Tarena Oracle 课程 day02
- 格式:doc
- 大小:26.50 KB
- 文档页数:4



超详细oracle教程菜鸟入门手册1. 什么是Oracle数据库Oracle数据库是全球领先的关系型数据库管理系统之一,被广泛应用于数据存储、数据处理和数据分析领域。
Oracle数据库可以在多种操作系统上运行,包括Windows、Linux、UNIX等。
Oracle数据库提供了丰富的功能和工具,支持高并发、高可用、高安全的数据存储和处理。
2. Oracle数据库的安装## 2.1 下载Oracle数据库安装包在Oracle官网下载对应版本的Oracle数据库安装包,根据操作系统选择对应的版本。
## 2.2 安装Oracle数据库双击安装包,按照提示进行安装。
需要注意的是,在安装过程中需要设置管理员账号和密码,以及数据库实例名称等信息。
## 2.3 配置Oracle数据库安装完成后,需要进行一些配置工作,包括设置环境变量、创建监听器等。
具体步骤可以参考Oracle官方文档。
3. Oracle数据库的基本操作## 3.1 登录Oracle数据库使用SQL*Plus或其他数据库管理工具登录Oracle数据库,输入管理员账号和密码即可。
## 3.2 创建表使用CREATE TABLE语句创建表,指定表名、字段名、数据类型等信息。
## 3.3 插入数据使用INSERT INTO语句插入数据,指定表名和插入的数据内容。
## 3.4 查询数据使用SELECT语句查询数据,可以指定查询条件、排序方式等。
## 3.5 更新数据使用UPDATE语句更新数据,可以指定更新条件和更新的数据内容。
## 3.6 删除数据使用DELETE语句删除数据,可以指定删除条件。
4. Oracle数据库的高级功能## 4.1 数据库备份和恢复Oracle数据库支持多种备份和恢复方式,包括数据文件备份、在线备份、冷备份等。
在数据库出现故障或数据丢失的情况下,可以通过备份文件进行恢复。
## 4.2 数据库性能优化Oracle数据库提供了多种性能优化工具,包括AWR报告、SQL调优等。
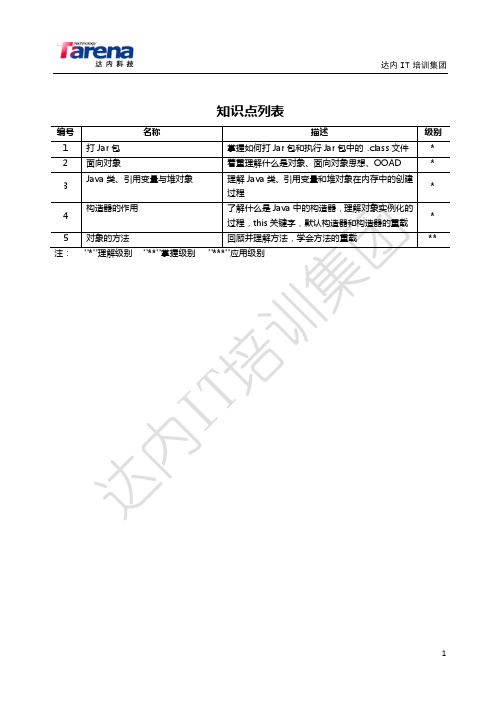
知识点列表编号名称描述级别1 打Jar包掌握如何打Jar包和执行Jar包中的 .class文件*2 面向对象着重理解什么是对象、面向对象思想、OOAD *3 Java类、引用变量与堆对象理解Java类、引用变量和堆对象在内存中的创建过程*4 构造器的作用了解什么是Java中的构造器,理解对象实例化的过程,this关键字,默认构造器和构造器的重载*5 对象的方法回顾并理解方法,学会方法的重载** 注:"*"理解级别"**"掌握级别"***"应用级别1.打Jar包*Jar包是Java中的压缩包格式,同zip格式一样,用来对.class文件统一管理,如下是在windows 系统和linux系统中不同的打包和执行.class程序的过程,如图所示:注:✓执行jar包中的.class文件有2种方法:java unix.day01.DoubleBallDemo 在系统配置的CLASSPATH找.class java -cp demo.jar unix.day01.DoubleBallDemo 在指定的jar包中找.class✓软件完成后,一般不给源代码,给用户的就是一系列的jar包2.面向对象(OO) *2.1.什么是Object(对象)Object(对象)相当于中文语义“东西”。
Object是指一个具体事物实例,比如飞机、狗、运气、哲学等看得见的,看不见得,有形的、无形的,具体的,抽象的都是对象,总之“一切皆Object”。
2.2.面向对象面向对象(Object Oriented),是指面向客观事物之间的关系。
人类日常的思维方式是面向对象的,自然界事物之间的关系是对象与对象之间的关系。
面向对象的定义:首先根据客户需求抽象出业务对象;然后对需求进行合理分层,构建相对独立的业务模块;之后设计业务逻辑,利用多态、继承、封装、抽象的编程思想,实现业务需求;最后通过整合各模块,达到高类聚、低耦合的效果,从而满足客户要求。


1.Oracle的使用1.1. SQLPLUS的命令初始化表的位置:set NLS_LANG=american_7ascii (设置编码才可以使用下面脚本)cd $ORACLE_HOME/rdbms cd demo summit2.sql*********************************我们目前使用的是oralce 9i 9201 版本select * from v$version;恢复练习表命令:sqlplus **/** @summit2.sql //shell要在这个文件的位置。
登陆oracle的命令:sqlplus 用户名/密码show user 显示当前登陆的身份.set pause onset pause off 分页显示.oracle中默认日期和字符是左对齐,数字是右对齐table or view does not exist ; 表或示图不存在edit 命令用于自动打开vi修改刚修执行过的sql的命令。
修改方法二:l 3 先定位到行 c /旧串/新串执行出错时,利用错误号来查错误:!oerr ora 942 (装完系统后会装一个oerr工具,用于通过错误号来查看错误的具体信息)想在sql中执行unix命令时,把所有的命令前加一个!就可以,或者host( 用于从sql从切换至unix环境中去)/*** 初次使用时注意 ****运行角本时的命令:先切换到unix环境下,cd $oracle_home cd sqlplus cd demo 下面有两个角本建表语句。
@demobld.sqlsqlplus nanjing/nanjing @demobid.sql 直接运行角本,后面跟当前目录或者是绝对路径保存刚才的sql语句:save 命令第二次保存时要替换之前的角本 save 文件名 replace把刚才保的sql重新放入 buffer中spool on 开启记录spool off 关闭记录spool 文件名此命令会把所有的操作存在某个文件中去常见缩写:nls national language support 国家语言支持1.2. SQL的结构|DDL 数据库定义|DML 数据库管理SQL――Commit rollback|DCL 数据库控制|grant+revoke 权限管理表分为:系统表(数据字典),用户表注:知道数据字典可以更便于使用数据库。
走进Oracle (2)1.Oracle简介 (4)2.Oracle安装 (5)3.Oracle客户端工具 (10)4.Oracle服务 (17)5.Oracle启动和关闭 (18)6.Oracle用户和权限 (19)7.本章总结 (22)8.本章练习 (23)SQL数据操作和查询 (26)1.SQL简介 (27)2.Oracle数据类型 (27)3.创建表和约束 (28)4.数据操纵语言(DML) (31)5.操作符 (36)6.高级查询 (37)7.本章总结 (45)8.本章练习 (46)子查询和常用函数 (49)1.子查询 (50)2.Oracle中的伪列 (52)3.Oracle函数 (55)4.本章总结 (64)5.本章练习 (65)表空间、数据库对象 (68)1.Oracle数据库对象 (69)2.同义词 (69)3.序列 (72)4.视图 (74)5.索引 (76)6.表空间 (78)7.本章总结 (82)8.本章练习 (83)PL/SQL程序设计 (86)1.PL/SQL简介 (87)2.PL/SQL块 (88)3.PL/SQL数据类型 (92)4.PL/SQL条件控制和循环控制 (94)5.PL/SQL中动态执行SQL语句 (104)6.PL/SQL的异常处理 (106)7.本章总结 (112)8.本章练习 (113)Oracle应用于.Net平台 (115)1.回顾 (116)2.使用连接Oracle (117)3.抽象工厂中加入Oracle (121)4.本章总结 (126)5.本章练习 (127)数据库导入导出 (129)1.Oracle导入导出 (130)2.EXP导出数据 (130)3.IMP导入 (133)4.常见问题 (134)第1章走进Oracle主要内容Oracle安装✓Oracle创建用户和角色✓客户端链接Oracle服务器1.Oracle简介在第一学期我们已经接触过关系型数据库SQL Server,对数据库、表、记录、表的增删改查操作等这些基本的概念已经了解。
