VSAM文件笔记
- 格式:pdf
- 大小:121.87 KB
- 文档页数:6
CICS实验4(VSAM文件建立)
1.实验目的:通过本实验学习VSAM 文件的建立和在CICS 中如何定义与操
作VSAM 文件。
2.实验内容:掌握JCL创建VSAM文件以及再主机环境下的VSAM编辑工具
ditto(M.7)的使用,同时掌握在CICS 中如何定义与操作VSAM
文件。
3.实验步骤:
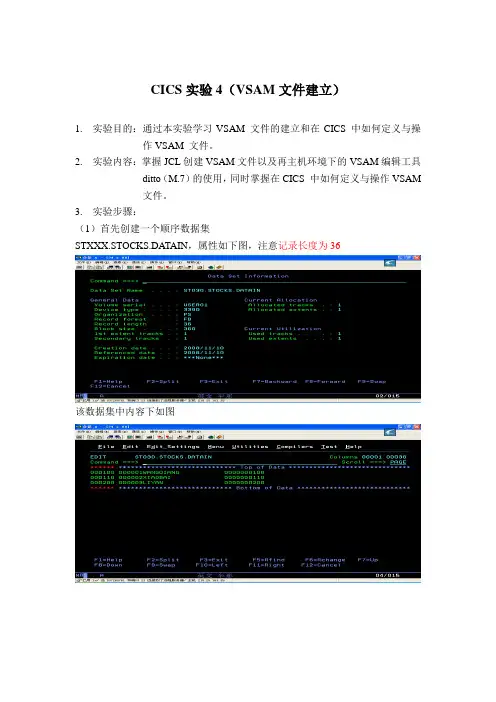
(1)首先创建一个顺序数据集
STXXX.STOCKS.DATAIN,属性如下图,注意记录长度为36
该数据集中内容下如图
(2)编写一个JCL作业,用于COPY顺序数据集STXXX.STOCKS.DATAIN的记录进入要创建的VSAM文件STXXX.STOCKS.CLUSTER中,程序如下图
SUB提交作业创建VSAM文件STXXX.STOCKS.CLUSTER
(3)在主机环境下的VSAM编辑工具ditto(M.7)的查看该文件
(4)启动CICS,在CICS中定义VSAM文件
安装VSAM文件
(5)通过CECI READ FILE(STOCKS)RIDFLD(000001)命令读取VSAM 文件中的记录
注:CICS中文件打开命令CEMT S FILE(STOCKS)OPEN
CICS中文件关闭命令CEMT S FILE(STOCKS)CLOSE。

清华考研辅导班-2020清华大学962数学-数据方向基础综合考研经验真题参考书目清华大学962数学-数据方向基础综合考试科目,2020年初试时间安排为12月22日下午14:00-17:00业务课二进行笔试,清华大学自主命题,考试时间3小时。
一、适用院系及专业清华大学伯克利深圳学院0812J3数据科学与信息技术清华大学伯克利深圳学院0830J2环境科学与新能源技术二、考研参考书目清华大学962数学-数据方向基础综合有官方指定的考研参考书目,盛世清北整理如下:《数据结构》(C语言版) 清华大学出版社严蔚敏、吴伟民盛世清北建议:(1)参考书的阅读方法目录法:先通读各本参考书的目录,对于知识体系有着初步了解,了解书的内在逻辑结构,然后再去深入研读书的内容。
体系法:为自己所学的知识建立起框架,否则知识内容浩繁,容易遗忘,最好能够闭上眼睛的时候,眼前出现完整的知识体系。
问题法:将自己所学的知识总结成问题写出来,每章的主标题和副标题都是很好的出题素材。
尽可能把所有的知识要点都能够整理成问题。
(2)学习笔记的整理方法A:通过目录法、体系法的学习形成框架后,在仔细看书的同时应开始做笔记,笔记在刚开始的时候可能会影响看书的速度,但是随着时间的发展,会发现笔记对于整理思路和理解课本的内容都很有好处。
B:做笔记的方法不是简单地把书上的内容抄到笔记本上,而是把书上的关键点、核心部分记到笔记上,关上书本,要做到仅看笔记就能将书上的内容复述下来,最后能够通过对笔记的记忆就能够再现书本。
三、重难点知识梳理2020年清华大学深圳国际研究生院962 《数学-数据方向基础综合》考研考试大纲:考试内容:1.1什么是数据结构1.2基本概念和术语1.3抽象数据类型的表示与实现1.4算法和算法分析1.4.1算法1.4.2算法设计的要求1.4.3算法效率的度量1.4.4算法的存储空间需求2 线性表2.1线性表的类型定义2.2线性表的顺序表示和实现2.3线性表的链式表示和实现2.3.1线性链表2.3.2循环链表2.3.3双向链表2.4一元多项式的表示及相加3栈和队列3.1栈3.1.1抽象数据类型栈的定义3.1.2栈的表示和实现3.2栈的应用举例3.2.1数制转换3.2.2括号匹配的检验3.2.3行编辑程序3.2.4迷宫求解3.2.5表达式求值3.3栈与递归的实现3.4队列3.4.1抽象数据类型队列的定义3.4.2链队列——队列的链式表示和实现3.4.3循环队列——队列的顺序表示和实现3.5离散事件模拟4 串4.1串类型的定义4.2串的表示和实现4.2.1定长顺序存储表示4.2.2堆分配存储表示4.2.3串的块链存储表示4.3串的模式匹配算法4.3.1求子串位置的定位函数Index(S,T,pos)4.3.2模式匹配的一种改进算法4.4串操作应用举例4.4.1文本编辑4.4.2建立词索引表5 数组和广义表5.1数组的定义5.2数组的顺序表示和实现5.3矩阵的压缩存储5.3.1特殊矩阵5.3.2稀疏矩阵5.4广义表的定义5.5广义表的存储结构5.6m元多项式的表示5.7广义表的递归算法5.7.1求广义表的深度5.7.2复制广义表5.7.3建立广义表的存储结构6 树和二叉树6.1树的定义和基本术语6.2二叉树6.2.1二叉树的定义6.2.2二叉树的性质6.2.3二叉树的存储结构6.3遍历二叉树和线索二叉树6.3.1遍历二叉树6.3.2线索二叉树6.4树和森林6.4.1树的存储结构6.4.2森林与二叉树的转换6.4.3树和森林的遍历6.5树与等价问题6.6赫夫曼树及其应用6.6.1最优二叉树(赫夫曼树)6.6.2赫夫曼编码6.7回溯法与树的遍历6.8树的计数7 图7.1图的定义和术语7.2图的存储结构7.2.1数组表示法7.2.2邻接表7.2.3十字链表7.2.4邻接多重表7.3图的遍历7.3.1深度优先搜索7.3.2广度优先搜索7.4图的连通性问题7.4.1无向图的连通分量和生成树7.4.2有向图的强连通分量7.4.3最小生成树7.4.4关节点和重连通分量7.5有向无环图及其应用7.5.1拓扑排序7.5.2关键路径7.6最短路径7.6.1从某个源点到其余各顶点的最短路径7.6.2每一对顶点之间的最短路径8 动态存储管理8.1概述8.2可利用空间表及分配方法8.3边界标识法8.3.1可利用空间表的结构8.3.2分配算法8.3.3回收算法8.4伙伴系统8.4.1可利用空间表的结构8.4.2分配算法8.4.3回收算法8.5无用单元收集8.6存储紧缩9 查找9.1静态查找表9.1.1顺序表的查找9.1.2有序表的查找9.1.3静态树表的查找9.1.4索引顺序表的查找9.2动态查找表9.2.1二叉排序树和平衡二叉树9.2.2B树和B+树9.2.3键树9.3哈希表9.3.1什么是哈希表9.3.2哈希函数的构造方法9.3.3处理冲突的方法9.3.4哈希表的查找及其分析10 内部排序10.1概述10.2插入排序10.2.1直接插入排序10.2.2其他插入排序10.2.3希尔排序10.3快速排序10.4选择排序10.4.1简单选择排序10.4.2树形选择排序10.4.3堆排序10.5归并排序10.6基数排序10.6.1多关键字的排序10.6.2链式基数排序10.7各种内部排序方法的比较讨论11 外部排序11.1外存信息的存取11.2外部排序的方法11.3多路平衡归并的实现11.4置换一选择排序11.5最佳归并树12 文件12.1有关文件的基本概念12.2顺序文件12.3索引文件12.4ISAM文件和VSAM文件12.4.1ISAM文件12.4.2VSAM文件12.5直接存取文件(散列文件)12.6多关键字文件12.6.1多重表文件12.6.2倒排文件四、考研真题2009年,教育部出台了严格管理院校自主命题专业考试科目相关资料、限制专业课辅导的规定,很多学校从那时起不再公布和出售真题,并不再提供专业课参考书目。



