几种字符串哈希HASH算法的性能比较
- 格式:docx
- 大小:89.16 KB
- 文档页数:5

字符串差异对比算法
1.暴力算法(BruteForce算法):这是一种最简单直观的
算法,也被叫做盲目比较算法。
它的原理是从字符串的第一个
字符开始比较,逐个字符进行比较,直到找到差异或者字符比
较完毕。
这种算法的时间复杂度较高,对于较大的字符串效率
较低。
2.动态规划算法(LongestCommonSubsequence,LCS
算法):LCS算法通过构建一个二维矩阵,比较两个字符串的
每个字符,找出最长公共子序列。
最长公共子序列即是两个字
符串中同时出现的最长的子序列。
LCS算法的时间复杂度为
O(m*n),其中m和n分别为两个字符串的长度。
3.基于哈希的算法(Diff算法):Diff算法通过将字符串分
成较小的块或行,然后计算每个块的哈希值,比较两个字符串
中相同的块,并使用其他算法处理不同的块。
这种算法常用于
文本编辑器中的差异对比。
4.基于后缀树的算法(SuffixTree算法):后缀树是一种特殊的树结构,用于表示一个字符串的所有后缀。
SuffixTree算
法通过构建两个字符串的后缀树,并比较两个树的结构,找出
差异。
这种算法的时间复杂度为O(m+n),其中m和n分别为两个字符串的长度。
这些算法各有优缺点,根据具体的应用场景选择合适的算法。
例如,对于较小的字符串比较,暴力算法可能足够简单而有效。
而对于较大的字符串比较,可以采用更为高效的算法,如动态规划算法或基于哈希的算法。
取决于需求,我们可以选择合适的算法来实现字符串差异对比。

常见的字符串匹配算法分析比较字符串是计算机领域中最常见的数据结构之一。
而计算机领域中的一个重要任务就是查找和比较字符串。
在实际应用中,字符串匹配算法如匹配关键字、拼写检查、文本比较等,是一个必要且重要的工具。
在此,本文将为大家介绍几种常见的字符串匹配算法及其优缺点,在选择算法时可以参考。
1.朴素字符串匹配算法朴素字符串匹配算法,也被称为暴力匹配算法,是字符串匹配算法中最简单的算法。
其思路是从文本的第一个字符开始与模式串的第一个字符依次比较,如果不成功就将模式串向右移动一位,直到模式串匹配成功。
算法效率较低,但实现简单。
2.Boyer-Moore算法Boyer-Moore算法是一种高效的字符串查找算法,该算法通过先进行坏字符规则和好后缀规则的比较而快速跳过无用的匹配。
其基本思路是先将模式串从右往左匹配,当发现匹配不上时,通过坏字符规则将模式串向右移,在移动过程中通过好后缀规则进一步加快匹配速度。
Boyer-Moore算法适合于长串和短模串、任意字符集的串匹配。
3.KMP算法KMP算法是由Knuth-Morris-Pratt三个人设计的,是一种著名的字符串匹配算法。
KMP算法优化了朴素匹配算法,通过预处理模式串信息(即计算next数组),能够快速地匹配文本串。
其核心思想是通过next数组记录当前位置前缀字符串中的最长公共前后缀,并通过将模式串向右移动来加快匹配速度。
KMP算法适用于模式串较短但匹配次数较多的情况。
4.Rabin-Karp算法Rabin-Karp算法是一种依赖于哈希思想的字符串匹配算法。
该算法通过哈希函数将文本和模式串的哈希值计算出来,从而利用哈希表快速匹配。
相比较于前面介绍的算法,Rabin-Karp算法无须进行模式串的比较,它的匹配速度也较快。
总结:在选择字符串匹配算法时需要根据不同的实际需求来进行选择。
朴实算法虽然算法效率不高,但是它的实现简单理解容易;Boyer-Moore算法的应用范围广,特别适用于在字符集较大时的匹配;KMP算法比较简单,容易实现,并且适用于较短的模式串;Rabin-Karp算法能够快速匹配,而且能减少一部分的比较。
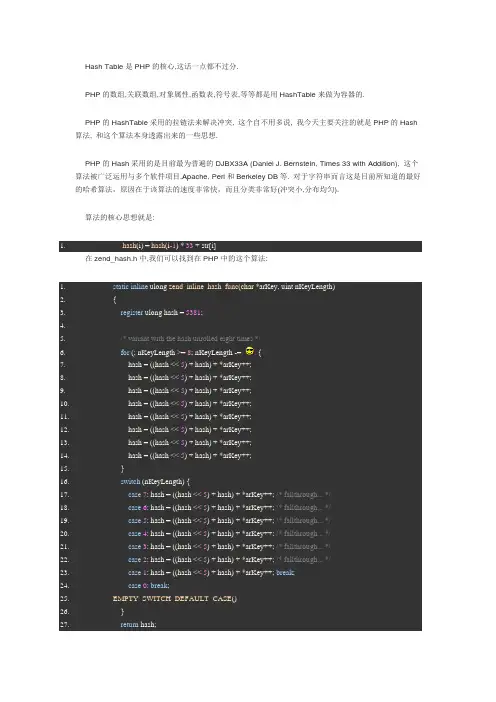
Hash Table是PHP的核心,这话一点都不过分.PHP的数组,关联数组,对象属性,函数表,符号表,等等都是用HashTable来做为容器的.PHP的HashTable采用的拉链法来解决冲突, 这个自不用多说, 我今天主要关注的就是PHP的Hash 算法, 和这个算法本身透露出来的一些思想.PHP的Hash采用的是目前最为普遍的DJBX33A (Daniel J. Bernstein, Times 33 with Addition), 这个算法被广泛运用与多个软件项目,Apache, Perl和Berkeley DB等. 对于字符串而言这是目前所知道的最好的哈希算法,原因在于该算法的速度非常快,而且分类非常好(冲突小,分布均匀).算法的核心思想就是:1.hash(i) = hash(i-1) * 33 + str[i]在zend_hash.h中,我们可以找到在PHP中的这个算法:1.static inline ulong zend_inline_hash_func(char *arKey, uint nKeyLength)2.{3.register ulong hash = 5381;4.5./* variant with the hash unrolled eight times */6.for (; nKeyLength >= 8; nKeyLength -= {7. hash = ((hash << 5) + hash) + *arKey++;8. hash = ((hash << 5) + hash) + *arKey++;9. hash = ((hash << 5) + hash) + *arKey++;10. hash = ((hash << 5) + hash) + *arKey++;11. hash = ((hash << 5) + hash) + *arKey++;12. hash = ((hash << 5) + hash) + *arKey++;13. hash = ((hash << 5) + hash) + *arKey++;14. hash = ((hash << 