oracle中文使用手册Oracle是一款功能强大的关系型数据库管理系统,广泛应用于企业数据管理和应用开发领域。
本手册将详细介绍Oracle数据库的基本概念、常用命令和操作方法,以帮助初学者快速上手和熟练使用Oracle。
1. Oracle简介Oracle是美国Oracle公司开发的一种关系型数据库管理系统。
它是目前企业级应用系统首选的数据库产品之一,被广泛应用于各个行业的数据管理和应用开发中。
Oracle具有可靠性高、性能优异、安全性强等特点,成为大型企业数据处理的首选。
2. 安装与配置在开始使用Oracle之前,首先需要进行安装和配置。
可以从Oracle官方网站下载安装程序,根据提示进行安装。
安装完成后,需要进行一些基本的配置,如创建数据库实例、设置监听器等。
详细的安装和配置过程可以参考Oracle官方提供的文档或手册。
3. 数据库连接与登录使用Oracle数据库前,需要先进行数据库连接和登录。
可以使用SQL*Plus命令行工具或Oracle SQL Developer等图形化界面工具来进行连接和登录。
在连接时需要提供数据库的主机名、端口号和SID等信息,以及合法的用户名和密码。
连接成功后,即可开始对数据库进行操作。
4. SQL基本操作SQL是结构化查询语言,用于在关系型数据库中进行数据的增删改查等操作。
下面介绍一些常用的SQL命令:- 创建表: 使用CREATE TABLE语句可以创建数据表,并指定表的字段、数据类型、约束等信息。
- 插入数据: 使用INSERT INTO语句可以向表中插入数据。
- 更新数据: 使用UPDATE语句可以更新表中的数据。
- 删除数据: 使用DELETE FROM语句可以删除表中的数据。
- 查询数据: 使用SELECT语句可以查询表中的数据。
5. 数据库事务和锁机制数据库事务是指对数据库进行的一系列操作,要么全部执行成功,要么全部不执行。
Oracle提供了事务管理机制,可以确保数据库的一致性和完整性。
Hello, and welcome to this online, self-paced lesson entitled “Introducing Oracle R Enterprise.” This session is part of an eight-lesson tutorial series on Oracle R Enterprise.My name is Brian Pottle. I will be your guide for the next 45 minutes of interactive lectures and review sessions on this lesson.“Introducing Oracle R Enterprise” is the first lesson of eight self-study sessions on Oracle R Enterprise.In this lesson, you’ll learn:•What R is, who uses it, and why they use it.•Next, we’ll examine several common user interfaces for R.•Finally, you’ll learn about Oracle’s strategy for supporting the R community. So, let’s start with the first topic: Using R: What, Who, and Why?R is a language and environment for statistical computing and graphics. This GNU Project is similar to the S language and environment, which was developed at Bell Laboratories (formerly AT&T, now Lucent Technologies) by John Chambers and colleagues. R can be considered a different implementation of S. There are some important differences, but much code written for S runs unaltered under R.R is an open-source language and environment that supports:•Statistical computing and data visualization•Data manipulations and transformations•And sophisticated graphical displaysWith over 2 million R users worldwide, R is increasingly being used as the statistical tool in the academic world. Many colleges and universities worldwide are using R today in their statistics classes. In addition, more and more corporate analysts are using R.R benefits from around 5000open-source packages, which can be thought of as a collection of related functions. This number grows continuously with new packages submissions from the R user community.Each package provides specialized functionality in such areas as bioinformatics and financial market analysis.In the slide, the list on the right shows “CRAN Task Views.” CRAN stands for the Comprehensive R Archive Network, which is a network of FTP and web servers that store identical, up-to-date versions of R code and documentation.The CRAN Task Views list areas of concentration for a set of packages. Each link contains information that is available on a wide range of topics.So, why do statisticians and data analysts use R?•As mentioned previously, R is a statistics language that is similar to SAS or SPSS.•R is a powerful and extensible environment, with a wide range of statistics and data visualization capabilities.-Powerful: Users can perform data analysis and visualization with a minimal amount of R code.-Extensible: Users can write their own R functions and packages that can be used locally, shared within their organizations, or shared with the broader R communitythrough CRAN.