系统聚类分析课程设计
- 格式:docx
- 大小:19.11 KB
- 文档页数:16



聚类课程设计一、教学目标本课程的教学目标是使学生掌握聚类分析的基本概念、方法和应用。
通过本课程的学习,学生应能够理解聚类的目的和意义,熟悉聚类分析的基本算法,掌握聚类结果的解释和评估,并能够将聚类分析应用到实际问题中。
具体来说,知识目标包括:1.了解聚类分析的基本概念,如聚类、簇、距离度量等。
2.掌握常用的聚类算法,如 K-means、层次聚类、DBSCAN 等。
3.理解聚类分析的应用领域和实际意义。
技能目标包括:1.能够使用相关软件或编程语言实现聚类分析算法。
2.能够对聚类结果进行解释和评估,如确定合适的聚类个数、评估聚类质量等。
3.能够将聚类分析应用到实际问题中,如数据挖掘、图像处理等。
情感态度价值观目标包括:1.培养学生的数据分析能力和问题解决能力。
2.培养学生对数据的敏感性和批判性思维。
3.培养学生对聚类分析在实际应用中的认识和价值判断。
二、教学内容本课程的教学内容主要包括聚类分析的基本概念、方法和应用。
具体的教学大纲如下:1.引言:介绍聚类分析的背景和意义,概述本课程的主要内容和目标。
2.聚类分析的基本概念:介绍聚类、簇、距离度量等基本概念。
3.聚类算法:介绍 K-means、层次聚类、DBSCAN 等常用聚类算法。
4.聚类结果的解释和评估:讲解如何确定合适的聚类个数、评估聚类质量等。
5.聚类分析的应用:介绍聚类分析在数据挖掘、图像处理等领域的应用实例。
三、教学方法为了激发学生的学习兴趣和主动性,本课程将采用多种教学方法相结合的方式。
具体包括:1.讲授法:教师通过讲解和演示,向学生传授聚类分析的基本概念、方法和应用。
2.讨论法:学生进行小组讨论,促进学生之间的交流和思考。
3.案例分析法:通过分析实际案例,让学生了解聚类分析在实际问题中的应用。
4.实验法:安排实验课程,让学生亲手操作和实践聚类分析算法。
四、教学资源为了支持教学内容和教学方法的实施,丰富学生的学习体验,我们将准备以下教学资源:1.教材:选择一本关于聚类分析的教材,作为学生学习的主要参考资料。

第五章聚类分析(一)教学目的通过本章的学习,对聚类分析从总体上有一个清晰地认识,理解聚类分析的基本思想和基本原理,掌握用聚类分析解决实际问题的能力。
(二)基本要求了解聚类分析的定义,种类及其应用范围,理解聚类分析的基本思想,掌握各类分析方法的主要步骤。
(三)教学要点1、聚类分析概述;2、系统聚类分析基本思想,主要步骤;3、动态聚类法基本思想,基本原理,主要步骤;4、模糊聚类分析基本思想,基本原理,主要步骤;5、图论聚类分析基本思想,基本原理。
(四)教学时数6课时(五)教学内容1、聚类分析概述2、系统聚类分析3、动态聚类法4、模糊聚类分析5、图论聚类分析统计分组或分类可以深化人们的认识。
实际应用中,有些情况下进行统计分组比较容易,分组标志确定了,分组也就得到了,但是,有些情况下进行统计分组却比较困难,特别是当客观事物性质变化没有明显标志时,用于确定分组的标志和组别就很难确定。
聚类分析实际上给我们提供了一种对于复杂问题如何分组的统计方法。
第一节聚类分析概述一、聚类分析的定义聚类分析是将样品或变量按照它们在性质上的亲疏程度进行分类的多元统计分析方法。
聚类分析时,用来描述样品或变量的亲疏程度通常有两个途径,一是把每个样品或变量看成是多维空间上的一个点,在多维坐标中,定义点与点,类和类之间的距离,用点与点间距离来描述样品或变量之间的亲疏程度;另一个是计算样品或变量的相似系数,用相似系数来描述样品或变量之间的亲疏程度。
二、聚类分析的种类(一)聚类分析按照分组理论依据的不同,可分为系统聚类法,动态聚类法,模糊聚类、图论聚类、聚类预报等多种聚类方法。
1、系统聚类分析法。
是在样品距离的基础上定义类与类的距离,首先将n个样品自成一类,然后每次将具有最小距离的两个类合并,合并后再重新计算类与类之间的距离,再并类,这个过程一直持续到所有的样品都归为一类为止。
这种聚类方法称为系统聚类法。
根据并类过程所做的样品并类过程图称为聚类谱系图。

r软件聚类分析课程设计一、课程目标知识目标:1. 理解聚类分析的基本概念、原理及在R软件中的实现方法;2. 学会使用R软件进行数据预处理、聚类分析及结果解读;3. 掌握不同聚类算法(如K-means、层次聚类等)的优缺点及适用场景。
