线 性 回 归 方 程 推 导
- 格式:pdf
- 大小:225.71 KB
- 文档页数:7

第二节一元线性回归方程的建立一元线性回归分析是处理两个变量之间关系的最简单模型,它所研究的对象是两个变量之间的线性相关关系。
通过对这个模型的讨论,我们不仅可以掌握有关一元线性回归的知识,而且可以从中了解回归分析方法的基本思想、方法和应用。
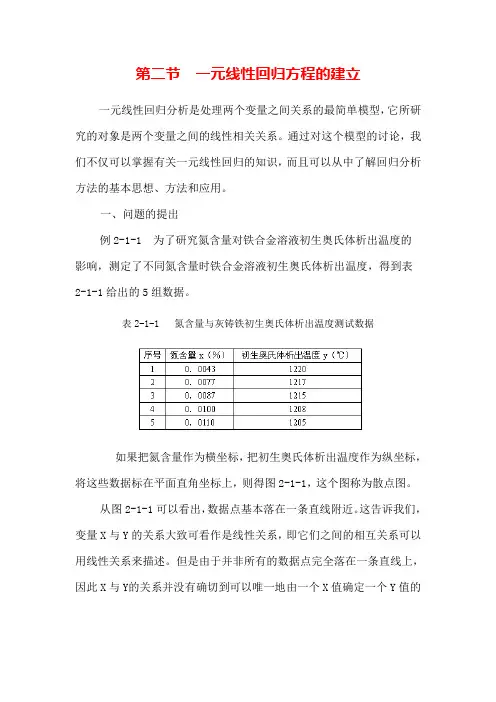
一、问题的提出例2-1-1 为了研究氮含量对铁合金溶液初生奥氏体析出温度的影响,测定了不同氮含量时铁合金溶液初生奥氏体析出温度,得到表2-1-1给出的5组数据。
表2-1-1 氮含量与灰铸铁初生奥氏体析出温度测试数据如果把氮含量作为横坐标,把初生奥氏体析出温度作为纵坐标,将这些数据标在平面直角坐标上,则得图2-1-1,这个图称为散点图。
从图2-1-1可以看出,数据点基本落在一条直线附近。
这告诉我们,变量X与Y的关系大致可看作是线性关系,即它们之间的相互关系可以用线性关系来描述。
但是由于并非所有的数据点完全落在一条直线上,因此X与Y的关系并没有确切到可以唯一地由一个X值确定一个Y值的程度。
其它因素,诸如其它微量元素的含量以及测试误差等都会影响Y 的测试结果。
如果我们要研究X与Y的关系,可以作线性拟合(2-1-1)二、最小二乘法原理如果把用回归方程计算得到的i值(i=1,2,…n)称为回归值,那么实际测量值y i与回归值i之间存在着偏差,我们把这(i=1,2,3,…,n)。
这样,我们就可以用残差平种偏差称为残差,记为e i方和来度量测量值与回归直线的接近或偏差程度。
残差平方和定义为: (2-1-2) 所谓最小二乘法,就是选择a和b使Q(a,b)最小,即用最小二乘法得到的回归直线是在所有直线中与测量值残差平方和Q最小的一条。
由(2-1-2)式可知Q是关于a,b的二次函数,所以它的最小值总是存在的。
下面讨论的a和b的求法。


线性回归——正规方程推导过程线性回归——正规方程推导过程我们知道线性回归中除了利用梯度下降算法来求最优解之外,还可以通过正规方程的形式来求解。
首先看到我们的线性回归模型:f(xi)=wTxif(x_i)=w^Tx_if(xi?)=wTxi?其中w=(w0w1.wn)w=begin{pmatrix}w_0w_1.w_nend{pmatrix}w=?w0?w1?. wn?,xi=(x0x1.xn)x_i=begin{pmatrix}x_0x_1.x_nend{pmatrix}xi?=?x0 x1.xn,m表示样本数,n是特征数。
然后我们的代价函数(这里使用均方误差):J(w)=∑i=1m(f(xi)?yi)2J(w)=sum_{i=1}^m(f(x_i)-y_i)^2J(w) =i=1∑m?(f(xi?)?yi?)2接着把我的代价函数写成向量的形式:J(w)=(Xw?y)T(Xw?y)J(w)=(Xw-y)^T(Xw-y)J(w)=(Xw?y)T(Xw?y) 其中X=(1x11x12?x1n1x21x22?x2n?1xm1xm2?xmn)X=begin{pmatrix}1 x_{11} x_{12} cdots x_{1n}1 x_{21} x_{22} cdots x_{2n}vdots vdots vdots ddots vdots1 x_{m1} x_{m2} cdots x_{mn}end{pmatrix}X=?11?1?x11?x21?xm1?x12?x22?xm2?x1n?x2n?xmn?最后我们对w进行求导,等于0,即求出最优解。
在求导之前,先补充一下线性代数中矩阵的知识:1.左分配率:A(B+C)=AB+ACA(B+C) = AB+ACA(B+C)=AB+AC;右分配率:(B+C)A=BA+CA(B+C)A = BA + CA(B+C)A=BA+CA2.转置和逆:(AT)?1=(A?1)T(A^T)^{-1}=(A^{-1})^T(AT)?1=(A?1)T,(AT)T=A(A^T)^T=A(AT)T=A3.矩阵转置的运算规律:(A+B)T=AT+BT(A+B)^T=A^T+B^T(A+B)T=AT+BT;(AB)T=BTAT(AB)^T=B^TA^T(AB)T=BTAT然后介绍一下常用的矩阵求导公式:1.δXTAXδX=(A+AT)Xfrac{delta X^TAX}{delta X}=(A+A^T)XδXδXTAX?=(A+AT)X2.δAXδX=ATfrac{delta AX}{delta X}=A^TδXδAX?=AT3.δXTAδX=Afrac{delta X^TA}{delta X}=AδXδXTA?=A然后我们来看一下求导的过程:1.展开原函数,利用上面的定理J(w)=(Xw?y)T(Xw?y)=((Xw)T?yT)(Xw?y)=wTXTXw?wTXTy?yTXw+yT yJ(w)=(Xw-y)^T(Xw-y)=((Xw)^T-y^T)(Xw-y)=w^TX^TXw-w^TX^Ty-y^TXw+y^TyJ(w)=(Xw?y)T(Xw?y)=((Xw)T?yT)(Xw?y)=wTXTXw?wTXTy?yT Xw+yTy2.求导,化简得,δJ(w)δw=(XTX+(XTX)T)w?XTy?(yTX)T=0?2XTXw?2XTy=0?XTXw=X Ty?w=(XXT)?1XTyfrac{delta J(w)}{delta w}=(X^TX+(X^TX)^T)w-X^Ty-(y^TX)^T=0implies2X^TXw-2X^Ty=0implies X^TXw=X^Tyimplies w=(XX^T)^{-1}X^TyδwδJ(w)?=(XTX+(XTX)T)w?XTy?(yTX)T=0?2XTX w?2XTy=0?XTXw=XTy?w=(XXT)?1XTy最后补充一下关于矩阵求导的一些知识,不懂可以查阅:矩阵求导、几种重要的矩阵及常用的矩阵求导公式这次接着一元线性回归继续介绍多元线性回归,同样还是参靠周志华老师的《机器学习》,把其中我一开始学习时花了较大精力弄通的推导环节详细叙述一下。

