应用回归分析-第8章课后习题参考答案
- 格式:doc
- 大小:406.50 KB
- 文档页数:19

第一章测试1【多选题】(2分)当一个经济问题的回归模型通过了各种统计检验,且模型具有合理的经济意义时,该回归模型就可用于A.经济变量的因素分析B.模型的显著性检验C.进行经济预测D.给定被解释变量值来控制解释变量值2【判断题】(2分)常用的样本数据有时间序列数据和横截面数据。
A.错B.对3【多选题】(2分)随机误差项主要包括以下哪些因素的影响?A.其他随机因素B.样本采集过程中的测量误差C.由于人们认识的局限性或时间、费用、数据质量等的约束未引入回归模型但又对回归被解释变量有影响的因素D.理论模型的设定误差4【判断题】(2分)变量间具有密切关联而又不能由某一个或某一些变量确定另外一个变量的关系称为变量间的统计关系。
A.对B.错5【单选题】(2分)进行回归分析时,假定相关的两个变量()。
A.都不是随机变量B.一个是随机变量,一个不是随机变量C.都是随机变量D.随机或非随机都可以第二章测试1【单选题】(2分)总体平方和SST、残差平方和SSE、回归平方和SSR三者之间的关系是()。
A.SSE=SSR-SSTB.SST=SSR+SSEC.SSR=SST+SSED.SSE=SSR+SST2【单选题】(2分)反映由模型中解释变量所解释的那部分离差大小的是()。
A.残差平方和B.总体平方和C.回归平方和D.样本平方和3【多选题】(2分)古典线性回归模型的普通最小二乘估计量的特性有()。
A.无偏性B.不一致性C.最小方差D.线性4【判断题】(2分)一元线性回归分析中的回归平方和SSR的自由度是1。
A.错B.。

第二章 一元线性回归分析思考与练习参考答案2.1 一元线性回归有哪些基本假定?答: 假设1、解释变量X 是确定性变量,Y 是随机变量;假设2、随机误差项ε具有零均值、同方差和不序列相关性: E(εi )=0 i=1,2, …,n Var (εi )=σ2 i=1,2, …,n Cov(εi, εj )=0 i≠j i,j= 1,2, …,n假设3、随机误差项ε与解释变量X 之间不相关: Cov(X i , εi )=0 i=1,2, …,n假设4、ε服从零均值、同方差、零协方差的正态分布 εi ~N(0, σ2 ) i=1,2, …,n 2.2 考虑过原点的线性回归模型 Y i =β1X i +εi i=1,2, …,n误差εi (i=1,2, …,n)仍满足基本假定。
求β1的最小二乘估计 解:21112)ˆ()ˆ(ini i ni i i e X Y Y Y Q β∑∑==-=-=得:2.3 证明(2.27式),∑e i =0 ,∑e i X i =0 。
证明:∑∑+-=-=nii i ni X Y Y Y Q 121021))ˆˆ(()ˆ(ββ其中:即: ∑e i =0 ,∑e i X i =02.4回归方程E (Y )=β0+β1X 的参数β0,β1的最小二乘估计与最大似然估计在什么条件下等价?给出证明。
答:由于εi ~N(0, σ2 ) i=1,2, …,n所以Y i =β0 + β1X i + εi ~N (β0+β1X i , σ2 ) 最大似然函数:)()(ˆ1211∑∑===ni ini ii XY X β01ˆˆˆˆi ii i iY X e Y Y ββ=+=-0100ˆˆQQββ∂∂==∂∂使得Ln (L )最大的0ˆβ,1ˆβ就是β0,β1的最大似然估计值。
同时发现使得Ln (L )最大就是使得下式最小,∑∑+-=-=nii i ni X Y Y Y Q 121021))ˆˆ(()ˆ(ββ上式恰好就是最小二乘估计的目标函数相同。


《应用回归分析》部分课后习题答案第一章回归分析概述1.1 变量间统计关系和函数关系的区别是什么?答:变量间的统计关系是指变量间具有密切关联而又不能由某一个或某一些变量唯一确定另外一个变量的关系,而变量间的函数关系是指由一个变量唯一确定另外一个变量的确定关系。
1.2 回归分析与相关分析的联系与区别是什么?答:联系有回归分析和相关分析都是研究变量间关系的统计学课题。
区别有 a.在回归分析中,变量y称为因变量,处在被解释的特殊地位。
在相关分析中,变量x和变量y处于平等的地位,即研究变量y与变量x的密切程度与研究变量x与变量y的密切程度是一回事。
b.相关分析中所涉及的变量y与变量x全是随机变量。
而在回归分析中,因变量y是随机变量,自变量x可以是随机变量也可以是非随机的确定变量。
C.相关分析的研究主要是为了刻画两类变量间线性相关的密切程度。
而回归分析不仅可以揭示变量x对变量y的影响大小,还可以由回归方程进行预测和控制。
1.3 回归模型中随机误差项ε的意义是什么?答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究y与x1,x2…..xp的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
1.4 线性回归模型的基本假设是什么?答:线性回归模型的基本假设有:1.解释变量x1.x2….xp是非随机的,观测值xi1.xi2…..xip是常数。
2.等方差及不相关的假定条件为{E(εi)=0 i=1,2…. Cov(εi,εj)={σ^23.正态分布的假定条件为相互独立。
4.样本容量的个数要多于解释变量的个数,即n>p.1.5 回归变量的设置理论根据是什么?在回归变量设置时应注意哪些问题?答:理论判断某个变量应该作为解释变量,即便是不显著的,如果理论上无法判断那么可以采用统计方法来判断,解释变量和被解释变量存在统计关系。

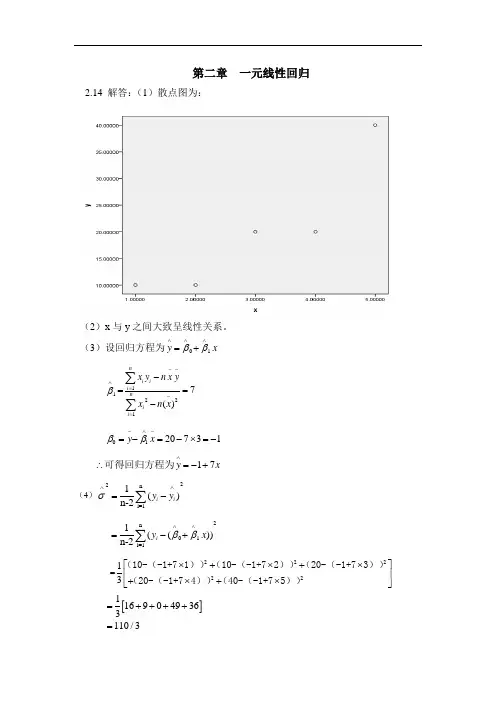
