用回归模型预测木材剩余物
- 格式:doc
- 大小:192.50 KB
- 文档页数:3

货架寿命预测公式(一)货架寿命预测公式1. 货架寿命预测公式的重要性货架寿命预测是对货架寿命进行科学估算的过程,对于企业的库存管理和生产计划具有重要意义。
合理预测货架寿命可以减少库存损失和节省资源,提高资金利用率和客户满意度。
2. 常见的货架寿命预测公式在货架寿命预测中,常见的公式包括:•线性回归模型•指数平滑模型•ARIMA模型•支持向量回归模型线性回归模型线性回归模型是一种常见的预测模型,其公式为:Y = β0 + β1X1 + β2X2 + ... + βnXn + ε其中,Y表示货架寿命,X1、X2、…、Xn表示影响货架寿命的各种因素,β0、β1、β2、…、βn表示线性回归系数,ε表示误差项。
例子:假设我们要预测一个货架的寿命,我们可以考虑以下因素:负载重量、使用时间、环境湿度等。
我们可以收集不同货架的这些数据,并使用线性回归模型拟合,进而预测该货架的寿命。
指数平滑模型指数平滑模型是一种基于历史数据加权平均的预测模型,其公式为:Ft+1 = αYt + (1-α)Ft其中,Ft+1表示第t+1个时期的预测值,Yt表示第t个时期的实际值,Ft表示第t个时期的预测值,α为平滑系数。
例子:假设我们有一系列货架的寿命数据,我们可以使用指数平滑模型预测下一个时间段各货架的寿命情况。
通过调整平滑系数α的大小,可以控制历史数据的权重,进而影响预测结果。
ARIMA模型ARIMA模型是一种常用于时间序列预测的模型,其公式为:Yt = c + ϕ1Yt-1 + ϕ2Yt-2 + ... + ϕpYt-p + εt - θ1εt-1 - θ2εt-2 - ... - θqεt-q其中,Yt表示第t个时期的实际值,c为常数,ϕ1、ϕ2、…、ϕp为自回归系数,εt为误差项,θ1、θ2、…、θq为移动平均系数。
例子:我们收集了某货架每日销售量的时间序列数据,我们可以使用ARIMA模型来预测未来一段时间内货架的寿命。



长白山主要树种直径生长的多元回归预测模型:以云杉为例刘洋;亢新刚;郭艳荣;高北延;冯启祥【摘要】A total of 949 trees from 18 clear-cut stands and 78 standard trees of Picea koraiensis in Changbai Mountains were selected to establish a multiple regression prediction model for diameter growth of dominant tree species. In the course of model building, the potential increment of tree diameter was determined to build an equation for diameter growth of open-grown trees. Then three competition indexs were applied to express modified function as a quantitative index to measure mean site quality, stand density, and distances to the nearest neighboring trees in order to correct the potential increment of tree diameter. The data were analyzed with SPSS software. The functions with the highest correlation coefficient and lowest surplus sum of squares were chosen as the realistic diameter growth model. The model could reasonably predict the diameter size of the dominant tree species and diameter structure of the future stand, which