多元统计分析第九章聚类分析
- 格式:doc
- 大小:717.00 KB
- 文档页数:30

聚类分析聚类分析又称群分析,它是研究(样品或指标)分类问题的一种多元统计方法,所谓类,通俗地说,就是指相似元素的集合。
聚类分析内容非常丰富,按照分类对象的不同可分为样品分类(Q-型聚类分析)和指标或变量分类(R-型聚类分析);按照分类方法可分为系统聚类法和快速聚类法。
1. 系统聚类分析先将n 个样品各自看成一类,然后规定样品之间的“距离”和类与类之间的距离。
选择距离最近的两类合并成一个新类,计算新类和其它类(各当前类)的距离,再将距离最近的两类合并。
这样,每次合并减少一类,直至所有的样品都归成一类为止。
系统聚类法直观易懂。
1.1系统聚类法的基本步骤:第一,计算n 个样品两两间的距离 ,记作D= 。
第二,构造n 个类,每个类只包含一个样品。
第三,合并距离最近的两类为一新类。
第四,计算新类与各当前类的距离。
第五,重复步骤3、4,合并距离最近的两类为新类,直到所有的类并为一类为止。
第六,画聚类谱系图。
第七,确定类的个数和类。
1.2 系统聚类方法:1.2.1最短距离法1.2.2最长距离法1.2.3中间距离法1.2.4重心法1.2.5类平均法1.2.6离差平方和法(Ward 法)上述6种方法归类的基本步骤一致,只是类与类之间的距离有不同的定义。
最常用的就是最短距离法。
1.3 最短距离法以下用ij d 表示样品i X 与j X 之间距离,用ij D 表示类i G 与j G 之间的距离。
定义类i G 与j G 之间的距离为两类最近样品的距离,即ij G G G G ij d D j J i i ∈∈=,min设类p G 与q G 合并成一个新类记为r G ,则任一类k G 与r G 的距离是:ij G X G X kr d D j j i i ∈∈=,min ⎭⎬⎫⎩⎨⎧=∈∈∈∈ij G X G X ij G X G X d d q j k i p j k i ,,min ,min min {}kq kp D D ,min = 最短距离法聚类的步骤如下:ij d {}ij d(1)定义样品之间距离,计算样品两两距离,得一距离阵记为)0(D ,开始每个样品自成一类,显然这时ij ij d D =。


多元统计分析-聚类分析聚类分析是⼀个迭代的过程对于n个p维数据,我们最开始将他们分为n组每次迭代将距离最近的两组合并成⼀组若给出需要聚成k类,则迭代到k类是,停⽌计算初始情况的距离矩阵⼀般⽤马⽒距离或欧式距离个⼈认为考试只考 1,2⽐较有⽤的⽅法是3,4,5,8最喜欢第8种距离的计算 欧式距离 距离的⼆范数 马⽒距离 对于X1, X2均属于N(u, Σ) X1,X2的距离为 (X1 - X2) / sqrt(Σ)那么不同的聚类⽅法其实也就是不同的计算类间距离的⽅法1.最短距离法 计算两组间距离时,将两组间距离最短的元素作为两组间的距离2.最长距离法 将两组间最长的距离作为两组间的距离3.中间距离法 将G p,G q合并成为G r 计算G r与G k的距离时使⽤如下公式 D2kr = 1/2 * D2kp + 1/2 * D2kq + β * D2pq β是提前给定的超参数-0.25<=β<=04.重⼼法 每⼀组都可以看成⼀组多为空间中点的集合,计算组间距离时,可使⽤这两组点的重⼼之间的距离作为类间距离 若使⽤的是欧⽒距离 那么有如下计算公式 D2kr = n p/n r * D2kp + n q/n r * D2kq - (n p*n q / n r*n r ) * D2pq5.