.应用软件D.数据软件8 •数据库系统是由若干部分组成的。
下列不属于数据库系统组成部分的是BA. 数据库B.操作系统C.应用程序D.数据库管理系统9 •下列关于客户/服务器结构和文件服务器结构的描述,错误的是DA. 客户/服务器结构将数据库存储在服务器端,文件服务器结构将数据存储在客户端B. 客户/服务器结构返回给客户端的是处理后的结果数据,文件服务器结构返回给客户端的是包含客户所需数据的文件C. 客户/服务器结构比文件服务器结构的网络开销小D. 客户/服务器结构可以提供数据共享功能,而用文件服务器结构存储的数据不能共享数据库是相互关联的数据的集合,它用综合的方法组织数据,具有较小的数据冗余,可供多个用户共享,具有较高的数据独立性,具有安全控制机制,能够保证数据的安全、可靠,允许并发地使用数据库,能有效、及时地处理数据,并能保证数据的一致性和完整性。

数据库系统及应用(第二版)习题解答习题一1. 什么是数据库?数据库是相互关联的数据的集合,它用综合的方法组织数据,具有较小的数据冗余,可供多个用户共享,具有较高的数据独立性,具有安全控制机制,能够保证数据的安全、可靠,允许并发地使用数据库,能有效、及时地处理数据,并能保证数据的一致性和完整性。
2. 简要概述数据库、数据库管理系统和数据库系统各自的含义。
数据库、数据库管理系统和数据库系统是三个不同的概念,数据库强调的是相互关联的数据,数据库管理系统是管理数据库的系统软件,而数据库系统强调的是基于数据库的计算机应用系统。
3. 数据独立性的含义是什么?数据独立性是指数据的组织和存储方法与应用程序互不依赖、彼此独立的特性。
这种特性使数据的组织和存储方法与应用程序互不依赖,从而大大降低应用程序的开发代价和维护代价。
4. 数据完整性的含义是什么?保证数据正确的特性在数据库中称之为数据完整性。
5. 简要概述数据库管理员的职责。
数据库管理员的职责可以概括如下:(1 首先在数据库规划阶段要参与选择和评价与数据库有关的计算机软件和硬件,要与数据库用户共同确定数据库系统的目标和数据库应用需求,要确定数据库的开发计划;(2 在数据库设计阶段要负责数据库标准的制定和共用数据字典的研制,要负责各级数据库模式的设计,负责数据库安全、可靠方面的设计;(3 在数据库运行阶段首先要负责对用户进行数据库方面的培训;负责数据库的转储和恢复;负责对数据库中的数据进行维护;负责监视数据库的性能,并调整、改善数据库的性能,提高系统的效率;继续负责数据库安全系统的管理;在运行过程中发现问题、解决问题。
6. 文件系统用于数据管理存在哪些明显的缺陷?文件系统用于数据管理明显存在如下缺陷:(1 数据冗余大。
这是因为每个文件都是为特定的用途设计的,因此就会造成同样的数·2·《数据库系统及应用》习题解答据在多个文件中重复存储。
(2 数据不一致性。

实验二:drop table 订单明细godrop table 订购单godrop table 产品godrop table 客户gocreate table 客户(客户号char(8) primary keycheck(客户号like '[a-z]%' or 客户号like '[A-Z]%'), 客户名称varchar(40) not null,联系人char(8),地址varchar(40),邮政编码char(6) check(邮政编码like '[0-9][0-9][0-9][0-9][0-9][0-9]'),电话char(12) check(isnumeric(电话)=1and (len(ltrim(电话)))>=7))--drop table 产品create table 产品(产品号char(8)collate Chinese_PRC_Stroke_CS_AI_WS --大小写敏感not nullprimary key check(产品号like '[A-Z][A-Z]%'),产品名称varchar(40) ,规格说明char(40) unique,单价smallmoney check(单价>0))--drop table 订购单create table 订购单(客户号char(8) not null foreign key references 客户,订单号char(8) primary key,订购日期datetime default getdate())--drop table 订单明细create table 订单明细(订单号char(8) foreign key references 订购单,序号tinyint ,产品号char(8)collate Chinese_PRC_Stroke_CS_AI_WS --大小写敏感not null foreign key references 产品,数量smallint check(数量>0),primary key (订单号,序号))2 1)--1.产品规格的类型改为varchar(40)alter table 产品alter column 规格说明varchar(40)--出现以下错误:服务器: 消息5074,级别16,状态8,行1对象'UQ__产品__7C8480AE' 依赖于列'规格说明'。

数据库系统及应用第二版课后上机答案实验章节:第一,二,三,四,五,七实验一、实验目的:熟悉数据库的基本操作,会运用sql处理问题二、实验内容:1.建立数据库,2.建立表和数据完整性,3.SQL数据操作,4.SQL 数据查询,5视图的定义和操作,7.存储过程三.、程序源代码:实验一:1. create database test1on(name=test1_dat,filename='d:\ly\data\test1dat.mdf',size=5MB)log on(name=test1_log,filename='d:\ly\data\test1log.ldf')2.create database test2onprimary(name=test2_dat1,filename='d:\ly\data\test2dat1.mdf'),(name=test2_dat2,filename='d:\ly\data\test2dat2.ndf'),(name=test2_dat3,filename='d:\ly\data\test2dat3.ndf')log on(name=test2_log1,filename='d:\ly\data\test2log1.ldf'),(name=test2_log2,filename='d:\ly\data\test2log2.ldf')3. create database test3onprimary(name=test3_dat,filename='d:\ly\data\test3dat.mdf'),filegroup w1(name=test3_dat1,filename='d:\ly\data\test3dat1.ndf'),(name=test3_dat2,filename='d:\ly\data\test3dat2.ndf'), filegroup w2(name=test3_dat3,filename='e:\ly\data\test3dat3.ndf'), (name=test3_dat4,filename='e:\ly\data\test3dat4.ndf'), filegroup w3(name=test3_dat5,filename='f:\ly\data\\test3dat5.ndf'), (name=test3_dat6,filename='f:\ly\data\\test3dat6.ndf') log on(name=test3_log,filename='d:\ly\data\test3log.ldf')4. alter database test1add file(name=new_dat,filename='d:\ly\data\newdat.ndf',size=5MB)5. alter database test1modify file(name=test1_dat,size=10 MB)6.Drop database test1Drop database test2Drop database test3实验21建库:CREATE DATABASE 订单管理ON(NAME=order_dat,FILENAME='d:\ly\data\orderdat.mdf', SIZE= 10,MAXSIZE= 50,FILEGROWTH= 5 )LOG ON(NAME=order_log,FILENAME='d:\ly\data\orderlog.ldf', SIZE= 5MB,MAXSIZE= 25MB,FILEGROWTH= 5MB)建表:客户号char(8) primary