线性回归算法推导线性回归之最小二乘法推导及python实现前言线性模型基本形式模型评估寻找最优解python实现最小二乘法本文章为个人的学习笔记。
学习书籍《机器学习》(周志华著,俗称西瓜书)。
线性模型基本形式首先是最基本的线性模型:f(x)=w1x1+w2x2+w3x3+.+wnxn+bf( textbf{x} )=w_1x_1+w_2x_2+w_3x_3+.+w_nx_n+bf(x)=w1?x1?+w 2?x2?+w3?x3?+.+wn?xn?+b化简成向量形式f(x)=xw+bf( textbf{x})= textbf{x}textbf{w} +b f(x)=xw+bf(x)≈yf( textbf{x})approx yf(x)≈y其中x=(x1,x2,x3.,xn)textbf{x}=(x_1,x_2,x_3.,x_n)x=(x1?,x2?,x3?. ,xn?),xix_ixi? 代表xtextbf{x}x的第i个属性。
而w=(w1;w2;w3;.;wn)textbf{w}=(w_1;w_2;w_3;.;w_n)w=(w1?;w2?;w3 ;.;wn)对应于 xtextbf{x}x 不同属性的系数。
其中yyy代表了数据xtextbf{x}x的真实情况,而f(x)f(bf{x})f(x)得到的是对xtextbf{x}x的预测值,我们通过(y,x)(y,textbf{x})(y,x)对模型进行训练,力求通过线性模型f(x)f(bf{x})f(x)来对yyy未知的数据进行预测。
为了计算方便,令:x=(x1,x2,x3.,xn,1)textbf{x}=(x_1,x_2,x_3.,x_n,1)x=(x1?,x 2?,x3?.,xn?,1)w=(w1;w2;w3;.;wn;b)textbf{w}=(w_1;w_2;w_3;.;w _n;b)w=(w1?;w2?;w3?;.;wn?;b)线性模型就写成如下形式:f(x)=wxf( textbf{x})= textbf{w} textbf{x} f(x)=wx模型评估线性回归的目标就是要找到一个最合适的模型来使得预测的准确度最大化。


线性回归之最小二乘法线性回归Linear Regression——线性回归是机器学习中有监督机器学习下的一种简单的回归算法。
分为一元线性回归(简单线性回归)和多元线性回归,其中一元线性回归是多元线性回归的一种特殊情况,我们主要讨论多元线性回归如果因变量和自变量之间的关系满足线性关系(自变量的最高幂为一次),那么我们可以用线性回归模型来拟合因变量与自变量之间的关系.简单线性回归的公式如下:y^=ax+b hat y=ax+by^?=ax+b多元线性回归的公式如下:y^=θTx hat y= theta^T x y^?=θTx上式中的θthetaθ为系数矩阵,x为单个多元样本.由训练集中的样本数据来求得系数矩阵,求解的结果就是线性回归模型,预测样本带入x就能获得预测值y^hat yy^?,求解系数矩阵的具体公式接下来会推导.推导过程推导总似然函数假设线性回归公式为y^=θxhat y= theta xy^?=θx.真实值y与预测值y^hat yy^?之间必然有误差?=y^?yepsilon=haty-y?=y^?y,按照中心极限定理(见知识储备),我们可以假定?epsilon?服从正态分布,正态分布的概率密度公式为:ρ(x)=1σ2πe?(x?μ)22σ2rho (x)=frac {1}{sigmasqrt{2pi}}e^{-frac{(x-mu)^2}{2sigma^2}}ρ(x)=σ2π1e2σ2(x?μ)2?为了模型的准确性,我们希望?epsilon?的值越小越好,所以正态分布的期望μmuμ为0.概率函数需要由概率密度函数求积分,计算太复杂,但是概率函数和概率密度函数呈正相关,当概率密度函数求得最大值时概率函数也在此时能得到最大值,因此之后会用概率密度函数代替概率函数做计算.我们就得到了单个样本的误差似然函数(μ=0,σmu=0,sigmaμ=0,σ为某个定值):ρ(?)=1σ2πe?(?0)22σ2rho (epsilon)=frac {1}{sigmasqrt{2pi}}e^{-frac{(epsilon-0)^2}{2sigma^2}}ρ(?)=σ2π?1?e?2σ2(?0)2?而一组样本的误差总似然函数即为:Lθ(?1,?,?m)=f(?1,?,?m∣μ,σ2)L_theta(epsilon_1,cdots,e psilon_m)=f(epsilon_1,cdots,epsilon_m|mu,sigma^2)Lθ?(?1?,? ,?m?)=f(?1?,?,?m?∣μ,σ2)因为我们假定了?epsilon?服从正态分布,也就是说样本之间互相独立,所以我们可以把上式写成连乘的形式:f(?1,?,?m∣μ,σ2)=f(?1∣μ,σ2)?f(?m∣μ,σ2)f(epsilon_1,cdots,epsilon_m|mu,sigma^2)=f(epsilon_1|mu,sigma^2)*cdots *f(epsilon_m|mu,sigma^2)f(?1?,?,?m?∣μ,σ2)=f(?1?∣μ,σ2)?f(?m?∣μ,σ2) Lθ(?1,?,?m)=∏i=1mf(?i∣μ,σ2)=∏i=1m1σ2πe?(?i?0)22σ2L_theta(epsilon_1,cdots,epsilon_m)=prod^m_{i=1}f(epsilon _i|mu,sigma^2)=prod^m_{i=1}frac{1}{sigmasqrt{2pi}}e^{-frac{(epsilon_i-0)^2}{2sigma^2}}Lθ? (?1?,?,?m?)=i=1∏m?f(?i?∣μ,σ2)=i=1∏m?σ2π?1?e?2σ2(?i?0)2?在线性回归中,误差函数可以写为如下形式:i=∣yiy^i∣=∣yiθTxi∣epsilon_i=|y_i-haty_i|=|y_i-theta^Tx_i|?i?=∣yi?y^?i?∣=∣yi?θTxi?∣最后可以得到在正态分布假设下的总似然估计函数如下:Lθ(?1,?,?m)=∏i=1m1σ2πe?