第二章 一元线性回归2.14 解答:(1)散点图为:(2)x 与y 之间大致呈线性关系。
(3)设回归方程为01y x ββ∧∧∧=+1β∧=12217()ni ii nii x y n x yxn x --=-=-=-∑∑0120731y x ββ-∧-=-=-⨯=-17y x ∧∴=-+可得回归方程为(4)22ni=11()n-2i i y y σ∧∧=-∑ 2n 01i=11(())n-2i y x ββ∧∧=-+∑=2222213⎡⎤⨯+⨯+⨯⎢⎥+⨯+⨯⎣⎦(10-(-1+71))(10-(-1+72))(20-(-1+73))(20-(-1+74))(40-(-1+75)) []1169049363110/3=++++=6.1σ∧=(5)由于211(,)xxN L σββ∧t σ∧==服从自由度为n-2的t 分布。
因而/2||(2)1P t n αασ⎡⎤⎢⎥<-=-⎢⎥⎣⎦也即:1/211/2(p t t ααβββ∧∧∧∧-<<+=1α-可得195%β∧的置信度为的置信区间为(7-2.3537+2.353 即为:(2.49,11.5)2201()(,())xxx Nn L ββσ-∧+t ∧∧==服从自由度为n-2的t 分布。
因而/2|(2)1P t n αα∧⎡⎤⎢⎥⎢⎥<-=-⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦即0/200/2()1p βσββσα∧∧∧∧-<<+=- 可得195%7.77,5.77β∧-的置信度为的置信区间为()(6)x 与y 的决定系数22121()490/6000.817()ni i nii y y r y y ∧-=-=-==≈-∑∑(7)由于(1,3)F F α>,拒绝0H ,说明回归方程显著,x 与y 有显著的线性关系。
(8)t σ∧==其中2221111()22n ni i i i i e y y n n σ∧∧====---∑∑ 7 3.661==≈/2 2.353t α= /23.66t t α=>∴接受原假设01:0,H β=认为1β显著不为0,因变量y 对自变量x 的一元线性回归成立。


第八章 相关分析与回归分析习题参考答案一、名词解释函数关系:函数关系亦称确定性关系,是指变量(现象)之间存在的严格确定的依存关系。
在这种关系中,当一个或几个相互联系的变量取一定的数值时,必定有另一个且只有一个变量有确定的值与之对应。
相关关系:是指变量(现象)之间存在着非严格、不确定的依存关系。
在这种关系中,当一个或几个相互联系的变量取一定的数值时,可以有另一变量的若干数值与之相对应。
这种关系不能用完全确定的函数来表示。
相关分析:相关分析主要是研究两个或者两个以上随机变量之间相互依存关系的方向和密切程度的方法,直线相关用相关系数表示,曲线相关用相关指数表示,多元相关用复相关系数表示。
回归分析:回归分析是研究某一随机变量关于另一个(或多个)非随机变量之间数量关系变动趋势的方法。
其目的在于根据已知非随机变量来估计和预测随机变量的总体均值。
单相关:单相关是指仅涉及两个变量的相关关系。
复相关:复相关是指一个变量对两个或者两个以上其他变量的相关关系。
正相关:正相关是指两个变量的变化方向是一致的,当一个变量的值增加(或减少)时,另一变量的值也随之增加(或减少)。
负相关:负相关是指两个变量的变化方向相反,即当一个变量的值增加(或减少)时,另一个变量的值会随之减少(或增加)。
线性相关:如果相关的两个变量对应值在直角坐标系中的散点图近似呈一条直线,则称为线性相关。
非线性相关:如果相关的两个变量对应值在直角坐标系中的散点图近似呈现出某种曲线形式,则为非线性相关。
相关系数:相关系数是衡量变量之间线性相关密切程度及相关方向的统计分析指标。
取值在-1到1之间。
两个变量之间的简单样本相关系数的计算公式为:()()niix x y y r --∑二、单项选择1.B;2.D;3.D;4.C;5.A;6.D 。
三、判断题(正确的打“√”,错误的打“×”) 1.×; 2.×; 3.√; 4.×; 5.×; 6.×; 7.×; 8.√. 四、简答题1、什么是相关关系?相关关系与函数关系有什么区别?答:相关关系,是指变量(现象)之间存在着非严格、不确定的依存关系。

第八章相关分析与回归分析一、单项选择题(以下每小题各有四项备选答案,其中只有一项是正确的。
)1.根据散点图8-1,可以判断两个变量之间存在( )。
A.正线性相关关系B.负线性相关关系C.非线性关系D.函数关系[答案] A2.假设某品牌的笔记本市场需求只与消费者的收入水平和该笔记本的市场价格水平有关。
则在假定消费者的收入水平不变的条件下,该笔记本的市场需求与其市场价格水平的相关关系就是一种( )。
A.单相关B.复相关C.偏相关D.函数关系[答案] C[解析] 在某一现象与多种现象相关的场合,假定其他变量不变,专门考察其中两个变量的相关关系称为偏相关。
在假定消费者的收入水平不变的条件下,该笔记本的市场需求与其市场价格水平的关系就是一种偏相关。
3.相关图又称( )。
A.散布表B.折线图C.散点图D.曲线图[答案] C[解析] 相关图又称散点图,是指把相关表中的原始对应数值在乎面直角坐标系中用坐标点描绘出来的图形。
4.下列相关系数取值中错误的是( )。
A.-0.86 B.0.78 C.1.25 D.0[答案] C[解析] 相关系数r的取值介于-1与1之间。
5.如果相关系数r=0,则表明两个变量之间( )。
A.相关程度很低B.不存在任何关系C.不存在线性相关关系D.存在非线性相关关系[答案] C[解析] 相关系数r是根据样本数据计算的度量两个变量之间线性关系强度的统计量。
