python常用模块
- 格式:doc
- 大小:495.50 KB
- 文档页数:90

python运维开发常⽤模块(四)⽂件对⽐模块difflib1.difflib介绍difflib作为 Python的标准库模块,⽆需安装,作⽤是对⽐⽂本之间的差异,且⽀持输出可读性⽐较强的HTML⽂档,与Linux下的diff命令相似。
我们可以使⽤difflib对⽐代码、配置⽂件的差别,在版本控制⽅⾯是⾮常有⽤。
Python 2.3或更⾼版本默认⾃带difflib模块,⽆需额外安装。
⽰例1:两个字符串的差异对⽐[yhl@myhost part2]$ cat simple1.py#!/usr/bin/python#_*_coding:utf-8_*_#****************************************************************## ScriptName: simple1.py# Author: BenjaminYang# Create Date: 2019-05-13 11:08# Modify Author: BenjaminYang# Modify Date: 2019-05-13 11:08# Function:#***************************************************************#import difflibtext1 = """text1: #定义字符串1This module provides classes and functions for comparing sequences.including HTML and context and unified diffs.difflib document v7.4add string"""text1_lines=text1.splitlines() #以⾏进⾏分隔text2="""text2: #定义字符串2This module provides classes and functions for Comparing sequences.including HTML and context and unified diffs.difflib document v7.5"""text2_lines=text2.splitlines()d=difflib.Differ() #创建Differ()对象diff=pare(text1_lines,text2_lines) #采⽤compare⽅法对字符串进⾏⽐较print'\n'.join(list(diff))本⽰例采⽤Differ()类对两个字符串进⾏⽐较,另外difflib的 SequenceMatcher()类⽀持任意类型序列的⽐较,HtmlDiff()类⽀持将⽐较结果输出为HTML格式⽰例运⾏结果符号含义说明⽣成美观的对⽐HTML格式⽂档采⽤HtmlDiff()类将新⽂件命名为simple2.py,运⾏# python simple2.py>diff.html,再使⽤浏览器打开diff.html⽂件,结果如图⽰2-2所⽰,HTML⽂档包括了⾏号、差异标志、图例等信息,可读性增强了许多的make_file()⽅法就可以⽣成美观的HTML ⽂档,对⽰例1中代码按以下进⾏修改:⽰例2:对⽐Nginx配置⽂件差异当我们维护多个Nginx配置时,时常会对⽐不同版本配置⽂件的差异,使运维⼈员更加清晰地了解不同版本迭代后的更新项,实现的思路是读取两个需对⽐的配置⽂件,再以换⾏符作为分隔符,调⽤ difflib.HtmlDiff()⽣成HTML格式的差异⽂档。

python常⽤模块及第三⽅库功能简介前⾔: Python吸引⼈的⼀个出众的优点就是它有众多的第三⽅库函数,可以更⾼效率的实现开发,经过整理与⽐对,整理了运维相关的常⽤模块,并将其功能简介,对其中重要的常⽤模块,接下来的博客会进⾏相应的详细介绍与功能使⽤介绍。
Python运维常⽤的20个库:1、psutil是⼀个跨平台库(https:///giampaolo/psutil)能够实现获取系统运⾏的进程和系统利⽤率(内存,CPU,磁盘,⽹络等),主要⽤于系统监控,分析和系统资源及进程的管理。
2、IPy(/haypo/python-ipy),辅助IP规划。
3、dnspython()Python实现的⼀个DNS⼯具包。
4、difflib:difflib作为Python的标准模块,⽆需安装,作⽤是对⽐⽂本之间的差异。
5、filecmp:系统⾃带,可以实现⽂件,⽬录,遍历⼦⽬录的差异,对⽐功能。
6、smtplib:发送电⼦邮件模块7、pycurl()是⼀个⽤C语⾔写的libcurl Python实现,功能强⼤,⽀持的协议有:FTP,HTTP,HTTPS,TELNET等,可以理解为Linux下curl命令功能的Python封装。
8、XlsxWriter:操作Excel⼯作表的⽂字,数字,公式,图表等。
9、rrdtool:⽤于跟踪对象的变化,⽣成这些变化的⾛⾛势图10、scapy(/projects/scapy/)是⼀个强⼤的交互式数据包处理程序,它能够对数据包进⾏伪造或解包,包括发送数据包,包嗅探,应答和反馈等功能。
11、Clam Antivirus免费开放源代码防毒软件,pyClamad,可以让Python模块直接使⽤ClamAV病毒扫描守护进程calmd。
12、pexpect:可以理解成Linux下expect的Python封装,通过pexpect我们可以实现对ssh,ftp,passwd,telnet等命令⾏进⾏⾃动交互,⽽⽆需⼈⼯⼲涉来达到⾃动化的⽬的。

Python常⽤模块os.path之⽂件及路径操作⽅法以下是 os.path 模块的⼏种常⽤⽅法:⽅法说明os.path.abspath(path)返回绝对路径os.path.basename(path)返回⽂件名monprefix(list)返回list(多个路径)中,所有path共有的最长的路径os.path.dirname(path)返回⽂件路径os.path.exists(path)如果路径 path 存在,返回 True;如果路径 path 不存在,返回 False。
os.path.lexists路径存在则返回True,路径损坏也返回Trueos.path.expanduser(path)把path中包含的"~"和"~user"转换成⽤户⽬录os.path.expandvars(path)根据环境变量的值替换path中包含的"$name"和"${name}"os.path.getatime(path)返回最近访问时间(浮点型秒数)os.path.getmtime(path)返回最近⽂件修改时间os.path.getctime(path)返回⽂件 path 创建时间os.path.getsize(path)返回⽂件⼤⼩,如果⽂件不存在就返回错误os.path.isabs(path)判断是否为绝对路径os.path.isfile(path)判断路径是否为⽂件os.path.isdir(path)判断路径是否为⽬录os.path.islink(path)判断路径是否为链接os.path.ismount(path)判断路径是否为挂载点os.path.join(path1[, path2[, ...]])