key check(客户号like '[A-z]%'),客户名称varchar(40) not null,联系人char(8),地址varchar(40),邮政编码char(6) check(邮政编码like '[0-9][0-9][0-9][0-9][0-9][0-9]'), 电话char(12) check(电话like '[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]')) create table 产品( 产品号char(8) primary key check(产品号like '[A-z][A-z]%'),产品名称varchar(40),规格说明char(40) constraint uni unique,单价smallmoney constraint dj check(单价>0))create table 订购单(客户号char(8) not null foreign key references 客户,订单号char(8) primary key,订购日期datetime default getdate())create table 订单名细(订单号char(8) foreign key references 订购单,序号tinyint,产品号char(8) not null foreign key references 产品,数量smallint constraint sl check(数量>0)primary key(订单号,序号))2.1、先取消唯一性约束:alter table 产品drop constraint unialter table 产品alter column 规格说明varchar(40)2.2 alter table 订购单add 完成日期datetime null2.3 先取消约束alter table 订单名细drop constraint num;ALTER TABLE 订单名细ADD CONSTRAINT num CHECK (数量>= 0 AND 数量<= 1000)alter table 订单名细drop constraint num3.1 create index sup_kh_idx on 客户(客户名称)3.2 create unique index cp_idx on 产品(产品名称)3.3由于create table命令中的primary key 约束将隐式创建聚集索引,且在创建表时已经指定了关键字,则不可以再创建聚集索引3.4create index dd_mx_idx on 订单名细(订单号,序号,数量desc)四、实验数据、结果分析:实验3客户表:订购单:订单名细:产品:1、insert into 订单名细values( 'dd16','32','cp56','150') insert 客户(客户号,客户名称)values ('E20','广西电子') 订购单备份:select* into 订购单备份from 订购单select * from 订购单备份2、delete from 客户where 客户号='E10'delete from 客户where 客户号='E10'3、update 订单名细set 数量=225where 订单号='dd13'4、update 订购单set 订购日期='2011-10-11'where 订单号in (select 订单号from 订单名细where 产品号in (select 产品号from 产品where 产品名称='MP4'))5delete from 订购单where 客户号in( select 客户号from 客户where 客户名称='华中电子厂')由于语句与REFERENCE 约束"FK__订单名细__订单号__145C0A3F"冲突。
(1)磁盘容量
共10个盘面,每个盘面100 000个磁道,所以共10*100 000个磁道
每个磁道1000个扇区,每个扇区1024个字节,所以磁盘的容量为
10*100 000*1000*1024B=9
10KB
(2)平均位密度
每个磁道1000个扇区,每个扇区1024个字节,每个字节8bit故每个磁道容量为1000KB,对于3.5英寸直径上的位密度可计算为
1000*1024*8/(3.5*π%
⨯)=828227.68173bit/inch
90
(3)最大寻道时间
最大寻道时间出现在从最内层磁道寻找最外层磁道,或者相反,此时磁头经过99999个磁道,故最大寻道时间计算为
(1+0.0002*99999)ms=20.9998 ms
(4) 最大旋转等待时间
最大旋转等待时间为旋转一圈所用的时间,即60/10000s=6ms
(5) 块传输时间65536字节(64扇区)
要传输64扇区的块,磁头必须经过64个扇区和63个空隙,空隙占20%,扇区占80%,围绕着圆周有1000个扇区,1000个空隙,由于间隙合在一起为72度,扇区为288度,所以64个扇区63个空隙的总度数为(72*63/1000)+(288*64/1000)=22.968度,传输时间为
22.968/360*6ms=0.3828ms
(6) 平均寻道时间
在磁盘上移动1/3的距离需要1+0.0002n=1+0.0002*(100 000/3)=7.667ms (7) 平均旋转等待时间
平均旋转等待时间为旋转半周所花费的时间,即3ms。
第六章关系数据理论第六章讲解关系数据理论。
这是关系数据库的又一个重点。
学习本章的目的有两个。
一个是理论方面的,本章用更加形式化的关系数据理论来描述和研究关系模型。
另一个是实践方面的,关系数据理论是我们进行数据库设计的有力工具。
因此,人们也把关系数据理论中的规范化理论称为数据库设计理论,有的书把它放在数据库设计部分介绍以强调它对数据库设计的指导作用。
一、基本知识点本章讲解关系数据理论,内容理论性较强,分为基本要求部分(《概论》6.1~6.3)和高级部分《概论》6.4)。
前者是计算机大学本科学生应该掌握的内容;后者是研究生应该学习掌握的内容。
①需要了解的:什么是一个“不好”的数据库模式;什么是模式的插入异常和删除异常;规范化理论的重要意义。
②需要牢固掌握的:关系的形式化定义;数据依赖的基本概念(函数依赖、平凡函数依赖、非平凡的函数依赖、部分函数依赖、完全函数依赖、传递函数依赖的概念,码、候选码、外码的概念和定义,多值依赖的概念);范式的概念;从lNF 到4NF的定义;规范化的含义和作用。
③需要举一反三的:四个范式的理解与应用,各个级别范式中存在的问题(插入异常、删除异常、数据冗余)和解决方法;能够根据应用语义,完整地写出关系模式的数据依赖集合,并能根据数据依赖分析某一个关系模式属于第几范式。
④难点:各个级别范式的关系及其证明。
二、习题解答和解析1.理解并给出下列术语的定义:函数依赖、部分函数依赖、完全函数依赖、传递依赖、候选码、主码、外码、全码(All-key)、lNF、2NF、3NF、BCNF、多值依赖、4NF。
解析解答本题不能仅仅把《概论》上的定义写下来。
关键是真正理解和运用这些概念。
答函数依赖:设R(U)是一个关系模式,U是R的属性集合,X和Y是U的子集。
对于R(U)的任意一个可能的关系r,如果r中不存在两个元组,它们在X上的属性值相同,而在Y上的属性值不同,则称“X函数确定Y”或“Y函数依赖于X”,记作X→Y。
Solutions for Chapter 2Solutions for Section 2.1Solutions for Section 2.2Solutions for Section 2.3Solutions for Section 2.4Solutions for Section 2.5Solutions for Section 2.6Solutions for Section 2.1Exercise 2.1.1(a)Terabyte disks are about 100 times as large as ``1999'' disks. 