技能目标:1. 能够独立操作R软件进行聚类分析,并对结果进行可视化展示;2. 能够根据实际数据特点选择合适的聚类算法,调整相关参数,优化分析结果;3. 能够运用聚类分析结果对实际问题进行解释和阐述。
情感态度价值观目标:1. 培养学生对数据科学和R软件的兴趣,激发主动学习的热情;2. 培养学生的团队合作意识,学会在团队中分享、交流、协作;3. 培养学生严谨的科学态度,注重数据分析的客观性和准确性。
课程性质:本课程为高年级数据分析相关课程,旨在通过R软件聚类分析的学习,提高学生的数据分析能力,培养学生解决实际问题的能力。
学生特点:学生具备一定的统计学和R软件基础,对数据分析有一定了解,具备独立思考和解决问题的能力。
教学要求:结合学生特点和课程性质,注重理论与实践相结合,强调学生在实际操作中掌握聚类分析方法,并能应用于实际问题。
在教学过程中,关注学生的学习反馈,及时调整教学策略,确保课程目标的实现。
通过课程学习,使学生具备独立进行聚类分析的能力,为后续学习和工作打下坚实基础。
二、教学内容1. 聚类分析基本概念与原理- 聚类分析的分类及各自特点- 聚类分析的数学原理及算法流程2. R软件基础操作与数据预处理- R软件的基本操作与数据导入- 数据清洗、整理与转换3. 常用聚类算法及其R实现- K-means算法及其R实现- 层次聚类算法及其R实现- DBSCAN算法及其R实现4. 聚类结果可视化与评估- 聚类结果的可视化方法- 聚类效果的评估指标与优化方法5. 聚类分析在实际案例中的应用- 选择合适的数据集进行聚类分析- 根据实际需求调整聚类算法与参数- 案例分析与结果解读教学内容安排与进度:1. 第1周:聚类分析基本概念与原理2. 第2周:R软件基础操作与数据预处理3. 第3-4周:常用聚类算法及其R实现4. 第5周:聚类结果可视化与评估5. 第6周:聚类分析在实际案例中的应用教材章节关联:1. 《统计学》第十章:聚类分析2. 《R语言实战》第四章:数据处理与可视化3. 《数据挖掘与机器学习》第六章:聚类分析方法三、教学方法本课程将采用以下教学方法,旨在激发学生的学习兴趣,提高学生的主动参与度和实践能力:1. 讲授法:通过系统的讲解,使学生掌握聚类分析的基本概念、原理和算法流程。

04 聚类分析聚类分析专题§6.1引言俗话说,“物以类聚,人以群分”,在自然科学和社会科学等各领域中,存在着大量的分类问题。
分类学是人类认识世界的基础科学,在古老的分类学中,人们主要靠经验和专业知识进行定性的分类,很少利用数学工具进行定量的分类。
随着人类科学技术的发展,对分类的要求越来越高,以致有时仅凭经验和专业知识难以确切地进行分类,于是人们逐渐地把数学工具引用到了分类学中,这便形成了数值分类学这一学科,之后又将多元分析的技术引入到数值分类学,便又从数值分类学中分离出一个重要分支一一聚类分析。
与多元分析的其它分析方法相比,聚类分析方法较为粗糙,理论上还不够完善,正处于发展阶段。
但是,由于该方法应用方便,分类效果较好,因此越来越为人们所重视。
这些年来聚类分析的方法发展较快,内容越来越丰富。
判别分析与聚类分析都是研究事物分类的基本方法,它们有着不同的分类目的,彼此之间既有区别又有联系。
各种判别分析方法都要求对类有事先的了解,通常是每一类都有一个样本,据此得出判别函数和规则,进而可对其它新的样品属于哪一类作出判断。
对类的事先了解和确定常常可以通过聚类分析得到。
聚类分析的目的是把分类对象按一定规则分成若干类,这些类不是事先给定的,而是根据数据的特征确定的。
在同一类里的这些对象在某种意义上倾向于彼此相似,而在不同类里的对象倾向于不相似。
聚类分析能够用来概括数据而不只是为了寻找“自然的”或“实在的”分类。
例如,在选拔少年运动员时,对少年的身体形态、身体素质、生理功能的各种指标进行测试,据此对少年进行分类,分在同一类里的少年这些指标较为相近。
类确定好之后,可以根据各类的样本数据得出选材的判别规则,作为选材的依据。
又如,根据啤酒中含有的酒精成分、纳成分、所含的热量“卡路里”数值,可以对啤酒进行分类。
聚类分析根据分类对象不同分为Q型聚类分析和R型聚类分析。