(?i?0)22σ2=∏i=1m1σ2πe?(yi θTxi)22σ2L_theta(epsilon_1,cdots,epsilon_m)=prod^m_{i=1} frac{1}{sigmasqrt{2pi}}e^{-frac{(epsilon_i-0)^2}{2sigma^2}}=pro d^m_{i=1}frac{1}{sigmasqrt{2pi}}e^{-frac{(y_i-theta^Tx_i)^2}{2sigma^2}}L θ?(?1?,?,?m?)=i=1∏m?σ2π?1?e?2σ2(?i?0)2?=i=1∏m?σ2π?1 e2σ2(yi?θTxi?)2?推导损失函数按照最大总似然的数学思想(见知识储备),我们可以试着去求总似然的最大值.遇到连乘符号的时候,一般思路是对两边做对数运算(见知识储备),获得对数总似然函数:l(θ)=loge(Lθ(?1,?,?m))=loge(∏i=1m1σ2πe?(yi?θTxi)22σ2)l(theta)=log_e(L_theta(epsilon_1,cdots,epsilon_m))=log_ e(prod^m_{i=1}frac{1}{sigmasqrt{2pi}}e^{-frac{(y_i-theta^Tx_i)^2}{2sigma^2}}) l(θ)=loge?(Lθ?(?1?,?,?m?))=loge?(i=1∏m?σ2π?1?e?2σ2(yi θTxi?)2?)l(θ)=loge(∏i=1m1σ2πe?(yi?θTxi)22σ2)=∑i=1mloge1σ2πexp(?(yi?θTxi)22σ2)=mloge1σ2π?12σ2∑i=1m(yi?θTxi)2l (theta) = log_e(prod^m_{i=1}frac {1}{sigmasqrt{2pi}}e^{-frac{(y_i-theta^Tx_i)^2}{2sigma^2}}) = sum_{i=1}^mlog_efrac {1}{sigmasqrt{2pi}}exp({-frac{(y_i-theta^Tx_i)^2}{2sigma^2} })=mlog_efrac{1}{sigmasqrt{2pi}}-frac{1}{2sigma^2}sum^m_{i= 1}(y^i-theta^Tx^i)^2l(θ)=loge?(i=1∏m?σ2π?1?e?2σ2(yi?θTxi?)2?)=i=1∑m?loge?σ2π?1?exp(?2σ2(yi?θTxi?)2?)=mloge?σ2π?1?2σ21?i=1∑m?(yi?θTxi)2前部分是一个常数,后部分越小那么总似然值越大,后部分则称之为损失函数,则有损失函数的公式J(θ)J(theta)J(θ):J(θ)=12∑i=1m(yi?θTxi)2=12∑i=1m(yi?hθ(xi))2=12∑i=1m (hθ(xi)?yi)2J(theta)=frac{1}{2}sum^m_{i=1}(y^i-theta^Tx^i)^2=frac{1}{2} sum^m_{i=1}(y^i-h_theta(x^i))^2=frac{1}{2}sum^m_{i=1}(h_the ta(x^i)-y^i)^2J(θ)=21?i=1∑m?(yi?θTxi)2=21?i=1∑m?(yi?hθ?(xi))2=21?i=1∑m?(hθ?(xi)?yi)2解析方法求解线性回归要求的总似然最大,需要使得损失函数最小,我们可以对损失函数求导.首先对损失函数做进一步推导:J(θ)=12∑i=1m(hθ(xi)?yi)2=12(Xθ?y)T(Xθ?y)J(theta)=fr ac{1}{2}sum^m_{i=1}(h_theta(x^i)-y^i)^2=frac{1}{2}(Xtheta-y )^T(Xtheta-y)J(θ)=21?i=1∑m?(hθ?(xi)?yi)2=21?(Xθ?y)T(Xθy)注意上式中的X是一组样本形成的样本矩阵,θthetaθ是系数向量,y也是样本真实值形成的矩阵,这一步转换不能理解的话可以试着把12(Xθ?y)T(Xθ?y)frac{1}{2}(Xtheta-y)^T(Xtheta-y)21?(Xθ?y) T(Xθ?y)带入值展开试试.J(θ)=12∑i=1m(hθ(xi)?yi)2=12(Xθ?y)T(Xθ?y)=12((Xθ)T? yT)(Xθ?y)=12(θTXT?yT)(Xθ?y)=12(θTXTXθ?yTXθ?θTXTy+yTy)J(theta)=frac{1}{2}sum^m_{i=1}(h_theta(x^i)-y^i)^2=frac{1} {2}(Xtheta-y)^T(Xtheta-y)=frac{1}{2}((Xtheta)^T-y^T)(Xtheta -y)=frac{1}{2}(theta^TX^T-y^T)(Xtheta-y)=frac{1}{2}(theta^T X^TXtheta-y^TXtheta-theta^TX^Ty+y^Ty)J(θ)=21?i=1∑m?(hθ?( xi)?yi)2=21?(Xθ?y)T(Xθ?y)=21?((Xθ)T?yT)(Xθ?y)=21?(θTXT yT)(Xθ?y)=21?(θTXTXθ?yTXθ?θTXTy+yTy)根据黑塞矩阵可以判断出J(θ)J(theta)J(θ)是凸函数,即J(θ)J(theta)J(θ)的对θthetaθ的导数为零时可以求得J(θ)J(theta)J(θ)的最小值.J(θ)?θ=12(2XTXθ?(yTX)T?XTy)=12(2XTXθ?XTy?XTy)=XTXθXTyfrac{partialJ(theta)}{partialtheta}=frac{1}{2}(2X^TXtheta-(y^TX)^T-X^Ty )=frac{1}{2}(2X^TXtheta-X^Ty-X^Ty)=X^TXtheta-X^Ty?θ?J(θ)? =21?(2XTXθ?(yTX)T?XTy)=21?