类平均法 两组之间的距离 = 组间每两个样本距离平⽅的平均值开根号 表达式为D2kr = n p/n r * D2kp + n q/n r * D2kq6.可变类平均法 可以反映合并的两类的距离的影响 表达式为D2kr = n p/n r *(1- β) * D2kp + n q/n r *(1- β) * D2kq + β*D2pq 0<=β<17.可变法 D2kr = (1- β)/2 * (D2kp + D2kq) + β*D2pq8.离差平⽅和法 这个⽅法⽐较实⽤ 就是计算两类距离的话,就计算,如果将他们两类合在⼀起之后的离差平⽅和 因为若两类本⾝就是⼀类,和本⾝不是⼀类,他们的离差平⽅和相差较⼤ 离差平⽅和:类中每个元素与这⼀类中的均值距离的平⽅之和 若统⼀成之前的公式就是 D2kr = (n k + n p)/(n r + n k) * D2kp + (n k + n q)/(n r + n k) -(n k)/(n r + n k) * * D2pq⼀些性质 除了中间距离法之外,其他的所有聚类⽅法都具有单调性 单调性就是指每次聚类搞掉的距离递增 空间的浓缩和扩张 D(A)>=D(B) 表⽰A矩阵中的每个元素都不⼩于B D(短) <= D(平) <= D(长) D(短,平) <= 0 D(长,平) >= 0 中间距离法⽆法判断。




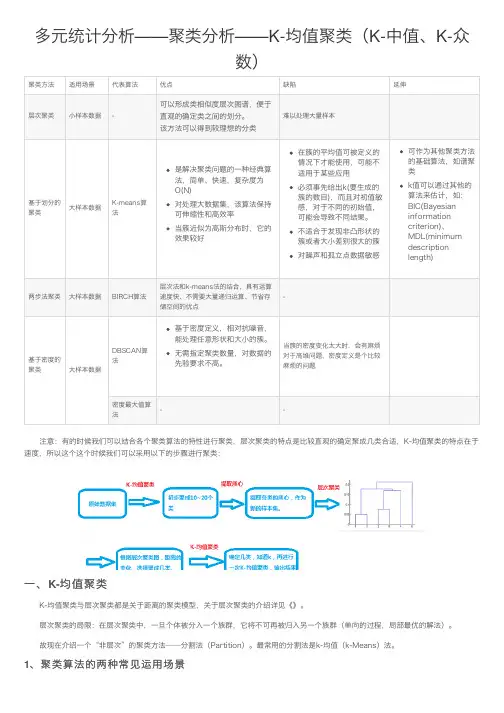
多元统计分析——聚类分析——K-均值聚类(K-中值、K-众数)注意:有的时候我们可以结合各个聚类算法的特性进⾏聚类,层次聚类的特点是⽐较直观的确定聚成⼏类合适,K-均值聚类的特点在于速度,所以这个这个时候我们可以采⽤以下的步骤进⾏聚类:⼀、K-均值聚类K-均值聚类与层次聚类都是关于距离的聚类模型,关于层次聚类的介绍详见《》。
层次聚类的局限:在层次聚类中,⼀旦个体被分⼊⼀个族群,它将不可再被归⼊另⼀个族群(单向的过程,局部最优的解法)。
故现在介绍⼀个“⾮层次”的聚类⽅法——分割法(Partition)。
最常⽤的分割法是k-均值(k-Means)法。
1、聚类算法的两种常见运⽤场景发现异常情况:如果不对数据进⾏任何形式的转换,只是经过中⼼标准化或级差标准化就进⾏快速聚类,会根据数据分布特征得到聚类结果。
这种聚类会将极端数据单独聚为⼏类。
这种⽅法适⽤于统计分析之前的异常值剔除,对异常⾏为的挖掘,⽐如监控银⾏账户是否有洗钱⾏为、监控POS机是有从事套现、监控某个终端是否是电话卡养卡客户等等。
将个案数据做划分:出于客户细分⽬的的聚类分析⼀般希望聚类结果为⼤致平均的⼏⼤类(原始数据尽量服从正态分布,这样聚类出来的簇的样本点个数⼤致接近),因此需要将数据进⾏转换,⽐如使⽤原始变量的百分位秩、Turkey正态评分、对数转换等等。
在这类分析中数据的具体数值并没有太多的意义,重要的是相对位置。
这种⽅法适⽤场景包括客户消费⾏为聚类、客户积分使⽤⾏为聚类等等。
以上两种场景的⼤致步骤如下:聚类算法不仅是建模的终点,更是重要的中间预处理过程,基于数据的预处理过程,聚类算法主要应⽤于以下领域:图像压缩:在使⽤聚类算法做图像压缩过程时,会先定义K个颜⾊数(例如128种颜⾊、256种颜⾊),颜⾊数就是聚类类别的数量;K均值聚类算法会把类似的颜⾊分别放在K个簇中,然后每个簇使⽤⼀种颜⾊来代替原始颜⾊,那么结果就是有多少个簇,就⽣成了由多少种颜⾊构成的图像,由此实现图像压缩。


武汉理工大学实验(实训)报告项目名称实验2―聚类分析所属课程名称多元统计分析项目类型设计性实验实验(实训)日期年月日班级学号姓名指导教师武汉理工大学统计学系制实验报告2聚类分析(设计性实验)实验原理:聚类分析的目的是将分类对象按一定规则分为若干类,这些类不是事先给定的,而是根据数据的特征确定的。
