四参数Logistic模型研究进展及其评析
- 格式:pdf
- 大小:389.97 KB
- 文档页数:5

Logistic回归模型分析综述及应用研究的开题报告标题: Logistic回归模型分析综述及应用研究摘要:随着信息技术的发展,数据分析在社会生活中得到越来越广泛的应用。
Logistic回归模型作为一种广泛应用于统计分析中的分类模型,能够对事件的概率进行预测和分析。
本文将针对Logistic回归模型进行综述,包括其基本概念、原理、优点以及在分类问题中的应用。
同时,本文将以某电商平台的用户购买行为数据为例,探究Logistic回归模型在实际应用中的可行性和有效性。
通过对实验结果的分析和验证,进一步说明了Logistic回归模型在分类问题中的重要性和应用价值。
关键词: Logistic回归模型;事件的概率;分类问题;应用研究。
一、研究背景随着大数据时代的到来,数据分析在社会生活中得到越来越广泛的应用。
而分类问题是数据分析中的一个重要分支领域。
分类问题是指在给定训练样本的情况下,预测新样本所属类别的问题。
Logistic回归模型作为一种广泛应用于统计分析中的分类模型,能够对事件的概率进行预测和分析。
在实际应用中,Logistic回归模型能够对用户的购买行为、信用评估、疾病诊断等问题进行分析和预测,具有广泛的应用价值。
二、研究内容本文将以某电商平台的用户购买行为数据为例,探究Logistic回归模型在实际应用中的可行性和有效性。
具体内容包括以下几个方面:1. Logistic回归模型的基本概念:介绍Logistic回归模型的定义、分类原理和数学基础。
2. Logistic回归模型的优点:分析Logistic回归模型在分类问题中的优点,包括能够处理非线性关系、参数易于解释等。
3. Logistic回归模型在分类问题中的应用:以某电商平台的用户购买行为数据为例,对Logistic回归模型在分类问题中的应用进行探究。
4. 实验设计和分析:对实验设计和分析方法进行说明,分析实验结果和验证Logistic回归模型在分类问题中的可行性和有效性。

logistic模型调研报告本调研报告将对logistic模型进行深入分析和研究。
我们将了解该模型的定义、应用领域、优点和局限性,并且探讨一些相关的实际案例。
在整个报告中,我们将提供详细的信息和数据,以支持我们的结论。
一、引言logistic模型是一种用来建立两分类或多分类问题的概率模型。
它可以将输入特征映射到概率输出。
由于其简单且易于解释的特点,logistic模型在许多领域得到广泛应用,如医学、金融、市场营销等。
二、定义logistic回归模型是一种广义线性模型,其核心思想是通过对输入特征的线性组合应用一个非线性函数(称为logistic函数或sigmoid函数),来拟合观测数据的概率分布。
通常,logistic模型的输入特征通过最大似然估计方法来确定模型的参数。
三、应用领域1. 医学研究:logistic模型可以用于预测某种疾病的患病风险,并提供可靠的诊断结果。
2. 金融风险评估:logistic模型在信用评估和违约预测方面具有很高的应用价值,可以帮助金融机构降低风险。
3. 市场营销:logistic模型可以预测客户购买某种产品或服务的可能性,有助于制定有效的市场策略。
四、优点1. 简单易懂:logistic模型基于简单的线性组合和sigmoid函数,其结果易于解释和理解。
2. 可解释性强:logistic模型可以通过参数的大小和方向来解释输入特征对输出结果的影响。
3. 计算效率高:logistic模型的训练过程相对较快,即使在大规模数据集上也能够表现出良好的性能。
五、局限性1. 对异常值敏感:logistic模型对异常值比较敏感,当存在异常值时,模型的性能容易受到影响。
2. 必须线性可分:logistic模型要求输入特征能够线性可分,当特征之间存在复杂的非线性关系时,模型的拟合能力会受到限制。
3. 学习能力有限:logistic模型的学习能力有限,当数据具有高度复杂的规律时,模型可能无法完全捕捉到其中的信息。

logistic回归模型的统计诊断与实例分析Logistic回归模型是统计学和机器学习领域中主要的分类方法之一。
它可以用于分析两类和多类的定性数据,从而提取出有用的结论和决策。
在这篇文章中,我将介绍Logistic回归模型的统计诊断,并举例说明如何运用Logistic回归模型进行实例分析。