5) + hash) + *arKey++;15. }16.switch (nKeyLength) {17.case7: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */18.case6: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */19.case5: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */20.case4: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */21.case3: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */22.case2: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */23.case1: hash = ((hash << 5) + hash) + *arKey++; break;24.case0: break;25.EMPTY_SWITCH_DEFAULT_CASE()26. }27.return hash;28.}相比在Apache和Perl中直接采用的经典Times 33算法:1.hashing function used in Perl 5.005:2.# Return the hashed value of a string: $hash = perlhash("key")3.# (Defined by the PERL_HASH macro in hv.h)4.sub perlhash5. {6.$hash = 0;7.foreach (split//, shift) {8.$hash = $hash*33 + ord($_);9. }10.return$hash;11. }在PHP的hash算法中, 我们可以看出很处细致的不同.首先, 最不一样的就是, PHP中并没有使用直接乘33, 而是采用了:1. hash << 5 + hash这样当然会比用乘快了.然后, 特别要主意的就是使用的unrolled, 我前几天看过一片文章讲Discuz的缓存机制, 其中就有一条说是Discuz会根据帖子的热度不同采用不同的缓存策略, 根据用户习惯,而只缓存帖子的第一页(因为很少有人会翻帖子).于此类似的思想, PHP鼓励8位一下的字符索引, 他以8为单位使用unrolled来提高效率, 这不得不说也是个很细节的,很细致的地方.另外还有inline, register变量… 可以看出PHP的开发者在hash的优化上也是煞费苦心最后就是, hash的初始值设置成了5381, 相比在Apache中的times算法和Perl中的Hash算法(都采用初始hash为0), 为什么选5381呢? 具体的原因我也不知道, 但是我发现了5381的一些特性:1.Magic Constant 5381:2. 1. odd number3. 2. prime number4. 3. deficient number5. 4. 001/010/100/000/101 b看了这些, 我有理由相信这个初始值的选定能提供更好的分类.至于说, 为什么是Times 33而不是Times 其他数字, 在PHP Hash算法的注释中也有一些说明, 希望对有兴趣的同学有用:1. DJBX33A (Daniel J. Bernstein, Times 33 with Addition)2.3. This is Daniel J. Bernstein's popular `times 33' hash function as4. posted by him years ago on ng.c. It basically uses a function5. like ``hash(i) = hash(i-1) * 33 + str[i]''. This is one of the best6. known hash functions for strings. Because it is both computed very7. fast and distributes very well.8.9. The magic of number 33, i.e. why it works better than many other10. constants, prime or not, has never been adequately explained by11. anyone. So I try an explanation: if one experimentally tests all12. multipliers between 1 and 256 (as RSE did now) one detects that even13. numbers are not useable at all. The remaining 128 odd numbers14. (except for the number 1) work more or less all equally well. They15. all distribute in an acceptable way and this way fill a hash table16. with an average percent of approx. 