外文翻译--关于数据库死锁的知识
- 格式:doc
- 大小:40.00 KB
- 文档页数:6

mysql死锁的原因和处理方法MySQL死锁的原因和处理方法。
MySQL作为一种常用的关系型数据库管理系统,在数据处理过程中可能会出现死锁的情况。
死锁是指两个或多个事务在执行过程中,因争夺资源而造成的互相等待的现象,导致它们都无法继续执行下去。
本文将就MySQL死锁的原因和处理方法进行详细介绍。
一、死锁的原因。
1. 事务并发执行。
在MySQL中,多个事务同时对相同的数据进行读写操作时,就有可能发生死锁。
这是因为每个事务在执行过程中会锁定所涉及的数据,当多个事务之间出现循环等待的情况时,就会导致死锁的发生。
2. 锁的粒度过大。
如果在事务中对数据进行操作时,锁的粒度过大,即锁定了过多的数据,就会增加死锁的概率。
因为锁的粒度过大会导致不同的事务之间争夺同一把锁,从而增加了死锁的可能性。
3. 事务持有锁的时间过长。
当事务持有锁的时间过长时,就会增加其他事务发生死锁的可能。
因为其他事务需要等待较长的时间才能获取到所需的锁,从而增加了死锁的风险。
二、死锁的处理方法。
1. 设置合理的事务隔离级别。
在MySQL中,可以通过设置合理的事务隔离级别来减少死锁的发生。
通过设置较低的隔禅级别,可以减少事务对数据的锁定,从而降低死锁的概率。
2. 优化数据库索引。
通过优化数据库索引,可以减少事务对数据的锁定时间,从而降低死锁的风险。
合理的索引设计可以减少数据的扫描次数,提高数据的访问效率,从而减少死锁的可能性。
3. 控制事务的大小和时长。
在编写程序时,应尽量控制事务的大小和持有锁的时间,避免长时间的锁定操作。
可以将大的事务拆分成多个小的事务,并尽量减少事务的持有时间,从而降低死锁的概率。
4. 监控和处理死锁。
在MySQL中,可以通过设置死锁检测和处理机制来监控和处理死锁。
当发生死锁时,可以通过自动或手动的方式来解除死锁,从而保证数据库的正常运行。
结语。
通过以上介绍,我们可以看到MySQL死锁的原因和处理方法。
在实际应用中,我们应该充分理解死锁的原因,采取合理的措施来预防和处理死锁,从而保证数据库系统的稳定和可靠运行。

5分钟快速了解数据库死锁产⽣的场景和解决⽅法前⾔加锁(Locking)是数据库在并发访问时保证数据⼀致性和完整性的主要机制。
任何事务都需要获得相应对象上的锁才能访问数据,读取数据的事务通常只需要获得读锁(共享锁),修改数据的事务需要获得写锁(排他锁)。
当两个事务互相之间需要等待对⽅释放获得的资源时,如果系统不进⾏⼲预则会⼀直等待下去,也就是进⼊了死锁(deadlock)状态。
以下内容适⽤于各种常见的数据库管理系统,包括 Oracle、MySQL、Microsoft SQL Server 以及 PostgreSQL等。
死锁是如何产⽣的?演⽰死锁的产⽣⾮常简单,我们只需要创建⼀个包含两⾏数据的简单⽰例表:CREATE TABLE t_lock(id int PRIMARY KEY, col int);INSERT INTO t_lock VALUES (1, 100);INSERT INTO t_lock VALUES (2, 200);SELECT * FROM t_lock;id|col|--+---+1|100|2|200|如果我们在不同事务中以不同的顺序修改数据,就可能引起事务之间的相互等待。
⼀个事务等待另⼀个事务释放资源不会产⽣什么问题,但是如果两个事务互相等待对⽅的资源,数据库管理系统只有两个选择:⽆限等待或者中⽌⼀个事务并让另⼀个事务成功执⾏。
显然⽆限等待不是解决问题的⽅法,因此数据库通常是等待⼀定时间之后中⽌其中⼀个事务。
以下是⼀个死锁的演⽰案例:事务⼀事务⼆备注BEGIN;BEGIN;分别开始两个事务UPDATE t_lock SET col = col + 100 WHERE id = 1;UPDATE t_lockSET col = col + 200WHERE id = 2;事务⼀修改 id=1 的数据,事务⼆修改 id=2 的数据UPDATE t_lockSET col = col + 100WHERE id = 2;事务⼀修改 id=2 的数据,需要等待事务⼆释放写锁等待中…UPDATE t_lockSET col = col + 200WHERE id = 1;事务⼆修改 id=1 的数据,需要等待事务⼀释放写锁死锁死锁数据库检测到死锁,选择中⽌⼀个事务更新成功返回错误对于 MySQL InnoDB,默认启⽤了 innodb_deadlock_detect 选项,事务⼆返回以下错误信息:ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction如果我们禁⽤ InnoDB 死锁检测选项,事务⼆在等待 50 s(innodb_lock_wait_timeout )后提⽰等待超时:ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transactionOracle 检测到死锁时返回以下错误:ORA-00060: 等待资源时检测到死锁Microsoft SQL Server 检测到死锁时返回的错误如下消息 1205,级别 13,状态 51,第 7 ⾏事务(进程 ID 67)与另⼀个进程被死锁在锁资源上,并且已被选作死锁牺牲品。



数据库死锁解决方案介绍在多用户系统中,数据库死锁是一个常见的问题。
当两个或多个事务同时请求访问共享资源时,这些事务可能会相互等待对方释放资源,导致死锁的发生。
本文将介绍数据库死锁的概念、原因以及解决方案。
数据库死锁的概念数据库死锁是指两个或多个事务因互相等待对方释放资源而无法继续执行的状态。
具体来说,当一个事务请求占用了一个资源的排他锁(X锁),而另一个事务请求占用了同一个资源的共享锁(S锁),就可能发生死锁。
数据库死锁的原因数据库死锁通常是由以下几个原因引起的:1.事务并发执行:在多用户系统中,多个事务可以同时执行。
如果这些事务同时操作相同的数据,就可能导致死锁。
2.锁竞争:当多个事务同时请求对同一个资源的锁时,就会发生锁竞争。
如果这些事务同时请求对方已经持有的锁,就可能导致死锁。
3.持有和等待:一个事务在等待其他事务释放资源时,仍然持有自己占用的资源,这就可能导致死锁。
4.循环等待:当多个事务之间存在循环依赖关系时,就可能发生循环等待,从而导致死锁。
数据库死锁解决方案在面对数据库死锁问题时,我们可以采取以下几种解决方案:1. 死锁检测和回滚数据库系统可以通过死锁检测算法检测死锁的发生。
一旦检测到死锁,系统可以选择回滚其中一个事务来解除死锁。
回滚操作会取消该事务已经执行的操作,使得其他事务可以继续执行。
2. 超时设置和重试数据库系统可以为每个事务设置超时时间。
当一个事务等待时间超过设定的超时时间时,系统可以选择终止该事务,释放其占用的资源,并重新执行该事务。
这种方法可以减少死锁的持续时间,提高系统的可用性。
3. 锁粒度优化锁粒度是指对数据进行锁定的程度。
如果锁粒度过大,会导致并发性能下降。
反之,如果锁粒度过小,会增加死锁的风险。
