试验数据处理
- 格式:ppt
- 大小:3.84 MB
- 文档页数:60

临床试验数据处理流程
一、数据收集
1.设定数据收集计划
(1)确定收集数据的时间点和方法
2.收集临床试验数据
(1)记录患者信息、治疗方案、观察结果等
二、数据录入
1.设定数据录入规范
(1)确定数据录入格式和要求
2.录入数据
(1)将收集到的数据录入电子表格或数据库
三、数据清洗
1.核对数据准确性
(1)检查数据是否完整和准确
2.处理缺失数据
(1)填补缺失数据或进行合理处理
四、数据分析
1.制定分析方案
(1)确定数据分析方法和工具
2.进行数据统计分析
(1)分析数据关联性、统计指标等
五、结果解读
1.解读数据分析结果
(1)分析数据背后的医学意义
2.撰写数据报告
(1)撰写临床试验数据报告
六、数据存档
1.存储数据
(1)将数据存档备份
2.归档文件
(1)确保数据文件整理有序并归档。

实验数据处理分析组:李学章李超杨春梅张雪2015年3月29日实验数据处理分析人员在任何一个工作环节都离不开数据,存在两个问题需要解决:一个是怎样测、读数据、应该记录几位数?另一个是怎样评价分析结果?一、有效数字及其位数1、有效数字:分析测定中实际能测量到的数字,包括所有准确数字和最后一位估计的不准确数字。
例如:0.2374g 12.35mL2、“零”的作用:定位作用和作为有效数字。
3、“零”的意义:①“零”在具体数字前,只起定位作用,不作有效数字。
例如:0.3378g、0.0326g。
②“零”在具体数字中间或后面,都作有效数字。
例如:1.2057g、1.33200g③以“零”结尾的正整数,其有效数字不确定。
例如:1200(2、3或4位)二、有效数字的修约规则一次修约到底,四舍六入五成双。
即①所谓“四舍”:当尾数≤4时,舍去尾数;例如:12.354→12.35(保留4位)②所谓“六入”:当尾数≥6时,向左进一位;例如:3.6787→3.679(保留4位)③所谓“五成双”:当尾数等于5时,5后有具体数就进1;5后没有数时看单双,若保留下来的未位数是奇数,则进位,若保留下来的未位数是偶数,则将5舍去。
总之,应保留偶数。
例如:将下列数修约为两位有效数字。
0.205→0.200.315→0.320.325→0.323.148→3.17.3976→7.474.51→75例如:将11.4565修约为两位有效数字,应一次修约为11,而不能进行多次修约,把11.4565→11.456(一次修约)→11.46(二次修约)→11.5(三次修约)→12(四次修约),得出错误的结果。
三、有效数字的运算法则1、加减法运算法则:几个有效数字相加或相减,其和或差的有效数字位数以小数点后位数最少的数字为准。
例如:23.36+5.120+3.05843=23.36+5.12+3.06=31.5421.25-3.206=21.25-3.21=18.042、乘除法运算法则:几个有效数字相乘或相除,其积或商的有效数字位数以有效数字位数最少的数字为准。

工程试验数据分析与处理一、前言在工程实验中,数据分析与处理是不可缺少的一环。
本文将重点讨论工程试验数据的处理方法,以及如何分析数据,提取有用信息。
二、数据预处理在进行数据分析之前,数据预处理至关重要。
数据预处理的目的是将原始数据转换成可用于分析的数据。
常见的数据预处理方法包括数据清理、数据编码、数据缺失值处理、数据归一化等。
2.1 数据清理数据清理是指对原始数据进行清除无关数据、填补错漏数据、转换格式等操作,以保证数据的质量和可用性。
数据清理可以采用编程软件如MATLAB等进行自动化处理,也可以采用手动方法进行处理。
2.2 数据编码数据编码是指将原始数据转换成适合计算机处理的形式,并保证其可被识别和分析。
常见的数据编码方法包括二进制编码、BCD码等。
2.3 数据缺失值处理数据缺失值处理是指在数据预处理过程中发现某些数据值缺失或不完整,需要采用相应方法进行填补。
数据缺失值处理的方法有很多,如简单平均法、回归分析、插值法等。
2.4 数据归一化数据归一化是指将不同量纲的数据转化为具有相同量纲的数据,以便于进行比较和分析。
数据归一化包括线性归一化、标准归一化等。
三、数据分析方法数据分析是指对收集的数据进行处理、分析,并从中提取有用的信息。
数据分析方法有很多,常见的有统计分析、数据挖掘、机器学习等。
3.1 统计分析统计分析是把大量的随机数据按某种特定规律加以整理、分析和解释的一种科学方法。
常见的统计分析方法包括描述统计分析、假设检验、回归分析等。
3.2 数据挖掘数据挖掘是通过大量数据的分析,发掘其中隐藏的模式与规律,以发掘有用的信息。
数据挖掘包括分类、聚类、关联规则挖掘等。
3.3 机器学习机器学习是一种人工智能分支,它旨在让计算机通过学习数据和经验,来自我学习并提高性能。
常见的机器学习方法包括监督学习、无监督学习、强化学习等。
四、数据可视化数据可视化是将数据以图形、表格等方式呈现,以便于理解和分析。
数据可视化方法包括柱状图、折线图、散点图、饼图、雷达图等。