(2XTXθ?XTy?XTy)=XTXθ?XTy 当上式等于零时可以求得损失函数最小时对应的θthetaθ,即我们最终想要获得的系数矩阵:XTXθ?XTy=0XTXθ=XTy((XTX)?1XTX)θ=(XTX)?1XTyEθ=(XTX)?1 XTyθ=(XTX)?1XTyX^TXtheta-X^Ty=0X^TXtheta=X^Ty((X^TX)^{-1}X^TX)theta=(X^TX)^{-1}X^TyEtheta=(X^TX)^{-1}X^Tytheta=(X^TX)^{-1}X^TyXTXθ?XTy=0XT Xθ=XTy((XTX)?1XTX)θ=(XTX)?1XTyEθ=(XTX)?1XTyθ=(XTX)?1XTy (顺便附上一元线性回归的系数解析解公式:θ=∑i=1m(xi?x ̄)(yi?y ̄)∑i=1m(xi?x  ̄)2theta=frac{sum^m_{i=1}(x_i-overline{x})(y_i-overline{y} )}{sum^m_{i=1}(x_i-overline{x})^2}θ=∑i=1m?(xi?x)2∑i=1m?( xi?x)(yi?y?)?)简单实现import numpy as npimport matplotlib.pyplot as plt# 随机创建训练集,X中有一列全为'1'作为截距项X = 2 * np.random.rand(100, 1)y = 5 + 4 * X + np.random.randn(100, 1)X = np.c_[np.ones((100,1)),X]# 按上面获得的解析解来求得系数矩阵thetatheta = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)# 打印结果print(theta)# 测试部分X_test = np.array([[0],X_test = np.c_[(np.ones((2, 1))), X_test]print(X_test)y_predict = X_test.dot(theta)print(y_predict)plt.plot(X_test[:,-1], y_predict, 'r-')plt.axis([0, 2, 0, 15])plt.show()sklearn实现import numpy as npimport matplotlib.pyplot as pltfrom sklearn.linear_model import LinearRegression X = 2 * np.random.rand(100, 1)y = 5 + 4 * X + np.random.randn(100, 1)X = np.c_[np.ones((100,1)),X]# 新建线性回归模型model = LinearRegression(fit_intercept=False)# 代入训练集数据做训练model.fit(X,y)# 打印训练结果print(model.intercept_,model.coef_)X_test = np.array([[0],X_test = np.c_[(np.ones((2, 1))), X_test]print(X_test)y_predict =model.predict(X_test)print(y_predict)plt.plot(X_test[:,-1], y_predict, 'r-')plt.axis([0, 2, 0, 15])plt.show()使用解析解的公式来求得地模型是最准确的.计算量非常大,这会使得求解耗时极多,因此我们一般用的都是梯度下降法求解.知识储备距离公式机器学习中常见的距离公式 - WingPig - 博客园中心极限定理是讨论随机变量序列部分和分布渐近于正态分布的一类定理。


线性回归方程推导理论推导机器学习所针对的问题有两种:一种是回归,一种是分类。
回归是解决连续数据的预测问题,而分类是解决离散数据的预测问题。
线性回归是一个典型的回归问题。
其实我们在中学时期就接触过,叫最小二乘法。
线性回归试图学得一个线性模型以尽可能准确地预测输出结果。
?先从简单的模型看起:?首先,我们只考虑单组变量的情况,有:?使得?假设有m个数据,我们希望通过x预测的结果f(x)来估计y。
其中w和b都是线性回归模型的参数。
?为了能更好地预测出结果,我们希望自己预测的结果f(x)与y 的差值尽可能地小,所以我们可以写出代价函数(cost function)如下:?接着代入f(x)的公式可以得到:?不难看出,这里的代价函数表示的是预测值f(x)与实际值y之间的误差的平方。
它对应了常用的欧几里得距离简称“欧氏距离”。
基于均方误差最小化来求解模型的方法我们叫做“最小二乘法”。
在线性回归中,最小二乘法实质上就是找到一条直线,使所有样本数据到该直线的欧式距离之和最小,即误差最小。
?我们希望这个代价函数能有最小值,那么就分别对其求w和b的偏导,使其等于0,求解方程。
?先求偏导,得到下面两个式子:?很明显,公式中的参数m,b,w都与i无关,简化时可以直接提出来。
?另这两个偏导等于0:?求解方程组,解得:?这样根据数据集中给出的x和y,我们可以求出w和b来构建简单的线性模型来预测结果。
接下来,推广到更一般的情况:?我们假设数据集中共有m个样本,每个样本有n个特征,用X矩阵表示样本和特征,是一个m×n的矩阵:?用Y矩阵表示标签,是一个m×1的矩阵:?为了构建线性模型,我们还需要假设一些参数:?(有时还要加一个偏差(bias)也就是,为了推导方便没加,实际上结果是一样的)好了,我们可以表示出线性模型了:?h(x)表示假设,即hypothesis。
通过矩阵乘法,我们知道结果是一个n×1的矩阵。


用python求解多元线性回归方程的权重和残差最近学金融的妹妹要处理数据写论文,对一个文科妹子来说,数学学不会,公式看不懂怎么破~作为姐姐的我看在眼里,疼在心里,打算帮妹妹解决掉数据计算这方面的问题。
原来就是求三元线性回归的残差啊,害,这有什么难的,妹妹就是不会算权重,一直在网上寻找已经算好权重的数据,为此特意开通了什么会员,咱也不知道咱也不敢问。
于是乎,利用自己所学的python,写下了这个程序。
简单介绍一下什么是线性回归?答:线性回归是通过一个或多个自变量与因变量之间进行建模的回归分析。