在同一类里的这些对象在某种意义上倾向于彼此相似,而在不同的类里的对象倾向于不相似。
系统聚类法是聚类分析中用的最多的一种,其基本思想是:开始将n个对象各自作为一类,并规定对象之间的距离和类与类之间的距离,然后将距离最近的两类合并成一个新类,计算新类与其它类之间的距离;重复进行两个最近类的合并,每次减少一类,直至所有的对象合并为一类。
实验题目一:为了对11种语言——英语、挪威语、丹麦语、荷兰语、德语、法语、西班牙语、意大利语、波兰语、匈牙利语及芬兰语进行比较研究,研究人员选取每种语言的1至10十个数字相应的单词列表分析。
对于同一数字,某两种语言的第一个字母若相同,则称这两者在该数字上一致,否则非一致。
将这11种语言两两比较后,计算每一对在十个数字上非一致的数目,得到下列距离矩阵:E N Da Du G Fr Sp I P H FiE 0N 2 0Da 2 1 0Du 7 5 6 0G 6 4 5 5 0Fr 6 6 6 9 7 0Sp 6 6 5 9 7 2 0I 6 6 5 9 7 1 1 0P 7 7 6 10 8 5 3 4 0H 9 8 8 8 9 10 10 10 10 0Fi 9 9 9 9 9 9 9 9 9 8 0(1)对这11种语言分别用最小距离法(single linkage)、最大距离法(complete linkage)、平均距离法(average linkage)进行聚类分析;(2)画出以上三种方法聚类分析结果的树状图;(3)结合三种方法的树状图,你认为将11种语言分为哪几类比较合适?(4)用最大距离法将11种语言聚为3类,并将聚类结果存储在一个SPSS数据文件中。

多元统计实验报告设计题目:聚类分析聚类分析是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法,它们讨论的对象是大量的样品,要求能合理地按各自的特性来进行合理的分类,没有任何模式可供参考或依循,即是在没有先验知识的情况下进行的。
基本思想:是根据事物本身的特性研究个体分类的方法;聚类原则:是同一类中的个体有较大的相似性,不同类中的个体差异很大系统聚类分析法一、分析数据1990年全国人口普查数据二、基本原理系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品或变量总能聚到合适的类中。
系统聚类的计算步骤:●对数据进行变换处理,消除量纲●构造n个类,每个类只包含一个样本计算●n个样本两两间的距离{dij}●合并距离最近的两类为一新类●计算新类与当前各类的距离,重复上一步●画聚类图●决定类的个数和类三、实验步骤①1、选择Analyze→Classify→Hierarchical Cluster,打开分层聚类分析主对话框;2、选择聚类分析变量点击向右的箭头按钮,将三个变量移到Variable栏中;3、选择标识变量,单击“地区”点击向右的箭头按钮,将其移入Label Case By栏中;4、选择聚类方法,单击Method…按钮,选择数值标准化法,Z-Score;选择聚类法Between-group linkage;距离测度采用Interval的Squared Euclidean distance;单击Continue按钮,返回主对话框;5、选择输出统计量,单击Statistics…按钮,打开Statistics子对话框。
选择输出Agglomeration Schedule、Proximity Matric,范围从3类到5类的聚类解,单击Continue按钮,返回主对话框;6、选择输出聚类图,单击Plots…按钮,打开Plots子对话框。