如果相关系数r=0,说明两个变量之间不存在线性相关关系。
6.当所有观测值都落在回归直线上,则两个变量之间的相关系数为( )。
A.1 B.-1C.+1或-1 D.大于-1,小于+1[答案] C[解析] 当所有观测值都落在回归直线上时,说明两个变量完全线性相关,所以相关系数为+1或-1。
即当两个变量完全正相关时,r=+1;当两个变量完全负相关时,r=-1。
7.对于回归方程,下列说法中正确的是( )。
A.只能由自变量x去预测因变量yB.只能由因变量y去预测自变量xC.既可以由自变量x去预测因变量y,也可以由变量因y去预测自变量xD.能否相互预测,取决于自变量x和变量因y之间的因果关系[答案] A[解析] 回归方程中,只能由自变量x去预测因变量y,而不能由因变量y不能预测自变量x。

第8章 非线性回归思考与练习参考答案8.1 在非线性回归线性化时,对因变量作变换应注意什么问题?答:在对非线性回归模型线性化时,对因变量作变换时不仅要注意回归函数的形式, 还要注意误差项的形式。
如:(1) 乘性误差项,模型形式为e y AK L αβε=, (2) 加性误差项,模型形式为y AK L αβε=+对乘法误差项模型(1)可通过两边取对数转化成线性模型,(2)不能线性化。
一般总是假定非线性模型误差项的形式就是能够使回归模型线性化的形式,为了方便通常省去误差项,仅考虑回归函数的形式。
8.2为了研究生产率与废料率之间的关系,记录了如表8.15所示的数据,请画出散点图,根据散点图的趋势拟合适当的回归模型。
表8.15生产率x (单位/周) 1000 2000 3000 3500 4000 4500 5000 废品率y (%)5.26.56.88.110.2 10.3 13.0解:先画出散点图如下图:5000.004000.003000.002000.001000.00x12.0010.008.006.00y从散点图大致可以判断出x 和y 之间呈抛物线或指数曲线,由此采用二次方程式和指数函数进行曲线回归。
(1)二次曲线 SPSS 输出结果如下:Model Summ ary.981.962.942.651R R SquareAdjusted R SquareStd. E rror of the EstimateThe independent variable is x.ANOVA42.571221.28650.160.0011.6974.42444.2696Regression Residual TotalSum of Squares dfMean SquareF Sig.The independent variable is x.Coe fficients-.001.001-.449-.891.4234.47E -007.0001.4172.812.0485.843 1.3244.414.012x x ** 2(Constant)B Std. E rror Unstandardized Coefficients BetaStandardizedCoefficientstSig.从上表可以得到回归方程为:72ˆ 5.8430.087 4.4710yx x -=-+⨯ 由x 的系数检验P 值大于0.05,得到x 的系数未通过显著性检验。

8.2 一元线性回归模型及其应用课后训练巩固提升1.对于经验回归方程y ^=b ^x+a ^(b ^>0),下列说法错误的是 ( )A.当x 增加一个单位时,y ^的值平均增加b ^个单位 B.点(x,y )一定在y ^=b ^x+a ^所表示的直线上 C.当x=t 时,一定有y=b ^t+a ^D.当x=t 时,y 的值近似为b ^t+a ^解析:经验回归方程是一个模拟函数,它表示的是一系列离散的点大致所在直线的位置及其大致变化规律,故有些散点不一定在经验回归直线上. 答案:C2.有一名同学家开了一个小卖部,他为了研究气温对热饮销售的影响,经过统计得到了一个热饮销售杯数与当天气温之间的线性关系,其经验回归方程为y ^=-2.35x+155.47.如果某天气温为4 ℃,那么该小卖部大约能卖出热饮的杯数是( )A.140B.146C.151D.164答案:B3.设两个变量x 和y 之间具有线性相关关系,它们的样本相关系数是r,y 关于x 的经验回归直线的斜率是b ^,纵轴上的截距是a ^,那么必有( ) A.b ^与r 的符号相同B.a ^与r 的符号相同C.b ^与r 的符号相反D.a ^与r 的符号相反解析:因为b ^>0时,两变量正相关,此时r>0; b ^<0时,两变量负相关,此时r<0, 所以b ^与r 的符号相同. 答案:A4.有一散点图如图所示,在5个点中去掉D(3,10)后,下列说法正确的是( )A.残差平方和变小B.相关系数r 变小C.决定系数R2变小D.解释变量x与响应变量y的线性相关程度变弱解析:由题中散点图可知,只有D点偏离经验回归直线,去掉D点后,解释变量x与响应变量y的线性相关程度变强,相关系数r变大,决定系数R2变大,残差平方和变小,故选A.答案:A5.(多选题)3月15日,某市物价部门对5家商场的某商品一天的销售量及其价格进行调查,5家商场的售价x(单位:元)和销售量y(单位:件)之间的一组数据如表所示:根据表中数据得到y关于x的回归直线方程是y^=-3.2x+a^,则下列说法正确的有( )A.a^=40B.回归直线过点(10,8)C.当x=8.5时,y的估计值为12.8D.点(10.5,6)处的随机误差为0.4解析:由题意可知x =15×(9+9.5+10+10.5+11)=10,y =15×(11+10+8+6+5)=8,故回归直线过点(10,8),且8=-3.2×10+a ^⇒a ^=40,故A,B 正确.