其中可以为一个或多个自变量之间的线性组合。
一元线性回归涉及到的变量只有一个;多元线性回归涉及到的变量有两个及两个以上。
线性关系模型为:w 为权重,b 为偏置项,其中 w 、x 为矩阵。
转换成矩阵如下:话不多说,上案例。
妹妹论文中的公式是:可简化为:根据推导得到:典型的多元线性回归方程,具体推导就不详细说明了,大家自行百度。
接下来上代码。
如果不怕麻烦想试一下’.txt’文件转‘.csv’ 文件,就看方法一,想直接用.xlsx转.csv的看方法二。
方法一:先将excel表转换成.txt文件接下来打开.txt文件,另存为’utf-8’格式,如果不是,会报错。
from numpy.linalg import inv # 矩阵求逆from numpy import dot # 求矩阵点乘import numpy as npimport pandas as pdtxt = np.loadtxt('file.txt')txtDF = pd.DataFrame(txt)txtDF.to_csv('file.csv', index=False)data = pd.read_csv('file.csv')dataset = pd.DataFrame(data,copy = True)test = dataset.iloc[:, 0:4]test = test.copy()X = test.iloc[:, [1,2,3]]Y = test.iloc[:, 0]theta = dot(dot(inv(dot(X.T, X)), X.T), Y)y = dot(theta, X.T)print('权重',theta) # 权重loss = np.array(Y-y) # 残差print('残差',loss)运行结果:权重和残差都可以算出来了。
一元线性回归与多元线性回归理论及公式推导一元线性回归回归分析只涉及到两个变量的,称一元回归分析。
一元回归的主要任务是从两个相关变量中的一个变量去估计另一个变量,被估计的变量,称因变量,可设为Y;估计出的变量,称自变量,设为X。
回归分析就是要找出一个数学模型Y=f(x)y=ax+b多元线性回归注:为使似然函数越大,则需要最小二乘法函数越小越好线性回归中为什么选用平方和作为误差函数?假设模型结果与测量值误差满足,均值为0的高斯分布,即正态分布。
这个假设是靠谱的,符合一般客观统计规律。
若使模型与测量数据最接近,那么其概率积就最大。
概率积,就是概率密度函数的连续积,这样,就形成了一个最大似然函数估计。
对最大似然函数估计进行推导,就得出了推导后结果:平方和最小公式1.x的平方等于x的转置乘以x。
2.机器学习中普遍认为函数属于凸函数(凸优化问题),函数图形如下,从图中可以看出函数要想取到最小值或者极小值,就需要使偏导等于0。
3.一些问题上没办法直接求解,则可以在上图中选一个点,依次一步步优化,取得最小值(梯度优化)SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。
解决方案:1.动态更改学习速率a的大小,可以增大或者减小2.随机选样本进行学习批量梯度下降每次更新使用了所有的训练数据,最小化损失函数,如果只有一个极小值,那么批梯度下降是考虑了训练集所有数据,是朝着最小值迭代运动的,但是缺点是如果样本值很大的话,更新速度会很慢。
随机梯度下降在每次更新的时候,只考虑了一个样本点,这样会大大加快训练数据,也恰好是批梯度下降的缺点,但是有可能由于训练数据的噪声点较多,那么每一次利用噪声点进行更新的过程中,就不一定是朝着极小值方向更新,但是由于更新多轮,整体方向还是大致朝着极小值方向更新,又提高了速度。
小批量梯度下降法是为了解决批梯度下降法的训练速度慢,以及随机梯度下降法的准确性综合而来,但是这里注意,不同问题的batch是不一样的,nlp的parser训练部分batch一般就设置为10000,那么为什么是10000呢,我觉得这就和每一个问题中神经网络需要设置多少层,没有一个人能够准确答出,只能通过实验结果来进行超参数的调整。
线性回归及其变式Q1:线性回归的原理Q2:线性回归损失函数的推导过程Q3:求解线性回归损失函数的方法有哪些Q4:如何解决共线性(待补充)Q5:如何防止过拟合Q6:分布式训练怎么做(待补充)Q7:正则化的目的和方法Q8:为什么L1正则化能产生稀疏解,L2则不可以Q1:线性回归的原理线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。
其表达形式为y = w'x+e,e 为误差服从均值为0的正态分布。
可以利用梯度下降法等方法求出权重w'的值。
Q2:线性回归损失函数的推导过程首先线性回归有3个假设:(1)误差存在且为;(2)误差的分布基本符合正态分布,因为通常我们不知道是什么分布的时候,根据经验来说正态分布往往效果不错。
(3)每一个样本的误差都是独立同分布的,且满足随机性。
于是我们可以得到第个样本的误差为的概率是:然后,?是真实值与预测值之间的误差,于是把这两个值代进去。
这是一个似然函数,我们希望它的值越大越好!常规操作取一个log,于是就有由此可以得到线性回归的损失函数或者说目标函数就是之所以有1-2这么个系数,只是因为后续用到梯度下降的时候,求导可以把它约掉,方便计算而已,这不会影响最终的结果。
而且注意噢,这里可是没有除以m的!!!!Q3:求解线性回归损失函数的方法有哪些(1)梯度下降法梯度下降又可以是批梯度下降,也可以是随机梯度下降。
下面是只有一个样本的时候的批梯度下降的公式推导。
当有m个样本时,在学习速率后面做一个累加即可。
如果是随机梯度下降,每次只需要用到一个样本就行了。
(2)正规方程组上一个简单的推导过程。
Q4:如何解决共线性Q5:如何防止过拟合通过添加正则化项来防止过拟合。
(1)Lasso回归使用L1正则化(2)Ridge回归使用L2正则化(3)ElasticNet回归使用L1+L2正则化Lasso回归可以将系数收缩到0,从而达到变量选择的效果,这是一种非常流行的变量选择方法。