把⽬录和⽂件名合成⼀个路径os.path.normcase(path)转换path的⼤⼩写和斜杠os.path.normpath(path)规范path字符串形式os.path.realpath(path)返回path的真实路径os.path.relpath(path[, start])从start开始计算相对路径os.path.samefile(path1, path2)判断⽬录或⽂件是否相同os.path.sameopenfile(fp1, fp2)判断fp1和fp2是否指向同⼀⽂件os.path.samestat(stat1, stat2)判断stat tuple stat1和stat2是否指向同⼀个⽂件os.path.split(path)把路径分割成 dirname 和 basename,返回⼀个元组os.path.splitdrive(path)⼀般⽤在 windows 下,返回驱动器名和路径组成的元组os.path.splitext(path)分割路径,返回路径名和⽂件扩展名的元组os.path.splitunc(path)把路径分割为加载点与⽂件os.path.walk(path, visit, arg)遍历path,进⼊每个⽬录都调⽤visit函数,visit函数必须有3个参数(arg, dirname, names),dirname表⽰当前⽬录的⽬录名,names代表当前⽬录下的所有⽂件名,args 则为walk的第三个参数os.path.supports_unicode_filenames设置是否⽀持unicode路径名os.path.abspath(path)输⼊相对路径,返回绝对路径Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)] on win32 Type "copyright", "credits" or "license()" for more information.>>> import os>>> print(os.path.abspath("."))C:\Users\28914\AppData\Local\Programs\Python\Python37os.path.basename(path)返回路径最后的⽂件或⽬录名,单纯的字符串处理,不会管该路径是否存在>>> import os>>> os.path.basename("E:\\abc\\efg.txt")'efg.txt'和os.path.basename相反,返回路径中去除了最后的⽂件或⽬录名后的部分,也是单纯的字符串处理>>> import os>>> os.path.dirname("E:\\abc\\efg.txt")'E:\\abc'os.path.split(path)单纯的字符串处理,分割路径,返回由其⽬录名和⽂件名组成的元组>>> import os>>> os.path.split("E:\\abc\\efg.txt")('E:\\abc', 'efg.txt')os.path.splitext(path)单纯的字符串处理,分割路径,返回由其⽂件名和扩展名组成的元组>>> import os>>> os.path.splitext("E:\\abc\\efg.txt")('E:\\abc\\efg', '.txt')os.path.join(dirpath,filename)将路径与⽂件名拼接,根据操作系统⾃动使⽤相应的路径分隔符,Windows⽤“”,Linux⽤“/”>>> import os>>> os.path.splitext("E:\\abc\\efg.txt")('E:\\abc\\efg', '.txt')os.path.exists(path)判断⽂件或⽬录是否存在,返回True或False>>> import os>>> os.path.exists("E:\\abc\\efg.txt")Falseos.path.isdir(path)判断路径是不是⽂件夹,路径不存在同样返回False>>> import os>>> os.path.isdir("E:\\abc\\efg.txt")Falseos.path.isfile(path)判断路径是不是⽂件,路径不存在同样返回False>>> import os>>> os.path.isfile("E:\\abc\\efg.txt")Falseos.path.getsize(path)获取⽂件⼤⼩,单位字节,⽂件不存在则报错,不能直接⽤于⽂件夹>>> import os>>> os.path.getsize("D:\\2019-11-07.txt")5973获取⽂件创建时间os.path.getmtime(path)获取⽂件最后修改时间os.path.getatime(path)获取⽂件最近访问时间总结以上所述是⼩编给⼤家介绍的Python常⽤模块os.path之⽂件及路径操作⽅法,希望对⼤家有所帮助,如果⼤家有任何疑问请给我留⾔,⼩编会及时回复⼤家的。

浅谈python中常⽤的excel模块库⽬录openpyxl如何安装:使⽤效果之⼀:xlwings如何安装:使⽤效果之⼀:XlsxWriter如何安装:使⽤效果之⼀:Tablibxlrd如何安装:xlwtxlutils如何安装:openpyxlopenpyxl是⼀个Python库,⽤于读取/写⼊Excel 2010 xlsx / xlsm / xltx / xltm⽂件。
它的诞⽣是因为缺少可从Python本地读取/写⼊Office Open XML格式的库。
如何安装:使⽤pip安装openpyxl$ pip install openpyxl使⽤效果之⼀:⽐如可以直接读取表格数据后综合输出写⼊到后⾯的⼀列中xlwingsxlwings是BSD许可的Python库,可轻松从Excel调⽤Python,同样也可在python中轻易调⽤excel。
它使⽤了⼲净且功能强⼤的Python代码替换VBA宏,可以同时⽀持在Windows和Mac上⼯作,同时在Excel和WPS都可兼容使⽤。
功能⻬全,⽀持Excel的新建、打开、修改、保存。
如何安装:pip install xlwings使⽤效果之⼀:可以使⽤python语⾔对Excel、WPS表格进⾏操作。
XlsxWriterXlsxWriter是⼀个Python模块,⽤于以Excel 2007+ XLSX⽂件格式编写⽂件。
它可以⽤于将⽂本,数字和公式写⼊多个⼯作表,并且⽀持诸如格式设置,图像,图表,⻚⾯设置,⾃动过滤器,条件格式设置等功能。
与编写Excel⽂件的替代Python模块相⽐,XlsxWriter具有⼀些优点和缺点。
优点:1.它⽐任何其他模块⽀持更多的Excel功能。
2.它具有由Excel⽣成的⽂件的⾼度保真度。
在⼤多数情况下,⽣成的⽂件与Excel⽣成的⽂件100%等价。
3.它具有⼤量的⽂档,⽰例⽂件和测试。
4.它速度很快,即使对于⾮常⼤的输出⽂件,也可以配置为使⽤很少的内存。

python中常⽤的内置模块汇总内置模块(⼀)Python内置的模块有很多,我们也已经接触了不少相关模块,接下来咱们就来做⼀些汇总和介绍。
内置模块有很多 & 模块中的功能也⾮常多,我们是没有办法注意全局给⼤家讲解,在此我会整理出项⽬开发最常⽤的来进⾏讲解。
osimport os# 1. 获取当前脚本绝对路径"""abs_path = os.path.abspath(__file__)print(abs_path)# 2. 获取当前⽂件的上级⽬录base_path = os.path.dirname( os.path.dirname(路径) )print(base_path)# 3. 路径拼接p1 = os.path.join(base_path, 'xx')print(p1)p2 = os.path.join(base_path, 'xx', 'oo', 'a1.png')print(p2)# 4. 判断路径是否存在exists = os.path.exists(p1)print(exists)# 5. 创建⽂件夹os.makedirs(路径)path = os.path.join(base_path, 'xx', 'oo', 'uuuu')if not os.path.exists(path):os.makedirs(path)# 6. 是否是⽂件夹file_path = os.path.join(base_path, 'xx', 'oo', 'uuuu.png')is_dir = os.path.isdir(file_path)print(is_dir) # Falsefolder_path = os.path.join(base_path, 'xx', 'oo', 'uuuu')is_dir = os.path.isdir(folder_path)print(is_dir) # True# 7. 