100 is about 2^7, so there will have to be about seven doublings of disk size. According to Moore's law, that will take 10.5 years, so terabyte disks should be available in computer stores around 2010.Return to TopSolutions for Section 2.2Exercise 2.2.1(a)The disk has 10 * 10,000 = 100,000 tracks. The average track has 1000 * 512 = 512,000 bytes. Thus, the capacity is 51.2 gigabytes.Exercise 2.2.1(c)The maximum seek time occurs when the heads have to move across all the tracks. Thus, substitute 10,000 (really 9999) for n in the formula 1+.001n to get 11 milliseconds.Exercise 2.2.1(d)The maximum rotational latency is one full revolution. Since the disk rotates at 10,000 rpm, it takes 1/10000 of a minute, or 1/167 of a second to rotate, or about 6 milliseconds.Exercise 2.2.3First, we need to estabish the probability density function for the position of a random sector. Sincethese vary with the radius, the density at the inner edge is 3/7 the density of the outer edge, so the probability density looks like a trapezoid:** ** ** * 7/5* *3/5 * ** **********Call this function p(x) = 3/5 + 4x/5, with x varying from 0 to 1 and representing the fraction of the way from the inner to the outer edge that a sector is.Our question asks for the average over all x and y distributed by function p of the magnitude of x-y, that is:1 1INT INT p(x)p(y)|x-y| dx dy0 0Since the moves outward must equal the moves inward, we can eliminate the absolute-magnitude operator by doubling, and restricting to the case where x>y. That is, we compute:1 x2 INT INT p(x)p(y)(x-y) dx dy0 0If we substitute for p, we get1 x2 INT INT (3/5 + 4x/5)(3/5+4y/5)(x-y) dx dy0 0Now, we have only to expand terms, integrate first on y, then on x, to get the value of this integral: 121/375. That is, the average sector-to-sector move of the heads will traverse this fraction of the tracks, which is just slightly less than 1/3 of the tracks.Return to TopSolutions for Section 2.3Exercise 2.3.2(a)The relation occupies 250,000 blocks, and the sort takes 4 disk I/O's per block, or 1,000,000 diskI/O's. If the number of tuples were doubled, the relation would occupy twice as many blocks, so we would expect 2,000,000 disk I/O's. We should check that the 2-phase sort is still possible, but since doubling the size of the relation would require 40 sublists rather than 20, there will still be plenty of room in memory on the second pass.Exercise 2.3.2(c)Doubling the size of blocks reduces the number of disk I/O's needed to half, or 500,000. We might imagine that we could keep growing the size of blocks indefinitely, and thus reduce the number of disk I/O's to almost zero. In a sense we can, but there are limitations, including the fact that transfer time will eventually grow to dominate other aspects of latency, in which case counting disk I/O's fails to be a good measure of running time.Exercise 2.3.4Binary search requires probing the block in the middle of the 250,000 blocks, then the one in the middle of the first or second half, and so on, for log_2(250,000) = 18 probes, until we can narrow down the presence of the desired record on one block. Thus, we require 18 disk I/O's.Exercise 2.3.6Look ahead to the solution to Exercise 2.3.8. The formula derived there tells us that:1.Doubling B halves n. That is, the larger the block size, the smaller the relation we can sort withthe two-phase, multiway merge sort! Here is one good reason to keep block sizes modest.2.If we double R, then we halve the number of tuples we can sort, but that is no surprise, since thenumber of blocks occupied by the relation would then remain constant.3.If we double M we multiply by 4 the number of tuples we can sort.Exercise 2.3.8The number of sorted sublists s we need is s = nR/M. On the second phase we need one block for each sublist, plus one for the merged list. Thus, we require Bs < M. Substituting for s, we get nRB/M < M, or n < M^2/RB.Return to TopSolutions for Section 2.4Exercise 2.4.2Recall that the Megatron 747 has a transfer time (in