当x=8.5时,y ^=-3.2×8.5+40=12.8,故C 正确.点(10.5,6)处的随机误差为6-(-3.2×10.5+40)=-0.4,故D 不正确,故选ABC. 答案:ABC6.某品牌服装专卖店为了解保暖衬衣的销售量y(单位:件)与平均气温x(单位:℃)之间的关系,随机统计了连续四旬的销售量与当旬平均气温,其数据如表:由表中数据算出线性回归方程y ^=b ^x+a ^中的b ^=-2,样本中心点为(10,38). (1)表中数据m= ;(2)气象部门预测三月中旬的平均气温约为22 ℃,据此估计,该品牌的保暖衬衣在三月中旬的销售量为 .解析:(1)由y =38,得m=40.(2)由a ^=y −b ^x ,得a ^=58,则y ^=-2x+58, 当x=22时,y ^=14,故估计三月中旬的销售量为14件. 答案:(1)40 (2)14件7.某工厂1~8月份某种产品的产量x(单位:t)与成本y(单位:万元)的统计数据如下表.(1)画出散点图;(2)判断y 与x 是否具有线性相关关系,若有,求出其经验回归方程. 解:(1)散点图如图.(2)由图可看出,这些点基本分布在一条直线附近,可以认为x 和y 线性相关.∵x =6.85,y =157.25,∑i=18x i y i =8764.5,∑i=18x i 2=382.02,∴b ^=∑i=18x i y i -8xy∑i=18x i 2-8x 2=8764.5-8×6.85×157.25382.02-8×6.852≈22.169,a ^=y −b ^x ≈157.25-22.169×6.85≈5.392. ∴经验回归方程为y ^=22.169x+5.392.1.由变量x 与y 相对应的一组数据(1,y 1),(5,y 2),(7,y 3),(13,y 4),(19,y 5)得到的经验回归方程为y ^=2x+45,则y =( ) A.135 B.90 C.67D.63解析:因为x =15×(1+5+7+13+19)=9,y =2x +45,所以y =2×9+45=63. 答案:D2.某鞋厂为了研究初二学生的脚长)的关系,从初二某班随机抽取10名学生,根据测量数据的散点图(图略)可以看出y 与x 之间有线性相关关系,设其经验回归方程为y ^=b ^x+a ^.已知∑i=110x i =225,∑i=110y i =1 600,b ^=4.该班某学生的脚长为24 cm,据此估计其身高为( ) A.160 cm B.163 cm C.166 cmD.170 cm解析:x =22.5,y =160,a ^=160-4×22.5=70,则经验回归方程为y ^=4). 答案:C3.(多选题)四名同学根据各自的样本数据研究变量x,y 之间的相关关系,并求得经验回归方程,分别得到以下四个结论,其中一定不正确的结论是( )A.y 与x 负相关,且y ^=2.347x-6.423 B.y 与x 负相关,且y ^=-3.476x+5.648 C.y 与x 正相关,且y ^=5.437x+8.493 D.y 与x 正相关,且y ^=-4.326x-4.578解析:A 结论错误,由经验回归方程知,此两变量的关系是正相关; B 结论正确,经验回归方程符合负相关的特征; C 结论正确,经验回归方程符合正相关的特征; D 结论不正确,经验回归方程符合负相关的特征. 故选AD.答案:AD4.对具有线性相关关系的变量x,y,测得一组数据如表:根据上表,利用最小二乘法得它们的经验回归方程为y^=10.5x+a^,据此模型预测,当x=10时,y^= .×(2+4+5+6+8)=5,解析:根据表中数据,计算x=15y=1×(20+40+60+70+80)=54,5代入经验回归方程y^=10.5x+a^中,求得a^=54-10.5×5=1.5,故经验回归方程为y^=10.5x+1.5,据此模型预测,当x=10时,y^=10.5×10+1.5=106.5.答案:106.55.某市春节期间7家超市的广告费支出x i(单位:万元)和销售额y i(单位:万元)的数据如下:销售额y i 19 32 40 44 52 53 54(1)若用线性回归模型拟合y 与x 的关系,求y 关于x 的经验回归方程. (2)若用对数回归模型拟合y 与x 的关系,可得经验回归方程y ^=12ln x+22,经计算得出线性回归模型和对数回归模型的决定系数R 2分别约为0.75和0.97,请用决定系数R 2说明选择哪个回归模型更合适,并用此模型预测A 超市广告费支出为8万元时的销售额.参考数据及公式:x =8,y =42,∑i=17x i y i =2 794,∑i=17x i 2=708,b^=∑i=1nx i y i -nxy ∑i=1nx i 2-nx 2,a ^=y −b ^x ,ln 2≈0.7. 解:(1)b ^=∑i=17x i y i -7xy∑i=17x i 2-7x 2=2794-7×8×42708-7×82=1.7,a ^=y −b ^x =28.4,故y 关于x 的经验回归方程是y ^=1.7x+28.4. (2)因为0.75<0.97, 所以对数回归模型更合适.把x=8代入回归方程y ^=12ln x+22,得y ^=12×ln 8+22=36ln 2+22≈47.2,所以当x=8万元时,预测A 超市销售额为47.2万元.6.假设关于某设备的使用年限x(单位:年)和支出的维修费用y(单位:万元),有如下表的统计资料:若由资料知y 对x 呈线性相关关系,试求: (1)经验回归方程y ^=b ^x+a ^.(2)估计使用年限为10年时,维修费用是多少? (3)计算残差平方和.(4)求决定系数R 2并说明模型的拟合效果. 解:(1)将已知条件制成下表.