cudnn配置环境变量
- 格式:docx
- 大小:36.86 KB
- 文档页数:2
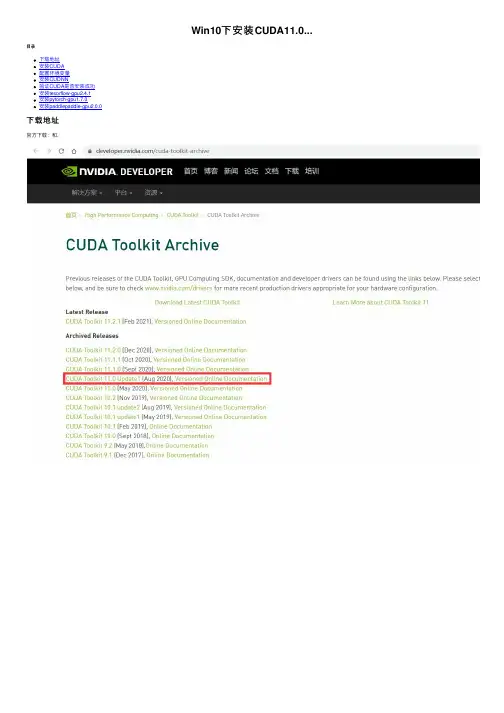
Win10下安装CUDA11.0...⽬录下载地址安装CUDA配置环境变量安装CUDNN验证CUDA是否安装成功安装tesorflow-gpu2.4.1安装pytorch-gpu1.7.0安装paddlepaddle-gpu2.0.0下载地址官⽅下载:和.安装之前,建议关掉360安全卫⼠双击cuda_11.0.3_451.82_win10.exe⽂件根据⾃⼰需要更改安装路径将Visual Studio Integration的勾去掉配置环境变量C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\libnvvp;安装CUDNN将下载的CUDNN解压缩,如下图。
将将CUDNN⽂件夹⾥⾯的bin、include、lib⽂件直接复制到CUDA的安装⽬录,如下图为CUDA的安装位置,粘贴过来直接覆盖即可。
# CUDA的安装⽬录C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0等待复制完成,即可!验证CUDA是否安装成功打开cmd,输⼊如下命令,即可!nvcc -V安装tesorflow-gpu2.4.1查看对应版本pip install -i https:///simple tensorflow-gpu==2.4.1测试代码import tensorflow as tfimport osos.environ['TF_CPP_MIN_LOG_LEVEL']='2'print(tf.__version__)a = tf.constant(1.)b = tf.constant(2.)print(a+b)print('GPU:', tf.test.is_gpu_available())安装pytorch-gpu1.7.0查看对应版本pip install torch===1.7.0+cu110 torchvision===0.8.1+cu110 torchaudio===0.7.0 -f https:///whl/torch_stable.html测试代码import torchprint(torch.__version__)print(torch.cuda.is_available())安装paddlepaddle-gpu2.0.0查看对应版本python -m pip install paddlepaddle-gpu==2.0.0.post110 -f https:///whl/stable.html测试代码import paddlepaddle.utils.run_check()到此这篇关于Win10下安装CUDA11.0+CUDNN8.0+tensorflow-gpu2.4.1+pytorch1.7.0+paddlepaddle-gpu2.0.0的⽂章就介绍到这了,更多相关tensorflow pytorch CUDA 安装内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。

linux cuda cudnn 卸载摘要:1.介绍CUDA 和cuDNN2.CUDA 和cuDNN 的安装3.CUDA 和cuDNN 的卸载4.总结正文:一、介绍CUDA 和cuDNNCUDA(Compute Unified Device Architecture)是NVIDIA 推出的一种通用并行计算架构,它允许开发人员使用NVIDIA 的GPU 来进行高性能计算。
而cuDNN(CUDA Deep Neural Network library)是专为深度神经网络计算而设计的GPU 加速库,它提供了许多深度学习所需的计算功能,如卷积、池化等。
二、CUDA 和cuDNN 的安装在安装CUDA 和cuDNN 之前,确保系统中已正确安装了NVIDIA 驱动。
以下是在Linux 系统中安装CUDA 和cuDNN 的步骤:1.首先,访问NVIDIA 官网,下载与系统相匹配的CUDA 版本。
2.解压缩下载的文件,进入解压后的文件夹。
3.在终端中执行如下命令安装CUDA:```sudo./install_cuda_linux.sh```4.安装cuDNN:```sudo cp /usr/local/cuda/include/cuDNN/.* /usr/local/cuda/include sudo cp /usr/local/cuda/lib64/tensore_core.* /usr/local/cuda/lib64 ```5.设置环境变量:```export PATH=/usr/local/cuda/bin:$PATHexport LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH ```三、CUDA 和cuDNN 的卸载卸载CUDA 和cuDNN 的步骤如下:1.卸载cuDNN:```cd /usr/local/cuda-11.5/bin./cuda-uninstaller```2.卸载CUDA:```sudo rm -rf /usr/local/cuda```3.删除解压文件:```sudo rm -rf /usr/local/cuda```四、总结本文介绍了CUDA 和cuDNN 在Linux 系统中的安装与卸载方法。

linux环境GPU版pytorch安装教程在Linux环境下安装GPU版PyTorch需要进行以下步骤:1.确认显卡驱动:首先要确保系统中正确安装了适配自己显卡的驱动程序。
可以通过输入以下命令来检查显卡驱动版本:```nvidia-smi```如果出现显卡驱动的信息说明已经正确安装。
