Oracle通过sqlplus spool导入出数据
- 格式:docx
- 大小:21.19 KB
- 文档页数:6

Oracle数据库的导⼊导出
在接管⼀个服务器维护⼯作的时候遇到⼀个oracle数据库迁移的问题,没弄个oracle,因此百度查、找同事问,弄的鸡飞狗跳。
⾸先是导出(其实还有⼀种⽅式:⽤plsql导出)
exp ⽤户名/密码@SID file=f:\xx.dmp owner=⽤户名,回车
在导出成功后,在选定的路径中即可找到备份的数据库⽂件(备份⽂件格式为:DMP)
其次是导⼊
我打算⽤同⼀个表空间,因此需要先创建⼀个⽤户
因为是本地,因此输⼊命令连接到库
sqlplus / as sysdba
创建⽤户
create user 账户 identified by 数据库 default tablespace 表空间名
⽤户授权
grant connect, resource to ⽤户名
grant dba to ⽤户名
导⼊数据库
imp 账号/⼝令@数据库 fromuser=备份时导出账号 touser=账号(现⽤账号)
然后会提⽰你没有DMP⽂件,把DMP⽂件拖进去即可。

oracle导数据的方式【原创实用版】目录1.Oracle 简介2.Oracle 导数据的方式2.1 使用 SQL*Plus2.2 使用数据泵2.3 使用导入导出工具2.4 使用外部表2.5 使用批处理正文Oracle 是一款广泛使用的关系型数据库管理系统,它具有高性能、安全、可扩展性强等特点。
在 Oracle 中,数据的导入导出是非常常见的操作。
下面我们将介绍几种 Oracle 导数据的方式。
首先,我们来介绍一下使用 SQL*Plus 导数据。
SQL*Plus 是 Oracle 提供的一个命令行工具,通过它可以直接执行 SQL 语句。
要使用SQL*Plus 导数据,需要先登录到 Oracle 数据库,然后使用 INSERT、SELECT 等 SQL 语句将数据导入到目标表中。
这种方法适用于数据量较小的情况。
其次,我们来介绍一下使用数据泵导数据。
数据泵是 Oracle 提供的一个数据传输工具,它可以将数据从一个源移动到另一个源,包括将数据导入到 Oracle 数据库中。
使用数据泵导数据需要创建一个数据泵实例,然后使用相应的命令将数据导入到目标表中。
数据泵适用于大量数据的导入导出操作。
再来介绍一下使用导入导出工具导数据。
Oracle 提供了一个名为“导入导出”的图形化工具,通过它可以方便地实现数据的导入导出。
使用导入导出工具需要先创建一个导入导出任务,然后设置相应的导入导出选项,最后执行任务将数据导入到目标表中。
这种方法适用于对数据库操作不熟悉的用户。
此外,还可以使用外部表导数据。
外部表是 Oracle 提供的一种数据存储方式,它允许将数据存储在文件系统中,同时又能像操作普通表一样操作外部表。
要使用外部表导数据,需要先创建一个外部表,然后将数据文件复制到指定的位置,最后使用 ALTER TABLE 命令将数据加载到外部表中。
这种方法适用于数据量较大且需要频繁访问数据的情况。
最后,我们来介绍一下使用批处理导数据。

oracle之spool详细使⽤总结(转)今天实际项⽬中⽤到了spool,发现⽹上好多内容不是很全,⾃⼰摸索了好半天,现在总结⼀下。
⼀、通过spool 命令,可以将select 数据库的内容写到⽂件中,通过在sqlplus设置⼀些参数,使得按指定⽅式写到⽂件中(1)常规使⽤spool⽅法,将set的⼀些命令和spool,select等放⼊.sql脚本中,然后再sqlplus中运⾏该脚本。
以下为logmnr.sql脚本,在sqlplus中执⾏@logmnr.sql就可以写⼊⽂件record3.txt中。
不会再终端显⽰任何信息。
但是,如果是在sqlplus中输⼊:set termout off;......spool record3.txtselect ....... from .....;spool off;前⾯的设置是没有⽤的,还是会在终端中显⽰⼤量信息。
1 set echo off;2 set heading off;3 set line 100;4 set long 2000000000;5 set longchunksize 255;6 set wra on;7 set newpage none;8 set pagesize 0;9 set numwidth 12;10 set termout off;11 set trimout on;12 set trimspool on;13 set feedback off;14 set timing on;15 execute dbms_logmnr.add_logfile(LogFileName=>'/oracle/app/oracle/logs/hrbfct_1_4156_748575599.arc',Options=>dbms_logmnr.new);16 execute dbms_logmnr.add_logfile(LogFileName=>'/oracle/app/oracle/logs/hrbfct_2_6645_748575599.arc',Options=>dbms_logmnr.addfile);17 execute dbms_logmnr.start_logmnr(DictFileName=>'/oracle/app/oracle/logs/dict.ora');18 spool /oracle/app/oracle/logs/record3.txt;19 select to_clob(sql_redo)||'|'||to_char(scn)||'|'||to_char(timestamp)||'|'||to_char(session_info)||'|'||to_char(table_name)||'|'||to_char(seg_owner)||'?'20 from v$logmnr_contents;21 spool off;22 exit;(2)那到底能否在shell脚本中运⾏还不显⽰这些信息呢,答案是有的。

Oracle导⼊导出数据的⼏种⽅式oracle导⼊导出数据1.导出dmp格式⽂件--备份某⼏张表exp smsc/smsc file=/data/oracle_bak/dmp/bakup0209_2.dmp tables=\(send_msg_his,send_msg,recv_msg_his,recv_msg\)--备份整个数据库--⽅式1exp smsc/smsc file=/data/oracle_bak/dmp/bakupsmmc0209_2.dmp full=y--⽅式2exp cop/cop@133.96.84.39:1521/coprule file=/home/oracle/cop_20160902.dmp owner=cop log=/home/oracle/cop.log--本机上exp zop/zop@orcl file= D:\zop_bak.dmp owner=zop log=D:\zop_ba.log2.导⼊dmp格式⽂件--数据的导⼊--1 将D:\daochu.dmp 中的数据导⼊ TEST数据库中。
imp system/manager@TEST file=d:\daochu.dmpimp aichannel/aichannel@TEST full=y file=d:\datanewsmgnt.dmp ignore=y--上⾯可能有点问题,因为有的表已经存在,然后它就报错,对该表就不进⾏导⼊。
-- 在后⾯加上 ignore=y 就可以了。
--2 将d:daochu.dmp中的表table1 导⼊imp system/manager@TEST file=d:\daochu.dmp tables=(table1)--基本上上⾯的导⼊导出够⽤了。
不少情况要先是将表彻底删除,然后导⼊。
注意:操作者要有⾜够的权限,权限不够它会提⽰。
数据库时可以连上的。
可以⽤tnsping TEST 来获得数据库TEST能否连上。

Oracle数据库导入导出命令总结Oracle数据库导入导出命令总结执行环境:可以在SQLPLUS.EXE或者DOS(命令行)中执行,DOS中可以执行时由于在oracle中,安装目录\\ora9i\\BIN被设置为全局路径,该目录下有EXP.EXE与IMP.EXE文件被用来执行导入导出。
oracle用java编写,SQLPLUS.EXE、EXP.EXE、IMP.EXE这两个文件是被包装后的类文件。