Q型聚类分析是指对样品进行聚类,R型聚类分析是指对变量进行聚类。
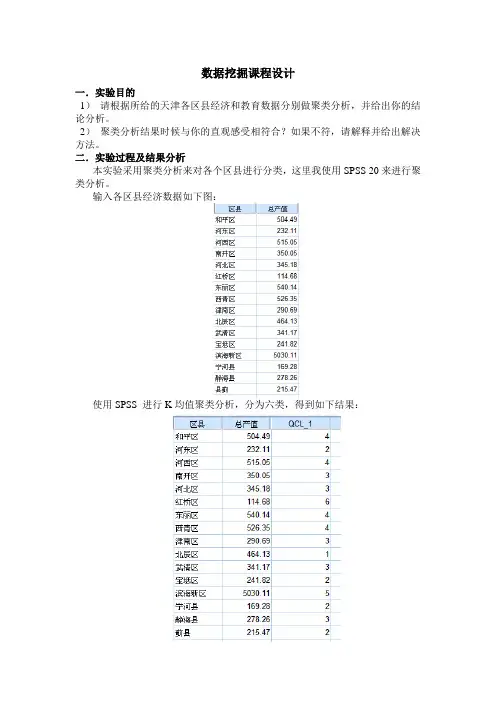
数据挖掘课程设计一.实验目的1)请根据所给的天津各区县经济和教育数据分别做聚类分析,并给出你的结论分析。
2)聚类分析结果时候与你的直观感受相符合?如果不符,请解释并给出解决方法。
二.实验过程及结果分析本实验采用聚类分析来对各个区县进行分类,这里我使用SPSS 20来进行聚类分析。
输入各区县经济数据如下图:使用SPSS 进行K均值聚类分析,分为六类,得到如下结果:每个聚类中的案例数聚类1 1.0002 4.0003 5.0004 4.0005 1.0006 1.000有效16.000缺失.000上图中的第三列(QCL_1)即为分类情况,说明如下:北辰区分为一类,标记为1;河东区、宝坻区、宁河县、蓟县分为一类,标记为2;南开区、河北区、津南区、武清区、静海县分为一类,标记为3;和平区、河西区、东丽区、西青区分为一类,标记为4;滨海新区为一类,标记为5;红桥区分为一类,标记为6 。
结果分析:分类结果从整体来看还是比较合理的。
滨海新区这一地区产值非常高,毫无疑问是单独的一类;红桥区产值最低,也分为一类,这个与我的直观感受不太相符,作为天津市市内六区之一的红桥区,产值最低,分为一类,我觉得很不可思议,问题可能是数据量不够大,或者说评价指标太少,这里我们只有一个评价指标(总产值),导致结果具有偶然性,适当增加评价指标应该可以增加结果的准确性。
输入各区县教育数据(中学数量和中学在校生以及教师数量)如下图:使用SPSS 对这三个变量进行K均值聚类分析,分为六类,得到如下结果:每个聚类中的案例数聚类1 1.0002 1.0003 2.0004 6.0005 1.0006 5.000有效16.000缺失 1.000上图中的第五列(QCL_1)即为分类情况,说明如下:滨海新区分为一类,标记为1;蓟县分为一类,标记为2;武清区、宝坻区分为一类,标记为3;和平区、河东区、河西区、南开区、河北区、宁河县分为一类,标记为4;静海县分为一类,标记为5;红桥区、东丽区、西青区、津南区、北辰区分为一类,标记为6 。

DCWTechnology Analysis技术分析93数字通信世界2024.021 大数据平台聚类分析系统架构设计1.1 功能架构设计用户聚类分析系统功能架构设计首先是创建聚类任务,根据相对应的核心条件(比如圈人条件以及调度频率等),待聚类任务运行完毕后创建clu s t e r level 数据便能够予以可视化呈现。
之后在可视化呈现的基础上通过人工予以再次标注,并予以再次聚合计算,如此便可生成tribe level 指标数据并用于用户分析。
如图1所示[1]。
1.2 技术架构设计(1)前端展示:具备与用户进行交互的功能。
用户通过该页面登录进入该聚类分析系统,之后用户进行的创建聚类任务、查看聚类结果等相关操作行为均在该模块范围内[2]。
(2)后端调度:该模块的核心职责是响应前端传输至此的全部请求,同时和数据库、HDFS 、Hive大数据平台聚类分析系统的设计与实现孙雪峰(首都经济贸易大学密云分校,北京 101500)摘要:互联网领域蕴含着海量的数据信息,且这些信息呈现出多样性以及复杂性,总体而言,可以大致将这些数据划分成用户行为数据和内容数据,科学精细地分析处理这些数据,是强化用户分群治理效率、内容分类研究以及实现精细化运营的重要手段。
但现阶段尚无一站式的大数据聚类分析系统可供人们使用,因此,文章详细分析和阐述了基于大数据平台的聚类分析系统设计与实现,以此为相关工作人员提供参考。