2. 安装CUDA:PyTorch使用CUDA进行GPU加速,所以需要安装对应的CUDA版本。
可以通过以下步骤安装CUDA:```chmod +x cuda_*.runsudo ./cuda_*.run```安装过程中会询问是否安装NVIDIA驱动,如果之前已经安装了驱动则无需再次安装。
c. 添加CUDA路径到系统环境变量。
找到cuda安装目录下的bin文件夹,打开终端,并执行以下命令:```export PATH=/usr/local/cuda-<version>/bin${PATH:+:${PATH}}export LD_LIBRARY_PATH=/usr/local/cuda-<version>/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}} ```其中`<version>`为CUDA的版本号,例如`11.0`。
3. 安装cuDNN:cuDNN是NVIDIA提供的用于深度学习框架的GPU加速库,PyTorch需要使用到它。
可以按照以下步骤安装cuDNN:4. 创建虚拟环境:为了避免与系统Python环境冲突,最好在安装PyTorch之前创建一个虚拟环境。
可以使用`virtualenv`或者`conda`来创建虚拟环境。
这里使用`conda`为例:a. 如果没有安装`conda`,可以先安装`conda`,并创建一个新的环境:```conda create -n pytorch_env python=3.7```在这个例子中,我们创建了一个名为`pytorch_env`的环境,并选择了Python 3.7版本。

不同版本python添加环境变量的方法在大多数操作系统中,为Python添加环境变量通常是为了能够从任何位置运行Python脚本,或者能够找到Python的安装目录。
以下是针对不同版本Python添加环境变量的方法:Python (Windows)1. 使用安装程序: 在安装Python时,通常会有一个选项来选择是否将Python添加到系统PATH。
选择“Add Python to PATH”来将Python 添加到环境变量。
2. 手动添加: 如果您没有在安装过程中选择此选项,您需要手动添加。
打开“系统属性” -> “高级” -> “环境变量”。
在“系统变量”下,找到并选择“Path”,然后点击“编辑”。
在弹出的窗口中,点击“新建”,然后输入Python的安装路径(例如 `C:\Python39`)。
3. 使用命令行: 打开命令提示符或PowerShell,然后输入以下命令来验证Python是否已添加到环境变量:```bashpython -c "import sys; print()"```如果此命令返回了Python的完整路径,那么您已经成功地将Python添加到了环境变量。
Python (Linux/macOS)1. 使用包管理器: 如果您使用的是如APT或Homebrew这样的包管理器安装的Python,通常这些包管理器会自动将Python添加到环境变量。
2. 手动添加: 如果您没有使用包管理器或需要手动添加,可以编辑`~/.bashrc`或`~/.bash_profile`文件(取决于您的系统),并添加以下行:```bashexport PATH=$PATH:/path/to/your/python```然后运行`source ~/.bashrc`或`source ~/.bash_profile`使更改生效。
3. 使用命令行: 打开终端,然后输入以下命令来验证Python是否已添加到环境变量:```bashwhich python3```如果此命令返回了Python的路径,那么您已经成功地将Python添加到了环境变量。

Python中的环境变量配置技巧Python是一种高级编程语言,其独特的语法和强大的库使之在数据科学、人工智能等领域广泛应用。
在使用Python编写程序时,经常需要使用到一些环境变量,如PATH、PYTHONPATH等。
本文旨在介绍Python中的环境变量配置技巧,以帮助Python开发者更好地使用Python。
一、环境变量的作用环境变量是操作系统用来存储一些重要信息的一种机制。
在使用Python时,环境变量主要有以下两种作用:1.指定Python解释器的位置使用Python编写程序时,需要指定Python解释器的位置。
环境变量可以将Python解释器的位置添加到系统的PATH变量中,从而让系统可以找到Python解释器的位置,避免每次使用Python时都需要输入Python解释器的路径。
2.添加Python模块的搜索路径在使用Python开发程序时,需要引用各种Python模块。
环境变量可以将Python模块的搜索路径添加到系统的PYTHONPATH变量中,从而让程序可以找到所需的Python模块。
二、环境变量的配置方法在Python中,环境变量的配置方法主要有以下三种:1.在命令行中设置环境变量在Linux和macOS系统中,可以使用export命令设置环境变量。
例如,将Python解释器的位置/usr/bin/python添加到系统的PATH变量中,可以使用以下命令:export PATH=$PATH:/usr/bin/python这样,在使用Python时,就不需要指定Python解释器的位置了。
如果需要将Python模块的搜索路径添加到系统的PYTHONPATH变量中,可以使用以下命令:export PYTHONPATH=/path/to/mymodule这样,程序就可以找到模块路径了。
在Windows系统中,可以使用set命令设置环境变量。
