第2章多元回归分析
- 格式:ppt
- 大小:214.00 KB
- 文档页数:44








应用回归分析_第2章课后习题参考答案1. 简答题1.1 什么是回归分析?回归分析是一种统计建模方法,用于研究自变量与因变量之间的关系。
它通过建立数学模型,根据已知的自变量和因变量数据,预测因变量与自变量之间的关系,并进行相关的推断和预测。
1.2 什么是简单线性回归和多元线性回归?简单线性回归是指只包含一个自变量和一个因变量的回归模型,通过拟合一条直线来描述两者之间的关系。
多元线性回归是指包含多个自变量和一个因变量的回归模型,通过拟合一个超平面来描述多个自变量和因变量之间的关系。
1.3 什么是残差?残差是指回归模型中,观测值与模型预测值之间的差异。
在回归分析中,我们希望最小化残差,使得模型与观测数据的拟合效果更好。
1.4 什么是拟合优度?拟合优度是用来评估回归模型对观测数据的拟合程度的指标。
一般使用R方(Coefficient of Determination)来表示拟合优度,其值范围为0到1,值越接近1表示模型拟合效果越好。
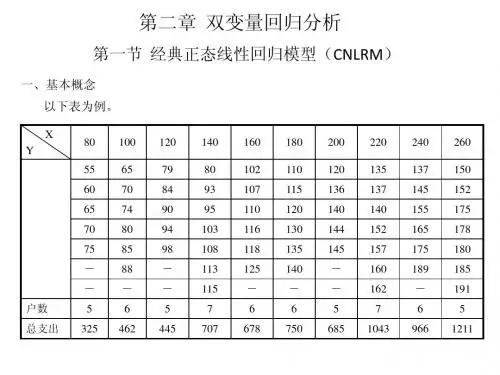
2. 计算题2.1 简单线性回归假设我们有一组数据,其中X为自变量,Y为因变量,如下所示:X Y13253749511我们想要建立一个简单线性回归模型,计算X与Y之间的线性关系。
首先,我们需要计算拟合直线的斜率和截距。
根据简单线性回归模型的公式Y = β0 + β1*X,我们可以通过最小二乘法计算出斜率和截距的估计值。
首先,计算X和Y的均值:mean_x = (1 + 2 + 3 + 4 + 5) / 5 = 3mean_y = (3 + 5 + 7 + 9 + 11) / 5 = 7然后,计算X和Y的方差:var_x = ((1-3)^2 + (2-3)^2 + (3-3)^2 + (4-3)^2 + (5-3)^2) / 5 = 2var_y = ((3-7)^2 + (5-7)^2 + (7-7)^2 + (9-7)^2 + (11-7)^2) / 5 = 8接下来,计算X和Y的协方差:cov_xy = ((1-3) * (3-7) + (2-3) * (5-7) + (3-3) * (7-7) + (4-3) * (9-7) + (5-3) * (11-7)) / 5 = 4根据最小二乘法的公式:β1 = cov_xy / var_x = 4 / 2 = 2β0 = mean_y - β1 * mean_x = 7 - (2 * 3) = 1因此,拟合直线的方程为:Y = 1 + 2X。

第二章 回归分析与相关分析§3 多元线性回归分析在现实地理系统中,任何事物的变化都是多种因素影响的结果,一因多果、一果多因的情况比比皆是。
为了处理一果多因的因果关系问题,我们需要掌握多元线性回归知识。
本节着重讲述二元线性回归分析。
至于三元以上,基本原理可以依此类推。
1 基本模型二元线性回归模型可以表为2211x b x b a y ++=, (3-1)式中a 、b 1、b 2为待定的偏回归参数(partial regression coefficient )。
理论上的预测模型为i i i x b x b a y2211ˆ++=. (3-2) 原则上讲,式(3-2)中的参数a 、b 1、b 2与式(3-1)中的a 、b 1、b 2是有区别的:式(3-1)的是真实的系数值,式(3-2)的是计算的系数值。
但为了方便起见,我们不作符号上的区分。