删除⽂件或⽂件夹os.remove("⽂件路径")path = os.path.join(base_path, 'xx')shutil.rmtree(path)listdir,查看⽬录下所有的⽂件walk,查看⽬录下所有的⽂件(含⼦孙⽂件)import os"""data = os.listdir("/Users/feimouren/PycharmProjects/luffyCourse/day14/commons")print(data)# ['convert.py', '__init__.py', 'page.py', '__pycache__', 'utils.py', 'tencent']# ⽆法查看⽂件夹中⼦⽂件夹中的⽂件要遍历⼀个⽂件夹下的所有⽂件,例如:遍历⽂件夹下的所有mp4⽂件 data获取到的是⼀个⽣成器,在编列⽣成器时,会获取到三个元素,1.⽂件夹路径,2.⽂件夹中的⽂件夹,3.⽂件在遍历时,如果⽂件夹中还有⽂件夹,那么会继续遍历这个⽂件夹同样会获取data = os.walk("/Users/wupeiqi/Documents/视频教程/飞Python/mp4")for path, folder_list, file_list in data:for file_name in file_list:file_abs_path = os.path.join(path, file_name)ext = file_abs_path.rsplit(".",1)[-1]if ext == "mp4":print(file_abs_path)shutilimport shutil# 1. 删除⽂件夹"""path = os.path.join(base_path, 'xx')shutil.rmtree(path)# 2. 拷贝⽂件夹shutil.copytree("/Users/wupeiqi/Desktop/图/csdn/","/Users/wupeiqi/PycharmProjects/CodeRepository/files")# 3.拷贝⽂件shutil.copy("/Users/wupeiqi/Desktop/图/csdn/************************","/Users/wupeiqi/PycharmProjects/CodeRepository/")shutil.copy("/Users/wupeiqi/Desktop/图/csdn/************************","/Users/wupeiqi/PycharmProjects/CodeRepository/x.png")# 4.⽂件或⽂件夹重命名shutil.move("/Users/wupeiqi/PycharmProjects/CodeRepository/x.png","/Users/wupeiqi/PycharmProjects/CodeRepository/xxxx.png")shutil.move("/Users/wupeiqi/PycharmProjects/CodeRepository/files","/Users/wupeiqi/PycharmProjects/CodeRepository/images")# 5. 压缩⽂件# base_name,压缩后的压缩包⽂件# format,压缩的格式,例如:"zip", "tar", "gztar", "bztar", or "xztar".# root_dir,要压缩的⽂件夹路径# shutil.make_archive(base_name=r'datafile',format='zip',root_dir=r'files')# 6. 解压⽂件# filename,要解压的压缩包⽂件# extract_dir,解压的路径# format,压缩⽂件格式# shutil.unpack_archive(filename=r'datafile.zip', extract_dir=r'xxxxxx/xo', format='zip')sysimport sys# 1. 获取解释器版本"""print(sys.version)print(sys.version_info)print(sys.version_info.major, sys.version_info.minor, sys.version_info.micro)# 2. 导⼊模块路径print(sys.path)randomimport random# 1. 获取范围内的随机整数v = random.randint(10, 20)print(v)# 2. 获取范围内的随机⼩数v = random.uniform(1, 10)# 3. 随机抽取⼀个元素v = random.choice([11, 22, 33, 44, 55])# 4. 随机抽取多个元素v = random.sample([11, 22, 33, 44, 55], 3)# 5. 打乱顺序data = [1, 2, 3, 4, 5, 6, 7, 8, 9]random.shuffle(data)print(data)hashlibimport hashlibhash_object = hashlib.md5()hash_object.update("武沛齐".encode('utf-8'))result = hash_object.hexdigest()print(result)import hashlibhash_object = hashlib.md5("iajfsdunjaksdjfasdfasdf".encode('utf-8'))hash_object.update("武沛齐".encode('utf-8'))result = hash_object.hexdigest()print(result)"""在加密时,为了防⽌密码被撞出来,通常会在第⼆⾏代码处加盐,即添加我们⾃⼰知道的随机的字符串,这样就可以防⽌别⼈破解密码"""configparserxmljsonjson模块,是python内部的⼀个模块,可以将python的数据格式转换为json格式的数据,也可以将json格式的数据转换为python的数据格式。

python eml解析的模块介绍EML是一种常见的电子邮件文件格式,通常用于存储和交换电子邮件。
在使用Python进行EML解析时,可以使用多个模块来处理和提取EML文件中的各个部分。
以下是一些常用的Python模块,可以用于解析EML文件:1. email模块:Python标准库中的email模块提供了一套用于处理EML文件的类和函数。
它允许您解析EML文件中的邮件头、正文、附件等部分。
通过使用email模块,您可以轻松地访问邮件的各个组成部分,并进行需要的操作。
以下是email模块的一些常见类和函数:- email.message.Message:表示EML文件的一封邮件。
可以使用该类的方法来获取邮件头、正文和附件等部分。
- email.parser.Parser:用于将原始EML文件解析为email.message.Message对象。
- email.utils.parseaddr():用于解析EML文件中的发件人和收件人地址。
- email.utils.parseaddr():用于解析EML文件中的日期和时间。
2. cemail模块:cemail模块是一个第三方Python库,提供了更高效的方式来解析EML文件。
它是对Python标准库中email模块的一个优化版本,可以处理更大的EML文件,并提供更快的性能。
cemail模块的用法与email模块类似,但在处理大量的EML文件时,使用cemail模块可能会更加高效。
3. eml_parser模块:eml_parser模块是一个基于C的Python扩展,通过解析原始EML文件来提取邮件的各个部分。
它可以解析大型EML文件,并提供了访问邮件头、正文和附件的方法。
eml_parser模块的使用方法简单且高效,适用于需要处理大量EML文件的应用场景。
4. mail-parser模块:mail-parser模块是一个功能强大的EML解析工具,可以处理邮件的各个部分,并提供了详细的元数据和附件信息。

Python常用的数据分析库有哪些?Python数据分析模块介绍。
Python本身的数据分析功能并不强,需要一些第三方的扩展库来增强它的能力。
们课程用到的库包括NumPy、Pandas、Matplotlib、Seaborn、NLTK等,接下来将针对相关库一个简单的介绍,方便后面章节的学习。