一、Logistic回归模型统计诊断Logistic回归模型作为一种二项分类模型,其输出结果可以用图形化地展示。
Logistic回归分析结果采用曲线图来表示:其中X 轴为样本属性变量,Y轴为回归系数。
当离散变量的值变化时,曲线图变化情况可以反映出输出结果关于输入变量的敏感性。
因此,通过观察曲线图,可以进行相应的模型验证和诊断。
此外,还可以根据Logistic回归的统计诊断,检验模型的拟合度和效果,如用R Square和AIC等度量指标,亦可以用传统的Chi-square计检验来诊断模型结果是否显著。
二、Logistic回归模型实例分析下面以一个关于是否给学生提供免费早餐的实例说明,如何使用Logistic回归模型分析:首先,针对学生的社会经济地位、学习成绩、性别、年龄等变量,采集建立实例,并将实例作为输入数据进行Logistic回归分析;其次,根据Logistic回归模型的统计诊断,使用R Square和AIC等统计指标来评估模型的拟合度和效果,并利用Chi-square统计检验检验模型系数的显著性;最后,根据分析结果,为学校制定有效的政策方案,进行有效的学生早餐服务。
总之,Logistic回归模型可以有效地进行分类分析,并能够根据输入变量提取出可以给出显著有用结论和决策的模型。
本文介绍了Logistic回归模型的统计诊断,并举例说明如何运用Logistic回归模型进行实例分析。

logistic增长模型的评价与推广1.引言1.1背景随着大数据时代的到来,预测和分析数据的需求变得越来越重要。
在复杂的决策过程中,准确预测事物的增长趋势对于制定有效的策略至关重要。
lo gi st ic增长模型作为一种经典的预测模型,被广泛应用于人口、市场、生态等领域。
1.2目的本文旨在评价lo gi st i c增长模型的优缺点,并探讨其推广应用的潜力,以期帮助读者更好地理解和运用l ogi s ti c增长模型。
2. lo gistic增长模型l o gi st ic增长模型是基于S形曲线的一种常见曲线模型,可用于描述某个变量随时间变化的增长趋势。
该模型基于逻辑函数,能够将线性增长转化为非线性增长,更准确地反映事物在不同阶段的增长速度。
3.评价log istic增长模型3.1优点-非线性拟合能力强,适用于描述复杂的增长模式;-可解释性强,能够给出增长速率和收敛值等直观的指标;-模型简单且计算效率高,易于使用和实现。
3.2缺点-对数据的要求较高,需要有较长的时间序列观测数据;-受初始值和收敛值的影响较大,易受数据的噪声干扰;-无法准确描述长期增长或衰减的特殊情况。
4.推广应用4.1人口增长预测l o gi st ic增长模型在人口学领域有着广泛的应用。
通过分析历史人口数据,可以利用lo g is ti c增长模型预测未来人口的变化趋势,为政府决策提供参考依据,如合理规划社会保障、教育资源分配等。
4.2市场份额预测对于市场研究和市场营销而言,l og is tic增长模型能够帮助企业预测产品在市场中的份额变化。
通过将历史市场份额数据拟合到l og is ti c 增长模型,可以预测未来市场份额的变化趋势,从而指导企业的市场战略制定和资源配置。
4.3生态系统模拟生态系统的变化与数量增长有密切关系,l o gi st ic增长模型可以用于模拟生态系统中不同物种的数量动态。
这对于生态学研究和保护生态平衡具有重要意义,可帮助科学家了解不同物种的生态演替规律,并为生态系统管理提供科学依据。




logistic模型的研究与应用文献综述摘要:一、引言1.物流行业的背景及挑战2.Logistic模型的基本概念与意义二、Logistic模型的发展历程1.早期研究2.近年来的发展三、Logistic模型的应用领域1.物流与供应链管理2.市场营销与销售预测3.生物医学与生态学4.社会经济与政策分析四、Logistic模型的优势与局限性1.优势a.适用于分类问题b.具有良好的预测能力c.易于理解和操作2.局限性a.数据要求较高b.对样本量有一定要求c.无法处理多元线性关系五、Logistic模型在物流行业的应用案例1.货物配送路径优化2.库存管理与需求预测3.运输调度与优化六、Logistic模型在其它领域的应用案例1.市场营销与销售预测2.生物医学与生态学3.社会经济与政策分析七、未来发展趋势与展望1.技术创新与智能化发展2.跨学科研究与应用3.我国在该领域的发展前景八、总结1.Logistic模型的重要性2.各领域应用的启示3.进一步研究的建议正文:一、引言随着全球经济的发展和贸易往来的日益频繁,物流行业面临着巨大的挑战和机遇。