实测数据的模型可以表作d yd x b x b a y i i i i i ±=±++=ˆ2211, (3-3) 从而i i i i i i x b x b a y yy d 2211ˆ---=-=. (3-4) 令min )(12221112→---==∑∑==ni i i i n i i x b x b a y d S . (3-5)为求极值,分别对a 、b 1、b 2求偏导,并令其为零,可得0)(22211=---=∂∂∑ii i i x b x b a y a S, (3-6) 0)(2122111=---=∂∂∑i ii i i x x b x b a y b S, (3-7)0)(2222111=---=∂∂∑i ii i i x x b x b a y b S. (3-8) 上面三式可以化为正规方程形式⎪⎪⎩⎪⎪⎨⎧=++=++=++∑∑∑∑∑∑∑∑∑∑∑i i i i i ii i i i i i i i i y x x b x x b x a y x x x b x b x a y x b x b an 22222112121221112211. (3-9) 根据线性代数的有关原理,可令∑∑∑∑∑∑∑∑∑=222122121121iiiiiiiiiii i i x x x y x xx x y x xx y A , ∑∑∑∑∑∑∑∑=2222211121ii iiiiiii i i x y x xx x y x x x y nB ,∑∑∑∑∑∑∑∑=iiiiii iiii i yx x x x yx x x yx n B 2212121112, ∑∑∑∑∑∑∑∑=222122121121iiiiiiii i i xx x xx x x x x x nC .借助Cramer 法则容易得到C Aa =,C B b 11=,CB b 12=. (3-10) 2 回归结果的检验检验的类型与一元线性回归相似,包括相关系数检验、标准误差检验、F 检验、t 检验和DW 检验。
第⼆章回归分析中的⼏个基本概念第四章⼀、练习题(⼀)简答题1、多元线性回归模型的基本假设是什么?试说明在证明最⼩⼆乘估计量的⽆偏性和有效性的过程中,哪些基本假设起了作⽤?2、多元线性回归模型与⼀元线性回归模型有哪些区别?3、某地区通过⼀个样本容量为722的调查数据得到劳动⼒受教育的⼀个回归⽅程为fedu medu sibs edu 210.0131.0094.036.10++-=R 2=0.214式中,edu 为劳动⼒受教育年数,sibs 为该劳动⼒家庭中兄弟姐妹的个数,medu 与fedu 分别为母亲与⽗亲受到教育的年数。
问(1)若medu 与fedu 保持不变,为了使预测的受教育⽔平减少⼀年,需要sibs 增加多少?(2)请对medu 的系数给予适当的解释。
(3)如果两个劳动⼒都没有兄弟姐妹,但其中⼀个的⽗母受教育的年数为12年,另⼀个的⽗母受教育的年数为16年,则两⼈受教育的年数预期相差多少? 4、以企业研发⽀出(R&D )占销售额的⽐重为被解释变量(Y ),以企业销售额(X1)与利润占销售额的⽐重(X2)为解释变量,⼀个有32容量的样本企业的估计结果如下:099.0)046.0()22.0()37.1(05.0)log(32.0472.0221=++=R X X Y其中括号中为系数估计值的标准差。
(1)解释log(X1)的系数。
如果X1增加10%,估计Y 会变化多少个百分点?这在经济上是⼀个很⼤的影响吗?(2)针对R&D 强度随销售额的增加⽽提⾼这⼀备择假设,检验它不虽X1⽽变化的假设。
分别在5%和10%的显著性⽔平上进⾏这个检验。
(3)利润占销售额的⽐重X2对R&D 强度Y 是否在统计上有显著的影响? 5、什么是正规⽅程组?分别⽤⾮矩阵形式和矩阵形式写出模型:i ki k i i i u x x x y +++++=ββββΛ22110,n i ,,2,1Λ=的正规⽅程组,及其推导过程。
2.1回归分析与回归函数一、判断题1. 总体回归直线是解释变量取各给定值时被解释变量条件期望的轨迹。
