一种改进的MEP决策树剪枝算法
- 格式:doc
- 大小:1.77 MB
- 文档页数:11

决策树模型的剪枝方法及实践技巧决策树是一种经典的机器学习算法,它通过一系列的决策节点来对数据进行分类或者回归预测。
然而,决策树模型往往会出现过拟合的问题,因此需要进行剪枝来降低模型的复杂度,提高泛化能力。
本文将介绍决策树模型的剪枝方法及实践技巧,帮助读者更好地理解和应用决策树模型。
1. 决策树模型剪枝方法决策树模型的剪枝方法主要包括预剪枝和后剪枝两种方式。
预剪枝是在决策树构建过程中,在每个节点分裂前,先对分裂后的子树进行评估,如果分裂后无法提升模型的泛化能力,就停止分裂。
这样可以避免过拟合,提高模型的泛化能力。
后剪枝是在决策树构建完成后,对已有的决策树进行修剪。
具体方法是通过交叉验证等技术,对每个节点进行剪枝,从而降低模型的复杂度,提高泛化能力。
2. 决策树模型剪枝实践技巧在实际应用中,对决策树模型进行剪枝需要注意以下几点技巧。
首先,选择合适的评估指标。
在预剪枝中,需要选择合适的评估指标来衡量分裂后模型的泛化能力,常用的评估指标包括信息增益、基尼指数等。
在后剪枝中,可以通过交叉验证等技术来选择合适的剪枝节点。
其次,合理设置剪枝参数。
在实践中,需要根据具体问题合理设置剪枝参数,以达到最佳的泛化能力。
这需要结合实际应用场景和数据特点来进行调参,需要一定的经验和技巧。
最后,进行模型评估和验证。
在进行剪枝之后,需要对剪枝后的模型进行评估和验证,以确保模型的泛化能力得到提升。
可以通过交叉验证、留出法等技术来对模型进行评估,选择最佳的剪枝策略。
3. 决策树模型剪枝的应用案例在实际应用中,决策树模型的剪枝技巧被广泛应用于各个领域。
以金融领域为例,决策树模型可以用来进行信用评分、风险控制等工作。
通过合理的剪枝方法,可以提高模型的准确性和稳定性,帮助金融机构更好地进行风险管理。
另外,在医疗领域,决策树模型也被广泛应用于疾病诊断、药物治疗等方面。
通过剪枝方法,可以提高模型的泛化能力,提高诊断准确性,为医生提供更好的辅助决策。

用遗传算法改进的BP神经网络剪枝算法来优化决策树模型武彤;程辉
【期刊名称】《计算机科学》
【年(卷),期】2013(040)0z2
【摘要】决策树是一种有效的分类方法,但在构建决策树模型的过程中,常常会出现模型过度拟合的现象.利用基于BP神经网络的决策树剪枝算法(BP-Pruning)进行软剪枝处理,然后根据BP-Pruning的一些不足,提出一种改进算法,简称GBP-Pruning算法.该算法通过引入遗传算法来训练BP-Pruning算法模型中的权值和阈值,从而克服了BP-Pruning算法上的不足,最后验证了GBP-Pruning算法的可行性.