在Python中,常用的数据分析库主要有以下几种:1、NumPy库NumPyPython源的数值计算扩展工具,它了Python对多维数组的支持,能够支持高级的维度数组与矩阵运算。
此外,针对数组运算也了量的数学函数库。
NumPy部分Python科学计算的基础,它具有以下功能:(1)快速的多维数据对象ndarray。
(2)高性能科学计算和数据分析的基础包。
(3)多维数组(矩阵)具有矢量运算能力,快速、节省空间。
(4)矩阵运算。
无需循环,可完成类似Matlab中的矢量运算。
(5)线性代数、随机数生成以及傅里叶变换功能。
2、Pandas库Pandas一个基于NumPy的数据分析包,它为了解决数据分析任务而创建的。
Pandas中纳入了量库和标准的数据模型,了地操作型数据集所需要的函数和方法,使用户能快速便捷地处理数据。
Pandas作为强而的数据分析环境中的重要因素之一,具有以下特:(1)一个快速的DataFrame对象,具有默认和自定义的索引。
(2)用于在内存数据结构和不同文件格式中读取和写入数据,比如CSV和文本文件、Excel文件及SQL数据库。
(3)智能数据对齐和缺失数据的集成处理。
(4)基于标签的切片、花式索引和数据集的子集。
(5)可以删除或入来自数据结构的列。
(6)按数据分组进行聚合和转换。
(7)高性能的数据合并和连接。
(8)时间序列功能。
Python与Pandas在各种学术和商业领域中都有应用,包括金融、神经科学、经济学、统计学、广告、网络分析等。
3、Matplotlib库Matplotlib一个用在Python中绘制数组的2D图形库,虽然它起源于模仿MATLAB图形命令,但它独立于MATLAB,可以通过Pythonic和面向对象的使用,Python中最出色的绘图库。

Python常⽤模块——Colorama模块简介Python的Colorama模块,可以跨多终端,显⽰字体不同的颜⾊和背景,只需要导⼊colorama模块即可,不⽤再每次都像linux⼀样指定颜⾊。
1. 安装colorama模块pip install colorama2. 常⽤格式常数Fore是针对字体颜⾊,Back是针对字体背景颜⾊,Style是针对字体格式Fore: BLACK, RED, GREEN, YELLOW, BLUE, MAGENTA, CYAN, WHITE, RESET.Back: BLACK, RED, GREEN, YELLOW, BLUE, MAGENTA, CYAN, WHITE, RESET.Style: DIM, NORMAL, BRIGHT, RESET_ALL注意,颜⾊RED,GREEN都需要⼤写,先指定是颜⾊和样式是针对字体还是字体背景,然后再添加颜⾊,颜⾊就是英⽂单词指定的颜⾊ from colorama import Fore, Back, Styleprint(Fore.RED + 'some red text')print(Back.GREEN + 'and with a green background')print(Style.DIM + 'and in dim text')print(Style.RESET_ALL)print('back to normal now') 输出结果# 记得要及时关闭colorma的作⽤范围# 如果不关闭的话,后⾯所有的输出都会是你指定的颜⾊print(Style.RESET_ALL)3.Init关键字参数:init()接受⼀些* * kwargs覆盖缺省⾏为,autoreset是⾃动恢复到默认颜⾊init(autoreset = False):init(wrap=True):The default behaviour is to convert if on Windows and output is to a tty (terminal).在windows系统终端输出颜⾊要使⽤init(wrap=True)#!/usr/bin/env python#encoding: utf-8from colorama import init, Fore, Back, Styleif __name__ == "__main__":init(autoreset=True) # 初始化,并且设置颜⾊设置⾃动恢复print(Fore.RED + 'some red text')print(Back.GREEN + 'and with a green background')print(Style.DIM + 'and in dim text')# 如果未设置autoreset=True,需要使⽤如下代码重置终端颜⾊为初始设置#print(Fore.RESET + Back.RESET + Style.RESET_ALL) autoreset=Trueprint('back to normal now')输出结果4.使⽤实例import sysimport osimport randomimport stringfrom colorama import Fore,Style,initimport platformdef print_arg(arg):"""打印参数:param arg::return:"""for ind, val in enumerate(arg):if ind == 0:print_color(Fore.YELLOW,r"------执⾏%s输⼊参数为--------"% val) else:print(val, end=",")def print_color(color, mes=""):"""获得系统平台windows终端需要设置init(wrap=True):param color::param mes::return:"""v_system = platform.system()if v_system != 'Windows':print(color+mes)else:# init(wrap=True)print(color+mes)# 获得系统参数v_arg = sys.argvinit(autoreset=True) # 初始化,并且设置颜⾊设置⾃动恢复# print_color(Fore.YELLOW+platform.system())if len(v_arg) != 4:# print(platform.system())print_arg(v_arg)print_color(Fore.RED,"---参数输⼊错误--")print_color(Fore.RED, "fileStrReplace.py ⽂件名旧字符串新字符串") else:f_name = v_arg[1].strip()old_str = v_arg[2].strip() # 旧字符new_str = v_arg[3].strip() # 替换的新字符f_new_name = "%s.new" % f_namereplace_count = 0 # 字符替换次数if not os.path.exists(f_name):print_color(Fore.YELLOW, "%s⽂件不存在" % f_name)f_new = open(f_new_name, 'w')f = open(f_name, "r",)for line in f: # 读取⼤⽂件if old_str in line:new_line = line.replace(old_str, new_str) # 字符替换replace_count += 1else:new_line = linef_new.write(new_line) # 内容写新⽂件f.close()f_new.close()if replace_count == 0:print_color(Fore.YELLOW,"字符%s不存在" % (old_str))else:bak_f = f_name + ''.join(random.sample(string.digits, 6))os.rename(f_name, bak_f) # 备份旧⽂件os.rename(f_new_name, f_name) # 把新⽂件名字改成原⽂件的名字,就把之前的覆盖掉了print_color(Fore.GREEN, "⽂件替换成功,[字符%s替换%s]共%s次,源⽂件备份[%s]" % (old_str,new_str, replace_count,bak_f)) # print_color(Style.RESET_ALL) # 还原默认颜⾊。