86%.17.18. If one compares the Chi^2 values of the variants, the number 33 not19. even has the best value. But the number 33 and a few other equally20. good numbers like 17, 31, 63, 127 and 129 have nevertheless a great21. advantage to the remaining numbers in the large set of possible22. multipliers: their multiply operation can be replaced by a faster23. operation based on just one shift plus either a single addition24. or subtraction operation. And because a hash function has to both25. distribute good _and_ has to be very fast to compute, those few26. numbers should be preferred and seems to be the reason why Daniel J.27. Bernstein also preferred it.28.29. -- Ralf S. Engelschall <rse@>。

字符串哈希算法转数字字符串哈希算法是将字符串转换成数字的一种算法。
常用的字符串哈希算法有哈希函数(Hash function),其主要思想是通过某种算法将字符串映射到一个数字上。
主要有两种方法将字符串转换成数字:1.加法哈希:将每个字符的ASCII 码相加得到的数字作为哈希值。
2.乘法哈希:将每个字符的ASCII 码相乘得到的数字作为哈希值。
常用的字符串哈希算法有:●MD5:128位的哈希值,经过改进的MD5算法●SHA:Secure Hash Algorithm,安全哈希算法,包括SHA-1,SHA-2,SHA-3等●MurmurHash:高性能哈希算法,常用于哈希表●FNV:Fowler-Noll-Vo哈希算法Java中加法哈希的实现方法如下:public int addHash(String str) {int hash = 0;for (int i = 0; i < str.length(); i++) {hash += str.charAt(i);}return hash;}//例子String s = "hello";int hash = addHash(s);这个函数接受一个字符串作为输入,遍历每个字符,将它们的ASCII 码值相加,最后返回哈希值。
这里的哈希值就是"h" 的ASCII 码值104 加上"e" 的ASCII 码值101 加上"l" 的ASCII 码值108 加上"l" 的ASCII 码值108 加上"o" 的ASCII 码值111,即:104 + 101 + 108 + 108 + 111 = 432。

详解HASH(字符串哈希)HASH意为(散列),是OI的常⽤算法。
我们常⽤哈希的原因是,hash可以快速(⼀般来说是O(段长))的求出⼀个⼦段的hash值,然后就可以快速的判断两个串是否相同。
今天先讲string类的hash。
可以发现,与⼀个string有关的HASH值不仅仅跟每个字符的个数有关,还和字符的位⼦有关。
通过简单的思考,我们可以构造如图的模型:写⼀个⽐较正常的hash模板吧const int EE = 97;const int MOD = 100000007;int HASH(string p){int E = 1;int ret = 0;int tl = p.size();for (int i=0;i<tl;i++)ret += E*p[i], E *= EE;return ret;}题⽬来了:KMP问题题⽬描述如题,给出两个字符串s1和s2,其中s2为s1的⼦串,求出s2在s1中所有出现的位置。
输⼊输出格式输⼊格式:第⼀⾏为⼀个字符串,即为s1第⼆⾏为⼀个字符串,即为s2输出格式:⼀⾏包含⼀个整数,表⽰s2在s1中出现的位置的个数输⼊输出样例输⼊样例#1:ABABABCABA输出样例#1:2说明时空限制:1000ms,128M数据规模:设s1长度为N,s2长度为M对于30%的数据:N<=15,M<=5对于70%的数据:N<=10000,M<=100对于100%的数据:N<=1000000,M<=1000000思路⾸先说明:此题正解为KMP,不为hash。
如果想知道KMP算法,请百度⼀下。
但是我们学的可是“hash”呀,不能直接预处理,如果直接预处理的话,时间为O(n*m),炸掉。
我们就可以递推: "已知长度为m的序列a[1]...a[m],现在已知"a[1]...a[m]"的hash值为K,欲求a[2]...a[m+1]的hash值。

今天做的模块又用到了Hash函数,突然想起Hash函数可能会比较占CPU资源,所以希望使用一种速度最快的摘要函数。
但是PHP中的Hash函数很多,MD4、MD5、SHA-1、SHA-256、SHA-384以及SHA-512,都是比较常见的安全领域的HASH应用。
于是写了个程序对比了一下PHP支持的各种Hash函数:代码<?phpdefine('testtime', 50000);$algos = hash_algos();foreach($algos as $algo) {$st = microtime();for($i = 0; $i < testtime; $i++) {hash($algo, microtime().$i);}$et = microtime();list($ss, $si) = explode(' ', $st);list($es, $ei) = explode(' ', $et);$time[$algo] = $ei + $es - $si - $ss;}asort($time, SORT_NUMERIC);print_r($time);?