【总页数】4页(P278-280,295)
【作者】武彤;程辉
【作者单位】贵州大学计算机科学与信息学院贵阳550025;贵州大学计算机科学与信息学院贵阳550025
【正文语种】中文
【中图分类】TP39
【相关文献】
1.基于改进相关性剪枝算法的BP神经网络的结构优化 [J], 宋清昆;郝敏
2.基于遗传算法改进的BP神经网络房价预测分析 [J], 李春生;李霄野;张可佳
3.基于遗传算法改进BP神经网络的风电功率预测研究 [J], 王冰冰; 赵天乐
4.基于自适应遗传算法改进的BP神经网络卡钻事故预测 [J], 刘海龙;李彤;张奇志
5.基于遗传模拟退火算法改进BP神经网络的中长期电力负荷预测 [J], 徐扬;张紫涛
因版权原因,仅展示原文概要,查看原文内容请购买。

2023年度决策树方法使用中的改进策略随着机器学习技术的不断发展,决策树方法已成为一个常用的算法模型,用于问题分类、预测、回归等领域。
然而,决策树模型也有一些缺陷和不足之处,需要进一步的改进。
本文将探讨决策树方法使用中的改进策略,旨在提高决策树方法的性能和效率。
一、改进决策树的准确性1. 增加训练集数据量决策树模型的正确性直接受训练数据的质量和数量影响。
为了提高决策树方法的准确性,需要增加训练集数据量。
在收集训练样本时,应尽可能地覆盖所有情况,避免数据偏差。
同时,在样本量较少时,可以使用交叉验证和Bootstrap等技术来收集更多的数据。
2. 剪枝方法决策树的过拟合问题是常见的问题。
为了解决这个问题,需要采取剪枝方法。
剪枝有两种方法:预剪枝和后剪枝。
预剪枝是在建立决策树的过程中就剪去分支。
后剪枝是在决策树建立完成后,对树进行剪枝。
预剪枝可以防止过拟合,但是会影响决策树的准确性。
后剪枝保留了更多的决策路径,可以提高模型的准确性。
3. 特征选择特征选择是指如何选择最能刻画变量区别的特征。
在构建决策树时,特征选择是关键的一步。
使用错误率或基尼不纯度等指数来比较不同特征的重要性,然后选择具有最大信息熵的特征进行划分。
同一个特征可能存在多种划分方法,特征选择的目的是找到最优的划分方法,从而提高分类的准确性。
二、改进决策树的效率1. 建立随机森林随机森林是一种基于决策树的集成学习方法,可以提高决策树的效率和准确性。
随机森林包含多个决策树,每个树对数据进行分类,最终结果由所有树的结果加和算出。
随机森林可以降低单个决策树的过拟合风险,同时避免了由于数据选取不当导致的偏差。
2. 优化算法决策树的建模过程是非常耗时的,因为需要计算每个特征的信息增益以及决策树的每个节点。
为了提高效率,可以使用优化算法。
一种是贪心算法,该算法在每个节点选择特征时都选择最优特征。
另一种是回溯算法,该算法在建立决策树时遍历所有可能的节点。

决策树模型的剪枝方法及实践技巧决策树是一种用于分类和回归的监督学习算法,其模型具有可解释性强、计算复杂度低等优点,在实际应用中得到了广泛的应用。
然而,决策树模型在训练时容易出现过拟合的问题,为了提高模型的泛化能力,剪枝方法被提出。
本文将介绍决策树模型的剪枝方法及实践技巧。
一、决策树模型的剪枝方法(1)预剪枝预剪枝是在决策树构建过程中,在节点划分前进行剪枝。
其核心思想是在节点划分时,根据一定的准则决定是否进行划分。
预剪枝方法有很多种,如信息增益、信息增益比、基尼指数等。
以信息增益为例,它是根据划分前后的信息增益大小来决定是否进行划分,当信息增益小于一定阈值时,停止划分。
预剪枝方法简单直观,但容易出现欠拟合的问题。
(2)后剪枝后剪枝是在决策树构建完成后,对已生成的树进行剪枝。
其核心思想是通过对节点的子树进行剪枝,去掉对模型泛化能力影响不大的节点。
后剪枝方法有很多种,如代价复杂度剪枝、悲观剪枝等。
以代价复杂度剪枝为例,它是通过引入惩罚项来对树进行剪枝,当加入惩罚项后,选择代价最小的子树作为最终的决策树。
后剪枝方法相对于预剪枝方法,更加灵活,能够有效避免欠拟合的问题。
二、决策树模型的剪枝实践技巧(1)交叉验证在决策树模型的剪枝过程中,为了找到最优的剪枝参数,可以采用交叉验证的方法。