任务6 试验数据分析与处理((再仔细查找一下))一、试验检测数据分析与处理1.概念(1)总体:研究对象的全体。
构成总体的每个单位称为个体。
(2)样本:总体的一部分。
样本所含的个体数,称为样本容量。
从总体中抽取样本称为抽样。
若总体中每个个体被抽取的可能性相同,这样的抽样称为随机抽样,所获得的样本称为随机样本。
2.算术平均值算术平均值是表示一组数据集中位置最有用的统计特征量,经常用样本的算术平均值来代表总体的平均水平。
总体的算术平均值用μ表示,样本的算术平均值则用表示。
如果n个样本数据为x1、x2、…、xn,那么,样本的算术平均值为:x̅=1n(x1+x2+⋯+x n)=1n∑x ini=13.加权平均值若对同一物理量用不同的方法或对同一物理量用不同的人去测定,测定的数据可能会受到某种因素的影响,这种影响的权重必须给予考虑,一般采用加权平均的方法进行计算。
表达方法:W=W1x2+W2x2+⋯+W n x n W1+W2+⋯+W n4.中位数在一组数据x1、x2、…、xn中,按其大小次序排序,以排在正中间的一个数表示总体的平均水平,称之为中位数,或称中值。
n为奇数时,正中间的数只有一个;n为偶数时,正中间的数有两个,则取这两个数的平均值作为中位数,即:x̅={x n+1212(x n2+x n2+1)5.极差在一组数据中最大值与最小值之差,称为极差,记作R:R=X max−X min6.标准偏差标准偏差有时也称标准离差、标准差或称均方差,它是衡量样本数据波动性(离散程度)的指标。
在质量检验中,总体的标准偏差σ一般不易求得。
样本的标准偏差S按下式计算:s=√(x1−x̅)2+(x2−x̅)2+⋯+(x n−x̅)2n−1=√∑(x i−x̅)2ni=1n−17.变异系数标准偏差是反映样本数据的绝对波动状况,当测量较大的量值时,绝对误差一般较大;而测量较小的量值时,绝对误差一般较小,因此,用相对波动的大小,即变异系数更能反映样本数据的波动性。
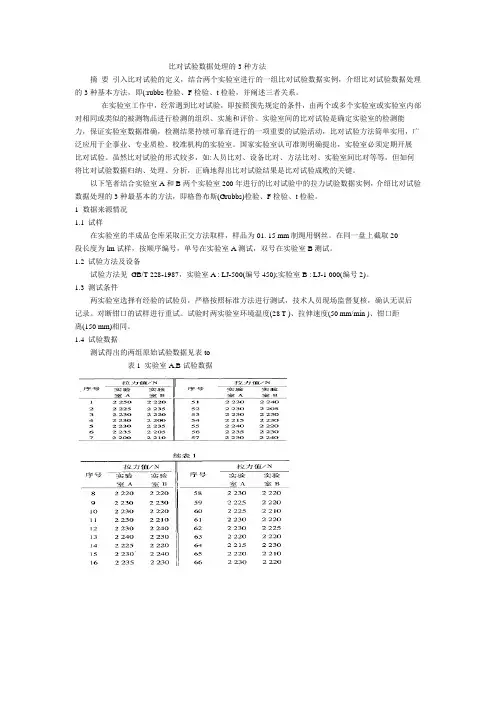
比对试验数据处理的3种方法摘要引入比对试验的定义,结合两个实验室进行的一组比对试验数据实例,介绍比对试验数据处理的3种基本方法,即(:rubbs检验、F检验、t检验,并阐述三者关系。
在实验室工作中,经常遇到比对试验,即按照预先规定的条件,由两个或多个实验室或实验室内部对相同或类似的被测物品进行检测的组织、实施和评价。
实验室间的比对试验是确定实验室的检测能力,保证实验室数据准确,检测结果持续可靠而进行的一项重要的试验活动,比对试验方法简单实用,广泛应用于企事业、专业质检、校准机构的实验室。
国家实验室认可准则明确提出,实验室必须定期开展比对试验。
虽然比对试验的形式较多,如:人员比对、设备比对、方法比对、实验室间比对等等,但如何将比对试验数据归纳、处理、分析,正确地得出比对试验结果是比对试验成败的关键。
以下笔者结合实验室A和B两个实验室200年进行的比对试验中的拉力试验数据实例,介绍比对试验数据处理的3种最基本的方法,即格鲁布斯(Grubbs)检验、F检验、t检验。
1 数据来源情况1.1 试样在实验室的半成品仓库采取正交方法取样,样品为01. 15 mm制绳用钢丝。
在同一盘上截取20段长度为lm试样,按顺序编号,单号在实验室A测试,双号在实验室B测试。
1.2 试验方法及设备试验方法见GB/T 228-1987,实验室A : LJ-500(编号450);实验室B : LJ-1 000(编号2)。
1.3 测试条件两实验室选择有经验的试验员,严格按照标准方法进行测试,技术人员现场监督复核,确认无误后记录。
对断钳口的试样进行重试。
试验时两实验室环境温度(28 T )、拉伸速度(50 mm/min )、钳口距离(150 mm)相同。
1.4 试验数据测试得出的两组原始试验数据见表to表1 实验室A,B试验数据2 数据处理的方法步骤2.1 基本统计处理对两组原始试验数据进行基本的统计计算,求出最大值、最小值、平均值、极差、标准偏差等,结果见表2。

