17优先队列-二叉堆-堆排序
- 格式:pptx
- 大小:247.86 KB
- 文档页数:39

堆的应用与实现优先队列堆排序等堆的应用与实现:优先队列、堆排序等堆是一种重要的数据结构,它可以应用于多种场景中,例如优先队列和排序算法。
在本文中,我们将探讨堆的应用以及如何实现优先队列和堆排序。
一、堆的概念与性质堆是一种特殊的完全二叉树,它可以分为最大堆和最小堆两种类型。
最大堆满足父节点的值大于等于子节点的值,而最小堆则相反,父节点的值小于等于子节点的值。
堆具有以下性质:1. 堆总是一棵完全二叉树,即除了最后一层,其他层都是完全填满的。
2. 在最大堆中,任意节点的值都大于等于其子节点的值;在最小堆中,则反之。
3. 堆的根节点是最大值(最大堆)或最小值(最小堆)。
4. 堆的左子节点和右子节点的值相对于父节点的值具有一定的顺序关系。
二、优先队列优先队列是一种特殊的队列,它的出队顺序依赖于元素的优先级而非它们被加入队列的顺序。
堆可以用来实现优先队列。
在堆中,每个元素都有一个优先级,优先级高的元素先出队。
优先队列可以应用于很多场景,例如任务调度、事件处理等。
下面是一个使用堆实现优先队列的伪代码:```class PriorityQueue:def __init__(self):self.heap = []def push(self, item):heapq.heappush(self.heap, item)def pop(self):return heapq.heappop(self.heap)```在上述代码中,我们使用Python中的heapq库来实现堆操作。
通过heappush和heappop函数,我们可以实现元素的入队和出队操作,同时保证堆的特性。
三、堆排序堆排序是一种高效的排序算法,它利用堆数据结构进行排序。
堆排序的基本思想是将待排序序列构建成一个最大堆(或最小堆),然后反复将堆顶元素与最后一个元素交换,并进行调整,直到整个序列有序。
下面是使用堆排序算法对一个数组进行排序的示例代码:```def heapify(arr, n, i):largest = ileft = 2 * i + 1right = 2 * i + 2if left < n and arr[i] < arr[left]:largest = leftif right < n and arr[largest] < arr[right]:largest = rightif largest != i:arr[i], arr[largest] = arr[largest], arr[i]heapify(arr, n, largest)def heap_sort(arr):n = len(arr)for i in range(n // 2 - 1, -1, -1):heapify(arr, n, i)for i in range(n - 1, 0, -1):arr[i], arr[0] = arr[0], arr[i]heapify(arr, i, 0)```在上述代码中,我们首先通过堆化操作将待排序序列构建为一个最大堆。

堆与优先队列1.堆与优先队列普通的队列是⼀种先进先出的数据结构,即元素插⼊在队尾,⽽元素删除在队头。
⽽在优先队列中,元素被赋予优先级,当插⼊元素时,同样是在队尾,但是会根据优先级进⾏位置调整,优先级越⾼,调整后的位置越靠近队头;同样的,删除元素也是根据优先级进⾏,优先级最⾼的元素(队头)最先被删除。
另外,优先队列也叫堆。
2.优先队列与⼆叉树⾸先,优先队列是⼆叉树的⼀种特例,是在⼆叉树的基础上,再定义⼀种性质:根节点的key值⽐左⼦树和右⼦树⼤(最⼤优先队列,也叫⼤顶堆)或⼩(最⼩优先队列,也叫⼩顶堆),通过在⼆叉树上维护这⼀性质,这样该⼆叉树就是优先队列。
2.1 ⼆叉树的性质在学习优先队列时,我们要先对⼆叉树有⼀定的认知。
2.1.1 ⼆叉树的定义⼆叉树(binary tree)是指树中节点的度不⼤于2的有序树,它是⼀种最简单且最重要的树。
⼆叉树的递归定义为:⼆叉树是⼀棵空树,或者是⼀棵由⼀个根节点和两棵互不相交的,分别称作根的左⼦树和右⼦树组成的⾮空树;左⼦树和右⼦树⼜同样都是⼆叉树。
2.1.2 ⼆叉树的基本形态⼆叉树是递归定义的,其结点有左右⼦树之分,逻辑上⼆叉树有五种基本形态: [3]1、空⼆叉树——如图(a);2、只有⼀个根结点的⼆叉树——如图(b);3、只有左⼦树——如图(c);4、只有右⼦树——如图(d);5、完全⼆叉树——如图(e)。