交叉验证通过将数据集分成训练集和验证集,多次重复训练和验证的过程,以此来评估不同剪枝参数下模型的性能。
通过交叉验证,可以选择最优的剪枝参数,从而提高模型的泛化能力。
(2)特征选择在决策树模型的剪枝过程中,选择合适的特征对模型的性能起着关键作用。
特征选择可以通过信息增益、信息增益比、基尼指数等方法来进行。
在剪枝过程中,可以通过特征选择来减少决策树的复杂度,提高模型的泛化能力。
(3)模型评估在决策树模型的剪枝过程中,模型评估是非常重要的一环。
在剪枝后的模型上进行评估,可以有效地评估模型的泛化能力。
常见的模型评估方法包括准确率、精确率、召回率等。

决策树的优化-剪枝优化剪枝(pruning)的⽬的是为了避免决策树模型的过拟合。
因为决策树算法在学习的过程中为了尽可能的正确的分类训练样本,不停地对结点进⾏划分,因此这会导致整棵树的分⽀过多,也就导致了过拟合。
决策树的剪枝策略最基本的有两种:预剪枝(pre-pruning)和后剪枝(post-pruning):预剪枝(pre-pruning):预剪枝就是在构造决策树的过程中,先对每个结点在划分前进⾏估计,若果当前结点的划分不能带来决策树模型泛化性能的提升,则不对当前结点进⾏划分并且将当前结点标记为叶结点。
后剪枝(post-pruning):后剪枝就是先把整颗决策树构造完毕,然后⾃底向上的对⾮叶结点进⾏考察,若将该结点对应的⼦树换为叶结点能够带来泛化性能的提升,则把该⼦树替换为叶结点。
⼀、预剪枝(pre-pruning)关于预剪枝(pre-pruning)的基本概念,在前⾯已经介绍过了,下⾯就直接举个例⼦来看看预剪枝(pre-pruning)是怎样操作的。
数据集为(图⽚来⾃西⽠书):这个数据集根据信息增益可以构造出⼀颗未剪枝的决策树(图⽚来⾃西⽠书):下⾯来看下具体的构造过程:前⾯博客()讲过⽤信息增益怎么构造决策树,这边还是⽤信息增益构造决策树,先来计算出所有特征的信息增益值:因为⾊泽和脐部的信息增益值最⼤,所以从这两个中随机挑选⼀个,这⾥选择脐部来对数据集进⾏划分,这会产⽣三个分⽀,如下图所⽰:但是因为是预剪枝,所以要判断是否应该进⾏这个划分,判断的标准就是看划分前后的泛华性能是否有提升,也就是如果划分后泛化性能有提升,则划分;否则,不划分。
下⾯来看看是否要⽤脐部进⾏划分,划分前:所有样本都在根节点,把该结点标记为叶结点,其类别标记为训练集中样本数量最多的类别,因此标记为好⽠,然后⽤验证集对其性能评估,可以看出样本{4,5,8}被正确分类,其他被错误分类,因此精度为43.9%。
划分后:划分后的的决策树为:则验证集在这颗决策树上的精度为:5/7 = 71.4% > 42.9%。

基于决策树算法的改进与应用基于决策树算法的改进与应用一、引言决策树算法是一种常用的机器学习算法,广泛应用于数据挖掘、模式识别、智能推荐等领域。
其简单直观的特性使得决策树算法成为人工智能领域的热门研究方向之一。
然而,传统的决策树算法在一些问题上存在不足,例如容易过拟合、难以处理连续型属性等。
本文将介绍基于决策树算法的改进方法以及其在实际应用中的案例。
二、改进方法1. 剪枝方法传统决策树算法容易过拟合,剪枝方法是一种常用的改进策略。
剪枝方法通过减少决策树的深度和宽度,降低模型复杂度,从而提高泛化能力。
常用的剪枝方法包括预剪枝和后剪枝。
预剪枝在决策树构建过程中进行剪枝操作,根据一定的剪枝准则判断是否继续划分子节点;后剪枝则先构建完整的决策树,再根据相应的剪枝准则进行剪枝操作。
剪枝方法可以有效地改善传统决策树算法的过拟合问题,提高模型的泛化性能。
2. 连续属性处理传统决策树算法难以处理连续型属性,常用的处理方法是二分法和离散化。
二分法通过将连续属性划分为两个离散的取值范围,从而将连续属性转化为离散属性。
离散化方法则将连续属性划分为若干个离散的取值,例如等宽法、等频法等。
这样,连续属性就可以像离散属性一样进行处理,便于在决策树算法中应用。
三、应用案例1. 土壤质量评估土壤质量评估是农业生产和环境保护的重要问题之一。
传统的土壤质量评估方法繁琐且耗时,难以适应大规模的数据分析需求。
基于决策树算法的改进方法可以有效地解决这个问题。