python常⽤函数及模块原⽂来源于博客园和CSDN1.计算函数abs()--取绝对值max()--取序列最⼤值,包括列表、元组min()--取序列最⼩值len()--取长度divmod(a,b)---取a//b除数整数以及余数,成为⼀个元组pow(x,y)--取x的Y次幂pow(x,y,z)先x的Y次幂,再对Z取余round()--修改精度,如果没有,默认取0位range()快速⽣成⼀个列表2.其他函数callable()--返回是否可调⽤返回true或falseisinstance(a,type)---判断前⾯的是否是后⾯的这种类型,返回true或falsecmp(a,b)---判断ab是否相等,相等返回0,A<B返回-1,A>B返回1range()--快速⽣成⼀个列表,类型为listxrange()---快速⽣成⼀个列表,类型为xrange3.类型转换函数type()int()long()float()complex()--转换成负数hex()--转换成⼗六进制oct()--转换成⼋进制chr()--参数0-252,返回当前的ASCII码ord()--参数ASCII码,返回对应的⼗进制整数4.string函数str.capitalize()--对字符串⾸字母⼤写str.replace(a.b)---对字符串a改为bstr.split()---对字符串进⾏分割,第⼀个参数是分隔符,后⾯参数是分割⼏次。
string函数导⼊使⽤5.序列函数filter()--筛选返回为true返回成序列lambda--定义函数zip()---对多个列表进⾏压缩组合成⼀个新列表,但是如果多个列表的元素个数不同,组合的结果按最少元素的进⾏组合map--对多个列表进⾏压缩组合成⼀个新列表,但是如果多个列表的元素个数不同,结果是将所有的元素取出来,缺少的以None代替。
如果是None,直接组合,如果是函数,可以按函数进⾏组合reduce()--对每个元素先前两个执⾏函数,然后结果和后⼀个元素进⾏函数操作,如阶乘,阶加----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------urlencode与urldecode当url中包含中⽂或者参数包含中⽂,需要对中⽂或者特殊字符(/、&)做编码转换。

Python有许多内建模块,它们提供了各种功能,以帮助您在编程时更有效地完成任务。
以下是一些常用的内建模块以及它们的使用方法:1. `math`:提供了一组数学函数和常数。
例如,`(x)` 返回 x 的平方根,`` 是圆周率π。
2. `os`:提供了与操作系统交互的功能。
例如,`(path)` 返回指定路径下的文件和目录名列表。
3. `sys`:提供对 Python 解释器使用或维护的一些变量的访问。
例如,`` 是命令行参数列表。
4. `datetime`:用于处理日期和时间。
例如,`()` 返回当前的日期和时间。
5. `json`:用于处理 JSON 数据。
例如,`(s)` 将 JSON 字符串 s 解析为Python 对象,`(obj)` 将 Python 对象 obj 编码为 JSON 字符串。
6. `random`:生成随机数。
例如,`(a, b)` 返回一个在 a 和 b 之间(包括 a 和 b)的随机整数。
7. `re`:用于正则表达式匹配。
例如,`(pattern, string)` 尝试从string 的开始位置匹配 pattern。
8. `collections`:提供了一些额外的数据类型,如Counter、defaultdict、OrderedDict等。
9. `itertools`:提供了用于高效循环的函数。
10. `functools`:提供了高阶函数和其他功能。
这只是 Python 内建模块的一小部分,还有许多其他模块(如 `zipfile`、`subprocess`、`shutil`、`argparse` 等)可以用于完成各种任务。
使用这些模块可以大大提高 Python 代码的效率和可读性。
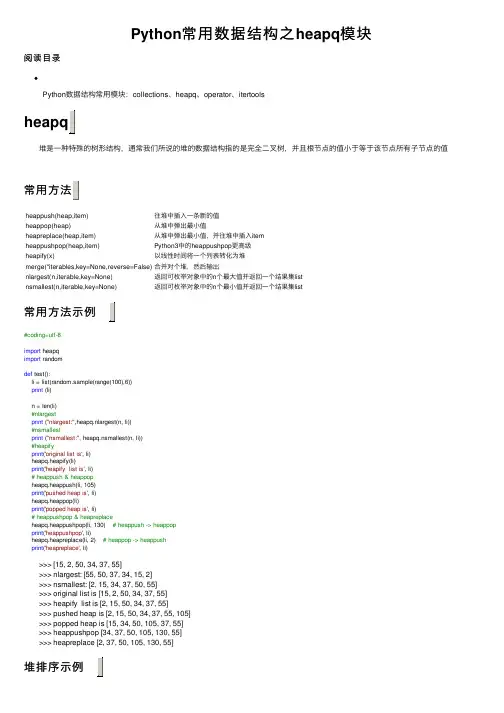
Python常⽤数据结构之heapq模块阅读⽬录Python数据结构常⽤模块:collections、heapq、operator、itertools 堆是⼀种特殊的树形结构,通常我们所说的堆的数据结构指的是完全⼆叉树,并且根节点的值⼩于等于该节点所有⼦节点的值 heappush(heap,item)往堆中插⼊⼀条新的值heappop(heap)从堆中弹出最⼩值heapreplace(heap,item)从堆中弹出最⼩值,并往堆中插⼊itemheappushpop(heap,item)Python3中的heappushpop更⾼级heapify(x)以线性时间将⼀个列表转化为堆merge(*iterables,key=None,reverse=False)合并对个堆,然后输出nlargest(n,iterable,key=None)返回可枚举对象中的n个最⼤值并返回⼀个结果集listnsmallest(n,iterable,key=None)返回可枚举对象中的n个最⼩值并返回⼀个结果集list常⽤⽅法⽰例 #coding=utf-8import heapqimport randomdef test():li = list(random.sample(range(100),6))print (li)n = len(li)#nlargestprint ("nlargest:",heapq.nlargest(n, li))#nsmallestprint ("nsmallest:", heapq.nsmallest(n, li))#heapifyprint('original list is', li)heapq.heapify(li)print('heapify list is', li)# heappush & heappopheapq.heappush(li, 105)print('pushed heap is', li)heapq.heappop(li)print('popped heap is', li)# heappushpop & heapreplaceheapq.heappushpop(li, 130) # heappush -> heappopprint('heappushpop', li)heapq.heapreplace(li, 2) # heappop -> heappushprint('heapreplace', li) >>> [15, 2, 50, 34, 37, 55] >>> nlargest: [55, 50, 37, 34, 15, 2] >>> nsmallest: [2, 15, 34, 37, 50, 55] >>> original list is [15, 2, 50, 34, 37, 55] >>> heapify list is [2, 15, 50, 34, 37, 55] >>> pushed heap is [2, 15, 50, 34, 37, 55, 105] >>> popped heap is [15, 34, 50, 105, 37, 55] >>> heappushpop [34, 37, 50, 105, 130, 55] >>> heapreplace [2, 37, 50, 105, 130, 55]堆排序⽰例 heapq模块中有⼏张⽅法进⾏排序: ⽅法⼀:#coding=utf-8import heapqdef heapsort(iterable):heap = []for i in iterable:heapq.heappush(heap, i)return [heapq.heappop(heap) for j in range(len(heap))]if__name__ == "__main__":li = [30,40,60,10,20,50]print(heapsort(li)) >>>> [10, 20, 30, 40, 50, 60] ⽅法⼆(使⽤nlargest或nsmallest):li = [30,40,60,10,20,50]#nlargestn = len(li)print ("nlargest:",heapq.nlargest(n, li))#nsmallestprint ("nsmallest:", heapq.nsmallest(n, li)) >>> nlargest: [60, 50, 40, 30, 20, 10] >>> nsmallest: [10, 20, 30, 40, 50, 60] ⽅法三(使⽤heapify):def heapsort(list):heapq.heapify(list)heap = []while(list):heap.append(heapq.heappop(list))li[:] = heapprint (li)if__name__ == "__main__":li = [30,40,60,10,20,50]heapsort(li) >>> [10, 20, 30, 40, 50, 60]堆在优先级队列中的应⽤ 需求:实现任务的添加,删除(相当于任务的执⾏),修改任务优先级pq = [] # list of entries arranged in a heapentry_finder = {} # mapping of tasks to entriesREMOVED = '<removed-task>'# placeholder for a removed taskcounter = itertools.count() # unique sequence countdef add_task(task, priority=0):'Add a new task or update the priority of an existing task'if task in entry_finder:remove_task(task)count = next(counter)entry = [priority, count, task]entry_finder[task] = entryheappush(pq, entry)def remove_task(task):'Mark an existing task as REMOVED. Raise KeyError if not found.'entry = entry_finder.pop(task)entry[-1] = REMOVEDdef pop_task():'Remove and return the lowest priority task. Raise KeyError if empty.'while pq:priority, count, task = heappop(pq)if task is not REMOVED:del entry_finder[task]return taskraise KeyError('pop from an empty priority queue') 。
python database模块详解Python database模块详解数据库是计算机系统中用来存储、管理和查询大量数据的工具。
Python作为一门强大的编程语言,提供了多种数据库模块来帮助开发者连接、操作和管理数据库。
本文将以中括号为主题,一步一步详细介绍Python数据库模块的使用。
一、为何使用数据库模块在开发过程中,我们经常需要与数据库进行交互,数据库模块提供了一种简单而直接的方式来连接和操作数据库。
使用数据库模块可以节约开发时间,提供更高效的数据存储和查询方式,同时也支持多种数据库类型。
二、Python常用的数据库模块1. SQLite3(轻量级数据库)SQLite3是一种嵌入式数据库引擎,它不需要独立的服务器进程,以库的形式被链接到Python程序中。
Python内置了SQLite3模块,可以直接使用。
2. MySQL(开源关系型数据库)MySQL是一种关系型数据库,被广泛应用于Web应用程序开发。
Python提供了多个MySQL驱动模块,如mysql-connector-python、pymysql等。
3. PostgreSQL(高级开源关系型数据库)PostgreSQL是一种功能强大的开源关系型数据库,具有良好的性能和可扩展性。
Python提供了多个PostgreSQL驱动模块,如psycopg2、PyGreSQL等。
4. Oracle(企业级关系型数据库)Oracle是一种功能强大的企业级关系型数据库,广泛应用于企业系统中。
Python 提供了cx_Oracle模块,用于连接和操作Oracle数据库。
5. NoSQL数据库除了传统的关系型数据库外,Python还支持多种NoSQL数据库,如MongoDB、Redis等。
对于这些数据库,可以使用相应的Python模块进行开发。
三、使用数据库模块的基本步骤无论使用哪种数据库模块,一般的连接和操作步骤都类似。
下面以SQLite3为例来介绍基本的步骤。
python标准库函数
Python标准库函数是Python内置的函数库,它包含了大量的标准库模块和函数,可以被直接调用和使用。
以下是Python标准库函数的一些常用模块和函数:
1. os模块:提供与操作系统交互的函数,如文件和目录操作等。
2. sys模块:提供与Python解释器交互的函数,如获取命令行参数和退出程序等。
3. re模块:提供正则表达式支持的函数,用于字符串的匹配、搜索和替换等操作。
4. time模块:提供与时间相关的函数,如获取当前时间、日期格式化和时间延迟等。
5. datetime模块:提供与日期和时间操作相关的函数,如获取当前日期、计算时间差和日期转换等。
6. math模块:提供数学运算的函数,包括三角函数、指数函数等。
7. random模块:提供随机数生成相关的函数,如生成随机数、洗牌和抽样等。
8. hashlib模块:提供加密哈希函数,如MD5和SHA1等。
9. json模块:提供JSON(JavaScript Object Notation)编解码器,用于序列化和反序列化Python对象和JSON字符串之间的相互转换。
以上是Python标准库函数的一些常用模块和函数,你可以在编程中根据需要选择调用。
Python常用模块大全(总结)Python是一种强大且广泛使用的编程语言,它拥有许多内置的模块和标准库,同时也有众多的第三方模块可用于各种不同的用途。
在本文中,我们将介绍一些常用的Python模块,以帮助您更好地了解Python的功能和巩固您的编程知识。
1. sys模块:sys模块提供了一些与Python解释器相关的变量和函数,例如命令行参数、标准输入输出等。
2. os模块:os模块提供了一些与操作系统相关的功能,例如文件操作、目录操作等。
5. random模块:random模块提供了生成随机数的功能。
6. math模块:math模块提供了一些基本的数学函数和常量,例如三角函数、对数函数等。
7. re模块:re模块提供了正则表达式的功能,用于模式匹配和字符串处理。
8. json模块:json模块提供了处理JSON格式数据的功能,例如将对象转换为JSON格式、从JSON格式解析数据等。
9. csv模块:csv模块提供了处理CSV文件的功能,例如读取、写入CSV文件等。
11. requests模块:requests模块是一个HTTP库,用于发送HTTP请求和处理响应。
12. hashlib模块:hashlib模块提供了一些加密算法,例如MD5、SHA1等。
13. sqlite3模块:sqlite3模块提供了一个轻量级的数据库引擎,用于处理SQLite数据库。
14. threading模块:threading模块提供了多线程编程的功能,例如创建线程、线程同步等。
15. multiprocessing模块:multiprocessing模块提供了多进程编程的功能,例如创建进程、进程间通信等。
16. subprocess模块:subprocess模块提供了创建和管理子进程的功能。