SQLPLUS.EXE调用EXP.EXE、IMP.EXE所包裹的类,完成导入导出功能。
下面介绍的是导入导出的实例。
数据导出:1将数据库zxcc完全导出,用户名kf密码zx导出到D:\\zxcc.dmp中expkf/zx@zxccfile=d:\\zxcc.dmpfull=yfull=y表示全库导出。
full总共有2个可选项yes(y)/no(n),缺省情况下full=no,这时只会将该用户下的对象导出。
2将数据库zxcc中kf用户与cc用户的表导出expkf/zx@zxccfile=d:\\zxcc_ur.dmpowner=(kf,cc)full方式可以备份所有用户的数据库对象,包括表空间、用户信息等,owner=XX只能备份指定用户的对象,其他用户下的就不备份了,EXP中full=y和owner=XX是不能同时使用的。
3将数据库zxcc中的表kf_operator、kf_role导出expkf/zx@zxccfile=d:\\zxcc_tb.dmptables=(kf_operator,kf_role)tables=xx表示备份相关表,不能同时和owner、full使用。
4将数据库中的表kf_operator中的字段oper_id以"00"打头的数据导出expkf/zx@zxccfile=d:\\zxcc_t.dmptables=(kf_operator)query=\\"whereop er_idlike"00%"\\"query主要是导出合适条件的数据。

oracle数据的导⼊导出(两种⽅法三种⽅式)⼤概了解数据库中数据的导⼊导出。
在oracle中,导⼊导出数据的⽅法有两种,⼀种是使⽤cmd命令⾏的形式导⼊导出数据,另⼀种是使⽤PL/SQL⼯具导⼊导出数据。
1,使⽤cmd命令⾏导⼊导出数据 1.1整库导出 整库导出:exp 管理员账号/密码 full=y;//参数full表⽰整库导出。
导出后会在当前⽬录下⽣成⼀个EXPDAT.DMP的⽂件,此⽂件为备份⽂件。
如果想导出数据到指定位置,并且取个名字,需要添加file参数。
例如:exp system/123456 file= C:\person.dmp full=y。
1.2整库导⼊ 整库导⼊:imp 管理员账号/密码 full=y file=C:\person.dmp。
1.3使⽤cmd命令按⽤户导出导⼊ 1.3.1 按⽤户导出:exp 管理员账号/密码 owner=⽤户名 file=C:\person.dmp。
1.3.2 按⽤户导⼊:imp 管理员账号/密码 file=C:\person.dmp fromuser=⽤户名。
1.4使⽤cmd命令按表导出导⼊ 1.4.1按表导出:exp 管理员账号/密码 file=person.dmp tables=t_person,t_student。
1.4.2按表导⼊:imp 管理员账号/密码 file =person.dmp tables=t_person,t_student。
2.)使⽤PL/SQL 开发⼯具导出导⼊数据 pl/sql⼯具包含三种⽅式导出oracle表结构和表数据,分别为:oracle export,SQL inserts,pl/sql developer。
它们的含义如下: 第⼀种oracle export:导出的是.dmp格式的⽂件,.dmp⽂件是⼆进制⽂件,可以跨平台,包含权限等。
第⼆种SQL inserts :导出的是.sql格式的⽂件,可以⽤⽂本编辑器查看,通⽤性⽐较好,效率不如第⼀种,适合⼩数据量的导⼊导出。

Oracle导出excel数据推荐阅读:oracle导出excel(⾮csv)的⽅法有两种,1、使⽤sqlplus spool,2、使⽤包体现将⽹上相关代码整理后贴出以备不时之需:使⽤sqlplus:使⽤sqlplus需要两个⽂件:sql脚本⽂件和格式设置⽂件。
去除冗余信息,main.sql--main.sql 注意,需要在sqlplus下运⾏⾮plsql命令⾏下set linesize 200set term off verify off feedback off pagesize 999set markup html on entmap ON spool on preformat offspool test_tables.xls@get_tables.sqlspool offexitsql脚本,get_tables.sql--get_tables.sqlselect * from all_objects where rownum<=1000;然后在sqlplus下运⾏main.sql使⽤包体编程:create or replace package smt_xlsx_maker_pkg is/******************************************************************************NAME: SMT_XLSX_MAKER_PKGPURPOSE: XLSX ⽣成 Pkg,主要是从Oracle数据库端⽣成Xlsx⼆进制的⽂件。
REVISIONS:Ver Date Author Description--------- ---------- --------------- ------------------------------------1.0 2011/2/19 Anton Scheffer 1,New Create the pkg1.1 2015/6/10 Sam.T 1.优化核⼼处理⽣成xlsx的代码,使得⽣成⽂档的执⾏效率⼤⼤提⾼!1.1 2015/6/10 Sam.T 1.query2sheet增加绑定变量的可选输⼊参数。

Oracle中Spool命令的使⽤⽅法实例
前⾔
对于Oracle中的Spool命令,其实还可以换⼀种问法为,如何将sqlplus中的结果输出到指定的⽂件夹中。
近期在进⾏Oracle数据库备份的时候,由于数据库安装时出现问题,在进⾏逐步排查过程时,为了⽅便,将执⾏的相关语句在控制台的结果信息都输出到⽇志⽂件,以便能及时反馈到Oracle相关⽀持部门进⾏问题解决。
Oracle中Spool 命令使⽤⽅法
⽅法/步骤
⾸先需要明⽩Spool是Oracle的命令⽽不是sql语句。
Spool命令是将在这期间oracle所有的操作结果写⼊到指定的⽂件中。
其实可以理解为spool命令将创建⼀个新⽂件,在接下来对oracle所有的操作及操作接⼝都将输⼊到该⽂件中。
1、使⽤Spool命令前期准备
当前需要对Spool进⾏⼀些设置。
常⽤的设置有如下⼏种其解释如图:
2、创建接收⽂件
前期⼯作准备完成,接下来就是创建接收信息的⽂件,如我们创建⼀个⽂件名为moreinfo.log的接收⽂件。
3、执⾏操作
接下来,我们就可以进⾏相关操作了,⽐如查询⼀个表的数据等
4、关闭Spool
在对数据库操作完成后,接下来就是关闭Spool命令并将信息更新到创建的⽂件中。
这样我们就讲操作数据库相应的结果写⼊到moreinfo.log中了。
5、查看⽂件是否已经⽣成。
我们需要先退出sqlplus,在进⾏ls,查看⽂件是否已经⽣成。
总结
到此这篇关于Oracle中Spool命令使⽤的⽂章就介绍到这了,更多相关Oracle中Spool命令使⽤内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
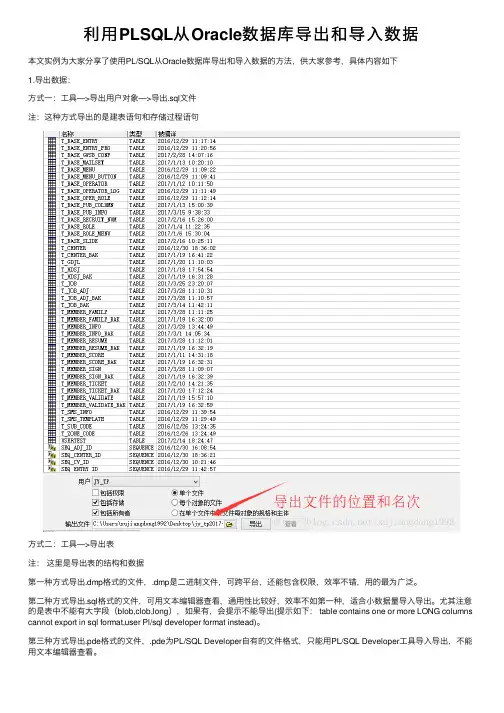
利⽤PLSQL从Oracle数据库导出和导⼊数据
本⽂实例为⼤家分享了使⽤PL/SQL从Oracle数据库导出和导⼊数据的⽅法,供⼤家参考,具体内容如下
1.导出数据:
⽅式⼀:⼯具—>导出⽤户对象—>导出.sql⽂件
注:这种⽅式导出的是建表语句和存储过程语句
⽅式⼆:⼯具—>导出表
注:这⾥是导出表的结构和数据
第⼀种⽅式导出.dmp格式的⽂件,.dmp是⼆进制⽂件,可跨平台,还能包含权限,效率不错,⽤的最为⼴泛。
第⼆种⽅式导出.sql格式的⽂件,可⽤⽂本编辑器查看,通⽤性⽐较好,效率不如第⼀种,适合⼩数据量导⼊导出。
尤其注意的是表中不能有⼤字段(blob,clob,long),如果有,会提⽰不能导出(提⽰如下: table contains one or more LONG columns cannot export in sql format,user Pl/sql developer format instead)。
