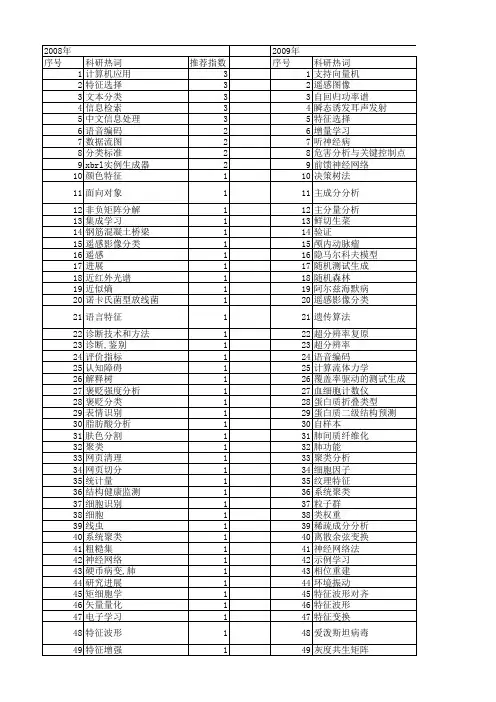
数据挖掘建模——分类方法—方晓萍
- 格式:ppt
- 大小:4.54 MB
- 文档页数:7

统计师如何应对数据挖掘和建模数据挖掘和建模是统计师工作中十分重要的一部分。
随着数据量的不断增加和业务需求的日益复杂化,统计师需要掌握有效的数据挖掘和建模技巧,以解决实际问题并提供准确的决策支持。
本文将介绍统计师应如何应对数据挖掘和建模的挑战,并提供一些实用的技巧和方法。
数据挖掘和建模是从大量的数据中发现并提取有用信息的过程。
统计师在此过程中需要进行数据预处理、特征选择、模型建立和评估等一系列步骤。
首先,在数据预处理阶段,统计师需要对原始数据进行清洗和格式化处理,以消除数据中的噪声和缺失值,并确保数据的一致性和完整性。
其次,在特征选择阶段,统计师需要根据问题的具体需求和数据的特点选择最相关和最具有代表性的特征,以提高模型的性能和解释能力。
然后,在模型建立阶段,统计师需要选择合适的建模算法,并根据实际情况进行模型参数的求解和调优。
最后,在模型评估阶段,统计师需要使用合适的评估指标对模型的性能进行评估,并根据评估结果对模型进行修正和改进。
在应对数据挖掘和建模的挑战时,统计师可以采取以下几点策略。
首先,对于数据预处理,统计师应充分理解数据的特点和背景,并灵活运用数据清洗和格式化的方法,以确保数据的准确性和可用性。
例如,可以使用插补方法填补缺失值,使用异常检测方法识别和处理异常值等。
其次,在特征选择中,统计师应注意选择具有代表性和相关性的特征,并运用数据可视化和相关性分析等方法来帮助选择最佳的特征集。
此外,在模型建立和评估中,统计师可以使用交叉验证和网格搜索等技术来寻找最优的模型参数,并使用AUC、准确率等指标来评估模型的性能和泛化能力。
最后,在应对实际问题时,统计师应借助领域知识和专业经验,将数据挖掘和建模技术与实际业务相结合,以产生可操作和有意义的结果。
除了技巧和方法,统计师还需要具备一些关键的能力和素质来应对数据挖掘和建模的挑战。
首先,统计师需要良好的数理统计基础和数据分析能力,以理解和运用各种统计方法和建模技术。




数据挖掘中的非结构化数据分析方法在当今信息爆炸的时代,各行各业都面临着大量的非结构化数据。
这些数据包括文本、图像、音频、视频等形式,不同于结构化数据的明确格式和规则,非结构化数据的处理和分析一直是数据挖掘领域的难题。
本文将探讨数据挖掘中的非结构化数据分析方法。
一、文本挖掘文本挖掘是非结构化数据分析中的重要领域之一。
在大数据时代,海量的文本数据蕴含着丰富的信息,如何从中提取有用的知识成为了研究的热点。
文本挖掘技术主要包括文本预处理、特征提取和模型建立等步骤。
文本预处理是对文本数据进行清洗和归一化的过程,如去除标点符号、停用词等。
特征提取则是将文本数据转化为可用于分析的数值特征,常用的方法有词袋模型、TF-IDF等。
模型建立阶段则是根据特征进行分类、聚类或关联规则挖掘等任务。
二、图像分析随着数字图像的广泛应用,图像分析成为非结构化数据分析的重要领域之一。
图像分析技术主要包括图像预处理、特征提取和模式识别等步骤。
图像预处理是对图像数据进行去噪、增强和分割等操作,以提高后续分析的准确性。
特征提取则是将图像数据转化为可用于分析的数值特征,常用的方法有颜色直方图、纹理特征等。
模式识别阶段则是根据特征进行目标检测、图像分类等任务。
三、音频处理音频处理是非结构化数据分析中的重要领域之一。
音频数据广泛存在于语音识别、音乐分析等领域,如何从音频数据中提取有用的信息是音频处理的核心任务。
音频处理技术主要包括音频预处理、特征提取和模型建立等步骤。
音频预处理是对音频数据进行去噪、降噪和音频分割等操作,以提高后续分析的准确性。
特征提取则是将音频数据转化为可用于分析的数值特征,常用的方法有MFCC、功率谱等。
模型建立阶段则是根据特征进行语音识别、情感分析等任务。
四、视频分析视频分析是非结构化数据分析中的重要领域之一。
随着视频数据的快速增长,如何从视频数据中提取有用的信息成为了研究的热点。
视频分析技术主要包括视频预处理、特征提取和目标跟踪等步骤。