在改进的决策树算法中,可以采用剪枝方法减少决策树的深度,从而提高模型的泛化性能。
另外,通过对连续属性进行离散化处理,可以更好地利用土壤质量监测数据进行决策树构建和评估。
实践证明,基于决策树算法的土壤质量评估方法能够快速、准确地判断土壤质量状况。
2. 金融风险评估金融风险评估是银行和金融机构的核心业务之一。
传统的金融风险评估方法主要基于统计分析和经验法则,存在模型复杂度高、计算量大的问题。
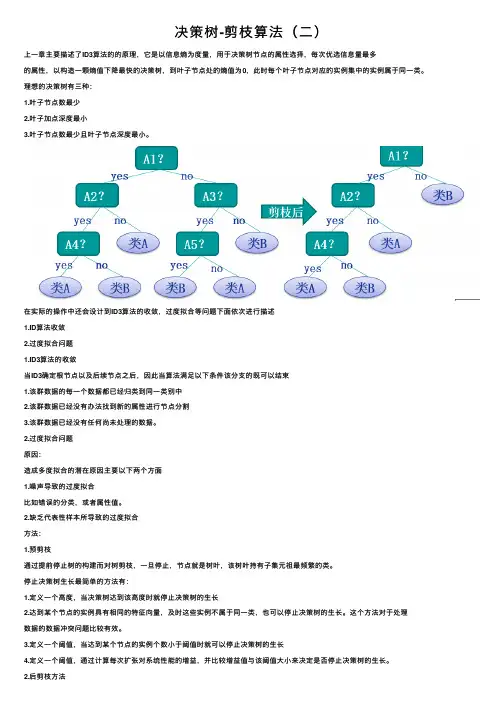
决策树-剪枝算法(⼆)上⼀章主要描述了ID3算法的的原理,它是以信息熵为度量,⽤于决策树节点的属性选择,每次优选信息量最多的属性,以构造⼀颗熵值下降最快的决策树,到叶⼦节点处的熵值为0,此时每个叶⼦节点对应的实例集中的实例属于同⼀类。
理想的决策树有三种:1.叶⼦节点数最少2.叶⼦加点深度最⼩3.叶⼦节点数最少且叶⼦节点深度最⼩。
在实际的操作中还会设计到ID3算法的收敛,过度拟合等问题下⾯依次进⾏描述1.ID算法收敛2.过度拟合问题1.ID3算法的收敛当ID3确定根节点以及后续节点之后,因此当算法满⾜以下条件该分⽀的既可以结束1.该群数据的每⼀个数据都已经归类到同⼀类别中2.该群数据已经没有办法找到新的属性进⾏节点分割3.该群数据已经没有任何尚未处理的数据。
2.过度拟合问题原因:造成多度拟合的潜在原因主要以下两个⽅⾯1.噪声导致的过度拟合⽐如错误的分类,或者属性值。
2.缺乏代表性样本所导致的过度拟合⽅法:1.预剪枝通过提前停⽌树的构建⽽对树剪枝,⼀旦停⽌,节点就是树叶,该树叶持有⼦集元祖最频繁的类。
停⽌决策树⽣长最简单的⽅法有:1.定义⼀个⾼度,当决策树达到该⾼度时就停⽌决策树的⽣长2.达到某个节点的实例具有相同的特征向量,及时这些实例不属于同⼀类,也可以停⽌决策树的⽣长。
这个⽅法对于处理数据的数据冲突问题⽐较有效。
3.定义⼀个阈值,当达到某个节点的实例个数⼩于阈值时就可以停⽌决策树的⽣长4.定义⼀个阈值,通过计算每次扩张对系统性能的增益,并⽐较增益值与该阈值⼤⼩来决定是否停⽌决策树的⽣长。
2.后剪枝⽅法后剪枝(postpruning):它⾸先构造完整的决策树,允许树过度拟合训练数据,然后对那些置信度不够的结点⼦树⽤叶⼦结点来代替,该叶⼦的类标号⽤该结点⼦树中最频繁的类标记。
相⽐于先剪枝,这种⽅法更常⽤,正是因为在先剪枝⽅法中精确地估计何时停⽌树增长很困难。
以上可以理解为后剪枝的基本思想,其中后剪枝⽅法主要有以下⼏个⽅法:Reduced-Error Pruning(REP,错误率降低剪枝)Pesimistic-Error Pruning(PEP,悲观错误剪枝)Cost-Complexity Pruning(CCP,代价复杂度剪枝)EBP(Error-Based Pruning)(基于错误的剪枝)以下分别进⾏说明:1.REPREP⽅法是⼀种⽐较简单的后剪枝的⽅法,在该⽅法中,可⽤的数据被分成两个样例集合:⼀个训练集⽤来形成学习到的决策树,⼀个分离的验证集⽤来评估这个决策树在后续数据上的精度,确切地说是⽤来评估修剪这个决策树的影响。

Micr ocomputer Applica tions V ol.27,No.5,2011技术交流微型电脑应用2011年第27卷第5期6文章编号:1007-757X(2011)05-0062-03一种改进决策树剪枝算法的研究吕伟忠摘要:决策树归纳方法的剪枝过程是为了消除最终生成的决策树对训练集的过度适应以及减少结点的数量,但最终生成的决策树依然过于庞大。
而有些应用对于决策树的精度要求不是很高。
通过对剪枝过程加以优化,使得在牺牲少量精度的同时结点的数量大大减少,从而提高生成规则的可理解性。
关键词:决策树;剪枝;MDL ;分类器;预测精度;C4.5中图分类号:TP18文献标识码:A0引言数据挖掘[1]作为一种发现大量数据中潜在知识的数据分析方法和技术,已经成为各界关注的热点。
其中决策树[2][3]以其出色的数据分析效率、直观易懂等特点倍受青睐。
