最新多元统计分析-因子分析案例
- 格式:ppt
- 大小:542.50 KB
- 文档页数:7
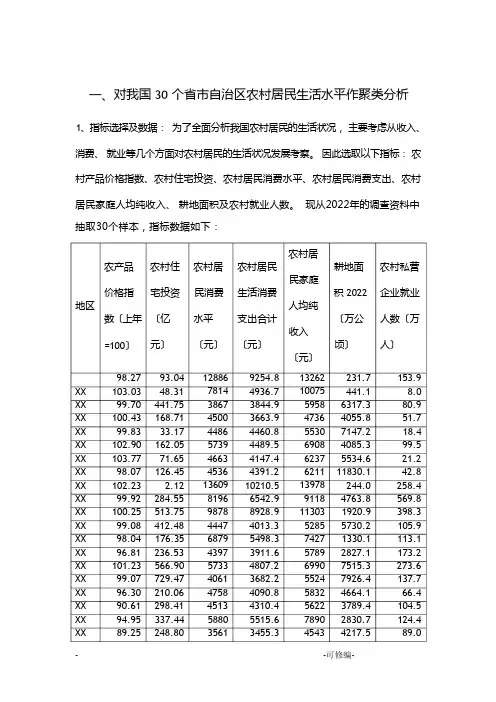
一、对我国30 个省市自治区农村居民生活水平作聚类分析1、指标选择及数据:为了全面分析我国农村居民的生活状况,主要考虑从收入、消费、就业等几个方面对农村居民的生活状况发展考察。
因此选取以下指标:农村产品价格指数、农村住宅投资、农村居民消费水平、农村居民消费支出、农村居民家庭人均纯收入、耕地面积及农村就业人数。
现从2022年的调查资料中抽取30个样本,指标数据如下:农村居民生活消费支出合计〔元〕9254.84936.73844.93663.94460.84489.54147.44391.2 10210.56542.98928.94013.35498.33911.64807.23682.24090.84310.45515.63455.3农村私营企业就业人数〔万人〕153.98.080.951.718.499.521.242.8258.4569.8398.3105.9113.1173.2273.6137.766.4104.5124.489.0 农村居民家庭人均纯收入〔元〕132621007559584736553069086237621113978911811303528574275789699055245832562278904543农产品价格指数〔上年=100〕98.27 103.0399.70 100.4399.83 102.90 103.7798.07 102.2399.92 100.2599.0898.0496.81 101.2399.0796.3090.6194.9589.25耕地面积2022〔万公顷〕231.7441.16317.34055.87147.24085.35534.611830.1244.04763.81920.95730.21330.12827.17515.37926.44664.13789.42830.74217.5 农村居民消费水平〔元〕1288678143867450044865739466345361360981969878444768794397573340614758451358803561农村住宅投资〔亿元〕93.0448.31441.75168.7133.17162.0571.65126.452.12284.55513.75412.48176.35236.53566.90729.47210.06298.41337.44248.80地区XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX数据来源: ?中国统计年鉴 2022?.2、将数据发展标准化变换:农村居民生活消费支出合计〔元〕2.53 0.15 -0.46 -0.56 -0.12 -0.10 -0.29 -0.153.06 1.04 2.35 -0.36 0.46 -0.42 0.08 -0.55 -0.32 -0.20 农村居民家庭人均纯收入〔元〕2.37 1.30 -0.07 -0.48 -0.21 0.25 0.02 0.01 2.60 0.98 1.71 -0.30 0.42 -0.13 0.27 -0.22 -0.11 -0.18农产品价格指数〔上年=100〕0.09 1.33 0.47 0.65 0.50 1.30 1.52 0.04 1.12 0.52 0.61 0.30 0.04 -0.28 0.86 0.30 -0.42 -1.89农村居民消费水平〔元〕2.82 0.92 -0.56 -0.33 -0.33 0.14 -0.26 -0.313.09 1.06 1.69 -0.35 0.57 -0.36 0.14 -0.49 -0.23 -0.32 农村私营企业就业人数〔万人〕 