多元线性回归推导过程常用算法一多元线性回归详解1此次我们来学习人工智能的第一个算法:多元线性回归.文章会包含必要的数学知识回顾,大部分比较简单,数学功底好的朋友只需要浏览标题,简单了解需要哪些数学知识即可.本章主要包括以下内容数学基础知识回顾什么是多元线性回归多元线性回归的推导过程详解如何求得最优解详解数学基础知识回顾我们知道,y=ax+b这个一元一次函数的图像是一条直线.当x=0时,y=b,所以直线经过点(0,b),我们把当x=0时直线与y轴交点到x轴的距离称为直线y=ax+b图像在x轴上的截距,其实截距就是这个常数b.(有点拗口,多读两遍)截距在数学中的定义是:直线的截距分为横截距和纵截距,横截距是直线与X轴交点的横坐标,纵截距是直线与Y轴交点的纵坐标。
根据上边的例子可以看出,我们一般讨论的截距默认指纵截距.既然已知y=ax+b中b是截距,为了不考虑常数b的影响,我们让b=0,则函数变为y=ax.注意变换后表达式的图像.当a=1时,y=ax的图像是经过原点,与x轴呈45°夹角的直线(第一,三象限的角平分线),当a的值发生变化时,y=ax 的图像与x轴和y轴的夹角也都会相应变化,我们称为这条直线y=ax的倾斜程度在发生变化,又因为a是决定直线倾斜程度的唯一的量(即便b不等于0也不影响倾斜程度),那么我们就称a为直线y=ax+b的斜率.斜率在数学中的解释是表示一条直线(或曲线的切线)关于(横)坐标轴倾斜程度的量.还是y=ax+b,我们知道这个函数的图像是一条直线,每个不同的x对应着直线上一点y.那么当自变量x的值变化的时候,y值也会随之变化.数学中我们把x的变化量成为Δx,把对应的y的变化量成为Δy,自变量的变化量Δx与因变量的变化量Δy的比值称为导数.记作y'.y'=Δy-Δx常用的求导公式在这部分不涉及,我们用到一个记住一个即可.4-矩阵和向量什么是向量:向量就是一个数组.比如[1,2,3]是一个有三个元素的向量.有行向量和列向量之分,行向量就是数字横向排列:X=[1,2,3],列向量是数字竖向排列,如下图什么是矩阵:矩阵就是元素是数组的数组,也就是多维数组,比如[[1,2,3],[4,5,6]]是一个两行三列的矩阵,也叫2*3的矩阵. 行代表内层数组的个数,列代表内层数组的元素数.一个矩阵中的所有数组元素相同.5-向量的运算:一个数乘以一个向量等于这个数同向量中的每个元素相乘,结果还是一个向量.2 * [1,2,3] = [2,4,6]一个行向量乘以一个列向量,是两个向量对位相乘再相加,结果是一个实数.= 11 + 22 + 3*3 = 14附加:转置转置用数学符号T来表示,比如W向量的转置表示为.转置就是将向量或者矩阵旋转九十度.一个行向量的转置是列向量,列向量的转置是行向量.一个m*n的矩阵转置是n*m的矩阵.注:以上概念完全是为了读者能容易理解,并不严谨,若想知道上述名词的严谨解释,请自行百度.什么是多元线性回归我们知道y=ax+b是一元一次方程,y=ax1+bx2+c(1和2是角标,原谅我的懒)是二元一次方程.其中,"次"指的是未知数的最大幂数,"元"指的是表达式中未知数的个数(这里就是x的个数).那么"多元"的意思可想而知,就是表达式中x(或者叫自变量,也叫属性)有很多个.当b=0时,我们说y=ax,y和x的大小始终符合y-x=a,图像上任意一点的坐标,y值都是x值的a倍.我们把这种横纵坐标始终呈固定倍数的关系叫做"线性".线性函数的图像是一条直线.所以我们知道了多元线性回归函数的图像一定也是一条直线.现在我们知道了多元线性回归的多元和线性,而回归的概念我们在人工智能开篇(很简短,请点搜索"回归"查看概念)中有讲述,所以多元线性回归就是:用多个x(变量或属性)与结果y的关系式来描述一些散列点之间的共同特性.这些x和一个y关系的图像并不完全满足任意两点之间的关系(两点一线),但这条直线是综合所有的点,最适合描述他们共同特性的,因为他到所有点的距离之和最小也就是总体误差最小.所以多元线性回归的表达式可以写成:y= w0x0 + w1x1 + w2x2 + . + wnxn (0到n都是下标哦)我们知道y=ax+b这个线性函数中,b表示截距.我们又不能确定多元线性回归函数中预测出的回归函数图像经过原点,所以在多元线性回归函数中,需要保留一项常数为截距.所以我们规定 y= w0x0 + w1x1 + w2x2 + . + wnxn中,x0=1,这样多元线性回归函数就变成了: y= w0 + w1x1 + w2x2 + . + wnxn,w0项为截距.如果没有w0项,我们 y= w0x0 + w1x1 + w2x2 + . + wnxn就是一个由n+1个自变量所构成的图像经过原点的直线函数.那么就会导致我们一直在用一条经过原点的直线来概括描述一些散列点的分布规律.这样显然增大了局限性,造成的结果就是预测出的结果函数准确率大幅度下降.有的朋友还会纠结为什么是x0=1而不是x2,其实不管是哪个自变量等于1,我们的目的是让函数 y= w0x0 + w1x1 + w2x2 + . + wnxn编程一个包含常数项的线性函数.选取任何一个x都可以.选x0是因为他位置刚好且容易理解.多元线性回归的推导过程详解1-向量表达形式我们前边回顾了向量的概念,向量就是一个数组,就是一堆数.那么表达式y= w0x0 + w1x1 + w2x2 + . + wnxn是否可以写成两个向量相乘的形式呢?让我们来尝试一下.假设向量W= [w1,w2.wn]是行向量,向量X= [x1,x2.xn],行向量和列向量相乘的法则是对位相乘再相加, 结果是一个实数.符合我们的逾期结果等于y,所以可以将表达式写成y=W * X.但是设定两个向量一个是行向量一个是列向量又容易混淆,所以我们不如规定W和X都为列向量.所以表达式可以写成 (还是行向量)与向量X 相乘.所以最终的表达式为:y= * X,其中也经常用θ(theta的转置,t是上标)表示.此处,如果将两个表达式都设为行向量,y=W * 也是一样的,只是大家为了统一表达形式,选择第一种形式而已.2-最大似然估计最大似然估计的意思就是最大可能性估计,其内容为:如果两件事A,B 相互独立,那么A和B同时发生的概率满足公式P(A , B) = P(A) * P(B)P(x)表示事件x发生的概率.