其核心思想是先把整个数据库作为树的根结点,利用信息论中的信息增益寻找数据库中具有最大信息量的属性作为结点分裂依据,而后根据属性的不同取值进行分裂、建立分枝,并在每个子结点中重复该操作,直到生成一棵完整的决策树。
但由于噪声和孤立点的存在,许多分枝反映的是训练集中的异常。
剪枝方法可以处理这种过分适应数据问题。
MDL (最小描述长度)[4]方法是由Mehtam M 等人在1995年提出的一种决策树剪枝方法,其核心思想是将构造的决策树中所包含的信息量以二进制编码的形式表示,利用编码的长度代表决策树某一分枝的误分类率的大小,进而决定剪枝与否。
而剪枝后的决策树可能依然包含成百上千个结点,生成的规则相当复杂,难以理解。
而在某些实际应用中,用户对分类精度要求不是很高,对细节不作关注,只需要获得数据大概的轮廓。
因此,能够牺牲少量的精度换取一颗简单许多的决策树显得非常有吸引力。
部分专家已对此作出验证,如Bohanec andBratko [5]已经用实验证明:决策树结点数量减少将近一半,对精度的损失不到0.5%。

决策树方法使用中的改进策略决策树方法是一种有效的机器学习算法,可以用于分类和回归问题。
它可以生成一棵分类树来描述一些关键特征和它们与目标变量之间的关系。
对于一个新数据点,可以通过一系列的特征判断最终属于哪个类别。
但是,决策树方法也有一些局限性和缺陷。
针对这些问题,可以采用一些改进策略来提高决策树方法的性能和效果。
一、剪枝算法决策树方法容易出现过拟合问题,即训练数据集上的错误率较低,但是在测试数据集上的错误率较高。
这是因为决策树过于复杂,在训练数据集上学习到了过多无用的特征,导致模型泛化能力不足。
为了解决这个问题,可以采用剪枝算法来优化决策树。
剪枝算法是通过直接去掉一些不必要的子树或者将其缩减成单个节点的方法来降低决策树的复杂度。
这样可以提高模型的泛化能力,降低过拟合的风险。
常见的剪枝算法有预剪枝和后剪枝两种方法。
预剪枝是在生成树的过程中,先对每个节点进行测试,如果发现没有改善分类效果,就剪去该子树。
后剪枝是在决策树生成完毕后,对已有的决策树进行剪枝。
具体实现方式有多种,例如代价复杂度剪枝、错误率降低剪枝等。
二、连续与离散变量的处理决策树方法一般只适用于离散型特征,对于连续型特征需要进行离散化处理。
一种方法是二分法,将连续型特征划分为二元属性。
另一种方法是多元划分法,将连续型特征划分为多个区间,每个区间对应一个离散属性值。
这样一来,连续型特征也可以加入到决策树模型中。
三、缺失值的处理在实际数据处理中,经常会遇到因为种种原因导致特征值缺失的情况。
如何处理缺失值对于决策树的构建和分类结果都有很大的影响。
一种方法是采用多数表决法,即选择该特征下样本中数量最多的分类作为缺失值的分类。
另一种方法是采用概率模型,根据样本中其他特征的值来推断缺失值。
还有一些特殊的方法,如均方差代替缺失值等。
四、处理类别约束决策树模型中多分类变量不能很好地表示,只能使用二元分裂器分解问题,因此通常使用独热编码将多分类问题转化为二元分类问题。

决策树剪枝算法决策树是一种常用的分类和回归算法,在机器学习领域具有广泛的应用。
然而,构建一个过于复杂的决策树容易导致过拟合,使得模型在训练集上表现很好,但在测试集上的泛化能力较差。
为了解决这个问题,需要使用剪枝算法。
本文将介绍决策树剪枝算法及其原理和步骤。
一、决策树剪枝算法概述决策树剪枝算法旨在通过减少决策树的复杂度,提高其泛化能力。
通常,剪枝是通过去除决策树的一些子树或叶节点来实现的,以达到简化模型结构的目的。
决策树剪枝算法可分为预剪枝和后剪枝两种。
1. 预剪枝预剪枝是在构建决策树的过程中,在每次划分节点时,首先计算划分后的验证集误差,如果划分后的误差没有显著改善,就停止划分并将当前节点标记为叶子节点,不再继续生长子树。
这种方法避免了过分生长决策树,有效地控制了模型的复杂度。
2. 后剪枝后剪枝是在决策树构建完成后,对已生成的决策树进行修剪的过程。
具体步骤是从底部向上递归地对非叶子节点进行考察,每次考察一个节点,判断如果将其替换为叶子节点后,整个决策树的泛化能力是否提高。
如果提高,则进行剪枝操作,将该节点替换为叶子节点。