设经验回归方程为y ^=b ^x+a ^, 于是有b ^=∑i=15x i y i -5xy∑i=15x i 2-5x 2=112.3-5×4×590-5×42=1.23,a ^=y −b ^x =5-1.23×4=0.08,第11页 共11页 故经验回归方程为y ^=1.23x+0.08.(2)当x=10时,y ^=1.23×10+0.08=12.38,即估计使用10年时维修费用是12.38万元.(3)因为y ^1=2.54,y ^2=3.77,y ^3=5,y ^4=6.23,y ^5=7.46,所以残差平方和∑i=15(y i -y ^i )2=0.651. (4)决定系数R 2=1-∑i=15(y i -y ^i )2∑i=15(y i -y )2=1-0.65115.78≈0.958 7,模型的拟合效果较好,使用年限解释了95.87%的维修费用支出.。
第8章 非线性回归思考与练习参考答案8.1 在非线性回归线性化时,对因变量作变换应注意什么问题?答:在对非线性回归模型线性化时,对因变量作变换时不仅要注意回归函数的形式, 还要注意误差项的形式。
如:(1) 乘性误差项,模型形式为e y AK L αβε=, (2) 加性误差项,模型形式为y AK L αβε=+。
对乘法误差项模型(1)可通过两边取对数转化成线性模型,(2)不能线性化。
一般总是假定非线性模型误差项的形式就是能够使回归模型线性化的形式,为了方便通常省去误差项,仅考虑回归函数的形式。
8.2为了研究生产率与废料率之间的关系,记录了如表8.15所示的数据,请画出散点图,根据散点图的趋势拟合适当的回归模型。
表8.15生产率x (单位/周) 1000 2000 3000 3500 4000 4500 5000 废品率y (%)5.26.56.88.110.2 10.3 13.0解:先画出散点图如下图:5000.004000.003000.002000.001000.00x12.0010.008.006.00y从散点图大致可以判断出x 和y 之间呈抛物线或指数曲线,由此采用二次方程式和指数函数进行曲线回归。
(1)二次曲线 SPSS 输出结果如下:从上表可以得到回归方程为:72ˆ 5.8430.087 4.4710yx x -=-+⨯ 由x 的系数检验P 值大于0.05,得到x 的系数未通过显著性检验。
由x 2的系数检验P 值小于0.05,得到x 2的系数通过了显著性检验。
(2)指数曲线ANOVA.5731.57379.538.000.0365.007.6096RegressionResidualTotalSum ofSquares df Mean Square F Sig.The independent variable is x.Coe fficients.000.000.9708.918.0004.003.34811.514.000x(Constant)B Std. E rrorUnstandardizedCoefficientsBetaStandardizedCoefficientst Sig.The dependent variable is ln(y).从上表可以得到回归方程为:0.0002tˆ 4.003y e由参数检验P值≈0<0.05,得到回归方程的参数都非常显著。
实用回归分析第四版第一章回归分析概述1.3回归模型中随机误差项ε的意义是什么?答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究y与x1,x2…..xp的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
1.4 线性回归模型的基本假设是什么?答:线性回归模型的基本假设有:1.解释变量x1.x2….xp是非随机的,观测值xi1.xi2…..xip是常数。
2.等方差及不相关的假定条件为{E(εi)=0 i=1,2…. Cov(εi,εj)={σ^23.正态分布的假定条件为相互独立。
4.样本容量的个数要多于解释变量的个数,即n>p.第二章一元线性回归分析思考与练习参考答案2.1一元线性回归有哪些基本假定?答:假设1、解释变量X是确定性变量,Y是随机变量;假设2、随机误差项ε具有零均值、同方差和不序列相关性:E(εi)=0 i=1,2, …,nVar (εi)=σ2i=1,2, …,nCov(εi,εj)=0 i≠j i,j= 1,2, …,n假设3、随机误差项ε与解释变量X之间不相关:Cov(X i, εi)=0 i=1,2, …,n假设4、ε服从零均值、同方差、零协方差的正态分布εi~N(0, σ2) i=1,2, …,n2.3 证明(2.27式),∑e i =0 ,∑e i X i=0 。
证明:∑∑+-=-=niiiniXYYYQ12121))ˆˆ(()ˆ(ββ其中:即: ∑e i =0 ,∑e i X i =02.5 证明0ˆβ是β0的无偏估计。