由上述我们可以得知,⼀颗节点数为3的⼆叉树,有五种形态:2.1.2 相关术语1、节点:⾄少包含⼀个key值的数据及若⼲指向⼦树分⽀的指针;2、节点的度:⼀个节点拥有的⼦节点的数⽬称为节点的度;3、叶⼦节点:度为0的节点;4、分⽀节点:度不为0的节点;5:数的度:数中所有节点的度的最⼤值;6、节点的层次:从根节点开始诉求你,假设根节点为第⼀层,根节点的⼦节点为第⼆层,⼀次类推,如果某⼀个节点位于第L层,则其⼦节点位于第L + 1层;7、树的深度:也称为树的⾼度,树中所有节点的层次最⼤值称为树的深度;2.1.3 ⼆叉树的性质性质1:⼆叉树的第i层上⾄多有22-1(i >= 1)个节点;性质2:深度为h的⼆叉树中⾄多有2h - 1个节点;性质3:节点数为n的⼆叉树中,有n-1条边。

![[Java]-优先队列,二叉堆,堆排序](https://uimg.taocdn.com/57568d0eb6360b4c2e3f5727a5e9856a561226e5.webp)
[Java]-优先队列,⼆叉堆,堆排序泛型优先队列API返回值⽅法名作⽤构造函数MaxPQ()创建⼀个优先队列构造函数MaxPQ(int N)创建⼀个⼤⼩为N的优先队列构造函数MaxPQ(Key[] a)利⽤数组a创建⼀个优先队列void insert(Key v)向队列中插⼊元素vKey Max()返回最⼤元素Key delMax()删除最⼤元素并返回boolean isEmpty()判断优先队列是否为空int size()返回优先队列的⼤⼩优先队列最重要的操作就是删除最⼤元素和插⼊元素⼀个优先队列的⽤例package cn.ywrby.test;import edu.princeton.cs.algs4.*;//⼀个优先队列的⽤例//输⼊多组数据,打印出其中最⼤的M⾏数据//tinyBatch.txt测试⽤例public class TopM {public static void main(String[] args){int M=5;MinPQ<Transaction> pq=new MinPQ<Transaction>(M+1);while(StdIn.hasNextLine()){pq.insert(new Transaction(StdIn.readLine())); //将输⼊插⼊优先队列if(pq.size()>M){ //当队列长度⼤于输出长度,删除最⼩值pq.delMin();}}//将队列中的元素放⼊栈,然后输出,实现倒序Stack<Transaction> stack=new Stack<Transaction>();while(!pq.isEmpty()){stack.push(pq.delMin());}for(Transaction t:stack){StdOut.println(t);}}}⼆叉堆在⼆叉堆的数组中,每个元素都保证⼤于等于另外两个特定位置的元素,以此类推,便得到这种结构当⼀棵⼆叉树的每个节点都⼤于等于它的两个⼦节点时,它被称为堆有序易知,根节点是对有序的⼆叉树的最⼤节点⼆叉堆是⼀组能够⽤对有序的完全⼆叉树排序的元素,并在数组中按照层级储存(不使⽤数组的第⼀个位置)在⼀个堆中,位置k的结点的⽗结点的位置为(k2)向下取整(2k)向下取整,⽽它的⼦节点的位置分别为2k,2k+1。


二叉堆构建及应用方法全面讲解二叉堆是一种特殊的二叉树结构,具有以下两个性质:1. 完全二叉树:除了最后一层,其他层的节点都是满的,并且最后一层的节点从左到右依次填满。
2. 堆序性质:对于最大堆,父节点的值大于等于其子节点的值;对于最小堆,父节点的值小于等于其子节点的值。
本文将全面讲解二叉堆的构建和应用方法,并通过实例介绍其具体应用场景。
一、二叉堆的构建方法1. 数组表示法:将二叉堆存储在一个数组中,通过以下方式实现对应关系:- 对于节点i,它的左子节点为2i+1,右子节点为2i+2。
- 对于节点i,它的父节点为(i-1)/2。
2. 初始化二叉堆:通过给定的数组构建一个二叉堆,可以使用下面的方法:- 从最后一个非叶子节点开始,依次向上调整节点位置,使得整个树满足堆序性质。
- 调整节点位置的方法是,将节点与其子节点进行比较,并交换位置。
二、二叉堆的应用方法1. 堆排序:堆排序是利用二叉堆进行排序的一种排序算法。