关键词:大数据;聚类分析;系统设计;系统实现doi:10.3969/J.ISSN.1672-7274.2024.02.031中图分类号:TP 311.13 文献标志码:A 文章编码:1672-7274(2024)02-0093-03Design and Implementation of Cluster Analysis System for Big Data PlatformSUN Xuefeng(Capital University of Economics and Trade, Miyun Branch, Beijing 101500, China)Abstract: The internet field contains a vast amount of data information, which presents diversity and complexity. Overall, this data can be roughly divided into user behavior data and content data, and scientifically and meticulously analyzed and processed. It is an important means to strengthen the efficiency of user group governance, research on content classification, and achieve refined operations. However, at present, there is no one-stop big data clustering analysis system available for the public to use. Therefore, this article conducts research on this topic, analyzes and elaborates in detail on the design and implementation of clustering analysis systems based on big data platforms, in order to provide reference for relevant staff.Key words: big data; cluster analysis; system design; system implementation作者简介:孙雪峰(1980-),男,北京人,讲师,博士研究生,研究方向为计算机应用技术专业、计算机网络与应用技术、新媒体与网络传播。

聚类分析教案怎么写标题:聚类分析教案撰写指南教案概述:聚类分析是一种数据挖掘技术,用于将相似的数据项组织成簇/群集。
本教案旨在帮助学生了解聚类分析的基本概念、原理和应用,以及学习如何使用常见的聚类算法进行数据分析和解释。
教学目标:1. 理解聚类分析的定义和目的。
2. 了解聚类分析的基本步骤和常见算法。
3. 掌握使用Python编程语言进行聚类分析的基本技巧。
4. 能够解释聚类分析结果并进行有效的数据应用。
教学准备:1. 电脑、投影仪和幻灯片。
2. 计算机编程软件(如Python)和相关聚类分析库。
3. 教学用例数据集。
教学步骤:引入阶段:1. 通过引用现实生活中的聚类案例,激发学生对聚类分析的兴趣和认识。
2. 提出问题:为什么需要聚类分析?聚类分析在哪些领域有应用?概念讲解阶段:3. 解释聚类分析的定义和目的,强调其在数据挖掘、模式识别和市场细分等领域的重要性。
4. 介绍聚类分析的基本步骤:数据准备、相似性度量、簇/群集生成和结果解释。
5. 示例讲解不同的聚类算法,如K均值聚类、密度聚类和层次聚类。
实践操作阶段:6. 使用Python编程语言演示如何进行聚类分析,包括数据加载、特征选择和聚类算法的应用。
7. 引导学生根据教学用例数据集,自己进行聚类分析实验,并记录分析结果。
结果解释阶段:8. 引导学生解释分析结果,包括簇的特征、相似性度量和簇的可解释性。
9. 讨论聚类分析的应用场景和限制,如何将其结果应用于实际问题。
课堂延伸:10. 引导学生进一步探索不同算法的优缺点和特点,如有监督聚类、非凸聚类等。
11. 鼓励学生自主学习其他聚类分析工具和应用案例,并进行报告分享。
教学评估:12. 布置练习作业,要求学生使用聚类分析技术解决特定问题并撰写实验报告。
13. 对学生的实验报告进行评估,并提供反馈和改进建议。
14. 综合考核学生对聚类分析的理解和应用能力,如组织小组讨论、开展实际项目等。
总结:在本节课中,学生将学会聚类分析的基本概念、原理和应用,并掌握使用Python进行聚类分析的技巧。