例如,将Python解释器的位置C:\Python27添加到系统的PATH变量中,可以使用以下命令:set PATH=%PATH%;C:\Python27如果需要将Python模块的搜索路径添加到系统的PYTHONPATH变量中,可以使用以下命令:set PYTHONPATH=C:\Python27\Lib\site-packages2.在Python程序中设置环境变量在Python程序中,可以使用os模块设置环境变量。

windows安装cuda的方法
CUDA是NVIDIA公司开发的一个并行计算平台和编程模型,可以让开发者使用GPU来加速应用程序的运算速度。
在Windows操作系统下,安装CUDA可以让开发者在本地环境中进行CUDA程序的编写和测试。
以下是安装CUDA的方法:
1. 下载CUDA安装包
从NVIDIA官网下载与自己显卡型号和操作系统版本相匹配的CUDA安装包。
2. 安装CUDA Toolkit
运行下载的CUDA安装包,按照提示完成安装。
3. 配置环境变量
在环境变量中添加CUDA的路径,以便在命令行中运行CUDA程序。
在系统变量中添加以下两个环境变量:
(1)CUDA_PATH:CUDA安装路径,例如“C:Program FilesNVIDIA GPU Computing ToolkitCUDAv10.1”
(2)PATH:CUDA相关的路径,例如
“%CUDA_PATH%bin;%CUDA_PATH%libnvvp”
4. 安装显卡驱动
安装显卡驱动可以确保CUDA程序能够正常运行。
从NVIDIA官网下载与自己显卡型号和操作系统版本相匹配的显卡驱动程序,运行安装即可。
5. 验证CUDA安装成功
在命令行中输入“nvcc -V”,如果输出CUDA的版本信息,则表示CUDA安装成功。
现在,您已经完成了在Windows操作系统下安装CUDA的全部步骤,可以开始使用CUDA进行并行计算了。
Windows下安装CUDA8.0在Win10下安装CUDA8.0,并使⽤VS2013测试;机器配置:Windows 10VS 2013CUDA8.0CUDA 8.0:CUDA其他版本:1. 安装CUDA 8.0双击安装下载的.exe⽂件,然后选择解压路径,如下图,解压到哪⾥⽆所谓,安装成功会⾃动删除;解压完成后,得到如下图:精简:安装所有CUDA模块,并覆盖掉当前的NVIDIA驱动程序;(说实话,容易出问题)⾃定义:选择⾃⼰想要安装的模块,此处选择这⾥;选择⾃定义后,出现下图所⽰:下⾯⼏个模块准确具体有什么⽤,不能100%确定,但能⼤概才出来:CUDA:这个是必须的,下⾯有CUDA Runntime、Samples⼀些东西;NVIDIA GeForce Experience:这个好像是为了更好的游戏体验,之前安装显卡驱动程序时也提⽰是否安装,果断拒绝了;Other components:这⾥的PhysX好像也是为了游戏体验来的;Driver components:这个就要慎重了,意思就是重新安装显卡驱动程序;如果之前已经成功安装驱动程序,这⾥就不⽤选了;如果之前没安装驱动程序,建议还是去官⽹上单独下载驱动程序进⾏安装吧;选择好需要安装的模块,就要选择安装路径了,我的选择如下图:在如图所⽰位置建⽴相应⽂件夹,然后再指定安装路径;安装成功后;Ctrl+R,打开cmd:nvcc -V输出版本信息,则表明安装成功;配置环境变量将F:\CUDA\NVIDIA GPU Computing Tookit\CUDA\v8.0\lib\x64添加的系统变量的path中;2. 安装CuDNN下载对应CUDA 8.0版本的CuDNN:(如果安装的是其他版本的CUDA,注意CuDNN的版本)下载完成后,解压得到⼀个名为cuda的⽂件夹;将该⽂件夹下的⽂件复制到上⼀步安装的CUDA中;注意对应的⽂件夹;./cuda/bin/**.dll 复制到 ./NVIDIA GPU Computing Tookit/CUDA/v8.0/bin/./cuda/include/**.dll 复制到 ./NVIDIA GPU Computing Tookit/CUDA/v8.0/include/./cuda/lib/x64/**.dll 复制到 ./NVIDIA GPU Computing Tookit/CUDA/v8.0/lib/x64/安装完成;3. 测试1使⽤VS2013打开./cuda/v8.0/Samples_vs2013.sln;加载完成后,执⾏本地Windows编译,最后输出成功,见下图;4. 测试2在VS2013上配置CUDA;4.1 新建项⽬并进⾏配置1. 打开VS2013,新建空⽩项⽬,设置项⽬名称、位置信息,如下图;2. 在源⽂件添加—>新建项—>NVIDIA CUDA 8.0—>CUDA C/C++ File,命名为hello.cu,如下图;hello.cu右键—>属性—>配置属性—>常规—>项类型,配置如下图;3. 在项⽬上右键—>⽣成依赖项—>⽣成⾃定义—>选择CUDA 8.0,如下图;4. 在项⽬上右键—>属性—>常规—>配置管理器—>活动解决⽅案平台(新建)—>键⼊或选择新平台(选择x64),如下图;5. 项⽬右键—>属性—>VC++⽬录—>包含⽬录,如下图,添加;F:\CUDA\NVIDIA GPU Computing Tookit\CUDA\v8.0\include6. 项⽬右键—>属性—>VC++⽬录—>库⽬录,如下图,添加;F:\CUDA\NVIDIA GPU Computing Tookit\CUDA\v8.0\lib\x647. 项⽬右键—>属性—>链接器—>常规,如下图,添加;$(CUDA_PATH_V8_0)\lib\$(Platform)8. 