选择Dendrogram 树形图,单击Continue按钮,返回主对话框;7、点击OK按钮,显示结果清单。
多元统计分析——聚类分析多元统计分析中的聚类分析(Cluster Analysis)是一种将相似的个体或对象归为一类的数据分析方法。
聚类分析的目的是通过寻找数据中的相似性来识别或发现存在的模式和结构,可以帮助我们理解和解释数据中的复杂性。
聚类分析在许多领域中都得到了广泛的应用,例如市场细分、社会学、生物学、医学等。
聚类分析的基本原理是将数据样本根据其相似性归为不同的组或类。
相似性可以通过计算数据之间的距离或相似度来度量。
常用的距离度量方法有欧氏距离、曼哈顿距离、闵可夫斯基距离等,相似度度量方法有相关系数、夹角余弦等。
在聚类分析中,我们通常将相似的样本放在同一类别中,不相似的样本放在不同类别中。
聚类分析可以分为两种类型:层次聚类和划分聚类。
层次聚类是一种将数据样本分层次地组织成树状结构的聚类方法。
划分聚类则是将数据样本划分为预先确定的K个不重叠的类的聚类方法。
其中最常用的层次聚类算法有聚合法和分裂法,最常用的划分聚类算法是K均值算法。
聚类分析的基本步骤包括数据准备、相似度度量、类别划分和结果解释。
在数据准备阶段,需要选择合适的变量和样本。
相似度度量是聚类分析的核心,不同的距离或相似性度量方法可能会导致不同的聚类结构。
类别划分可以根据层次聚类算法或划分聚类算法来进行。
结果解释则是对聚类结果进行分析和解释,常用的方法包括聚类矩阵、平均距离图、树状图等。
聚类分析的优势在于能够帮助我们理解数据中的结构和模式,发现数据中的共性和差异性。
聚类分析可以为我们提供有关样本之间的关系和特征的重要信息。
此外,聚类分析还可以帮助我们进行市场细分和目标市场选择、发现新的疾病群和药物靶点等。
然而,聚类分析也存在一些局限性。
首先,聚类结果可能会受到初始聚类中心选择的影响。
其次,聚类结果的解释需要结合领域知识和专家判断,可能存在主观性。
此外,聚类分析对数据的样本大小和变量数目也有一定的要求,数据的维度增加会导致计算量的增加。
第9章 聚类分析9.1 引言俗话说:“物以聚类,人以群分”,在现实世界中存在着大量的分类问题。
例如,生物可以分成动物和植物,动物又可分为脊椎动物和无脊椎动物等;人按年龄可分为少年、青年、中年、老年,对少年的身体形态、身体素质及生理功能的各项指标进行测试,据此对少年又可进行分类;在环境科学中,我们可以对按大气污染的轻重分成几类区域;在经济学中,根据人均国民收入、人均工农业产值和人均消费水平等多项指标对世界上所有国家的经济发展状况进行分类;在产品质量管理中,要根据各产品的某些重要指标可以将其分为一等品,二等品等。
研究事物分类问题的基本方法有两种:一是判别分析,二是聚类分析。
若已知总体的类别数目及各类的特征,要对类别未知的个体正确地归属其中某一类,这时需要用判别分析法。
若事先对总体到底有几种类型无从知晓,则要想知道观测到的个体的具体的分类情况,这时就需要用聚类分析法。
聚类分析的基本思想:首先定义能度量样品(或变量)间相似程度(亲疏关系)的统计量,在此基础上求出各样品(或变量)间相似程度的度量值;然后按相似程度的大小,把样品(或变量)逐一归类,关系密切的聚集到一个小的分类单位,关系疏远的聚合到一个大的分类单位,直到所有的样品(或变量)都聚合完毕,把不同的类型一一划分出来,形成一个由小到大的分类系统;最后根据整个分类系统画出一副分群图,称之为亲疏关系谱系图。