这一过程不断重复,直到无法再剪枝为止。
二、决策树剪枝算法详解以下将详细介绍决策树剪枝算法的具体步骤。
1. 划分数据集首先,将数据集划分为训练集和验证集,训练集用于构建决策树,验证集用于评估模型的泛化能力。
2. 构建决策树使用训练集构建完整的决策树,可以采用各种常见的决策树算法,如ID3、C4.5或CART等。
3. 叶子节点替换从决策树的叶子节点开始,逐个将叶子节点替换为其对应的父节点,并计算替换后决策树在验证集上的误差。
4. 进行剪枝操作如果替换后的决策树在验证集上的误差小于替换前的误差,则进行剪枝操作,将节点替换为叶子节点。
5. 重复剪枝操作不断重复步骤3和步骤4,直到无法再进行剪枝为止。
三、决策树剪枝算法的优缺点决策树剪枝算法有以下优点:1. 有效地减少了决策树的复杂度,提高了模型的泛化能力。

决策树算法改进案例一、背景决策树算法是一种常用的机器学习算法,广泛应用于分类和回归问题。
然而,在实际应用中,决策树算法存在一些问题,如过拟合、欠拟合等。
为了提高决策树算法的性能,我们需要对算法进行改进。
决策树模型对某些特征的敏感度过高,导致模型对某些样本的分类结果不稳定。
2. 决策树模型对某些样本的分类结果过于简单或复杂,导致模型对数据的解释性不强。
3. 决策树模型在训练过程中出现过拟合现象,导致模型在测试集上的性能不佳。
三、改进方案针对上述问题,我们提出以下改进方案:1. 使用特征选择方法,如信息增益、互信息等,选择对分类有重要影响的特征,减少对无关特征的敏感度。
2. 使用集成学习方法,如随机森林、梯度提升决策树等,增加模型的泛化能力,减少过拟合现象。
3. 对决策树算法进行剪枝,减少不必要的分支,提高模型的复杂度。
四、实现过程以下是使用Python和scikit-learn库实现改进方案的代码示例:1. 导入所需的库和数据集:from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.feature_selection import SelectKBest, chi2from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressorfrom sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifierfrom sklearn.metrics import accuracy_score, classification_report iris = load_iris()X = iris.datay = iris.targetX_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.2, random_state=42)2. 使用特征选择方法:from sklearn.feature_selection import SelectKBest, chi2k = 5 # 选择前5个最重要的特征selector = SelectKBest(chi2, k=k)X_train = selector.fit_transform(X_train, y_train)X_test = selector.transform(X_test)3. 使用集成学习方法:clf = GradientBoostingClassifier(n_estimators=100, max_depth=1, learning_rate=0.1)clf.fit(X_train, y_train)y_pred = clf.predict(X_test)accuracy = accuracy_score(y_test, y_pred)print("Accuracy:", accuracy)4. 对决策树算法进行剪枝:clf = DecisionTreeRegressor(max_depth=1)clf.fit(X_train, y_train)y_pred = clf.predict(X_test)print("Accuracy after pruning:", accuracy)五、实验结果与分析通过上述改进方案,我们得到了以下实验结果:* 特征选择方法可以有效地减少决策树对无关特征的敏感度,提高模型的稳定性。