科技前沿78 2016年5月软件工程中数据挖掘技术的应用研究范凯文北京理工大学珠海学院,广东珠海 519088摘要:随着我国信息技术的不断发展,日常生活和工作中会不断的遇到大量的复杂的信息,如何把这些信息中隐藏的有价值的信息提取出来引发了人们的思考,以软件工程为例,介绍了软件工程和数据挖掘技术的历史、现今的发展,还说明数据挖掘技术的含义和流程;也阐述了数据挖掘技术在软件工程中的应用。
关键词:桥头跳车;城市道路建筑;路基处理;地基沉陷中图分类号:TP311.13 文献标识码:A 文章编号:1009-6434(2016)05-0078-01数据挖掘技术是将大量的数据中将有用的信息部分挖掘出来,将隐藏在数据库中的有价值的信息挖掘搜寻出来,从而提高人们工作质量和效率,因此数据挖掘技术的应用在软件工程领域中显的十分重要。
1 数据挖掘技术和软件工程的历史、发展现状和概念1.1 据挖掘、软件工程的历史数据挖掘在早些年被称为数据库中的知识发现,正式出现于20世纪80年代,数据挖掘的发展是以数据库为基础,起初研究的重点偏重理论的方法,但随着数据挖掘的发展重点转向了系统应用,并且多种学科相互渗透和结合,例如和软件工程的结合与渗透[1]。
软件工程的概念的提出是在1968年北约的科技委员会为了摆脱软件危机的会议上,软件工程专注研究用工程化的方法去维护和构建软件,使软件质量高、经济又安全,软件工程目标是既要满足给定的成本条件和要求的时间限度还要满足用户对软件成品的需求[2]。
1.2 发展现状在上世纪九十年代初期,开始将数据挖掘技术应用于软件工程中,Allen K等人提出用数据挖掘的方式发现代码中的复用关系,在此之后数据挖掘技术在软件工程中发展迅速。
2004年的挖掘软件资源库研讨会标志着数字挖掘技术已经成为软件工程的重要组成部分,它渗透到程序代码分析、漏洞检测、软件项目管理和软件开发等领域[3]。
1.3 数据挖掘技术的定义很多有重要价值的信息隐藏在数据资料中,数据挖掘是采用一定的技术手段从大量的数据中挖掘出重要信息的方法,在软件工程中,数据挖掘技术可以挖掘出有价值的重要的信息来预测系统是否出现漏洞,从而定位出系统出现故障的位置,还可以寻找代码之间的相互关系、进行项目成本评估等等。


收稿日期:2020 01 13;修回日期:2020 03 03 基金项目:国家社科基金重大项目(13&ZD091,18ZDA200) 作者简介:张璐璐(1993 ),女,河北景县人,硕士,主要研究方向为数据挖掘、智能信息处理;赵书良(1967 ),男(通信作者),河北献县人,教授,博导,主要研究方向为数据挖掘、智能信息处理(zhaoshuliang@sina.com);田真真(1994 ),女,河北威县人,硕士,主要研究方向为数据挖掘、智能信息处理;陈润资(1981 ),男,河南潢川人,博士研究生,主要研究方向为数据挖掘、智能信息处理.多尺度分类挖掘算法张璐璐a,b,c,赵书良a,b,c ,田真真a,b,c,陈润资d(河北师范大学a.计算机与网络空间安全学院;b.河北省供应链大数据分析与数据安全工程研究中心;c.河北省网络与信息安全重点实验室;d.数学科学学院,石家庄050024)摘 要:多尺度分类挖掘多局限于空间数据,且对一般数据尺度特性进行分类的研究较少。
针对上述问题,进行普适的多尺度分类方法研究,以扩大多尺度适用范围。
从空间数据估计角度出发,结合层次理论和尺度特性,基于概率密度估计离散化方法,针对数据的多尺度特性进行分类挖掘。
以非局部均值和三次卷积插值为理论基础,利用Q统计和不一致度量进行操作,提出多尺度分类尺度上推算法和多尺度分类尺度下推算法。
采用UCI数据集和H省人口真实数据集进行实验,并与CFW、MSCSUA和MSCSDA等算法进行对比,结果表明,该算法可行有效。
与其他算法相比,尺度上推算法正确率平均提高4.5%,F score提高4.8%,NMI提高12.3%,尺度下推算法各个相应指标分别平均提高5.3%,6.6%和11.8%。