1,什么是VSAM?VSAM(Virtual Storage Access Method)――虚拟存储访问方法Virtual Storage Access Method (VSAM) is the first access method specificallydesigned to operate in a virtual storage environment.与其它的访问方法相比,VSAM和操作系统MVS,MVS/XA,MVS/ESA更兼容,提高了应用程序的效率。
2,VSAM 的功能:处理程序和操作系统的接口。
3,VSAM 术语RBA——The Relative Byte Address文件中的记录由其位移以字节编址,并且编址是从文件的起始位置开始。
这个位移就是记录的相对字节地址RBA。
CI——Control IntervalCI是VSAM方法在虚存(Virtual Storage)和外存(DASD)之间传送数据信息的基本单位。
每个CI由一个以上的定长或变长的逻辑记录、自由空间、及描述本CI数据存放和空间使用情况等控制信息所组成。
CA——Control Area在VSAM文件中,CI组成更大的结构-----控制区域CA(Control Area),文件中的每个CA 都有同样数量与大小的CI,若干个CI构成CA。
CI的数量由VSAM所决定。
Cluster在VSAM方法中,族是由一组有关的部分而组成的结构。
4.VSAM数据类型Linear Data Set (LDS)Entry-Sequenced Data Set (ESDS)Relative Record Data Set (RRDS)Key-Sequenced Data Set (KSDS)Variable Relative Record Data Set (VRRDS)5.VSAM操作Utility——IDCAMS– Define 创建一个VSAM文件– Listcat 列出VSAM文件的信息– Repro 从SDS文件中导入数据到KSDS文件中– Print 打印KSDS文件中的一部份record– Delete 删除一个VSAM文件6.创建VSAM创建VSAM的JCL语句:以帐号ST999为例://ST999A JOB CLASS=A,NOTIFY=&SYSUID//STEP1 EXEC PGM=IDCAMS (注:PGM必须是IDCAMS)//SYSPRINT DD SYSOUT=*//SYSIN DD *DEFINE CLUSTER ( NAME (ST999.VSAMNAME) -INDEXED -RECORDS( 3000 100 ) -RECSZ ( 100 100 ) -KEYS ( 3 0 ) -VOLUME ( USER03 ))//建好一个VSAM后,不能在3.4 中编辑,会显示VSAM processing unavail, 应该在M.7中查看。

1 简介 (2)2 VSAM 数据集类型和结构 (3)2.1 VSAM 术语 (3)一.控制段(Control Interval) (3)例题一:控制区间1[Control Interval 1] (3)例题二:控制区间2[Control Interval 2] (4)例题三:控制区间3[Control Interval 3] (4)二.控制区(Control Area) (5)优化控制区域的大小(Optimizing Control Area Size) (6)一个大的控制区域的优点(Advantages of a Large Control Area Size) (6)一个大的控制区域的缺点(Disadvantages of a Large Control Area Size) (7)控制区域(CA)的大小牵连到几方面 (7)三.相对字节位置(Relative Byte Address) (7)四.Spanned Record (7)五.数据集(Cluster) (9)六.访问控制块(Access Control Block) (10)七.记录 (10)2.2 VSAM 数据集类型 (10)一.ESDS 数据集 (12)二.KSDS 数据集 (13)三.RRDS 数据集 (26)四.VRRDS 数据集 (27)五.LDS数据集 (27)3 VSAM 的编目 (28)一.主编目(Master Catalog) (29)二.用户编目(User Catalog) (30)4 IDCAMS (30)4.1 AMS 命令格式 (30)4.2 AMS 功能介绍 (31)4.3 AMS 命令的应用 (31)一. DEFINE MASTERCATALOG (31)二. DEFINE USERCATALOG (32)三.DEFINE CLUSTER (32)四.REPRO (34)五.LISTCAT (35)4.4 AMS 实例 (35)1 简介VSAM 的全称为Virtual Storage Access Method,它是一种访问方法,用来组织数据记录并且利用编目实现数据集的维护。

cobol学习笔记(1) COBOL入門 COBOLとは?2010/06/29 16:35COBOL面向商业的通用语言 (Common business Oriented Language) コボル∙ 1960.04 CODASYL-60∙ 1968. ANSI COBOL(COBOL68)第1次規格∙ COBOL74 第2次規格∙ COBOL85 第3次規格∙ COBOL2002 第4次規格COBOL是Common Business-Oriented Language(公用面向商业的语言)的缩写,主要供数据处理、数据收集及分析之用。
COBOL自60年代初开始广泛应用于计算机应用领域(商业和其他领域)。
事实上,除了商业之外,各种管理工作都广泛使用COBOL,如各种统计工作,财会工作,企业计划编制,作业制度,情报检索,人事管理等。
COBOL针对商业世界的使用,是真正商用应用程序开发的首选语言。
1.适于数据处理领域。
2.采用英语语法的高级语言,可读性、可维护性、可移植性较强。
3.通用性强,标准化程度较高。
4.结构严谨,层次分明。
5.缺点是比较繁琐。
cobol的书写格式(每行)1、前6列为序号区(一般不编辑)2、第7列为标示列,仅可以写如下几个标示符。
a. “*” 注释符(注释当前行的代码)b “/“ 注释符(注释当前行的代码,程序编译时,强制程序清单另起一页,不建议使用)c “-“ 字符串连接符d “D” DEBUG行标示符(程序为DEBUG模式时,标有该标示符的语句行代码执行,否则和注释行效果一样)3、第8列---11列为A区,包括以下内容。