因此,通过调整锁粒度来优化锁管理是减少死锁的一种有效方法。
可以通过采用行级锁或表级锁来平衡并发性能和死锁风险。
4. 事务隔离级别设置数据库事务的隔离级别决定了资源锁定的方式。

数据库锁机制与死锁处理技巧总结数据库锁机制和死锁处理技巧总结数据库是存储和管理数据的重要工具,而锁机制是一种保证数据一致性和并发性的关键技术。
在多个用户同时访问数据库时,可能会导致死锁的出现,因此,适当的死锁处理技巧也是非常重要的。
本文将对数据库锁机制和死锁处理技巧进行总结。
1. 数据库锁机制1.1 共享锁共享锁(Shared Lock)是一种保证并发性的锁机制,多个用户可以同时获取共享锁,用于读取操作。
共享锁不会阻塞其他用户的共享锁获取请求,但会阻塞独占锁的获取请求。
1.2 独占锁独占锁(Exclusive Lock)是一种用于保证数据一致性的锁机制,只有一个用户能够获取独占锁,用于写操作。
独占锁会阻塞其他用户的共享锁和独占锁获取请求。
1.3 行级锁行级锁(Row-Level Locks)是一种对数据库表中的行进行锁定的机制,可以在并发访问时提高性能。
行级锁只会锁定所需的行,而不是整个表,从而减少了数据库锁冲突和死锁的可能性。
1.4 锁粒度锁粒度决定了锁的范围,从而影响了并发性和锁冲突的可能性。
通常有三种锁粒度:- 表级锁(Table-Level Locks):锁定整个表,在高并发环境下性能较差。
- 页面级锁(Page-Level Locks):锁定数据库表的页面,在某些情况下性能较好。
- 行级锁(Row-Level Locks):锁定表中的行,可以提高并发性能,但可能增加锁冲突的可能性。
2. 死锁处理技巧2.1 死锁的概念死锁指的是两个或多个进程在互相等待对方占用的资源,从而导致进程之间无法继续进行的情况。
当多个进程竞争有限的资源时,死锁可能发生。
2.2 死锁的预防预防死锁是一种在设计数据库时考虑并发控制的重要方法。
以下是一些预防死锁的技巧:- 保持锁的有序性:按照统一的顺序获取和释放锁,避免循环等待。
- 减少锁持有时间:尽量缩短持有锁的时间,从而减少死锁的可能性。
- 使用超时机制:设定锁的超时时间,超过一定时间后自动释放锁。

死锁产⽣条件以及预防和处理算法 ⼀、死锁的概念 在多道程序系统中,虽可借助于多个进程的并发执⾏,来改善系统的资源利⽤率,提⾼系统的吞吐量,但可能发⽣⼀种危险━━死锁。
所谓死锁(Deadlock),是指多个进程在运⾏中因争夺资源⽽造成的⼀种僵局(Deadly_Embrace),当进程处于这种僵持状态时,若⽆外⼒作⽤,它们都将⽆法再向前推进。
⼀组进程中,每个进程都⽆限等待被该组进程中另⼀进程所占有的资源,因⽽永远⽆法得到的资源,这种现象称为进程死锁,这⼀组进程就称为死锁进程。
⼆、死锁产⽣的原因 产⽣死锁的原因主要是: (1)因为系统资源不⾜。
(2)进程运⾏推进的顺序不合适。
(3)资源分配不当等。
如果系统资源充⾜,进程的资源请求都能够得到满⾜,死锁出现的可能性就很低,否则就会因争夺有限的资源⽽陷⼊死锁。
其次,进程运⾏推进顺序与速度不同,也可能产⽣死锁。
产⽣死锁的四个必要条件: (1)互斥条件:⼀个资源每次只能被⼀个进程使⽤。
(2)请求与保持条件:⼀个进程因请求资源⽽阻塞时,对已获得的资源保持不放。
(3)⾮抢占:进程已获得的资源,在末使⽤完之前,不能强⾏抢占。
(4)循环等待条件:若⼲进程之间形成⼀种头尾相接的循环等待资源关系。
三、死锁处理⽅法: (1)可使⽤协议以预防或者避免死锁,确保系统不会进⼊死锁状态; (2)可允许系统进⼊死锁状态,然后检测他,并加以恢复; (3)可忽视这个问题,认为死锁不可能发⽣在系统内部。
四、死锁预防 1、互斥:对于⾮共享资源,必须要有互斥条件; 2、占有并等待: 为了确保占有并等待条件不会出现在系统中,必须保证:当⼀个进程申请⼀个资源时,它不能占有其他资源。
⼀种可以使⽤的协议是每个进程在执⾏前申请并获得所有资源,可以实现通过要求申请资源的系统调⽤在所有的其他系统调⽤之前执⾏。
3、⾮抢占: 为了确保第三个条件不成⽴,可以使⽤如下协议:如果⼀个进程占有资源并申请另⼀个不能⽴即分配的资源,那么其现已分配资源都可被抢占; 4、循环等待: 为了确保循环等待条件不成⽴,⼀种可⾏的算法是:对所有资源进程排序,且要求每个进程按照递增顺序来申请进程。

死锁(ora-00060)以及死锁相关的知识点最近碰到一个死锁的问题:ora-00060 deadlock detected while waiting for resource (ora-00060 等待资源时检测到死锁)查看udump(SQL> show parameter USER_DUMP_DEST; 查看该目录)下面的trace,发现如下日志:*** 2009-08-13 10:53:11.656*** SERVICE NAME:(his3) 2009-08-13 10:53:11.593*** SESSION ID:(130.3437) 2009-08-13 10:53:11.593DEADLOCK DETECTED[Transaction Deadlock]Current SQL statement for this session:UPDATE MY_KUCUN1 SET KUCUNSL = KUCUNSL - :B3 WHERE YINGYONGID = :B2 AND JIAGEID = :B1----- PL/SQL Call Stack -----object line objecthandle number name33DF6A44 6002 package body HIS3KS.PKG_MY_JINXIAOCUN2FD11B48 1 anonymous blockThe following deadlock is not an ORACLE error. It is adeadlock due to user error in the design of an applicationor from issuing incorrect ad-hoc SQL. The followinginformation may aid in determining the deadlock:Deadlock graph:---------Blocker(s)-------- ---------Waiter(s)---------Resource Name process session holds waits process session holds waitsTX-000b001c-00005019 38 130 X 19 106 XTX-00010025-000100ee 19 106 X 38 130 Xsession 130: DID 0001-0026-00008297 session 106: DID 0001-0013-00004EB8 session 106: DID 0001-0013-00004EB8 session 130: DID 0001-0026-00008297 Rows waited on:Session 106: obj - rowid = 0000E1AB - AAAOGrAAXAAAJHQAAT(dictionary objn - 57771, file - 23, block - 37328, slot - 19)Session 130: obj - rowid = 0000E1AB - AAAOGrAAXAAAJHQAAZ(dictionary objn - 57771, file - 23, block - 37328, slot - 25)Information on the OTHER waiting sessions:Session 106:pid=19 serial=671 audsid=309881 user: 64/HIS3KSO/S info: user: NT AUTHORITY\ANONYMOUS LOGON, term: MEDIINFO-QA2, ospid: 6708:6612, machine: WORKGROUP\MEDIINFO-QA2program: cicsas.exeapplication name: cicsas.exe, hash value=0Current SQL Statement:UPDATE MY_KUCUN1 SET KUCUNSL = KUCUNSL - :B3 WHERE YINGYONGID = :B2 AND JIAGEID = :B1End of information on OTHER waiting sessions.================================================== =几个重要的信息就是锁的类型是X,说明是DML语句导致的行级排他锁,涉及到两个Session:130和106。

数据库事务管理中的死锁与解决方案在数据库管理系统中,事务是一组数据库操作的逻辑单位,为了保证数据的完整性和一致性,事务必须具备原子性、一致性、隔离性和持久性四个特性。
然而,在多用户并发访问数据库时,可能会出现死锁问题,即多个事务因为争夺资源而相互等待,导致系统无法继续执行。
本文将深入探讨数据库事务管理中的死锁问题,并提出一些解决方案。
一、死锁的概念与原因1. 概念:死锁是指两个或多个事务在执行过程中,因为争夺系统资源而造成的互相等待的现象,导致这些事务永远无法继续执行下去,从而陷入死循环。
2. 原因:死锁的产生主要是由于并发事务对资源的竞争造成的。
简单来说,当多个事务同时请求对方已经占有的资源时,就可能出现死锁。
二、死锁产生的条件为了产生死锁,必须满足以下四个条件,缺一不可:1. 互斥条件:一个资源同时只能被一个事务占有。
2. 请求与保持条件:一个事务占有了某个资源后,又请求其他事务占有的资源。
3. 不可剥夺条件:资源不能被强行剥夺,只能由占有者主动释放。
4. 循环等待条件:多个事务之间形成一个循环等待资源的关系。
三、常见的死锁解决方案1. 死锁检测与解除:死锁检测是指通过算法检测系统中是否存在死锁,一旦发现死锁的存在,就需要通过解除死锁来解决。
常见的死锁解除算法有:银行家算法、资源分配图算法等。
这些算法的核心思想是通过找出死锁的原因,然后选择一个牺牲者并解除其占有的资源,从而打破死锁的循环。
2. 超时机制:超时机制是指设置一个事务等待资源的时间上限,当超过这个时间上限后,系统会主动终止该事务,释放其占有的资源。
这样可以避免因为死锁而导致系统无法继续执行。
3. 死锁预防:死锁预防是通过在事务执行过程中采取一系列措施来预防死锁的发生。
常见的死锁预防措施包括:加锁顺序、资源有序分配、避免事务持有多个资源等。
通过合理规划事务的执行顺序和资源的分配,可以有效地减少死锁的产生。
4. 死锁避免:死锁避免是在事务执行之前,先进行资源分析,根据资源的需求和可用性来决定是否执行该事务,以避免可能导致死锁的事务被执行。
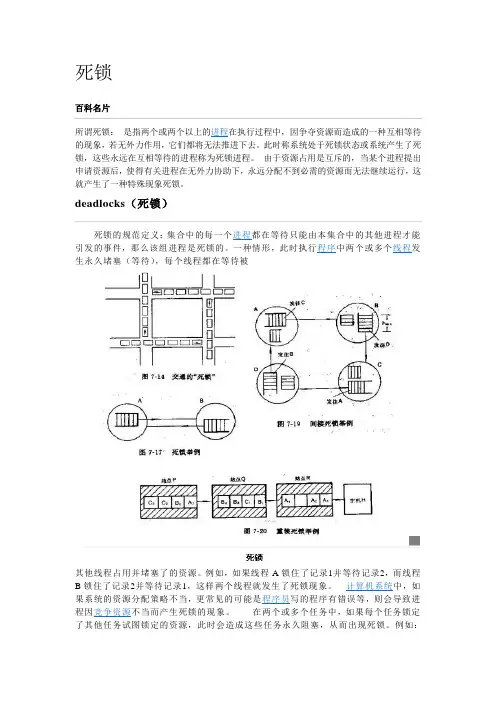
死锁百科名片所谓死锁:是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。
此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
由于资源占用是互斥的,当某个进程提出申请资源后,使得有关进程在无外力协助下,永远分配不到必需的资源而无法继续运行,这就产生了一种特殊现象死锁。
deadlocks(死锁)死锁的规范定义:集合中的每一个进程都在等待只能由本集合中的其他进程才能引发的事件,那么该组进程是死锁的。
一种情形,此时执行程序中两个或多个线程发生永久堵塞(等待),每个线程都在等待被其他线程占用并堵塞了的资源。
例如,如果线程A锁住了记录1并等待记录2,而线程B锁住了记录2并等待记录1,这样两个线程就发生了死锁现象。
计算机系统中,如果系统的资源分配策略不当,更常见的可能是程序员写的程序有错误等,则会导致进程因竞争资源不当而产生死锁的现象。
在两个或多个任务中,如果每个任务锁定了其他任务试图锁定的资源,此时会造成这些任务永久阻塞,从而出现死锁。
例如:事务A 获取了行 1 的共享锁。
事务 B 获取了行 2 的共享锁。
现在,事务 A 请求行 2 的排他锁,但在事务 B 完成并释放其对行 2 持有的共享锁之前被阻塞。
现在,事务 B 请求行 1 的排他锁,但在事务 A 完成并释放其对行 1 持有的共享锁之前被阻塞。
事务 B 完成之后事务 A 才能完成,但是事务 B 由事务 A 阻塞。
该条件也称为循环依赖关系:事务 A 依赖于事务B,事务 B 通过对事务 A 的依赖关系关闭循环。
除非某个外部进程断开死锁,否则死锁中的两个事务都将无限期等待下去。
Microsoft SQL Server 数据库引擎死锁监视器定期检查陷入死锁的任务。
如果监视器检测到循环依赖关系,将选择其中一个任务作为牺牲品,然后终止其事务并提示错误。
这样,其他任务就可以完成其事务。

【转】Deadlock的⼀些总结(死锁分析及处理)1.1.1 摘要在系统设计过程中,系统的稳定性、响应速度和读写速度⾄关重要,就像那样,当然我们可以通过提⾼系统并发能⼒来提⾼系统性能总体性能,但在并发作⽤下也会出现⼀些问题,例如死锁。
今天的博⽂将着重介绍死锁的原因和解决⽅法。
1.1.2 正⽂定义:死锁是由于并发进程只能按互斥⽅式访问临界资源等多种因素引起的,并且是⼀种与执⾏时间和速度密切相关的错误现象。
的定义:若在⼀个进程集合中,每⼀个进程都在等待⼀个永远不会发⽣的事件⽽形成⼀个永久的阻塞状态,这种阻塞状态就是死锁。
死锁产⽣的必要条件:1.互斥mutual exclusion):系统存在着临界资源;2.占有并等待(hold and wait):已经得到某些资源的进程还可以申请其他新资源;3.不可剥夺(no preemption):已经分配的资源在其宿主没有释放之前不允许被剥夺;4.循环等待(circular waiting):系统中存在多个(⼤于2个)进程形成的封闭的进程链,链中的每个进程都在等待它的下⼀个进程所占有的资源;图1死锁产⽣条件我们知道哲学家就餐问题是在计算机科学中的⼀个经典问题(并发和死锁),⽤来演⽰在并⾏计算中多线程同步(Synchronization)时产⽣的问题,其中⼀个问题就是存在死锁风险。
