一种基于动机倾向的标签推荐方法_靳延安
- 格式:pdf
- 大小:387.05 KB
- 文档页数:6


一种改进的层次聚类算法
靳延安;刘行军
【期刊名称】《武汉理工大学学报(信息与管理工程版)》
【年(卷),期】2011(033)006
【摘要】针对凝聚式的层次聚类算法在聚类过程中层次化的迭代运算使误差不断累积,导致聚类结果较差的问题,在GN快速算法基础上提出了一种改进的凝聚式层次聚类算法,即网状聚类算法.实验结果表明,该改进算法避免了误差的积累,可以获得更高质量的聚类结果.
【总页数】5页(P883-886,912)
【作者】靳延安;刘行军
【作者单位】湖北经济学院信息管理学院,湖北武汉430205;湖北经济学院信息管理学院,湖北武汉430205
【正文语种】中文
【中图分类】TP391
【相关文献】
1.一种改进的短文本层次聚类算法 [J], 李天彩;席耀一;王波;张佳明
2.FCM聚类算法与改进层次聚类算法的结合 [J], 陈亚平;吴陈
3.一种改进的模糊层次聚类算法 [J], 周维柏;黄德波;李蓉
4.一种改进的层次聚类算法在面包品质检验中的应用 [J], 张红梅;丁伟;范艳峰
5.一种模糊加权的改进层次聚类算法研究 [J], 李剑英;丁世飞;徐丽;钱钧
因版权原因,仅展示原文概要,查看原文内容请购买。

申请新增学士学位授权专业简况表学校名称(代码)湖北经济学院法商学院(13251)(公章)学科门类(代码)工商管理类(1102)专业名称(代码)电子商务(110209W)批准时间2003年湖北省学位委员会办公室2012年3月9 日填填表说明一、表内各项目要求提供原始材料备查。
二、“专任教师”是指具有教师资格、专门从事教学工作的人员,分三个部分组成:独立学院自有教师,聘期在两年(含)以上的;母体学校委派,能达到独立学院专任教师年工作量且聘期连续两年(含)以上的;聘期不足两年,达到专任教师年工作量的外聘教师按50%计入;聘期不足一年的不计专任教师。
三、符合岗位资格是指主讲教师具有讲师及以上(含讲师)职称或具有硕士及以上学位,通过岗前培训并取得合格证、高等教育教师资格证书的教师。
四、折合在校生数=普通本、专科生数+预科生数+成人脱产班学生数。
五、生师比=折合在校生数/教师总数(教师总数=专任教师数+聘期不足两年的外聘教师数×0.5)。
六、专任教师中具有研究生学位的比例=(具有研究生学位专任教师数/专任教师数) ×100%。
七、专任教师中具有高级职称的比例=具有副高级以上职务的专任教师数/专任教师数。
八、生均四项经费=四项经费/折合在校生数,四项经费包括本科业务费、教学差旅费、体育维持费、教学仪器设备维修费。
各项经费的具体内容为:本专科生业务费:包括专业建设、课程建设、教材建设等费用,进行实验、实习、毕业设计(论文)所需的各种原材料,低值易耗品及加工、运杂费,生产实习费,答辩费,资料讲义印刷费及学生讲义差价支出等。
教学差旅费:教师进行教学调查、资料搜集、教材编审调研等业务活动的市内交通费、误餐费、外地差旅费。
体育维持费:各种低值体育器械和运动服装的购置费、修理费,体育运动会费用,支付场地租金和参加校际以上运动会的教职工运动员的伙食补助费,以及公共体育教研室的业务性报刊、杂志、资料等零星费用。




一种基于用户标签网络的个性化推荐方法
毛进;易明;操玉杰;沈劲枝
【期刊名称】《情报学报》
【年(卷),期】2012(031)001
【摘要】基于标签进行个性化推荐是目前的一个研究热点,不同的推荐算法对标签进行了不同的处理.用户使用的标签之间存在着某种内在联系,由此可构建用户标签网络.根据这一启示,本文提出了一种基于用户标签网络的个性化推荐算法.首先,将用户标签网络视为用户兴趣模型雏形,利用社会网络分析方法计算标签权重,并以加权标签集的形式表示用户兴趣模型,最后将标签权重转化为资源与用户兴趣的相似度,进而实现个性化推荐.实验表明,本方法能较为准确地揭示用户的兴趣,产生的推荐资源与用户兴趣匹配程度较高.