项⽬右键—>属性—>链接器—>输⼊—>附加依赖项,如下图,添加;注意:不同版本的CUDA,下⾯的lib是不同的;当然,⼀个项⽬也不⼀定需要所有的lib;具体有哪些lib,位于:F:\CUDA_Dev_Doc_Sam\v8.0\lib\x64;cublas.libcublas_device.libcuda.libcudadevrt.libcudart.libcudart_static.libcudnn.libcufft.libcufftw.libcurand.libcusolver.libcusparse.libnppc.libnppi.libnppial.libnppicc.libnppicom.libnppidei.libnppif.libnppig.libnppim.libnppist.libnppisu.libnppitc.libnpps.libnvblas.libnvcuvid.libnvgraph.libnvml.libnvrtc.libOpenCL.lib4.2 编译在上⾯建的hello.cu⽂件中添加下⾯代码:// CUDA runtime 库 + CUBLAS 库#include <cuda_runtime.h>#include <cublas_v2.h>#include <device_launch_parameters.h>#include <time.h>#include <iostream># pragma warning (disable:4819)using namespace std;bool initDevice(void)int cnt, i;cudaGetDeviceCount(&cnt);if (cnt < 0){cout << "Can not find CUDA device" << endl;return false;}for (i = 0; i < cnt; i++){cudaDeviceProp porp;if (cudaGetDeviceProperties(&porp, i) == cudaSuccess){if (porp.major >= 1) {break;}}}if (i == cnt){cout << "< 1.0" << endl;}return true;}__global__ void kernel_compute(float *model, float *input, float *output){int idx_x, idx_y;idx_y = blockIdx.x;idx_x = idx_y * blockDim.x + threadIdx.x;float sum = 0;for (int i = 0; i < 9; i++){sum += input[idx_x] * model[i];}//printf("%3d %d %2.6f %2.6f\n", idx_x, idx_y, sum, input[idx_x]);output[idx_x] = sum;}/*block ---> row*/int buildMaps(float *model, float *input, float *output, int height, int width){initDevice();float *dev_m = NULL, *dev_i = NULL, *dev_o = NULL;int size = height * width;cudaMalloc((void **)&dev_m, 9 * sizeof(float));cudaMalloc((void **)&dev_i, size * sizeof(float));cudaMalloc((void **)&dev_o, size * sizeof(float));cudaMemcpy(dev_m, model, 9 * sizeof(float), cudaMemcpyHostToDevice);cudaMemcpy(dev_i, input, size * sizeof(float), cudaMemcpyHostToDevice);dim3 grid(height, 1, 1);dim3 block(width, 1, 1);kernel_compute << <grid, block >> > (dev_m, dev_i, dev_o);cudaMemcpy(output, dev_o, size * sizeof(float), cudaMemcpyDeviceToHost); return 0;}新建main.cpp⽂件;#include <iostream>#include <Windows.h>#include <stdlib.h>#include <time.h>using namespace std;extern int buildMaps(float *model, float *input, float *output, int height, int width); void show(float *ptr, int height, int width, char *str){cout << str << " : " << endl;for (int h = 0; h < height; h++){for (int w = 0; w < width; w++){int cnt = h * width + w;printf("%5.5f ", ptr[cnt]);}cout << endl;}}#define width 5#define size (width * width)int main(){float *model = (float *)malloc(9 * sizeof(float));float *input = (float *)malloc(size * sizeof(float));float *output = (float *)malloc(size * sizeof(float));if (!model || !input || !output){std::cout << "Malloc Error" << endl;exit(-1);for (int i = 0; i < 9; i++){model[i] = (float)(i);}srand((unsigned)time(0));for (long long int i = 0; i < size; i++){input[i] = ((rand() % 100) * 1.f) / (rand() % 100 + 1);}buildMaps((float *)model, (float *)input, output, width, width); show(model, 3, 3, "model");show(input, width, width, "input");show(output, width, width, "output");int a;cin >> a;}编译,输出结果为:。

pytorch cuda编译摘要:1.Pytorch CUDA 概述2.编译前的准备工作3.编写代码和配置文件4.编译和测试5.总结正文:一、Pytorch CUDA 概述Pytorch 是一种基于Python 的机器学习库,广泛应用于各种深度学习任务。
为了提高计算性能,Pytorch 提供了CUDA 支持,允许用户在NVIDIA GPU 上运行深度学习模型。
CUDA(Compute Unified Device Architecture)是NVIDIA 推出的一种通用并行计算架构,通过CUDA,用户可以使用NVIDIA GPU 进行高性能计算。
二、编译前的准备工作在使用Pytorch CUDA 之前,需要确保以下几点:1.安装NVIDIA 驱动:首先,需要确保你的系统中安装了最新版本的NVIDIA 驱动。
2.安装CUDA:其次,需要安装CUDA Toolkit。
可以从NVIDIA 官网上下载对应版本的CUDA Toolkit。
3.安装cuDNN:安装CUDA 的同时,需要安装cuDNN(CUDA DeepNeural Network library),它是专为深度学习而设计的GPU 加速库。
4.配置环境变量:将CUDA 和cuDNN 的安装路径添加到系统环境变量中,以便Pytorch 能够找到它们。
5.验证安装:可以使用“nvcc --version”和“cuDNN --version”命令检查CUDA 和cuDNN 的版本。
三、编写代码和配置文件编写Pytorch CUDA 代码时,需要遵循以下几个步骤:1.创建一个新的Pytorch 项目:使用`pytorch.nn.Module`创建一个新的深度学习模型。
2.编写前向传播和反向传播的代码:为模型编写前向传播和反向传播的代码,以便训练模型。
3.配置CUDA:在Pytorch 模型中,使用`torch.cuda`模块配置CUDA。
需要指定GPU 设备,并将模型移动到GPU 设备上。

深度学习环境配置指南!(Windows、Mac、Ubuntu全讲解)第⼀时间获取价值内容⼊门深度学习,很多⼈经历了从⼊门到放弃的⼼酸历程,且千军万马倒在了⼊门第⼀道关卡:环境配置问题。
俗话说,环境配不对,学习两⾏泪。
如果你正在⾯临配置环境的痛苦,不管你是Windows⽤户、Ubuntu⽤户还是苹果死忠粉,这篇⽂章都是为你量⾝定制的。
接下来就依次讲下Windows、Mac和Ubuntu的深度学习环境配置问题。
⼀、Windows系统深度学习环境配置系统:Win10 64位操作系统安装组合:Anaconda+PyTorch(GPU版)+GTX1060开源贡献:伍天⾈,内蒙古农业⼤学1.1 打开Anaconda Prompt1、conda create -n pytorch python=3.7.0:创建名为pytorch的虚拟环境,并为该环境安装python=3.7。
2、activate pytorch:激活名为pytorch的环境1.2 确定硬件⽀持的CUDA版本NVIDIA控制⾯板-帮助-系统信息-组件2020年5⽉19⽇16:46:31,我更新了显卡驱动,看到我的cuda⽀持11以内的1.3 确定pytorch版本,torchvision版本因为官⽅源太慢了,这⾥使⽤清华源下载1.4 镜像中下载对应的安装包清华镜像:https:///anaconda/cloud/pytorch/win-64/pytorch:torchvision:1.5 本地安装接着第⼀步,在pytorch环境下进⾏安装,依次输⼊如下指令。
然后回到虚拟环境所在⽬录,⽤conda install anaconda安装环境所需的基础包1.6 测试代码1:from future import print_functionimport torchx = torch.rand(5, 3)print(x)输出类似于以下的张量:代码2:import torchtorch.cuda.is_available()输出:True如果以上两段代码输出⽆异常,表明环境搭建成功。

最详细不过的CUDA的下载安装使⽤、环境变量配置,有这⼀篇就够了在上⼀期中,我们介绍了为什么使⽤GPU可以加速计算和处理图像,以及查看⾃⼰的电脑能否使⽤GPU加速,不知道的可以去看上⼀期⽂章,这期我们正式的来下载与安装GPU加速⼯具CUDA,并检查是否安装成功。
前⾔:可以看到,如果我们想要下载安装CUDA需要有NVIDA的显卡、Windows系统、Visual Studio,即:第⼀步:查看⾃⼰电脑是否有NVIDA显卡。
第⼆步:查看⾃⼰是否有⽀持的版本的微软Windows系统,具体⼤家可看上图Table1。