第三种⽅式导出.pde格式的⽂件,.pde为PL/SQL Developer⾃有的⽂件格式,只能⽤PL/SQL Developer⼯具导⼊导出,不能⽤⽂本编辑器查看。
2. 数据导⼊(Tools→Import Tables…)
1.导⼊.dmp类型的oracle⽂件。
2.导⼊.sql类型的oracle⽂件。
3.导⼊.pde类型的oracle⽂件。
以上就是本⽂的全部内容,希望对⼤家的学习有所帮助,也希望⼤家多多⽀持。

Oracle 数据导入导出详细步骤说明:1.请先设置好 oracle 实例的环境变量 [grneas 是当前已安装的数据库实例名 ]Windows 下在 cmd 命令窗口执行: set ORACLE_SID=grneas Linux/AIX 下在终端窗口执行: exportORACLE_SID=grneasWindows 下查看该变量是否正确的命令:echo %ORACLE_SID%Linux/AIX 下查看该变量是否正确的命令: echo $ORACLE_SID 2.进入 sqlplus 窗口的命令:所有操作系统都用: sqlplus /nologconn / as sysdba 一、 Oracle 数据导出(备份)1.创建目录(导出文件存放位置)在 sqlplus 窗口下执行:grant read,write on directory expdpdir to system,grneas;其中: expdpdir 为目录名, grneas 是 EAS 用户名3.数据导出windows 在 cmd 窗口, linux 、AIX 在终端 ssh 窗口直接执行:(不要进入 sqlplus 窗口)expdp grneas/kingdee@grneas schemas=grneasdirectory=expdpdirdumpfile=grneas_20110706.dmplogfile=grneas_20110706.log 说明: 1).以上命令要在同一行输入再回车2).其中的 grneas/kingdee@grneas 是指要连接的数据库实例、用户及密码,若已在前面设置好环境变量 ORACLE_SID 为当前要导出的实例,则可不加 @grneas3).schemas=grneas表示要导出的 EAS 用户(方案)为 grneas, 在oracle 下,数据库对象在不同用户间是隔离的,每个用户都有自己的一些表、视图等,所以我们只要导出 EAS 用户的数据就可以了4).directory=expdpdir 表示导出时使用的目录,也就是文件存放的位置5).dumpfile=grneas_20110706.dmp 表示导出的数据文件名6).logfile=grneas_20110706.log 表示导出日志文件名,也存放在相同目录下二、 Oracle 数据导入(还原)以下是将原 grneas 数据备份还原到新账套 grneas21.创建表空间在 sqlplus 窗口下执行:create tablespaceEAS_D_grneas2_STANDARD datafile'/oradata/test/EAS_D_grneas2_STANDARD.dbf' size 2000m;以上命令创建数据表空间,要在同一行下回车执行 create temporarytablespace EAS_T_grneas2_STANDARD tempfile'/oradata/test/EAS_T_grneas2_STANDARD.dbf' size 500m;以上命令创建临时表空间,要在同一行下回车执行2.设置表空间自动增长在 sqlplus 窗口下执行:alter database datafile'/oradata/test/EAS_D_grneas2_STANDARD.dbf' autoextend on;alter database tempfile'/oradata/test/EAS_T_grneas2_STANDARD.dbf' autoextend on;3.创建目录(若目录已创建,可以略去不做,准备导入的备份文件要放在此目录下)在 sqlplus 窗口下执行: create user grneas2 identified by kingdee default tablespace EAS_D_grneas2_STANDARD temporary tablespace EAS_T_grneas2_STANDARD; 说明:identified by kingdee 表示密码为 kingdee 5.用户授权grant connect,resource,dba to grneas2;6.目录授权grant read,write on directory expdpdir tosystem,grneas2;7•数据导入(将原grneas账套恢复到一个新的 grneas2账套)impdp grneas2/kingdee@grneas directory=expdpdirdumpfile=grneas_20110706.dmplogfile=impgrneas_20110706.l og schemas=grneasremap_schema=grneas:grneas2remap_tablespace=EAS_D_grneas_STANDARD:EAS_D_grneas2_STANDARD,EAS_T_grneas_STANDARD:EAS_T_grneas2_STANDARD--sqlfile=script.sql ( 生成 SQL 脚本 )说明: 1).以上命令要在同一行输入再回车2).其中的grneas2/kingdee@grneas是指要连接的数据库实例、用户及密码,若已在前面设置好环境变量 ORACLE_SID 为当前要导入的实例,则可不加 @grneas3).schemas=grneas表示要导入的原 EAS 用户(方案)为grneas4).directory=expdpdir 表示导入时使用的目录,也就是文件存放的位置5).dumpfile=grneas_20110706.dmp 表示要导入的数据文件6).logfile=impgrneas_20110706.log 表示导入时产生的日志文件7).remap_schema=grneas:grneas2表示导入的数据也由原来的 EAS_D_grneas_STANDARD 改为存储到 EAS_D_grneas2_STANDARD 表空间9).--sqlfile=script.sql ( 生成 SQL 脚本)表示只生成脚本,有加这个参数就只生成脚本没有导入数据,要查看脚本才加这个参数,否则在导入的时候,就不要加这个参数注意区别大小写……其它 oracle 命令查看用户与表空间Select * from dba_users;查看锁表进程 SQL 语句 1:select sess.sid,sess.serial#,lo.oracle_username,lo.os_user_name,ao.object_name,lo.locked_modefrom v$locked_object lo,dba_objects ao, v$session sesswhere ao.object_id = lo.object_id andlo.session_id = sess.sid;查看锁表进程 SQL 语句 2:select * from v$session t1, v$locked_objectt2 where t1.sid = t2.SESSION_ID;杀掉锁表进程:如有記錄則表示有 lock ,記錄下 SID 和 serial# ,將記錄的ID 替換下面的 738,1429,即可解除 LOCK alter system kill session '738,1429';数据库用户被锁定时解锁命令alter user theas account unlock;启动 EMemctl start dbconsole。