如何来理解独立呢?两件事独立是说这两件事不想关,比如我们随机抽取两个人A和B,这两个人有一个共同特性就是在同一个公司,那么抽取这两个人A和B的件事就不独立,如果A和B没有任何关系,那么这两件事就是独立的.我们使用多元线性回归的目的是总结一些不想关元素的规律,比如以前提到的散列点的表达式,这些点是随机的,所以我们认为这些点没有相关性,也就是独立的.总结不相关事件发生的规律也可以认为是总结所有事件同时发生的概率,所有事情发生的概率越大,那么我们预测到的规律就越准确.这里重复下以前我们提到的观点.回归的意思是用一条直线来概括所有点的分布规律,并不是来描述所有点的函数,因为不可能存在一条直线连接所有的散列点.所以我们计算出的值是有误差的,或者说我们回归出的这条直线是有误差的.我们回归出的这条线的目的是用来预测下一个点的位置.考虑一下,一件事情我们规律总结的不准,原因是什么?是不是因为我们观察的不够细或者说观察的维度不够多呢?当我们掷一个骰子,我们清楚的知道他掷出的高度,落地的角度,反弹的力度等等信息,那上帝视角的我们是一定可以知道他每次得到的点数的.我们观测不到所有的信息,所以我们认为每次投骰子得到的点数是不确定的,是符合一定概率的,未观测到的信息我们称为误差.一个事件已经观察到的维度发生的概率越大,那么对应的未观测到的维度发生的概率就会越小.可以说我们总结的规律就越准确.根据最大似然估计P(y) = P(x1,x2 . xn)= P(x1) * P(x2) . P(xn)当所有事情发生的概率为最大时,我们认为总结出的函数最符合这些事件的实际规律.所以我们把总结这些点的分布规律问题转变为了求得P(x1,x2 . xn)= P(x1) * P(x2) . P(xn)的发生概率最大.3-概率密度函数数学中并没有一种方法来直接求得什么情况下几个事件同时发生的概率最大.所以引用概率密度函数.首先引入一点概念:一个随机变量发生的概率符合高斯分布(也叫正太分布).此处为单纯的数学概念,记住即可.高斯分布的概率密度函数还是高斯分布.公式如下:公式中x为实际值,u为预测值.在多元线性回归中,x就是实际的y,u 就是θ * X.既然说我们要总结的事件是相互独立的,那么这里的每个事件肯定都是一个随机事件,也叫随机变量.所以我们要归纳的每个事件的发生概率都符合高斯分布.什么是概率密度函数呢?它指的就是一个事件发生的概率有多大,当事件x带入上面公式得到的值越大,证明其发生的概率也越大.需要注意,得到的并不是事件x发生的概率,而只是知道公式的值同发生的概率呈正比而已.如果将y= θT* X中的每个x带入这个公式,得到如下函数求得所有的时间发生概率最大就是求得所有的事件概率密度函数结果的乘积最大,则得到:求得最大时W的值,则总结出了所有事件符合的规律.求解过程如下(这里记住,我们求得的是什么情况下函数的值最大,并不是求得函数的解):公式中,m为样本的个数,π和σ为常数,不影响表达式的大小.所以去掉所有的常数项得到公式:因为得到的公式是一个常数减去这个公式,所以求得概率密度函数的最大值就是求得这个公式的最小值.这个公式是一个数的平方,在我国数学资料中把他叫做最小二乘公式.所以多元线性回归的本质就是最小二乘.J(w)′=2(Y?Xw)TXJ(w)^{#x27;}=2(Y-Xtextbf{w})^TXJ(w)′=2(Y?Xw )TXSystem.out.print("("+xy[0]+",");X为自变量向量或矩阵,X维度为N,为了能和W0对应,X需要在第一行插入一个全是1的列。
线性回归损失函数推导-最大似然
线性回归作为一种监督学习方法,在机器学习领域中属于最基本的优化问题,即根据现有的数据集,找到一个能够最好拟合这组数据的线性函数即可,根据这个线性函数对新来的数据进行预测。
本文将会覆盖最简单的线性回归的解释和标准方程求解最优线性回归参数,至于梯度下降法求解,会有单独的另外一篇博客介绍。
什么是回归分析
显而易见,线性回归就是一种回归分析,那么什么是回归分析呢?
简单的说,就是找到一条能够最好的代表所有数据的函数,这个函数可以是线性的,当然也可以是非线性的。
而通常情况下数据集并不会是严格的能够使用一条函数代表,所以就会需要我们引入误差的概念,就是说最小化这个误差就行了,通常使用的方法有:最小二乘法、最大似然估计法等,后面我们会介绍到,对于线性回归来说这两种方法其实是等价的。
最小二乘法:又称为最小平方法,就是把所有误差的平方相加,获得的值为总误差,最小化这个误差就是优化目标。
什么是线性回归(Linear Regression)
线性回归就是上面提到的,能够代表现有数据集的函数是线性的,如下图所示:
上图中的红色点就表示二维空间的数据集,而蓝色的线就是我们要求解的线性函数。
对于一个线性函数,我们通常的表示方法是:
f(x)=wxb
其中w和b都是常量参数,推广到多维空间,该表示方法同样适用:f(x1,x2?xn)=w1x1w2x2?wnxnb=[x1,x2?xn]?w1w2?wn?b
为了统一参数,我们可以为x维度加上一个1,为w维度增加上一个b,这样线性函数就统一成了:
f(x1,x2?xn)=[x1,x2?xn,1]?w1w2?wnb?=x′w′
使用标准方程法求解
有了线性回归的函数表示,我们的目标自然是获得w的最优值了,根据这个最优值就可以对新来的数据进行预测了。
那么如何获得最优的w呢?我们这里可以使用最小二乘法,误差函数为:
L(w)=∑i(wxi?yi)2
最小化线性误差:
minwL(w)=minw∑i(wxi?yi)2
要获得该函数的最小值,只需要对其求w的导数,并令导数为0即可:
dL(w)dw=?L(w)?w1?L(w)?w2?L(w)?wn?=2∑ixixTiw?2∑ixiyi=0
即求L(w)关于w的各个维度的偏导数,然后求和即可。
为了表示方便,我们假设有n个样本,这些样本的属性集合,以及他们的结果值的集合分别为:
X=?x1x2?xn?,Y=?y1y2?yn?