a 部、节名。
b 层号014、第12列---72列为B区,过程部的程序必须写在B区中。
5、第72以后部分不能编辑。
cobol学习笔记(2)COBOL的程序结构 IDENTIFICATION DIVISION 标识部見出し部2010/06/29 20:44COBOL程序由4部(DIVISION)组成:IDENTIFICATION DIVISION.(标识部)、ENVIRONMENT DIVISION.(环境部)、DATA DIVISION.(数据部)、PROCEDURE DIVISION.(过程部),而每个部又由若干节 (SECTION)组成。



About the T utorialVSAM stands for Virtual Storage Access Method. VSAM is a file storage access method used in MVS, ZOS and OS/390 operating systems. It was introduced by IBM in 1970's. It is a high performance access method used to organize data in form of files in Mainframes. VSAM is used by COBOL and CICS in Mainframes to store and retrieve data. VSAM makes it easier for application programs to execute an input-output operation.AudienceThis tutorial is designed for software programmers with a need to understand the VSAM concepts starting from scratch. This tutorial will give you enough understanding on VSAM from where you can take yourself to higher level of expertise.PrerequisitesBefore proceeding with this tutorial, you should have a basic understanding of JCL and COBOL. A basic understanding of any of the file handling method will help you in understanding the VSAM concepts and move fast on the learning track. Disclaimer & CopyrightCopyright 2018 by Tutorials Point (I) Pvt. Ltd.All the content and graphics published in this e-book are the property of Tutorials Point (I) Pvt. Ltd. The user of this e-book is prohibited to reuse, retain, copy, distribute or republish any contents or a part of contents of this e-book in any manner without written consent of the publisher.We strive to update the contents of our website and tutorials as timely and as precisely as possible, however, the contents may contain inaccuracies or errors. Tutorials Point (I) Pvt. Ltd. provides no guarantee regarding the accuracy, timeliness or completeness of our website or its contents including this tutorial. If you discover any errors on our website or inthistutorial,******************************************.iT able of ContentsAbout the Tutorial (i)Audience (i)Prerequisites (i)Disclaimer & Copyright (i)Table of Contents............................................................................................................................................. i i 1.VSAM - OVERVIEW (1)Characteristics of VSAM (1)Limitations of VSAM (1)2.VSAM – COMPONENTS (2)VSAM Cluster (2)Control Interval (2)Analysis of Control Interval (3)Control Area (3)3.VSAM - CLUSTER (4)Defining a Cluster (4)Deleting a Cluster (7)4.VSAM – ENTRY SEQUENCED DATA SET (9)Defining ESDS Cluster (9)Deleting ESDS Cluster (11)5.VSAM – KEY SEQUENCED DATA SET (12)KSDS File Structure (12)Defining KSDS Cluster (13)Deleting KSDS Cluster (14)ii6.VSAM – RELATIVE RECORD DATA SET (16)RRDS File Structure (16)Defining RRDS Cluster (17)Deleting RRDS Cluster (18)7.VSAM – LINEAR DATA SET (19)Defining LDS Cluster (19)Deleting LDS Cluster (20)8.VSAM – COMMANDS (22)Alter (22)Repro (23)Listcat (24)Examine (25)Verify (25)9.VSAM – ALTERNATE INDEX (27)Creation of Alternate Index (27)Define Alternate Index (27)Define Path (29)Building Index (30)10.VSAM – CATALOG (31)Master Catalog (31)User Catalog (32)Data Space (32)Unique Clusters (32)Sub-allocated Clusters (32)Non-VSAM datasets (32)iii11.VSAM – FILE STATUS (33)12.VSAM – INTERVIEW QUESTIONS (35)ivVSAM 1Virtual Storage Access Method (VSAM) is high performance access method and data set organization, which organizes and maintains data via a catalog structure. It utilizes virtual storage concept and can protect datasets at various levels by giving passwords. VSAM can be used in COBOL programs like physical sequential files. VSAM are the logical datasets for storing records. Files can be read sequentially and randomly in VSAM. It is an improved way of storing data which overcomes some of the limitations of conventional file systems like Sequential Files.Characteristics of VSAMFollowing are the characteristics of VSAM:∙VSAM protects data against unauthorized access by using passwords. ∙VSAM provides fast access to data sets. ∙VSAM has options for optimizing performance. ∙VSAM allows data set sharing in both batch and online environment. ∙VSAM are more structured and organized in storing data. ∙ Free space is reused automatically in VSAM files.Limitations of VSAMThe only limitation of VSAM is that it cannot be stored on TAPE volume. It is always stored on DASD space. It requires a number of cylinders to store the data which is not cost-effective.1.VSAM 2VSAM consists of following components:∙VSAM Cluster ∙Control Area ∙ Control IntervalVSAM ClusterVSAM are the logical datasets for storing records and are known as clusters. A cluster is an association of the index, sequence set and data portions of the dataset. The space occupied by a VSAM cluster is divided in contiguous areas called Control Intervals. We will discuss about control intervals later in this module.There are two main components in a VSAM cluster:∙ Index Component contains the index part. Index records are present in Index component. Using index component VSAM is able to retrieve records from the data component.∙Data Component contains the data part. Actual data records are present in Data component. Control IntervalControl Intervals (CI) in VSAM are equivalent to blocks for non-VSAM data sets. In non-VSAM methods, the unit of data is defined by the block. VSAM works with logical data area which is known as Control Intervals.Control Intervals are the smallest unit of transfer between a disk and the operating system. Whenever a record is retrieved directly from the storage, the entire CI containing the record is read into VSAM Input-Output buffer. The desired record is then transferred to work area from VSAM buffer.Control Interval consists of:∙Logical Records ∙Control information fields ∙ Free SpaceWhen a VSAM dataset is loaded, control intervals are created. The default Control Interval size is 4K bytes and it can extend up to 32K bytes.2.VSAM Analysis of Control IntervalFollowing is the description of terms used in the above program:∙R1..R5: Records which are stored in Control Interval.