关键词:多尺度;不一致度量;尺度转换;多尺度分类挖掘;Q统计中图分类号:TP391 文献标志码:A 文章编号:1001 3695(2021)02 016 0414 07doi:10.19734/j.issn.1001 3695.2020.01.0007Multi scaleclassificationalgorithmZhangLulua,b,c,ZhaoShulianga,b,c ,TianZhenzhena,b,c,ChenRunzid(a.CollegeofComputer&CyberSecurity,b.HebeiProvincialEngineeringResearchCenterforSupplyChainBigDataAnalytics&DataSecurity,c.KeyLaboratoryofNetwork&InformationSecurity,d.SchoolofMathematicalSciences,HebeiNormalUniversity,Shijiazhuang050024,China)Abstract:Multi scaleclassificationminingaremostlylimitedtospatialdata,andtherearefewresearchesonscalecharacteristicsofgeneraldata.Bysolvingtheaboveproblems,thispapertriedtostudytheuniversalmulti scaleclassificationmethod,inordertoexpandthescopeofmulti scaleapplication.Fromtheperspectiveofspatialdataestimation,combinedthehierar chicaltheoryandscalecharacteristics,andbasedonthediscretizationmethodofprobabilitydensityestimation,thispaperstudiedtheclassificationminingonmulti scalecharacteristicsofgeneraldata.Basedonthetheoryofnon localmeananddoublecubeinterpolation,usingQstatisticsandinconsistentmeasurementtooperate,itproposedtheupscalingalgorithmofmulti scaleclassificationanddownscalingalgorithmofmulti scaleclassification.ThispaperperformedexperimentsonUCIda tasetsandHprovincerealpopulationdataset,andcomparedwithCFW,MSCSUA,MSCSDAandotheralgorithms.Theresultsshowthatthealgorithmsinthispaperarefeasibleandeffective.Comparedwithotheralgorithms,theupscalingalgorithmimprovesaccuracyby4.5%,Fscoreby4.8%andNMIby12.3%andthedownscalingalgorithmimprovesthecorrespon dingindexesby5.3%,6.6%and11.8%.Keywords:multi scale;disagreementmeasure;scaleconversion;multi scaleclassificationmining;Qstatistics0 引言尺度是各种数据自身的属性,普遍存在于客观世界中[1,2]。

统计师如何进行数据挖掘和模型建立数据挖掘和模型建立是统计师在处理大量数据时所应用的重要技能。
本文将介绍统计师如何进行数据挖掘和模型建立的基本步骤和方法。
1. 数据挖掘的基本步骤数据挖掘是从大量数据中发现隐藏在其中的模式、关联规则和趋势的过程。