•It’s easy to install and use.•And it’s free and downloadable from the R Project website.Although it’s a powerful and effective statistical environment, R has limitations.First, R was conceived as a single-user tool that was not multithreaded. The client and server components are bundled together as a single executable, much like Excel.•R is limited by the memory and processing power of the machine on which it runs. •Also, R can’t automatically leverage the CPU capacity on a user’s multiprocessor laptop without special packages and programming.Second, R suffers from another scalability limitation that is associated with RAM.•R requires data that it operates on to be first loaded into memory.•In addition, R’s approach to passing data between function invocations results in data duplication. This “call by value” approach to parameter passing can use up memoryquickly.So inherently, R is really not designed for use with big data.Some users have provided packages to overcome some of the memory limitations, but the users must explicitly program with these packages.R provides a wealth of resources to help users, including:•Many R-related books that are available on the R project website•Many user groups and user conferences that are available to the R community •Online libraries of reusable code from the CRAN website•Documented R packages with sample data and codeNext, let’s examine several common user interfaces for R.First, let’s take a quick look at the interface that comes with open-source R by default, called the R Console.•This default open-source R graphical user interface (GUI) includes a command-line interface for running scripts or individual functions, as shown in the slide.•In addition, open-source R supports many third-party graphics packages.-In this example, we load a popular third-party graphics package named “ggplot2.”-Then, the graphics package is called from the R Console command line. The second qplot function call displays the graphic on the right.-Here, the qplot function is invoked on the mtchars data set, which comes with R. In the graph, we plot miles per gallon against weight, with the size of each dotindicating the number of cylinders.In addition to the default open-source R GUI, you can use a third-party integrated development environment (IDE), such as RStudio, which is shown in the slide.With RStudio:•You can use the upper-left pane to view R scripts and select portions of an R script for execution.•In the Console pane, you can execute R scripts or functions at the command line, in a similar fashion as the default R GUI.•You can execute selected portions of R scripts in the top window by clicking the Run button. With this method, selected lines are pasted into the Console pane and executed.•You can view graph results in the right pane. In this case, the Plots tab is selected.In this next view, the R script that we saw previously is displayed in the viewer window.•Here, the first portion of the script is selected. This code requests help on the gplot() function.•When the Run button is clicked, the selected code is pasted into the Console pane and then executed.•In the display pane, you can select (and switch between) different tabbed output views on the Files, Plots, Packages, and Help tabs. In this case, the Help tab is selected to display results from the R help command. In this final view, the last function in the R script is selected.•This same gplot() function was shown previously in the default R GUI.