图2哲学家就餐问题(图⽚源于wiki)⽽对应到数据库中,当两个或多个任务中,如果每个任务锁定了其他任务试图锁定的资源,此时会造成这些任务阻塞,从⽽出现死锁;这些资源可能是:单⾏(RID,堆中的单⾏)、索引中的键(KEY,⾏锁)、页(PAG,8KB)、区结构(EXT,连续的8页)、堆或B树(HOBT) 、表(TAB,包括数据和索引)、⽂件(File,数据库⽂件)、应⽤程序专⽤资源(APP)、元数据(METADATA)、分配单元(Allocation_Unit)、整个数据库(DB)。
假设我们定义两个进程P1和P2,它们分别拥有资源R2和R1,但P1需要额外的资源R1恰好P2也需要R2资源,⽽且它们都不释放⾃⼰拥有的资源,这时资源和进程之间形成了⼀个环从⽽形成死锁。
数据库引起的死锁及死锁的定义死锁的定义: 当多个进程同时访问⼀个数据库时,其中的每个进程拥有的资源都是其他进程所需的,由此造成的每个进程都⽆法继续下去的情况。
死锁产⽣的原因:⼀般情况只发⽣锁超时,就是⼀个进程需要访问表或者字段的时候,另外⼀个程序正在执⾏带锁的访问(⽐如修改数据),那么这个进程就会等待,当等了很久锁还没有解除的话就会锁超时,报告⼀个系统错误,拒绝执⾏相应的SQL操作。
所谓死锁:是指两个或两个以上的进程在执⾏过程中,因争夺资源⽽造成的⼀种互相等待的现象,若⽆外⼒作⽤,它们都将⽆法推进下去。
此时称系统处于死锁状态或系统产⽣了死锁,这些永远在互相等待的进程称为死锁进程。
由于资源占⽤是互斥的,当某个进程提出申请资源后,使得有关进程在⽆外⼒协助下,永远分配不到必需的资源⽽⽆法继续运⾏,这就产⽣了⼀种特殊现象死锁。
⼀种情形,此时执⾏程序中两个或多个线程发⽣永久堵塞(等待),每个线程都在等待被其他线程占⽤并堵塞了的资源。
例如,如果线程A锁住了记录1并等待记录2,⽽线程B锁住了记录2并等待记录1,这样两个线程就发⽣了死锁现象。
计算机系统中,如果系统的资源分配策略不当,更常见的可能是程序员写的程序有错误等,则会导致进程因竞争资源不当⽽产⽣死锁的现象。
锁有多种实现⽅式,⽐如意向锁,共享-排他锁,锁表,树形协议,时间戳协议等等。
锁还有多种粒度,⽐如可以在表上加锁,也可以在记录上加锁。
死锁产⽣的四个必要条件:1)互斥条件:指进程对所分配到的资源进⾏排它性使⽤,即在⼀段时间内某资源只由⼀个进程占⽤。
如果此时还有其它进程请求资源,则请求者只能等待,直⾄占有资源的进程⽤毕释放。
2)请求和保持条件:指进程已经保持⾄少⼀个资源,但⼜提出了新的资源请求,⽽该资源已被其它进程占有,此时请求进程阻塞,但⼜对⾃⼰已获得的其它资源保持不放。
3)不剥夺条件:指进程已获得的资源,在未使⽤完之前,不能被剥夺,只能在使⽤完时由⾃⼰释放。
死锁问题及其解决方法一、死锁的介绍死锁(Deadlocks)通常发生在两个或多个进程(sessions)对被彼此锁住的资源发出请求的情况下。
其最常见的锁的类型为:行级锁(row-level locks)和块级锁(block-level locks)。
ORACLE会自动侦察到死锁情况,并通过回滚其中一个造成死锁的语句,从而释放其中一个锁来解决它,如上图中的C时间所示。
需要说明的,如果一个事务中的某个语句造成死锁现象,回滚的只是这个语句而不是整个事务。
二、行级死锁及其解决方法行级锁的发生如下图所示,在A时间,Transacrion1和Transction2分别锁住了它们要update的一行数据,没有任何问题。
但每个Transaction都没有终止。
接下来在B时间,它们又试图update当前正被对方Transaction锁住的行,因此双方都无法获得资源,此时就出现了死锁。
之所以称之为死锁,是因为无论每个Transaction等待多久,这种锁都不会被释放。
行级锁的死锁一般是由于应用逻辑设计的问题造成的,其解决方法是通过分析trace文件定位出造成死锁的SQL语句、被互相锁住资源的对象及其记录等信息,提供给应用开发人员进行分析,并修改特定或一系列表的更新(update)顺序。
以下举例说明出现行级死锁时如何定位问题所在。
1.环境搭建create table b (b number);insert into b values(1);insert into b values(2);commit;session1: update b set b=21 where b=2;session2: update b set b=11 where b=1;session1: update b set b=12 where b=1;session2: update b set b=22 where b=2;此时出现死锁现象。
数据库事务处理中的死锁与并发控制策略在数据库管理系统中,死锁和并发控制是关键的概念,涉及到确保多个并发事务能够同时运行而不发生冲突的问题。
本文将讨论数据库事务处理中的死锁和并发控制策略,以解决这些问题。
一、死锁的概念和原因1. 死锁的定义死锁是指两个或多个事务互相等待对方持有的资源,并导致彼此无法继续执行的情况。
如果不采取措施来解决死锁,系统将进入无限等待的状态。
2. 死锁的产生原因死锁通常由以下四个条件同时满足而产生:- 互斥条件:资源只能被一个事务占用,其他事务需要等待。
- 持有并等待条件:事务在持有一些资源的同时,还等待获取其他资源。
- 不可剥夺条件:已被一事务占用的资源不能被其他事务剥夺。
- 循环等待条件:一系列事务形成一种循环等待资源关系。
二、死锁的检测与解决策略1. 死锁的检测死锁的检测是指通过算法检测系统中是否有死锁的发生,一旦检测到死锁,系统可以采取相应的策略来解决。
常见的死锁检测算法有图论算法和资源分配图算法。
2. 死锁的解决策略- 死锁预防:通过破坏死锁产生的四个必要条件之一来预防死锁的发生。
例如,破坏持有并等待条件,要求事务在执行前一次性申请所需的全部资源。
- 死锁避免:通过事务请求资源时的动态分配,根据资源的状况决定是否分配给请求资源的事务。
常用的避免算法有银行家算法和资源分配图算法。
- 死锁检测与解除:先进行死锁检测,一旦检测到死锁的存在,通过撤销事务、资源抢占或回滚等方式解除死锁。
三、并发控制策略1. 一致性与隔离级别一致性和隔离级别是数据库中的重要概念,用于定义并发事务的行为和执行结果的可见性。
- 一致性:确保并发事务的执行结果与顺序执行结果相同。
基本原则是事务应该遵守数据库的完整性约束和业务逻辑。
- 隔离级别:定义了一种隔离的程度,用于控制并发事务间相互干扰的程度。
隔离级别从低到高分为读未提交、读提交、可重复读和串行化。
2. 并发控制技术为了确保并发执行的多个事务能够正确地访问和修改数据库,数据库管理系统中使用了多种并发控制技术。
mysql数据库死锁原因及解决办法死锁(Deadlock)所谓死锁:是指两个或两个以上的进程在执⾏过程中,因争夺资源⽽造成的⼀种互相等待的现象,若⽆外⼒作⽤,它们都将⽆法推进下去。
此时称系统处于死锁状态或系统产⽣了死锁,这些永远在互相等待的进程称为死锁进程。
由于资源占⽤是互斥的,当某个进程提出申请资源后,使得有关进程在⽆外⼒协助下,永远分配不到必需的资源⽽⽆法继续运⾏,这就产⽣了⼀种特殊现象死锁。