如何在激烈的市场竞争中提高运输效率、降低运营成本、提升客户满意度,成为物流企业关注的焦点。
Logistic模型作为一种常用的预测与优化工具,在物流领域得到了广泛的应用。
本文通过对Logistic模型的研究与应用进行文献综述,旨在揭示其在物流行业及相关领域的优势与局限性,为今后我国在该领域的研究和应用提供参考。
二、Logistic模型的发展历程Logistic模型起源于20世纪50年代,早期研究主要关注于物流领域的运输问题。
近年来,随着大数据、互联网等技术的发展,Logistic模型在各个领域得到了广泛关注,应用范围不断扩大。
三、Logistic模型的应用领域1.物流与供应链管理:Logistic模型在物流领域主要应用于运输调度、路径优化、库存管理等方面。
通过对运输网络的优化,企业可以降低运输成本、提高运输效率;通过库存管理和需求预测,企业可以更好地应对市场波动,确保供应链的稳定运行。

logistic回归模型评价
logistic回归模型是一种常见的有监督学习方法,主要用于二分类问题或多分类问题。
由于它可以预测类别变量,所以在回归模型中被广泛使用。
它通过计算模型输出和实际输出值之间的误差,来评估模型的准确性和可靠性。
1.用性
Logistic回归模型的实用性取决于它的计算和拟合能力,尤其是对于复杂的数据集。
使用可对数据集进行基本拟合以获得更好的性能,它可以消除重复的数据、噪声、偏离等问题,同时可以提供良好的结果。
它有一套自动诊断工具供用户在使用过程中调节参数以优化模型性能。
2.率
Logistic回归模型的效率很高,可以在多次迭代中逐步拟合出最佳的模型参数。
它可以快速地进行多次循环,这可以提高模型的精度。
此外,Logistic回归模型的拟合过程只需要少量的数据,从而节省了大量的存储空间。
3.靠性
Logistic回归模型的可靠性取决于其计算精度,通过拟合大量数据,可以准确地计算出预测结果。
此外,它采用了基于概率的模型,因此可以根据不同数据集得出不同结果。
最后,它采用最小二乘法评估模型效果,因此可以更快地收敛,最大程度地减少模型误差。
综上所述,Logistic回归模型具有良好的实用性、高效的计算
能力和可靠的结果,是一种可以用于多分类和二分类问题的强大算法。
但是,对于高维数据,收敛速度和准确度都会受到影响,因此在实际应用中,应该谨慎使用Logistic回归模型。
科研数据处理方法——四参数拟合
数据处理,是科研工作者必须要掌握的技能。
然而,由于数据形式的多种多样,伴随着方法也是层出不穷。
对于免疫检测的数据处理,常常会用到四参数拟合,下面介绍其具体的数据处理方法。
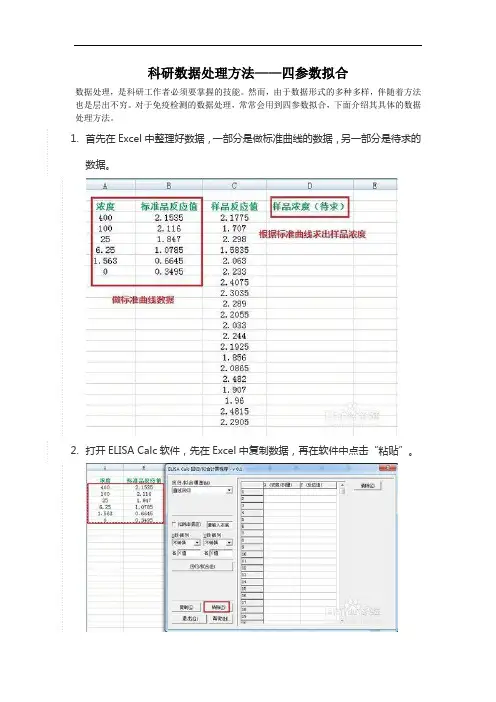
1.首先在Excel中整理好数据,一部分是做标准曲线的数据,另一部分是待求的
数据。
2.打开ELISA Calc软件,先在Excel中复制数据,再在软件中点击“粘贴”。
3.选择回归/拟合模型,选中“四参数”,点击“回归/拟合按钮”。
4.弹出的窗口中显示了曲线,可以截图下来。
别忘了X和Y分别表示的什么。
这是标准品提供一个方程。
样品有反应值,要计算X值,点击“由Y计算X”。
5.复制Excel中的样品的反应值,点击软件的“粘贴”按钮,即可自动计算出对
应的X值,也即是样品浓度。
6.方程拟合的好坏,还可以查看方程来检验,主要看r^2的值,越接近1,拟
合效果越好。

四参数Logistic模型研究进展及其评析在测验中存在着低能力被试答对高难度试题的猜测现象,和高能力被试答错容易试题的睡眠现象,此时可以使用四参数模型来分析测验数据。
Barton和Lord 认为应用四参数模型的实践意义不大,但结论的依据不充分。
近年来研究者从测验项目拟合,改善被试能力估计等方面进行了分析,认为在四参数模型下可以有效纠正被试能力高估或低估现象,认为单、两、三参数模型是四参数模型的特例,建议使用四参数模型。
标签:IRT;四参数模型;猜测现象;睡眠现象1 四参数Logistic模型的测量涵义及其研究进展1.1 测验中的猜测现象和睡眠现象以及四参数Logistic模型在测验时,低能力被试凭猜测或者其它原因答对了高难度试题的现象,叫做猜测现象(guessing phenomenon)。
此外在测验中还存在高能力被试答错容易试题的现象,Wright将其称为睡眠现象(sleeping phenomenon)。
有研究者在测验分析时,发现了测验中存在着睡眠现象。
