第五章 假设检验
- 格式:doc
- 大小:54.00 KB
- 文档页数:4







第五章假设检验与回归分析本章主要介绍了假设检验和回归分析两种统计方法。
一、假设检验假设检验是通过收集样本数据来对总体参数的假设进行推断的一种统计方法。
假设检验的步骤如下:1.建立原假设和备择假设:原假设是需要进行检验的参数的假设值,备择假设是对原假设的一种否定或补充。
通常将备择假设设置为我们要验证的假设。
2.收集样本数据:根据样本数据进行统计分析,并计算出检验统计量。
3.确定显著性水平:显著性水平是拒绝原假设的最大错误概率,通常取0.05或0.014.计算拒绝域的临界值:根据显著性水平和自由度,在统计表中查找检验统计量的临界值。
5.比较检验统计量和临界值:如果检验统计量落在拒绝域内,则拒绝原假设,否则接受原假设。
二、回归分析回归分析是一种用于研究两个或多个变量之间关系的统计方法。
它可以用来建立一个变量对另一个变量的预测模型。
回归分析的步骤如下:1.收集数据:根据需要收集自变量和因变量的数据。
2.建立模型:选择适当的回归模型,将自变量和因变量进行数学表达。
3.估计参数:使用最小二乘法等方法,对模型参数进行估计。
4.检验模型:通过检验模型的显著性水平,确定模型是否合理。
5.利用模型:使用估计的模型来进行预测和分析。
回归分析可以分为简单线性回归和多元线性回归两种。
简单线性回归是指只有一个自变量和一个因变量之间的关系,多元线性回归是指有多个自变量和一个因变量之间的关系。
回归分析的应用非常广泛,可以用于市场营销、财务管理、经济预测等领域。
通过回归分析,可以找到影响因变量的主要因素,并对未来的变化进行预测。
总之,假设检验和回归分析是统计学中两种重要的方法。
假设检验用于对总体参数的假设进行验证,回归分析用于研究变量之间的关系。
这两种方法在实际应用中具有广泛的价值。



第五章假设检验本章介绍假设检验的基本概念以及参数检验与非参数检验的主要方法。
通过学习,要求:1.掌握统计检验的基本概念,理解该检验犯两类错误的可能;2.熟练掌握总体均值与总体成数指标的各种检验方法;包括:z 检验、t 检验和p-值检验;4.掌握基本的非参数检验方法,包括:符号检验、秩和检验与游程检验;5.能利用Excel 进行假设检验。
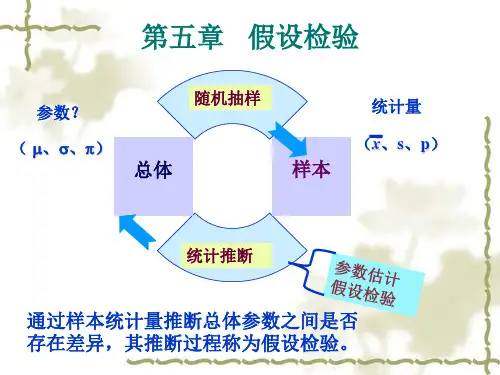
第一节假设检验概述一、假设检验的基本概念假设检验是统计推断的另一种方式,它与区间估计的差别主要在于:区间估计是用给定的大概率推断出总体参数的范围,而假设检验是以小概率为标准,对总体的状况所做出的假设进行判断。
假设检验与区间估计结合起来,构成完整的统计推断内容。
假设检验分为两类:一类是参数假设检验,另一类是非参数假设检验。
本章分别讨论这两类检验方法。
进行假设检验,首先要对总体的分布函数形式或分布的某些参数做出假设,然后再根据样本数据和“小概率原理”,对假设的正确性做出判断。
这种思维方法与数学里的“反证法”很相似,“反证法”先将要证明的结论假设为不正确的,作为进一步推论的条件之一使用,最后推出矛盾的结果,以此否定事先所作的假设。
反证法所认为矛盾的结论,也就是不可能发生的事件,这种事件发生的概率为零,该事件是不能接受的现实。
其实,我们在日常生活中,不仅不肯接受概率为0的事件,而且对小概率事件,也持否定态度。
比如,虽然偶尔也有媒体报导陨石降落的消息,但人们不必担心天空降落的陨石会砸伤自己。
所谓小概率原理,即指概率很小的事件在一次试验中实际上不可能出现。
这种事件称为“实际不可能事件”。
小概率的标准是多大?这并没有绝对的标准,一般我们以一个所谓显著性水平α(0<α<1)作为小概率的界限,α的取值与实际问题的性质有关。
所以,统计检验又称显著性检验。
下面通过一个具体例子说明假设检验是怎样进行的。