>此程序测试每种hash函数支持的算法,对50000个字符串执行hash计算,然后将耗时按从低到高排序,结果如下:代码Array([crc32b] => 1.14942403926[crc32] => 1.150********[adler32] => 1.17250810205[md4] => 1.21484698894[md5] => 1.25582505324[sha256] => 1.31992111638[ripemd256] => 1.34005199425[ripemd128] => 1.34174097336[sha1] => 1.34424093234[ripemd160] => 1.36161398381[haval128,3] => 1.37490507759[haval160,3] => 1.37925811601[haval192,3] => 1.37971906387[haval224,3] => 1.38690299403[haval256,3] => 1.38968507692[tiger128,3] => 1.40321999939[tiger192,3] => 1.42025405684[tiger160,3] => 1.42113689062[ripemd320] => 1.42461802158[haval128,4] => 1.4465580045[haval160,4] => 1.44935391309[haval192,4] => 1.45606506625[haval224,4] => 1.4650528846[tiger128,4] => 1.47951410777[tiger192,4] => 1.49081709387[haval256,4] => 1.50713596634[haval160,5] => 1.51613600436[haval224,5] => 1.51645894888[haval192,5] => 1.51678603177[haval256,5] => 1.51900808377[tiger160,4] => 1.52507308815[haval128,5] => 1.53689793875[whirlpool] => 1.82801189377[snefru] => 1.85931909387[gost] => 1.89863007236[sha384] => 1.95804009064[sha512] => 1.97130295938[md2] => 4.99702701607)CRC是冗余验证算法,不适合用来做唯一标识符Hash计算,MD4是最快的摘要算法,MD5次之,SHA系列算法居然是SHA-256最快,比SHA-1还快一些。

被逼的,发个技术文章吧(几种经典的hash算法)注:最近因为在做和hash有关的题目,感到很纠结。
虽然上学期数据结构学过,但是当时觉得hash没什么用,所以没有认真学~后悔啊~~~现在恶补一下~计算理论中,没有Hash函数的说法,只有单向函数的说法。
所谓的单向函数,是一个复杂的定义,大家可以去看计算理论或者密码学方面的数据。
用“人类”的语言描述单向函数就是:如果某个函数在给定输入的时候,很容易计算出其结果来;而当给定结果的时候,很难计算出输入来,这就是单项函数。
各种加密函数都可以被认为是单向函数的逼近。
Hash函数(或者成为散列函数)也可以看成是单向函数的一个逼近。
即它接近于满足单向函数的定义。
Hash函数还有另外的含义。
实际中的Hash函数是指把一个大范围映射到一个小范围。
把大范围映射到一个小范围的目的往往是为了节省空间,使得数据容易保存。
除此以外,Hash 函数往往应用于查找上。
所以,在考虑使用Hash函数之前,需要明白它的几个限制:1. Hash的主要原理就是把大范围映射到小范围;所以,你输入的实际值的个数必须和小范围相当或者比它更小。
不然冲突就会很多。
2. 由于Hash逼近单向函数;所以,你可以用它来对数据进行加密。
3. 不同的应用对Hash函数有着不同的要求;比如,用于加密的Hash函数主要考虑它和单项函数的差距,而用于查找的Hash函数主要考虑它映射到小范围的冲突率。
应用于加密的Hash函数已经探讨过太多了,在作者的博客里面有更详细的介绍。
所以,本文只探讨用于查找的Hash函数。
Hash函数应用的主要对象是数组(比如,字符串),而其目标一般是一个int类型。
以下我们都按照这种方式来说明。
一般的说,Hash函数可以简单的划分为如下几类:1. 加法Hash;2. 位运算Hash;3. 乘法Hash;4. 除法Hash;5. 查表Hash;6. 混合Hash;下面详细的介绍以上各种方式在实际中的运用。

常用哈希算法
常用的哈希算法包括:
1. MD5(Message-Digest Algorithm 5):产生128位(16字节)哈希值,常用于校验数据完整性,但因其较短的哈希长度和安全性弱而逐渐被淘汰。
2. SHA-1(Secure Hash Algorithm 1):产生160位(20字节)哈希值,常用于数字签名和安全证书,但随着安全性问题的暴露,已经不再推荐使用。
3. SHA-256(Secure Hash Algorithm 256):产生256位(32字节)哈希值,是SHA-2家族中的一种,目前广泛应用于数字签名、数据完整性验证等领域。
4. SHA-3(Secure Hash Algorithm 3):产生不同长度的哈希值,比如SHA3-256、SHA3-512等,是新一代的哈希算法,设计目标是提供更高的安全性和性能。
5. Bcrypt:主要用于密码存储,采用不可逆的哈希函数,加入了“盐”(salt)以增加破解难度,适合保护用户密码。
6. Argon2:专门设计用于密码哈希,被评选为密码哈希竞赛的获胜者,具有抗GPU和ASIC攻击的特性。
7. SHA-512:SHA-2家族中的一种,产生512位(64字节)哈希值,广泛用于安全领域和密码学中。
选择使用哪种哈希算法取决于具体的应用需求和安全要求。
在安全性方面,越新的哈希算法通常具有更高的安全性,但也需要考虑到性能、资源消耗和算法的广泛应用情况。
1/ 1。

常见的hash算法常见的Hash算法包括MD5、SHA-1、SHA-256、SHA-512、CRC32等。
本文将介绍这些常用的Hash算法。