证明:)1[)ˆ()ˆ(1110∑∑==--=-=ni i xxi n i i Y L X X X Y n E X Y E E ββ )] )(1([])1([1011i i xx i n i i xx i ni X L X X X n E Y L X X X n E εββ++--=--=∑∑==1010)()1(])1([βεβεβ=--+=--+=∑∑==i xx i ni i xx i ni E L X X X nL X X X n E 2.6 证明 证明:)] ()1([])1([)ˆ(102110i i xxi ni ixx i ni X Var L X X X n Y L X X X n Var Var εβββ++--=--=∑∑== 222212]1[])(2)1[(σσxx xx i xx i ni L X n L X X X nL X X X n +=-+--=∑=2.7 证明平方和分解公式:SST=SSE+SSR证明:2.8 验证三种检验的关系,即验证: (1)21)2(r r n t --=;(2)2221ˆˆ)2/(1/t L n SSE SSR F xx ==-=σβ 01ˆˆˆˆi i i i iY X e Y Y ββ=+=-())1()1()ˆ(222122xx ni iL X n X XX nVar +=-+=∑=σσβ()()∑∑==-+-=-=n i ii i n i i Y Y Y Y Y Y SST 1212]ˆ()ˆ[()()()∑∑∑===-+--+-=ni ii ni i i i ni iY Y Y Y Y Y Y Y 12112)ˆˆ)(ˆ2ˆ()()SSESSR )Y ˆY Y Y ˆn1i 2ii n1i 2i +=-+-=∑∑==0100ˆˆQQββ∂∂==∂∂证明:(1)ˆt======(2)2222201111 1111ˆˆˆˆˆˆ()()(())(()) n n n ni i i i xxi i i iSSR y y x y y x x y x x Lβββββ=====-=+-=+--=-=∑∑∑∑2212ˆ/1ˆ/(2)xxLSSRF tSSE nβσ∴===-2.9 验证(2.63)式:2211σ)L)xx(n()e(Varxxii---=证明:0112222222ˆˆˆvar()var()var()var()2cov(,)ˆˆˆvar()var()2cov(,())()()11[]2[]()1[1]i i i i i i ii i i ii ixx xxixxe y y y y y yy x y y x xx x x xn L n Lx xn Lβββσσσσ=-=+-=++-+---=++-+-=--其中:222221111))(1()(1))(,()()1,())(ˆ,(),())(ˆ,(σσσββxxixxiniixxiiiniiiiiiiiLxxnLxxnyLxxyCovxxynyCovxxyCovyyCovxxyyCov-+=-+=--+=-+=-+∑∑==2.10 用第9题证明是σ2的无偏估计量证明:2221122112211ˆˆ()()()22()111var()[1]221(2)2n ni ii in niii i xxE E y y E en nx xen n n Lnnσσσσ=====-=---==----=-=-∑∑∑∑第三章2ˆ22-=∑neiσ1.一个回归方程的复相关系数R=0.99,样本决定系数R 2=0.9801,我们能判断这个回归方程就很理想吗? 答:不能断定这个回归方程理想。
第二章 一元线性回归2.14 解答:(1)散点图为:(2)x 与y 之间大致呈线性关系。
(3)设回归方程为01y x ββ∧∧∧=+1β∧=12217()ni ii nii x y n x yxn x --=-=-=-∑∑0120731y x ββ-∧-=-=-⨯=-17y x ∧∴=-+可得回归方程为(4)22ni=11()n-2i i y y σ∧∧=-∑ 2n 01i=11(())n-2i y x ββ∧∧=-+∑=2222213⎡⎤⨯+⨯+⨯⎢⎥+⨯+⨯⎣⎦(10-(-1+71))(10-(-1+72))(20-(-1+73))(20-(-1+74))(40-(-1+75)) []1169049363110/3=++++=6.1σ∧=≈ (5)由于211(,)xxN L σββ∧t σ∧==服从自由度为n-2的t 分布。
因而/2|(2)1P t n αασ⎡⎤⎢⎥<-=-⎢⎥⎣⎦也即:1/211/2(p t t ααβββ∧∧∧∧-<<+=1α-可得195%β∧的置信度为的置信区间为(7-2.3537+2.353 即为:(2.49,11.5)2201()(,())xxx Nn L ββσ-∧+t ∧∧==服从自由度为n-2的t 分布。
因而/2(2)1P t n αα∧⎡⎤⎢⎥⎢⎥<-=-⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦即0/200/2()1p βσββσα∧∧∧∧-<<+=- 可得195%7.77,5.77β∧-的置信度为的置信区间为()(6)x 与y 的决定系数22121()490/6000.817()nii nii y y r y y ∧-=-=-==≈-∑∑(7)由于(1,3)F F α>,拒绝0H ,说明回归方程显著,x 与y 有显著的线性关系。
(8)t σ∧==其中2221111()22n ni i i i i e y y n n σ∧∧====---∑∑ 7 3.661==≈ /2 2.353t α= /23.66t t α=>∴接受原假设01:0,H β=认为1β显著不为0,因变量y 对自变量x 的一元线性回归成立。
第8章 非线性回归思考与练习参考答案在非线性回归线性化时,对因变量作变换应注意什么问题答:在对非线性回归模型线性化时,对因变量作变换时不仅要注意回归函数的形式, 还要注意误差项的形式。
如:(1) 乘性误差项,模型形式为e y AK L αβε=, (2) 加性误差项,模型形式为y AK L αβε=+。
对乘法误差项模型(1)可通过两边取对数转化成线性模型,(2)不能线性化。
一般总是假定非线性模型误差项的形式就是能够使回归模型线性化的形式,为了方便通常省去误差项,仅考虑回归函数的形式。
为了研究生产率与废料率之间的关系,记录了如表所示的数据,请画出散点图,根据散点图的趋势拟合适当的回归模型。