【例5-1】消费者协会接到消费者投诉,指控品牌纸包装饮料存在容量不足,有欺骗消费者之嫌。
第五章假设检验5.1 现实中的统计案例一:时下不少大学生在一边学习的同时也不断寻找一些机会打些零工以赚点钱弥补学习和生活之需,这已经是学生们之间人所共知的事情。
这没有丝毫的让人好奇之处,让人好奇的是这些打工的学生究竟一个月平均能赚多少钱?假设有人说:这个数据是500元,你觉得信不信它呢?当然,你首先需要收集证据,没有证据是肯定说明不了任何问题的。
又假设有人通过组织调查取得过如下数据(调查到一共30人,单位:元):350 500 900 100 100 200 240 300 100 320450 260 650 380 290 400 800 400 250 400290 870 540 320 140 160 300 400 500 340 这时你该做何结论?就算是你得到以上数据的平均数等于423元,你是否就可以作出“是”或“不是”的回答?因为你要作出的回答是针对整个总体的,根据却又只是来自部分总体——即样本,所以事实上不论你最终作出的是“是”还是“不是”的回答,其实都存在犯错误的可能。
那么,如何以样本的数据去对总体参数下结论才最科学?才最不容易犯错误呢?这就是一个属于单个总体参数假设检验的问题了,是本章需要解决的问题。
案例二:你可能认为每一个美国人都知道像这样一些简单历史问题的答案“在美国国旗上有多少颗星?有多少条条纹?星代表什么?条纹又代表什么?”。
非常有意思的是,并非每一个人都知道问题的答案,而且当你知道问题的答案时,你也许会大吃一惊的。
1998年美国杂志《Today’s America》就确实做过这么一个调查,所得到的数据肯定多多少少会出乎很多人的意料之外。
下面就是按性别和美国地区列出的知道星的数目的成年人的百分比:男士女士大城市小城镇农村n(知道)72 72 57 56 31n(不知道)22 34 25 16 15在纽约的伊利县里200个成人被问及在美国国旗上有多少颗星。
上面的表现是属于每一类的成人的数目。
第五章假设检验本章介绍假设检验的基本概念以及参数检验与非参数检验的主要方法。
通过学习,要求:1.掌握统计检验的基本概念,理解该检验犯两类错误的可能;2.熟练掌握总体均值与总体成数指标的各种检验方法;包括:z检验、t检验和p-值检验;4.掌握基本的非参数检验方法,包括:符号检验、秩和检验与游程检验;5.能利用Excel进行假设检验。
第一节假设检验概述一、假设检验的基本概念假设检验是统计推断的另一种方式,它与区间估计的差别主要在于:区间估计是用给定的大概率推断出总体参数的范围,而假设检验是以小概率为标准,对总体的状况所做出的假设进行判断。
假设检验与区间估计结合起来,构成完整的统计推断内容。
假设检验分为两类:一类是参数假设检验,另一类是非参数假设检验。
本章分别讨论这两类检验方法。
进行假设检验,首先要对总体的分布函数形式或分布的某些参数做出假设,然后再根据样本数据和“小概率原理”,对假设的正确性做出判断。
这种思维方法与数学里的“反证法”很相似,“反证法”先将要证明的结论假设为不正确的,作为进一步推论的条件之一使用,最后推出矛盾的结果,以此否定事先所作的假设。
反证法所认为矛盾的结论,也就是不可能发生的事件,这种事件发生的概率为零,该事件是不能接受的现实。
其实,我们在日常生活中,不仅不肯接受概率为0的事件,而且对小概率事件,也持否定态度。
比如,虽然偶尔也有媒体报导陨石降落的消息,但人们不必担心天空降落的陨石会砸伤自己。
所谓小概率原理,即指概率很小的事件在一次试验中实际上不可能出现。
这种事件称为“实际不可能事件”。
小概率的标准是多大?这并没有绝对的标准,一般我们以一个所谓显著性水平α(0<α<1)作为小概率的界限,α的取值与实际问题的性质有关。