具体步骤如下:- 构建一个最大堆。
- 将堆顶元素与最后一个元素交换,并将最后一个元素从堆中排除。
- 对剩余元素重新进行堆化操作。
- 重复上述步骤,直到堆中只剩下一个元素,即完成排序。
2. 优先队列:优先队列是一种特殊的队列,元素按照一定的优先级顺序进行排列。
二叉堆可以用来实现优先队列,具体操作如下: - 插入操作:将新元素插入到二叉堆的末尾,然后通过上浮操作将其调整到合适的位置。
- 删除操作:将堆顶元素与最后一个元素交换,然后通过下沉操作将堆顶元素调整到合适的位置。
三、二叉堆的应用场景1. Top K 问题:通过维护一个大小为 K 的最小堆,在遍历数据时保持堆中元素是当前最大的 K 个元素,可以解决 Top K 问题。
2. 堆中的中位数:将数据分成两部分,一部分较小的元素存放在最大堆中,一部分较大的元素存放在最小堆中,可以快速求解中位数。
3. Dijkstra 算法:在求解单源最短路径问题时,使用最小堆来维护待处理的节点集合,每次选择最小路径的节点进行拓展。

二叉堆实现方法及应用场景详解二叉堆是一种经典的数据结构,常用于解决一些问题,比如优先级队列的实现。
本文将详细介绍二叉堆的实现方法,并探讨二叉堆在实际应用中的场景。
1. 什么是二叉堆?二叉堆是一种完全二叉树,并且满足堆性质:任意节点的值都大于等于(或小于等于)其子节点的值。
我们通常将值较大的堆称为“大顶堆”,将值较小的堆称为“小顶堆”。
2. 二叉堆的实现方法二叉堆可以使用数组来实现,不同的节点在数组中的位置可以通过下标进行计算。
假设一个节点的索引为i,其左子节点的索引为2i+1,右子节点的索引为2i+2,父节点的索引为(i-1)/2。
实现一个二叉堆需要考虑两个重要操作:插入新节点和删除堆中的最值(即根节点)。
- 插入节点:将新节点添加到数组末尾,然后通过上浮操作,将新节点依次与父节点进行比较和交换,直到满足堆的性质。
- 删除堆中的最值:将根节点与数组末尾的节点进行交换,然后通过下沉操作,将根节点依次与子节点进行比较和交换,直到满足堆的性质。
通过以上操作,我们可以实现一个基本的二叉堆。
3. 二叉堆的应用场景二叉堆在实际应用中有着广泛的应用场景,下面介绍几个常见的应用场景。
- 优先级队列:优先级队列是一种特殊的队列,每个元素都有一个优先级。
二叉堆可以实现优先级队列的基本功能,快速插入和删除最值。
- 堆排序:堆排序是一种基于二叉堆的排序算法,通过不断删除堆中的最值,并将其放入结果中,完成排序操作。
堆排序具有稳定的时间复杂度,适用于大规模数据集。
- 图的最短路径算法:Dijkstra算法就是基于优先级队列来实现的,通过使用二叉堆来维护待处理的节点集合,可以高效地找到图中两个节点间的最短路径。
- 数据流中的第K大元素:维护一个大小为K的小顶堆,可以在数据流中快速找到第K大的元素。
除了以上应用场景外,二叉堆还可以用于解决一些实际问题,比如:- 任务调度问题:优先级高的任务会被优先执行,可以使用二叉堆来维护任务的优先级队列,从而实现任务调度的功能。

算法面试英文词汇以下是一些算法面试中可能会遇到的英文词汇:1. 算法分析:Algorithm Analysis2. 时间复杂度:Time Complexity3. 空间复杂度:Space Complexity4. 递归:Recursion5. 动态规划:Dynamic Programming6. 分治法:Divide and Conquer7. 贪心算法:Greedy Algorithm8. 回溯法:Backtracking9. 插入排序:Insertion Sort10. 快速排序:Quick Sort11. 归并排序:Merge Sort12. 堆排序:Heap Sort13. 二分查找:Binary Search14. 深度优先搜索:Depth-First Search (DFS)15. 广度优先搜索:Breadth-First Search (BFS)16. 优先队列:Priority Queue17. 并查集:Disjoint Set18. 线段树:Segment Tree19. 平衡二叉树:Balanced Binary Tree20. 红黑树:Red-Black Tree21. AVL树:AVL Tree22. 图论:Graph Theory23. 最小生成树:Minimum Spanning Tree (MST)24. 