统计师在进行数据挖掘时,通常需要遵循以下基本步骤:(1) 确定挖掘目标和问题:统计师需要明确自己的挖掘目标,并定义清晰的问题。
例如,分析某产品用户购买行为的模式,以优化市场营销策略。
(2) 数据收集和预处理:统计师需要收集相关数据,并对数据进行预处理。
这包括数据清洗、数据变换和数据集成等操作,以确保数据的质量和一致性。
(3) 特征选择和提取:统计师需要选择合适的特征,或者从原始数据中提取有用的特征。
这有助于降低数据维度和消除冗余信息。
(4) 数据挖掘算法选择和应用:统计师需要根据具体问题选择适合的数据挖掘算法,并将其应用于数据集中。
常用的算法包括关联规则挖掘、聚类分析、分类算法等。
(5) 模型评估和结果解释:统计师需要评估所构建模型的性能,并解释挖掘结果。
这有助于确定模型的可靠性和应用领域。
2. 模型建立的基本步骤模型建立是统计师将数据挖掘的结果应用于实际决策时的关键步骤。
以下是统计师进行模型建立时应考虑的基本步骤:(1) 确定建模目标和问题:统计师需要明确建模的目标,并定义清晰的问题。
例如,预测某产品销量的趋势,以辅助生产计划。
(2) 数据准备和变量选择:统计师需要准备建模所需的数据,并进行变量选择。
这包括数据清洗、特征工程等操作,以确保数据的适用性和质量。
(3) 模型选择和训练:统计师需要选择适合的模型,并采用合适的算法进行训练。
例如,线性回归、决策树、神经网络等模型。
(4) 模型评估和优化:统计师需要评估所构建模型的效果,并对模型进行优化。
这可以通过交叉验证、调整模型参数等方式来实现。
(5) 模型应用和结果解释:统计师需要将建立的模型应用于实际决策中,并解释模型的结果。
数据挖掘技术的使用方法及模型构建数据挖掘技术是一种从大规模数据集中提取出有趣模式和相关信息的过程。
它可以帮助企业和组织发现隐藏在数据背后的知识,以支持决策制定和业务增长。
本文将介绍数据挖掘技术的使用方法以及模型构建过程。
数据挖掘技术的使用方法:1. 理解问题:在开始使用数据挖掘技术之前,首先要明确待解决的问题是什么。
确定目标,明确研究的方向和目的,这有助于指导后续的数据处理和模型建立过程。
2. 数据收集与预处理:数据挖掘的第一步是收集和准备数据。
数据可以来自各种来源,如数据库、文本文件、传感器等。
在收集数据后,需要进行一些预处理步骤,如数据清洗、数据集成、数据转换和数据规约,以确保数据的质量和一致性。
3. 特征选择与转换:在数据挖掘过程中,选择合适的特征对结果的准确性起着至关重要的作用。
特征选择是从原始数据中选择最重要的特征,以减少数据的维度和复杂性。
特征转换是通过数学变换将原始数据转换为适合挖掘的形式,如标准化、离散化等。
4. 模型选择与构建:在选择和构建模型时,需要根据具体问题的性质和数据的特征来确定。
常见的数据挖掘模型包括决策树、神经网络、支持向量机、朴素贝叶斯等。
根据数据集的特点和目标,选择合适的算法并进行模型训练和调优。
5. 模型评估与验证:在模型构建完成后,需要对其进行评估和验证,以确保其准确性和有效性。
常用的评估指标包括准确率、召回率、精确率和F1值等。
通过交叉验证、混淆矩阵等方法对模型进行验证,可以帮助发现模型的潜在问题和改善空间。
6. 模型应用与结果解释:完成模型的评估后,可以将模型应用于实际问题中,并解释其结果。
根据模型输出的结论和建议,制定相应的决策和战略。
同时,对模型结果进行解释和解读,帮助理解和传达数据挖掘的发现。
模型构建的过程:1. 确定目标:首先要明确构建模型的目标是什么,例如预测销售额、识别垃圾邮件,或者推荐产品。
2. 数据准备:收集相关的数据,包括特征和目标变量,并进行数据预处理,如清洗、集成和转换。
68*本文系国家自然科学基金资助项目“用于数据挖掘的神经网络模型及其融合技术研究”(项目编号:60275020课题研究成果之一。
收稿日期:2006-03-25修回日期:2006-07-23本文起止页码:68-71,108钱晓东天津大学电气与自动化工程学院天津300072〔摘要〕对数据挖掘中的核心技术分类算法的内容及其研究现状进行综述。