聚类分析给人们提供了丰富多彩的分类方法,大致可归为:⑴系统聚类法:首先,将n 个样品看成n 类,然后将性质最接近的两类合并成一个新类,得到1 n 类,合并后重新计算新类与其它类的距离与相近性测度。
这一过程一直继续直到所有对象归为一类为止,并且类的过程可用一张谱系聚类图描述。
⑵动态聚类法(调优法):首先对n 个对象初步分类,然后根据分类的损失函数尽可能小的原则进行调整,直到分类合理为止。
⑶有序样品聚类法(最优分割法):开始将所有样品看成一类,然后根据某种最优准则将它们分割为二类、三类,一直分割到所需的K类为止。
聚类分析引言俗话说:“物以聚类,人以群分”,在现实世界中存在着大量的分类问题。
例如,生物可以分成动物和植物,动物又可分为脊椎动物和无脊椎动物等;人按年龄可分为少年、青年、中年、老年,对少年的身体形态、身体素质及生理功能的各项指标进行测试,据此对少年又可进行分类;在环境科学中,我们可以对按大气污染的轻重分成几类区域;在经济学中,根据人均国民收入、人均工农业产值和人均消费水平等多项指标对世界上所有国家的经济发展状况进行分类;在产品质量管理中,要根据各产品的某些重要指标可以将其分为一等品,二等品等。
研究事物分类问题的基本方法有两种:一是判别分析,二是聚类分析。
若已知总体的类别数目及各类的特征,要对类别未知的个体正确地归属其中某一类,这时需要用判别分析法。
若事先对总体到底有几种类型无从知晓,则要想知道观测到的个体的具体的分类情况,这时就需要用聚类分析法。
聚类分析的基本思想:首先定义能度量样品(或变量)间相似程度(亲疏关系)的统计量,在此基础上求出各样品(或变量)间相似程度的度量值;然后按相似程度的大小,把样品(或变量)逐一归类,关系密切的聚集到一个小的分类单位,关系疏远的聚合到一个大的分类单位,直到所有的样品(或变量)都聚合完毕,把不同的类型一一划分出来,形成一个由小到大的分类系统;最后根据整个分类系统画出一副分群图,称之为亲疏关系谱系图。
聚类分析给人们提供了丰富多彩的分类方法,大致可归为:⑴系统聚类法:首先,将n 个样品看成n 类,然后将性质最接近的两类合并成一个新类,得到1 n 类,合并后重新计算新类与其它类的距离与相近性测度。
这一过程一直继续直到所有对象归为一类为止,并且类的过程可用一张谱系聚类图描述。
⑵动态聚类法(调优法):首先对n 个对象初步分类,然后根据分类的损失函数尽可能小的原则进行调整,直到分类合理为止。
⑶有序样品聚类法(最优分割法):开始将所有样品看成一类,然后根据某种最优准则将它们分割为二类、三类,一直分割到所需的K类为止。
这种方法适用于有序样品的分类问题,故称为有序样品聚类法.⑷模糊聚类法:该方法多用于定性变量的分类.利用模糊集理论来处理分类问题,它对经济领域中具有模糊特征的两态数据和多态数据具有明显的分类效果.⑸图论聚类法:利用图论中最小支撑树的概念来处理分类问题,创造了独具风格的方法.⑹聚类预报法:利用聚类方法处理预报问题,在多元统计分析中,可用来作预报的方法很多,如回归分析或判别分析.但对一些异常数据,如气象中的灾害性天气的预报,使用回归分析或判别分析处理的效果都不好,而聚类预报弥补了这一不足,这是一个值得重视的方法。
本书主要介绍⑴~⑷聚类分析不仅可以对样品进行分类,也可以对变量进行分类。
对样品的分类称为Q型聚类分析,对变量进行分类称为R型聚类分析。
聚类分析的历史还很短,它的方法很粗糙,理论上还不完善,但由于能解决许多实际问题,所以很受人们重视,同回归分析、判别分析一起被称为多元分析的三大实用分析方法。
聚类统计量在对样品(或变量)进行分类时,样品(或变量)之间的相似性是如何度量的呢?这一节中,我们介绍三种相似性度量—距离、匹配系数和相似系数。