【总页数】7页(P24-30)
【作者】毛进;易明;操玉杰;沈劲枝
【作者单位】华中师范大学信息管理系,武汉,430079;华中师范大学信息管理系,武汉,430079;华中师范大学信息管理系,武汉,430079;华中师范大学信息管理系,武汉,430079
【正文语种】中文
【相关文献】
1.基于标签聚类与用户模型的个性化推荐方法研究 [J], 刘如娟
2.一种基于用户标签的社交网络好友推荐算法 [J], 汪强;何广达;杨安桔;张臣坤
3.基于社会化标签和历史价格曲线的网络结构个性化推荐方法 [J], 凌霄娥
4.一种综合 LBS 和社会网络标签的个性化推荐方法 [J], 陈平华;何婕;梁琼
5.一种用于网络用户行为聚类的标签自动生成方法 [J], 毕猛;邵中;徐剑
因版权原因,仅展示原文概要,查看原文内容请购买。
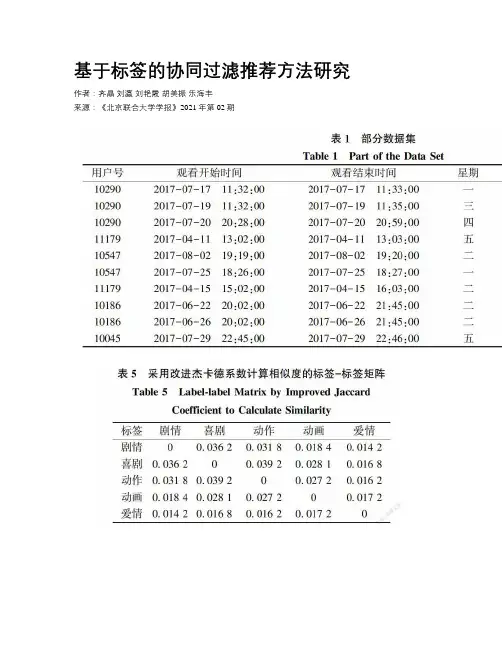
基于标签的协同过滤推荐方法研究作者:齐晶刘瀛刘艳霞胡美振乐海丰来源:《北京联合大学学报》2021年第02期[摘要] 摘要傳统基于物品的协同过滤算法由于物品相似度矩阵稀疏,推荐准确率不高。
针对这一问题,提出一种基于标签和改进杰卡德系数的协同过滤算法,进行电视节目个性化推荐。
首先,爬取相关信息对原始数据进行扩充,并利用统计学方法对时间特征进行归一化处理,计算用户偏好系数;然后,统计出现次数较高的类别作为推荐类别标签,并利用改进的杰卡德系数构造标签相似度矩阵;最后,根据推荐类别标签的用户偏好系数计算节目的推荐系数。
实验结果表明,基于标签的协同过滤算法可以降低稀疏矩阵对推荐准确率的影响,相比基于物品的协同过滤算法,准确率提高了5%,召回率提高了3.1%。
另外,使用改进的杰卡德系数计算相似度,减少了热门标签对推荐系统的影响,进一步将准确率提高了5%,召回率提高了2.3%。
[关键词] 关键词协同过滤;标签类别相似度;个性化推荐;惩罚系数;杰卡德系数[中图分类号] 中图分类号TP 391.3[文献标志码] A[文章编号] 1005-0310(2021)02-0047-06Research on Collaborative Filtering Recommendation Method Based onLabelsQi Jing1,Liu Ying2,Liu Yanxia2,Hu Meizhen2,Le Haifeng3(1. Tourism College, Beijing Union University, Beijing 100101, China; 2. College of Urban Rail Transit and Logistics, Beijing Union University, Beijing 100101, China; 3. College of Robotics, Beijing Union University, Beijing 100101, China)Abstract:摘要In the era of big data, traditional itembased collaborative filtering algorithms lead to the sparseness of item similarity matrix, and the recommendation accuracy rate is not high. To solve this problem, a labelbased collaborative filtering algorithm is proposed. First, this algorithm expands the original data by crawling the relevant information, and uses statistical methods to normalize the time characteristics to calculate the user preference coefficient. Next, it selects those with higher occurrences from all crawled categories as recommended category labels. The category constructs a label similarity matrix using the improved Jaccard coefficients that incorporate the penalty coefficients. Finally, the program recommendation coefficients are calculated according to the user preference coefficients of the recommended category labels. The experimental results show that thelabelbasedcollaborativefiltering algorithm can reduce the influence of sparse matrix on the recommendation accuracy. Compared with theitembased collaborative filtering algorithm,the accuracy rate increases by 5% and the recall rate increases by 3.1%. In addition, using the improved Jaccard coefficient to calculate the similarity can reduce the influence of hot tags on therecommendation system, and