0.37 -0.78 -0.21 -0.44-0.70 -0.06 -0.68 -0.51 1.20 3.66 2.31 -0.01 0.05 0.52 1.32 0.24 -0.32 -0.02农村住宅投资〔亿元〕-0.67 -0.91 1.24 -0.25 -0.99 -0.29 -0.78 -0.48 -1.16 0.38 1.64 1.08 -0.21 0.12 1.93 2.82 -0.03 0.46耕地面积 2022 〔万公顷〕-1.36 -1.29 0.84 0.02 1.15 0.03 0.56 2.84 -1.36 0.28 -0.75 0.63 -0.97 -0.42 1.28 1.43 0.24 -0.07地区XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XXXX 101.91 26.22 3846 3446.2 5275 727.5 5.3 XX 88.99 80.12 3652 3624.6 5277 2235.9 36.7675 XX 96.94 456.10 4748 3897.5 5087 5947.4 140.3 XX 96.11 137.22 2926 2852.5 3472 4485.3 25.4 XX 96.50 158.97 3603 3398.3 3952 6072.1 41.3XX 95.83 151.79 3683 3793.8 4105 4050.3 1.7 XX 100.22 97.33 2975 2942.0 3425 4658.8 22.0 XX 94.61 63.63 3684 3863 542.7 10.5 11.4 XX 99.39 29.51 3894 4675 1107.1 43.6 16.7 XX 92.87 79.35 3590 3457.9 4643 4124.6 18.73、用K-均值聚类法对样本发展分类如下:聚类成员案例号地区聚类距离12 3 4 5 6 7 8 910111213141516171819 XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX12343233121324333421069.193060.35920.651506.42577.122453.891487.955006.412094.382853.423015.141204.491612.461880.402088.551282.272230.152053.351119.98XX -0.77 0.67 0.19 0.47 0.57 -0.42 0.14 XX -2.24 0.19 -0.68 -0.67 -0.54 0.08 -0.14 XX 1.04 -1.03 -0.57 -0.68 -0.30 -1.18 -0.81 XX -2.31 -0.74 -0.64 -0.58 -0.30 -0.64 -0.56 XX -0.25 1.32 -0.23 -0.43 -0.36 0.71 0.26 XX -0.46 -0.42 -0.92 -1.00 -0.90 0.18 -0.65 XX -0.36 -0.31 -0.66 -0.70 -0.74 0.75 -0.52 XX -0.54 -0.34 -0.63 -0.48 -0.69 0.02 -0.83 XX 0.60 -0.64 -0.90 -0.96 -0.92 0.24 -0.67 XX -0.85 -0.83 -0.63 -0.45 -1.88 -1.44 -0.76 XX 0.39 -1.01 -0.55 0.00 -1.69 -1.43 -0.71 XX -1.30 -0.74 -0.67 -0.67 -0.51 0.05 -0.70分四类的情况下,最终分类结果如下:第一类:、XX、XX。