has a great significance for mastering the stand dynamics and estimating stand growth condition. In addition, the fitting degree was checked with 432 trees of the analytic trees form 8 clear-cut stands and 23 standard trees of P. Koraiensis which did not participate model building. It is found that the practical application error of the regression model is small, and the model can achieve the better fitting effect and forecast precision.%选取长白山地区18块皆伐标准地的949株云杉解析木和78株云杉标准木,建立长白山主要树种直径生长的多元回归预测模型.在生长模型中,首先确定林木直径的潜在生长量,建立疏开木的直径潜在生长方程,然后用反映立地质量、林分密度、对象木与周围相邻木最近距离3个竞争指数所表示的修正函数对直径潜在生长函数进行修正.采用SPSS软件对参数进行拟合,依据相关系数最大,剩余平方和最小得到直径的实际生长模型.该模型可以合理预测长白山地区主要树种一定时期内未来直径大小和林分的直径结构,这对把握林分动态、预估林分生长状态有极其重要的意义.另外,用未参加建模的8块皆伐标准地的432株云杉解析木和23株云杉标准木,对直径生长的多元回归预测模型的拟合度进行检验,结果显示拟合效果很好.【期刊名称】《东北林业大学学报》【年(卷),期】2012(040)002【总页数】4页(P1-4)【关键词】直径生长;多元回归预测模型;天然异龄林;长白山【作者】刘洋;亢新刚;郭艳荣;高北延;冯启祥【作者单位】省部共建森林培育与保护教育部重点实验室(北京林业大学)北京100083;省部共建森林培育与保护教育部重点实验室(北京林业大学)北京 100083;北京林业大学;吉林省汪清林业局;吉林省汪清林业局【正文语种】中文【中图分类】S758.5林分内各种大小直径的树木的分配状态,直接影响树木的树高、干形、材积、材种及树冠等因子的变化;林木直径可以被快速、方便且准确地测量,同时它是许多森林经营技术及测树制表技术理论的依据[1]。


回归模型的估计方法及在林业中的应用研究的开题报告一、选题背景和意义在林业科学中,建立回归模型是一个重要的研究领域。
回归模型是通过建立某些变量之间的关系,来预测或者解释一个变量的变化。
在林业科学中,回归模型可以用来预测树木的生长情况,森林病理学的研究、森林火灾预测等。
回归模型估计方法是林业研究中的重点之一。
回归模型估计方法包括最小二乘法、广义线性模型、岭回归等。
这些方法用于回归模型的建立和参数估计,是林业研究中不可缺少的一部分。
二、研究目的本研究的目的是探讨回归模型估计方法及其在林业中的应用。
具体目标如下:1. 综述回归模型估计方法的基本原理和主要方法;2. 探究回归模型在林业中的应用领域;3. 运用回归模型分析森林生态系统数据,探讨不同估计方法的优劣;4. 提出可行的林业回归模型估计方法。
三、研究内容本研究的主要内容包括以下几个方面:1. 回归模型估计方法的基本原理和主要方法:综述回归模型和回归分析的基本原理;介绍回归模型估计方法,如最小二乘法、广义线性模型、岭回归等;分析估计方法的优点和局限性。
2. 回归模型在林业中的应用领域:综述回归模型在林业中的应用领域,如树木生长预测、森林火灾预测、生物量估算等。
3. 运用回归模型分析森林生态系统数据:通过收集森林生态系统数据,运用回归模型进行数据分析,探讨不同估计方法的优劣。
4. 提出可行的林业回归模型估计方法:根据数据分析结果和回归模型估计方法的特点,提出可行的林业回归模型估计方法。
四、研究方法和技术路线本研究采用文献综述、案例分析和数理统计方法。
具体流程如下:1. 文献综述:通过检索相关文献,综述回归模型估计方法的基本原理和主要方法,回归模型在林业中的应用领域等。
2. 案例分析:选择森林生态系统数据,运用回归模型分析数据,探讨不同估计方法的优劣。