Reise和Waller在分析人格测验MMPI-2时,发现了一些试题存在着睡眠现象的作答情况。
简小珠,戴海崎,彭春妹(2007)在分析测验时也发现了一些试题同时存在着猜测现象和睡眠现象,或单独存在猜测现象和睡眠现象。
或许有研究者会提出疑问:试题存在睡眠现象,是不是试题质量存在问题?已有研究已经分析了测验中存在睡眠现象的试题,发现这些试题的测量性能都良好,认为睡眠现象与试题是否存在质量问题之间没有必然的联系。
另外从题型的角度来看,如果测验中一些填空题,试题难度较大,高能力被试未必能全部答对,那么存在试题作答概率的上渐近线(即睡眠现象);而对于低能力被试来说则很难答对,猜测度就有可能为0,这时可以用三参数模型γ型(含a,b,γ参数)来反映。
如果将此填空题改为选择题的形式,低能力被试群体就可能存在猜测现象,那么就同时存在睡眠现象和猜测现象,这时可以使用四参数模型来反映。
Logistic模型的研究Logistic模型是一种常用的统计分析工具,广泛应用于各个领域,如生物学、医学、经济学等。
本文将探讨Logistic模型的基本概念、应用方法以及一些在实际研究中的注意事项。
一、Logistic模型的基本概念Logistic回归是一种广义线性模型(GLM),用于建立因变量与一个或多个自变量之间的关系。
与线性回归模型不同,Logistic模型适用于因变量为二分类或多分类的情况。
Logistic模型的因变量通常为二分类问题,其中0和1表示两种可能的结果。
在Logistic回归中,对数几率(logit)函数被用来建立因变量和自变量之间的关系。
该函数将因变量为1的概率转化为一个连续的变量,其取值范围为负无穷到正无穷。
当因变量为二分类问题时,logit函数为:logit(p) = ln(p / (1-p))其中,p表示因变量为1的概率。
通过对数几率函数,可以得到Logistic模型的形式化表达式:p = 1 / (1 + exp(-(β0 + β1*x1 + β2*x2 + ... +βn*xn)))其中,p表示因变量为1的概率,β0、β1、β2...βn 表示模型的系数,x1、x2...xn表示自变量。
二、Logistic模型的应用方法Logistic模型通常用于预测和解释因变量为二分类问题的情况。
在应用Logistic模型时,需要注意以下几点:1. 数据准备:收集样本数据时,需要保证样本的随机性和代表性。
同时,应避免自变量之间存在多重共线性,以免引起模型的不稳定性。
2. 变量选择:根据研究目的和理论背景,选择与因变量相关的自变量。
此外,还可以通过变量筛选方法(如逐步回归法或最大似然比检验)来确定最佳的自变量组合。
3. 模型拟合:使用最大似然估计法对Logistic模型进行参数估计。
通过最大化似然函数,求解模型的系数,得到最佳拟合的Logistic模型。
4. 模型评估:通过各种指标(如对数似然比统计量、准确率、召回率、F1值等)对Logistic模型进行评估,以判断模型的拟合效果和预测能力。
Origin四参数逻辑斯谛模型1.简介在统计学和机器学习领域,逻辑斯谛回归模型是一种用于对分类问题进行建模的常见方法。
它利用自变量的线性组合来预测事件发生的概率。
然而,逻辑斯谛回归模型仅适用于二分类问题。
为了克服这一限制,出现了O ri gi n四参数逻辑斯谛模型,它能够更好地处理多分类问题。
2.四参数逻辑斯谛函数在O ri gi n四参数逻辑斯谛模型中,使用了四个参数来描述逻辑斯谛函数的形状。
这四个参数分别是:-α:S型曲线的上限,即当自变量趋近正无穷时的函数值。
-β:S型曲线的下限,即当自变量趋近负无穷时的函数值。
-γ:控制函数的斜率,影响曲线在中心点处的陡峭程度。
-δ:控制曲线在中心点处的偏移量,影响曲线在x轴上的位置。
四参数逻辑斯谛函数的数学表达式如下:$$f(x)=\al ph a-\f rac{(\al ph a-\b et a)}{1+\e xp(-\g am ma(x-\d el ta))}$$其中,$x$为自变量,$f(x)$为因变量的预测概率。
3.建模过程要建立O ri gi n四参数逻辑斯谛模型,以下是主要的步骤:步骤1:数据准备收集与问题相关的数据集,并进行预处理。
确保数据集中包含一个目标变量和多个自变量。
步骤2:模型拟合选择一个合适的统计软件,例如O ri gi n,将数据导入软件中。
然后,使用四参数逻辑斯谛模型来拟合数据。
步骤3:参数估计模型拟合后,通过最大似然估计等方法来估计模型的参数。