1. MD5(Message Digest Algorithm 5)MD5是一种广泛使用的Hash算法,其输出结果为128位(16字节)的哈希值。
MD5算法以输入的数据流作为输入,并输出固定长度的哈希值。
由于其较短的哈希值长度和高效的计算性能,MD5广泛应用于密码验证、数据完整性校验等场景。
然而,由于MD5具有较高的碰撞概率和易受到暴力破解攻击,因此在一些安全性要求较高的场景中不建议使用。
2. SHA-1(Secure Hash Algorithm 1)SHA-1是一种常用的Hash算法,其输出结果为160位(20字节)的哈希值。
SHA-1算法与MD5类似,使用输入数据流作为输入并输出固定长度的哈希值。
SHA-1在安全性方面较MD5有所提升,但也存在安全性问题。
近年来,SHA-1已被证实存在碰撞漏洞,因此在一些安全性要求较高的场景中不建议使用。
3. SHA-256(Secure Hash Algorithm 256 bits)SHA-256是SHA系列中的一种较新的Hash算法,其输出结果为256位(32字节)的哈希值。
SHA-256相比于MD5和SHA-1,在安全性方面有显著提升。
SHA-256的哈希值长度更长,碰撞概率更低,因此在一些密钥生成、数据完整性校验等场景中得到广泛应用。
4. SHA-512(Secure Hash Algorithm 512 bits)SHA-512是SHA系列中的一种较新的Hash算法,其输出结果为512位(64字节)的哈希值。
SHA-512是SHA-256的更高级版本,其哈希值长度更长,安全性更高。
SHA-512适用于需要更高安全性级别的场景,如数字签名、网络安全等领域。
5. CRC32(Cyclic Redundancy Check)除了上述常用的Hash算法,还有一些其他的Hash算法,如SHA-224、SHA-384、MD6等。

常见的Hash算法常见的Hash算法1.简介哈希函数按照定义可以实现⼀个伪随机数⽣成器(PRNG),从这个⾓度可以得到⼀个公认的结论:哈希函数之间性能的⽐较可以通过⽐较其在伪随机⽣成⽅⾯的⽐较来衡量。
⼀些常⽤的分析技术,例如泊松分布可⽤于分析不同的哈希函数对不同的数据的碰撞率(collision rate)。
⼀般来说,对任意⼀类的数据存在⼀个理论上完美的哈希函数。
这个完美的哈希函数定义是没有发⽣任何碰撞,这意味着没有出现重复的散列值。
在现实中它很难找到⼀个完美的哈希散列函数,⽽且这种完美函数的趋近变种在实际应⽤中的作⽤是相当有限的。
在实践中⼈们普遍认识到,⼀个完美哈希函数的哈希函数,就是在⼀个特定的数据集上产⽣的的碰撞最少哈希的函数。
现在的问题是有各种类型的数据,有⼀些是⾼度随机的,有⼀些有包含⾼纬度的图形结构,这些都使得找到⼀个通⽤的哈希函数变得⼗分困难,即使是某⼀特定类型的数据,找到⼀个⽐较好的哈希函数也不是意见容易的事。
我们所能做的就是通过试错⽅法来找到满⾜我们要求的哈希函数。
可以从下⾯两个⾓度来选择哈希函数:1.数据分布⼀个衡量的措施是考虑⼀个哈希函数是否能将⼀组数据的哈希值进⾏很好的分布。
要进⾏这种分析,需要知道碰撞的哈希值的个数,如果⽤链表来处理碰撞,则可以分析链表的平均长度,也可以分析散列值的分组数⽬。
2.哈希函数的效率另个⼀个衡量的标准是哈希函数得到哈希值的效率。
通常,包含哈希函数的算法的算法复杂度都假设为O(1),这就是为什么在哈希表中搜索数据的时间复杂度会被认为是"平均为O(1)的复杂度",⽽在另外⼀些常⽤的数据结构,⽐如图(通常被实现为红⿊树),则被认为是O(logn)的复杂度。
⼀个好的哈希函数必修在理论上⾮常的快、稳定并且是可确定的。
通常哈希函数不可能达到O(1)的复杂度,但是哈希函数在字符串哈希的线性的搜索中确实是⾮常快的,并且通常哈希函数的对象是较⼩的主键标识符,这样整个过程应该是⾮常快的,并且在某种程度上是稳定的。

hash 相关算法Hash相关算法在计算机科学中,Hash(哈希)算法是一种将任意长度的数据映射为固定长度的值的算法。
它是一种常用的密码学算法,广泛应用于数据完整性校验、数据加密和唯一标识等领域。
本文将介绍几种常见的Hash相关算法及其应用。
一、MD5算法MD5(Message Digest Algorithm 5)是一种广泛使用的Hash算法,它将任意长度的数据映射为128位的哈希值。
MD5算法具有较快的计算速度和较低的冲突概率,被广泛应用于文件完整性校验、密码存储和数据加密等领域。
然而,由于MD5算法存在碰撞漏洞,即不同的输入可能会生成相同的哈希值,因此在一些安全性要求较高的场景下,不推荐使用MD5算法。
二、SHA算法SHA(Secure Hash Algorithm)是一系列Hash算法的统称,包括SHA-1、SHA-256、SHA-512等。
SHA-1算法将任意长度的数据映射为160位的哈希值,而SHA-256和SHA-512算法分别将数据映射为256位和512位的哈希值。
SHA算法具有较高的安全性和较低的冲突概率,被广泛应用于数字签名、证书验证和密码学等领域。
三、CRC算法CRC(Cyclic Redundancy Check)是一种基于多项式除法的Hash算法,主要用于数据完整性校验。
CRC算法将数据按照一定的规则进行逐位异或运算,最终得到一个固定长度的校验值。
CRC算法具有较快的计算速度和较低的冲突概率,被广泛应用于网络通信、存储系统和数据校验等领域。
四、Bcrypt算法Bcrypt是一种基于Blowfish加密算法的Hash算法,主要用于密码存储和验证。
Bcrypt算法将密码和随机生成的盐值进行多轮的加密运算,得到一个固定长度的哈希值。
Bcrypt算法具有较高的安全性和较慢的计算速度,对于密码破解攻击具有较好的防护效果。
五、HMAC算法HMAC(Hash-based Message Authentication Code)是一种基于Hash算法的消息认证码算法,用于验证数据的完整性和真实性。
redis 的基本5种数据类型Redis是一种高性能的键值存储系统,它支持多种数据类型的存储和操作。