距离和匹配系数常用来度量样品之间的相似性,相似系数常用来变量之间的相似性。
样品之间的距离和相似系数有着各种不同的定义,而这些定义与变量的类型有着非常密切的关系。
通常变量按取值的不同可以分为:1.定量变量:变量用连续的量来表示,例如长度、重量、速度、人口等,又称为间隔尺度变量。
2.定性变量:并不是数量上有变化,而只是性质上有差异。
定性变量还可以再分为:⑴有序尺度变量:变量不是用明确的数量表示,而是用等级表示,例如某产品分为一等品、二等品、三等品等,文化程度分为文盲、小学、中学、大学等。
⑵名义尺度变量:变量用一些类表示,这些类之间既无等级关系,也无数量关系,例如性别分为男、女,职业分为工人、教师、干部、农民等。
下面我们主要讨论具有定量变量的样品聚类分析,描述样品间的亲疏程度最常用的是距离。
9.2.1距离1. 数据矩阵设ij x 为第i 个样品的第j 个指标,数据矩阵如下表表9.1 数据矩阵在上表中,每个样品有p 个变量,故每个样品都可以看成是p R 中的一个点,n 个样品就是p R 中的n 个点。
在p R 中需定义某种距离,第i 个样品与第j 个样品之间的距离记为ij d ,在聚类过程中,相距较近的点倾向于归为一类,相距较远的点应归属不同的类。
所定义的距离ij d 一般应满足如下四个条件:⑴0≥ij d ,对一切j i ,;且0),(=j i x x d 当且仅当j i x x =⑵ji ij d d =,对一切j i ,;⑶kj ik ij d d d +≤,对一切k j i ,,2.定量变量的常用的距离对于定量变量,常用的距离有以下几种:⑴闵科夫斯基(Minkowski )距离qp k q jk ik ij x xq d 11][)(∑=-= 这里q 为某一自然数。
闵科夫斯基距离有以下三种特殊形式:1) 当1=q 时,∑=-=p k jk ik ij x xd 1)1(称为绝对值距离,常被形象地称为“城市街区”距离;2) 当2=q 时,2112][)2(∑=-=p k jk ik ij x xd ,称为欧氏距离,这是聚类分析中最常用的距离; 3)当∞=q 时,jk ik pk ij x x d -=∞≤≤1m ax )(,称为切比雪夫距离。
)(q d ij 在实际中用得很多,但是有一些缺点,一方面距离的大小与各指标的观测单位有关,另一方面它没有考虑指标间的相关性。
当各指标的测量值相差悬殊时,应先对数据标准化,然后用标准化后的数据计算距离;最常用的标准化处理是:令 j j ij ij s x x x -=*其中∑==n i ij j x n x 11为第j 个变量的样本均值,∑=--=ni j ij j x x n s 12)(11为第j 个变量的样本方差。
⑵兰氏(Lance 和Williams )距离当0>ij x (;,,2,1n i = p j ,,2,1 =)时,第i 个样品与第j 个样品间的兰氏距离为∑=+-=pk jk ik jk ik ij x x x x L d 1)(这个距离与各变量的单位无关,但没有考虑指标间的相关性。
⑶马氏距离(Mahalanobis )距离第i 个样品与第j 个样品间的马氏距离为 )()'()(1j i j i ij x x S x x M d --=-其中)',,,(21ip i i i x x x x =,),,(21jp j j j x x x x =,S 为样品协方差矩阵。
使用马氏距离的好处是考虑到了各变量之间的相关性,并且与各变量的单位无关;但马氏距离有一个很大的缺陷,就是S 难确定。
由于聚类是一个动态过程,故S 随聚类过程而变化,那么同样的两个样品之间的距离可能也会随之而变化,这不符和聚类的基本要求。