所以,统计检验又称显著性检验。
下面通过一个具体例子说明假设检验是怎样进行的。
【例5-1】消费者协会接到消费者投诉,指控品牌纸包装饮料存在容量不足,有欺骗消费者之嫌。
包装上标明的容量为250毫升。
消费者协会从市场上随机抽取50盒该品牌纸包装饮品,测试发现平均含量为248毫升,小于250毫升。
这是生产中正常的波动,还是厂商的有意行为?消费者协会能否根据该样本数据,判定饮料厂商欺骗了消费者呢?上述例子中,消费者协会实际要进行的是一项统计检验工作,检验总体平均容量是否等于包装上注明的250毫升。
即,检验总体平均μ=250是否成立。
这就是一个原假设(null H表示,即:hypothesis),通常用0H:μ=250H,备选假设是在原假设被否定时与原假设对立的是备选假设(alternative hypothesis)1另一种可能成立的结论。
备选假设比原假设还重要,这要由实际问题来确定,一般把期望出现的结论作为备选假设。
上例中可能的备选假设有三种:第一种:如果消费者协会希望知道的是,该品牌饮料的平均容量是否为标明的250毫升,H:μ≠250则1第二种:如果消费协会希望知道该品牌饮料的平均容量是否少于标明的250毫升,则H:μ<2501第三种:如果消费者协会希望知道该品牌饮料的平均容量是否大于标明的250毫升,则H:μ>2501由于备选假设不同,可将假设检验分为双侧(边、尾)检验(two tailed test),和单侧(边、尾)检验(one tailed test)。
对此,我们在后面将进一步说明。
原假设与备选假设确定之后,我们要构造一个统计量来决定是“接受原假设,拒绝备选假设”,还是“拒绝原假设,接受备选假设”。
对不同的问题,要选择不同的检验统计量。
检验统计量确定后,就要利用该统计的分布以及由实际问题中所确定的显著性水平,来进一步确定检验统计量拒绝原假设的取值范围,即拒绝域。
在给定的显著性水平α下,检验统计量的可能取值范围被分成两部分:小概率区域与大概率区域。
小概率区域就是概率不超过显著性水平α的区域,是原假设的拒绝区域;大概率区域是概率为1-α的区域,是原假设的接受区域。
如果样本统计量落入拒绝域,我们就拒绝原假设,接受备选假设,认为样本数据支持备选假设的结论;如果样本统计量落入接受区域,我们就接受原假设,认为没有充分证据证明备选假设结论为真。
请注意,我们这里使用的判断语气比较委婉,原因是:拒绝域是小概率区域,按小概率原理应该拒绝原假设,但是,小概率事件不是完全不可能事件,还是有可能发生的;接受区域是大概率区域,大概率事件也不是必然事件。
无论是接受原假设还是拒绝原假设,都有产生判断失误的可能。
因此,不宜将统计检验的结论过于绝对化。
二、两种类型的错误统计假设检验是通过比较检验统计量的样本数值,作出决策。
统计量是随机变量,据之所作的判断不可能保证百分之百的正确。
一般来说,决策结果存在以下四种情形:原假设是真实的,判断结论是接受原假设,这是一种正确的判断;原假设是不真实的,判断结论是拒绝原假设,这也是种正确的判断;原假设是真实的,判断结论是拒绝原假设,这是一种产生“弃真错误”的判断;原假设是不真实的,判断结论是接受原假设,这又是一种产生“取伪错误”的判断。
以上四种判断可归纳为下列表格形式:以上的弃真错误也称作假设检验的“第一类错误”;取伪错误也称作假设检验的“第二类错误”。
无论是第一类错误还是第二类错误,都是检验结论失真的表现,都是应尽可能地加以避免的情形,如果不能完全避免,也应该对其发生的概率加以控制。
第一类错误产生的原因是:在原假设为真的情况下,检验统计量不巧刚好落入小概率的拒绝区域。
因此,犯第一类错误的概率大小就等于显著性水平的大小,即等于α。
我们可以通过控制显著性水平大小的方式,来控制犯第一类错误的可能性大小。