最短路径:Shortest Path25. Dijkstra算法:Dijkstra's Algorithm26. Bellman-Ford算法:Bellman-Ford Algorithm27. Floyd-Warshall算法:Floyd-Warshall Algorithm28. 拓扑排序:Topological Sort29. 网络流:Flow in Networks30. 最少生成树:Minimum Cost Spanning Tree (MCTS)31. 二分图匹配:Bipartite Matching32. 并查集操作:Union, Find, Union-by-Rank, Path Compression33. 二叉堆操作:Insert, Delete, Decrease Key, Increase Key, Merge34. 数据结构操作:Insert, Delete, Search, Get Size, Is Empty, Clear35. 链表操作:Create, Delete, Insert Before, Insert After, Print, Find, Merge36. 数组操作:Sort, Reverse, Find Max/Min, Find Index of Max/Min, Rotate, Transpose37. 树操作:Create Root, Insert Node, Delete Node, Find Node, Find Parent of Node, Print Tree38. 图操作:Create Graph, Add Edge, Delete Edge, Find Nodes Connected by Edge, BFS/DFS from Source Node39. 图论问题常见术语:Vertex Cover, Independent Set, Connected Component, Shortest Path, Bipartite Checking, Max Flow/Min Cut 40. 其他常见术语:Big O notation, Amortized analysis, Randomized algorithm, NP-hard problem41. 其他常用算法术语:Divide and Conquer approach, Greedy approach, Dynamic Programming approach42. 动态规划的边界情况处理:Base case/Recursion case。

二叉堆和优先队列高效实现堆排序和Dijkstra算法堆排序和Dijkstra算法是计算机科学中常见且高效的算法。
它们的实现中常用到二叉堆和优先队列的数据结构。
本文将介绍二叉堆和优先队列的概念,以及它们在堆排序和Dijkstra算法中的应用。
一、二叉堆二叉堆是一种特殊的完全二叉树,满足以下两个性质:1. 结构性质:除最后一层外,每一层都是满的,最后一层从左到右填入节点。
2. 堆序性质:对于任意节点i,其父节点值小于等于其子节点的值。
二叉堆有两种类型:大顶堆和小顶堆。
大顶堆中,父节点的值大于等于其子节点;小顶堆中,父节点的值小于等于其子节点。
二叉堆的根节点即堆中的最值。
二、优先队列优先队列是一种可以快速访问和删除最值元素的数据结构。
它支持两个主要操作:1. 插入操作:将元素按照一定的优先级插入队列中。
2. 弹出操作:弹出队列中的最值元素。
优先队列可以用二叉堆实现,其中小顶堆用于实现最小优先队列,大顶堆用于实现最大优先队列。
通过保持堆序性质,我们可以在O(logn)的时间复杂度内完成插入和弹出的操作。
三、堆排序堆排序是一种高效的排序算法,基于二叉堆数据结构。
其主要步骤如下:1. 构建最大堆:将待排序序列构建成一个最大堆。
2. 交换堆顶元素和最后一个元素:将最大堆的堆顶元素与最后一个元素交换,此时最大值被固定在了最后。
3. 调整堆:调整剩余元素构建一个新的最大堆。
4. 重复步骤2和步骤3,直到剩余元素只有一个。
堆排序的时间复杂度为O(nlogn),且具有原地排序的优点,但是不稳定。
四、Dijkstra算法Dijkstra算法是一种解决单源最短路径问题的贪心算法。
其核心思想是利用优先队列选择当前最短路径的顶点来遍历附近的节点,并更新到达这些节点的最短距离。
其主要步骤如下:1. 创建一个距离数组dist,存储源点到每个顶点的最短距离。