这些参数将决定逻辑斯谛函数的形状。
步骤4:模型评估使用一些评估指标,如准确率、精确度和召回率等,来评估模型的性能。
根据评估结果,可以进行模型调整或改进。
4.应用领域O r ig in四参数逻辑斯谛模型在许多领域中得到了广泛应用,包括但不限于:-医学疾病诊断:根据患者的临床指标,预测患有不同疾病的概率。
-市场预测:利用消费者的特征信息,预测其对不同产品的偏好程度。
-财务风险评估:根据企业的财务数据,预测其破产的概率。
四参数Logistic模型和传统模型对被试作答拟合能力的比较研究刘玥;刘红云【摘要】针对测验中高能力被试答错容易试题的睡眠现象,可使用四参数Logistic 模型分析数据.研究选取了来自心理测验和成就测验的实际数据,分别采用传统模型和四参数Logistic模型进行拟合,对不同模型的拟合指标及参数估计结果进行比较.结果表明,四参数Logistic模型能够提高拟合程度,增强估计结果的准确性,有效纠正高能力被试能力被低估的现象.建议在必要时使用四参数Logistic模型进行数据分析.%High- ability test - takers may on occasion answer an easy question incorrectly,which is called sleeping phenomenon (Wright,1977). In these situations,four parameter logistic model(4PM)may be uniquely suited for characterizing the data. The 4PM was proposed by Barton andLord(1981),which added the d parameter to allow upper asymptotes to be less than 1. 00. The more gener-al formulation of the 4PM(Waller & Reise,2010)suggestedd as an item-specific upper asymptote. Besides,a three parameter logistic model for reversed data(3PMR)was discussed,which was suited for the situations with no guessing phenomenon but sleeping phenome-non. In the previous researches,the4PM provided good fit for some psychological tests,such as MMPI and so on. However,for achieve-ment tests,Barton and Lord in their earlier work found that the 4PM failed to improve the likelihood or to significantly change any ability estimates for the datasets collected by ETS. Therefore,is it really inappropriate to use the 4PM in achievementtests?Moreover,most previous researches focused on the differences of parameter estimations based on simulated data. However,how often the sleeping phe-nomenon happen in real situations is still worth studying. In our research,we fitted seven models to the Taylor Manifest Anxiety Scale ( TMA)and the large-scale Maths test. Meanwhile,the dataset of Maths tests was used to construct two different distributions:approxi-mately normal distribution(skewness is 0. 