further improve the accuracy rate by 5% and the recall rate by 2.3% on the labelbased collaborative filtering algorithm.Keywords:关键词Collaborative filtering; Label category similarity; Personalized recommendation; Penalty coefficient; Jaccard coefficient0 引言北京联合大学学报2021年4月第35卷第2期齐晶等:基于标签的协同过滤推荐方法研究随着电视“互联网+”和电子商务的兴起,个性化推荐有了突飞猛进的发展,相关研究主要集中在推荐算法和推荐应用,不同类型的物品使用不同的推荐算法来达到既定的目的[1]。


![一种基于动态交互注意力机制的序列推荐方法及其系统[发明专利]](https://uimg.taocdn.com/6a4cce8c783e0912a3162a48.webp)
专利名称:一种基于动态交互注意力机制的序列推荐方法及其系统
专利类型:发明专利
发明人:蔡飞,陈洪辉,刘俊先,罗爱民,舒振,陈涛,罗雪山
申请号:CN201910533753.1
申请日:20190619
公开号:CN110245299A
公开日:
20190917
专利内容由知识产权出版社提供
摘要:本发明提出了一种基于动态交互注意力机制的序列推荐方法,包括获取用户的初始短期偏好和初始长期偏好;根据交互式注意力网络结合初始短期偏好和初始长期偏好得到长期偏好和短期偏好;根据序列推荐模型结合长期偏好和短期偏好对相应物品进行打分并根据打分结果为用户推荐物品。
本发明构建的用于顺序推荐(DCN‑SR)的动态交互注意力机制网络模型,通过该模型能够学习用户长期和短期交互的共同依赖表示,并结合长期偏好和短期偏好,使推荐结果更加准确。
申请人:中国人民解放军国防科技大学
地址:410003 湖南省长沙市开福区砚瓦池
国籍:CN
代理机构:北京风雅颂专利代理有限公司
代理人:马骁
更多信息请下载全文后查看。
一种基于显著兴趣点的图像检索方法程涛;侯榆青;李明俐;常哲【摘要】提出一种利用显著兴趣点结合颜色矩和距离直方图进行图像检索的方法.该方法将兴趣点作为图像中用户关注的主要视觉线索,包括显著兴趣点检测、距离直方图和颜色矩的特征提取3个步骤,既利用兴趣点的局部颜色特征,又考虑兴趣点间的空间距离关系,克服了传统颜色矩没有空间位置信息的缺陷.实验结果表明,该方法实现简单,能够有效提高图像检索的效率.【期刊名称】《计算机工程》【年(卷),期】2010(036)018【总页数】3页(P171-173)【关键词】显著兴趣点;局部颜色特征;距离直方图;颜色矩【作者】程涛;侯榆青;李明俐;常哲【作者单位】西北大学信息科学与技术学院,西安,710127;西北大学信息科学与技术学院,西安,710127;西北大学信息科学与技术学院,西安,710127;西北大学信息科学与技术学院,西安,710127【正文语种】中文【中图分类】TP3911 概述兴趣点是图像中灰度值在X方向和Y方向都有很大变化的一类特殊点,是一种非常有用的图像底层特征,已经有学者利用兴趣点在大型图像数据库中检索图像[1-2]。
这些方法一般将传统的兴趣点检测算法与匹配算法直接应用于图像检索中,但未与图像检索的特点相结合,因此,检索的效率并不高。
从认知心理学的角度看,在一幅图像中,兴趣点通常都处于视觉关注的重要部位,而这些重要部位通常蕴含丰富的颜色、纹理、空间位置关系等细节信息[3]。
基于上述思想,本文提出一种基于显著兴趣点颜色及距离直方图的图像检索方法:充分利用兴趣点这一重要的视觉特征,将兴趣点作为视觉关注的重要线索,将局部颜色特征与全局距离直方图特征有机结合进行图像检索。
2 兴趣点检测兴趣点的检测算法有很多,如Harris算法、Freeman-Davis算法、Sankar-sharma算法[4]。
本文采用Kitchen和Rosenfeld的算子[5]检测兴趣点,兴趣点测度值如式(1)所示:其中,I表示图像的灰度值; xI、 yI分别是I在X和Y方向上的一阶导数; xxI、yyI、 xyI分别为I的二阶导数。
一种基于社会信任潜在因子模型的推荐方法
邢星;张维石;贾志淳
【期刊名称】《计算机科学》
【年(卷),期】2014(041)001
【摘要】随着社交网络的快速发展、社交网络用户规模的不断扩大,如何为用户推荐感兴趣的信息变得越发困难.传统的推荐方法利用用户兴趣的历史数据来预测用户未来感兴趣的项目,忽视了社交网络中的信任关系,导致推荐方法的推荐质量不高.针对上述问题,提出了基于社会信任潜在因子模型的推荐方法.该方法引入社会信任来度量社交网络中朋友之间的隐含信任关系,根据社会信任程度来选择用户信任的朋友,对用户信任的朋友与目标用户的共同兴趣进行潜在因子分析,构建基于社会信任的潜在因子模型,实现目标用户的前k个项目推荐.真实数据集上的对比实验结果表明,基于社会信任潜在因子模型的推荐方法在推荐质量上优于现有的推荐方法.【总页数】6页(P163-167,191)
【作者】邢星;张维石;贾志淳
【作者单位】渤海大学信息科学与技术学院锦州121013;大连海事大学信息科学技术学院大连116026;渤海大学信息科学与技术学院锦州121013
【正文语种】中文
【中图分类】TP311
【相关文献】
1.一种基于潜在类别模型的新闻推荐方法 [J], 文鹏;蔡瑞;吴黎兵
2.基于潜在因子模型的跨领域信息推荐算法 [J], 高升;任思婷;郭军
3.URTP:一种基于用户-区域-时间-商品的因子分解推荐模型 [J], 胡亚慧;杨莎;刘晶;余伟;李石君;王俊;方其庆
4.基于潜在因子算法的课程推荐系统研究 [J], 徐江红;赵婉芳;赵静雅
5.基于PMF进行潜在特征因子分解的标签推荐∗ [J], 刘胜宗;樊晓平;廖志芳;吴言凤
因版权原因,仅展示原文概要,查看原文内容请购买。