(T )2. 线性回归是指解释变量和被解释变量之间呈现线性关系。
( F )3. 随机变量的条件期望与非条件期望是一回事。
(F )4、总体回归函数给出了对应于每一个自变量的因变量的值。
(F )二、单项选择题1.变量之间的关系可以分为两大类,它们是( A )。
A .函数关系与相关关系B .线性相关关系和非线性相关关系C .正相关关系和负相关关系D .简单相关关系和复杂相关关系2.相关关系是指( D )。
A .变量间的非独立关系B .变量间的因果关系C .变量间的函数关系D .变量间不确定性的依存关系3.进行相关分析时的两个变量( A )。
A .都是随机变量B .都不是随机变量C .一个是随机变量,一个不是随机变量D .随机的或非随机都可以4.回归分析中定义的( B )。
A.解释变量和被解释变量都是随机变量B.解释变量为非随机变量,被解释变量为随机变量C.解释变量和被解释变量都为非随机变量D.解释变量为随机变量,被解释变量为非随机变量5.表示x 和y 之间真实线性关系的总体回归模型是( C )。
A .01ˆˆˆt t Y X ββ=+B .01()t t E Y X ββ=+C .01t t t Y X u ββ=++D .01t t Y X ββ=+6.一元线性样本回归直线可以表示为( C )A .i i X Y u i 10++=ββ B. i 10X )(Y E i ββ+=C. i i e X Y ++=∧∧i 10ββ D. i 10X i Y ββ+=∧7.对于i 01i i ˆˆY =X +e ββ+,以ˆσ表示估计标准误差,r 表示相关系数,则有( D)。
A .ˆ0r=1σ=时,B .ˆ0r=-1σ=时,C .ˆ0r=0σ=时,D .ˆ0r=1r=-1σ=时,或8.相关系数r 的取值范围是( D )。
第二章回归分析中的几个基本概念1. 回归模型(Regression Model):回归模型是回归分析的基础,用来描述两个或多个变量之间的关系。
回归模型通常包括一个或多个自变量和一个或多个因变量。
常用的回归模型有线性回归模型和非线性回归模型。
线性回归模型是最简单的回归模型,其中自变量和因变量之间的关系可以用一条直线来表示。
线性回归模型的表达式为:Y=β0+β1*X1+β2*X2+...+βn*Xn+ε其中,Y表示因变量,X1、X2、…、Xn表示自变量,β0、β1、β2、…、βn表示回归系数,ε表示误差项。
2. 回归系数(Regression Coefficients):回归系数是回归模型中自变量的系数,用来描述自变量对因变量的影响程度。
回归系数可以通过最小二乘法估计得到,最小二乘法试图找到一组系数,使得模型的预测值和实际观测值的误差平方和最小。
回归系数的符号表示了自变量与因变量之间的方向关系。
如果回归系数为正,表示自变量的增加会使因变量增加,即存在正向关系;如果回归系数为负,表示自变量的增加会使因变量减少,即存在负向关系。
3. 拟合优度(Goodness-of-fit):拟合优度是用来评估回归模型对样本数据的拟合程度。
通常使用R方(R-squared)来度量拟合优度。
R 方的取值范围在0到1之间,越接近1表示模型对数据的拟合程度越好。
R方的解释是,回归模型中自变量的变异能够解释因变量的变异的比例。
例如,如果R方为0.8,表示模型中自变量解释了因变量80%的变异,剩下的20%可能由其他未考虑的因素引起。
4. 显著性检验(Significance Test):显著性检验用于判断回归模型中自变量的系数是否显著不为零,即自变量是否对因变量有显著影响。
常用的方法是计算t值和p值进行检验。
t值是回归系数除以其标准误得到的统计量。
p值是t值对应的双侧检验的概率。
如果p值小于给定的显著性水平(通常是0.05),则可以拒绝原假设,即认为回归系数显著不为零,即自变量对因变量有显著影响。