实验数据记录与处理一、 实验数据记录在电路实验中,实验数据主要来源于测量仪器和设备的读数,因此,对于指针式仪表和数字式仪表的读数要根据具体仪器和设备而定。
对于使用指针式仪表测量时,直接读取的指针式仪表的指示值一般不是被测量的测量值,而是要经过换算才可得到所需的测量结果,尤其是在具有多量程的指针式仪表中,更应该注意不同量程下每个标度尺分格所代表的数值大小。
指针式仪表的指示值称为直接读数,简称读数,是指示式仪表指针所指出的标尺值,通常用格数表示。
但是,要准确读取测量值的大小,还需要确定指针式仪表的标度尺每分格所代表的被测量的大小,即要确定分格常数,其计算公式为:分格常数=仪表量程/仪表满刻度格数可以看出,对于统一仪表,选择的量程不同则分格常数也不同。
被测量的测量值可以由下式计算得出:测量值=读数(格)×分格常数应注意,测量值的有效数字的位数应与读数的有效数字的位数一致。
对于使用数字式仪表测量时,通常可以直接读出被测量的量值,读出值即可作为测量结果予以记录而无须再经换算。
需要指出的是,对数字式仪表而言,若测量时量程选择不当,则会丢失有效数字,因此,应合理地选择数字式仪表的量程。
实际测量时一般是使被测量值小于但接近于所选择的量程,而不可以选择过大的量程。
在实验数据读取时,当实验条件和测试仪器设备确定的情况下,不论采用指针式仪表还是采用数字式仪表,都应当尽可能获得较多的有效数字位数,以便在处理数据和误差分析中获得更多的信息,给出更加准确的实验结果。
二、 测量数据的处理进行实验时,通常有两个目的,一是欲知某个基本电路或整个电路系统的工作状态,及电路的运行情况;二是了解电路或整个系统的特性,亦当某些条件(如输入频率、幅度、负载、时间等)改变时,系统会出现什么反应。
不管是哪种目的,首先都需要获取足够的原始数据,然后对这些原始数据进行加工、整理、分析,才能做出结论。
因此,实验时仅获得一些测量数据还远达不到实验目的,还必须对其进行处理。