097)and negatively skewed distribution(skewness is-0. 199). The models compared were Rasch model,two parameter logistic model(2PM),three parameter logistic model(3PM),3PM with reversing scores on each item(3PM_R),4PM,4PM with equal guessing parameters(4PM_c)and 4PM with equal d parameters(4PM_d). The R package sirt was used to estimate all the models in our study. In order to investigate the differences of these models,we computed:(1)the model fit indexAIC, BIC;(2)the correlations of the item parameter estimations of the best fitted logistic model with d parameter and the second best model without d parameter,for all the items and after the easiest 5,10,and 10 items were deleted;(3)the correlations of the ability parameter estimations of the two models discussed in(2),for all and the top 1000,500,300,200,100 respondents. The results indicated that(1) the Rasch model showed the worst fit for all the datasets. For TMA data,the 3PMR showed the best fit,for the Maths tests,the 4PM showed the best fit;(2)the difficulty parameters were quite similar inthe two compared models,however,there was lager difference be-tween the discrimination parameters,the negatively skewed StandardMaths test data showed similar results;when the easiest items were deleted,the correlation of the discrimination parameters became larger,especially for the negatively skewed Standard Maths test;(3)the ability parameters of two compared models correlated highly across all groups of respondents,however,the correlations for the top 1000,500,300,200,100 groups were relatively small,especially for the top 100 respondents. In conclusion,the 4PM is necessary in both psy-chological tests and achievement tests. For practitioners who should make a decision about whether to choose the 4PM,the type of the tests,the purpose of the tests,and the complexity of the computation should be considered at the same time.【期刊名称】《心理学探新》【年(卷),期】2018(038)003【总页数】8页(P228-235)【关键词】项目反应理论;睡眠现象;四参数Logistic模型【作者】刘玥;刘红云【作者单位】北京师范大学心理学部,北京100875;北京师范大学心理学部,北京100875【正文语种】中文【中图分类】B841.21 前言1.1 测验中的睡眠现象在成就测验中,存在着一种高能力被试答错容易题目的“睡眠现象(sleeping phenomenon)”(Wright,1977)。