认为分类算法大体可分为传统分类算法和基于软计算的分类法两类,主要包括相似函数、关联规则分类算法、K 近邻分类算法、决策树分类算法、贝叶斯分类算法和基于模糊逻辑、遗传算法、粗糙集和神经网络的分类算法。
通过论述以上算法优缺点和应用范围,研究者对已有算法的改进有所了解,以便在应用中选择相应的分类算法。
〔关键词〕数据挖掘分类软计算〔分类号〕TP183A Review on Classification Algorithms in Data Mining Qian XiaodongSchool of Electrical Engineering and A utomation, Tianjin University, Tianjin 300072〔Abstract〕As one of the kernel techniques in the data mining, it is necessary to summarize the research status of classification algorithm.Classification algorithms can be divided into classical algorithms and algorithms based on soft computing, primarily including similar function,classification algorithms based on association rule, K-nearest Neighbor, decision tree, Bayes network and classification algorithms based on fuzzy logic, genetic algorithm, neural network and rough sets. By presenting the advantages and disadvantages and the application range of the algorithms mentioned above, it will behelpful for people to improve and select algorithms for applications, and even to develop new ones.〔Keywords〕data mining classification soft computing数据挖掘中分类方法综述*1前言数据挖掘源于20世纪90年代中期,是一个既年轻又活跃的研究领域,涉及机器学习、模式识别、统计学、数据库、知识获取与表达、专家系统、神经网络、模糊数学、遗传算法等多个领域。
数据挖掘又称数据库中的知识发现,是目前人工智能和数据库领域研究的热点问题,所谓数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程利用数据挖掘进行数据分析常用的方法主要有分类、回归分析、聚类、关联规则、特征、变化和偏差分析、Web页挖掘等,它们分别从不同的角度对数据进行挖掘。
① 分类。
分类是找出数据库中一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据库中的数据项映射到某个给定的类别。
它可以应用到客户的分类、客户的属性和特征分析、客户满意度分析、客户的购买趋势预测等,如一个汽车零售商将客户按照对汽车的喜好划分成不同的类,这样营销人员就可以将新型汽车的广告手册直接邮寄到有这种喜好的客户手中,从而大大增加了商业机会。
① 回归分析。
回归分析方法反映的是事务数据库中属性值在时间上的特征,产生一个将数据项映射到一个实值预测变量的函数,发现变量或属性间的依赖关系,其主要研究问题包括数据序列的趋势特征、数据序列的预测以及数据间的相关关系等。
它可以应用到市场营销的各个方面,如客户寻求、保持和预防客户流失活动、产品生命周期分析、销售趋势预测及有针对性的促销活动等。
① 聚类。
聚类分析是把一组数据按照相似性和差异性分为几个类别,其目的是使得属于同一类别的数据间的相似性尽可能大,不同类别中的数据间的相似性尽可能小。