决策树算法的剪枝过程好嘞,咱们今天聊聊决策树算法的剪枝过程,这个话题听起来可能有点儿复杂,但咱们就轻松点儿说,绝对不会让你打瞌睡。
想象一下,决策树就像一个老爷爷,满头白发,满口故事。
他把所有的经历都给记录在树上,每一根枝条都代表着一个选择。
比如说,今天咱们吃什么?一根枝条可能指向“米饭”,另一根可能指向“面条”。
这爷爷真是个话痨,讲得细致入微,直到你觉得都快饱了。
不过,问题来了,讲得太多,反而让人迷糊了。
咱们知道,选择太多可不是好事,听得让人脑壳疼,最后可能连“吃什么”都忘了。
这时候,就得想办法给这棵树“剪剪枝”了。
剪枝就像给头发修个发型,修得好看又清爽。
其实就是把那些不必要的细枝末节去掉,让树看起来更清晰、更简洁。
决策树剪枝分为两种:预剪枝和后剪枝。
预剪枝就像你在去理发店前就决定好只剪一点点,给人留下个好印象。
你一开始就决定只在特定条件下继续分裂,不然就停下。
这样做的好处就是避免树长得太复杂,没事儿还省得浪费时间。
后剪枝呢?就好比你已经剪完头发,发现没啥造型可言,哎呀,怎么那么丑。
于是,你就找个发型师给你重新修整。
后剪枝是在树构建完成后,再去掉那些表现不佳的分支,留下最有用的部分。
这样做的结果就是,你最终得到一棵既好看又实用的树,听着是不是舒服多了?剪枝的好处可多着呢!一方面,剪枝能减少过拟合,过拟合就像是你在一堆泡泡糖里越陷越深,结果根本分不清哪里是树,哪里是糖。
另一方,剪枝还能提高模型的泛化能力,意思就是说,剪得漂亮,面对新数据时也能表现得像个老手,绝对不会被难倒。
想想看,生活中不就是这么回事嘛,不能总是贪多嚼不烂,偶尔还得回头看看,究竟哪些才是最有价值的东西。
剪枝的过程还带点儿人情味。
每一次选择都是一种放弃,每一次放弃都是为了让自己更专注。
人生不也如此?我们都在做选择,剪去那些多余的杂念,把精力放在最重要的事上。
想想你每天的生活,看看那些让你分心的东西,咱们得学会适时放手,才能迎接更美好的明天。
基于决策树算法的改进与应用基于决策树算法的改进与应用一、引言决策树算法作为一种常用的机器学习算法,可用于解决分类和回归问题,具有较强的灵活性和可解释性。
本文旨在探讨基于决策树算法的改进方法,并介绍其在不同领域的应用。
二、决策树算法的原理与问题决策树算法通过将样本空间划分为相互无重叠的子空间,以实现对数据进行分类或回归预测。
然而,传统的决策树算法存在一些问题,包括容易过拟合、对数据特征变化敏感、处理高维数据困难等。
三、决策树算法的改进方法为了解决决策树算法的问题,研究者们提出了一系列改进方法。
1. 随机森林算法(Random Forest)随机森林算法将多个决策树组合在一起,通过集成学习的方式进行预测。
它采用了自助采样和特征随机选择的方法,降低了模型的方差和过拟合风险。
2. 提升算法(Boosting)提升算法通过迭代训练多个弱分类器,并将它们加权组合成强分类器。
具体而言,AdaBoost算法和Gradient Boosting算法是两种常见的提升算法,它们通过调整样本权重或残差进行模型更新,提高了分类性能。
3. 剪枝策略剪枝策略旨在防止决策树过拟合,提高模型的泛化能力。
常见的剪枝方法有预剪枝和后剪枝两种。
预剪枝通过设置停止条件,在构建过程中减少分支节点的数量,防止模型过于复杂。
后剪枝是在构建完整个决策树后,通过剪枝操作进行修剪,去掉对预测性能影响不大的节点和分支。
四、基于决策树算法的应用案例基于改进后的决策树算法,我们可以在不同领域中应用它来解决实际问题。
1. 医疗领域在医疗领域,我们可以利用决策树算法对患者的病情进行分类预测。
通过收集患者的症状和疾病信息,构建决策树模型,根据患者的特征属性进行分类,并对疾病进行诊断和治疗建议。
2. 金融领域在金融领域,决策树算法可以用于信用评分、欺诈检测等任务。
通过分析用户的个人信息、财务状况和历史行为等特征,构建决策树模型,对用户进行信用评估,以辅助金融机构的风险管理和决策。