SPOOL、SQLLOADER数据导出导入的一点小总结SPOOL、SQLLOADER数据导出导入一、SQLLOADER的CONTROL文件基本格式:LOAD DATAINFILE 'T.DAT' // 要导入的数据文件(格式1)//INFILE 'TT.DAT' // 导入多个文件(可以和格式1并列使用)//INFILE * // 要导入的内容就在CONTROL文件里下面的BEGINDATA后面就是导入的内容(和格式1互斥使用) APPEND INTO TABLE TABLE_NAME//指定装入的表(这里有几种加载方式) //以下是4种装入表的方式//APPEND//原先的表有数据就加在后面//INSERT//装载空表,如果原先的表有数据SQLLOADER会停止默认值//REPLACE//原先的表有数据原先的数据会全部删除//TRUNCATE//指定的内容和REPLACE的相同会用TRUNCATE 语句删除现存数据BADFILE 'C:BAD.TXT' // 指定坏文件地址FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'//装载这种数据: "10","20","30","40","50"//TERMINATED BY X'09' // 以十六进制格式'09'表示文本文件用TAB键分隔//示例文本数据: "10" "20" "30" "40" "50"//TERMINATED BY WHITESPACE // 装载这种数据: "10" "lg" "lg"TRAILING NULLCOLS*************表的字段没有对应的值时允许为空(COL_1,COL_2,COL_FILLER FILLER//FILLER关键字此列的数值不会被装载)//指定的TERMINATED可以在表的开头也可在表的内部字段部分//当没声明FIELDS TERMINATED BY ','时也可以逐个字段来声明//(//COL_1 [INTERGER EXTERNAL] TERMINATED BY ',' ,//COL_2 [DATE "DD-MON-YYY"] TERMINATED BY ',' ,//COL_3 [CHAR] TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'//)// 当没声明FIELDS TERMINATED BY ','用位置告诉字段装载数据//(//COL_1 POSITION(1:2),//COL_2 POSITION(3:10),//COL_3 POSITION(*:16), // 这个字段的开始位置在前一字段的结束位置//COL_4 POSITION(3:10) CHAR(8), // 指定字段的类型//COL_5 POSITION(3:10) "TRIM(:COL_5)", // 挤压两端空格//COL_6 POSITION(3:10) "SEQ.NEXTV AL", // 取SEQUENCE值//)BEGINDATA//对应开始的INFILE*要导入的内容就在CONTROL 文件里10,20,3020,30,40//注意BEGINDATA后的数值前面不能有空格二、CONTROL文件示例:1、普通装载LOAD DATAINFILE *REPLACE INTO TABLE DEPTFIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'(DEPTNO,DNAME,LOC)BEGINDATA10,SALES,"""USA"""20,ACCOUNTING,"VIRGINIA,USA"30,CONSULTING,VIRGINIA40,FINANCE,VIRGINIA50,"FINANCE","",VIRGINIA // LOC 列将为空60,"FINANCE",,VIRGINIA // LOC 列将为空2 、FIELDS TERMINATED BY WHITESPACE 和FIELDS TERMINATED BY X'09' 的情况LOAD DATAINFILE *REPLACE INTO TABLE DEPTFIELDS TERMINATED BY WHITESPACEFIELDS TERMINATED BY X'09'(DEPTNO,DNAME,LOC)BEGINDATA10 Sales Virginia3 、指定不装载那一列LOAD DATAINFILE *REPLACE INTO TABLE DEPTFIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'( DEPTNO,FILLER_1 FILLER, // 下面的"Something Not To Be Loaded" 将不会被装载//,DNAME,LOC) BEGINDATA20,Something Not To Be Loaded,Accounting,"Virginia,USA"4、POSITION的列子LOAD DATAINFILE *REPLACE INTO TABLE DEPT( DEPTNO POSITION(1:2),DNAME POSITION(*:16), // 这个字段的开始位置在前一字段的结束位置,LOC POSITION(*:29), ENTIRE_LINE POSITION(1:29))BEGINDATA10ACCOUNTING VIRGINIA,USA5 、使用函数日期的一种表达TRAILING NULLCOLS的使用LOAD DATAINFILE *REPLACE INTO TABLE DEPTFIELDS TERMINATED BY ','TRAILING NULLCOLS // 其实下面的ENTIRE_LINE在BEGINDATA后面的数据中是没有直接对应的列的值,//如果第一行改为10,Sales,Virginia,1/5/2000,, 就不用TRAILING NULLCOLS了(DEPTNO,DNAME "UPPER(NAME)", // 使用函数,LOC "UPPER(:LOC)",LAST_UPDATED DATE 'DD/MM/YYYY', // 日期的一种表达方式还有'DD-MON-YYYY' 等ENTIRE_LINE "EPTNO||NAME||:LOC||:LAST_UPDATED")BEGINDATA10,Sales,Virginia,1/5/200020,Accounting,Virginia,21/6/199930,Consulting,Virginia,5/1/200040,Finance,Virginia,15/3/20016 、使用自定义的函数// 解决的时间问题CREATE OR REPLACEFUNCTION MY_TO_DATE( P_STRING IN V ARCHAR2 ) RETURN DATE AS TYPE FMTARRAY IS TABLE OF V ARCHAR2(25);L_FMTS FMTARRAY := FMTARRAY( 'DD-MON-YYYY', 'DD-MONTH-YYYY', 'DD/MM/YYYY', 'DD/MM/YYYY HH24:MI:SS' );L_RETURN DATE;BEGINFOR I IN 1 .. L_FMTS.COUNTLOOPBEGINL_RETURN := TO_DATE( P_STRING, L_FMTS(I) );EXCEPTIONWHEN OTHERS THEN NULL;END;EXIT WHEN L_RETURN IS NOT NULL;END LOOP;IF ( L_RETURN IS NULL )THENL_RETURN :=NEW_TIME( TO_DATE('01011970','DDMMYYYY') + 1/24/60/60 *P_STRING, 'GMT', 'EST' );END IF;RETURN L_RETURN;END;/LOAD DATAINFILE *REPLACE INTO TABLE DEPTFIELDS TERMINATED BY ','TRAILING NULLCOLS(DEPTNO,DNAME "UPPER(NAME)",LOC "UPPER(:LOC)",LAST_UPDATED "MY_TO_DATE( :LAST_UPDATED )" // 使用自定义的函数)BEGINDATA10,Sales,Virginia,01-april-200120,Accounting,Virginia,13/04/200130,Consulting,Virginia,14/04/2001 12:02:0240,Finance,Virginia,98726829750,Finance,Virginia,02-apr-200160,Finance,Virginia,Not a date7 、合并多行记录为一行记录LOAD DATAINFILE *CONCATENATE 3 // 通过关键字CONCATENATE 把几行的记录看成一行记录INTO TABLE DEPTREPLACE //注意这个例子格式与前边有些不同FIELDS TERMINATED BY ','(DEPTNO,DNAME "UPPER(NAME)",LOC "UPPER(:LOC)",LAST_UPDATED DATE 'DD/MM/YYYY') BEGINDATA10,Sales, // 其实这3行看成一行10,Sales,Virginia,1/5/2000Virginia,1/5/2000// 这列子用CONTINUEIF LIST="," 也可以告诉SQLLDR在每行的末尾找逗号找到逗号就把下一行附加到上一行LOAD DATAINFILE *CONTINUEIF THIS(1:1) = '-' // 找每行的开始是否有连接字符- 有就把下一行连接为一行// 如-10,Sales,Virginia,// 1/5/2000 就是一行10,Sales,Virginia,1/5/2000// 其中1:1 表示从第一行开始并在第一行结束还有CONTINUEIF NEXT 但CONTINUEIF LIST最理想INTO TABLE DEPTREPLACEFIELDS TERMINATED BY ','(DEPTNO,DNAME "upper(:dname)",LOC "upper(:loc)",LAST_UPDATED date 'dd/mm/yyyy')BEGINDATA // 但是好象不能象右面的那样使用-10,Sales,Virginia, -10,Sales,Virginia,1/5/2000 1/5/2000-40, 40,Finance,Virginia,13/04/2001Finance,Virginia,13/04/20018 、载入每行的行号LOAD DATAINFILE *INTO TABLE TREPLACE( SEQNO RECNUM //载入每行的行号TEXT POSITION(1:1024))BEGINDATAfsdfasj //自动分配一行号给载入表t 的seqno字段此行为1fasdjfasdfl // 此行为2 ...9 、载入有换行符的数据注意: UNIX 和WINDOWS 不同n & /n< 1 > 使用一个非换行符的字符LOAD DATAINFILE *INTO TABLE DEPTREPLACEFIELDS TERMINATED BY ','TRAILING NULLCOLS(DEPTNO,DNAME "UPPER(NAME)",LOC "UPPER(:LOC)",LAST_UPDATED "MY_TO_DATE( :LAST_UPDATED )",COMMENTS "REPLACE(:COMMENTS,'N',CHR(10))" // REPLACE 的使用帮助转换换行符)BEGINDATA10,Sales,Virginia,01-april-2001,This is the SalesnOffice in Virginia20,Accounting,Virginia,13/04/2001,This is the AccountingnOffice inVirginia30,Consulting,Virginia,14/04/2001 12:02:02,This is the ConsultingnOfficein Virginia40,Finance,Virginia,987268297,This is the FinancenOffice in Virginia< 2 > 使用fix属性LOAD DATAINFILE DEMO17.DAT "FIX 101"INTO TABLE DEPTREPLACEFIELDS TERMINATED BY ','TRAILING NULLCOLS(DEPTNO,DNAME "UPPER(NAME)",LOC "UPPER(:LOC)",LAST_UPDATED "MY_TO_DATE( :LAST_UPDATED )",COMMENTS)BEGINDATA10,Sales,Virginia,01-april-2001,This is the Sales20,Accounting,Virginia,13/04/2001,This is the AccountingOffice in Virginia30,Consulting,Virginia,14/04/2001 12:02:02,This is the ConsultingOffice in Virginia40,Finance,Virginia,987268297,This is the FinanceOffice in Virginia// 这样装载会把换行符装入数据库,下面的方法就不会,但要求数据的格式不同LOAD DATAINFILE DEMO18.DAT "FIX 101"INTO TABLE DEPTREPLACEFIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'TRAILING NULLCOLS(DEPTNO,DNAME "UPPER(NAME)",LOC "UPPER(:LOC)",LAST_UPDATED "MY_TO_DATE( :LAST_UPDATED )",COMMENTS)BEGINDATA10,Sales,Virginia,01-april-2001,"This is the SalesOffice in Virginia"20,Accounting,Virginia,13/04/2001,"This is the Accounting Office in Virginia"30,Consulting,Virginia,14/04/2001 12:02:02,"This is the ConsultingOffice in Virginia"40,Finance,Virginia,987268297,"This is the Finance< 3 > 使用var属性LOAD DATAINFILE DEMO19.DAT "V AR 3"// 3 告诉每个记录的前3个字节表示记录的长度如第一个记录的071 表示此记录有71 个字节INTO TABLE DEPTREPLACEFIELDS TERMINATED BY ','TRAILING NULLCOLS(DEPTNO,DNAME "UPPER(NAME)",LOC "UPPER(:LOC)",LAST_UPDATED "MY_TO_DATE( :LAST_UPDATED )",COMMENTS)BEGINDATA07110,Sales,Virginia,01-april-2001,This is the SalesOffice in Virginia07820,Accounting,Virginia,13/04/2001,This is the AccountingOffice in Virginia08730,Consulting,Virginia,14/04/2001 12:02:02,This is the ConsultingOffice in Virginia07140,Finance,Virginia,987268297,This is the FinanceOffice in Virginia< 4 > 使用STR属性// 最灵活的一中可定义一个新的行结尾符WIN 回车换行: CHR(13)||CHR(10) ,此列中记录是以A|RN 结束的SELECT UTL_RAW.CAST_TO_RAW('|'||CHR(13)||CHR(10)) FROM DUAL;结果7C0D0ALOAD DATAINFILE DEMO20.DAT "STR X'7C0D0A'"INTO TABLE DEPTREPLACEFIELDS TERMINATED BY ','TRAILING NULLCOLS(DEPTNO,DNAME "UPPER(NAME)",LOC "UPPER(:LOC)",LAST_UPDATED "MY_TO_DATE( :LAST_UPDATED )",COMMENTS)BEGINDATA10,Sales,Virginia,01-april-2001,This is the SalesOffice in Virginia|20,Accounting,Virginia,13/04/2001,This is the AccountingOffice in Virginia|30,Consulting,Virginia,14/04/2001 12:02:02,This is the ConsultingOffice in Virginia|40,Finance,Virginia,987268297,This