第三步:查看⾃⼰是否有⽀持版本的Visual Studio,因为我们在安装CUDA时需要⽤到其中的组件,具体请看上图Table2。
安装⼯作总结查看⾃⼰有是否有⽀持NVIDA的独⽴显卡查看⾃⼰是否有NVIDA显卡驱动程序,没有请下载安装官⽹下载安装 Microsoft Visual Studio(申请⼀个微软账号)官⽹下载安装 CUDA检验CUDA安装是否成功CUDA安装成功后的使⽤这⾥教⼤家安装CUDA10.2和免费社区版VS2017的下载和安装教程正式下载与安装CUDA第⼀步:查看⾃⼰是否有⽀持安装CUDA的NVIDA显卡,具体请见我上期⽂章。
安装完后,可以打开NVIDA控制⾯板,查看GPU显卡所⽀持的CUDA版本,具体开始菜单 -》NVIDIA控制⾯板-》帮助-》系统信息-》组件-》nvidia.dll后⾯的cuda参数,可以看到,我的显卡⽀持版本为10.2,所以我下载安装cuda10.2版本。
第三步:下载安装 Visual Studio安装Visual Studio,因为CUDA在安装时,需要VS的⾥⾯的⼯具包来编译。
VS这⾥我安装的是社区免费版VS2017,⽆需秘钥key就可以使⽤,也可以使⽤其它版本,但是需要key,请见第⼀张图的Table2,在安装过程中,会⾃动检测本机是否已经安装了配套的VS版本其中之⼀,如果VS版本和Cuda版本不匹配的话,安装⽆法进⾏。

linux cuda cudnn 卸载-回复如何在Linux操作系统上卸载CUDA和cuDNN?CUDA和cuDNN是用于进行深度学习和并行计算的两个重要软件包。
然而,在某些情况下,你可能需要将它们从你的Linux操作系统上卸载。
本文将一步一步地指导你如何在Linux操作系统上卸载CUDA和cuDNN。
卸载CUDA:1. 第一步是先停止任何正在运行的CUDA相关的进程。
你可以通过在终端中运行以下命令来检查CUDA进程:nvidia-smi这个命令将显示当前正在运行的NVIDIA GPU相关的进程。
当然,这里假设你已经安装了NVIDIA驱动程序。
如果你看到任何与CUDA相关的进程,请通过运行以下命令终止它们:sudo kill -9 <PID>这里的`<PID>`是你要终止的进程的ID。
2. 接下来,你需要卸载NVIDIA驱动程序。
你可以使用以下命令来卸载驱动程序:sudo apt-get purge nvidia-*这个命令将会删除与任何NVIDIA驱动程序相关的软件包。
3. 现在你应该通过以下命令从系统中删除NVIDIA相关的配置文件:sudo rm /etc/X11/xorg.conf这个命令将删除Xorg服务器的配置文件。
4. 最后,你可以通过以下命令来删除CUDA目录:sudo rm -rf /usr/local/cuda这个命令将删除CUDA的安装目录。
卸载cuDNN:1. 首先,你需要找到你在系统上安装了cuDNN的路径。
你可以通过运行以下命令来找到它:sudo updatedblocate cudnn这个命令将更新系统的文件数据库,并搜索包含"cudnn"关键词的文件和目录。
2. 找到包含cuDNN文件的目录后,你可以删除这个目录。
例如,如果cuDNN文件存储在`/usr/local/cuda-10.2`目录中,你可以执行以下命令来删除它:sudo rm -rf /usr/local/cuda-10.23. 接下来,你需要编辑你的bash配置文件,以删除与cuDNN相关的环境变量。
cuda、cudnn下载安装教程cuda、cudnn下载安装教程
安装环境:
l 操作系统:win10
l python版本:3.8
l NVIDIA显卡驱动版本:432.0
l CUDA:10.1
l cudnn:8.0.3
注意CUDA、cudnn、 NVIDIA显卡驱动版本之间的匹配
⼀般⽽⾔,不同版本的CUDA要求不同的NVIDIA驱动版本,同时显卡驱动版本要不低于CUDA的安装版本,官⽅的版本对应要求说明:
具体的对照关系如下:
⼀、 cuda
1.1 cuda下载
下载地址:
如图:
双击击应⽤程序
安装cuda时,第⼀次会让设置临时解压⽬录,第⼆次会让设置安装⽬录;
临时解压路径,建议默认即可,也可以⾃定义。
安装结束后,临时解压⽂件夹会⾃动删除;
⼀路默认就可
添加cuda环境变量(控制⾯板—系统和安全—系统—⾼级系统设置---环境变量)
⼆、 cudnn
2.1 cudnn下载
下载地址:
注:需要注册登录才能下载
如图:
2.2 cudnn安装
解压⽂件夹,将解压后的⽂件夹下的⽂件拷贝到cuda安装⽬录与之相对应的⽂件夹下。
完⼯!!。
ubuntu利⽤conda创建虚拟环境,并安装
cuda,cudnn,pytorch
cd到安装包所在⽬录,安装:bash Anaconda3-5.1.0-Linux-x86_64.sh
创建虚拟环境:conda create -n your_env_name python=3.6
激活虚拟环境:source activate your_env_name
添加conda国内镜像:
1. conda config --add channels https:///anaconda/pkgs/free/
2. conda config --add channels https:///anaconda/pkgs/main/
3. conda config --add channels https:///anaconda/cloud/pytorch/
4. conda config --set show_channel_urls yes
安装pytorch指定版本:conda install pytorch=0.3.0 torchvision=0.2.0 -c soumith
或
根据电脑环境,按照pytorch官⽹对应代码安装