在Redis中,有五种基本的数据类型,分别是字符串(String)、哈希(Hash)、列表(List)、集合(Set)和有序集合(Sorted Set)。
下面将逐一介绍这五种数据类型的特点和使用场景。
一、字符串(String)字符串是Redis中最基本的数据类型,它可以存储任意长度的字符串。
在Redis中,字符串不仅可以作为简单的键值对存储,还可以进行一些常见的字符串操作,如拼接、截取、替换等。
此外,Redis 还提供了一些特殊的操作,如对字符串进行自增、自减等操作。
字符串类型适用于存储各种简单的数据,如用户信息、配置信息、计数器等。
由于Redis对字符串的操作非常高效,因此在需要频繁读写的场景下,使用字符串类型可以获得更好的性能。
二、哈希(Hash)哈希类型是一种键值对的集合,它可以存储多个字段和值。
在Redis中,哈希类型的键可以视为一个大的对象,而字段和值则对应于对象的属性和属性值。
哈希类型支持对单个字段进行读写操作,也支持对整个哈希对象进行读写操作。
哈希类型适用于存储结构化的数据,如用户信息、文章信息等。
使用哈希类型可以方便地对对象的各个属性进行读写操作,并且可以有效地减少内存占用。
三、列表(List)列表类型是一种有序的字符串列表,它可以存储多个字符串元素。
在Redis中,列表类型的元素可以进行插入、删除、修改等操作,并且可以根据索引进行访问。
此外,Redis还提供了一些特殊的操作,如对列表进行修剪、合并等。
列表类型适用于存储有序的数据集合,如消息队列、最新消息列表等。
使用列表类型可以方便地实现先进先出(FIFO)的数据结构,并且可以实现快速的插入和删除操作。
四、集合(Set)集合类型是一种无序的字符串集合,它可以存储多个字符串元素,且元素之间没有重复。
在Redis中,集合类型的元素可以进行添加、删除、查找等操作,还可以进行集合间的交集、并集、差集等操作。
列举3个哈希算法哈希算法,也称为哈希函数,是将任意大小的数据映射为固定大小的数据的算法。
它们广泛应用于密码学、数据结构、数据完整性校验等领域。
以下是列举的3个常见的哈希算法:MD5、SHA-1和SHA-2561. MD5(Message Digest Algorithm 5):MD5是一种广泛使用的哈希算法,由美国密码学家罗纳德·李维斯特(Ronald Rivest)于1991年设计。
它输出一个128位(32个十六进制字符)的哈希值。
MD5算法具有高度的不可逆性和唯一性,可以生成具有相同哈希值的两个不同输入的概率非常低。
然而,由于其较小的长度和已发现的一些弱点,MD5现已被认为是不安全的。
2. SHA-1(Secure Hash Algorithm 1):SHA-1是美国国家标准技术研究所(NIST)于1995年发布的一种哈希算法。
它输出一个160位(40个十六进制字符)的哈希值。
SHA-1是MD5的改进版本,提供了更高的安全性和抗碰撞能力。
然而,随着计算能力的提高,SHA-1也逐渐被认为不再安全,因为已经发现了一些有效的碰撞攻击。
3. SHA-256(Secure Hash Algorithm 256):SHA-256是SHA-2算法族中的一员,也是目前广泛使用的安全哈希算法之一、它输出一个256位(64个十六进制字符)的哈希值。
SHA-256提供了较高的安全性和抗碰撞能力,适用于许多密码学应用和数据完整性验证。
与SHA-1相比,SHA-256具有更长的哈希值,使得碰撞攻击更加困难。
这3个哈希算法在实际应用中各有优劣势。
MD5因为其较小的哈希长度和已发现的弱点而被广泛认为是不安全的;SHA-1在安全性上相对较好,但随着时间的推移逐渐被认为不再安全;SHA-256则提供了更高的安全性和抗碰撞能力,目前被广泛应用。
值得注意的是,随着计算能力的提高和密码学研究的进步,任何哈希算法在长期使用后都有可能被攻破,因此在选择哈希算法时应综合考虑安全性和性能。
Redis缓存的五种数据结构及其应用场景Redis是一款高性能的键值存储系统,常被用作缓存来提升应用程序的性能。
它支持多种数据结构,包括字符串(string)、列表(list)、哈希(hash)、集合(set)和有序集合(sorted set)。
本文将探讨这五种数据结构在缓存中的具体应用场景。
一、字符串(string)字符串是最简单的数据结构,在Redis缓存中有着广泛的应用。
它可以存储各类数据,如用户信息、配置文件等。
常见的应用场景有:1. 缓存对象或数据:将查询结果、用户信息等存储为字符串,以提高读取速度,并避免频繁访问数据库。
2. 分布式锁:利用Redis的setnx(SET if Not eXists)命令,实现分布式环境下的锁机制,避免资源竞争。
3. 计数器:通过Redis的incr(INCRement)或decr(DECRement)命令,实现计数功能,如统计文章浏览次数、用户登录次数等。
二、列表(list)列表是一种可以存储有序元素的数据结构,在Redis缓存中主要应用于消息队列、排行榜等场景。
具体应用包括:1. 消息队列:通过lpush(LPUSH)和rpop(RPOP)命令,实现消息的压入和弹出,实现简单的发布/订阅模型。
2. 最新消息排行榜:将每条消息按照发布时间存储在列表中,通过lrange(LRANGE)命令获取最新的消息列表。
3. 消息历史记录:维护用户的消息历史记录列表,方便用户查看之前的消息。
三、哈希(hash)哈希是一种存储键值对的数据结构,在Redis缓存中主要用于存储对象的属性。
常见应用场景有:1. 用户信息存储:将用户的各项属性存储在哈希结构中,方便读取和更新。
2. 对象缓存:将对象的各个属性存储在哈希结构中,以减少数据库访问次数,并提升读取性能。
3. 商品信息存储:将商品的名称、价格、库存等属性存储在哈希结构中,方便进行商品相关操作。
四、集合(set)集合是一种无序且不重复的数据结构,在Redis缓存中主要应用于标签管理、好友关系等场景。
三种Hash算法对⽐以及秒传原理.