初始时,源点到自身的距离为0,其他顶点的距离为无穷大。
2. 将源点插入到优先队列中。

二叉堆了解二叉堆的性质和操作二叉堆:了解二叉堆的性质和操作二叉堆是一种特殊的二叉树数据结构,它具有以下性质:1. 二叉堆是一个完全二叉树,即除了最后一层之外的所有层都是满的,且最后一层的节点都尽量靠左排列。
2. 二叉堆可以分为最大堆和最小堆两种类型。
最大堆是指父节点的值大于或等于其子节点的值,最小堆则相反。
3. 对于最大堆,堆顶元素是整个堆中的最大值;对于最小堆,则是最小值。
二叉堆的操作主要包括插入和删除两个步骤,下面将逐一介绍。
1. 插入操作:当我们向二叉堆中插入一个新的元素时,会依次执行以下步骤:- 将新元素放置在堆的最后一个位置。
- 通过与其父节点进行比较,并根据最大堆或最小堆的性质进行交换,直到满足堆的性质为止。
2. 删除操作:二叉堆的删除操作主要有两种情况,针对最大堆进行说明:- 删除堆顶元素:- 将堆顶元素与最后一个元素交换。
- 从根节点开始,将新的堆顶元素依次与其左右子节点进行比较,并与较大的子节点交换,直到满足堆的性质为止。
- 删除任意元素:- 首先,需要找到要删除的元素所在的位置。
- 然后,将该元素与最后一个元素交换。
- 对交换后的新元素进行堆化操作,即不断将其与左右子节点进行比较并交换,直到满足堆的性质为止。
二叉堆的应用:1. 优先队列:二叉堆可以实现高效的优先队列,即从队列中取出最大(或最小)值的操作时间复杂度为O(1)。
2. 堆排序:通过建立最大堆或最小堆,可以实现对数组的排序。
虽然二叉堆的操作看起来比较简单,但是它对于算法设计和实现非常重要。
通过合理的应用,可以大大提高算法的效率。
总结:二叉堆是一种重要的数据结构,它具有特殊的性质和操作。
了解二叉堆的性质和操作,对于算法设计和实现至关重要。
掌握二叉堆的原理,可以帮助我们更好地理解和使用它在各种应用中的优势。
无论是在优先队列还是堆排序中,二叉堆都发挥着重要的作用,是算法和数据结构领域中不可或缺的一部分。
了解并掌握二叉堆的性质和操作,将使我们的算法设计更加高效和优雅。
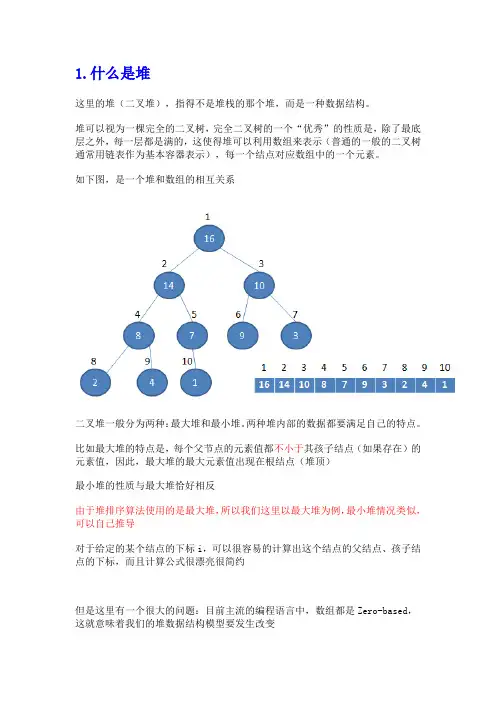
1.什么是堆这里的堆(二叉堆),指得不是堆栈的那个堆,而是一种数据结构。
堆可以视为一棵完全的二叉树,完全二叉树的一个“优秀”的性质是,除了最底层之外,每一层都是满的,这使得堆可以利用数组来表示(普通的一般的二叉树通常用链表作为基本容器表示),每一个结点对应数组中的一个元素。
如下图,是一个堆和数组的相互关系二叉堆一般分为两种:最大堆和最小堆。
两种堆内部的数据都要满足自己的特点。
比如最大堆的特点是,每个父节点的元素值都不小于其孩子结点(如果存在)的元素值,因此,最大堆的最大元素值出现在根结点(堆顶)最小堆的性质与最大堆恰好相反由于堆排序算法使用的是最大堆,所以我们这里以最大堆为例,最小堆情况类似,可以自己推导对于给定的某个结点的下标i,可以很容易的计算出这个结点的父结点、孩子结点的下标,而且计算公式很漂亮很简约但是这里有一个很大的问题:目前主流的编程语言中,数组都是Zero-based,这就意味着我们的堆数据结构模型要发生改变相应的,几个计算公式也要作出相应调整新公式很难看,很杯具这几个公式在C/C++中可以用宏或者内联函数实现view sourceprint?1 #define LEFT(x) ((x << 1) + 1)2 #define RIGHT(x) ((x + 1) << 1)3 #define PARENT(x) (((x + 1) >> 1) - 1)2.堆排序堆排序是一种利用堆这种数据结构,进行原地排序的排序算法,其时间复杂度是O(nlogn),而且只和数据规模有关堆排序算法是一种很漂亮的算法,这里需要用到三个函数:MaxHeapify、BuildMaxHeap和HeapSort2.1MaxHeapifyMaxHeapify的作用是保持最大堆的性质,是整个排序算法的核心。
MaxHeapify函数接受三个参数,数组,检查的起始下标和堆大小。