•The Run button is clicked and the code is executed. The Plots tab shows the current output. In fact, RStudio also lets you view previously generated plots.RStudio is only one of many third-party R IDEs.As shown in the table of this 2011 poll, RStudio is the second most commonly used interface, behind the built-in R console we looked at earlier. However, it’s often user preference that decides which IDE will be used.Data visualization helps convey information faster than most other means. The link shown in the slide is for the R Graph Gallery, where you can find a variety of graphic types for R.Here are a few examples of graphs in R. Of course, there are many others. Moving from left to right, and top to bottom, we show:• A box plot•Perspective graphs of mathematical surfaces•3-D scatter plots with points• A regression plane•Multivariate facet crafts•Smooth scatter plots•Venn diagrams•And even chromosome mappings from the bioconductor packageIn this final section of the lesson, you’ll learn about Oracle’s strategy for supporting the R community. This section includes the following topics:•Goals•Software term definitions•High- and mid-level architectural overviews•Software component features•R user-community definitionsScalability, performance, and production deployment are key requirements for the enterprise data analytics arena.•What may work fine on your laptop for thousands or even millions of rows, won’t scale to 100s of millions and billions of rows.•Similarly, performance may be adequate on smaller scale data, but will moving to “big data” allow you to keep up? The cost of moving data to a separate server can render an application unusable.•Finally, when you’ve finished your project in a lab environment, how easy is it to deploy that result into production?Each of these requirements are met by Oracle’s strategy for supporting the R community.Oracle’s goal for supporting open-source R is to deliver enterprise-level advanced analytics based on the R environment. The strategy is implemented through the release of the following Oracle technologies:•Oracle R Enterprise (ORE), which is part of the Oracle Advanced Analytics option for Oracle Database 12c and 11g, release 2. ORE contains a statistics engine, andprovides transparent access to database-resident data from R, as you will learn in this tutorial series.•Oracle R distribution, which supports configurations of open-source R on various platforms. In addition, Oracle contributes bug fixes and enhancements to open-source R.•ROracle, the open-source Oracle database interface for R.•Oracle R Advanced Analytics for Hadoop, or ORAAH, provides an R interface to an Oracle Hadoop cluster on the BDA ,and also to non-Oracle Hadoop clusters. It enables you to access and manipulate data in the Hadoop Distributed File System, in the Oracle Database, and on the file system.Now, let’s examine an architectural view of ORE.•The R workspace console may be the default R GUI or any of the third-party R GUIs.Users execute R scripts here.•Then, the ORE transparency layer intercepts functions that operate on database tables or views. It translates the request into SQL for execution in Oracle Database fortransformations and statistical computations. In Oracle Database, the statistics engine consists of native database functionality that leverages SQL and the various database management system (DBMS) packages, as well as enhancements that are specific to ORE.