四参数逻辑回归模型1. 引言逻辑回归是一种广泛应用于分类问题的机器学习算法,通过将线性回归模型的输出映射到[0,1]区间上,来进行二分类任务的预测。
然而,对于某些问题,简单的逻辑回归模型可能无法很好地拟合数据,因此出现了四参数逻辑回归模型。
四参数逻辑回归模型在传统的逻辑回归模型的基础上引入了额外的参数,可以更灵活地适应数据的分布。
2. 传统逻辑回归模型回顾在介绍四参数逻辑回归模型之前,我们先回顾一下传统的逻辑回归模型。
逻辑回归模型假设输出变量y服从伯努利分布,即y只能取0或1两个值。
模型的输出通过sigmoid函数进行映射,公式如下:p(y=1|x)=11+e−wx其中,w是模型的参数,x是输入特征。
模型的目标是最大化似然函数,通过最大似然估计的方法求解参数w。
3. 四参数逻辑回归模型介绍传统的逻辑回归模型假设了一个对称的S形曲线,但在某些情况下,数据的分布可能不服从这种对称性。
四参数逻辑回归模型通过引入额外的参数,可以更灵活地拟合数据的分布。
四参数逻辑回归模型的公式如下:p(y=1|x)=11+e−(w1x+w2x2+w3x3+w4x4)可以看到,四参数逻辑回归模型中引入了三次项和四次项,使得模型的拟合能力更强。
4. 四参数逻辑回归模型的优点相比传统的逻辑回归模型,四参数逻辑回归模型具有以下优点: 1. 更强的拟合能力:四参数逻辑回归模型引入了额外的参数,可以更灵活地拟合数据的分布,适应更复杂的情况。
2. 更好的泛化能力:四参数逻辑回归模型在拟合训练数据的同时,也考虑了模型的泛化能力,可以在未见过的数据上取得较好的预测效果。
3. 更全面的特征表达:四参数逻辑回归模型可以通过引入高次项,更全面地表达输入特征的信息,提高了模型的表达能力。
5. 四参数逻辑回归模型的应用四参数逻辑回归模型在实际应用中具有广泛的应用场景,下面列举了几个典型的应用案例:5.1. 股票市场预测股票市场涨跌预测是一个重要的金融问题,传统的逻辑回归模型可能无法很好地捕捉股票市场的非线性特征。
四参数logistic约束模型
首先,让我们来看增长率参数。
这个参数代表了增长的速率,也就是说,它决定了增长曲线的陡峭程度。
增长率参数的值越大,增长曲线就会越陡峭,增长速度越快;反之,增长率参数越小,增长曲线就会越平缓,增长速度越慢。
其次,上限参数是指增长过程的上限值,也就是增长过程最终会趋于的数值。
在实际应用中,这个参数可以用来描述一个系统或者过程的最大容量或者最大承载能力。
当增长过程接近上限值时,增长速度会逐渐减缓,最终趋于稳定状态。
然后,下限参数则是指增长过程的下限值,也就是增长过程的起始值。
这个参数可以用来描述一个系统或者过程的初始状态,或者是增长过程的最小值。
在实际应用中,下限参数通常用来表示某个过程的起始状态或者最小容量。
最后,增长偏移参数用于描述增长曲线的偏移情况。
它可以用来调整增长曲线的位置,使其与实际数据更好地拟合。
增长偏移参数的调节可以帮助我们更准确地预测增长过程的发展趋势。
总的来说,四参数logistic约束模型提供了一种灵活而全面的方法来描述各种增长过程,通过调节这四个参数的值,我们可以更好地理解和预测不同系统和过程的增长趋势。
这种模型在许多领域都有着广泛的应用,对于研究和预测各种增长现象都具有重要的意义。
四参数Logistic模型研究进展及其评析
简小珠;张敏强;彭春妹
【期刊名称】《心理学探新》
【年(卷),期】2010(030)003
【摘要】在测验中存在着低能力被试答对高难度试题的猜测现象,和高能力被试答错容易试题的睡眠现象,此时可以使用四参数模型来分析测验数据.Barton和Lord 认为应用四参数模型的实践意义不大,但结论的依据不充分.近年来研究者从测验项目拟合,改善被试能力估计等方面进行了分析,认为在四参数模型下可以有效纠正被试能力高估或低估现象,认为单、两、三参数模型是四参数模型的特例,建议使用四参数模型.