函数的代码如下view sourceprint?01 /*02 输入: Ary(int[]) - [in,out]排序数组03 nIndex(int) - 起始下标04 nHeapSize(int) - 堆大小(zero-based)05 输出: -06 功能: 从nIndex开始检查并保持最大堆性质07 */08 void MaxHeapify(int Ary[], int nIndex, int nHeapSize)09 {10 int nL = LEFT(nIndex);11 int nR = RIGHT(nIndex);12 int nLargest;1314 if (nL <= nHeapSize && Ary[nIndex] < Ary[nL])15 {16 nLargest = nL;17 }18 else19 {20 nLargest = nIndex;21 }2223 if (nR <= nHeapSize && Ary[nLargest] < Ary[nR])24 {25 nLargest = nR;26 }2728 if (nLargest != nIndex)29 {30 // 调整后可能仍然违反堆性质31 Swap(Ary[nLargest], Ary[nIndex]);32 MaxHeapify(Ary, nLargest, nHeapSize);33 }34 }由于一次调整后,堆仍然违反堆性质,所以需要递归的测试,使得整个堆都满足堆性质MaxHeapify(A,1,9)作用过程如图所示对于有n个元素的堆来说,MaxHeapify的运行时间最坏情况是O(logn)(可以通过主定理的得到)。
堆与优先队列了解堆的性质和优先队列的应用堆与优先队列:了解堆的性质和优先队列的应用在计算机科学中,堆(Heap)是一种常见的数据结构,用于解决许多实际问题,特别是在优先级队列的实现中。
本文将介绍堆的性质以及优先队列在实际问题中的应用。
一、堆的性质堆是一种特殊的完全二叉树,它具有以下性质:1. 完全二叉树:堆是一个完全二叉树,除了最后一层外,其它层的节点数都达到了最大值,最后一层的节点从左至右排列。
2. 堆序性:对于大顶堆(MaxHeap)来说,父节点的值大于或等于其子节点的值;对于小顶堆(MinHeap)来说,父节点的值小于或等于其子节点的值。
堆可以通过数组或二叉树来表示,其中数组表示是最常用的方法。
在数组表示中,父节点与子节点之间的关系可以通过索引的方式来表示,这种方式使得堆的操作更加高效。
二、优先队列优先队列是一种特殊的队列,其中每个元素都有一个优先级。
与普通队列不同的是,在优先队列中,具有较高优先级的元素优先出队列。
优先队列可以使用堆来实现,具体来说,可以使用小顶堆或大顶堆来构建优先队列。
在使用堆实现优先队列时,我们根据元素的优先级将其插入到堆中,并且可以随时删除最高(最低)优先级的元素。
优先队列的应用非常广泛,比如:1. 任务调度:在操作系统中,可以使用优先队列来调度不同优先级的任务,优先级高的任务将被优先处理。
2. 网络路由:在路由器中,优先队列可以用于选择最佳路径,从而提高网络的传输效率。
3. 模拟系统:在模拟系统中,优先队列可以用于按照优先级处理事件,使得模拟结果更接近真实情况。
4. 数据压缩:在哈夫曼编码等数据压缩算法中,优先队列可以用于选择出现频率最高的字符。
总之,优先队列的应用涉及各个领域,其高效的实现依赖于堆这一数据结构。
结论通过对堆的性质和优先队列的应用的介绍,我们可以充分了解到堆在计算机科学中的重要性。
堆的性质使得我们可以高效地实现优先队列,从而解决许多实际问题。
希望本文对读者进一步了解堆和优先队列有所帮助,并可以在实际应用中灵活运用。
堆与优先队列的原理与应用场景解析堆(Heap)是一种特殊的数据结构,它被广泛应用于优先队列(Priority Queue)的实现中。
堆可以分为最大堆(Max Heap)和最小堆(Min Heap),它们在插入和删除元素时具有高效的性能,因此在许多需要动态维护最值的场景中得到了广泛的应用。
一、堆的原理堆是一种完全二叉树(Complete Binary Tree),其中每个节点的值都大于其子节点(对于最大堆)或小于其子节点(对于最小堆)。
这个特性可以通过两种方式实现:大根堆和小根堆。
大根堆满足以下性质:1. 任意节点的值都大于等于其子节点的值。
2. 根节点的值是整个堆中的最大值。
小根堆满足以下性质:1. 任意节点的值都小于等于其子节点的值。
2. 根节点的值是整个堆中的最小值。
堆可以通过数组来实现,其中数组的下标表示堆中的位置关系。
对于节点 i,它的左子节点在位置 2i+1,右子节点在位置 2i+2,父节点在位置 (i-1)/2。