注:
安装conda完成后,输⼊conda list,若出现未找到命令,则需修改环境变量:export PATH=~/anaconda3/bin:$PATH(此法每次开机后都要修改,也可修改配置⽂件永久⽣效)
每个不同镜像⽹站⾥⾯包含各种不同的下载包,可根据⾃⼰的需求打开查找对应的安装包,。
Ubuntu18.04安装CUDA10.2+cuDNN 1 安装CUDA10.2下载CUDA:,选择CUDA Toolkit 10.2版本选择操作系统、架构、Distribution及其版本(这⾥是Ubuntu18.04)和runfile(local)⽂件格式可以使⽤wget下载,亦可复制链接进⾏下载下载完成后:sudo sh cuda_10.2.89_440.33.01_linux.run步骤说明:(1)Do you accept the above EULA? accept(2)CUDA Installer 取消Driver安装(Enter选择/取消)-> Install(3)⽇志配置环境变量:vim ~/.bashrc添加:export PATH=/usr/local/cuda-10.2/bin:$PATHexport LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH⽣效:source ~/.bashrc验证:cd /usr/local/cuda-10.2/samples/1_Utilities/deviceQuerysudo make./deviceQuery出现如下输出,则CUDA安装成功或nvcc -V出现如下输出,则CUDA安装成功。
2 安装cuDNN下载cuDNN:(需注册)选择:I Agree To the Terms of the cuDNN Software License Agreement -> Archived cuDNN Releases选择适配Ubuntu、CUDA 10.2的最新版cuDNN v8.2.2 -> cuDNN Library for Linux (x86)下载完成后,解压,进⼊相应⽬录,运⾏以下命令:sudo cp cuda/include/cudnn.h /usr/local/cuda-10.2/includesudo cp cuda/include/cudnn_version.h /usr/local/cuda-10.2/includesudo cp cuda/lib64/libcudnn* /usr/local/cuda-10.2/lib64sudo chmod a+r /usr/local/cuda-10.2/include/cudnn.hsudo chmod a+r /usr/local/cuda-10.2/include/cudnn_version.hsudo chmod a+r /usr/local/cuda-10.2/lib64/libcudnn*验证:cat /usr/local/cuda-10.2/include/cudnn_version.h | grep CUDNN_MAJOR -A 2。
Ubuntu20.04CUDAcuDNN安装⽅法(图⽂教程)CUDA安装下载cuda输⼊nvidia-smi命令查看⽀持的cuda版本如果⽆法查看,则说明尚未安装nvidia驱动,点击附加驱动,选择对应版本的驱动即可⾃动下载。
Ubuntu20.04⾃带的gcc版本为9.7.0,需要添加gcc7才可安装cuda10.2,输⼊命令安装gcc7apt-get install gcc-7 g++-7查看gcc版本,可以看到⽬前系统中存在7和9两个版本使⽤update-alternatives进⾏版本切换,输⼊以下命令:sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 100sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-9 50此时输⼊sudo update-alternatives --config gcc命令查看gcc的默认版本,可以看到当前默认gcc版本为7,即切换成功。
安装cuda输⼊命令进⾏安装sudo sh cuda_10.2.89_440.33.01_linux.run点击continuecuda安装包是⾃带显卡驱动的,所以这⼀步按空格去掉安装显卡驱动的选项,然后选择install配置环境变量输⼊gedit ~/.bashrc命令打开⽂件,在⽂件结尾输⼊以下语句,保存。
export PATH=/usr/local/cuda-10.2/bin${PATH:+:${PATH}}export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}更新环境变量配置source ~/.bashrc⾄此cuda安装完成,输⼊nvcc -V命令查看cuda信息安装cuDNN下载解压之后,将cuda/include/cudnn.h⽂件复制到usr/local/cuda/include⽂件夹,将cuda/lib64/下所有⽂件复制到/usr/local/cuda/lib64⽂件夹中,并添加读取权限:sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*⾄此cuDNN安装完成到此这篇关于Ubuntu 20.04 CUDA&cuDNN安装⽅法(图⽂教程)的⽂章就介绍到这了,更多相关Ubuntu20.04 CUDA&cuDNN安装内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