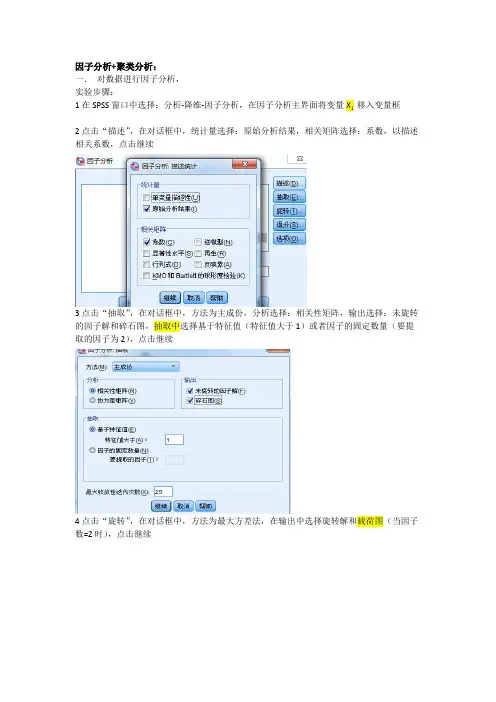
因子分析+聚类分析:一.对数据进行因子分析,实验步骤:1在SPSS窗口中选择:分析-降维-因子分析,在因子分析主界面将变量X1 移入变量框2点击“描述”,在对话框中,统计量选择:原始分析结果,相关矩阵选择:系数,以描述相关系数,点击继续3点击“抽取”,在对话框中,方法为主成份,分析选择:相关性矩阵,输出选择:未旋转的因子解和碎石图,抽取中选择基于特征值(特征值大于1)或者因子的固定数量(要提取的因子为2),点击继续4点击“旋转”,在对话框中,方法为最大方差法,在输出中选择旋转解和载荷图(当因子数=2时),点击继续5点击“得分”,在对话框中,选中“保存为变量”和“显示因子得分系数矩阵”,在方法中选择“回归”,点击继续6点击确定实验结果分析:1.特征根和累计贡献率由表中可以看出,因为成份1和2的特征值>1,被提取出来,而且由于第三个特征根相比下降比较快,我们也只选取两个公共因子,对1和2旋转后其累计贡献率为82.488%。
由碎石图,我们也可以看出1和2的特征值大于1,可以被提取出来,其余变量特征值过小,不予提取。
从旋转成份矩阵可以看出,经过旋转的载荷系数产生了明显的区别,横向找到最大的一个数,如上表中黄色部分画出,第一个公因子在v1,v3,v5上占有较大载荷,说明于这三个指标有较大的相关性,命名为;第二个公因子在v2,v4,v6上有较大载荷,有较大相关性,归为一类,可命名为。
该表为成分转换矩阵,给出旋转所需的矩阵可以用成份得分系数矩阵写出各个因子关于中心标准化后的变量的表达式。
F1=0.385x1-0.001x2+…..F2=…..(分析的举例:第一个因子在外貌自信心洞察力推销能力工作魄力志向抱负理解能力潜能等变量上有较大的系数,可以抽象为应聘者主客观工作能力因子第二个因子在简历格式工作经验适应力变量上有较大的系数,可抽象为应聘者对客观环境的适应力因子第三个因子在兴趣爱好诚信度求职渴望度变量上有较大的系数,可抽象为应聘者的兴趣和诚信因子。
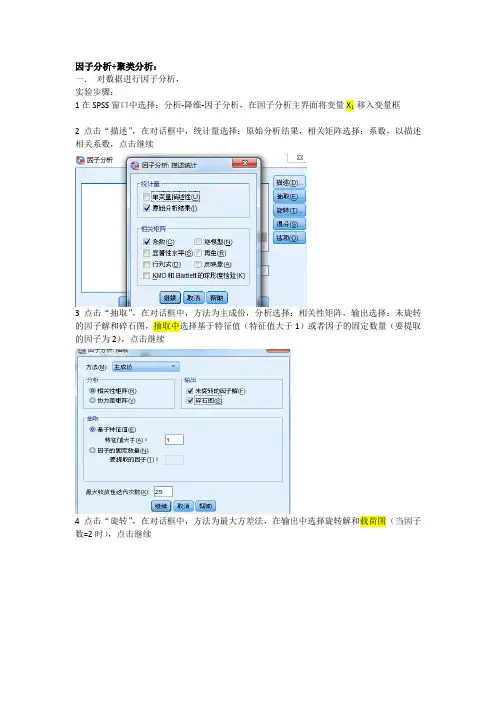
因子分析+聚类分析:一.对数据进行因子分析,实验步骤:1在SPSS窗口中选择:分析-降维-因子分析,在因子分析主界面将变量X1 移入变量框2点击“描述”,在对话框中,统计量选择:原始分析结果,相关矩阵选择:系数,以描述相关系数,点击继续3点击“抽取”,在对话框中,方法为主成份,分析选择:相关性矩阵,输出选择:未旋转的因子解和碎石图,抽取中选择基于特征值(特征值大于1)或者因子的固定数量(要提取的因子为2),点击继续4点击“旋转”,在对话框中,方法为最大方差法,在输出中选择旋转解和载荷图(当因子数=2时),点击继续5点击“得分”,在对话框中,选中“保存为变量”和“显示因子得分系数矩阵”,在方法中选择“回归”,点击继续6点击确定实验结果分析:1.特征根和累计贡献率解释的总方差成份初始特征值提取平方和载入旋转平方和载入合计方差的 % 累积 % 合计方差的 % 累积 % 合计方差的 % 累积 %1 2.731 45.520 45.520 2.731 45.520 45.520 2.688 44.802 44.8022 2.218 36.969 82.488 2.218 36.969 82.488 2.261 37.687 82.4883 .442 7.360 89.8484 .341 5.688 95.5365 .183 3.044 98.5806 .085 1.420 100.000提取方法:主成份分析。
由表中可以看出,因为成份1和2的特征值>1,被提取出来,而且由于第三个特征根相比下降比较快,我们也只选取两个公共因子,对1和2旋转后其累计贡献率为82.488%。
由碎石图,我们也可以看出1和2的特征值大于1,可以被提取出来,其余变量特征值过小,不予提取。