•Finally, the results can be leveraged by enterprise systems, such as Oracle Business Intelligence Enterprise Edition (OBIEE), or web services-based applications.This design results in:•No changes to the R user experience in the development environment•The ability to scale to large data sets in the production environment•And, the ability to embed results in operational systems, such as Oracle OBIEE DashboardsThis architectural view illustrates how ORE can work with Oracle R Advanced Analytics for Hadoop. ORAAH enables native R access to the Hadoop cluster for both: •MapReduce programming in R, and•Access to Hadoop Distributed File System (HDFS) data, in either the Big Data Appliance (as shown in the slide), or non-Oracle Hadoop clustersOracle Big Data Appliance has been mentioned a couple of time so far in this lesson. So, what is it? Oracle BDA:•Is an optimized solution for storing and integrating low-density data into Exadata.•Is a preintegrated configuration with 18 of Oracle's Sun servers that include InfiniBand and Ethernet connectivity to simplify implementation and management.•Has the Cloudera distribution, including Apache Hadoop to acquire and organize data, along with Oracle NoSQL Database Community Edition to acquire data.•Includes additional system software: Oracle Linux, Oracle Java Hotspot Virtual Machine, and an open-source distribution of R.Oracle Big Data Connectors is an option for BDA. It consists of:•Oracle Loader for Hadoop•Oracle Data Integrator Application Adapter for Hadoop•Oracle Direct Connector for HDFS•Oracle R Advanced Analytics for HadoopYou can use ORAAH to access data in Exadata, and perform R calculations on HDFS data by using scalable map-reduce methods.Now, let’s take a brief look at the components of Oracle R Enterprise. From a software perspective, ORE consists of R packages, database libraries, and SQL extensions.We’ll divide the features into three main groups: the Transparency Layer, the Statistics Engine, and SQL extensions.The Transparency Layer is a set of packages that map R data types to Oracle Database objects.•This feature automatically generates SQL for R expressions on mapped data types, enabling direct interaction with data in Oracle Database while using R languageconstructs.•Functionally, this mapping provides access to database tables from R as a type of data.frame: a base R data representation with rows and columns. ORE calls this an“ore.frame.”•Therefore, when you invoke an R function on an ore.frame, the R operation is sent to the database for execution as SQL.The Statistics Engine is a database library that supports a variety of statistical computations. This engine includes existing in-database advanced analytics and new features added specifically in ORE.SQL extensions enable in-database embedded R execution, which is particularly valuable for third-party R packages, or custom functions, that do not have equivalent in-databaseIf we look at ORE from the perspective of a collaborative execution model, it leverages three layers of computational engines.The first one is the client (or user) R engine, which resides on the desktop.•This R engine consists of the base R packages, the ORE packages, and any other R packages that the user may have installed.•At this level, the Transparency Layer intercepts R functions for in-database execution.•It also enables interactive display of graphical results, while flow control remains with the R environment.•From the client, users can submit entire R scripts for execution by Oracle Database, using embedded R execution.•And, although not explicitly depicted here, users can connect to a Hadoop Cluster by using Oracle R Connector for Hadoop.The second compute engine is Oracle Database.