milliseconds) of 0.5, and an average rotational latency of 7.8. If the average seek moves 1/3 of the way across 4096 tracks, the average seek time for the Megatron 747 is 1 + .002*(4096/3) = 3.7. Thus, the answer to part (a) is one block per 0.5 + 7.8 + 3.7 = 12 milliseconds, or 83 blocks per second, on each disk. Thus, the system can read 166 blocks per second.For a ``regular'' Megatron 747, the average latency is 0.5 + 7.8 + 6.5 = 14.8 milliseconds. However, if we have two, mirrored disks, each can be handling a request at the same time, or one read per 7.4 milliseconds. That gives us 135 blocks per second as the answer to (b).For part (c), restricting each disk to half the tracks means that if there is not always a queue of waiting requests (which slows the applications that the disk is supporting), then there might be two requests for the same half of the disk, in which case one disk is idle and a request waits.Exercise 2.4.3(a)Suppose that there are n requests waiting on each pass in the steady state. Then the time taken for a pass of the elevator algorithm is:1.0.5n for the transfers.2.7.8n for the rotational latencies.3.n + 16.4 for the seek times. To see the latter, notice that the head must start n times, whichaccounts for the first term, and total travel is 8192 tracks, which accounts for the second term, at the Megatron 747's rate of 500 tracks per millisecond.Let the time taken for a pass be t. Then 0.5n + 7.8n + n +16.4 = t. Also, during time t, another n requests must arrive, and they arrive one every A milliseconds. Thus, t = An.We can solve these two equations for n in terms of A; it is n = 16.4/(A - 9.3). The answer we want is t, the time to perform the pass. But t = An = 16.4A/(A - 9.3).Exercise 2.4.4Think of the requests as a random sequence of the integers 1 through 4. This sequence can be divided up into segments that do not contain two of the same integer, in a greedy way. For example, the sequence 123142342431 would be divided into 123, 1423, 42, and 31. The disks are serving all the requests from one segment, and each request is generated and starts at about the same time. When a segment is finished, the waiting request begins, along with other requests for other disks that are, by our assumption, generated almost immediately and thus finish at about the same time.The question is thus: if I choose numbers 1, 2, 3, and 4 at random, how many choices, on the average, can I make without a repeat? The cases are:1.1/4 of the time we get an immediate repeat on the second choice, and the length is therefore 1.2.(3/4)(1/2) = 3/8 of the time we get our first repeat at third number, and the length is 2.3.(3/4)(1/2)(3/4) = 9/32 of the time we get our first repeat at the fourth number, and our length is3.4.The remaining fraction of the time, 3/32, we get four different numbers, and our length is 4. The average length is therefore: (1/4)*1 + (3/8)*2 + (9/32)*3 + (3/32)*4 = 71/32.Return to TopSolutions for Section 2.5Exercise 2.5.1(a)There are five 1's, which is odd, so the parity bit is 1.Return to TopSolutions for Section 2.6Exercise 2.6.2To compute the mean time to failure, we can compute the probability that the system fails in a given year. The MTTF will be the inverse of that probability. Note that there are 8760 hours in a year.a) The system fails if the second disk fails while the first is being repaired. The probabiliy of afailure in a year is 2F. The probability that the second disk will fail during the H hours that theother is being prepared is H/8760. Thus, the probability of a failure in any year is 2FH/8760, and the MTTF is 4380/FHb) The system loses data if there are three disk crashes within an H hour period. The probabilityof any one disk failing