表生产率x (单位/周) 1000 2000 3000 3500 4000 4500 5000 废品率y (%)解:先画出散点图如下图:从散点图大致可以判断出x和y之间呈抛物线或指数曲线,由此采用二次方程式和指数函数进行曲线回归。
(1)二次曲线SPSS输出结果如下:从上表可以得到回归方程为:72ˆ 5.8430.087 4.4710yx x -=-+⨯ 由x 的系数检验P 值大于,得到x 的系数未通过显著性检验。
由x 2的系数检验P 值小于,得到x 2的系数通过了显著性检验。
(2)指数曲线从上表可以得到回归方程为:0.0002t ˆ 4.003ye = 由参数检验P 值≈0<,得到回归方程的参数都非常显著。
从R2值,σ的估计值和模型检验统计量F值、t值及拟合图综合考虑,指数拟合效果更好一些。
已知变量x与y的样本数据如表,画出散点图,试用αeβ/x来拟合回归模型,假设:(1)乘性误差项,模型形式为y=αeβ/x eε(2)加性误差项,模型形式为y=αeβ/x+ε。
表序号x y序号x y序号x y161127123813491451015解: 散点图:(1) 乘性误差项,模型形式为y=αe β/x e ε线性化:lny=ln α+β/x +ε 令y1=lny, a=ln α,x1=1/x . 做y1与x1的线性回归,SPSS 输出结果如下:Model Summ aryb.999a .997.997.04783Model 1RR SquareAdjusted R SquareStd. E rror of the EstimateP redictors: (Constant), x1a. Dependent Variable: y1b.从以上结果可以得到回归方程为:y1=+F 检验和t 检验的P 值≈0<,得到回归方程及其参数都非常显著。
回代为原方程为:y=(2)加性误差项,模型形式为y=αeβ/x+ε不能线性化,直接非线性拟合。
给初值α=,β=(线性化结果),NLS 结果如下:ANOVA a4.4582 2.229.00113.0004.459152.46714Source Regression ResidualUncorrected Total Corrected TotalSum of SquaresdfMean SquaresDependent variable: yR squared = 1 - (Residual Sum of Squares) /(Corrected Sum of Squares) = 1.000.a.从以上结果可以得到回归方程为: y=根据R 2≈1,参数的区间估计不包括零点且较短,可知回归方程拟合非常好,且其参数都显著。
Logistic 函数常用于拟合某种消费品的拥有率,表(书上239页,此处略)是北京市每百户家庭平均拥有的照相机数,试针对以下两种情况拟合Logistic 回归函数。
(1)已知100u =,用线性化方法拟合, (2)u 未知,用非线性最小二乘法拟合。
解:(1),100u =时,的线性拟合。
对0111t y b b u=+函数线性化得到:11ln() 1.8510.264100y -=--0111ln()ln ln 100b t b y -=+,令311ln()100y y =-,作3y 关于t 的线性回归分析,SPSS 输出结果如下:由表Model Summary 得到,0.994R =趋于1,回归方程的拟合优度好,由表ANOVA 得到回归方程显著,由Coefficients 表得到,回归系数都是显著的,得到方程:11ln() 1.8510.264100y -=--,进一步计算得到:00.157b =,10.768b =(100u =)回代变量得到最终方程形式为: 1ˆ0.010.1570.768ty=+⨯最后看拟合效果,通过sequence 画图:由图可知回归效果比较令人满意。
(2)非线性最小二乘拟合,取初值100u =,00.157b =,10.768b =: 一共循环迭代8次,得到回归分析结果为:Parameter E stimates91.062 2.03586.74795.377.211.028.152.271.727.012.701.753P aram eteru b c E stim ate Std. E rrorLow er Bound Upper Bound95% Confidence I ntervalANOVA a60774.331320258.11085.36916 5.33660859.7001915690.38618Source Regression Residual Uncorrected Total Corrected Total Sum ofSquares df MeanSquaresDependent variable: yR squared = 1 - (Residual Sum of Squares) /(Corrected Sum of Squares) = .995.a.0.995R =>,得到回归效果比线性拟合要好,且:91.062u =,00.211b =,10.727b =,回归方程为:110.211*0.72791.062ty =+。
最后看拟合效果,由sequence 画图:得到回归效果很好,而且较优于线性回归。
表(书上240页,此处略)数据中GDP 和投资额K 都是用定基居民消费价格指数(CPI )缩减后的,以1978年的价格指数为100。
(1) 用线性化乘性误差项模型拟合C-D 生产函数;(2) 用非线性最小二乘拟合加性误差项模型的C-D 生产函数; (3) 对线性化检验自相关,如果存在自相关则用自回归方法改进; (4) 对线性化检验多重共线性,如果存在多重共线性则用岭回归方法改进; (5) 用线性化的乘法误差项模型拟合C-D 生产函数;解:(1)对乘法误差项模型可通过两边取对数转化成线性模型。