∙FS: FS is free space, which can be used for further expansion of dataset.∙RDF: RDF is known as Record Definition Fields. RDF are 3 bytes long. It describes the length of records and tells how many adjacent records are of the same length.∙CIDF: CIDF is known as Control Interval Definition Fields. CIDF are 4 bytes long and contain information about the Control Interval.Control AreaA Control Area (CA) is formed by putting together two or more Control Intervals. A VSAM dataset is composed of one or more Control Areas. The size of VSAM is always a multiple of its Control Area. VSAM files are extended in units of Control Areas.Following is the example of Control Area:3VSAM 4VSAM cluster is defined in JCL . JCL uses IDCAMS utility to create a cluster. IDCAMS is a utility, developed by IBM, for access method services. It is used to primarily define VSAM datasets.Defining a ClusterThe following syntax shows the main parameters which are grouped under Define Cluster , Data and Index .Parameters at the CLUSTER level apply to the entire cluster. Parameters at the DATA or INDEX level apply only to the data or index component.3.VSAMWe will discuss each parameter in detail in the following table:ExampleFollowing is a basic example to show how to define a cluster in JCL:If you will execute the above JCL on Mainframes server. It should execute with MAXCC=0 and it will create MY.VSAM.KSDSFILE VSAM file.6Deleting a ClusterTo delete a VSAM file, the VSAM cluster needs to be deleted using IDCAMS utility. DELETE command removes the entry of the VSAM cluster from the catalog and optionally removes the file, thereby freeing up the space occupied by the object. If the VSAM data set has not expired, then it will not be deleted. To delete such types of datasets, use PURGE option.Above syntax shows the parameters which we can use with Delete statement. We will discuss each of them in detail in the following table:ExampleFollowing is a basic example to show how to delete a cluster in JCL:7If you will execute the above JCL on Mainframes server. It should execute with MAXCC=0 and it will delete MY.VSAM.KSDSFILE VSAM file.8VSAM 9ESDS is known as Entry Sequenced Data Set. An entry-sequenced data set behaves like sequential file organization with some more features included. We can access the records directly and for safety purpose we can use passwords also. We must code NONINDEXED inside the DEFINE CLUSTER command for ESDS datasets. Following are the key features of ESDS:∙ Records in ESDS cluster are stored in the order in which they were inserted into the dataset.