混凝土试验数据处理方法一、引言混凝土是建筑业中非常重要的材料,其强度、耐久性以及其他物理机械性质的测试和分析对于建筑物的质量和安全至关重要。
因此,正确的混凝土试验数据处理方法是建筑工程质量保证的重要组成部分,本文将详细介绍混凝土试验数据处理方法。
二、混凝土试验数据的收集与处理1.试件的准备混凝土试件的准备是混凝土试验中非常重要的一步,其质量直接影响混凝土试验数据的准确性。
试件应按照规范要求制备,制备时应注意混凝土的水灰比、配合比、搅拌时间等因素的影响。
同时应注意试件的尺寸、标记和编号等信息的记录。
试件制备完毕后,应在规定的湿度和温度下养护。
2.试验数据的收集试验数据的收集应在试件养护完毕后进行,试验数据的收集包括试件的尺寸、质量、强度等指标的测试,同时应记录试验数据的时间、地点、试验人员等信息。
试验数据的收集应严格按照规范要求进行,以确保数据的准确性。
3.试验数据的处理试验数据处理是混凝土试验中非常重要的环节,其目的是计算混凝土强度等物理机械性质的指标,判断试件的质量和强度是否符合要求。
试验数据的处理主要包括数据的整理、分析和计算等步骤。
三、混凝土试验数据处理方法1.试验数据的整理试验数据的整理是指对试验数据进行初步分类、汇总和整理,以便进行后续分析和计算。
试验数据的整理主要包括试件编号、试验时间、试件尺寸、试件质量、试验结果等信息的记录。
试验数据的整理应按照规范要求进行,以确保数据的可靠性和准确性。
2.试验数据的分析试验数据的分析是指对试验数据进行初步的统计和分析,以确定试件的强度等物理机械性质的指标。
试验数据的分析主要包括试件的平均强度、标准差、变异系数等指标的计算。
试验数据的分析应按照规范要求进行,以确保数据的可靠性和准确性。
3.试验数据的计算试验数据的计算是指根据试验数据进行混凝土强度等物理机械性质的指标计算。
试验数据的计算主要包括试件的抗压强度、抗拉强度、抗弯强度等指标的计算。
试验数据的计算应按照规范要求进行,以确保数据的可靠性和准确性。


试验数据处理方法
试验数据处理方法是一种系统的处理方法,旨在评估并分析实验数据的有效性和准确性。
以下是一些常用的试验数据处理方法:
1. 数据清洗:验证数据的完整性和准确性,去除异常值和错误数据,修正缺失数据。
可以使用统计方法、数据模型和算法等技术进行数据清洗。
2. 数据整理:将实验数据整理成适合分析的格式,例如数据表格或矩阵。
整理过程包括对数据进行排序、合并、分组和重塑等操作。
3. 描述性统计分析:对试验数据进行统计描述,包括计算平均值、中位数、标准差、方差等统计指标。
描述性统计可以帮助了解数据的分布情况和基本特征。
4. 探索性数据分析:通过绘制图表、做出可视化展示,探索试验数据的特征和关系。
常用的探索性数据分析方法包括直方图、散点图、箱线图等。
5. 假设检验和显著性分析:根据已有的假设,使用统计推断的方法判断实验数据的显著性。
常用的假设检验方法包括t检验、方差分析、卡方检验等。
6. 相关性分析:分析试验数据之间的相关关系,即一个变量如何随着另一个变量的变化而变化。
常用的相关性分析方法包括皮尔逊相关系数、斯皮尔曼相关系数等。
7. 回归分析:建立和评估变量之间的数学模型,用于预测和解释变量之间的关系。
常见的回归分析方法有线性回归、非线性回归、多元回归等。
8. 实验设计和优化:根据试验目标和限制条件,设计合适的实验方案,使得试验结果可以得到有效的解释和应用。
优化方法可以使用因子设计、响应曲面分析等。
以上是一些常用的试验数据处理方法,具体的方法选择和实施要根据试验目标、数据类型和问题背景等因素进行决定。