即上面的导数可以重新写为:
dL(w)dw=2∑ixixTiw?2∑ixiyi=2XTXw?2XTY=0
由于矩阵的逆与原矩阵相乘为1,所以上式求解可得:
w?=(XTX)?1XTY
w?即为我们要求的最优值了。
第一个问题
有了上面的求解w*公式,我们只需要遍历所有训练数据集,将数据读出来后进行矩阵运算即可。
也正因为如此,第一个问题来了,假如我们的数据维度特别高,那么这种矩阵运算是十分耗费时间的,即便使用一些如分治法的策略,也只能很有限的降低计算复杂度。
所以标准方程的方式,只适合于数据量和数据维度不是非常大的情况,否则更建议使用梯度下降法进行计算,关于梯度下降法,后面我会再写一篇文章专门介绍。
第二个问题
不可逆怎么办,这个问题比较关键,为了解决这个问题,研究者为求解w*的函数引入了对角矩阵作为参数来保证
XTX可逆,即原求解公式变为:
w?=(XTXλI)?1XTY
其中λI为形如下列格式的单位对角矩阵:
λ?1000010000100001?
这种方法求出的w*一定是最优的。
那么,引入这么一个参数,必然要有其具体的函数意义,比如高斯分
不中引入噪声、SVM中引入松弛变量,那么这里的
λI表示什么含义呢。
概率解释
标准方程获得的结果可以从很多个角度来解释其意义,我们可以选择从概率的角度来看(但这个式子并非是从概率论推出来的,具体如何来的笔者也暂不知道……只是前辈告诉我就是突然出现这么一个式子比较合理,从各个角度都能解释的通)。
我们这里从三个不同的角度来看待线性回归的参数估计问题,他们分别是:最大似然估计、贝叶斯估计和最大后验估计。
一)最大似然估计
最大似然估计比较简单,它假定要估计的模型参数w虽然是未知的,但应该当确定值,然后找到符合对数似然最大分布的参数值。
首先,我们假设线性模型为:
其中δ是线性样本上的噪声数据,我们假设噪声符合高斯分布,即ε∼N(0,δ2)
在确定w和x的情况下,我们可以看到y与ε分布相同,也就是说对于每一个数据点:
p(yi|xi;w)=p(ε)=12π?√δexp(?ε22δ2)
由于ε=y?wx,所以:
p(yi|xi;w)=12π?√δexp(?(yi?wxi)22δ2)
对于所有的样本X,以及他们所有的预测结果Y有:
P(Y|X;w)=∏p(yi|xi;w)
最大化这个概率,求出w就是我们的目标,为了方便计算,我们把上式的连乘转换为负对数最大似然求极小值问题,把p值代入即可得:
L(w)=?∑ilog(p(yi|xi;w))=12δ2∑i(yi?wxi)2C
由于δ、C都是常数,所以最小化这个L(w)与最小二乘法的结果一样。
现在我们知道了为什么标准方程中使用差平方的和是合理的,而不是使用其他的误差计算方式。
二)贝叶斯最大后验估计
贝叶斯估计的特点是,假设已知样本处于分布D上(如高斯分布),根据已有样本计算在分布D上概率最大的参数w。
给定X、Y推导w的贝叶斯后验概率:
p(w|X,Y)=p(w,Y|X)p(Y|X)
由于贝叶斯的特点就是假设样本分布于D上,所以我们这里假设该分布为高斯分布,那么参数w在该分布上的概率为w|X∼N(0,γ2),即:p(w|X)=1γ2π?√exp(?w22γ2)
则,贝叶斯后验概率可以转换为:
p(w|Y,X)=p(w,Y|X)p(Y|X)=p(Y|w,X)p(w|X)∫p(Y|w,X)p(w|X)dw
根据贝叶斯定理和条件概率的基本性质(维基百科),我们可以把上市做一些转换,因为我们已经预先假设了p(w|X),所以要转换结果有它。
最大化p(w|Y,X)可以表示为:
maxwp(w|Y,X)=maxwp(w,Y|X)p(Y|X)=p(Y|w,X)p(w|X)p(Y|X)
由于p(Y|X)为常数,所以上式等价于maxwp(Y|w,X)p(w|X)
最小化其负对数后验概率:
minw?log(p(Y|w,X)p(w|X))=minw?log(p(Y|w,X))?log(p(w|X))
=?∑log(p(yi|w,xi))?log(p(w|X))
=1δ2∑(yi?wxi)21γ2w2
如果我们令λ=δ2γ2,则上式等价于:
minw∑(yi?wxi)2λw2
令其全导数为零,则最优解为:
w?=(XTXλI)?12XTY
我们发现贝叶斯最大后验概率与标准方程形式相同,从概率的角度是有意义的。
λI
的含义,其中I是单位对角矩阵,
一个简单的线性回归,里面涉及的知识还是很深的,不时回头回顾总能发现新的东西,学无止境啊。
当所有事情发生的概率为最大时,我们认为总结出的函数最符合这些事件的实际规律.所以我们把总结这些点的分布规律问题转变为了求得P(x1,x2 . xn)= P(x1) * P(x2) . P(xn)的发生概率最大.
对数似然: 对数似然相对于似然函数的有点在于运算方便。
似然函数求取的方法是迭乘, 数字较大时会很不方便;对数似然求取的方法是迭加。
(相比于似然函数而言, 对数似然较为实用)
params = gradient_descent(X, y)
1.左分配率:A(B+C)=AB+ACA(B+C) = AB+ACA(B+C)=AB+AC;右分配率:(B+C)A=BA+CA(B+C)A = BA + CA(B+C)A=BA+CA
(wTXTXw)w=(wTAw)w,①=?wT?wAw+?(Aw)T?ww,②=?wT?wAw+?(wTAT)?ww,③=(A+AT)w=2Aw=2ATw,
线性回归的目标就是要找到一个最合适的模型来使得预测的准确度最大化。
此时就需要找到最合适的wtextbf{w}w来使模型的到的预测值尽可能的接近真实值yyy。
我们这里从三个不同的角度来看待线性回归的参数估计问题,他们分别是:最大似然估计、贝叶斯估计和最大后验估计。
但实际上,有一点我必须要澄清,虽然上面的代码只有几行,非常方便,但是在实际使用线性回归的场景当中,我们并不会直接通过公式来计算(theta),而是会使用其他的方法迭代来优化。
Ux = attr(XScale, "scaled:center")
return np.loadtxt(filePath, delimiter=contentDelimiter, usecols=contentCols,。