【总页数】5页(P69-73)
【作者】简小珠;张敏强;彭春妹
【作者单位】华南师范大学,心理应用研究中心,广州,510631;井冈山大学,教育学院,吉安,343009;华南师范大学,心理应用研究中心,广州,510631;井冈山大学,教育学院,吉安,343009
【正文语种】中文
【中图分类】B841.2
【相关文献】
1.四参数Logistic模型和传统模型对被试作答拟合能力的比较研究 [J], 刘玥;刘红云
2.Rstan包在四参数Logistic模型参数估计中的应用 [J], 付志慧; 武健; 马明玥
3.基于Logistic模型的火后树木死亡率研究进展 [J], 王晓红;魏娜;王千雪;于宏影;黄艳
4.基于Logistic模型的火后树木死亡率研究进展 [J], 王晓红;魏娜;王千雪;于宏影;黄艳
5.四参数Logistic模型潜在特质参数的Warm加权极大似然估计 [J], 孟祥斌;陶剑;陈莎莉
因版权原因,仅展示原文概要,查看原文内容请购买。
万方数据
万方数据
第3期简小珠等四参数Logistic模型研究进展及其评析71
Barton和Lord没有进行卡方检验。
第三,在分析数学模型是否适合测验数据时,测验极大似然值仅是其中一个参考指标,而且目前依据的参考指标主要是项目拟合指数、被试残差等。
第四,Barton和krd仅由4批实测数据得出的结论,是否具有广泛的代表性,这也值得质疑。
图1中等能力被试答错第36题后的能力步长曲线
图2中等能力被试答对第36题后的能力步长曲线
注:图1、图2的数据来源于简小珠硕士论文(详见参考文献4)。
由该论文中表9的数据绘制成图1,由表8.的数据绘制成图2。
其中,图1中增加-r参数为0.995、0.999、0.9999时的能力步长曲线;图2中增加c参数为0.ol、0.005、0.001、0.0001时的能力步长曲线。
论据二,被试能力估计值在被试整体上没有显著的改变。
Barton和Lord使用散点图表示三、四参数模型下的能力估计值,发现被试群体在测验上的能力估计没有显著改变。
而最近研究认为_y参数在0.99或0.98时能够有效纠正高能力被试答错容易试题时的能力低估现象-3’15J。
这个观点是不是矛盾?文章认为,由于Barton和LDrd在散点图形上是从被试群体的被试估计值的整体变化情况来分析的;而简小珠等的研究[31是从单个能力被试角度来分析能力估计值相对变化情况,Rulison和Loken也是仅从单个高能力被试的角度。
纠(多次模拟的能力估计值平均值,使用Bias和RMSE指标),分析高能力被试答错容易试题后能力估计值的变化情况。
为什么分析全部被试与单独分析高能力被试的能力估计值,会有不同的结果?文章根据已有的研究L43,从C、^y参数对被试能力估计值的影响的角度来分析。
由简小珠(2006)的论文中表格9可知【4],当被试答对试题时,该试题的y参数大小对被试能力估计值影响很小,能力估计值的变化都在0.001以下。
由图1可知:在被试答错试题时,7参数的大小对被试能力估计的影响,因所答错试题的难度大小不同而不同:1)先分析在横坐标b=一1.2的右边部分。
在b=一1.2位置,y=0.99的曲线与Y=1的曲线相差很小,相差只有0.015,即被试答错试题而且试题难度b一0>一1.2时,y参数由1减小至0.99时对被试能力估计值的影响很小。
2)再分析在横坐标b=1.2的左边部分。
随着被试答错容易试题的难度减小,y=0.99的曲线与7=1的曲线相差的距离越来越大,当b=一3.2时,能力步长相差为0.13左右,即被试答错容易试题而且试题难度b—p≤一1.2时,7参数为0.99时能有效纠正此时的能力高估现象。
而且由图1可知,y参数在0.95至0.995这个区间,都能够有效的纠正被试能力估计值高估现象。
综上所述,y参数对改善被试能力估计值的情况具有较强的针对性,仅对被试答错容易试题而且试题难度b—p≤一1.2时出现的能力低估现象具有较好的纠正作用;而对于被试答对试题的作答情况,或者被试答错试题而且试题难度b一护>一1.2时的作答情况,7参数对被试能力估计值的影响很小。
同理,由图2可得c参数对改善被试能力估计值的情况也具有较强的针对性,仅对被试答对高难度试题而且试题难度b—p≥一1.2时出现的能力高估现象具有较好的纠正作用;而对于被试答错试题的作答情况,或者被试答对试题而且试题难度b一日<一1.2时的作答情况,C参数对被戚能力估计值的影响很小。
假设某一被试即使答错了6道试题而且试题难度b一口=一1.2时,那么该被试能力步长后退的幅度,可以根据公式来计算一。
:作答相同的k题后的能力步长z忌X作答1题后的能力步长(k≤6)。
被试能力步长将后退的步长幅度约为0.09左右,可见被试答错6道试题而且试题难度b一日一一1.2时,对
被试能力估计值的影响相对很小。
而且。
只有被试万方数据
万方数据
万方数据。