∙ Records are referenced by physical address which is known as Relative Byte Address (RBA). Suppose if in an ESDS dataset, we have 80 byte records, the RBA of first record will be 0, RBA for second record will be 80, for third record it will be 160 and so on.∙ Records can be accessed sequentially by RBA which is known as addressed access .∙ Records are held in the order in which they were inserted. New records are inserted at the end.∙ Deletion of records is not possible in ESDS dataset. But they can be marked as inactive.∙ Records in ESDS dataset can be of fixed length or variable length.∙ ESDS is non-indexed. Keys are not present in ESDS dataset, so it may contain duplicate records.∙ ESDS can be used in COBOL programs like any other file. We will specify the file name in JCL and we can use the ESDS file for processing inside program. In COBOL program specify file organization as Sequential and access mode as Sequential with ESDS dataset.4.VSAMEnd of ebook previewIf you liked what you saw…Buy it from our store @ https://10。

.编码格式•第1~6列为序号区,用于表示行号。
行号不是必须的,也不必是顺序的,甚至可以是本机字符集中的任意字符,但正确的行号是很重要的。
•第7列为指示区,可以包含如下指示符:"*"指示本行内容为注释。
"-"指示本行代码为上一行的延续。
"D"指示本行代码为调试代码,将在启用DEBUGGING模式时被编译,未启用时将被忽略。
"/"指示编译器为源码列表开始新的一页,并且本行将被视为注释。
•第8~11列为A区。
下列项必须从A区开始:部标题(DIVISION)节标题(SECTION)段名(段标题)层指示符FD和SD,层号01和77DECLARATIVES 和END DECLARATIVESEND PROGRAM•第12~72列为B区。
作为程序主体的条目(entries),句子(sentences),语句(statements),从句(clauses)和续行(/)等都必须从B区开始。
*句法说明:节(SECTIONs)和段(paragraphs)定义了程序,它们又细分为以下部分:条目(entries):以句点(.)结尾的一系列从句。
构造于标识部、环境部和数据部。
从句(clauses):连续的COBOL字符串的有序集合,用于指定条目的某个属性。
构造于标识部、环境部和数据部。
句子(sentences):以句点(.)结尾的一个或多个语句的序列。
构造于过程部。
语句(statements):指定程序要执行的某个动作。
构造于过程部。
短语(phrases):构成从句和语句的更小单元。
2.基本结构----|----1----|----2----|----3----|----4----|----5----|----6----|----7----|----8//标识部000001 IDENTIFICATION DIVISION.000002 PROGRAM-ID. PGMNAME. //指定本程序名。
CICS/MVS技术日记作者按:当时业界都说CICS思想博大精深,引得版主下大力气苦苦探索,昨日偶然翻了出来,愿意贡献给有需要的网友。
后来迫于形式,开始学习使用J2EE、dot NET、XML、PKI、UML、CMM、LINUX等新玩意儿,功夫尚未练到家,心里也没底,不知老美的几个IT巨人厮杀的结果如何,将世界IT引向何处,吃不准哪片云彩有雨。
本文属于笔记性质,文笔未经考究,不存在任何“知识产权”,如果对网友有所宜处,版主不胜荣幸。
在对BMS进行编译时,可以使用两个选项,即Type=DSECT和Type=Map;前者生成逻辑MAP,后者生成物理MAP。
可以在LINKAGE SECTION中说明一个数据结构,而用ADDRESS获取其地址,空间的分配命令包括GETMAIN,LOAD,READ和READQ。
在多用户的环境下,不仅要考虑交易的完整性与一致性,而且要考虑多交易对资源的争夺,即避免死锁现象的出现。
为此,1.所有的应用程序必须以同样的KEY 值顺序对文件进行访问,即升序或降序。
2.所有应用在发起一个READ UPDA TE命令后必须写一个REWRITE或DELETE或UNLOCK。
3.WRITE MASSINSERT命令后需接一个UNLOCK命令。
CICS不支持广泛的混合语言编程环境,但COBOL可调用ASM的模块。
但一个CICS交易可由多个执行程序所组成,利用LINK或XCTL命令来相互调用。
CICS对子程序的调用可包括三种形式,即EXEC CICS LINK,STATIC COBOL CALL以及DYNAMIC COBOL CALL。
在CICS的COBOL宿主程序中,CICS的DFHEIBLK(EXEC INTERFACE BLOCK)以及DFHCOMMAREA(communication area)在LINKAGE SECTION中被插入。
CICS的NESTING:1.必须将最高层的程序及其所有直接或间接的程序所为编译的一个单元来提交。
第12章文件12.1 复习笔记一、文件的基本概念1.文件概述(1)定义文件是性质相同的记录的集合。
(2)按关键字划分①单关键字文件若文件中的记录只有一个惟一标识记录的主关键字,则称之为单关键字文件;②多关键字文件若文件中的记录除了含有一个主关键字外,还含有若干个次关键字,则称之为多关键字文件。
(3)按是否定长划分①定长文件若文件中各记录含有的信息长度相同,则称这类记录为定长记录,由这种定长记录组成的文件称作定长文件;②不定长文件若文件中各记录含有的信息长度不等,则称作不定长文件。
2.文件的逻辑结构及操作(1)文件的逻辑结构文件中各记录之间存在着逻辑关系,当一个文件的各个记录按照某种次序排列起来时,各记录之间就自然地形成了一种线性关系。