三种Hash算法对⽐以及秒传原理
CRC (32/64) MD5 Sha1
分5个点来说
1.校验值长度
2.校验值类别
3.安全级别
4.应⽤场景
1).校验值长度
CRC(32/64) 分别是4个字节和8个字节
MD5 16字节所以长度为108位
sha1 20字节 160位长度
2)校验值类别
⼀般把CRC叫做校验码
md5和sha1叫做hash值或者散列值,从这⾥⼤概可以看出⽤处不同
3)安全级别
CRC<MD5<Sha1(当然sha1上⾯还有sha256或者sha512)
但是安全级别⾼并不是绝对好的,级别越⾼计算消耗的时间也越⾼
4).应⽤场景
CRC⼀般⽤于数据传输的校验
md5和sha1⼀般⽤于⽂件的校验或者⽂件的标志
秒传原理
分⼏种情况
1.⽤户上传
有时候⽤户上传⼤⽂件的时候会瞬间完成,这是因为之前有⽤户上传过相同的⽂件了,就会免去了这次上传过程
2.离线下载
3.好友分享⽂件
如何实现呢:
1.⽂件Hash(md5,SHA1等)
每个⽂件都计算出hash值,如果⽂件hash相同就免去上传过程.。
字符串Hash总结转载⾃:Hash是什么意思呢?某度翻译告诉我们:hash 英[hæʃ] 美[hæʃ]n. 剁碎的⾷物; #号; 蔬菜⾁丁;vt. 把…弄乱; 切碎; 反复推敲; 搞糟;我觉得Hash是引申出把...弄乱的意思。
今天就来谈谈Hash的⼀种——字符串hash。
据我的理解,Hash就是⼀个像函数⼀样的东西,你放进去⼀个值,它给你输出来⼀个值。
输出的值就是Hash值。
⼀般Hash值会⽐原来的值更好储存(更⼩)或⽐较。
那字符串Hash就⾮常好理解了。
就是把字符串转换成⼀个整数的函数。
⽽且要尽量做到使字符串对应唯⼀的Hash值。
字符串Hash的种类还是有很多种的,不过在信息学竞赛中只会⽤到⼀种名为“BKDR Hash”的字符串Hash算法。
它的主要思路是选取恰当的进制,可以把字符串中的字符看成⼀个⼤数字中的每⼀位数字,不过⽐较字符串和⽐较⼤数字的复杂度并没有什么区别(⾼精数的⽐较也是O(n)那么我们选择什么进制⽐较好?⾸先不要把任意字符对应到数字0,⽐如假如把a对应到数字0,那么将不能只从Hash结果上区分ab和b(虽然可以额外判断字符串长度,但不把任意字符对应到数字0更加省事且没有任何副作⽤),⼀般⽽⾔,把a-z对应到数字1-26⽐较合适。
关于进制的选择实际上⾮常⾃由,⼤于所有字符对应的数字的最⼤值,不要含有模数的质因⼦(那还模什么),⽐如⼀个字符集是a到z的题⽬,选择27、233、19260817都是可以的。
模数的选择(尽量还是要选择质数):绝⼤多数情况下,不要选择⼀个109最稳妥的办法是选择两个109如果能背过或在考场上找出⼀个1018偷懒的写法就是直接使⽤unsigned long long,不⼿动进⾏取模,它溢出时会⾃动对264⽤luogu P3370为例。
这是⾃然溢出hash(100)#include <cstdio>#include <cstring>#include <algorithm>using namespace std;typedef unsigned long long ull;ull base=131;ull a[10010];char s[10010];int n,ans=1;ull hashs(char s[]){int len=strlen(s);ull ans=0;for (int i=0;i<len;i++)ans=ans*base+(ull)s[i];return ans&0x7fffffff;}main(){scanf("%d",&n);for (int i=1;i<=n;i++){scanf("%s",s);a[i]=hashs(s);}sort(a+1,a+n+1);for (int i=2;i<=n;i++)if (a[i]!=a[i-1])ans++;printf("%d\n",ans);}这是单模数hash(80)#include <cstdio>#include <cstring>#include <algorithm>using namespace std;typedef unsigned long long ull;ull base=131;ull a[10010];char s[10010];int n,ans=1;ull mod=19260817;ull hashs(char s[]){int len=strlen(s);ull ans=0;for (int i=0;i<len;i++)ans=(ans*base+(ull)s[i])%mod; return ans;}main(){scanf("%d",&n);for (int i=1;i<=n;i++){scanf("%s",s);a[i]=hashs(s);}sort(a+1,a+n+1);for (int i=2;i<=n;i++)if (a[i]!=a[i-1])ans++;printf("%d\n",ans);}这是双hash(100)#include <cstdio>#include <cstring>#include <algorithm>using namespace std;typedef unsigned long long ull;ull base=131;struct data{ull x,y;}a[10010];char s[10010];int n,ans=1;ull mod1=19260817;ull mod2=19660813;ull hash1(char s[]){int len=strlen(s);ull ans=0;for (int i=0;i<len;i++)ans=(ans*base+(ull)s[i])%mod1; return ans;}ull hash2(char s[]){int len=strlen(s);ull ans=0;for (int i=0;i<len;i++)ans=(ans*base+(ull)s[i])%mod2; return ans;}bool comp(data a,data b){return a.x<b.x;}main(){scanf("%d",&n);for (int i=1;i<=n;i++){scanf("%s",s);a[i].x=hash1(s);a[i].y=hash2(s);}sort(a+1,a+n+1,comp);for (int i=2;i<=n;i++)if (a[i].x!=a[i-1].x || a[i-1].y!=a[i].y) ans++;printf("%d\n",ans);}这是只⽤⼀个10^18质数的hash(100)#include <cstdio>#include <cstring>#include <algorithm>using namespace std;typedef unsigned long long ull;ull base=131;ull a[10010];char s[10010];int n,ans=1;ull mod=212370440130137957ll;ull hashs(char s[]){int len=strlen(s);ull ans=0;for (int i=0;i<len;i++)ans=(ans*base+(ull)s[i])%mod;return ans;}main(){scanf("%d",&n);for (int i=1;i<=n;i++){scanf("%s",s);a[i]=hashs(s);}sort(a+1,a+n+1);for (int i=2;i<=n;i++)if (a[i]!=a[i-1])ans++;printf("%d\n",ans);}Hash还有⼀⽅⾯,就是它可以处理⼦串信息。
几种字符串哈希HASH算法的性能比较2011年01月26日星期三 19:40这不就是要找hash table的hash function吗?1 概述链表查找的时间效率为O(N),二分法为log2N,B+ Tree为log2N,但Hash链表查找的时间效率为O(1)。
设计高效算法往往需要使用Hash链表,常数级的查找速度是任何别的算法无法比拟的,Hash 链表的构造和冲突的不同实现方法对效率当然有一定的影响,然而Hash函数是Hash链表最核心的部分,本文尝试分析一些经典软件中使用到的字符串 Hash函数在执行效率、离散性、空间利用率等方面的性能问题。