Windows10下Tensorflow2.0安装及环境配置教程(图⽂)下载安装Anaconda下载地址,根据所需版本下载安装过程暂略(下次在安装时添加)下载安装Pycharm下载安装,下载对应使⽤版本即可如果你是在校学⽣,有学校的edu邮箱,可以免费注册Pycharm专业版,注册地址如下,本⽂不详细说明下载CUDA10.0下载地址如下下载之后默认安装即可下载CUDNN通过此处选择版本对应的,对于本次配置就选择Windows 10对应的版本下载CUDNN需要注册⼀个NVIDIA的账号,点击注册,登录即可下载好CUDNN之后将其解压在CUDA的安装⽬录下,Win10默认的安装⽬录如下:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0之后,通过右键点击此电脑——>属性——>⾼级系统设置——>环境变量然后配置环境变量,添加如下环境变量重新安装NVIDIA最新驱动因为安装CUDA时,因为版本原因,会安装版本较低的NVIDIA驱动,所以我们从官⽹下载最新的驱动重新覆盖安装⼀遍即可创建Conda环境,并安装tensorflow2.0通过Anaconda的conda create创建新的环境,便于我们程序及其环境的配置及其管理⾸先按Win+R键,输⼊cmd,回车然后在cmd界⾯输⼊,conda create --name tensorflow2.0 python=3.7,其中tensorflow2.0可以换成你想要的名字回车后输⼊y之后稍作等待可以看到安装成功使⽤conda info --env看看环境之后使⽤conda activate tensorflow2.0来激活刚才创建的环境依据需求pip安装tensorflow,sklearn,matplotlib等软件。
此处以tensorflow2.0为例,激活环境后输⼊pip install tensorflow-gpu,之后进⾏下载安装。
ubuntu---NVIDIA驱动+CUDA安装完可能会遇见的问题如果稍不注意:系统内核、GCC、下载的版本不对应、安装过程中选项选择不正确,在NVIDIA驱动 + CUDA 安装完后可能会遇见⼀些问题。
⼀、可能的操作:(1)nivida驱动安装完之后,重启电脑,发现GPU⽆法正常使⽤,出现⽆法登录桌⾯系统、分辨率改变等问题。
(2)CUDA安装完之后,重启电脑,发现GPU⽆法正常使⽤,出现⽆法登录桌⾯系统。
(3)系统软件升级之后(⼀般是使⽤了 sudo apt-get update),重启,在登陆界⾯输⼊密码后,回车,闪现⼀次⿊屏和⼀些代码,然后⼜重新回到登陆界⾯。
(4)点了ubuntu系统⾃动提⽰的软件升级以后,重启电脑导致。
(5)ubuntu 正常使⽤过程中,有些使⽤/安装需要软件升级,⽆意操作,更新软件的同时更新了内核。
可能的原因分析:1、主⽬录下的.Xauthority⽂件拥有者变成了root,从⽽以⽤户登陆的时候⽆法都取.Xauthority⽂件。
从⽽造成⽤户登陆不进⼊系统桌⾯。
说明:Xauthority,是startx脚本记录⽂件。
Xserver启动时,读⽂件~/.Xauthority,读⼊对应其display的记录。
当⼀个需要显⽰的客户程序启动调⽤XOpenDisplay()也读这个⽂件,并把找到的magic code 发送给Xserver。
当Xserver验证这个magic code正确以后,就同意连接啦。
观察startx脚本也可以看到,每次startx运⾏,都在调⽤xinit以前使⽤了xauth的add 命令添加了⼀个新的记录到~/.Xauthority,⽤来这次运⾏X使⽤认证#系统的Xauthority⽂件出现了问题,当前⽤户⽆权限调⽤他,所以使⽤rm -rf .Xauthority删除他,也有说使⽤sudo chown usrname.Xauthority将权修改为当前⽤户的。
cudnn配置环境变量
在深度学习中,使用GPU加速计算能够大大提高训练速度。
而在使用深度学习框架时,常常需要进行cudnn配置环境变量的操作。
本文将从步骤角度进行详细介绍。
步骤一、下载cudnn
cudnn可以在官方网站上下载,但需要先注册才能下载。
下载时需要选择对应的CUDA版本和操作系统,还需注意下载的是cudnn的压缩包。
步骤二、解压并安装cudnn
解压下载的cudnn压缩包,会得到一个cuda目录。
将cuda目录拷贝到CUDA安装目录中。
建议将cuda目录放在CUDA的子目录下,例如C:\Program Files\NVIDIA GPU Computing
Toolkit\CUDA\v10.0\cuda。
步骤三、设置环境变量
接下来需要设置环境变量。
这里以Windows下的环境变量设置为例,其他系统类似。
在Windows操作系统中,需要进入“系统属性”->“高级系统设置”->“环境变量”,找到系统变量中的PATH,并点击“编辑”。
在“编辑环境变量”对话框中,点击“新建”按钮,添加CUDA的路径,例如C:\Program Files\NVIDIA GPU Computing
Toolkit\CUDA\v10.0\cuda\bin和C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\cuda\libnvvp。
最后,点击“确定”按钮,保存设置。
步骤四、验证cudnn是否配置成功
在配置完环境变量后,需要验证是否配置成功。
可以通过以下方式进行验证:
在命令行中输入nvcc -V,若出现相应的版本信息,则说明配置成功。
在Python中执行import tensorflow as tf,不会出现cudnn错误提示,说明配置成功。
在此,我们便完成了cudnn配置环境变量的全部步骤。
当然,这只是cudnn的基本配置,更多高级功能的使用还需要进一步学习。
希望本文能为大家提供一些帮助。