在这种次序下,文件中每个记录最多只有一个直接后继记录和一个直接前驱记录,而文件的第一个记录只有直接后继没有直接前驱,文件的最后一个记录只有直接前驱而没有直接后继。
此时,文件可看成是一种线性结构。
(2)文件操作①检索文件检索就是在文件中查找满足给定条件的记录,它既可以按记录的逻辑号(即记录存入文件时的顺序编号)查找,也可以按关键字查找。
②维护文件维护主要是指对文件进行记录的插入、删除及修改等更新操作。
此外,为提高文件的效率,还要进行再组织操作、文件被破坏后的恢复操作以及文件中数据的安全保护等。
3.文件的存储结构(1)概念文件的存储结构是指文件在外存上的组织方式。
采用不同的组织方式就得到不同的存储结构。
(2)基本的组织方式①顺序组织;②索引组织;③哈希组织;④链组织。
文件组织的各种方式往往是这四种基本方式的结合。
二、顺序文件1.定义顺序文件是指按记录进入文件的先后顺序存放、其逻辑顺序跟物理顺序一致的文件。
若顺序文件中的记录按其主关键字有序,则称此顺序文件为顺序有序文件;否则称为顺序无序文件。
2.优点顺序文件的主要优点是连续存取的速度较快,即若文件中第i个记录刚被存取过,而下一个要存取的是第i+1个记录,则这种存取将会很快完成。
VSAM简介VSAM(virtual storage access method)文件是IBM公司在虚拟存储器和树型结构基础上,为了满足数据量大、存取速度快和维护方便的要求而发展起来的一种文件组织形式。
VSAM文件可分为以下几种组织形式:(1)键顺序文件KSDS:这种文件与索引文件相似,由索引部分和数据部分组成。
索引部分包含树型结构的多级索引。
数据部分内的记录按键值顺序排列。
因此,这种文件可以按键值顺序存取,也可以利用索引,根据键值进行直接存取。
(2)输入顺序文件ESDS:文件内的记录按输入顺序排列,因此,可以按照排列顺序进行存取,也可以指定记录的相对字节地址,对特定记录进行存取。
(3)相对记录文件RRDS:文件空间被划分为等长的SLOT,每个SLOT只存放一个记录,从第一个SLOT开始分别赋予连续的顺序号,这样的号码叫相对记录号。
只要给出相对记录号,就可实现对特定记录的直接存取。
(4)线性文件LDSVSAM文件结构VSAM数据集中的数据除线性数据集外,都被称为逻辑记录。
逻辑记录是用户访问数据集的单位。
VSAM的逻辑记录与非VSAM数据集的存储方式不同。
VSAM将记录存于CI(control interval)。
一个CI是直接访问存储设备的一片连续区域,用于存储数据记录及其控制信息。
当从直接存储设备上读取一个记录时,包含要读的记录的整个CI都被读到虚存的VSAM I/O缓冲中,然后用户要读的记录才从VSAM缓冲传输到用户定义的工作区。
缺月挂疏桐,漏断人初静,谁见幽人独往来,缥缈孤鸿影。
惊起却回首,有恨无人省,捡尽寒枝不肯栖,枫落吴江冷。
一个VSAM数据集在一个卷上可以占用最多119 - 123个Extent,或者占用4,294,967,296个字节。
CI的大小在不同的VSAM数据集中可以不同,但在一个数据集中必须相同。
在创建数据集时,你可以用访问方法服务的DEFINE命令指定CI的大小,也可以让系统自动选择CI的大小。
要在COBOL中使用文件,要在3个不同的部中放上信息。
环境部,要有程序使用的每个文件的文件控制项目(FILE-CONTROL)。
这个项目将程序中使用的文件名与程序外的实际文件联系起来。
这些项目还定义文件的组织和访问方式。
数据部,要有每个文件的文件描述符(FD)项目,就是数据定义。
过程部,放上处理语句,OPEN,READ,WRITE,DELETE等。
环境部中主要是FILE-CONTROL和I-O-CONTROL.I-O-CONTROL很少使用。
SELECT[OPTIONAL]file-name ASSIGN TO DEV/FILE[RESERVE N[AREA/AREAS]][FILE STATUS IS VAR]SELECT必须是第一句,其他顺序无关。
file-name是程序中传递使用的文件名,相当于实际文件的一个别名。
OPTIONAL用于执行可能不存在的文件。
ASSIGN将file-name连接到实际的外部设备或文件。
(TO好像可以省略。
)RESERVE指定文件缓冲区。
FILE STATUS指定一个变量存放文件状态,这个变量应该已在WORKING-STORAGE SECTION中定义。
对于顺序文件,还有声明如下:[ORGANIZATION IS SEQUENTIAL]可选,缺省为顺序组织文件[ACCESS MODE IS SEQUENTIAL]可选。
顺序文件只允许顺序访问[PADDING CHARACTER IS char]指定文件在固定块长设备上时键块所用的字符,char为一个字符的数据项。
[RECORD DELIMITER IS STANDARD/usr-define]指定如何确定变长纪录的长度。
顺序文件例子:SELECT file-name ASSIGN TO"/usr/file1"FILE STATUS IS file-status对于相对文件,还有声明如下:[ORGANIZATION IS RELATIVE]是相对文件必须的[ACCESS MODE IS SEQUENTIAL[RELATIVE KEY IS data]]或者[ACCESS MODE IS RANDOM/DYNAMIC RELATIVE KEY IS data]访问方式有3种,缺省是SEQUENTIAL。
RELATIVE KEY可选。
如果存在,则文件读取操作顺利完成后,data用所读取纪录的关键字更新。
data应为文件的纪录区中没有的整数数据项。
相对文件的例子:SELECT file-name ASSIGN TO"/usr/file2"ORGANIZATION IS RELATIVEACCESS MODE IS DYNAMIC RELATIVE KEY IS DAY-NUMBERFILE STATUS IS file-status对于索引文件,还有声明如下:[ORGANIZATION IS INDEXED]是索引文件必须的[ACCESS MODE IS SEQUENTIAL/RANDOM/DYNAMIC]RECORD KEY IS data1[ALTERNATE RECORD KEY IS data2[WITH DUPLICATES]]访问方式有3种,缺省是SEQUENTIAL。
RECORD KEY指定文件的主纪录关键字,data1应为定义该文件的某个记录区的字母数字数据项目。
这个关键字的描述及其在数据记录中的位置应该与生成文件时所用的关键字一致。
ALTERNATE RECORD KEY如果文件有替换关键字,则其关键字用这个从句的短语指定,索引中允许重复关键字时采用DUPLICATES.COBOL要求文件记录中定义data2。