•This database allows scaling to large data sets.•R users are able to access tables, views, and external tables, as well as data that is accessible through database links.•The SQL generator through the Transparency Layer can automatically leverage database parallelism.•It can also leverage both new and existing in-database statistical and data mining capabilities.The third compute engine (or engines) are those spawned and managed by Oracle Database, and they execute on the database server machine.•These embedded R engines enable more efficient data transfer between the database and R.•Because these engines run on the database server, rather than on the client, they are likely to have greater memory capacity and compute power. Exadata is an example.•The embedded R execution enables parallel data transfer, returning rich XML or PNG image output, SQL access to R, and the ability to run parallel simulations.•The embedded R engines also enable use of 3rd party packages or custom functions that do not have in-database SQL equivalent functionality.•The engines also enable R users to write and test map-reduce scripts before rolling them out to a Hadoop cluster.•Finally, these engines enable “lights-out” execution of R scripts; that is, scheduling or triggering R script packages inside a SQL or PL/SQL query.The ORE target environment design provides a comprehensive, database-centric environment for end-to-end analytic processes in R, with immediate deployment to production environments. It provides many benefits, including:•Elimination of R client engine memory constraint•Execution of R scripts through the Oracle Database server machine for scalability and performance•Seamless integration of Oracle Database as the HPC environment for R scripts, providing data parallelism and resource management•The ability to operationalize entire R scripts in production applications•Scoring of R models in Oracle DatabaseR and ORE can receive data from many sources. In this figure, we depict the R engine running on the user’s laptop, as shown in the previous slide.Through a series of R packages, R itself is able to access data stored in both files, and in databases.In addition, ORE provides transparent access to data stored in the local Oracle Database, as we previously discussed.In addition, ORE has access to:•Data in other databases, which are accessible through database links•Data in external tables•And, of course, data in HDFS. In addition to bulk import, ORE makes it possible to access Hadoop directly, in a similar fashion to external tables, by using HDFS connect.This means that you can join Hadoop data with database data.Here are a few resources on Oracle R related technology.So, in this lesson, we covered three primary topics.•First, you learned what R is, who uses it, and why they use it.•Then, we looked at some common user interfaces for R.•Finally, we discussed Oracle’s strategy for supporting the R community, including an overview of goals, definitions of software terms, high- and mid-level architecture,software component features, and R user-community definitions.You’ve just completed “Introducing Oracle R Enterprise”. Please move on to the next lesson in the series: “Getting Started with ORE”.。