is the FinanceOffice in Virginia|10 、象这样的数据用nullif 子句10-jan-200002350Flipper seemed unusually hungry today.10510-jan-200009945Spread over three meals.ID POSITION(1:3) NULLIF ID=BLANKS // 这里可以是BLANKS 或者别的表达式// 下面是另一个列子第一行的1 在数据库中将成为NULLLOAD DATAINFILE *INTO TABLE TREPLACE(N POSITION(1:2) INTEGER EXTERNAL NULLIF N='1',V POSITION(3:8))BEGINDATA1 1020lg三、SQLLOADER的命令:SQLLDR USERID=SYS/SYS@DB_SERVICE CONTROL=XXXX.CTL LOG=XXXX.LOGBINDSIZE=1048576 ROWS=100ERRORS=10000 READSIZE=2097152 SILENT=(HEADER,FEEDBACK)关于这些参数的帮助在命令行直接执行SQLLDR可以得到,这里指出BINDSIZE不应该大于READSIZE的值。
sqlplus导出⼀张表数据内⽹只让⽤sql developer 这软件搓的不⾏,数据加载到51⾏就⿊了,没法法⽤sqlplus。
打开cmd,sqlplus user/passwd@ip:port/库名set colsep , //输出分隔符set feedback off //回显本次sql命令处理的记录条数,缺省为onset heading off //输出域标题,缺省为onset trimout onspool xxx.csv --这⾥指定导出csv⽂件的路径和⽂件名称select '"' ||xxxx || '","' || xxxx || '","' || xxx || '"' from tmp; --这⾥指定导出表名和字段名spool offexit⾥的set零零碎碎的,这⾥整理归纳⼀下SQL> set timing on; //设置显⽰“已⽤时间:XXXX”SQL> set autotrace on-; //设置允许对执⾏的sql进⾏分析SQL> set trimout on; //去除标准输出每⾏的拖尾空格,缺省为offSQL> set trimspool on; //去除重定向(spool)输出每⾏的拖尾空格,缺省为offSQL> set echo on //设置运⾏命令是是否显⽰语句SQL> set echo off; //显⽰start启动的脚本中的每个sql命令,缺省为onSQL> set feedback on; //设置显⽰“已选择XX⾏”SQL> set feedback off; //回显本次sql命令处理的记录条数,缺省为onSQL> set colsep' '; //输出分隔符SQL> set heading off; //输出域标题,缺省为onSQL> set pagesize 0; //输出每页⾏数,缺省为24,为了避免分页,可设定为0。
oracle大数据量的导入和导出[ 录入:admin | 日期:2007-05-21 | 作者:| 来源:| 阅读:882 ]在oracle中批量数据的导出是借助sqlplus的spool来实现的。
批量数据的导入是通过sqlloa d来实现的。
在oracle中批量数据的导出是借助sqlplus的spool来实现的。
批量数据的导入是通过sqlloa d来实现的。
大量数据的导出部分如下:/**************************** sql脚本部分demo.sql begin**************************//*************************** @author meconsea* @date 20050413* @msn meconsea@* @Email meconsea@**************************///##--markup html:html格式输出,缺省为off//##--autocommit:自动提交insert、update、delete带来的记录改变,缺省为off//##--define:识别命令中的变量前缀符,缺省为on,也就是'&',碰到变量前缀符,后面的字符串作为变量处理.set colsep' '; //##--域输出分隔符set echo off; //##--显示start启动的脚本中的每个sql命令,缺省为onset feedback off; //##--回显本次sql命令处理的记录条数,缺省为onset heading off; //##--输出域标题,缺省为onset pagesize 0; //##--输出每页行数,缺省为24,为了避免分页,可设定为0。
set linesize 80; //##--输出一行字符个数,缺省为80set numwidth 12; //##--输出number类型域长度,缺省为10set termout off; //##--显示脚本中的命令的执行结果,缺省为onset timing off; //##--显示每条sql命令的耗时,缺省为offset trimout on; //##--去除标准输出每行的拖尾空格,缺省为offset trimspool on; //##--去除重定向(spool)输出每行的拖尾空格,缺省为off spool C:\data\dmczry.txt;select trim(czry_dm),trim(swjg_dm),trim(czry_mc) from dm_czry;spool off;EOF/************************ demo.sql end***********************/在数据导入的时候采用sqlload来调用,在该部分调用的时候用java来调用sqlload。
PLSQL导入导出Oracle数据库方法在Oracle数据库中,我们可以使用PL/SQL来导入和导出数据。
下面是一些常用的方法:1. 使用SQL*Loader工具导入数据:SQL*Loader是Oracle提供的一个强大的数据导入工具。
通过创建一个控制文件和数据文件,可以将数据从外部文件导入到Oracle表中。
以下是一个简单的示例:```sqlLOADDATAINFILE 'data.txt'INTO TABLE empFIELDSTERMINATEDBY','```2. 使用Oracle Data Pump导入导出数据:Oracle Data Pump是Oracle 10g之后引入的一种高效的导入导出工具。
它提供了更快的数据加载和卸载速度,并且可以在导入导出过程中进行并行操作。
以下是一个简单的示例:```sql--导出数据EXPORT SCHEMA scott DIRECTORY=data_pump_dirDUMPFILE=scott.dmp--导入数据IMPORT SCHEMA scott DIRECTORY=data_pump_dirDUMPFILE=scott.dmp```3.使用PL/SQL脚本导入导出数据:我们可以使用PL/SQL脚本编写自定义的导入导出逻辑。
以下是一个简单的示例:```sql--导出数据DECLAREfile_handle UTL_FILE.FILE_TYPE;emp_rec emp%ROWTYPE;BEGINfile_handle := UTL_FILE.FOPEN('DATA_DIR', 'emp_data.txt', 'W');FOR emp_rec IN (SELECT * FROM emp) LOOPUTL_FILE.PUT_LINE(file_handle, emp_rec.empno , ',' ,emp_rec.ename , ',' , emp_rec.job);ENDLOOP;UTL_FILE.FCLOSE(file_handle);END;--导入数据DECLAREfile_handle UTL_FILE.FILE_TYPE;line_text VARCHAR2(200);BEGINfile_handle := UTL_FILE.FOPEN('DATA_DIR', 'emp_data.txt', 'R');LOOPUTL_FILE.GET_LINE(file_handle, line_text);--解析并插入数据ENDLOOP;UTL_FILE.FCLOSE(file_handle);END;```这是一些常用的PL/SQL导入导出Oracle数据库的方法。