重复关键字的长度及其在数据记录中的位置应该与生成文件时一致,所有替换关键字应放在文件控制项中。
索引文件的例子:SELECT file-name ASSIGN TO"/usr/file3"ORGANIZATION IS INDEXEDACCESS MODE IS RANDOMRECORD KEY IS NUMBER OF EMPLOYEE-RECORDALTERNATE RECORD KEY IS LAST-NAME OF EMPLOYEE-RECORD WITH DUPLICATES ALTERNATE RECORD KEY IS SS-NUMBER OF EMPLOYEE-RECORDFILE STATUS IS file-status这里用户在程序中使用的文件名是file-name,实际文件名是file3。
file-name 的定义放在程序后边的数据部的文件节中。
文件是索引文件,程序可以随机访问文件。
文件的主关键字是NUMBER OF EMPLOYEE-RECORD,替换关键字是LAST-NAME和SS-NUMBER,都是文件记录区的字段。
LAST-NAME允许重复。
文件状态:(对文件操作时返回文件状态到定义的文件状态变量)ANY00成功ANY02对索引文件,成功但发现重复关键字READ04成功,但纪录长度不符合指定长度OPEN05成功,但文件是可选的,前面不存在OPEN,CLOSE07对顺序文件,成功,但媒介不是盘READ10文件已到末尾READ14对相对文件,相对纪录号的有效位超过相对关键字数据项允许的位WRITE,REWRITE21对索引文件,顺序出错WRITE22对索引和相对文件,带这个关键字的纪录已经存在START,READ23对索引和相对文件,带这个关键字的纪录不存在WRITE24对相对文件,相对纪录号的有效位超过相对关键字数据项允许的位ANY30I/O错误WRITE34对顺序文件,发生超边界错误OPEN35对顺序和相对文件,未发现非可选文件OPEN37对顺序和相对文件,该文件不支持指定的打开方式OPEN38对顺序和相对文件,文件已经用锁关闭OPEN39对顺序和相对文件,文件属性不支持程序中指定的属性OPEN41文件已经打开CLOSE42文件未打开DELETE,REWRITE43最近的操作不是READWRITE,REWRITE44纪录长度非法READ46没有有效的下一个记录READ,START47文件未在INPUT或I-O方式中打开WRITE48文件未在OUTPUT或EXTEND方式中打开DELETE,REWRITE49文件未在I-O方式中打开ANY90~99厂家定义由上可知,文件操作时会发生错误,COBOL提供了检查错误和恢复I/O错误的公用地点。
过程部开头应包括DECLARATIVES部分,放上出现错误时要执行的语句。
PROCEDURE DIVISION.DECLARATIVES.section-name SECTION.USE statement(出现错误时调用的节).paragraph-name.sentence...END DECLARATIVES.section-name SECTION.paragraph-name.sentence...USE AFTER STANDARD EXCEPTION/ERROR PROCEDURE ON file-name/INPUT/OUTPUT/I-O/EXTEND只能在USE语句中指定一个文件,一种方式也只能有一个USE语句。
如果既指定了文件,也指定了方式,则文件优先。
程序使用的所有文件要定义在数据部的第一节----文件节中。
FD file-name[BLOCK CONTAINS int-1[TO int-2]RECORDS/CHARACTERS][RECORD(CONTAINS int-3[TO int-4]CHARACTERS)/(IS VARYING IN SIZE[FROM int-5][TO int-6]CHARACTERS)/(DEPENDING ON data1)[LABEL(RECORD IS)/(RECORDS ARE)STANDARD/OMITTED][VALUE OF(implementor-name IS id-lit-1)...][DATA(RECORD IS)/(RECORDS ARE)data2]BLOCK CONTAINS指定实际纪录的具体长度或最大与最小长度的逻辑记录数或块数。
一般有操作系统和文件系统指定。
RECORD指定包含变长纪录的文件中记录的最大与最小长度或定长纪录的具体长度。
RECORD CONTAINS如果不带TO,则int-3是每个纪录的长度;如果带TO,介于int-3和int-4之间。
RECORD IS VARYING指定纪录长度最小int-5和最大int-6。
DEPENDING ON如要用,则需要在data1中保存纪录长度。
LABEL RECORD指定文件是否带标号。
(过时,下个版本不包含)VALUE和LABEL一起检查标号的不同部分。
(过时,下个版本不包含)DATA RECORD指定属于文件的纪录描述项(FD后的01层项目)并作为程序文档。
(过时,下个版本不包含)一般定义文件只用第一句:FD file-name顺序文件的LINAGE声明对顺序文件,LINAGE声明可以在文件输出是打印机或打印机兼容文件时指定一些打印细节。
[LINAGE IS BODY LINES[WITH FOOTING AT FOOT][LINES AT TOP TOP][LINES AT BOTTOM BOTTOM]][CODE-SET IS alphabet-name]整个文件分成TOP,BODY,BOTTOM三部分。
其中BODY包含有FOOT.CODE-SET指定文件中所用的字符集。
过程部主要是对文件的OPEN,CLOSE,READ,WRITE,START,REWRITE,DELETE等操作。
OPENOPEN文件有4种方式:(如果文件声明为OPTIONAL,则文件不存在会创建文件,否则会报错)OPEN INPUT FILE-NAME.只能读取的文件。
OPEN OUTPUT FILE-NAME.生成写入纪录的文件,读取该文件会出错。
若文件已存在,已有记录会被全部删除。
OPEN I-O FILE-NAME.可读可写的文件。
OPEN EXTEND FILE-NAME.生成写入的文件。
与OUTPUT的区别在于,若文件已存在,EXTEND将纪录加在文件末尾。
如果OPEN不成功,执行USE语句。
USE语句不存在,则程序结束。
顺序文件的OPEN可以有以下方式:OPEN INPUT FILE-NAME[(WITH NO REWIND)/REVERSED].OPEN OUTPUT FILE-NAME[WITH NO REWIND].REVERSED可以逆序处理,即由后向前处理。