3. 数理统计方法:运用数理统计方法对回归模型进行参数估计,分析数据,提出可行的林业回归模型估计方法。
五、预期结果和成果本研究的预期结果和成果如下:1. 回归模型估计方法的综述和分析:分析回归模型估计方法的基本原理和主要方法,回归模型在林业中的应用领域,探讨不同估计方法的优劣。



第三节 最小二乘估计量的性质三大性质:线性特性、无偏性和最小偏差性 一、 线性特性的含义线性特性是指参数估计值1ˆβ和2ˆβ分别是观测值t Y 或者是扰动项t μ的线性组合,或者叫线性函数,也可以称之为可以用t Y 或者是t μ来表示。
1、2ˆβ的线性特征证明 (1)由2ˆβ的计算公式可得: 222222()ˆt tttt ttttttt tt tt x y x Y x Y xxx xx x x x β--===⎛⎫== ⎪ ⎪⎝⎭∑∑∑∑∑∑∑∑∑∑∑Y Y Y Y需要指出的是,这里用到了因为t x 不全为零,可设2tt tx b x =∑,从而,t b 不全为零,故2ˆt t b β=∑Y 。
这说明2ˆβ是t Y 的线性组合。
(2)因为12t t t Y X ββμ=++,所以有()212122ˆt t t t t t t t t t t tb b X b b X b b βββμββμβμ==++=++=+∑∑∑∑∑∑Y这说明2ˆβ是t μ的线性组合。
需要指出的是,这里用到了220t t t t t x x b x x ===∑∑∑∑∑以及 ()2222222201t t tt t t tt ttttttttx x X x b X X x x x x X x X x x x x x⎛⎫+⎪== ⎪⎝⎭++==+=∑∑∑∑∑∑∑∑∑∑∑∑∑2、1ˆβ的线性特征证明 (1)因为12ˆˆY X ββ=-,所以有 ()121ˆˆ1t t t t tY X Y X b nXb n ββ=-=-⎛⎫=- ⎪⎝⎭∑∑∑Y Y这里,令1a Xb n=-,则有1ˆt a β=∑Y 这说明1ˆβ是t Y 的线性组合。
(2)因为回归模型为12t t t Y X ββμ=++,所以()11212ˆt t t t t t t t t ta a X a a X a βββμββμ==++=++∑∑∑∑∑Y因为111t t t a Xb X b nn⎛⎫=-=-=⎪⎝⎭∑∑∑∑。

林木生长模型及应用林木的生长对于森林资源的可持续利用和气候变化研究具有重要意义。
为了更好地理解和预测林木的生长过程,科学家们发展了各种生长模型。
本文将介绍林木生长模型的种类及其在林业管理和环境保护中的应用。
一、简介林木生长模型是一种数学模型,通过描述和预测林木的生长和发展过程,帮助我们理解林木生态系统的动态变化。
它可以基于林木的生物学特性、环境因素和管护措施等因素来推测林木的生长轨迹和生态系统的发展趋势。
二、林木生长模型的类型1. 统计模型统计模型是基于大量的观测数据和统计分析方法来建立的。
它通过分析林木的生长数据、环境因素和人为干扰等来研究林木的生长规律。
常见的统计模型有线性回归模型、非线性回归模型和广义线性模型等。
2. 生理生态模型生理生态模型是通过考虑林木的生理过程和生态环境的交互作用来建立的。
它基于对林木生理特性、光合作用、养分吸收和水分利用等过程的理解,预测林木的生长和发展。
典型的生理生态模型有森林动态模型、生理因子模型和光合作用模型等。
3. 过程模型过程模型是在理论基础上建立的,通过描述和模拟林木生长的各个过程来实现对整个林木生命周期的模拟。
它包括了从种子萌发到成年树的整个生长过程,并考虑了气候、土壤和种群动力学等因素。
过程模型能够提供详细的生长轨迹和动态变化,为林业管理和生态保护决策提供重要依据。
三、林木生长模型的应用1. 林业管理林木生长模型可以帮助林业管理者制定合理的抚育措施和采伐计划。
通过模拟林木的生长轨迹,可以预测不同管理干扰下林木的生长响应,并优化森林经营和资源利用。
此外,林木生长模型还可用于评估森林经营的效果和预测林木的稳定产量。
2. 气候变化研究气候变化对林木的生长和分布具有显著影响。
林木生长模型能够模拟林木对气候变化的响应,预测不同气候条件下林木的生长变化和物候期的转变。
这对于评估气候变化对生态系统的影响、制定气候适应策略和保护生态系统具有重要意义。
3. 生态环境保护通过模拟林木的生长过程和生态系统的发展,林木生长模型能够评估不同管护措施对生态环境的影响。