⼀种情形,此时执⾏程序中两个或多个线程发⽣永久堵塞(等待),每个线程都在等待被其他线程占⽤并堵塞了的资源。
例如,如果线程A锁住了记录1并等待记录2,⽽线程B锁住了记录2并等待记录1,这样两个线程就发⽣了死锁现象。
计算机系统中,如果系统的资源分配策略不当,更常见的可能是程序员写的程序有错误等,则会导致进程因竞争资源不当⽽产⽣死锁的现象。
锁有多种实现⽅式,⽐如意向锁,共享-排他锁,锁表,树形协议,时间戳协议等等。
锁还有多种粒度,⽐如可以在表上加锁,也可以在记录上加锁。
产⽣死锁的原因主要是:(1)系统资源不⾜。
(2)进程运⾏推进的顺序不合适。
(3)资源分配不当等。
如果系统资源充⾜,进程的资源请求都能够得到满⾜,死锁出现的可能性就很低,否则就会因争夺有限的资源⽽陷⼊死锁。
其次,进程运⾏推进顺序与速度不同,也可能产⽣死锁。
产⽣死锁的四个必要条件:(1)互斥条件:⼀个资源每次只能被⼀个进程使⽤。
(2)请求与保持条件:⼀个进程因请求资源⽽阻塞时,对已获得的资源保持不放。
(3)不剥夺条件:进程已获得的资源,在末使⽤完之前,不能强⾏剥夺。
(4)循环等待条件:若⼲进程之间形成⼀种头尾相接的循环等待资源关系。
这四个条件是死锁的必要条件,只要系统发⽣死锁,这些条件必然成⽴,⽽只要上述条件之⼀不满⾜,就不会发⽣死锁。
死锁的预防和解除:理解了死锁的原因,尤其是产⽣死锁的四个必要条件,就可以最⼤可能地避免、预防和解除死锁。
所以,在系统设计、进程调度等⽅⾯注意如何不让这四个必要条件成⽴,如何确定资源的合理分配算法,避免进程永久占据系统资源。
解析MySQL技术中的死锁处理方法引言数据库管理系统(DBMS)是现代软件系统中重要的一环,它负责管理和组织数据。
MySQL作为最流行的开源关系型数据库管理系统之一,具有高性能和可靠性。
然而,在高并发的场景下,数据库中的死锁问题可能会成为一个挑战。
本文将深入探讨MySQL技术中的死锁处理方法,帮助读者理解并解决这个常见的数据库问题。
一、死锁的概念和原因死锁指的是两个或多个事务相互等待对方所持有的资源,导致它们都无法继续执行的现象。
具体来说,当一个事务申请某个资源并持有该资源时,如果另一个事务也需要该资源,但已经被前一事务占用,则会发生死锁。
死锁的原因主要有两个:资源互斥和循环等待。
资源互斥表示同一时间只能有一个事务占用某个资源,而其他事务必须等待。
循环等待表示不同事务之间形成了一个环路,每个事务都在等待下一个事务所持有的资源。
二、死锁处理方法1. 避免死锁避免死锁是一种静态预防措施,在编写应用程序时就要考虑到可能的死锁情况,从而避免其发生。
下面介绍一些常用的避免死锁的方法。
(1)破坏资源互斥条件:通过合理的资源分配和组织,可以避免资源的独占,从而不会发生资源互斥的情况。
例如,可以使用共享锁代替独占锁,或者使用读写锁实现资源的多读单写。
(2)破坏循环等待条件:通过资源的有序分配,可以破坏循环等待的条件。
一种方法是引入一个全局的资源排序,事务只能按照固定的顺序来请求资源。
另一种方法是使用资源请求的层级关系,每个事务只能按照特定的顺序来请求资源。
2. 检测和解决死锁避免死锁并不是一种完全可行的方法,因为在复杂的并发环境中,很难事先考虑到所有的死锁情况。
因此,需要运行时检测死锁,并解决已经发生的死锁。
(1)死锁检测:死锁检测一般采用图论算法,将系统中的事务和资源构建成一个有向图。
如果图中存在一个环路,且环路上的所有节点都代表尚未满足的互斥资源申请,则认为发生了死锁。
可以使用深度优先搜索(DFS)或广度优先搜索(BFS)等算法来进行死锁检测。
数据库事务管理中的死锁与超时问题在数据库的事务管理过程中,死锁与超时问题是常见的挑战和难题。
处理这些问题需要深入理解数据库系统的工作原理和事务管理的机制。
本文将讨论数据库事务管理中的死锁与超时问题,并介绍有效的解决方案。
一、死锁问题1. 死锁的概念在数据库系统中,死锁是指两个或多个事务互相等待对方所持有的资源而无法继续执行的情况。
当发生死锁时,事务无法继续执行,会导致系统的停顿和资源浪费。
2. 死锁的原因死锁产生的原因主要有以下几种:- 互斥条件:事务在执行过程中需要访问独占资源,并且不能被其他事务同时访问;- 请求与保持条件:事务在获取了某个资源后,保持该资源的同时继续请求其他资源;- 不可剥夺条件:事务获得的资源不能被其他事务强制剥夺;- 循环等待条件:存在一个资源的循环链,每个事务都在等待下一个事务所持有的资源。
3. 死锁的检测与解决为了解决死锁问题,数据库系统采用以下两种方法:- 死锁检测:通过不断地扫描系统中的资源和等待队列,检测是否存在死锁情况;- 死锁解决:一旦检测到死锁,系统会采取一定的策略来解决死锁,如回滚某个事务或者剥夺某个事务所持有的资源。
在实际应用中,为了避免死锁的发生,可以采取以下策略:- 事务排序:按照一定规则给事务编号,不同的事务按照编号大小依次执行,避免资源的循环等待情况;- 超时机制:设置事务的最长执行时间,当事务执行时间超过设定的阈值时,系统会主动回滚该事务,避免长时间占用资源。
二、超时问题1. 超时的原因在数据库系统中,事务可能会因为以下原因导致超时:- 堵塞:事务无法获取所需的资源,等待队列中的其他事务持有资源过久;- 阻塞:事务等待其他事务执行后才能继续执行,若等待时间过长,也会导致超时。
2. 超时的影响超时问题会导致事务执行时间过长,增加系统的负载和响应时间。
对于在线事务处理系统来说,超时问题会降低系统的吞吐量,影响用户的体验。
3. 超时的解决方案为了解决超时问题,可以采取以下措施:- 优化数据库结构和索引:通过合理设计数据库结构和建立适当的索引,提高数据库的查询性能,减少堵塞和阻塞情况的发生;- 提高系统硬件配置:增加服务器的内存和处理能力,加快事务处理的速度,减少超时的可能性;- 调整事务隔离级别:合理设置事务的隔离级别,避免事务之间的互相干扰和阻塞;- 设置适当的超时时间:根据系统的负载和性能,设置合理的事务超时时间,避免事务执行时间过长。
外文翻译About the database of the knowledge of the deadlock Database itself provides lock management mechanism, but from a hand, database is the client applications "puppet", this is mainly because the client to the server has complete control of the gain of locks ability. The client in enquiries in the request and the way to query processing tend to have direct control, so, if we application design reasonable enough, then appear database is normal phenomenon dead lock.Below are listed some easy to have