二、优先队列的原理优先队列是一种特殊的队列,其中元素按照一定的优先级进行排序,具有较高优先级的元素先被取出。
堆作为优先队列的底层数据结构,为优先队列提供了高效的插入和删除操作。
在优先队列中,插入操作将新元素插入到合适的位置以保持有序性,而删除操作则总是从堆的根节点删除最大(最小)值,并保持堆的性质。
三、堆与优先队列的应用场景1. 任务调度:在操作系统中,不同的任务可能具有不同的优先级,使用优先队列可以按照优先级调度任务的执行。
2. 模拟系统:在模拟系统中,事件的发生具有不同的优先级,优先队列可以按照事件的优先级进行处理。
3. 图算法:在最短路径算法(如Dijkstra算法)中,需要动态地选择具有最小权值的边进行处理,优先队列可以高效地选择最小权值的边。
4. 操作系统内存管理:在操作系统的内存管理中,需要根据页面的访问情况来进行页面置换,使用优先队列可以根据页面的访问频率进行页面置换操作。
堆排序的几种方法堆排序是一种高效的排序算法,它可以将一个无序的数组或者列表按照升序或降序排列。
堆排序的实现有多种方法,本文将介绍其中的几种常见方法。
一、使用完全二叉树实现堆排序1. 首先构建一个完全二叉树,可以使用数组或者链表来表示。
2. 接下来,需要将该二叉树调整为最大堆或最小堆,即每个节点的值都大于或小于其子节点的值。
3. 然后,将根节点与最后一个节点交换位置,并将最后一个节点从堆中移除。
4. 重复上述步骤,直到堆中只剩下一个节点为止。
5. 最后,将得到的有序节点逆序排列,即得到了排序后的数组或列表。
二、使用优先队列实现堆排序1. 首先,将待排序的元素依次插入优先队列中。
2. 然后,从优先队列中依次取出元素,即可得到有序的结果。
三、使用递归实现堆排序1. 首先,将待排序的数组或列表转化为一个堆。
2. 然后,将堆中的根节点与最后一个节点交换位置,并保持堆的性质。
3. 接着,对堆的根节点进行递归操作,直到堆为空。
4. 最后,将得到的有序节点逆序排列,即得到了排序后的数组或列表。
四、使用迭代实现堆排序1. 首先,将待排序的数组或列表转化为一个堆。
2. 然后,将堆中的根节点与最后一个节点交换位置,并保持堆的性质。
3. 接着,对堆的根节点进行迭代操作,直到堆为空。
4. 最后,将得到的有序节点逆序排列,即得到了排序后的数组或列表。
堆排序的时间复杂度为O(nlogn),其中n为待排序元素的个数。
堆排序是一种稳定的排序算法,适用于大数据量的排序任务。
它的主要优点是实现简单、效率高,但缺点是需要额外的空间来存储堆。
堆排序是一种高效的排序算法,可以通过不同的实现方法来达到相同的排序效果。
无论是使用完全二叉树、优先队列、递归还是迭代,都可以实现堆排序的功能。
在实际应用中,可以根据具体情况选择合适的方法来进行排序,以达到最佳的排序效果。
优先队列的实现堆排序和哈夫曼编码优先队列是一种常见的数据结构,它维护了一组元素,并且每个元素都有一个与之关联的优先级。
优先队列的特点是每次取出优先级最高的元素,而不是按照插入的顺序进行操作。
这种数据结构在很多实际应用中都有广泛的运用,例如任务调度、事件管理等。
本文将介绍优先队列的两种实现方法:堆排序和哈夫曼编码。
一、堆排序堆排序是一种基于优先队列的排序算法,它的核心思想是利用堆这种数据结构来实现优先队列。
堆是一种完全二叉树,可以分为最大堆和最小堆两种形式。
最大堆的特点是父节点的值大于等于子节点的值,最小堆则相反。
在堆排序中,首先将待排序的元素构建成一个最大堆。
构建最大堆的过程可以通过不断调整父节点和子节点的位置来实现,确保每个父节点的值大于等于子节点。
接下来,将堆顶元素(即最大值)和堆的最后一个元素交换,然后将剩余元素重新构建成最大堆。
重复这个步骤,直到所有元素都取出来并按照递增或递减的顺序排列。
堆排序是一种高效的排序算法,它的时间复杂度为O(nlogn),其中n表示元素的个数。
由于堆的构建和调整操作都是基于完全二叉树的特性,所以堆排序的性能非常稳定,对于大规模数据的排序也具有较好的性能。
二、哈夫曼编码哈夫曼编码是一种用于数据压缩的编码方法,它通过根据字符出现的频率构建一棵二叉树,实现了对出现频率较高的字符使用较短的编码,而对出现频率较低的字符使用较长的编码,从而实现了对数据的高效压缩。
在哈夫曼编码中,首先统计字符出现的频率,并将每个字符作为一个节点构建成一个森林。
然后,从森林中选择两个频率最低的节点合并,构建一个新的二叉树,并将该节点的频率设置为两个子节点的频率之和。