oracle sqlplus用法
OracleSQL*Plus是一种交互式的命令行工具,用于执行SQL语句和PL/SQL代码,以及管理Oracle数据库。
以下是一些常用的Oracle SQL*Plus用法:
1. 连接到数据库:使用CONNECT命令连接到Oracle数据库。
例如,CONNECT username/password@database。
2. 执行SQL语句:使用SQL语句查询、更新、删除或插入数据。
例如,SELECT * FROM table_name。
3. 退出SQL*Plus:使用EXIT或QUIT命令退出SQL*Plus。
4. 保存SQL*Plus会话:使用SPOOL命令将会话输出保存到文件中。
例如,SPOOL filename.txt。
5. 设置SQL*Plus环境:使用SET命令设置SQL*Plus环境变量,例如设置显示行数或列数。
6. 保存SQL*Plus脚本:使用START命令从文件执行SQL*Plus 脚本。
7. 查看SQL*Plus版本:使用SELECT * FROM v$version命令查看SQL*Plus版本号。
8. 引用变量:使用DEFINE命令定义变量,使用&variable_name 引用变量。
9. 加载外部文件:使用@命令执行外部脚本文件。
10. 设置回滚点:使用SAVEPOINT和ROLLBACK命令设置回滚点和回滚数据。
以上是一些常用的Oracle SQL*Plus用法,掌握这些用法可以更有效地管理和操作Oracle数据库。
对于一些项目来说,不能使用plsqldev直接连上数据库,而只能通过telnet、ssh等方式登上终端,再在终端上运行sqlplus来查询。
有时查询出来的数据太多,一个屏幕装不下,或者需要对查出来的数据作进一步整理、统计,这时就需要把查询结果导出成一个文件。
使用sqlplus的spool功能也能做到,但比较复杂。
经过我几次总结,并结合网上的实例,整理出一个方便的方法,帖上来与大家分享一下。
1.新建一个expqry.sh的shell,写下如下语句:
#!/bin/bash
sqlplus -s user/pass@db << EOFa
set pagesize 0 linesize 2000 feedback off tab off colsep |
@somesql.sql
disconnect;
quit;
EOFa
配置expqry.sh,设置数据库的用户名user,密码pass,数据库db;
本例中将字段分隔符设为“|”,如果不喜欢,想用默认的TAB的话,可以将第三行改为
set pagesize 0 linesize 2000 feedback off tab off
2.新建一个sql文件somesql.sql,写上一些sql语句;
3.expqry.sh和somesql.sql放到同一目录下;
4.执行expqry.sh > outfile,就可将查询结果导出到outfile了。
可以对我的文档直接进行修改。
附件如下:。
之前用过spool导出oracle数据为文本,可惜一直也没有整理下,今天再次用到,网上找了相关文档,也算作个记录。
第一部分(实例,主要分两步),第二部分(参数小总结),第三部分(完全参数总结)第一部分第一步:这是我的导出数据的脚本call.sqlconn scott/tigerset echo offset term offset line 1000 pages 0set feedback offset heading offset trimspool onspool /temp/test/ldr_test.csvselect a.empno||',"'||a.ename||'",'||to_char(a.hiredate,'yyyy-mm-dd hh24:mi:ss')||','||a.sal from test a; spool offset trimspool offset heading onset feedback onset term onset echo onexit注释:call.sql脚本执行方法(1)sqlplus /nolog 先进入sqlplus命令模式(2)start call.sql 在sqlplus命令模式下执行第二步:导入数据的脚本add_test.ctlLOAD DATAINFILE ldr_test.csvTRUNCATE INTO TABLE testFIELDS TERMINATED BY"," OPTIONALLY ENCLOSED BY'"'(EMPNO,ENAME,HIREDATE date 'yyyy-mm-dd hh24:mi:ss',SAL)注释: 在第一步导出数据后,执行add_test.sql脚本命令为: sqlplus scott/tiger control=add_test.ctl至此用sqlplus导入/出数据完成了,如果有些参数不明白,请看一下第二三部分。
哦..忘了说test测试表的结构了,create table test as select empno,ename,hiredate,sal from emp;第二部分spool本身其实没有啥难的,就是set参数的个数太太多啦!!!下面就是我网上Copy的,当然有一些是自己加上去的SQL>set colsep' '; //-域输出分隔符SQL>set newp none //设置查询出来的数据分多少页显示,如果需要连续的数据,中间不要出现空行就把newp设置为none,这样输出的数据行都是连续的,中间没有空行之类的SQL>set echo off; //显示start启动的脚本中的每个sql命令,缺省为onSQL> set echo on //设置运行命令是是否显示语句SQL> set feedback on; //设置显示“已选择XX行”SQL>set feedback off; //回显本次sql命令处理的记录条数,缺省为on即去掉最后的"已经选择10000行"SQL>set heading off; //输出域标题,缺省为on 设置为off就去掉了select结果的字段名,只显示数据SQL>set headsep off //标题分隔符SQL>set pagesize 0; //输出每页行数,缺省为24,为了避免分页,可设定为0。
(可以简写为:set pages 0)SQL>set linesize 80; //输出一行字符个数,缺省为80。
(可以简写为:set line 80)SQL>set numwidth 12; //输出number类型域长度,缺省为10SQL>set termout/term off; //显示脚本中的命令的执行结果,缺省为onSQL>set trimout on; //去除标准输出每行的拖尾空格,缺省为offSQL>set trimspool on; //去除重定向(spool)输出每行的拖尾空格,缺省为offSQL>set serveroutput on; //设置允许显示输出类似dbms_outputSQL> set timing on; //设置显示“已用时间:XXXX”SQL> set autotrace on-; //设置允许对执行的sql进行分析SQL>set verify off //可以关闭和打开提示确认信息old 1和new 1的显示.第三部分这个是纯Copy的set命令全家福,呵呵,很专业,如果看不习惯的话可以全部改成小写使用set命令的语法如下: SET 系统变量值其中系统变量及其可选值如下:ARRAY[SIZE] {20(默认值)|n}AUTO[COMMIT] {OFF(默认值)|ON|IMM[EDIATE]}BLO[CKTERMINATOR] {.(默认值)|C}CMDS[EP] {;|C|OFF(默认值)|ON}COM[PATIBILITY] {V5|V6|V7|NATIVE(默认值)}CON[CAT] {.