locked application examples:A, the client cancel inquires no roll back after practice.Most of the application is inquires often happens homework. However, users through the front desk the client application inquires the backend database, sometimes will cancel inquires for any variety of reasons. If the user to open the window after mouth query, because users find reflect crash or slow compelled to cancel the query. But, when the client when cancel inquires, if not add rollback transaction statement, then at this time, because the user has to the server sends the inquiry's request, so, the backend database involved in the table, all have been added L locked. So even if the user cancel after inquires, all in the affairs for the locks within will remain. At this point, if other users need to check on the table or the user to open the window through input inquires to query conditions to improve the system response speed occurs when the jam phenomenon.Second, the client not to get all the results of my query.Usually, the user will be sent to the server after queries, foreground application must be done at once extraction all the results do. If the application did not extract all the results trip, it produces a problem. For as long as the application did not withdraw promptly all the results, the lock may stay at table and block other users. Since the application has been submitted to the server will SQ statements, the application must be extracted all results do. If the application does not follow the principle words (such as because at that time and no oversight configuration), can't fundamentally solve congestion.Three, inquires the execution time too long.Some inquires a relatively long time will cost. As for the query design is not reasonable or query design to watch and record it is, will make inquires the execution time lengthen. If sometimes need to Update on users record or Delete operation, if the line is involved in it, you will get a lot of lock. These locks whether finally upgrade to watch the lock, can block other inquiries.So often, don't take long time running decision support search and online transaction processing inquires the mixed together.When database meet blocked, often need to check the application submitted to the SQL statement itself, and check and connection management, all the results do processing and other relevant application behavior. Usually, the lock for to avoid the conflict in the jam, the author has the following Suggestions.Suggest a: after the completion of the extraction of all query results do.Some applications in order to improve the response speed of the user inquires, will have the option of extraction need record. The "smart" looks very reasonable, but, but will cause more waste. Because inquires not timely and fruit extraction of words, the lock cannot be released. When others inquires the data, will be happening.So, the author suggest in application design, database query for record to the extraction of in time. Through other means, such as adding inquires the conditions, or