接着,将新构建的二叉树重新放回森林中,重复这个步骤,直到森林中只剩下一个二叉树,即哈夫曼树。
根据哈夫曼树的特性,对于左子树走向的路径编码为0,右子树走向的路径编码为1。
通过遍历哈夫曼树,可以得到每个字符对应的编码。
由于频率较高的字符在哈夫曼树中离根节点较近,所以它们的编码较短,从而实现了对数据的高效压缩。
C语言中的堆与优先队列堆和优先队列是C语言中常用的数据结构,它们在很多算法和程序中发挥着重要的作用。
本文将介绍C语言中的堆和优先队列,包括其定义、操作和应用。
一、堆堆是一种特殊的二叉树结构,常用于实现优先级队列。
在C语言中,我们通常使用数组来表示堆。
堆可以分为最大堆和最小堆两种类型,根据具体的需求选择使用。
1. 定义最大堆:父节点的值大于等于其子节点的值。
最小堆:父节点的值小于等于其子节点的值。
2. 操作堆的常见操作包括:a. 插入元素:将元素插入到堆的最后一个位置,然后进行堆化操作,确保满足堆的性质。
b. 删除堆顶元素:将堆顶元素与最后一个元素交换,然后删除最后一个元素,再进行堆化操作,确保满足堆的性质。
c. 堆化操作:将一个无序的数组调整为一个堆。
可以通过从最后一个非叶子节点开始,依次向前进行比较和交换操作,直到根节点。
堆在C语言中常用于实现优先级队列、排序算法等。
优先级队列:通过堆来实现,可以方便地找到具有最高优先级的元素。
堆排序:使用堆来实现的一种排序算法,具有稳定性和不稳定性两种实现方式。
二、优先队列优先队列是一种特殊的队列数据结构,其中的元素按照优先级进行排序。
C语言中可以使用堆来实现优先队列。
1. 定义优先队列中的元素按照优先级排序,越高优先级的元素越先被处理。
2. 操作优先队列的主要操作包括:a. 插入元素:将元素按照优先级插入到队列中的适当位置。
b. 删除最高优先级元素:删除队列中优先级最高的元素,并返回该元素。
3. 应用优先队列在C语言中常用于任务调度、模拟系统等场景,需要按照特定的优先级进行处理。
堆和优先队列是C语言中常用的数据结构,通过堆可以实现优先队列功能。
堆具有最大堆和最小堆两种类型,可以用于实现排序算法和优先级队列。
优先队列是一种特殊的队列,按照优先级对元素进行排序,常用于任务调度等场景。
通过学习和掌握堆和优先队列的概念、操作和应用,我们能够更加灵活地处理不同场景下的数据和算法问题,提高程序的效率和优化性能。
最详细版图解优先队列(堆)1.队列是⼀种F I F O(F i r s t-I n-F i r s t-O ut)先进先出的数据结构,对应于⽣活中的排队的场景,排在前⾯的⼈总是先通过,依次进⾏。
2.优先队列是特殊的队列,从“优先”⼀词,可看出有“插队现象”。
⽐如在⽕车站排队进站时,就会有些⽐较急的⼈来插队,他们就在前⾯先通过验票。
优先队列⾄少含有两种操作的数据结构:i ns e r t(插⼊),即将元素插⼊到优先队列中(⼊队);以及d e l e t e M i n(删除最⼩者),它的作⽤是找出、删除优先队列中的最⼩的元素(出队)。
优先队列优先队列的实现常选⽤⼆叉堆,在数据结构中,优先队列⼀般也是指堆。
堆的两个性质:1.结构性:堆是⼀颗除底层外被完全填满的⼆叉树,底层的节点从左到右填⼊,这样的树叫做完全⼆叉树。
2.堆序性:由于我们想很快找出最⼩元,则最⼩元应该在根上,任意节点都⼩于它的后裔,这就是⼩顶堆(M i n-H e a p);如果是查找最⼤元,则最⼤元应该在根上,任意节点都要⼤于它的后裔,这就是⼤顶堆(M a x-he a p)。
结构性:完成⼆叉树通过观察发现,完全⼆叉树可以直接使⽤⼀个数组表⽰⽽不需要使⽤其他数据结构。
所以我们只需要传⼊⼀个s i z e就可以构建优先队列的结构(元素之间使⽤c om p a r e T o⽅法进⾏⽐较)。
完全⼆叉树的数组实现对于数组中的任意位置i的元素,其左⼉⼦在位置2i上,则右⼉⼦在2i+1上,⽗节点在在i/2(向下取整)上。
通常从数组下标1开始存储,这样的好处在于很⽅便找到左右、及⽗节点。
如果从0开始,左⼉⼦在2i+1,右⼉⼦在2i+2,⽗节点在(i-1)/2(向下取整)。
堆序性:我们这建⽴最⼩堆,即对于每⼀个元素X,X的⽗亲中的关键字⼩于(或等于)X中的关键字,根节点除外(它没有⽗节点)。
堆如图所⽰,只有左边是堆,右边红⾊节点违反堆序性。
根据堆序性,只需要常O(1)找到最⼩元。