函数修改环境变量| - NLS_LANG='SLMPLIFIED CHINESE_CHINA.ZHS16GBK'| - export NLS_LANG| - NLS_LANG='AMERICAN_7ASCII'| - export NLS_LANG单行函数| - 字符类型| - | - dual 可以用来测试函数,一些常量表达式都可以查询此表| - | - lower 将查询内容转换为小写| - | - upper 将查询内容转换成大写| - | - initcap 把查询内容首字母转换成大写| - | - concat 拼接函数| - | - substr 求子串函数,剪切字符串| - | - substr(字符,开始索引,截取个数)| - | - substr(字符,开始到最后)| - | - length 求长度| - | - lpad 右对齐| - | - lpad(字段,填充个数,填充字符)| - | - rpad 左对齐| - 数值类型| - | - round 四舍五入| - | - round(要操作的数,保留的位数)| - | - trunc 截取| - | - trunc(要操作的数,截取的位数)to_number现实| - | - to_number 显示数字类型转换| - | - select c1 from s_emp where c1 = 10;| - where to_numbet(c1) = 10;| - c1的index不能用| - | - select salary from s_emp where salary ='1450;| - where salary = to_number('1405')| - salary的index可以用| - | - 以下三种写法index用不了| - | - where salary*12 > 12000| - (where salary > 1000)| - | - where round(salary) = 1450| - (使用基于函数的索引)| - |- where c1=10 ---- c1 varchar2(3)| - (where c1 = '10')| - | - to_char 显示字符类型换换| - | - select first_name 姓名,to_char(salary,'$99,999.99') 工资from s_emp;| - | - select first_name 姓名,to_char(salary,'L99,999.99') 工资from s_emp;| -| - 日期类型| - 转换函数将hello world转换为大写select upper('hello world') from dual;计算出1+1的结果select 1+1 from dual;把42部门的员工姓名转换为小写select lower(first_name) 名字from s_emp where dept_id = 42;在不知道carman名字拼写情况下,要查询出此人的姓名和收入select first_name 姓名,salary*12 年薪from s_emp where upper(first_name) = 'CARMEN';拼接两个字符串'hello','world'select ('hello','world') from dual;要求列出每个员工姓名的最后两个字母select substr(first_name,-2,2) from s_emp;select first_name 姓名,substr(first_name,length(first_name)-1,2) 最后两个字母from s_emp;将员工姓名右对齐,其余的补上空格字符select lpad(first_name,10,' ') 姓名右对齐from s_emp;列出员工的姓名和领导好,如果领到号为空,则显示Bossselect first_name 姓名,nvl(to_char(manager_id),'Boss') 领导号from s_emp;多表查询| - 内连接inner join| - 等值连接:两张表有描述共同属性的一个列,常见的形式就是主外键想等| - 非等值连接:可以将两张表用某一个关系表达式连接起来| - 自连接:通过给表起别名将同一张表的列之间的关系转换成不同表之间的关系| - 外连接outer join| - 外连接的结果集=内连接的结果集+t1表中匹配不上的记录和t2表的null记录的组合,核心:”驱动表内容“一个都不能少| - left join| - right join| - full join列出员工姓名和员工所在部门的名称select first_name 姓名,name 部门名from s_emp e,s_dept d where e.dept_id=d.id;select e.first_name 姓名,e.dept_id 部门号, 部门名from s_emp e inner join s_dept d on e.dept_id=d.id;查出所有部门的编号,名称和所在地区的编号,名称select d.id 部门号, 部门名称,r.id 地区编号, 地区名称from s_dept d inner join s_region r on d.region_id = r.id;查出Carmen 在哪个部门上班select e.first_name 姓名, 部门from s_emp e inner join s_dept d on e.dept_id = d.idwhere e.first_name = 'Carmen';亚洲地区有哪些部门select 部门名, 地区名from s_dept d inner join s_region r on d.region_id = r.idwhere = 'Asia';'Carmen'在哪个地区上班select e.first_name 姓名, 地区from s_emp e join s_dept d on e.dept_id=d.id and e.first_name = 'Carmen'join s_region r on d.region_id = r.id;亚洲地区有哪些员工select e.first_name 姓名, 地区from s_dept d join s_region r on d.region_id=r.id and = 'Asia'join s_emp e on e.dept_id= d.id;查询表中员工的姓名,收入,工资等级emp和salgradeselect e.ename 姓名,sal 薪水,e.grade 工资等级from emp e join salgrade s on e.sal between s.losal and s.hisal;工资等级是3和5的员工select e.ename 姓名,sal 薪水,grade 工资等级from emp e join salgrade son sal between s.losal and s.hisal and s.grade in(3,5);SMITH的工资等级select e.ename 姓名,sal 薪水,grade 工资等级from emp e join salgrade son sal between s.losal and s.hisal and e.ename = 'SMITH';列出每一个员工的领导姓名,最高领导显示'Boss'select e1.first_name 姓名,nvl(e2.first_name,'Boss') 领导姓名from s_emp e1 left join s_emp e2 on e1.manager_id = e2.id;下面的内连接不能满足条件,因为查询的时候少了manager_id字段为空的那个条目select e1.first_name 姓名,e2.first_name 领导姓名from s_emp e1 join s_emp e2 on e1.manager_id = e2.id;列出所有领导的姓名select distinct nvl(e2.first_name,'Boss') 领导姓名from s_emp e1 left join s_emp e2 on e1.manager_id = e2.id;下面语句使用内连接,无法找到Carmenselect distinct e2.first_name 领导姓名from s_emp e1 join s_emp e2 on e1.manager_id = e2.id;* 显示所有没有员工的部门select e.empno,e.ename,d.dname,d.deptnofrom emp e right join dept don d.deptno = e.deptnowhere e.empno is null;哪些人是员工,既是哪些人不是领导select e1.first_name,e2.first_namefrom s_emp e1 right join s_emp e2on e1.manage_id = e2.idwhere e.id is null;By 混乱羽翼2010.11.25。