(默认值)|C|OFF|ON(默认值)}COPYC[OMMIT] {0(默认值)|n}CRT crtDEF[INE] {&|C|OFF|ON(默认值)}ECHO {OFF|ON}EMBEDDED {OFF(默认值)|ON}ESC[APE] {\(默认值)|C|OFF(默认值)|ON}FEED[BACK] {6(默认值)|n|OFF|ON}FLU[SH] {OFF|ON(默认值)}HEA[DING] {OFF|ON(默认值)}HEADS[EP] {|(默认值)|C|OFF|ON(默认值)}LIN[ESIZE] {80(默认值)|n}LONG {80(默认值)|n}LONGC[HUNKSIZE] {80(默认值)|n}MAXD[ATA] nNEWP[AGE] {1(默认值)|n}NULL textNUMF[ORMAT] 格式NUM[WIDTH] {10(默认值)|n}PAGES[IZE] {14(默认值)|n}PAU[SE] {OFF(默认值)|ON|text}RECSEP {WR[APPED](默认值)|EA[CH]|OFF}RECSEPCHAR { |C}SCAN {OFF|ON(默认值)}SERVEROUT[PUT] {OFF|ON} [SIZE n]SHOW[MODE] {OFF(默认值)|ON}SPA[CE] {1(默认值)|n}SQLC[ASE] {MIX[ED](默认值)|LO[WER]|UP[PER]}SQLCO[NTINUE] {>;(默认值)|文本}SQLN[UMBER] {OFF|ON(默认值)}SQLPER[FIX] {#(默认值)|C}SQLP[ROMPT] {SQL>;(默认值)|文本}SQLT[ERMINATOR] {;(默认值)|C|OFF|ON(默认值)}SUF[FIX] {SQL(默认值)|文本}TAB {OFF|ON(默认值)}TERM[OUT] {OFF|ON(默认值)}TI[ME] {OFF(默认值)|ON}TIMI[NG] {OFF(默认值)|ON}TRIM[OUT] {OFF|ON(默认值)}UND[ERLINE] {-(默认值)|C|OFF|ON(默认值)}VER[IFY] {OFF|ON(默认值)}WRA[P] {OFF|ON(默认值)}系统变量说明:ARRAY[SIZE] {20(默认值)|n} 置一批的行数,是SQL*PLUS一次从数据库获取的行数,有效值为1至5000. 大的值可提高查询和子查询的有效性,可获取许多行,但也需要更多的内存.当超过1000时,其效果不大.AUTO[COMMIT] {OFF(默认值)|ON|IMM[EDIATE]} 控制ORACLE对数据库的修改的提交. 置ON时,在ORACLE执行每个SQL命令或PL/SQL块后对数据库提交修改;置OFF时则制止自动提交,需要手工地提交修改,例如用SQL的COMMIT命令. IMMEDIATE功能同ON.BLO[CKTERMINATOR] {.(默认值)|C} 置非字母数字字符,用于结束PL/SQL块.要执行块时,必须发出RUN命令或/命令.CMDS[EP] {;|C|OFF(默认值)|ON} 置非字母数字字符,用于分隔在一行中输入的多个SQL/PLUS命令.ON或OFF控制在一行中是否能输入多个命令. ON时将自动地将命令分隔符设为分号(;).其中C表示所置字符.COM[PATIBILITY] {V5|V6|V7|NATIVE(默认值)} 指定当前所链接的ORACLE版本.如果当前ORACLE的版本为5,则置COMPATIBILITY为V5; 为版本6时置成V6; 为版本7时置成V7. 如果希望由数据库决定该设置,在置成NATIVE.CON[CAT] {.(默认值)|C|OFF|ON(默认值)}设置结束一替换变量引用的字符.在中止替换变量引用字符之后可跟所有字符,作为体会组成部分,否则SQL*PLUS将解释为替换变量名的一部分.当CONCAT开关为ON时,SQL*PLUS可重置CONCAT的值为点(.).COPYC[OMMIT] {0(默认值)|n} 控制COPY命令提交对数据库修改的批数.每次拷贝n批后,将提交到目标数据库.有效值为0到5000. 可用变量ARRAYSIZE设置一批的大小.如果置COPYCOMMIT为0,则仅在COPY操作结束时执行一次提交.CRT crt 改变SQL*PLUS RUNFORM命令使用的缺省CRT文件.如果置CRT不包含什么,则crt仅包含''''.如果在一个Form的系统调用期间,要使用NEW.CRT(缺省CRT是OLD.CRT),可按下列形式调用Form: SQL>;RUNFORM -C NEW form名或者SQL>;SET CRT NEWSQL>;RUNFORM form名第二中方法存储CRT选择,以致在下次运行RUNFORM命令(是在同一次SQL*PLUS交互中)时,不需要指定.DEF[INE] {&|C|OFF|ON(默认值)} 设置在替换变量时所使用的字符.ON或OFF控制SQL*PLUS是否扫描替换变量的命令及用他们的值代替. DEFINE的ON或OFF的设置控制SCAN变量的设置.ECHO {OFF|ON} 控制START命令是否列出命令文件中的每一命令.为ON时,列出命令;为OFF时,制止列清单.EMBEDDED {OFF(默认值)|ON} 控制每一报表在一页中开始的地方. 为OFF时,迫使每一报表是在新页的顶部开始;为ON时,运行一报表在一页的任何位置开始.ESC[APE] {\(默认值)|C|OFF(默认值)|ON} 定义作为Escape字符的字符.为OFF时,使Escape字符不起作用.为ON时,使Escape字符起作用.FEED[BACK] {6(默认值)|n|OFF|ON} 显示由查询返回的记录数.ON和OFF置显示为开或关.置FEEDBACK为ON时,等价于置n为1. 如果置FEEDBACK为0,等价于将它置成OFF.FLU[SH] {OFF|ON(默认值)} 控制输出送至用户的显示设备.为OFF时,运行操作系统做缓冲区输出;为ON时,不允许缓冲. 仅当非交互方式运行命令文件时使用OFF,这样可减少程序I/O总是,从而改进性能.HEA[DING] {OFF|ON(默认值)} 控制报表中列标题的打印.为ON时,在报表中打印列标题;为OFF时禁止打印列标题.HEADS[EP] {|(默认值)|C|OFF|ON(默认值)} 定义标题分隔字符.可在COLUMN命令中使用标题分隔符,将列标题分成多行.ON和OFF将标题分隔置成开或关.当标题分隔为关(OFF)时,SQL*PLUS打印标题分隔符像任何字符一样.LIN[ESIZE] {80(默认值)|n} 置SQL*PLUS在一行中显示的字符总数,它还控制在TTITLE和BTITLE中对准中心的文本和右对齐文本. 可定义LINESIZE为1至最大值,其最大值依赖于操作系统.LONG {80(默认值)|n} 为显示和拷贝LONG类型值的最大宽度的设置. 对于ORACLE7, n的最大值为2G 字节;对于版本6,最大值为32767.LONGC[HUNKSIZE] {80(默认值)|n} 为SQL*PLUS检索LONG类型值的增量大小.由于内存的限制,可按增量检索,该变量仅应用于ORACLE7.MAXD[ATA] n 置SQL*PLUS可处理的最大行宽字符数,其缺省值和最大值在不同操作系统中是可变的.NEWP[AGE] {1(默认值)|n} 置每一页的头和顶部标题之间要打印的空行数.如果为0, 在页之间送一换号符,并在许多终端上清屏.NULL text 设置表示空值(null)的文本,如果NULL没有文本,则显示空格(缺省时). 使用COLUMN命令中的NULL子句可控制NULL变量对该列的设置.NUMF[ORMAT] 格式设置显示数值的缺省格式,该格式是数值格式.NUM[WIDTH] {10(默认值)|n} 对显示数值设置缺省宽度.PAGES[IZE] {14(默认值)|n} 置从顶部标题至页结束之间的行数.在11英寸长的纸上打印报表,其值为54,上下各留一英寸(NEWPAGE值为6).PAU[SE] {OFF(默认值)|ON|text} 在显示报表时,控制终端滚动.在每一暂停时,必须按RETURN键.ON将引起SQL*PLUS在每一报表输出页开始时暂停.所指定的文本是每一次SQL*PLUS暂停时显示的文本.如果要键入多个词,必须用单引号将文本括起来.RECSEP {WR[APPED](默认值)|EA[CH]|OFF}RECSEPCHAR { |C} 指定显示或打印记录分行符的条件.一个记录分行符,是由RECSEPCHAR指定的字符组成的单行.空格为RECSEPCHAR的默认字符.RECSEP 告诉SQL*PLUS在哪儿做记录分隔.例如将RECSEP置成WRAPPED,在每一缠绕行之后,打印记录分行符.如果将RECSEP置成EACH,SQL*PLUS在每一行后打印一记录分行符.如果将RECSEP置成OFF, SQL*PLUS不打印分行符.来源:/mousever/article/details/7962202。