in a year is NF. If so, there are (N-1)(N-2)/2 pairs of other disks thatcould fail within an H hour period, and the chance that any one of them will do so is FH/8760.Thus, the probability of two additional disk failures is (N-1)(N-2)F^2H^2/(2*8760^2), orapproximately (NFH)^2/1.5*10^8. The MTTF is the inverse of this probability.Exercise 2.6.4(a)01010110.Exercise 2.6.5(a)01010110. Notice that this question calls for the same computation as Exercise 2.6.4(a), or at least it would have, except for the typo in the third ``block,'' where 0011011 should have been 00111011.Exercise 2.6.8(a)In the matrix of Fig. 2.17, we see that columns 1 and 7 differ in both the first and second rows. In each case, column 1 has bit 1 and column 7 has bit 0. Let's use the first row to recover disk 1. That step requires us to take the modulo-2 sum of disks 2, 3, and 5, the other disks where row 1 has bit 1.Next, we use row 3, the only row where column 7 has a 1, to recover disk 7 by taking the modulo-2 sum of disks 1, 3, and 4.Exercise 2.6.12The parity checks of disks 9 and 10 can be represented by the matrix1 1 1 1 0 0 0 0 1 0 00 0 0 0 1 1 1 1 0 1 0Before we add a third row representing the parity check of disk 11, we can recover from two disk failures if and only if the two disks have different columns (except for disk 11, which has only 0's in its column). We'll surely add a 1 in column 11. So far, there are five columns with 1,0 (columns 1, 2, 3, 4, and 9) and five columns with 0,1 (columns 5, 6, 7, 8, and 10). The best we can do is break each of these groups 3-and-2, to maximize the number of pairs of disks that no longer have identical columns. Thus, we can make disk 11 be a parity check on any two or three of the first group and any two or three of the second group. An example would be to make disk 11 be a parity check on columns 3 through 6, but there are many other correct answers.Return to Top。
数据库系统原理与设计习题集第一章绪论一、选择题1. DBS是采用了数据库技术的计算机系统,DBS是一个集合体,包含数据库、计算机硬件、软件和()。
A.系统分析员B.程序员C.数据库管理员D.操作员2.数据库(DB),数据库系统(DBS)和数据库管理系统(DBMS)之间的关系是()。
A. DBS包括DB和DBMSB. DBMS包括DB和DBSC. DB包括DBS和DBMSD. DBS就是DB,也就是DBMS3.下面列出的数据库管理技术发展的三个阶段中,没有专门的软件对数据进行管理的是()。
I.人工管理阶段II.文件系统阶段III.数据库阶段A. I和IIB.只有IIC. II和IIID.只有I4.下列四项中,不属于数据库系统特点的是()。
A.数据共享B.数据完整性C.数据冗余度高D.数据独立性高5.数据库系统的数据独立性体现在()。
A.不会因为数据的变化而影响到应用程序B.不会因为系统数据存储结构与数据逻辑结构的变化而影响应用程序C.不会因为存储策略的变化而影响存储结构D.不会因为某些存储结构的变化而影响其他的存储结构6.描述数据库全体数据的全局逻辑结构和特性的是()。
A.模式B.内模式C.外模式D.用户模式7.要保证数据库的数据独立性,需要修改的是()。
A.模式与外模式B.模式与内模式C.三层之间的两种映射D.三层模式8.要保证数据库的逻辑数据独立性,需要修改的是()。
A.模式与外模式的映射B.模式与内模式之间的映射C.模式D.三层模式9.用户或应用程序看到的那部分局部逻辑结构和特征的描述是(),它是模式的逻辑子集。
A.模式B.物理模式C.子模式D.内模式10.下述()不是DBA数据库管理员的职责。
A.完整性约束说明B.定义数据库模式C.数据库安全D.数据库管理系统设计选择题答案:(1) C (2) A (3) D (4) C (5) B(6) A (7) C (8) A (9) C (10) D二、简答题1.试述数据、数据库、数据库系统、数据库管理系统的概念。
Database System Implementation Solutions for Chapter 6Solutions for Section 6.1Solutions for Section 6.3Solutions for Section 6.4Solutions for Section 6.5Solutions for Section 6.6Solutions for Section 6.7Solutions for Section 6.8Solutions for Section 6.9Solutions for Section 6.10Solutions for Section 6.1Exercise 6.1.1(a)Technically, the U_S operator assumes that the arguments are sets, as well as the result. Since the arguments are really bags, the best we can do is use the SQL union operator, which removes duplicates from the output even if there are duplicates in the input. The answer is {(0,1), (2,3), (2,4), (3,4), (2,5), (0,2)}.Exercise 6.1.1(i){(1,0,1), (5,4,9), (1,0,1), (6,4,16), (7,9,16)}.Exercise 6.1.1(k){(0,1), (0,1), (2,4), (3,4)}. Note that all five tuples of R satisfy the first condition, that the first component is less than the second. The last two tuples satisfy the condition that the sum of the components is at least 6, and the