因此,在实际聚类分析中,马氏距离不是理想的距离。
⑷斜交空间距离第i 个样品与第j 个样品间的斜交空间距离定义为∑∑==*--=p k p l kl jl il jk ik ij r x x x xp d 12112]))((1[其中kl r 是变量k x 与变量l x 间的相关系数。
当p 个变量互不相关时,p d d ij ij )2(=*,即斜交空间距离退化为欧氏距离(除相差一个常数倍外)。
以上几种距离的定义均要求样品的变量是定量变量,如果使用的是定性变量,则有相应的定义距离的方法。
3.定性变量的距离下例只是对名义尺度变量的一种距离定义。
例9.1.1 某高校举办一个培训班,从学员的资料中得到这样6个变量:性别(1x )取值为男和女;外语语种(2x )取值为英、日和俄;专业(3x )取值为统计、会计和金融;职业(4x )取值为教师和非教师;居住处(5x )取值为校内和校外;学历(6x )取值为本科和本科以下。
现有两名学员:=1x (男,英,统计,非教师,校外,本科)ˊ=2x (女,英,金融,教师,校外,本科以下)ˊ这两名学员的第二个变量都取值“英”,称为配合的,第一个变量一个取值为“男”,另一个取值为“女”,称为不配合的。
一般地,若记配合的变量数为1m ,不配合的变量数为2m ,则它们之间的距离可定义为 21212m m m d +=按此定义本例中1x 与2x 之间的距离为32。
当样品的变量为定性变量时,通常采用匹配系数作为聚类统计量。
9.2.2.匹配系数定义9.2.1 第i 个样品与第j 个样品的匹配系数定义为∑==p k k ij ZS 1,其中jkik jk ik k x x x x Z ≠=⎩⎨⎧=当当,0,1 显然匹配系数越大,说明两样品越相似。
例9.2.1 对购买家具的顾客作聚类分析。
有以下三个变量:1x :喜欢的式样,老式记为1,新式记为2;2x :喜欢的图案,素式记为1,格子式记为2,花式记为3;3x :喜欢的颜色,蓝色记为1,黄色记为2,红色记为3,绿色记为4。
下面列出表9.2 四位顾客(样品)的观测值解 各样品为名义尺度变量,其取值仅代表不同状况、类别,无大小次序关系,故采用匹配系数作为聚类统计量,由定义得311111=++=S ,100112=++=S ,101013=++=S ,000014=++=S322=S ,023=S ,101024=++=S333=S ,234=S ,344=S注:⑴对j i ,∀,ij S 为非负整数;⑵ij S 越大,表明样品越相似;按ij S 由大到小,可将样品逐步聚类。
⑶上述匹配系数的计算没有考虑到各个变量取值个数的多寡而一视同仁。
在上例中,式样1x 只取两个值1和2,图案2x 取三个值(1,2,3),颜色3x 取四个值(1,2,3,4). 故{}1}1{}1{321=>=>=x P x P x P即 }{}{}{332211j i j i j i x x P x x P x x P =>=>=这样,ij S 的大小主要由1x 控制,而2x 与3x 的作用不适当地被削弱了。
为了解决这一问题,引进对指标加权的匹配系数:∑==p k k k ij x vS 1其中k v 是指标k x 的权数,等于k x 可能取值的个数。
对上例,求得各加权匹配系数为:911=S ,204031212=⨯+⨯+⨯=S ,3013013=+⨯+=S ,014=S ,922=S ,023=S ,3013024=+⨯+=S ,933=S ,614031234=⨯+⨯+⨯=S ,944=S .聚类分析方法不仅用来对样品进行分类,而且可用来对变量进行分类。