2 经典字符串Hash函数介绍作者阅读过大量经典软件原代码,下面分别介绍几个经典软件中出现的字符串Hash函数。
2.1 PHP中出现的字符串Hash函数static unsigned long hashpjw(char *arKey, unsigned int nKeyLength) {unsigned long h = 0, g;char *arEnd=arKey+nKeyLength;while (arKey < arEnd) {h = (h << 4) + *arKey++;if ((g = (h & 0xF0000000))) {h = h ^ (g >> 24);h = h ^ g;}}return h;}2.2 OpenSSL中出现的字符串Hash函数unsigned long lh_strhash(char *str){int i,l;unsigned long ret=0;unsigned short *s;if (str == NULL) return(0);l=(strlen(str)+1)/2;s=(unsigned short *)str;for (i=0; iret^=(s[i]<<(i&0x0f));return(ret);} *//* The following hash seems to work very well on normal text strings * no collisions on /usr/dict/words and it distributes on %2^n quite * well, not as good as MD5, but still good.*/unsigned long lh_strhash(const char *c){unsigned long ret=0;long n;unsigned long v;int r;if ((c == NULL) || (*c == '\0'))return(ret);/*unsigned char b[16];MD5(c,strlen(c),b);return(b[0]|(b[1]<<8)|(b[2]<<16)|(b[3]<<24));*/n=0x100;while (*c){v=n|(*c);n+=0x100;r= (int)((v>>2)^v)&0x0f;ret=(ret<>(32-r));ret&=0xFFFFFFFFL;ret^=v*v;c++;}return((ret>>16)^ret);}在下面的测量过程中我们分别将上面的两个函数标记为OpenSSL_Hash1和OpenSSL_Hash2,至于上面的实现中使用MD5算法的实现函数我们不作测试。
2.3 MySql中出现的字符串Hash函数#ifndef NEW_HASH_FUNCTION/* Calc hashvalue for a key */static uint calc_hashnr(const byte *key,uint length){register uint nr=1, nr2=4;while (length--){nr^= (((nr & 63)+nr2)*((uint) (uchar) *key++))+ (nr << 8);nr2+=3;}return((uint) nr);}/* Calc hashvalue for a key, case indepenently */static uint calc_hashnr_caseup(const byte *key,uint length){register uint nr=1, nr2=4;while (length--){nr^= (((nr & 63)+nr2)*((uint) (uchar) toupper(*key++)))+ (nr << 8);nr2+=3;}return((uint) nr);}#else/** Fowler/Noll/Vo hash** The basis of the hash algorithm was taken from an idea sent by email to the* IEEE Posix P1003.2 mailing list from Phong Vo (kpv@) and* Glenn Fowler (gsf@). Landon Curt Noll(chongo@)* later improved on their algorithm.** The magic is in the interesting relationship between the special prime * 16777619 (2^24 + 403) and 2^32 and 2^8.** This hash produces the fewest collisions of any function that we've seen so* far, and works well on both numbers and strings.*/uint calc_hashnr(const byte *key, uint len){const byte *end=key+len;uint hash;for (hash = 0; key < end; key++){hash *= 16777619;hash ^= (uint) *(uchar*) key;}return (hash);}uint calc_hashnr_caseup(const byte *key, uint len){const byte *end=key+len;uint hash;for (hash = 0; key < end; key++){hash *= 16777619;hash ^= (uint) (uchar) toupper(*key);}return (hash);}#endifMysql中对字符串Hash函数还区分了大小写,我们的测试中使用不区分大小写的字符串Hash函数,另外我们将上面的两个函数分别记为MYSQL_Hash1和MYSQL_Hash2。
2.4 另一个经验字符串Hash函数unsigned int hash(char *str){register unsigned int h;register unsigned char *p;for(h=0, p = (unsigned char *)str; *p ; p++)h = 31 * h + *p;return h;}3 测试及结果3.1 测试说明从上面给出的经典字符串Hash函数中可以看出,有的涉及到字符串大小敏感问题,我们的测试中只考虑字符串大小写敏感的函数,另外在上面的函数中有的函数需要长度参数,有的不需要长度参数,这对函数本身的效率有一定的影响,我们的测试中将对函数稍微作一点修改,全部使用长度参数,并将函数内部出现的计算长度代码删除。
我们用来作测试用的Hash链表采用经典的拉链法解决冲突,另外我们采用静态分配桶(Hash链表长度)的方法来构造Hash链表,这主要是为了简化我们的实现,并不影响我们的测试结果。
测试文本采用单词表,测试过程中从一个输入文件中读取全部不重复单词构造一个Hash表,测试内容分别是函数总调用次数、函数总调用时间、最大拉链长度、平均拉链长度、桶利用率(使用过的桶所占的比率),其中函数总调用次数是指Hash函数被调用的总次数,为了测试出函数执行时间,该值在测试过程中作了一定的放大,函数总调用时间是指Hash函数总的执行时间,最大拉链长度是指使用拉链法构造链表过程中出现的最大拉链长度,平均拉链长度指拉链的平均长度。
测试过程中使用的机器配置如下:PIII600笔记本,128M内存,windows 2000 server操作系统。
3.2 测试结果以下分别是对两个不同文本文件中的全部不重复单词构造Hash链表的测试结果,测试结果中函数调用次数放大了100倍,相应的函数调用时间也放大了100倍。
从上表可以看出,这些经典软件虽然构造字符串Hash函数的方法不同,但是它们的效率都是不错的,相互之间差距很小,读者可以参考实际情况从其中借鉴使用。