tuple (0,1) satisfies the condition that the sum exceed the product. Onlythe tuple (2,3) satisfies neither of the latter two conditions, and therefore doesn't appear in the result.Exercise 6.1.2(a){(0,1,2), (0,1,2), (0,1,2), (0,1,2), (2,3,5), (2,4,5), (3,4,5)}.Exercise 6.1.2(e){(0,1,4,5), (0,1,4,5), (2,3,2,3), (2,4,2,3)}.Exercise 6.1.2(g){(0,2), (2,7), (3,4)}.Exercise 6.1.3(a)One way to express the semijoin is by projecting S onto the list L of attributes in common with R and then taking the natural join: R JOINpi_L(S).A second way is to take the natural join first, and then project onto the attributes of R.Exercise 6.1.3(c)First, we need to find the tuples of R that don't join with S and therefore need to be padded. Let T = R - pi_M(R JOIN S), where M is the schema, or list of attributes, of R. Then the left outerjoin is (R JOIN S) UNION (T x N), where N is the suitable ``null'' relation with one tuple that has NULL for each attribute of S that is not an attribute of R.Exercise 6.1.5(a)When a relation has no duplicate tuples, DELTA has no effect on it. Thus, DELTA is idempotent.Exercise 6.1.5(b)The result of PI_L is a relation over the list of attributes L. Projecting this relation onto L has no effect, so PI_L is idempotent.Return to TopSolutions for Section 6.3Exercise 6.3.1(a)The iterator for pi_L(R) can be described informally as follows:Open():R.Open()GetNext():Let t = R.GetNext(). If Found = False, return. Else, construct andreturn the tuple consisting of the elements of list L evaluated fortuple t.Close():R.Close()Exercise 6.3.1(b)Here is the iterator for delta(R):Open():First perform R.Open(). Then, initialize a main-memorystructure S that will represent a set of tuples of R seen so far. Forexample, a hash table could be used. Initially, set S is empty. GetNext():Repeat R.GetNext() until either Found = False or a tuple t that is not in set S is returned. In the later case, insert t into S and return that tuple. Close():R.Close()Exercise 6.3.1(d)For the set union R1 union R2 we need both a set S that will store the tuples of R1 and a flag CurRel as in Example 6.13. Here is a summary of the iterator:Open()Perform R1.Open() and initialize to empty the set S.GetNext()If CurRel = R1 then perform t = R1.GetNext(). If Found = True, theninsert t into S and return t. If Found = False, then R1 is exhausted.Perform R1.Close(), R2.Open(), set CurRel = R2, and repeatedlyperform t = R2.GetNext() until either Found = False (in which case,just return), or t is not in S. In the latter case, return t.Close():Perform R2.Close()Exercise 6.3.3A group entry needs a value of starName, since that is the attribute we aregrouping on. It also needs an entry for the sum of lengths, since that sum is part of the result of the query of Exercise 6.1.6(d). Finally, the group entry needs a count of the number of tuples in the group, since this count isneeded to accept or reject groups according to the HAVING clause.Exercise 6.3.5(a)Read R into main memory. Then, for each tuple t of S, see if t joins with any of the tuples of R that are in memory. Output any of those tuples that do join with t, and delete them from the main-memory set.Exercise 6.3.5(b)Read S into memory. Then, for each tuple t of R, see if t joins with any tuple of S in memory; output t if so.Exercise 6.3.5(e)Read R into main memory. Then, for each tuple t of S, find those tuples in memory with which t joins, and output the joined tuples. Also mark as``used'' all those tuples of R that join with t. After S is exhausted, examine the tuples in main memory, and for each tuple r that is not marked ``used,'' pad r with nulls and output the result.Return to TopSolutions for Section 6.4Exercise 6.4.2The formula in Section 6.4.4 