它可以应用到客户群体的分类、客户背景分析、客户购买趋势预测、市场的细分等。
① 关联规则。
关联规则是描述数据库中数据项之间所存在的关系的规则,即根据一个事务中某些项的出现可导出另一些项在同一事务中也出现,即隐藏在数据间的关联或相互关系。
在客户关系管理中,通过对企业的客户数据库里的大量数据进行挖掘,可以从大量的记录中发现有趣的关联关系,找出影响市场营销效果的关键因素,为产品定位、定价与定制客户群,客户寻求、细分与保持,市场营销与推销,营销风险评估和诈骗预测等决策支持提供参考依据。
一种基于几何分布的新支持向量机多分类方法
李雷;房小萍;张宁
【期刊名称】《计算机技术与发展》
【年(卷),期】2012(000)011
【摘要】二叉树支持向量机是多分类问题的一种有效方法,然而分类的效果与二叉树的结构密切相关。
获得更好的分类效果和更高的效率,要使得二叉树高度尽量小而两个子类尽量易分。
距离通常用来衡量两个类的分离程度,但不能反映类的分布情况。
考虑到多分类中类的分布,文中定义新的分离度和相似度来衡量两个类的分离度,并且提出了一中新的基于几何分布二叉树支持向量机多分类算法,该方法使得二叉树高度尽量小而两个子类尽量易分。
实验表明该方法具有较高的分类准确率和效率。
【总页数】4页(P172-175)
【作者】李雷;房小萍;张宁
【作者单位】南京邮电大学理学院,江苏南京 210046;南京邮电大学理学院,江苏南京 210046;南京邮电大学自动化学院,江苏南京 210046
【正文语种】中文
【中图分类】TP31
【相关文献】
1.基于支持向量机的多分类方法研究 [J], 郎宇宁;蔺娟如
2.基于一种新的核聚类方法生成RBF核的支持向量机 [J], 朱昌明
3.基于有序分割的支持向量机多分类方法 [J], 单斌;秦永元;杨颖涛;王蓉;唐大林
4.一种新的基于ART的支持向量机多类分类方法 [J], 王安娜;袁文静;王勤万;刘俊芳
5.基于树状结构的支持向量机多分类方法 [J], 张鸿雁
因版权原因,仅展示原文概要,查看原文内容请购买。
数据挖掘中数据探索方法及应用数据挖掘是从大量的数据中发现模式、关联、异常和趋势等有用信息的过程。
数据挖掘中的数据探索是其中的一项关键任务,它通过对数据进行可视化和统计分析,来发现数据中隐藏的规律和特征。
本文将介绍数据挖掘中常用的数据探索方法及其应用。
一、数据探索方法1.可视化分析:可视化分析是数据探索中常用的方法之一,通过绘制图表和图形来展示数据之间的关系和趋势。
常用的可视化方法包括散点图、折线图、柱状图、饼图等。
可视化分析能够帮助我们直观地了解数据的分布情况,发现数据的异常和规律。
2.描述统计分析:描述统计分析是对数据进行总结和描述的方法,常用的统计指标包括均值、中位数、频数、标准差等。
通过描述统计分析,我们可以了解数据的中心趋势和离散程度,对数据的特征进行描述。
3.相关性分析:相关性分析用于衡量一组变量之间的相关关系。
常用的相关性指标包括皮尔逊相关系数和斯皮尔曼秩相关系数。
通过相关性分析,可以了解变量之间的线性关系和趋势,并进一步筛选出与目标变量相关性较高的变量。
4. 聚类分析:聚类分析是将相似的样本归为一类的过程,常用于对数据进行分类和分组。
常用的聚类算法包括K-means算法和层次聚类算法。
通过聚类分析,我们可以发现数据中潜在的群体和类别。
5.预测模型:预测模型是根据已有的数据和变量之间的关系,来预测未来的值或趋势。
常用的预测模型包括线性回归模型、决策树模型和神经网络模型等。
通过预测模型,我们可以根据历史数据来预测未来的趋势和变化。
二、数据探索应用1.金融领域:数据探索在金融领域的应用非常广泛。
比如,在信用评分中,可以使用数据探索方法来分析与信用相关的变量,找出影响信用评分的关键因素;在投资决策中,可以使用数据探索方法来分析股票、债券等资产的历史数据,预测未来的价格和波动。
2.零售领域:数据探索在零售领域的应用也非常重要。
比如,在销售预测中,可以使用数据探索方法来分析历史销售数据,发现销售的季节性和周期性特征,从而预测未来销售额;在客户细分中,可以使用数据探索方法来分析客户的消费行为和偏好,将客户分为不同的群体,制定个性化的营销策略。