聚类分析的sas过程课程设计一、课程目标知识目标:1. 掌握聚类分析的基本概念和原理;2. 学习使用SAS软件进行聚类分析的过程和步骤;3. 了解不同聚类方法的优缺点及适用场景;4. 掌握对聚类结果进行解释和评价的方法。
技能目标:1. 能够运用SAS软件进行数据预处理,为聚类分析做好准备;2. 熟练操作SAS软件,运用合适的聚类方法对数据进行聚类分析;3. 学会对聚类结果进行可视化展示,并从中提取有价值的信息;4. 能够结合实际案例,运用聚类分析方法解决实际问题。
情感态度价值观目标:1. 培养学生对数据分析的兴趣,提高数据挖掘和统计分析的意识;2. 增强学生的团队协作能力,学会在团队中发挥个人特长,共同完成数据分析任务;3. 培养学生严谨的科学态度,注重实证研究,形成基于数据说话的习惯;4. 引导学生关注社会热点问题,运用所学知识为社会发展和决策提供支持。
课程性质:本课程为数据分析方向的专业课,旨在帮助学生掌握聚类分析方法,提高数据挖掘能力。
学生特点:学生具备一定的统计学基础和SAS软件操作能力,具有较强的学习兴趣和动手实践能力。
教学要求:结合课程性质和学生特点,采用案例教学、课堂讨论与实践操作相结合的教学方式,注重培养学生的实际操作能力和数据分析思维。
通过本课程的学习,使学生能够独立完成聚类分析任务,并为后续相关课程打下坚实基础。
二、教学内容1. 聚类分析基本概念:介绍聚类分析的定义、类型和基本原理,引导学生了解聚类分析在数据分析中的应用和价值。
2. 聚类方法选择:讲解常用的聚类方法(如K-means、系统聚类等),分析各种方法的优缺点及适用场景,帮助学生根据实际需求选择合适的聚类方法。
3. 数据预处理:介绍在聚类分析之前进行数据预处理的必要性,包括数据清洗、标准化、降维等操作,提高学生数据预处理的能力。
4. SAS软件操作:详细讲解SAS软件中进行聚类分析的步骤,包括数据导入、聚类过程调用、参数设置等,使学生熟练掌握SAS软件操作。
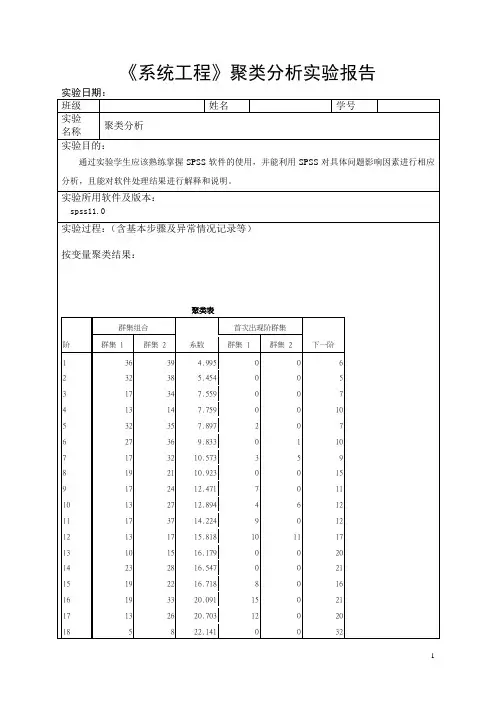
实验4 系统聚类分析(Hierarchical cluster analysis)实习环境要求:计算机及相关设备、SPSS统计软件实习目的:熟练运用SPSS软件进行系统聚类分析实习分组:每人一组,独立完成实验内容:聚类分析是直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。
聚类分析事先并不知道对象类别的面貌,甚至连共有几个类别也不确定。
一、数据准备课本71页,表3.4.2已经有该文件:表3.4.2某地区九个农业区的七项经济指标数据二、菜单命令如下:(Analyze>Classify>Hierarchical Cluster)1、系统聚类分析主界面设置如图选择要参加聚类的变量(Variable(s));选择对样品聚类(Cases默认)还是变量聚类(Variables)。
在样品聚类时,你还可以使用标签变量(Label Cases By:)来代替默认的记录号结果输出。
是否显示(Display)统计量(Statistics)和统计图(Plots),默认都显示。
2、按Method…按钮,进行设置2.1 Transform Values选择原始数据标准化方法如需要变换,一般做标准正态变换。
本例课本选择了极差标准化(Range 0 to 1)。
其他选项含义:None:不变换Z scores :标准正态变换,具体方法为(?):(X-mean)/sRange –1 to 1 :将数据范围转化为-1至1之间,具体方法为(?):[X-min-(max-min)/2]/ [(max-min)/2]Range 0 to 1 :将数据范围转化为0 至1之间,具体方法为:(X-min)/(max-min)。
即:极差标准化。
Maximum magnitude of 1:极大值标准化。
做最大值为1的转换,具体方法为:X/maxMean of 1:做均值为1的转换Standard deviation of 1做标准差为1的转换2.2 样本间距离的计算公式(Measure defines the formula for calculating distance.)对不同的数据类型有不同的计算公式,我们一般仅涉及间隔尺度数据,不涉及分类变量的计数数据和二元数据。