gives 10000 + 10000*10000/999 or 110,101. Return to TopSolutions for Section 6.5Exercise 6.5.2(a)An iterator for delta(R) must do the first sorting pass in its Open() function. Here is a sketch:Open():Perform R.Open() and repeatedly use R.GetNext() to readmemory-sized chunks of R. Sort each into a sorted sublist and writeout the list. Each of these lists may be thought of as having its owniterator. Open each list and initialize a data structure into which the``current'' element of each list may be read into main memory.Use GetNext() for each list to initialize the main-memory structurewith the first element of each list. Finally, execute R.Close(). GetNext():Find the least tuple t in the main-memory structure, and output onecopy of it. Delete all copies of t in main memory, using GetNext() for the appropriate sublist, until all copies of t have disappeared, thenreturn. If there was no such tuple t, because all the sublists wereexhausted, set Found = False and return.Close():Close all the sorted sublists.Exercise 6.5.2(c)For R1 intersect R2 do the following:Open():Open R1 and R2, use their GetNext() functions to read all their tuples in main-memory-sized chunks, and create sorted sublists, which arestored on disk. Initialize a main-memory data structure that will hold the ``current'' tuple of each sorted sublist, and usethe Open() and GetNext() functions of an iterator from each sublist toinitialize the structure to have the first tuple from each sublist. Finally, close R1 and R2.GetNext():Find the least tuple t among all the first elements of the sorted sublists.If t occurs on a list from R1 and a list from R2, then output t, removethe copies of t, use GetNext from the two sublists involved toreplentish the main-memory structure, and return. If t appears on only one of the sublists, do not output t. Ratherm remove it from its list,replentish that list, and repeat these steps with the new least t. Ifno t exists, because all the lists are exhausted, set Found = False andreturn.Close():Close all the sorted sublists.Exercise 6.5.3(b)The formula of Fig. 6.16 gives 5*(10000+10000) = 100,000. Note that the memory available, which is 1000 blocks, is larger than the minimum required, which is sqrt(10000), or 100 blocks. Thus, the method is feasible.Exercise 6.5.5(a)We effectively have to perform two nested-loop joins of 500 and 250 blocks, respectively, using 101 blocks of memory. Such a join takes 250 +500*250/100 = 1500 disk I/O's, so two of them takes 3000. To this number, we must add the cost of sorting the two relations, which takes four disk I/O's per block of the relations, or another 6000. The total disk I/O cost is thus 9000.Exercise 6.5.7(a)The square root of the relation size, or 100 blocks, suffices.Return to TopSolutions for Section 6.6Exercise 6.6.1(a)To compute delta(R) using a ``hybrid hash'' approach, pick a number of buckets small enough that one entire bucket plus one block for each of the other buckets will just fit in memory. The number of buckets would beslightly larger than B(R)/M. On the first pass, keep all the distinct tuples of the first bucket in main memory, and output them the first time they are seen. On the second pass, do a one-pass distinct operation on each of the other buckets.The total number of disk I/O's will be one for M/B(R) of the data and three for the remaining (B(R)-M)/B(R) of the data. Since the datarequires B(R) blocks, the total number of disk I/O's is M + 3(B(R) - M) =3B(R) - 2M, compared with 3B(R) for the standard approach.Exercise 6.6.4This is a trick question. Each group, no matter how many members, requires only one tuple in main memory. Thus, no modifications are needed, and in fact, memory use will be pleasantly