the way backstage inquires, to improve the efficiency of the inquires. At the same time, in the application level set reasonable cache, and can also be very significantly improved query efficiency.Suggest two: in the transaction execution don't let the user input content.Although in the affairs of the process with sex, can let the user participation, in order to improve the interactivity. But, we don't recommend the database administrator tend to do so. Because if the user in affairs during the exec ution of the input and number, will extend the affairs of the execution time. Although people smarter, but the response speed still don't have a computer so fast. So, during the implementation of the user participation to let the process, will extend the a ffairs of waiting time. So unless there is a special needs, not in the application's execution process, reminds the user input parameters. Some affairs of the executive must parameters, best provide beforehand. If can through the variables in the parameters such as need to go in.Suggest three: make affairs as far as possible the brief.The author thinks that, database administrator should put some problem is simplified. When a need to many SQL statements to complete, might as well take the task decomposition. At the same time, it breaks down into some brief business affairs.If the database a product information table, its record number two million. Now in a management needs, the one-time change one of the one million five hundred thousand record. If through a change affairs, the time is long. If it involves cascade update it, is time the meeting is longer.In view of this situation, we can learn affairs brief words. If the product information, may have a product type field. So in the update data, can we not one-time updates. But through the product category fields to control, to record the iteration points. So every category of update firm consumption of time may be greatly reduces. So although operation, will need more steps. But, can effectively avoid to go to the occurrence of congestion, and improve the performance of the database. Suggest four: child inquires the and list box, had better not use at the same time.Sometimes in the application of design, through the list box can really improve user input speed and accuracy, but, if foreground application does not have buffer mechanism, you often can cause congestion.As in a order management system, may need frequent input sales representatives. In order to user input convenience, sales representative often design into a list box. Every time need to input, foreground application from the background of all sales representative inquires information (if the application is not involved in the cache). On one hand, the son of nature, would be speed query slow; Second, the list box have growth time operation of the inquiry. The two parties face touch together, may causethe application of improving the running time process query. And the other user queries, such as the system administrator need to maintain customer