系统聚类分析课程设计系统聚类分析课程设计《空间分析》系统聚类算法及编程实现学院:地质工程与测绘学院专业:遥感科学与技术班级:2011260601 学号: 学生姓名:指导老师:目录第1章前言第2章算法设计背景2.1聚类要素的数据处2.2距离的计算第3章算法思想与编程实现3.1算法思3.2用Matlab编程实3.2.1程序代322编程操作结果4.1 K .均值聚类法的应用4.2 K.均值聚类法的优缺点 (14)第5章课程设计总结 (14)主要参考文献 (15)第一章前言本课题是根据李斌老师所教授的《空间分析》课程内容及要求而选定的,是对于系统聚类算法的分析研究及利用相关软件的编程而实现系统聚类。
研究的是系统聚类算法的分析及编程实现,空间聚类的目的是对空间物体的集群性进行分析,将其分为几个不同的子群(类)。
子群的形成的是地理系统运作的结果,根据此可以揭示某种地理机制。
此外,子群可以作为其它分析的基础,例如,公共设施的建立一般地说是根据居民点群的分布,而不是具体的居民住宅的分布来布置的,因此需要对居民点群进行聚类分析以形成若干居民点子群,这样便于简化问题,突出重点。
空间聚类可以采用不同的算法过程。
在分析之初假定n 个点自成一类,然后逐步合并,这样在聚类的过程中,分类将越来越少,宜至聚至一个适当的分类数目,这一聚类过程称之为系统聚类。
常见的聚类分析方法有系统聚类法、动态聚类法和模糊聚类法等。
下面主要介绍系统聚类算法,并基于Matlab 软件用K-means 算法(即k-均值算法)来实现系统聚类的算法编程。
第二章算法设计背景2. 1聚类要素的数据处理假设有m 个聚类的对象,每一个聚类对象都有个要素构成。
它们所对应的要素数据可用表3.4.1给出。
在聚类分析中,常用的聚类要素的数据处理方法有如下几种。
第4章K .均值算法应用与优缺点1313①总和标准化②标准差标准化③极大值标准化经过这种标准化所得的新数据,各要素的极大值为1,其余各数值小于L ④极差的标准化经过这种标准化所得的新数据,各要素的极大值为1,极小值为0,其余的数值均在。
系统聚类分析课程设计《空间分析》系统聚类算法及编程实现学院:地质工程与测绘学院专业:遥感科学与技术班级:2011260601 学号: 学生姓名:指导老师:目录第1章前言第2章算法设计背景2.1聚类要素的数据处2.2距离的计算第3章算法思想与编程实现3.1算法思3.2用Matlab编程实3.2.1程序代322编程操作结果4.1 K .均值聚类法的应用4.2 K.均值聚类法的优缺点 (14)第5章课程设计总结 (14)主要参考文献 (15)第一章前言本课题是根据李斌老师所教授的《空间分析》课程内容及要求而选定 的,是对于系统聚类算法的分析研究及利用相关软件的编程而实现系统聚 类。
研究的是系统聚类算法的分析及编程实现,空间聚类的目的是对空间 物体的集群性进行分析,将其分为几个不同的子群(类)。
子群的形成的 是地理系统运作的结果,根据此可以揭示某种地理机制。
此外,子群可以 作为其它分析的基础,例如,公共设施的建立一般地说是根据居民点群的 分布,而不是具体的居民住宅的分布来布置的,因此需要对居民点群进行 聚类分析以形成若干居民点子群,这样便于简化问题,突出重点。
空间聚类可以采用不同的算法过程。
在分析之初假定n 个点自成一类,然 后逐步合并,这样在聚类的过程中,分类将越来越少,宜至聚至一个适当的 分类数目,这一聚类过程称之为系统聚类。
常见的聚类分析方法有系统聚类 法、动态聚类法和模糊聚类法等。
下面主要介绍系统聚类算法,并基于Matlab 软件用K-means 算法(即k-均值算法)来实现系统聚类的算法编程。
第二章算法设计背景2. 1聚类要素的数据处理假设有m 个聚类的对象,每一个聚类对象都有个要素构成。
它们所对应 的要素数据可用表3.4.1给出。
在聚类分析中,常用的聚类要素的数据处 理方法有如下几种。
第4章K .均值算法应用与优缺点1313①总和标准化②标准差标准化③极大值标准化经过这种标准化所得的新数据,各要素的极大值为1,其余各数值小于L ④极差的标准化经过这种标准化所得的新数据,各要素的极大值为1,极小值为0,其余的数值均在。
与1之间。
2. 2距离的计算距离是事物之间差异性的测度,差异性越大,则相似性越小,所以距离是系统聚类分析的依据和基础。