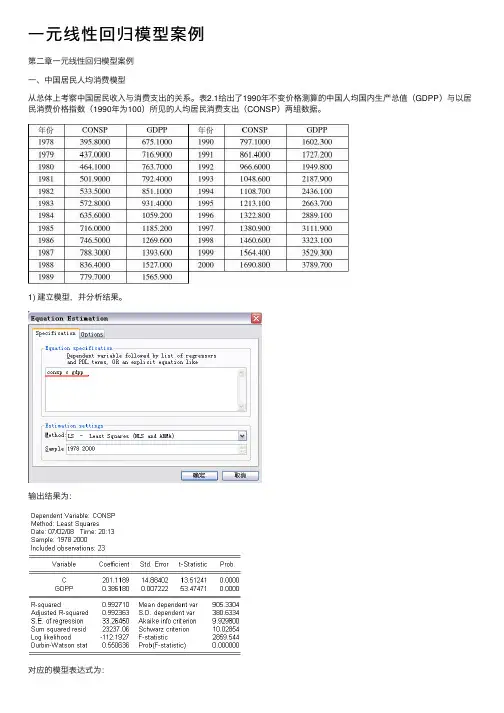
⼀元线性回归模型案例第⼆章⼀元线性回归模型案例⼀、中国居民⼈均消费模型从总体上考察中国居民收⼊与消费⽀出的关系。
表2.1给出了1990年不变价格测算的中国⼈均国内⽣产总值(GDPP)与以居民消费价格指数(1990年为100)所见的⼈均居民消费⽀出(CONSP)两组数据。
1) 建⽴模型,并分析结果。
输出结果为:对应的模型表达式为:201.1070.3862CONSP GDPP =+(13.51) (53.47) 20.9927,2859.23,0.55R F DW ===从回归估计的结果可以看出,拟合度较好,截距项和斜率项系数均通过了t 检验。
中国⼈均消费增加10000元,GDP 增加3862元。
⼆、线性回归模型估计表2.2给出⿊龙江省伊春林区1999年16个林业局的年⽊材采伐量和相应伐⽊剩余物数据。
利⽤该数据(1)画散点图;(2)进⾏OLS 回归;(3)预测。
表2.2 年剩余物y 和年⽊材采伐量x 数据(1)画散点图先输⼊横轴变量名,再输⼊纵轴变量名得散点图(2)OLS估计弹出⽅程设定对话框得到输出结果如图:由输出结果可以看出,对应的回归表达式为:0.76290.4043t t yx =-+ (-0.625) (12.11)20.9129,146.7166, 1.48R F DW === (3)x=20条件下模型的样本外预测⽅法⾸先修改⼯作⽂件范围将⼯作⽂件范围从1—16改为1—17确定后将⼯作⽂件的范围改为包括17个观测值,然后修改样本范围将样本范围从1—16改为1—17打开x的数据⽂件,利⽤Edit+/-给x的第17个观测值赋值为20将Forecast sample选择区把预测范围从1—17改为17—17,即只预测x=20时的y的值。
由上图可以知道,当x=20时,y的预测值是7.32,yf的分布标准差是2.145。
三、表2.3列出了中国1978—2000年的参政收⼊Y和国内⽣产总值GDP的统计资料。
单木生物量模型构建
单木生物量模型是一种用来估算森林中单棵树木的生物量的模型。
生物量是指树木的质量,包括树木的茎、枝、叶、根和果实等部分。
单木生物量模型可以用来估算森林的生物量总和,从而为森林资源管理、森林碳储存和其他应用提供依据。
构建单木生物量模型的过程如下:
选择样本:选择一定数量的树木作为样本,这些树木的生物量将用来构建模型。
样本的选取应该具有代表性,即能够代表整个森林中不同种类、不同年龄和不同位置的树木。
收集数据:对选定的样本进行测量,收集与生物量相关的数据。
这些数据可能包括树木的高度、胸径、分支结构、叶面积、果实重量等。
建立模型:根据收集的数据,使用统计学方法或机器学习方法建立单木生物量模型。
常见的方法包括线性回归、多项式回归和决策树等。
验证模型:使用已知生物量的树木来验证模型的准确性。
通常使用交叉验证的方法,将样本分成训练集和测试集,用训练集来构建模型,用测试集来验证模型的准确性。
如果模型的预测结果与已知生物量的误差较小,则表明模型较为准确。
应用模型:构建好的单木生物量模型可以用来估算森林中单棵树木的生物量。
可以使用模型对森林中的每棵树木进行预测,并统计出森林的生物量总和。
此外,单木生物
量模型还可以用来研究森林的生物量分布情况,以及影响森林生物量的因素等。
一种基于随机森林算法的探明储量预测新方法摘要传统的哈伯特模型、翁氏模型等预测方法主要采用一元多项式拟合储量增长趋势,无法解决多变量对储量预测的影响,使得预测结果与客观实际存在较大差距。
文章基于随机森林机器学习模型,建立了一种预测累计探明储量增长趋势的新方法。
该方法通过相关性分析找出影响探明储量增长的可量化指标,从而确定模型训练中的输入属性,以同类盆地油田年度累计探明储量为评价单元,建立随机森林机器学习样本数据集,通过调整决策树个数和单个决策树的最大特征数,对模型进行优化训练,从而建立累计探明储量预测模型,成功解决了多因素叠加下储量非线性增长预测的难题。
该方法在东部断陷盆地油田年度累计探明储量预测中应用成效显著,预测模型拟合的准确率达到88.19%,具有巨大的推广应用价值。
关键词:机器学习;随机森林算法;储量增长趋势;东部断陷盆地;油田年度累计探明储量O引言储量是勘探工作的目标和导向,采用科学的方法预测储量增长趋势和合理确定储量指标对于油公司发展规划编制和勘探工作部署制定具有至关重要的意义。