17. pickle模块:pickle模块提供了将对象序列化和反序列化的功能,用于对象的持久化存储和传输。
18. collections模块:collections模块提供了一些有用的数据结构,例如defaultdict、Counter等。
python标准库有哪些Python标准库是Python编程语言的核心部分,它包含了大量的模块和函数,可以帮助开发者完成各种任务,从文件操作到网络编程,从数据处理到图形界面开发。
在这篇文档中,我将为大家介绍Python标准库中一些常用的模块和函数,希望能够帮助大家更好地了解和使用Python标准库。
1. os 模块。
os 模块提供了许多与操作系统交互的函数,可以实现文件和目录的创建、删除、复制、重命名等操作,以及获取系统信息、执行系统命令等功能。
比如,可以使用os 模块中的 os.listdir() 函数来列出指定目录中的所有文件和子目录。
2. sys 模块。
sys 模块提供了与 Python 解释器交互的函数和变量,可以用来控制 Python 解释器的行为,比如获取命令行参数、设置路径、退出程序等。
sys 模块中的 sys.argv变量可以获取命令行参数,sys.exit() 函数可以退出程序并返回指定的状态码。
3. re 模块。
re 模块是Python 中用于处理正则表达式的模块,可以用来进行字符串的匹配、查找、替换等操作。
通过 re 模块,我们可以使用正则表达式来处理复杂的字符串操作,比如匹配邮箱、手机号码等。
4. datetime 模块。
datetime 模块提供了处理日期和时间的函数和类,可以用来获取当前时间、格式化时间、进行时间运算等。
比如,可以使用 datetime 模块中的 datetime.now() 函数来获取当前时间,datetime.timedelta() 类可以进行时间的加减运算。
5. random 模块。
random 模块用于生成随机数,可以用来进行随机数的生成、洗牌、抽样等操作。
通过 random 模块,我们可以实现随机数的生成,比如生成指定范围内的随机整数、随机选择列表中的元素等。
6. math 模块。
math 模块提供了数学运算的函数和常量,可以用来进行数学运算、取整、取余等操作。
Python的标准库有哪些Python的标准库是Python语言内置的一组模块和包,它们提供了各种各样的功能,包括文件操作、网络通信、数据处理、图形界面等。
使用标准库可以让开发者更加高效地编写Python程序,因为这些功能已经被封装好了,无需重复造轮子。
下面我们来看一下Python的标准库中都包含哪些模块和功能。
1. os模块,os模块提供了与操作系统交互的功能,可以进行文件和目录的操作,获取系统信息等。
比如可以使用os模块来创建、删除、移动文件和目录,获取当前工作目录,执行系统命令等。
2. re模块,re模块是Python中的正则表达式模块,用于处理字符串匹配和搜索。
通过re模块,可以进行字符串的模式匹配、替换、分割等操作,非常适合处理文本数据。
3. datetime模块,datetime模块提供了日期和时间的处理功能,可以进行日期的计算、格式化输出、时区转换等操作。
使用datetime模块可以方便地处理时间相关的业务逻辑。
4. math模块,math模块提供了数学运算相关的函数,包括常见的数学运算、三角函数、对数函数、幂函数等。
使用math模块可以进行数学计算,处理复杂的数学问题。
5. random模块,random模块用于生成随机数,包括整数、浮点数、随机选择等功能。
通过random模块可以实现随机数的生成和使用,用于模拟随机事件或者进行随机抽样。
6. urllib模块,urllib模块是Python中用于访问网络资源的模块,可以进行HTTP请求、下载文件、处理URL等操作。
通过urllib模块可以方便地与网络进行交互,获取网络资源。
7. json模块,json模块用于处理JSON格式的数据,可以进行JSON数据的解析、生成、格式化等操作。
JSON是一种常用的数据交换格式,使用json模块可以方便地处理JSON数据。
8. collections模块,collections模块提供了一些特殊的容器数据类型,如字典、列表、集合等的扩展。
python标准库有哪些Python标准库是Python编程语言的核心部分,它包含了大量的模块和功能,可以帮助开发者快速地实现各种功能。
本文将介绍Python标准库中一些常用的模块和功能,希望可以帮助大家更好地了解和应用Python标准库。
一、os模块。
os模块提供了丰富的方法来处理文件和目录,可以实现文件的创建、删除、重命名、文件属性的获取等操作。
同时,os模块还提供了一些与操作系统相关的功能,比如获取当前工作目录、改变工作目录、执行系统命令等。
使用os模块可以方便地进行文件和目录的管理,是Python编程中常用的模块之一。
二、sys模块。
sys模块提供了与Python解释器和系统交互的功能,可以获取Python解释器的信息、命令行参数、标准输入输出等。
通过sys模块,可以实现对Python解释器的控制和管理,比如修改模块搜索路径、退出Python解释器等。
sys模块在一些高级的应用场景中非常有用,可以帮助开发者更好地理解和控制Python解释器的行为。
三、re模块。
re模块是Python中用于处理正则表达式的模块,可以实现对字符串的模式匹配和替换。
正则表达式是一种强大的文本处理工具,可以用于字符串的匹配、查找、替换等操作。
re模块提供了丰富的方法来处理正则表达式,可以帮助开发者更好地利用正则表达式来处理文本数据。
四、datetime模块。
datetime模块提供了日期和时间的处理功能,可以实现日期时间的计算、格式化、解析等操作。
通过datetime模块,可以方便地处理日期时间相关的问题,比如计算日期之间的差值、格式化日期时间字符串、解析日期时间字符串等。
datetime模块在很多应用中都有广泛的应用,可以帮助开发者更好地处理日期时间相关的需求。
五、random模块。
random模块提供了随机数生成的功能,可以实现随机数的生成、序列的随机化、随机选择等操作。
通过random模块,可以方便地实现随机数相关的功能,比如生成随机数、打乱序列、随机选择元素等。
python中os模块中文帮助文档文章分类:Python编程python中os模块中文帮助文档翻译者:butalnd 翻译于2010.1.7——2010.1.8,个人博客:/ 注此模块中关于unix中的函数大部分都被略过,翻译主要针对WINDOWS,翻译速度很快,其中很多不足之处请多多包涵。
这个模块提供了一个轻便的方法使用要依赖操作系统的功能。
如何你只是想读或写文件,请使用open(),如果你想操作文件路径,请使用os.path模块,如果你想在命令行中,读入所有文件的所有行,请使用fileinput模块。
使用tempfile模块创建临时文件和文件夹,更高级的文件和文件夹处理,请使用shutil模块。
os.error内建OSError exception的别名。
导入依赖操作系统模块的名字。
下面是目前被注册的名字:'posix', 'nt', 'mac', 'os2', 'ce', 'java', 'riscos'.下面的function和data项是和当前的进程和用户有关os.environ一个mapping对象表示环境。
例如,environ['HOME'] ,表示的你自己home文件夹的路径(某些平台支持,windows不支持),它与C中的getenv("HOME")一致。
这个mapping对象在os模块第一次导入时被创建,一般在python启动时,作为site.py处理过程的一部分。
在这一次之后改变environment不影响os.environ,除非直接修改os.environ.注:putenv()不会直接改变os.environ,所以最好是修改os.environ注:在一些平台上,包括FreeBSD和Mac OS X,修改environ会导致内存泄露。
参考putenv()的系统文档。
如果没有提供putenv(),mapping的修改版本传递给合适的创建过程函数,将导致子过程使用一个修改的environment。