成份矩阵a成份1 2v1 .928 .253v2 -.301 .795v3 .936 .131v4 -.342 .789v5 -.869 -.351v6 -.177 .871由旋转前的成分矩阵可以写出每个原始变量关于各个成份的表达式。
第6章因子分析6.1 因子分析数学模型因子分析是很有用的统计分析工具,因子分析的实质就是找出少量不可观测的随机变量,用它们表示众多的可观测随机变量。
以下例子能说明因子分析的意义。
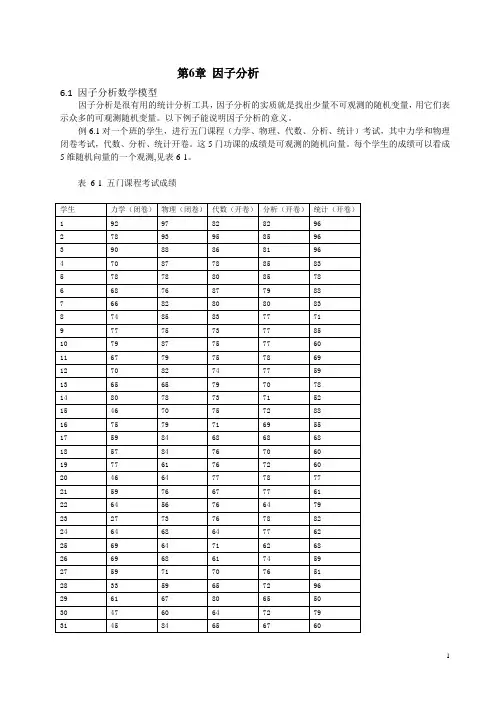
例6.1对一个班的学生,进行五门课程(力学、物理、代数、分析、统计)考试,其中力学和物理闭卷考试,代数、分析、统计开卷。
这5门功课的成绩是可观测的随机向量。
每个学生的成绩可以看成5维随机向量的一个观测,见表6-1。
表6-1 五门课程考试成绩经过一定计算(因子分析)后发现存在不可观测的随机变量:1f 、2f ,它们和51,...x x 间有关系 521542143213221212116377.1091469.9750.678264.162258.5364.721559.013358.6909.720269.564838.7523.721220.864570.8409.62v f f x v f f x v f f x v f f x v f f x +-+=+-+=+-+=+++=+++= (6.1) 其中1f 、2f 是不可观测的随机变量。
我们认为它们分别表示学生的学习能力和适应开闭卷能力,所以可分别称为学习因子和适应开闭卷因子。
(6.1)揭示了这两个因子如何影响5门功课的成绩,也揭示5门课成绩的实质:每门课的成绩由学习因子和适应开闭卷因子的线性组合,加上常数,再加上随机变量而得。
这是是很有意义的。
象例6.1那样,找出少量不可观测因子(例如1f 、2f ),并给出它们影响可观测随机变量(例如51,...x x )方式的统计分析,就是因子分析。
因子分析与主成分分析不同:主成分分析是寻求若干个可观测随机变量的少量线性组合,说明其含义;因子分析主要的目的是找出不一定可观测的潜在变量作为公共因子,并解释公共因子的意义,及如何用不可观测随机变量,计算可观测随机变量。
因子分析方法在心理学,经济,医学,生物学,教育学等方面有重要用途。
因子分析+聚类分析:一.对数据进行因子分析,实验步骤:1在SPSS窗口中选择:分析-降维-因子分析,在因子分析主界面将变量X1 移入变量框2点击“描述”,在对话框中,统计量选择:原始分析结果,相关矩阵选择:系数,以描述相关系数,点击继续3点击“抽取”,在对话框中,方法为主成份,分析选择:相关性矩阵,输出选择:未旋转的因子解和碎石图,抽取中选择基于特征值(特征值大于1)或者因子的固定数量(要提取的因子为2),点击继续4点击“旋转”,在对话框中,方法为最大方差法,在输出中选择旋转解和载荷图(当因子数=2时),点击继续5点击“得分”,在对话框中,选中“保存为变量”和“显示因子得分系数矩阵”,在方法中选择“回归”,点击继续6点击确定实验结果分析:1.特征根和累计贡献率由表中可以看出,因为成份1和2的特征值>1,被提取出来,而且由于第三个特征根相比下降比较快,我们也只选取两个公共因子,对1和2旋转后其累计贡献率为82.488%。
由碎石图,我们也可以看出1和2的特征值大于1,可以被提取出来,其余变量特征值过小,不予提取。
从旋转成份矩阵可以看出,经过旋转的载荷系数产生了明显的区别,横向找到最大的一个数,如上表中黄色部分画出,第一个公因子在v1,v3,v5上占有较大载荷,说明于这三个指标有较大的相关性,命名为;第二个公因子在v2,v4,v6上有较大载荷,有较大相关性,归为一类,可命名为。
该表为成分转换矩阵,给出旋转所需的矩阵可以用成份得分系数矩阵写出各个因子关于中心标准化后的变量的表达式。