传统的油气储量增长趋势的预测方法包括基于生命旋回的哈伯特模型、翁氏模型、逻辑斯谛模型、高斯模型等,以及基于概率论与蒙特卡洛统计模拟法的油田规模序列法”51,这些方法在国外广泛应用,国内油公司在学习、引进这些方法的同时,也在实际应用过程中建立了适合本地区储量增长特征的方法,例如对储量发现历史数据进行拟合的“帚状”预测模型以及针对勘探发现中储量“多峰”增长问题建立的多旋回哈伯特模型、多旋回高斯模型等51.现有的方法技术存在的主要问题包括:目前广泛应用的哈伯特模型、翁氏模型等预测的是盆地整个油气勘探生命旋回的资源量、最终探明储量,无法有效解决中短期储量增长预测的问题;现有的预测方法主要研究对象为单一盆地或凹陷,缺少对同种类型盆地的研究;目前的方法主要采用一元多项式拟合储量增长趋势,无法解决多变量对储量预测的影响,使得预测结果与客观实际存在较大差距。
统计学中的回归树模型统计学是一门研究数据收集、分析和解释的学科,而回归树模型是其中一种重要的方法。
回归树模型通过将数据集划分为不同的区域,每个区域内的数据具有相似的特征,从而建立了一棵树状结构。
本文将介绍回归树模型的基本原理、应用场景以及优缺点。
一、回归树模型的基本原理回归树模型的基本原理是通过将自变量空间划分为多个矩形区域,每个区域内的数据具有相似的特征。
在构建回归树时,首先选择一个自变量作为划分变量,并选择一个划分点将数据集分为两部分。
然后,对每个子集重复上述过程,直到满足某个停止准则为止。
最终,每个叶节点都对应一个区域,该区域内的数据通过叶节点上的平均值来预测。
回归树模型的构建过程可以用以下步骤总结:1. 选择一个自变量作为划分变量。
2. 选择一个划分点将数据集分为两部分。
3. 对每个子集重复上述过程,直到满足某个停止准则为止。
4. 每个叶节点对应一个区域,通过叶节点上的平均值来预测。
二、回归树模型的应用场景回归树模型在实际应用中有着广泛的应用场景。
以下是几个常见的应用场景:1. 房价预测:回归树模型可以通过房屋的各种特征(如面积、地理位置等)来预测房价。
通过构建回归树模型,可以将数据集划分为不同的区域,每个区域内的房屋具有相似的特征和价格水平。
2. 股票价格预测:回归树模型可以通过分析股票的历史数据(如交易量、市盈率等)来预测未来的股票价格。
通过构建回归树模型,可以将数据集划分为不同的区域,每个区域内的股票具有相似的特征和价格趋势。
3. 用户行为分析:回归树模型可以通过分析用户的行为数据(如点击量、购买量等)来预测用户的行为。
通过构建回归树模型,可以将数据集划分为不同的区域,每个区域内的用户具有相似的行为特征。
三、回归树模型的优缺点回归树模型作为一种常用的统计学方法,具有以下优点:1. 解释性强:回归树模型可以将数据集划分为不同的区域,每个区域内的数据具有相似的特征,从而更容易理解和解释模型的结果。
一元线性回归模型1.一元线性回归模型有一元线性回归模型(统计模型)如下,y t = 0 + 1 x t + u t上式表示变量y t 和x t之间的真实关系。
其中y t 称被解释变量(因变量),x t称解释变量(自变量),u t称随机误差项, 0称常数项, 1称回归系数(通常未知)。
上模型可以分为两部分。
(1)回归函数部分,E(y t) = 0 + 1 x t,(2)随机部分,u t。
图2.1 真实的回归直线这种模型可以赋予各种实际意义,收入与支出的关系;如脉搏与血压的关系;商品价格与供给量的关系;文件容量与保存时间的关系;林区木材采伐量与木材剩余物的关系;身高与体重的关系等。
以收入与支出的关系为例。
假设固定对一个家庭进行观察,随着收入水平的不同,与支出呈线性函数关系。
但实际上数据来自各个家庭,来自各个不同收入水平,使其他条件不变成为不可能,所以由数据得到的散点图不在一条直线上(不呈函数关系),而是散在直线周围,服从统计关系。
随机误差项u t中可能包括家庭人口数不同,消费习惯不同,不同地域的消费指数不同,不同家庭的外来收入不同等因素。
所以在经济问题上“控制其他因素不变”是不可能的。
回归模型的随机误差项中一般包括如下几项内容,(1)非重要解释变量的省略,(2)人的随机行为,(3)数学模型形式欠妥,(4)归并误差(粮食的归并)(5)测量误差等。
回归模型存在两个特点。