ln y =ln A +ln K +ln L令y ′=ln y ,β0=ln A ,x 1=ln K ,x 2=ln L ,则转化为线性回归方程:y ′=β0+x 1+x 2+SPSS 输出结果如下:模型综述表Model Summ aryb.997a .994.993.04836Model 1RR SquareAdjusted R SquareStd. E rror of the EstimateP redictors: (Constant), lnL, lnK a. Dependent Variable: lnYb.从模型综述表中可以看到,调整后的为,说明C-D 生产函数拟合效果很好,也说明GDP 的增长是一个指数模型。
方差分析表ANOVA b8.4462 4.2231805.601.000a.05122.0028.49724Regression Residual TotalModel1Sum of SquaresdfMean SquareF Sig.P redictors: (Constant), lnL, lnK a. Dependent Variable: lnYb.从方差分析表中可以看到,F 值很大,P 值为零,说明模型通过了检验,这与上述分析结果一致。
系数表Coe fficientsa-1.785 1.438-1.241.228.801.056.86114.370.000.402.171.1412.354.028(Constant)lnK lnLModel 1B Std. E rror Unstandardized Coefficients BetaStandardizedCoefficientstSig.Dependent Variable: lnYa.根据系数表显示,回归方程为:尽管模型通过了检验,但是也可以看到,常数项没有通过检验,但在这个模型里,当lnK 和lnL 都为零时,lnY 为,即当K 和L 都为1时,GDP 为,也就是说当投入资本和劳动力都为1个单位时,GDP 将增加个单位,这种解释在我们的承受范围内,可以认为模型可以用。
最终方程结果为:(2) y=0.801 L 用非线性最小二乘法拟合加性误差项模型的C-D 生产函数;上述假设误差是乘性的,现假设误差是加性的情况下使用非线性最小二乘法估计。
初值采用(1)中参数的结果,SPSS 输出结果如下:参数估计表Parameter E stimates.407.885-1.429 2.243.868.066.731 1.006.270.243-.234.774P aram eterP a b E stim ateStd. E rrorLow er Bound Upper Bound95% Confidence I ntervalSPSS 经过多步迭代,最终得到的稳定参数值为P=,a=,b=y=0.868 L 为了比较这两个方程,我们观察下面两个图线性回归估计拟合曲线图非线性最小二乘估计拟合曲线图我们知道,乘性误差相当于是异方差的,做了对数变换后,乘性误差转为加性误差,这种情况下认为方差是相等的,那么第一种情况(对数变换线性化)就大大低估了GDP数值大的项,因此,它对GDP前期拟合的很好,而在后期偏差就变大了,同时也会受到自变量之间的自相关和多重共线性的综合影响;非线性最小二乘法完全依赖数据,如果自变量之间存在比较严重的异方差、自相关以及多重共线性,将对拟合结果造成很大的影响。
因此,不排除异方差、自相关以及多重共线性的存在。
(3)对线性化回归模型采用DW检验自相关,结果如下:模型综述表Model Summ aryb.997a .994.993.04836.715Model 1RR SquareAdjusted R SquareStd. E rror of the EstimateDurbin-WatsonP redictors: (Constant), lnL, lnK a. Dependent Variable: lnYb.DW=<,落在自相关的区间,所以采用迭代法改进将得到的数据再取对数,而后用普通最小二乘法估计,保留DW 值模型综述表Model Summ aryb.983a .967.964478.90271 1.618Model 1RR SquareAdjusted R SquareStd. E rror of the Estimate Durbin-WatsonP redictors: (Constant), Ltt, Ktt a. Dependent Variable: Yttb. 方差分析表ANOVA b7.5542 3.777601.286.000a.13221.0067.68623Regression Residual TotalModel 1Sum of SquaresdfMean SquareF Sig.P redictors: (Constant), lnLtt, lnKtt a. Dependent Variable: lnYttb.系数表Coe fficientsa-1.859 1.470-1.265.220.755.054.85214.098.000.465.180.1562.577.018(Constant)lnKtt lnLttModel 1B Std. E rror Unstandardized Coefficients BetaStandardizedCoefficientstSig.Dependent Variable: lnYtta.从模型综述表中可以看到,DW=>,认为消除了自相关;方差分析表中可以看到F 值很大,P 值为零,说明模型通过了检验。