small.Return to TopSolutions for Section 6.7Exercise 6.7.1(a)Our option is to first copy all the tuples of R to the output. Then, for each tuple t of S, retrieve the tuples of R for which R.a matches the a-value of t. Check whether t appears among them, and output t if not.This method can be efficient if S is small and V(R,a) is large.Exercise 6.7.2(a)The values retrieved will fit on about 10000/k blocks, so that is the approximate cost of the selection.Exercise 6.7.5There is an error (see The Errata Sheet in that the relation Movie shouldbe StarsIn. However, it doesn't affect the answer to the question, as long as you believe the query can be answered at all.The point is that with the index, we have only to retrieve the blocks containing MovieStar records for the stars of ``King Kong.'' We don't know how many stars there are, but it is safe to assume that their records willoccupy many more blocks than there are stars in the two ``King Kong'' movies. Thus, using the index allows us to take the join while accessing only a small part of the MovieStar relation and is therefore to be preferred toa sort- or hash-join, each of which will access the entire MovieStar relation at least once.Return to TopSolutions for Section 6.8Exercise 6.8.1(a)One of the relations must fit in memory, which means thatmin(B(R),B(S)) >= M/2.Exercise 6.8.1(b)We can only assume that there will be M/2 blocks available during the first pass, so we cannot create more than M/2-1 buckets. Each pair of matching buckets must be joinable in a one-pass join, which means one of each pair of corresponding buckets must be no larger than M/2, as we saw in part (a). Since the average bucket size will be 1/(M/2 - 1) of the size of its relation, we require min(B(R),B(S))/(M/2 - 1) >= M/2, or approximatelymin(B(R),B(S)) >= M^2/4. This figure should be no surprise; it simply says we must make the most conservative assumption at all times about the size of memory.Return to TopSolutions for Section 6.9Exercise 6.9.1(a)The way we have defined the recursive algorithm, it always divides relations into M-1 pieces (100 pieces in this exercise) if it has to divide at all. In practice, we may have options to use fewer pieces at one or more levels or the recursion, and in this exercise there are many such options. However, we'll describe only the one that matches the policy given in the text. In what follows, all sorting and merging is based on the values of tuples in the join attributes only, since we are describing a join operation.Level 1: R and S are divided into 50 sublists each. The sizes of the lists are 400 and 1000 blocks, for R and S, respectively. Note that no disk I/O's are performed yet; the partition is conceptual.Level 2: Each of the sublists from Level 1 are divided into 100 subsublists; the sizes of these lists are 4 blocks for R, and 10 blocks for S. Again, no disk I/O's are performed for this conceptual partition.Level 3: We sort each of the subsublists from Level 2. Each block is read once from disk, and an equal number of blocks are written to disk as the sorted subsublists.Return to Level 2: We merge each of the 100 subsublists that comprise one sublist, using the standard multiway merging algorithm. Every block is read and written once during this process.Return to Level 1: We merge each of the 50 sorted sublists from R and the 50 sorted sublists from S, thus joining R and S. Each block is read once during this part.Return to TopSolutions for Section 6.10Exercise 6.10.1(a)If the division of tuples from R is as even as possible, some processors will have to perform 13 disk I/O's, but none will have to perform more. The 13 disk I/O's take 1.3 seconds, so the speedup is 10/1.3 or about 7.7.Return to Top。