如果这个平台支持unsetenv()函数,你可以删除mapping中的项目。
当从os.environ使用pop()或clear()删除一个项目时,unsetenv()会自动被调用(版本2.6)。
os.chdir(path)os.fchdir(fd)os.getcwd()这些函数在Files和Directories中。
os.ctermid()返回进程控制终端的文件名。
在unix中有效,请查看相关文档.。
os.getegid()返回当前进程有效的group的id。
对应于当前进程的可执行文件的"set id "的bit位。
在unix 中有效,请查看相关文档.。
os.geteuid()返回当前进程有效的user的id。
在unix中有效,请查看相关文档.。
os.getgid()返回当前进程当前group的id。
在unix中有效,请查看相关文档.。
os.getgroups()返回当前进程支持的groups的id列表。
在unix中有效,请查看相关文档.。
os.getlogin()返回进程控制终端登陆用户的名字。
在大多情况下它比使用environment变量LOGNAME 来得到用户名,或使用pwd.getpwuid(os.getuid())[0] 得到当前有效用户id的登陆名更为有效。
在unix中有效,请查看相关文档.。
os.getpgid(pid)返回pid进程的group id.如果pid为0,返回当前进程的group id。
在unix中有效,请查看相关文档.。
os.getpgrp()返回当前进程组的id.在unix中有效,请查看相关文档.。
os.getpid()返回当前进程的id.在unix,Windows中有效。
os.getppid()返回当前父进程的id.在unix中有效,请查看相关文档.。
os.getuid()返回当前当前进程用户的id.在unix中有效,请查看相关文档.。
os.getenv(varname[, value])返回environment变量varname的值,如果value不存在,默认为None.在大多版本的unix,Windows中有效。
os.putenv(varname, value)设置varname环境变量为value值。
此改变影响以os.system(), popen() 或fork()和execv()启动的子进程。
在大多版本的unix,Windows中有效。
当支持putenv()时,在os.environ分配项目时,自动调用合适的putenv()。
然而,调用putenv() 不会更新os.environ,所以直接设置os.environ的项。
os.setegid(egid)设置当前进程有效组的id.在unix中有效,请查看相关文档.。
os.seteuid(euid)设置当前进程有效用户的id.在unix中有效,请查看相关文档.。
os.setgid(gid)设置当前进程组的id.在unix中有效,请查看相关文档.。
os.setgroups(groups)设置当前进程支持的groups id列表。
groups必须是个列表,每个元素必须是个整数,这个操作只对超级用户有效,在unix中有效,请查看相关文档.。
os.setpgrp()调用system的setpgrp()或setpgrp(0, 0)() ,依赖于使用的是哪个版本的system. 请查看Unix 手册. 在unix中有效,请查看相关文档.。
os.setpgid(pid, pgrp)调用system的setpgid()设置pid进程group的id为pgrp.请查看Unix手册. 在unix中有效,请查看相关文档.。
os.setreuid(ruid, euid)设置当前process当前和有效的用户id. 在unix中有效,请查看相关文档.。
os.setregid(rgid, egid)设置当前process当前和有效的组id. 在unix中有效,请查看相关文档.。
os.getsid(pid)调用system的getsid(). 请查看Unix手册. 在unix中有效,请查看相关文档.。
os.setsid()调用system的setsid().请查看Unix手册. 在unix中有效,请查看相关文档.。
os.setuid(uid)设置当前user id. 在unix中有效,请查看相关文档.。
os.strerror(code)返回程序中错误code的错误信息。
在某些平台上,当给一个未知的code,strerror()返回NULL,将抛出ValueError。
在unix,Windows中有效。
os.umask(mask)设置当前权限掩码,同时返回先前的权限掩码。
在unix,Windows中有效。
os.fdopen(fd[, mode[, bufsize]])返回一个文件描述符号为fd的打开的文件对象。
mode和bufsize参数,和内建的open()函数是同一个意思。
在unix,Windows中有效。
mode必须以'r', 'w',或者'a'开头, 否则抛出ValueError.以'a'开头的mode, 文件描述符中O_APPEND位已设置.os.popen(command[, mode[, bufsize]])给或从一个command打开一个管理。
返回一个打开的连接到管道文件对象,文件对象可以读或写,在于模式是'r'(默认) 或'w',bufsize参数,和内建的open()函数是同一个意思。
command返回的状态(在wait()函数中编码) 和调用文件对象的close()返回值一样, 除非返回值是0(无错误终止), 返回None . 在unix,Windows中有效。
在2.6版本中已抛弃. 使用subprocess模块.os.tmpfile()返回一个打开的模式为(w+b)的文件对象.这文件对象没有文件夹入口,没有文件描述符,将会自动删除. 在unix,Windows中有效。
从version 2.6起: 所有的popen*()函数已抛弃. 使用subprocess模块.os.popen2(cmd[, mode[, bufsize]])os.popen3(cmd[, mode[, bufsize]])os.popen4(cmd[, mode[, bufsize]])16.1.3. 文件描述符操作这些函数操作使用文件描述符引用的I/O stream。
文件描述符是与当前进程打开的文件相对应的一些小整数. 例如标准输入的通常文件描述符中0, 标准输出是1,标准错误是2. 进程打开的更多文件将被分配为3, 4, 5,等. 这“文件描述符”有一点迷惑性;在Unix平台上, socket和pipe 通常也使用文件描述符引用.os.close(fd)关闭文件描述符fd. 在unix,Windows中有效。
这函数是为低层的I/O服务的,应用在os.open()或pipe()返回的文件描述符上。
关闭一个由内建函数open()或popen()或fdopen()打开的文件对象,使用close()方法。
os.closerange(fd_low, fd_high)关闭从fd_low(包含)到fd_high(不包含)所有的文件描述符,忽略错误。
在unix,Windows 中有效。
等同于:for fd in xrange(fd_low, fd_high):try:os.close(fd)except OSError:passos.dup(fd)返回文件描述符fd的cope. 在unix,Windows中有效。
os.dup2(fd, fd2)复制文件描述符fd到fd2, 如果有需要首先关闭fd2. 在unix,Windows中有效。
os.fchmod(fd, mode)改变文件描述符为fd的文件’mode‘为mode. 查看chmod()文档中mode的值. 在unix中有效,请查看相关文档.。
version 2.6中新增.os.fchown(fd, uid, gid)改变文件描述符为fd的文件的所有者和group的id为uid和gid. 如果不想它们中的一个, 就设置为-1. 在unix中有效,请查看相关文档.。
version 2.6中新增.os.fdatasync(fd)强制将文件描述符为fd的文件写入硬盘. 不强制更新metadata. 在unix中有效,请查看相关文档.。