information, and cause congestion.So, in the application design, the child inquires the best less. And the child inquires the list box and use at the same time, more need to ban. If you can't avoid it, should be in application realize caching mechanism. That way, the applications need to sales representative information, will from application cache made, not every time to check the database.At the same time, can be in the list box design "to search" function. When there is a change to the user information, such as the system administrator to join a new sales representatives. In no again before inquires, because of their application is achieved in the cache data, so not just updated content. At this time, users will need to run to inquires the function, let the foreground application from a database query information again. This kind of design, can increase the list box and the son of the execution time inquires, effectively avoid congestion.Suggest five: in the set when cancel inquires back issues.Foreground application is designed, should allow users to a temporary change in idea, cancel the query. Such as user inquires the all product information, may feel response time is long, hard to bear. At this time, they will think of cancel inquires the. In this case, the application design need to design a cancel inquires the button. The user can in the process of inquires click this button cancel inquires at any time. Meanwhile, in the button affair, need to pay attention to join a rollback command. Let the database server can prompt to records or table to unlock.At the same time to the best lock or query timeout mechanism. This is largely because, sometimes also can cost a lot inquires user host to a large number of resources, and cause client crash. At this time, to be able to lock the inquires the or overtime mechanisms, namely in inquires after overtime, database server of related objects for automatic unlock. This is also the database administrator need to program developers negotiation of a problem.In addition, explicit database connection to take control in the concurrent users, is expected to full load next use application to bear ability test, use the link, each inquires to set use inquires and lock exceeds the overtime, these methods can effectively avoid the lock conflict obstruction. When database administrators found that blocking the symptoms, can from these aspect, looking for solutions.From the above analysis can see, SQL Server database lock is a double-edged sword. The security database data consistency at the same time, they will give the database caused some negative effect. How do these negative influence to the least, is our database administrators task. In application design, follow the advice above, can effectively solve the problems for the lock blockages, improve the performance of the database. Visible, to basically solve congestion problem, need database management personnel and program developers work together.中文关于数据库死锁的知识数据库本身提供了锁管理机制,但是从一方面,数据库客户端应用程序的“傀儡”,这主要是由于客户端到服务器的完全控制获得的锁的能力。