F1=0.385x1-0.001x2+…..F2=…..(分析的举例:第一个因子在外貌自信心洞察力推销能力工作魄力志向抱负理解能力潜能等变量上有较大的系数,可以抽象为应聘者主客观工作能力因子第二个因子在简历格式工作经验适应力变量上有较大的系数,可抽象为应聘者对客观环境的适应力因子第三个因子在兴趣爱好诚信度求职渴望度变量上有较大的系数,可抽象为应聘者的兴趣和诚信因子。

Eviews多元因子分析案例分析
多元因子分析是一种常用的经济数据分析方法,它能够帮助我
们解释变量之间的关系以及其对观察数据的影响程度。
本文将以一
个案例为例,演示如何使用Eviews进行多元因子分析。
案例背景
在这个案例中,我们有一组经济数据,包括GDP增长率、通
货膨胀率、利率、失业率和投资增长率。
我们希望通过多元因子分析,找出这些变量之间的主要关系,并解释它们对经济发展的影响。
数据准备
在进行多元因子分析之前,我们首先需要准备好数据。
将数据
导入Eviews软件,并确保数据格式正确。
模型建立
在Eviews中,我们可以使用多元线性回归模型来进行因子分析。
通过选择适当的解释变量和因变量,我们可以建立一个能够解
释经济数据变动的模型。
数据分析
在模型建立完成后,我们可以进行数据分析。
通过观察回归结果,我们可以得出变量之间的关系以及各自的影响程度。
同时,我
们还可以进行统计检验,以评估模型的拟合程度和变量的显著性。
结论
通过Eviews多元因子分析,我们可以得出经济数据变量之间
的关系和影响程度。
这些结果可以帮助我们更好地理解经济的运行
规律,为决策提供参考。
以上就是Eviews多元因子分析的案例分析。
通过这个案例,
我们可以更好地掌握使用Eviews进行多元因子分析的方法和步骤。
希望本文对您有所帮助!。


多元统计实验报告设计题目:因子分析一、分析数据1995年我国社会发展状况的数据二、基本原理因子分析的基本思想是把每个研究变量分解为几个影响因素变量,将每个原始变量分解成两部分因素,一部分是由所有变量共同具有的少数几个公共因子组成的,另一部分是每个变量独自具有的因素,即特殊因子。
三、实验步骤及其结果分析1、选择Analyze→Data Reduction→Factor,打开Factor Analysis主对话框;2、选择变量X1至X6,点击向右的箭头按钮,将六个变量移到Variable栏中;3、点击Descriptives…按钮,打开Descriptives子对话框。
在此对话框的Statistics下选择Initial solution;Correlation Matrix下选择coefficients,单击Continue按钮,返回Factor Analysis主对话框;4、单击Extraction…按钮,打开Extraction子对话框。
在此对话框的Method 下选择Principal components;Analyze下选择Correlation Matrix;Extract下选择Number of Factor,并在其右端的矩形框键入6;Display下选择Unrotated factor 和Scree plot,单击Continue按钮,返回Factor Analysis主对话框;点击OK按钮,显示结果清单。
(1)相关矩阵从表Correlation Matrix(相关矩阵)可知,各变量间存在较强的相关关系,因此有必要进行因子分析。
表中主对角线上的元素为1,表明变量自身于自身的相关系数为1。
(2)解释总方差从表Total Variance Explained(解释总方差)可知,前三个因子一起解释总方差的93.466%(累计贡献率),这说明前三个因子提供了原始数据的足够信息。
5、根据以上分析提取因子情况,单击Extraction…按钮,打开Extraction子对话框。