α定的越小,犯第一类错误的可能性就越小,例如α=0.05,表示犯第一类错误的可能性为5%,100次判断中,产生弃真性错误的次数是5次;进一步降低显著性水平,取α=0.01,这时犯第一类错误的概率下降为1%。
所以统计学上,又称第一类错误为α错误。
第二类错误是“以假为真”的错误,即把不正确的原假设,当做正确的而将它接受了的错误。
犯第二类错误大小的概率记为β,因此,统计学上称第二类错误为β错误。
犯第二类错误的概率与犯第一类错误的概率是密切相关的,在样本一定条件下,α小,β就增大;α大,β就减小。
为了同时减小α和β,只有增大样本容量,减小抽样分布的离散性,这样才能达到目的。
它们这种关系可通过正态分布的统计检验,图示如下:图5-1 α与β关系示意图【例5-2】按照法律,在证明被告有罪之前应先假定他是无罪的。
也就是原假设是0H :被告无罪;备选假设1H :被告有罪。
法庭可能犯的第一类错误是:被告无罪但判他有罪;第二类错误是:被告有罪但判他无罪。
犯第一类错误的性质是“冤枉了好人”,第二类错误的性质是“放过了坏人”。
为了减小“冤枉好人”的概率,应尽可能接受原假设,判被告无罪,这就有可能增大了“放过坏人”的概率;反过来,为了不“放过坏人”,增大拒绝原假设的概率,相应地就又增加了“冤枉好人”的可能性,这就是α与β的关系。
当然,这只是在“一定的证据下”的两难选择。
如果进一步收集有关的证据,在充分的证据下,就有可能做到既不冤枉好人,又不放过坏人。
在现有证据不充分的条件下,法庭控制两类错误概率的实践是:按案件的性质决定首先要控制哪一类错误的概率,如果案件将来对社会危害大,就要控制少犯第二类错误的概率,免得放过的坏人继续危害社会;如果案件对社会没有什么大的危害,不妨“放他一马”,免得冤枉了好人,影响当事人“一生的前程”。
三、检验功效检验效果好与坏,与犯两类错误的概率都有关。
一个有效的检验首先是犯第一类错误的概率α不能太大,否则的话,就经常产生弃真现象;另外,β错误就是取伪的错误,在犯第一类错误概率得到控制的条件下,犯取伪错误的概率也要尽可能地小,或者说,不取伪的概率1-β应尽可能增大。
1-β越大,意味着当原假设不真实时,检验判断出原假设不真实的概率越大,检验的判别能力就越好;1-β越小,意味着当原假设不真实时,检验结论判断出原假设不真实的概率越小,检验的判别能力就越差。
可见1-β是反映统计检验判别能力大小的重要标志,我们称之为检验功效或检验力。
前面分析说明,第一类错误和第二类错误是一对矛盾体,在其他条件不变时,减小犯第一类错误的可能性,势必增加犯第二类错误的可能性;增大第一类错误的可能性,又能减小犯第二类错误的可能性。
可见α的大小,影响到β的大小,进而影响到1-β的大小。
犯第一类错误的概率或检验的显著性水平α是影响检验力的一个重要因素。
在其他条件不变下,显著性水平α增大,β随之减小,检验功效就增强。
可见取α=0.1时比取α=0.01时,检验的功效强,检验力大。
我们在统计检验中,一般都是首先控制犯第一类错误的概率,也就是显著性水平α都尽量取较小的值,尽量避免犯弃真的错误,在其他条件不变时,β就增大,检验的功效就减弱。
该如何来调和这一对相互对抗的矛盾呢?惟一的办法就是增大样本容量,因为增加样本容量α0 0 1能够既保证满足较小的α需要,同时又能减小犯第二类错误的概率β,抵消检验功效的衰减。
可见样本容量大小是影响检验功效大小的一个重要因素,可通过增大样本容量方法提高检验功效。
然而,实际上样本容量n的增加也是有限制的,兼顾α与β很困难,这时,鉴于α风险一般比β风险重要,首先考虑的还是控制α风险。
影响检验功效大小的另一因素是原假设与备选假设间的差异程度。
如果这两个假设间的差异是非常明显的,这时原假设不真而取伪的可能性就减小,即β就减小,检验功效就大。
否则的话,就较难通过检验把原假设与备选假设区分开来,影响检验功效的提高。