(1)建立在某些假定条件不变前提下抽象出来的回归函数不能百分之百地再现所研究的经济过程。
(2)也正是由于这些假定与抽象,才使我们能够透过复杂的经济现象,深刻认识到该经济过程的本质。
通常线性回归函数E(y t) = 0 + 1 x t是观察不到的,利用样本得到的只是对E(y t) = 0 + 1 x t 的估计,即对 0和 1的估计。
在对回归函数进行估计之前应该对随机误差项u t做出如下假定。
(1) u t 是一个随机变量,u t 的取值服从概率分布。
用回归模型预测木材剩余物
伊春林区位于黑龙江省东北部。
全区有森林面积218.9732万公顷,木材蓄积量为2.324602亿m3。
森林覆盖率为62.5%,是我国主要的木材工业基地之一。
1999年伊春林区木材采伐量为532万m3。
按此速度44年之后,1999年的蓄积量将被采伐一空。
所以目前亟待调整木材采伐规划与方式,保护森林生态环境。
为缓解森林资源危机,并解决部分职工就业问题,除了做好木材的深加工外,还要充分利用木材剩余物生产林业产品,如纸浆、纸袋、纸板等。
因此预测林区的年木材剩余物是安排木材剩余物加工生产的一个关键环节。
下面,请预测林区每年的木材剩余物:(注:显然引起木材剩余物变化的关键因素是年木材采伐量。
)给出伊春林区16个林业局1999年木材剩余物和年木材采伐量数据如表2.1。
表2.1 年剩余物y t和年木材采伐量x t数据
林业局
名年木材剩余物y t
(万m3)
年木材采伐量x t
(万m3)
乌伊岭26.13 61.4
东风23.49 48.3
新青21.97 51.8
红星11.53 35.9
五营7.18 17.8
上甘岭 6.80 17.0
友好18.43 55.0
翠峦11.69 32.7
乌马河 6.80 17.0
美溪9.69 27.3
大丰7.99 21.5
南岔12.15 35.5
带岭 6.80 17.0
朗乡17.20 50.0
桃山9.50 30.0
双丰 5.52 13.8
合计202.87 532.00
(1)做出散点图,根据图像判断建立一元线性回归方程是否合理?
(2)建立相应的回归方程,并解释斜率的经济意义。
(3)对所建立的回归方程进行检验(拟合情况、显著性、 1的置信区间)。
(4)假设乌伊岭林业局2000年计划采伐木材20万m3,求木材剩余物的点预测值和置信区间预测。
1.应用Eviews软件对年木材剩余物y和年木材采伐量x描散点图,结果如下
从以上结果可以看出,虽然不同的年木材采伐量和年木材剩余物之间存在差异,但平均来说,随着年木材采伐量的增加,年木材剩余物也在增加。
所以两个变量存在线性关系,可以进行线性回归。
2.运用Eviews 软件对y 和x 建立回归方程,结果如下:
由上图可得,年木材剩余物y 和年木材采伐量x 的线性方程为:
0.7629280.404280y x =-+
由方程可知:斜率为0.40428,表明年木材采伐量每增加1万平方米,年木材剩余物增加0.40428万平方米。
3.从上图可以看出:可决系数20.91289R =,方程拟合得较好,截距项与斜率项的t 检验均大于5%显著性水平下自由 为n-2=14的临界值()145.214025.0=t ,
通过了显著性检验,认为拟合的方程较好。
下面来计算1β的置信区间:
2
23722.26,58.05231,i i x e ==∑∑2ˆ2i e n σ=-∑=2.036319,1ˆβ=0.404280 则12
ˆi S x βσ=∑=0.033377,()145.214025.0=t
1β的置信区间是:11
ˆˆ1122
ˆˆ(,)t S t S ααββββ-⨯+⨯=(0.3326863,0.47587367) 4. 假设乌伊岭林业局2000年计划采伐木材20万m 3,由上述回归方程可预测该年的木材剩余物为:
Y = -0.762928 + 0.404280*20=7.322668
由于木材采伐量X 的均值与样本方差为
()25.33=x E ,()26.3722=x Var
在置信度为95%的情况下,该木材剩余物的预测区间为: ()() 4.5089127.32266775
26.372211625.3320161121605231.582.145127.322667752±=⎪⎪
⎭
⎫
⎝⎛⨯--++⨯-⨯±即(2.8138,11.8316)。