选择不同的距离,聚类结果会有所差异。
在地理分区和分类研究中,往往采用几种距离进行计算、对比,选择一种较为合适的距离进行聚类。
第三章算法思想与编程实现3. 1算法思想我们己经指出系统聚类方法首先将n个空间点看做是n个子群,然后根据所选用的聚类统计量来计算n个子群之间的关系。
对于距离,计算n个子群两两之间的距离,首先选择距离最近的两个子群(点)归为一个新的子群,这样就得到n-1个子群两两之间的聚类统计量,继续选择距离最近的子群合并,再得到n-2个子群……,依此类推,直到所有的子群全部合并。
K^neans算法是硬聚类算法,是典型的局域原型的目标函数聚类方法的代表,它是数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则。
K-means算法以欧式距离作为相似度测度,它是求对应某一初始聚类中心向量V最有分类,使得评价指标J最小。
算法采用误差平方和准则函数作为聚类准则函数。
K-均值算法的聚类准则是使每一聚类中,多模式点到该类别的中心的距离的平方和最小。
其基本思想是:通过迭代,主次移动各类的中心,直到得到最好的聚类为止。
其算法框图如图所示。
具体的计算步骤如下:假设图像上的目标要分为m类,m为己知数。
第一步:适当地选取皿个类的初始中心・・・,Z炒,初始中心的选择对聚类结果有一定的影响,初始中心的选择一般有如下几种方法:1)根据问题的性质和经验确定类别数m,从数据中找出直观上看来比较适合的m个类的初始中心。
2)将全部数据随即地分为m个类型,计算每类的重心,将这些重心作为m个类的初始中心。
第二步:在第k次迭代中,对任一样本X按如下的方法把它调整到m个类别中的某一类别中去。
对于所有的i j, i = 1,2, ・・・,m,如果〃X-Z^/7 < 〃X-Z9〃,则XWS产其中S产是以Z严为中心的类。
第三步:由第二步得到类新的中心N j式中,N,为S产类中的样本数。
Z严)是按照使J最小的原则确定的,J的表达式为:j^Ejkzrii第四步:对于所有的i=l,2…,m,如果ZL*,则迭代结束,否则转到第二步继续迭代。
这种算法的结果受到所选聚类中心的数目和其初始位置以及模式分布的几何性质和读入次序等因素的影响,并且在迭代过程中又没有调整类数的措施,因此可能产生不同的初始分类得到不同的结果,这是这种方法的缺点。
可以通过其他的简单的聚类中心试探方法,如最大距离法,找出初始中心,提高分类效果。
3.2用Mat lab编程实现3. 2.1程序代码对于上述的K-mean算法用Matlab软件实现编程并调用数据小的图片进行聚类分析及编程是否正确性的检测。
具体程序代码如下:%%读取图片Imag = imread('hand, jpg。
;sample = rgb2gray (Imag);[m n] = size (sampIe);sample = reshape (sample, m*n f 1); 渊只能读取三个波段%%将彩色图片转换为灰度图片%我读取图片的维数%%将矩阵变换为m*n行1列的向量k = 4; %%分成4类t = 0;%%控制循环次数flag = 0;燧一个和samp I e等维数的标记向・ocentrel = 80;%%选取第1类聚类中心ocentre2 = 160;%%选取第2类聚类中心ocentre3 = 220;%%选取第3类聚类中心ocentre4 = 255;%%选取第4类聚类中心samp I e = doub I e (samp I e) ; %北将u i nt8 类型转换为doub I e 型wh iIe t = 0%fsample1 = 0;%fsamp Ie2 = 0;%fsamp Ie3 = 0;%fsamp Ie4 = 0;fsample = zeros (4,1);num = zeros (4t 1);dis = zeros(1,4);for i = 1:m*n%a = 5 - 2;%b = 2 - 5;dis(1) = abs(sample(i) - ocentrel); %%求到第 1 个聚类中心距离dis(2) = abs (sampled) - ocentre2); %%求到第 2 个聚类中心距离d i s (3) = abs (samp Ie (i) - ocentre3): %%求到第 3 个聚类中心距离dis(4) = abs(sample(i) - ocentre4); 求到第4个聚类中心距离mindis = min([dis(1) dis(2) dis(3) dis(4)]) ; %%求最小的距离则给dis2 %选取最小值,第一个值给dis1,第二个值给dis2,判断dis2<dis1f值于dis1,计算第三个距离给dis2,返回第三步,循环sw i tch mindiscase dis(1)%flag = cat(1,flag.1); %%将标记数组赋值1,该点属于第1类%fsampIe1 = cat(1, fsampIe1sample(i));rflag ⑴=1;fsample(1) = fsampIe(1) + sample(i):num (1) = num(1) + 1;case d i s (2)%flag = cat(1,flag, 2); %%将标记数组赋值2,该点属于第2类%fsamp Ie2 = cat(1, fsampI e2f samp Ie(i));flag(i) = 2;f samp I e (2) = f samp I e (2) + samp I e (i);num (2) = num (2) + 1:case d i s (3)%flag = cat (1, fl ag. 3); %%将标记数组赋值3,该点属于第3类%fsamp Ie3 = cat(1, fsamp Ie3y samp Ie (i));flag ⑴=3;f samp I e (3) = f samp I e (3) + sample (i);num (3) = num (3) + 1;case d i s (4)%flag = cat (1,fl ag, 4); %%将标记数组赋值4,该点属于第4类XfsampIe4 = cat (1 f fsampIe4, sample(i));flag(i) = 4;fsampIe(4) = fsampIe(4) + sample(i):num ⑷=num ⑷ + 1;endend%%重新计算聚类中心%[m1 n1] = size(fsamplel):%[m2 n2] = s i ze (fsampIe2);% [m3 n3] = s i ze (f samp I e3):%[m4 n4] = s i ze (f samp I e4):%ncentre1 = sum (fsample1)/(m1 - 1);%ncentre2 = sum(fsamp Ie2)/(m2 - 1);%ncentre3 = sum (fsamp Ie3)/(m3 - 1);%ncentre4 = sum(fsamp Ie4) /(m4 -1);%flag%fsampIencentrel = fsample(1)/num(1):ncentre2 = fsamp Ie(2)/num(2):ncentre3 = fsamp I © (3)/num (3):ncentre4 = fsamp Ie (4)/num (4):沛lag ⑴=[];if ncentrel = ocentrel && ncentre2 = ocentre2...&& ncentre3 = ocentre3 && ncentre4 = ocentre4 for i = 1:m*n switch flag(i)case 1samp Ie (i) = 60;case 2samp Ie(i) =120;case 3samp le (i) = 180;case 4samp 16 (i) = 240;endendt = 1;elseocentrel = ncentrel;ocentre2 = ncentre2;ocentre3 = ncentre3;ocentre4 = ncentre4;endendsample = uint8 (sample);samp I e = reshape (samp I e9 n);imshow(sample);3. 2. 2编程操作结果实验调用前图片:实验调用后结果截图图片:第四章K-均值算法应用与优缺点4.1K-均值聚类法的应用①在机械设备铁路监测技术中的应用。