决策树代价复杂度剪枝算法介绍(全)转自 KPMG大数据挖掘决策树算法是数据挖掘中一种非常常用的算法,它不仅可以直接对个体进行分类,还可以预测出每个观测属于某一类别的可能性,因变量可以是二分变量,也可以有多种取值,因此该方法兼备了判别分析、二元logistic模型和多元logistic模型的功能。
由于这些特点,决策树算法还常被用作基分类器来进行集成学习,比如随机森林算法就是基于CART构建起来的。
决策树也可根据节点分裂规则不同而进行细分,比如CART、ID3和C4.5等。
首先,对应用比较广泛的CART算法中的代价复杂度剪枝进行理论探讨1. 为什么要剪枝?CART(classification and regression trees)实际上包括了两部分的内容,第一部分涉及因变量是离散变量的分类模型,也就是所谓的分类树;第二部分涉及了因变量是连续变量的回归模型,即回归树。
但第二部分内容在实际数据挖掘项目中应用的比较少,因此这里我们只介绍分类树的剪枝算法。
决策树建模属于有监督算法,因变量属于离散变量,而自变量可以是连续变量或离散变量。
一般来讲,只要决策树充分地生长,就可以将训练样本中的所有个体进行完美的分类,即每个终节点里面个体的因变量取值都是一样的。
但是我们都知道,现实世界中的数据总会存在不同程度的噪音,比如数据的错误、偶然以及冗余信息等,如果让模型完美拟合训练数据,实际应用时我们会受到噪音的误导。
因为这些噪音并不是真实的规律,将模型应用于验证数据时,模型的精度会出现大幅度的下降,即所谓的过拟合现象(overfitting)。
过拟合是很多机器学习算法中都必须考虑的问题,举一个例子,读中学的时候迫于考试压力,有的同学采取题海战术,甚至把题目背下来,但是一到考试,他就考得很差,因为考试时出现的题目与平时相比肯定经过了一些变化,他非常复杂地记住了每道题的做法,但却没有提炼出通用的、规律性的东西。
相反,背英语作文框架的同学往往会取得较高的分数,因为这些框架是通用的,是规律性的东西。
基于改进的决策树算法的气象灾害预警技术研究近年来,随着气候变化的不断加剧,各种气象灾害频发。
而如何及时准确地预警这些灾害,成为了当前急需解决的问题之一。
因此,在这个背景下,人们开始利用各种技术手段,来对气象灾害进行预警。
其中,决策树算法是一种基于数据挖掘的常用算法之一。
其可以对大量数据进行分析处理,从而找出其中的规律和关联性,进而实现决策预测。
而在气象灾害预警方面,经过对决策树算法的改进和优化,我们可以更好地实现对气象灾害的准确预警和及时预防。
下面,我们将进一步阐述这方面的技术研究成果。
一、改进决策树算法的重要性决策树的基本原理是将数据集反复分割成小的子集,直到每个子集都只包含一个类别,也可以说是同一类型的数据。
这样生成的树状结构可以依照和上层节点相同的方式来判断样本属于哪个类别。
然而,标准的决策树算法有时会产生一些错误分类的情况,例如:过拟合、欠拟合等。
因此,我们需要对其进行改进,以更好地适用于气象灾害预警这一领域。
二、改进方法之一:剪枝策略为了避免标准决策树算法中产生的过拟合问题,我们可以通过剪枝策略来解决。
具体而言,即基于某些指标和约束条件,通过将某些节点去掉从而产生较简单的树状结构,以实现更好的泛化能力。
这种剪枝策略可以分为预剪枝和后剪枝两种方式。
其中,预剪枝即在生成决策树时就对其进行裁剪;后剪枝则是先生成一个完整的决策树,再通过剪枝策略对其进行优化。
而这两种方式都可以有效地减小决策树的复杂度,从而提高其准确性和泛化能力,实现更好的气象灾害预警效果。
三、改进方法之二:增加属性选择度量指标另一种改进决策树算法的方法是增加属性选择度量指标。
这些指标通常是用来评估每个属性的信息熵、信息增益或基尼指数等信息量,从而决定是否选取该属性作为划分的标准。
在气象灾害预警中,我们可以根据不同的气象要素和灾害类型,选择合适的选择度量指标,以更好地决定将哪些属性作为判断规则,进而对预警信息进行过滤和调整。
四、应用案例:基于改进决策树算法的气象灾害预警示例通过前述改进方法,我们可以完善决策树算法,从而实现更好的气象灾害预警效果。